#
http://www.jdon.com/38244最近因為項目原因,研究了Cassandra,Hbase等幾個NoSQL數據庫,最終決定采用HBase。在這里,我就向大家分享一下自己對HBase的理解。
在說HBase之前,我想再嘮叨幾句。做互聯網應用的哥們兒應該都清楚,互聯網應用這東西,你沒辦法預測你的系統什么時候會被多少人訪問,你面臨的用戶到底有多少,說不定今天你的用戶還少,明天系統用戶就變多了,結果您的系統應付不過來了了,不干了,這豈不是咱哥幾個的悲哀,說時髦點就叫“杯具啊”。
其實說白了,這些就是事先沒有認清楚互聯網應用什么才是最重要的。從系統架構的角度來說,互聯網應用更加看重系統性能以及伸縮性,而傳統企業級應用都是比較看重數據完整性和數據安全性。那么我們就來說說互聯網應用伸縮性這事兒.對于伸縮性這事兒,哥們兒我也寫了幾篇博文,想看的兄弟可以參考我以前的博文,對于web server,app server的伸縮性,我在這里先不說了,因為這部分的伸縮性相對來說比較容易一點,我主要來回顧一些一個慢慢變大的互聯網應用如何應對數據庫這一層的伸縮。
首先剛開始,人不多,壓力也不大,搞一臺數據庫服務器就搞定了,此時所有的東東都塞進一個Server里,包括web server,app server,db server,但是隨著人越來越多,系統壓力越來越多,這個時候可能你把web server,app server和db server分離了,好歹這樣可以應付一陣子,但是隨著用戶量的不斷增加,你會發現,數據庫這哥們不行了,速度老慢了,有時候還會宕掉,所以這個時候,你得給數據庫這哥們找幾個伴,這個時候Master-Salve就出現了,這個時候有一個Master Server專門負責接收寫操作,另外的幾個Salve Server專門進行讀取,這樣Master這哥們終于不抱怨了,總算讀寫分離了,壓力總算輕點了,這個時候其實主要是對讀取操作進行了水平擴張,通過增加多個Salve來克服查詢時CPU瓶頸。一般這樣下來,你的系統可以應付一定的壓力,但是隨著用戶數量的增多,壓力的不斷增加,你會發現Master server這哥們的寫壓力還是變的太大,沒辦法,這個時候怎么辦呢?你就得切分啊,俗話說“只有切分了,才會有伸縮性嘛”,所以啊,這個時候只能分庫了,這也是我們常說的數據庫“垂直切分”,比如將一些不關聯的數據存放到不同的庫中,分開部署,這樣終于可以帶走一部分的讀取和寫入壓力了,Master又可以輕松一點了,但是隨著數據的不斷增多,你的數據庫表中的數據又變的非常的大,這樣查詢效率非常低,這個時候就需要進行“水平分區”了,比如通過將User表中的數據按照10W來劃分,這樣每張表不會超過10W了。
綜上所述,一般一個流行的web站點都會經歷一個從單臺DB,到主從復制,到垂直分區再到水平分區的痛苦的過程。其實數據庫切分這事兒,看起來原理貌似很簡單,如果真正做起來,我想凡是sharding過數據庫的哥們兒都深受其苦啊。對于數據庫伸縮的文章,哥們兒可以看看后面的參考資料介紹。
好了,從上面的那一堆廢話中,我們也發現數據庫存儲水平擴張scale out是多么痛苦的一件事情,不過幸好技術在進步,業界的其它弟兄也在努力,09年這一年出現了非常多的NoSQL數據庫,更準確的應該說是No relation數據庫,這些數據庫多數都會對非結構化的數據提供透明的水平擴張能力,大大減輕了哥們兒設計時候的壓力。下面我就拿Hbase這分布式列存儲系統來說說。
一 Hbase是個啥東東?
在說Hase是個啥家伙之前,首先我們來看看兩個概念,面向行存儲和面向列存儲。面向行存儲,我相信大伙兒應該都清楚,我們熟悉的RDBMS就是此種類型的,面向行存儲的數據庫主要適合于事務性要求嚴格場合,或者說面向行存儲的存儲系統適合OLTP,但是根據CAP理論,傳統的RDBMS,為了實現強一致性,通過嚴格的ACID事務來進行同步,這就造成了系統的可用性和伸縮性方面大大折扣,而目前的很多NoSQL產品,包括Hbase,它們都是一種最終一致性的系統,它們為了高的可用性犧牲了一部分的一致性。好像,我上面說了面向列存儲,那么到底什么是面向列存儲呢?Hbase,Casandra,Bigtable都屬于面向列存儲的分布式存儲系統。看到這里,如果您不明白Hbase是個啥東東,不要緊,我再總結一下下:
Hbase是一個面向列存儲的分布式存儲系統,它的優點在于可以實現高性能的并發讀寫操作,同時Hbase還會對數據進行透明的切分,這樣就使得存儲本身具有了水平伸縮性。
二 Hbase數據模型
HBase,Cassandra的數據模型非常類似,他們的思想都是來源于Google的Bigtable,因此這三者的數據模型非常類似,唯一不同的就是Cassandra具有Super cloumn family的概念,而Hbase目前我沒發現。好了,廢話少說,我們來看看Hbase的數據模型到底是個啥東東。
在Hbase里面有以下兩個主要的概念,Row key,Column Family,我們首先來看看Column family,Column family中文又名“列族”,Column family是在系統啟動之前預先定義好的,每一個Column Family都可以根據“限定符”有多個column.下面我們來舉個例子就會非常的清晰了。
假如系統中有一個User表,如果按照傳統的RDBMS的話,User表中的列是固定的,比如schema 定義了name,age,sex等屬性,User的屬性是不能動態增加的。但是如果采用列存儲系統,比如Hbase,那么我們可以定義User表,然后定義info 列族,User的數據可以分為:info:name = zhangsan,info:age=30,info:sex=male等,如果后來你又想增加另外的屬性,這樣很方便只需要info:newProperty就可以了。
也許前面的這個例子還不夠清晰,我們再舉個例子來解釋一下,熟悉SNS的朋友,應該都知道有好友Feed,一般設計Feed,我們都是按照“某人在某時做了標題為某某的事情”,但是同時一般我們也會預留一下關鍵字,比如有時候feed也許需要url,feed需要image屬性等,這樣來說,feed本身的屬性是不確定的,因此如果采用傳統的關系數據庫將非常麻煩,況且關系數據庫會造成一些為null的單元浪費,而列存儲就不會出現這個問題,在Hbase里,如果每一個column 單元沒有值,那么是占用空間的。下面我們通過兩張圖來形象的表示這種關系:
上圖是傳統的RDBMS設計的Feed表,我們可以看出feed有多少列是固定的,不能增加,并且為null的列浪費了空間。但是我們再看看下圖,下圖為Hbase,Cassandra,Bigtable的數據模型圖,從下圖可以看出,Feed表的列可以動態的增加,并且為空的列是不存儲的,這就大大節約了空間,關鍵是Feed這東西隨著系統的運行,各種各樣的Feed會出現,我們事先沒辦法預測有多少種Feed,那么我們也就沒有辦法確定Feed表有多少列,因此Hbase,Cassandra,Bigtable的基于列存儲的數據模型就非常適合此場景。說到這里,采用Hbase的這種方式,還有一個非常重要的好處就是Feed會自動切分,當Feed表中的數據超過某一個閥值以后,Hbase會自動為我們切分數據,這樣的話,查詢就具有了伸縮性,而再加上Hbase的弱事務性的特性,對Hbase的寫入操作也將變得非常快。
上面說了Column family,那么我之前說的Row key是啥東東,其實你可以理解row key為RDBMS中的某一個行的主鍵,但是因為Hbase不支持條件查詢以及Order by等查詢,因此Row key的設計就要根據你系統的查詢需求來設計了額。我還拿剛才那個Feed的列子來說,我們一般是查詢某個人最新的一些Feed,因此我們Feed的Row key可以有以下三個部分構成<userId><timestamp><feedId>,這樣以來當我們要查詢某個人的最進的Feed就可以指定Start Rowkey為<userId><0><0>,End Rowkey為<userId><Long.MAX_VALUE><Long.MAX_VALUE>來查詢了,同時因為Hbase中的記錄是按照rowkey來排序的,這樣就使得查詢變得非常快。
三 Hbase的優缺點
1 列的可以動態增加,并且列為空就不存儲數據,節省存儲空間.
2 Hbase自動切分數據,使得數據存儲自動具有水平scalability.
3 Hbase可以提供高并發讀寫操作的支持
Hbase的缺點:
1 不能支持條件查詢,只支持按照Row key來查詢.
2 暫時不能支持Master server的故障切換,當Master宕機后,整個存儲系統就會掛掉.
關于數據庫伸縮性的一點資料:
http://www.jurriaanpersyn.com/archives/2009/02/12/database-sharding-at-netlog-with-mysql-and-php/http://adam.blog.heroku.com/past/2009/7/6/sql_databases_dont_scale/
- 將INPUT通過SPLIT成M個MAP任務
- JOB TRACKER將這M個任務分派給TASK TRACKER執行
- TASK TRACKER執行完MAP任務后,會在本地生成文件,然后通知JOB TRACKER
- JOB TRACKER收到通知后,將此任務標記為已完成,如果收到失敗的消息,會將此任務重置為原始狀態,再分派給另一TASK TRACKER執行
- 當所有的MAP任務完成后,JOB TRACKER將MAP執行后生成的LIST重新整理,整合相同的KEY,根據KEY的數量生成R個REDUCE任務,再分派給TASK TRACKER執行
- TASK TRACKER執行完REDUCE任務后,會在HDFS生成文件,然后通知JOB TRACKER
- JOB TRACKER等到所有的REDUCE任務執行完后,進行合并,產生最后結果,通知CLIENT
- TASK TRACKER執行完MAP任務時,可以重新生成新的KEY VALUE對,從而影響REDUCE個數
- 假設遠程HADOOP主機名為ubuntu,則應在hosts文件中加上192.168.58.130 ubuntu
- 新建MAVEN項目,加上相應的配置
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.cloudputing</groupId>
<artifactId>bigdata</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>bigdata</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop</artifactId>
<version>0.9.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>0.94.1</version>
</dependency>
<!-- <dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>0.90.2</version>
</dependency> -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>3.0.5.RELEASE</version>
</dependency>
</dependencies>
</project>
-
hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
* Copyright 2010 The Apache Software Foundation
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://ubuntu:9000/hbase</value>
</property>
<!-- 在構造JOB時,會新建一文件夾來準備所需文件。
如果這一段沒寫,則默認本地環境為LINUX,將用LINUX命令去實施,在WINDOWS環境下會出錯 -->
<property>
<name>mapred.job.tracker</name>
<value>ubuntu:9001</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 此處會向ZOOKEEPER咨詢JOB TRACKER的可用IP -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>ubuntu</value>
</property>
<property skipInDoc="true">
<name>hbase.defaults.for.version</name>
<value>0.94.1</value>
</property>
</configuration>
- 測試文件:MapreduceTest.java
package com.cloudputing.mapreduce;
import java.io.IOException;
import junit.framework.TestCase;
public class MapreduceTest extends TestCase{
public void testReadJob() throws IOException, InterruptedException, ClassNotFoundException
{
MapreduceRead.read();
}
}
-
MapreduceRead.java
package com.cloudputing.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.NullOutputFormat;
public class MapreduceRead {
public static void read() throws IOException, InterruptedException, ClassNotFoundException
{
// Add these statements. XXX
// File jarFile = EJob.createTempJar("target/classes");
// EJob.addClasspath("D:/PAUL/WORK/WORK-SPACES/TEST1/cloudputing/src/main/resources");
// ClassLoader classLoader = EJob.getClassLoader();
// Thread.currentThread().setContextClassLoader(classLoader);
Configuration config = HBaseConfiguration.create();
addTmpJar("file:/D:/PAUL/WORK/WORK-SPACES/TEST1/cloudputing/target/bigdata-1.0.jar",config);
Job job = new Job(config, "ExampleRead");
// And add this statement. XXX
// ((JobConf) job.getConfiguration()).setJar(jarFile.toString());
// TableMapReduceUtil.addDependencyJars(job);
// TableMapReduceUtil.addDependencyJars(job.getConfiguration(),
// MapreduceRead.class,MyMapper.class);
job.setJarByClass(MapreduceRead.class); // class that contains mapper
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
// set other scan attrs
TableMapReduceUtil.initTableMapperJob(
"wiki", // input HBase table name
scan, // Scan instance to control CF and attribute selection
MapreduceRead.MyMapper.class, // mapper
null, // mapper output key
null, // mapper output value
job);
job.setOutputFormatClass(NullOutputFormat.class); // because we aren't emitting anything from mapper
// DistributedCache.addFileToClassPath(new Path("hdfs://node.tracker1:9000/user/root/lib/stat-analysis-mapred-1.0-SNAPSHOT.jar"),job.getConfiguration());
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
}
}
/**
* 為Mapreduce添加第三方jar包
*
* @param jarPath
* 舉例:D:/Java/new_java_workspace/scm/lib/guava-r08.jar
* @param conf
* @throws IOException
*/
public static void addTmpJar(String jarPath, Configuration conf) throws IOException {
System.setProperty("path.separator", ":");
FileSystem fs = FileSystem.getLocal(conf);
String newJarPath = new Path(jarPath).makeQualified(fs).toString();
String tmpjars = conf.get("tmpjars");
if (tmpjars == null || tmpjars.length() == 0) {
conf.set("tmpjars", newJarPath);
} else {
conf.set("tmpjars", tmpjars + ":" + newJarPath);
}
}
public static class MyMapper extends TableMapper<Text, Text> {
public void map(ImmutableBytesWritable row, Result value,
Context context) throws InterruptedException, IOException {
String val1 = getValue(value.getValue(Bytes.toBytes("text"), Bytes.toBytes("qual1")));
String val2 = getValue(value.getValue(Bytes.toBytes("text"), Bytes.toBytes("qual2")));
System.out.println(val1 + " -- " + val2);
}
private String getValue(byte [] value)
{
return value == null? "null" : new String(value);
}
}
}
界面:
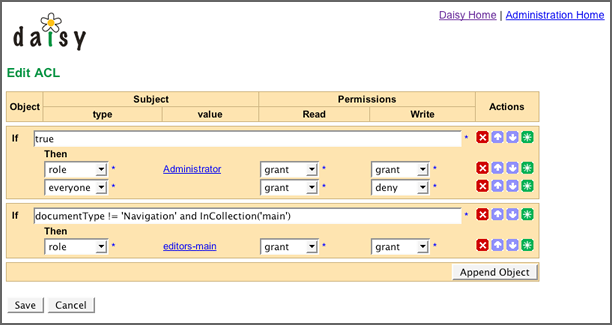
算法:

說明:
http://lilyproject.org/books/daisy_docs_book--2_3/publications/html-chunked/output/s182.html
注意:
此處的ACL可以是一個系統多個的,如某些情況用不同的ACL。
資源:可以指文檔ID,頁面ID之類的,由于文檔可能很多個,因此用表達式代替之。
角色:指ROLE/USER之類的。
動作(PERMISSION):指操作類型,如讀、寫、刪除等。
結果(ACTION):指GRANT、DENNY等。
具體實現方式:根據表達式進行運算,看哪個表達式為TRUE,則用哪個,再傳入PERMISSION 類型,角色,看ACTION是GRANT還是DENNY,如果是GRANT則授權通過,DENNY則授權不通過。
gartner十大戰略性技術分析如下:
1. 移動設備戰爭
移動設備多樣化,Windows僅僅是IT需要支持的多種環境之一,IT需要支持多樣化環境。
2. 移動應用與HTML5
HTML5將變得愈發重要,以滿足多元化的需求,以滿足對安全性非常看重的企業級應用。
3. 個人云
個人云將把重心從客戶端設備向跨設備交付基于云的服務轉移。
4. 企業應用商店
有了企業應用商店,IT的角色將從集權式規劃者轉變為市場管理者,并為用戶提供監管和經紀服務,甚至可能為應用程序專家提供生態系統支持。
5. 物聯網
物聯網是一個概念,描述了互聯網將如何作為物理實物擴展,如消費電子設備和實物資產都連接到互聯網上。
6. 混合型IT和云計算
打造私有云并搭建相應的管理平臺,再利用該平臺來管理內外部服務
7. 戰略性大數據
企業應當將大數據看成變革性的構架,用多元化數據庫代替基于同質劃分的關系數據庫。
8. 可行性分析
大數據的核心在于為企業提供可行的創意。受移動網絡、社交網絡、海量數據等因素的驅動,企業需要改變分析方式以應對新觀點
9. 內存計算
內存計算以云服務的形式提供給內部或外部用戶,數以百萬的事件能在幾十毫秒內被掃描以檢測相關性和規律。
10. 整合生態系統
市場正在經歷從松散耦合的異構系統向更為整合的系統和生態系統轉移,應用程序與硬件、軟件、軟件及服務打包形成整合生態系統。
結合應用實踐及客戶需求,可以有以下結論:
1. 大數據時代已經到來
物聯網發展及非結構化、半結構化數據的劇增推動了大數據應用需求發展。大數據高效應用是挖掘企業數據資源價值的趨勢與發展方向。
2. 云計算依舊是主題,云將更加關注個體
云計算是改變IT現狀的核心技術之一,云計算將是大數據、應用商店交付的基礎。個人云的發展將促使云端服務更關注個體。
3. 移動趨勢,企業應用商店將改變傳統軟件交付模式
Windows將逐步不再是客戶端主流平臺,IT技術需要逐步轉向支持多平臺服務。在云平臺上構建企業應用商店,逐步促成IT的角色將從集權式規劃者轉變為應用市場管理者
4. 物聯網將持續改變工作及生活方式
物聯網將改變生活及工作方式,物聯網將是一種革新的力量。在物聯網方向,IPV6將是值得研究的一個技術。
未來企業IT架構圖如下:

架構說明:
1.應用將被拆分,客戶端將變得極簡,用戶只需要關注極小部分和自己有關的內容,打開系統后不再是上百個業務菜單。
2.企業后端架構將以分布式架構為主,大數據服務能力將成為企業核心競爭力的集中體現。
3.非結構化數據處理及分析相關技術將會得到前所未有的重視。
受個人水平有限,僅供參考,不當之處,歡迎拍磚!
http://blog.csdn.net/sdhustyh/article/details/8484780
@import url(http://www.aygfsteel.com/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
第1章節:
> Hadoop背景
> HDFS設計目標
> HDFS不適合的場景
> HDFS架構詳盡分析
> MapReduce的基本原理
第2章節
> Hadoop的版本介紹
> 安裝單機版Hadoop
> 安裝Hadoop集群
第3章節
> HDFS命令行基本操作
> Namenode的工作機制
> HDFS基本配置管理
第4章節
> HDFS應用實戰:圖片服務器(1) - 系統設計
> 應用的環境搭建 php + bootstrap + java
> 使用Hadoop Java API實現向HDFS寫入文件
第5章節
> HDFS應用實戰:圖片服務器(2)
> 使用Hadoop Java API實現讀取HDFS中的文件
> 使用Hadoop Java API實現獲取HDFS目錄列表
> 使用Hadoop Java API實現刪除HDFS中的文件
第6章節
> MapReduce的基本原理
> MapReduce的運行過程
> 搭建MapReduce的java開發環境
> 使用MapReduce的java接口實現WordCount
第7章節
> WordCount運算過程分析
> MapReduce的combiner
> 使用MapReduce實現數據去重
> 使用MapReduce實現數據排序
> 使用MapReduce實現數據平均成績計算
第8章節
> HBase詳細介紹
> HBase的系統架構
> HBase的表結構,RowKey,列族和時間戳
> HBase中的Master,Region以及Region Server
第9章節
> 使用HBase實現微博應用(1)
> 用戶注冊,登陸和注銷的設計
> 搭建環境 struts2 + jsp + bootstrap + jquery + HBase Java API
> HBase和用戶相關的表結構設計
> 用戶注冊的實現
第10章節
> 使用HBase實現微博應用(2)
> 使用session實現用戶登錄和注銷
> “關注"功能的設計
> “關注"功能的表結構設計
> “關注"功能的實現
第11章節
> 使用HBase實現微博應用(3)
> “發微博"功能的設計
> “發微博"功能的表結構設計
> “發微博"功能的實現
> 展現整個應用的運行
第12章節
> HBase與MapReduce介紹
> HBase如何使用MapReduce
第13章節
> HBase應用實戰:話單查詢與統計(1)
> 應用的整體設計
> 開發環境搭建
> 表結構設計
第14章節
> HBase應用實戰:話單查詢與統計(2)
> 話單入庫單設計與實現
> 話單查詢的設計與實現
第15章節
> HBase應用實戰:話單查詢與統計(3)
> 統計功能設計
> 統計功能實現
第16章節
> 深入MapReduce(1)
> split的實現詳解
> 自定義輸入的實現
> 實例講解
第17章節
> 深入MapReduce(2)
> Reduce的partition
> 實例講解
第18章節
> Hive入門
> 安裝Hive
> 使用Hive向HDFS存入結構化數據
> Hive的基本使用
第19章節
> 使用MySql作為Hive的元數據庫
> Hive結合MapReduce
第20章節
> Hive應用實戰:數據統計(1)
> 應用設計,表結構設計
第21章節
> Hive應用實戰:數據統計(2)
> 數據錄入與統計的實現
1,對于HBase的存儲設計,要考慮它的存儲結構是:rowkey+columnFamily:columnQualifier+timestamp(version)+value = KeyValue in HBase,一個KeyValue依次按照rowkey,columnkey和timestamp有序。一個rowkey加一個column信息定位了hbase表的一個邏輯的行結構。
![0XJJ{2%~G~[G]JBPMW}YE~A](http://www.aygfsteel.com/images/blogjava_net/changedi/Windows-Live-Writer/HBasetip_10C32/0XJJ%7B2%25~G~%5BG%5DJBPMW%7DYE~A_2.jpg "0XJJ{2%~G~[G]JBPMW}YE~A")
2,從邏輯存儲結構到實際的物理存儲結構要經歷一個fold過程,所有的columnFamily下的內容被有序的合并,因為HBase把一個ColumnFamily存儲為一個StoreFile。
3,把HBase的查詢等價為一個逐層過濾的行為,那么在設計存儲時就應該明白,使設計越趨向單一的keyvalue性能會越好;如果是因為復雜的業務邏輯導致查詢需要確定rowkey、column、timestamp,甚至更夸張的是用到了HBase的Filter在server端做value的處理,那么整個性能會非常低。
4,因此在表結構設計時,HBase里有tall narrow和flat wide兩種設計模式,前者行多列少,整個表結構高且窄;后者行少列多,表結構平且寬;但是由于HBase只能在行的邊界做split,因此如果選擇flat wide的結構,那么在特殊行變的超級大(超過file或region的上限)時,那么這種行為會導致compaction,而這樣做是要把row讀內存的~~因此,強烈推薦使用tall narrow模式設計表結構,這樣結構更趨近于keyvalue,性能更好。
5,一種優雅的行設計叫做partial row scan,我們一般rowkey會設計為<key1>-<key2>-<key3>...,每個key都是查詢條件,中間用某種分隔符分開,對于只想查key1的所有這樣的情況,在不使用filter的情況下(更高性能),我們可以為每個key設定一個起始和結束的值,比如key1作為開始,key1+1作為結束,這樣scan的時候可以通過設定start row和stop row就能查到所有的key1的value,同理迭代,每個子key都可以這樣被設計到rowkey中。
6,對于分頁查詢,推薦的設計方式也不是利用filter,而是在scan中通過offset和limit的設定來模擬類似RDBMS的分頁。具體過程就是首先定位start row,接著跳過offset行,讀取limit行,最后關閉scan,整個流程結束。
7,對于帶有時間范圍的查詢,一種設計是把時間放到一個key的位置,這樣設計有個弊端就是查詢時一定要先知道查詢哪個維度的時間范圍值,而不能直接通過時間查詢所有維度的值;另一種設計是把timestamp放到前面,同時利用hashcode或者MD5這樣的形式將其打散,這樣對于實時的時序數據,因為將其打散導致自動分到其他region可以提供更好的并發寫優勢。
8,對于讀寫的平衡,下面這張圖更好的說明了key的設計:salting等價于hash,promoted等價于在key中加入其他維度,而random就是MD這樣的形式了。

9,還有一種高級的設計方式是利用column來當做RDBMS類似二級索引的應用設計,rowkey的存儲達到一定程度后,利用column的有序,完成類似索引的設計,比如,一個CF叫做data存放數據本身,ColumnQualifier是一個MD5形式的index,而value是實際的數據;再建一個CF叫做index存儲剛才的MD5,這個index的CF的ColumnQualifier是真正的索引字段(比如名字或者任意的表字段,這樣可以允許多個),而value是這個索引字段的MD5。每次查詢時就可以先在index里找到這個索引(查詢條件不同,選擇的索引字段不同),然后利用這個索引到data里找到數據,兩次查詢實現真正的復雜條件業務查詢。
10,實現二級索引還有其他途徑,
比如:
1,客戶端控制,即一次讀取將所有數據取回,在客戶端做各種過濾操作,優點自然是控制力比較強,但是缺點在性能和一致性的保證上;
2,Indexed-Transactional HBase,這是個開源項目,擴展了HBase,在客戶端和服務端加入了擴展實現了事務和二級索引;
3,Indexed-HBase;
4,Coprocessor。
11,HBase集成搜索的方式有多種:1,客戶端控制,同上;2,Lucene;3,HBasene,4,Coprocessor。
12,HBase集成事務的方式:1,ITHBase;2,ZooKeeper,通過分布式鎖。
13,timestamp雖然叫這個名字,但是完全可以存放任何內容來形成用戶自定義的版本信息。
應用服務器Apache企業應用XMLC
簡介
James 是一個企業級的郵件服務器,它完全實現了smtp 和 pops 以及nntp 協議。同時,james服務器又是一個郵件應用程序平臺。James的核心是Mailet API,而james 服務齊是一個mailet的容器。它可以讓你非常容易的實現出很強大的郵件應用程序。James開源項目被廣泛的應用于與郵件有關的項目中。你可以通過它來搭建自己的郵件服務器。我們可以利用Mailet API,編程接口來實現自己所需的業務。James集成了Avalon 應用程序框架以及Phoenix Avalon 框架容器。Phoenix為james 服務器提供了強大的支持。需要說明的是Avalon開源項目目前已經關閉。
快速上手
安裝james
我這次使用的安裝包是james 2.3.1。大家可以從這里下載到http://james.apache.org/download.cgi
現在讓我們開始我們激動人心的james之旅。首先我們將james-binary-2.3.1.zip解壓縮下載到你的安裝目錄。我們可以把這個過程理解為安裝的過程。我在這里將它解壓到c:\.并且把它改名為james.這樣我們的james就安裝好了。目錄為C:\james。很簡單吧!
準備知識 - 學習一些必要的知識
在我使用james的時候讓我感覺首先理解james的應用程序結構是很重要的。否則你會在使用中感到很困惑。
它的應用程序結構是這樣的:
James
|_ _apps
|_ _bin
|_ _conf
|_ _ext
|_ _lib
|_ _logs
|_ _tools
我們重點介紹一下兩個文件夾bin 和 apps.
bin目錄中的run.bat和run.sh是James的啟動程序。只要記住這個重要文件就可以。
啟動之后控制臺顯示如下:
Using PHOENIX_HOME: C:\james
Using PHOENIX_TMPDIR: C:\james\temp
Using JAVA_HOME: C:\j2sdk1.4.2_02
Phoenix 4.2
James Mail Server 2.3.1
Remote Manager Service started plain:4555
POP3 Service started plain:110
SMTP Service started plain:25
NNTP Service started plain:119
FetchMail Disabled
Apps 目錄下有個james的子目錄這個目錄是它的核心。
james
|_ _SAR-INF
|_ _conf
|_ _logs
|_ _var
|_mail
|_address-error
|_error
|_indexes
|_outgoing
|_relay-denied
|_spam
|_spool
|_nntp
|_....
…
|_users
SAR-INF 下有一個config.xml是james中的核心配置文件。
Logs 包含了與james有關的Log。調試全靠它了。
Var 包含了一些文件夾通過它們的名字我們大概也能猜測出它們的用途。Mail主要用于存儲郵件。nntp主要用于新聞服務器。Users用于存儲所有郵件服務器的用戶。也就是郵件地址前面的東東。如:pig@sina.com的pig就是所謂用用戶。
創建用戶:
我們在James上建若干用戶,用來測試收發郵件。當然如果你不用james本身的用戶也可以。James以telnet 的方式提供了接口用來添加用戶。下面我來演示一下。
首先使用telnet來連接james的remote manager .
1.telnet localhost 4555 回車
2.然后輸入管理員用戶名和密碼(user/pwd : root/root 是默認設置這個可以在config.xml中修改)
JAMES Remote Administration Tool 2.3.1
Please enter your login and password
Login id:
root
Password:
root
Welcome root. HELP for a list of commands
3.添加用戶
adduser kakaxi kakaxi
User kakaxi added
Adduser mingren mingren
User mingren added
4.查看添加情況
listusers
Existing accounts 2
user: mingren
user: kakaxi
得到上面的信息說明我們已經添加成功。
發送器
這個類主要用來測試我們的郵件服務器,可以不用將其打入包中。
java 代碼
package com.paul.jamesstudy;
import java.util.Date;
import java.util.Properties;
import javax.mail.Authenticator;
import javax.mail.Message;
import javax.mail.PasswordAuthentication;
import javax.mail.Session;
import javax.mail.Transport;
import javax.mail.internet.InternetAddress;
import javax.mail.internet.MimeMessage;
public class Mail {
private String mailServer, From, To, mailSubject, MailContent;
private String username, password;
private Session mailSession;
private Properties prop;
private Message message;
// Authenticator auth;//認證
public Mail() {
// 設置郵件相關
username = "kakaxi";
password = "kakaxi";
mailServer = "localhost";
From = "kakaxi@localhost";
To = "mingren@localhost";
mailSubject = "Hello Scientist";
MailContent = "How are you today!";
}
public void send(){
EmailAuthenticator mailauth =
new EmailAuthenticator(username, password);
// 設置郵件服務器
prop = System.getProperties();
prop.put("mail.smtp.auth", "true");
prop.put("mail.smtp.host", mailServer);
// 產生新的Session服務
mailSession = mailSession.getDefaultInstance(prop,
(Authenticator) mailauth);
message = new MimeMessage(mailSession);
try {
message.setFrom(new InternetAddress(From)); // 設置發件人
message.setRecipient(Message.RecipientType.TO,
new InternetAddress(To));// 設置收件人
message.setSubject(mailSubject);// 設置主題
message.setContent(MailContent, "text/plain");// 設置內容
message.setSentDate(new Date());// 設置日期
Transport tran = mailSession.getTransport("smtp");
tran.connect(mailServer, username, password);
tran.send(message, message.getAllRecipients());
tran.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
Mail mail;
mail = new Mail();
System.out.println("sending");
mail.send();
System.out.println("finished!");
}
}
class EmailAuthenticator extends Authenticator {
private String m_username = null;
private String m_userpass = null;
void setUsername(String username) {
m_username = username;
}
void setUserpass(String userpass) {
m_userpass = userpass;
}
public EmailAuthenticator(String username, String userpass) {
super();
setUsername(username);
setUserpass(userpass);
}
public PasswordAuthentication getPasswordAuthentication() {
return new PasswordAuthentication(m_username, m_userpass);
}
}
FTP服務器中,如果使用的是FTP協議,則用戶名和密碼是以明文方式傳輸的,如果是以SFTP 的方式,就會通過加密的方式傳輸。
如果服務器中的用戶增加了公鑰的設置,則要求客戶端要有相對應的私鑰。
public void setupSftpServer(){
SshServer sshd = SshServer.setUpDefaultServer();
sshd.setPort(22);
sshd.setKeyPairProvider(new SimpleGeneratorHostKeyProvider("hostkey.ser"));
List<NamedFactory<UserAuth>> userAuthFactories = new ArrayList<NamedFactory<UserAuth>>();
userAuthFactories.add(new UserAuthNone.Factory());
sshd.setUserAuthFactories(userAuthFactories);
sshd.setCommandFactory(new ScpCommandFactory());
List<NamedFactory<Command>> namedFactoryList = new ArrayList<NamedFactory<Command>>();
namedFactoryList.add(new SftpSubsystem.Factory());
sshd.setSubsystemFactories(namedFactoryList);
try {
sshd.start();
} catch (Exception e) {
e.printStackTrace();
}
}
在這里介紹對sftp操作的一種java框架:JSch-Java Secure Channel,官方地址是:
http://www.jcraft.com/jsch/
具體使用方法請看下面代碼:
package jsch;
import java.io.File;
import java.io.FileInputStream;
import java.util.Properties;
import com.jcraft.jsch.Channel;
import com.jcraft.jsch.ChannelSftp;
import com.jcraft.jsch.JSch;
import com.jcraft.jsch.JSchException;
import com.jcraft.jsch.Session;
public class Test {
protected String host;//sftp服務器ip
protected String username;//用戶名
protected String password;//密碼
protected String privateKey;//密鑰文件路徑
protected String passphrase;//密鑰口令
protected int port = 22;//默認的sftp端口號是22
/**
* 獲取連接
* @return channel
*/
public ChannelSftp connectSFTP() {
JSch jsch = new JSch();
Channel channel = null;
try {
if (privateKey != null && !"".equals(privateKey)) {
//使用密鑰驗證方式,密鑰可以使有口令的密鑰,也可以是沒有口令的密鑰
if (passphrase != null && "".equals(passphrase)) {
jsch.addIdentity(privateKey, passphrase);
} else {
jsch.addIdentity(privateKey);
}
}
Session session = jsch.getSession(username, host, port);
if (password != null && !"".equals(password)) {
session.setPassword(password);
}
Properties sshConfig = new Properties();
sshConfig.put("StrictHostKeyChecking", "no");// do not verify host key
session.setConfig(sshConfig);
// session.setTimeout(timeout);
session.setServerAliveInterval(92000);
session.connect();
//參數sftp指明要打開的連接是sftp連接
channel = session.openChannel("sftp");
channel.connect();
} catch (JSchException e) {
e.printStackTrace();
}
return (ChannelSftp) channel;
}
/**
* 上傳文件
*
* @param directory
* 上傳的目錄
* @param uploadFile
* 要上傳的文件
* @param sftp
*/
public void upload(String directory, String uploadFile, ChannelSftp sftp) {
try {
sftp.cd(directory);
File file = new File(uploadFile);
sftp.put(new FileInputStream(file), file.getName());
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 下載文件
*
* @param directory
* 下載目錄
* @param downloadFile
* 下載的文件
* @param saveFile
* 存在本地的路徑
* @param sftp
*/
public void download(String directory, String downloadFile,
String saveFile, ChannelSftp sftp) {
try {
sftp.cd(directory);
sftp.get(downloadFile,saveFile);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 刪除文件
*
* @param directory
* 要刪除文件所在目錄
* @param deleteFile
* 要刪除的文件
* @param sftp
*/
public void delete(String directory, String deleteFile, ChannelSftp sftp) {
try {
sftp.cd(directory);
sftp.rm(deleteFile);
} catch (Exception e) {
e.printStackTrace();
}
}
public void disconnected(ChannelSftp sftp){
if (sftp != null) {
try {
sftp.getSession().disconnect();
} catch (JSchException e) {
e.printStackTrace();
}
sftp.disconnect();
}
}
}
在jsch自帶的例子中,有一個可以根據密鑰生成公鑰的類,叫做UserAuthPubKey.java, 且帶有圖形界面。有用到的可以自己試試。