NoSQL Benchmarking
http://www.cubrid.org/blog/dev-platform/nosql-benchmarking/
http://www.badrit.com/blog/2013/11/18/redis-vs-mongodb-performance#.VMpfW2SUfsg
How many requests per second can I get out of Redis?
http://skipperkongen.dk/2013/08/27/how-many-requests-per-second-can-i-get-out-of-redis/
redisжҖ§иғҪӢ№ӢиҜ•еQҢжөӢиҜ•еЖҲеҸ‘жҖ§иғҪ
http://my.oschina.net/pblack/blog/102394
Architecture for Redis cache & Mongo for persistence
http://stackoverflow.com/questions/11218941/architecture-for-redis-cache-mongo-for-persistence
MongoDB with redis
http://stackoverflow.com/questions/10696463/mongodb-with-redis/10721249#10721249
Caching Data in Spring Using Redis
http://caseyscarborough.com/blog/2014/12/18/caching-data-in-spring-using-redis/
Springside Redis
https://github.com/springside/springside4/wiki/Redis
Spring CacheжіЁи§Ј+Redis
http://hanqunfeng.iteye.com/blog/2176172
Codis жҳҜдёҖдёӘеҲҶеёғејҸ Redis и§ЈеҶіж–ТҺЎҲ, еҜ№дәҺдёҠеұӮзҡ„еә”з”ЁжқҘиҜ? ҳqһжҺҘеҲ?Codis Proxy е’ҢиҝһжҺҘеҺҹз”ҹзҡ„ Redis Server жІЎжңүжҳҺжҳҫзҡ„еҢәеҲ?(дёҚж”ҜжҢҒзҡ„е‘ҪдЧoеҲ—иЎЁ), дёҠеұӮеә”з”ЁеҸҜд»ҘеғҸдӢЙз”ЁеҚ•жңәзҡ„ Redis дёҖж ·дӢЙз”? Codis еә•еұӮдјҡеӨ„зҗҶиҜ·жұӮзҡ„иҪ¬еҸ‘, дёҚеҒңжңәзҡ„ж•°жҚ®ҳqҒ移Ҫ{үе·ҘдҪ? жүҖжңүеҗҺиҫ№зҡ„дёҖеҲҮдәӢжғ? еҜ№дәҺеүҚйқўзҡ„е®ўжҲпL«ҜжқҘиҜҙжҳҜйҖҸжҳҺзҡ? еҸҜд»ҘҪҺҖеҚ•зҡ„и®ӨдШ“еҗҺиҫ№ҳqһжҺҘзҡ„жҳҜдёҖдёӘеҶ…еӯҳж— йҷҗеӨ§зҡ?Redis жңҚеҠЎ.
Codis з”ұеӣӣйғЁеҲҶҫl„жҲҗ:
Codis Proxy (codis-proxy)
Codis Manager (codis-config)
Codis Redis (codis-server)
ZooKeeper
codis-proxy жҳҜе®ўжҲпL«ҜҳqһжҺҘзҡ?Redis д»ЈзҗҶжңҚеҠЎ, codis-proxy жң¬инnе®һзҺ°дә?Redis еҚҸи®®, иЎЁзҺ°еҫ—е’ҢдёҖдёӘеҺҹз”ҹзҡ„ Redis жІЎд»Җд№ҲеҢәеҲ?(һ®ұеғҸ Twemproxy), еҜ№дәҺдёҖдёӘдёҡеҠЎжқҘиҜ? еҸҜд»ҘйғЁзЦvеӨҡдёӘ codis-proxy, codis-proxy жң¬инnжҳҜж— зҠ¶жҖҒзҡ„.
codis-config жҳ?Codis зҡ„з®ЎзҗҶе·Ҙе…? ж”ҜжҢҒеҢ…жӢ¬, ж·ХdҠ /еҲ йҷӨ Redis иҠӮзӮ№, ж·ХdҠ /еҲ йҷӨ Proxy иҠӮзӮ№, еҸ‘и“vж•°жҚ®ҳqҒ移Ҫ{үж“ҚдҪ? codis-config жң¬инnҳqҳиҮӘеёҰдәҶдёҖдё?http server, дјҡеҗҜеҠЁдёҖдё?dashboard, з”ЁжҲ·еҸҜд»ҘзӣҙжҺҘеңЁжөҸи§ҲеҷЁдёҠи§ӮеҜ?Codis йӣҶзҫӨзҡ„иҝҗиЎҢзҠ¶жҖ?
codis-server жҳ?Codis ҷе№зӣ®ҫlҙжҠӨзҡ„дёҖдё?Redis еҲҶж”Ҝ, еҹЮZәҺ 2.8.13 ејҖеҸ? еҠ е…Ҙдә?slot зҡ„ж”ҜжҢҒе’ҢеҺҹеӯҗзҡ„ж•°жҚ®иҝҒҝUАLҢҮд»? Codis дёҠеұӮзҡ?codis-proxy е’?codis-config еҸӘиғҪе’ҢиҝҷдёӘзүҲжң¬зҡ„ Redis дәӨдә’жүҚиғҪжӯЈеёёҳqҗиЎҢ.
Codis дҫқиө– ZooKeeper жқҘеӯҳж”ҫж•°жҚ®иө\з”ЮpЎЁе’?codis-proxy иҠӮзӮ№зҡ„е…ғдҝЎжҒҜ, codis-config еҸ‘и“vзҡ„е‘Ҫд»ӨйғҪдјҡйҖҡиҝҮ ZooKeeper еҗҢжӯҘеҲ°еҗ„дёӘеӯҳӢzИқҡ„ codis-proxy.
Codis ж”ҜжҢҒжҢүз…§ Namespace еҢәеҲҶдёҚеҗҢзҡ„дс”е“? жӢҘжңүдёҚеҗҢзҡ?product name зҡ„дс”е“? еҗ„йЎ№й…ҚзҪ®йғҪдёҚдјҡеҶІҪH?
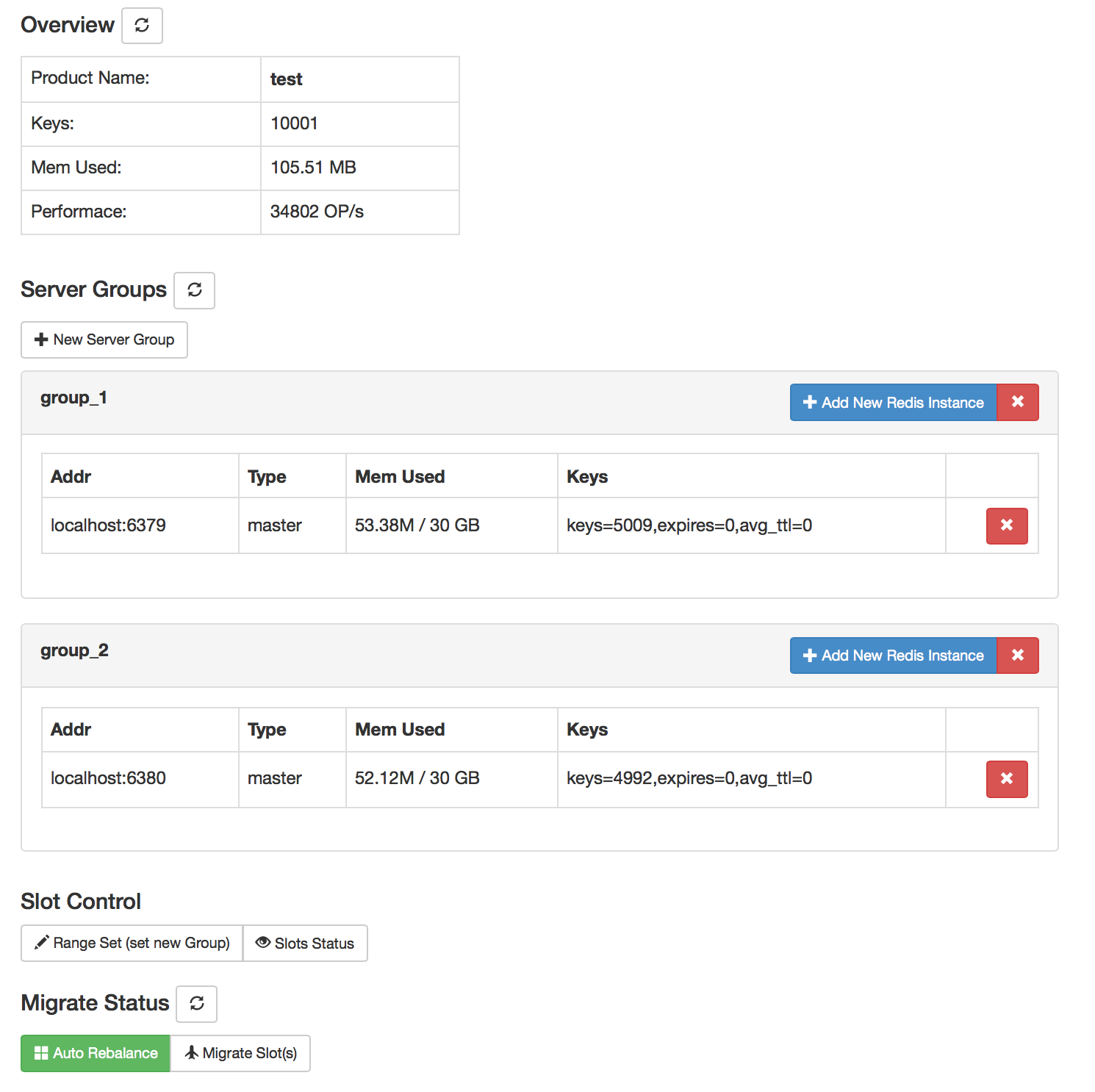
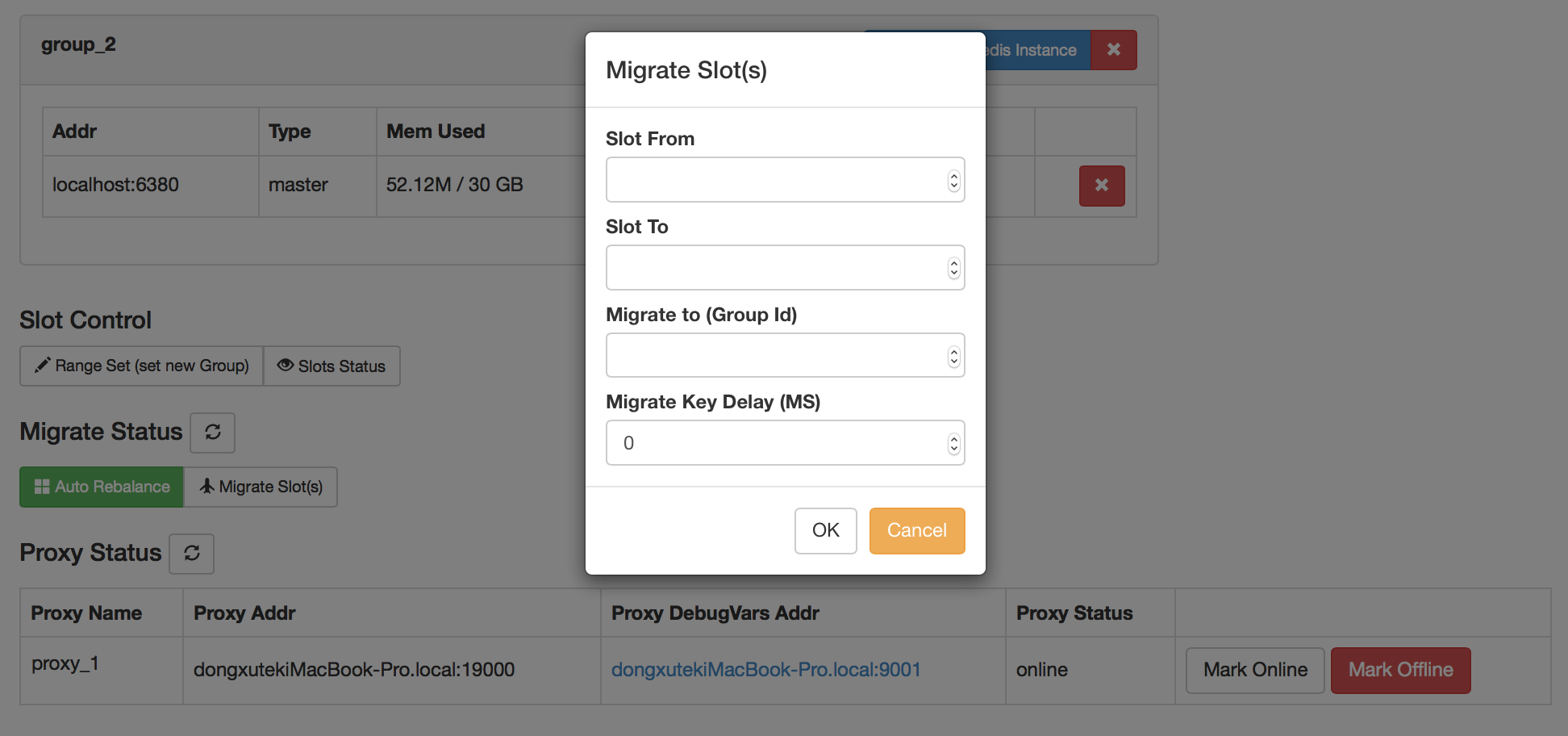
зӣ®еүҚ Codis е·Із»ҸжҳҜзЁіе®ҡйҳ¶ҢDөпјҢзӣ®еүҚиұҢиұҶиҚ?/a>е·Із»ҸеңЁдӢЙз”ЁиҜҘҫpИқ»ҹгҖ?/p> жһ¶жһ„еQ?/p> зүТҺҖ§пјҡ иҮӘеҠЁтqҢҷЎЎ дҪҝз”ЁйқһеёёҪҺҖеҚ?/p> еӣ‘ЦЕһеҢ–зҡ„йқўжқҝе’Ңз®ЎзҗҶе·Ҙе…?/p> ж”ҜжҢҒҫlқеӨ§еӨҡж•° Redis е‘ҪдЧoеQҢе®Ңе…Ёе…је®?nbsp;twemproxy ж”ҜжҢҒ Redis еҺҹз”ҹе®ўжҲ·з«?/p> е®үе…ЁиҖҢдё”йҖҸжҳҺзҡ„ж•°жҚ®з§»жӨҚпјҢеҸҜж №жҚ®йңҖиҰҒиҪ»жқҫж·»еҠ е’ҢеҲ йҷӨиҠӮзӮ№ жҸҗдҫӣе‘ҪдЧoиЎҢжҺҘеҸ?/p> RESTful APIs е®үиЈ…еQ?/p> Install go go get github.com/wandoulabs/codis cd codis ./bootstrap.sh make gotest cd sample follow instructions in usage.md з•ҢйқўжҲӘеӣҫеQ?/p> Dashboard Migrate Slots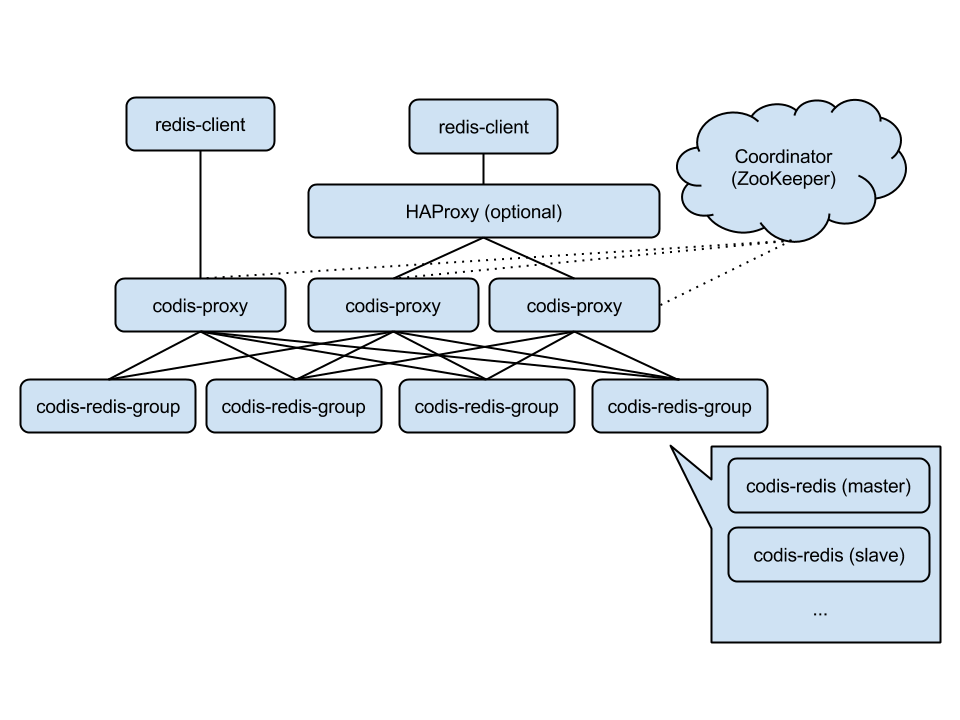
дёҖгҖҒжҷ®йҖҡеҗҢжӯҘж–№еј?/h3>
жңҖҪҺҖеҚ•е’ҢеҹәзЎҖзҡ„и°ғз”Ёж–№ејҸпјҢ
@Test public void test1Normal() { Jedis jedis = new Jedis("localhost"); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { String result = jedis.set("n" + i, "n" + i); } long end = System.currentTimeMillis(); System.out.println("Simple SET: " + ((end - start)/1000.0) + " seconds"); jedis.disconnect(); }еҫҲз®ҖеҚ•еҗ§еQҢжҜҸӢЖ?code style="padding: 1px 3px; margin: 0px 2px; font-family: Consolas, 'Bitstream Vera Sans Mono', 'Courier New', Courier, 'monospace !important'; border: 1px solid #eeeeee; border-top-left-radius: 3px; border-top-right-radius: 3px; border-bottom-right-radius: 3px; border-bottom-left-radius: 3px; word-break: break-all; color: #40aa53; background-color: #fcfcfc;">setд№ӢеҗҺйғҪеҸҜд»Ҙиҝ”еӣһз»“жһңпјҢж Үи®°жҳҜеҗҰжҲҗеҠҹгҖ?/p>
дәҢгҖҒдәӢеҠЎж–№еј?Transactions)
redisзҡ„дәӢеҠЎеҫҲҪҺҖеҚ•пјҢд»–дё»иҰҒзӣ®зҡ„жҳҜдҝқйҡңеQҢдёҖдёӘclientеҸ‘и“vзҡ„дәӢеҠЎдёӯзҡ„е‘Ҫд»ӨеҸҜд»Ҙиҝһҫlӯзҡ„жү§иЎҢеQҢиҖҢдёӯй—ҙдёҚдјҡжҸ’е…Ҙе…¶д»–clientзҡ„е‘Ҫд»ӨгҖ?/p>
зңӢдёӢйқўдҫӢеӯҗпјҡ
@Test public void test2Trans() { Jedis jedis = new Jedis("localhost"); long start = System.currentTimeMillis(); Transaction tx = jedis.multi(); for (int i = 0; i < 100000; i++) { tx.set("t" + i, "t" + i); } List<Object> results = tx.exec(); long end = System.currentTimeMillis(); System.out.println("Transaction SET: " + ((end - start)/1000.0) + " seconds"); jedis.disconnect(); }жҲ‘们и°ғз”Ёjedis.watch(…)ж–ТҺі•жқҘзӣ‘жҺ§keyеQҢеҰӮжһңи°ғз”ЁеҗҺkeyеҖјеҸ‘з”ҹеҸҳеҢ–пјҢеҲҷж•ҙдёӘдәӢеҠЎдјҡжү§иЎҢеӨЮpУ|гҖӮеҸҰеӨ–пјҢдәӢеҠЎдёӯжҹҗдёӘж“ҚдҪңеӨұиҙҘпјҢтq¶дёҚдјҡеӣһж»ҡе…¶д»–ж“ҚдҪңгҖӮиҝҷдёҖзӮҡwңҖиҰҒжіЁж„ҸгҖӮиҝҳжңүпјҢжҲ‘们еҸҜд»ҘдҪҝз”Ёdiscard()ж–ТҺі•жқҘеҸ–ж¶ҲдәӢеҠЎгҖ?/p>
дёүгҖҒз®ЎйҒ?Pipelining)
жңүж—¶еQҢжҲ‘们йңҖиҰҒйҮҮз”ЁејӮжӯҘж–№ејҸпјҢдёҖӢЖЎеҸ‘йҖҒеӨҡдёӘжҢҮд»ӨпјҢдёҚеҗҢжӯҘзӯүеҫ…е…¶ҳq”еӣһҫl“жһңгҖӮиҝҷж ·еҸҜд»ҘеҸ–еҫ—йқһеёёеҘҪзҡ„жү§иЎҢж•ҲзҺҮгҖӮиҝҷһ®ұжҳҜҪҺЎйҒ“еQҢи°ғз”Ёж–№жі•еҰӮдёӢпјҡ
@Test public void test3Pipelined() { Jedis jedis = new Jedis("localhost"); Pipeline pipeline = jedis.pipelined(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { pipeline.set("p" + i, "p" + i); } List<Object> results = pipeline.syncAndReturnAll(); long end = System.currentTimeMillis(); System.out.println("Pipelined SET: " + ((end - start)/1000.0) + " seconds"); jedis.disconnect(); }еӣӣгҖҒз®ЎйҒ“дёӯи°ғз”ЁдәӢеҠЎ
һ®ұJedisжҸҗдҫӣзҡ„ж–№жі•иҖҢиЁҖеQҢжҳҜеҸҜд»ҘеҒҡеҲ°еңЁз®ЎйҒ“дёӯдҪҝз”ЁдәӢеҠЎеQҢе…¶д»Јз ҒеҰӮдёӢеQ?/p>
@Test public void test4combPipelineTrans() { jedis = new Jedis("localhost"); long start = System.currentTimeMillis(); Pipeline pipeline = jedis.pipelined(); pipeline.multi(); for (int i = 0; i < 100000; i++) { pipeline.set("" + i, "" + i); } pipeline.exec(); List<Object> results = pipeline.syncAndReturnAll(); long end = System.currentTimeMillis(); System.out.println("Pipelined transaction: " + ((end - start)/1000.0) + " seconds"); jedis.disconnect(); }дҪҶжҳҜҫlҸжөӢиҜ•пјҲи§Ғжң¬ж–ҮеҗҺҫlӯйғЁеҲҶпјүеQҢеҸ‘зҺ°е…¶ж•ҲзҺҮе’ҢеҚ•зӢ¬дӢЙз”ЁдәӢеҠЎе·®дёҚеӨҡеQҢз”ҡиҮҢҷҝҳз•Ҙеҫ®е·®зӮ№гҖ?/p>
дә”гҖҒеҲҶеёғејҸзӣҙиҝһеҗҢжӯҘи°ғз”Ё
@Test public void test5shardNormal() { List<JedisShardInfo> shards = Arrays.asList( new JedisShardInfo("localhost",6379), new JedisShardInfo("localhost",6380)); ShardedJedis sharding = new ShardedJedis(shards); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { String result = sharding.set("sn" + i, "n" + i); } long end = System.currentTimeMillis(); System.out.println("Simple@Sharing SET: " + ((end - start)/1000.0) + " seconds"); sharding.disconnect(); }ҳqҷдёӘжҳҜеҲҶеёғејҸзӣҙжҺҘҳqһжҺҘеQҢеЖҲдё”жҳҜеҗҢжӯҘи°ғз”ЁеQҢжҜҸжӯҘжү§иЎҢйғҪҳq”еӣһжү§иЎҢҫl“жһңгҖӮзұ»дјјең°еQҢиҝҳжңүејӮжӯҘз®ЎйҒ“и°ғз”ЁгҖ?/p>
е…ӯгҖҒеҲҶеёғејҸзӣҙиҝһејӮжӯҘи°ғз”Ё
@Test public void test6shardpipelined() { List<JedisShardInfo> shards = Arrays.asList( new JedisShardInfo("localhost",6379), new JedisShardInfo("localhost",6380)); ShardedJedis sharding = new ShardedJedis(shards); ShardedJedisPipeline pipeline = sharding.pipelined(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { pipeline.set("sp" + i, "p" + i); } List<Object> results = pipeline.syncAndReturnAll(); long end = System.currentTimeMillis(); System.out.println("Pipelined@Sharing SET: " + ((end - start)/1000.0) + " seconds"); sharding.disconnect(); }дёғгҖҒеҲҶеёғејҸҳqһжҺҘжұ еҗҢжӯҘи°ғз”?/h3>
еҰӮжһңеQҢдҪ зҡ„еҲҶеёғејҸи°ғз”Ёд»Јз ҒжҳҜиҝҗиЎҢеңЁҫUҝзЁӢдёӯпјҢйӮЈд№ҲдёҠйқўдёӨдёӘзӣҙиҝһи°ғз”Ёж–№ејҸһ®ЧғёҚеҗҲйҖӮдәҶеQҢеӣ дёәзӣҙҳqһж–№ејҸжҳҜйқһзәҝҪEӢе®үе…Ёзҡ„еQҢиҝҷдёӘж—¶еҖҷпјҢдҪ е°ұеҝ…йЎ»йҖүжӢ©ҳqһжҺҘжұ и°ғз”ЁгҖ?/p>
@Test public void test7shardSimplePool() { List<JedisShardInfo> shards = Arrays.asList( new JedisShardInfo("localhost",6379), new JedisShardInfo("localhost",6380)); ShardedJedisPool pool = new ShardedJedisPool(new JedisPoolConfig(), shards); ShardedJedis one = pool.getResource(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { String result = one.set("spn" + i, "n" + i); } long end = System.currentTimeMillis(); pool.returnResource(one); System.out.println("Simple@Pool SET: " + ((end - start)/1000.0) + " seconds"); pool.destroy(); }дёҠйқўжҳҜеҗҢжӯҘж–№ејҸпјҢеҪ“然ҳqҳжңүејӮжӯҘж–№ејҸгҖ?/p>
е…«гҖҒеҲҶеёғејҸҳqһжҺҘжұ ејӮжӯҘи°ғз”?/h3>@Test public void test8shardPipelinedPool() { List<JedisShardInfo> shards = Arrays.asList( new JedisShardInfo("localhost",6379), new JedisShardInfo("localhost",6380)); ShardedJedisPool pool = new ShardedJedisPool(new JedisPoolConfig(), shards); ShardedJedis one = pool.getResource(); ShardedJedisPipeline pipeline = one.pipelined(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { pipeline.set("sppn" + i, "n" + i); } List<Object> results = pipeline.syncAndReturnAll(); long end = System.currentTimeMillis(); pool.returnResource(one); System.out.println("Pipelined@Pool SET: " + ((end - start)/1000.0) + " seconds"); pool.destroy(); }д№қгҖҒйңҖиҰҒжіЁж„Ҹзҡ„ең°ж–№
дәӢеҠЎе’Ңз®ЎйҒ“йғҪжҳҜејӮжӯҘжЁЎејҸгҖӮеңЁдәӢеҠЎе’Ңз®ЎйҒ“дёӯдёҚиғҪеҗҢжӯҘжҹҘиҜўҫl“жһңгҖӮжҜ”еҰӮдёӢйқўдёӨдёӘи°ғз”ЁпјҢйғҪжҳҜдёҚе…Ғи®ёзҡ„еQ?/p>
Transaction tx = jedis.multi(); for (int i = 0; i < 100000; i++) { tx.set("t" + i, "t" + i); } System.out.println(tx.get("t1000").get()); //дёҚе…Ғи®? List<Object> results = tx.exec(); … … Pipeline pipeline = jedis.pipelined(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { pipeline.set("p" + i, "p" + i); } System.out.println(pipeline.get("p1000").get()); //дёҚе…Ғи®? List<Object> results = pipeline.syncAndReturnAll();дәӢеҠЎе’Ңз®ЎйҒ“йғҪжҳҜејӮжӯҘзҡ„еQҢдёӘдәәж„ҹи§үпјҢеңЁз®ЎйҒ“дёӯеҶҚиҝӣиЎҢдәӢеҠЎи°ғз”ЁпјҢжІЎжңүеҝ…иҰҒеQҢдёҚеҰӮзӣҙжҺҘиҝӣиЎҢдәӢеҠЎжЁЎејҸгҖ?/p>
еҲҶеёғејҸдёӯеQҢиҝһжҺҘжұ зҡ„жҖ§иғҪжҜ”зӣҙҳqһзҡ„жҖ§иғҪз•ҘеҘҪ(и§ҒеҗҺҫlӯжөӢиҜ•йғЁеҲ?гҖ?/p>
еҲҶеёғејҸи°ғз”ЁдёӯдёҚж”ҜжҢҒдәӢеҠЎгҖ?/p>
еӣ дШ“дәӢеҠЎжҳҜеңЁжңҚеҠЎеҷЁз«Ҝе®һзҺ°еQҢиҖҢеңЁеҲҶеёғејҸдёӯеQҢжҜҸжүТҺ¬Ўзҡ„и°ғз”ЁеҜ№иұЎйғҪеҸҜиғҪи®үK—®дёҚеҗҢзҡ„жңәеҷЁпјҢжүҖд»ҘпјҢжІЎжі•ҳqӣиЎҢдәӢеҠЎгҖ?/p>
еҚҒгҖҒжөӢиҜ?/h3>
дәӢеҠЎе’Ңз®ЎйҒ“йғҪжҳҜејӮжӯҘжЁЎејҸгҖӮеңЁдәӢеҠЎе’Ңз®ЎйҒ“дёӯдёҚиғҪеҗҢжӯҘжҹҘиҜўҫl“жһңгҖӮжҜ”еҰӮдёӢйқўдёӨдёӘи°ғз”ЁпјҢйғҪжҳҜдёҚе…Ғи®ёзҡ„еQ?/p>
Transaction tx = jedis.multi(); for (int i = 0; i < 100000; i++) { tx.set("t" + i, "t" + i); } System.out.println(tx.get("t1000").get()); //дёҚе…Ғи®? List<Object> results = tx.exec(); … … Pipeline pipeline = jedis.pipelined(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { pipeline.set("p" + i, "p" + i); } System.out.println(pipeline.get("p1000").get()); //дёҚе…Ғи®? List<Object> results = pipeline.syncAndReturnAll();дәӢеҠЎе’Ңз®ЎйҒ“йғҪжҳҜејӮжӯҘзҡ„еQҢдёӘдәәж„ҹи§үпјҢеңЁз®ЎйҒ“дёӯеҶҚиҝӣиЎҢдәӢеҠЎи°ғз”ЁпјҢжІЎжңүеҝ…иҰҒеQҢдёҚеҰӮзӣҙжҺҘиҝӣиЎҢдәӢеҠЎжЁЎејҸгҖ?/p>
еҲҶеёғејҸдёӯеQҢиҝһжҺҘжұ зҡ„жҖ§иғҪжҜ”зӣҙҳqһзҡ„жҖ§иғҪз•ҘеҘҪ(и§ҒеҗҺҫlӯжөӢиҜ•йғЁеҲ?гҖ?/p>
еҲҶеёғејҸи°ғз”ЁдёӯдёҚж”ҜжҢҒдәӢеҠЎгҖ?/p>
еӣ дШ“дәӢеҠЎжҳҜеңЁжңҚеҠЎеҷЁз«Ҝе®һзҺ°еQҢиҖҢеңЁеҲҶеёғејҸдёӯеQҢжҜҸжүТҺ¬Ўзҡ„и°ғз”ЁеҜ№иұЎйғҪеҸҜиғҪи®үK—®дёҚеҗҢзҡ„жңәеҷЁпјҢжүҖд»ҘпјҢжІЎжі•ҳqӣиЎҢдәӢеҠЎгҖ?/p>
ҳqҗиЎҢдёҠйқўзҡ„д»Јз ҒпјҢҳqӣиЎҢӢ№ӢиҜ•еQҢе…¶ҫl“жһңеҰӮдёӢеQ?/p>
Simple SET: 5.227 seconds Transaction SET: 0.5 seconds Pipelined SET: 0.353 seconds Pipelined transaction: 0.509 seconds Simple@Sharing SET: 5.289 seconds Pipelined@Sharing SET: 0.348 seconds Simple@Pool SET: 5.039 seconds Pipelined@Pool SET: 0.401 seconds
еҸҰеӨ–еQҢз»ҸӢ№ӢиҜ•еҲҶеёғејҸдёӯз”ЁеҲ°зҡ„жңәеҷЁи¶ҠеӨҡпјҢи°ғз”Ёдјҡи¶Ҡж…ўгҖӮдёҠйқўжҳҜ2зүҮпјҢдёӢйқўжҳ?зүҮпјҡ
Simple@Sharing SET: 5.494 seconds Pipelined@Sharing SET: 0.51 seconds Simple@Pool SET: 5.223 seconds Pipelined@Pool SET: 0.518 seconds
дёӢйқўжҳ?0зүҮпјҡ
Simple@Sharing SET: 5.9 seconds Pipelined@Sharing SET: 0.794 seconds Simple@Pool SET: 5.624 seconds Pipelined@Pool SET: 0.762 seconds
дёӢйқўжҳ?00зүҮпјҡ
Simple@Sharing SET: 14.055 seconds Pipelined@Sharing SET: 8.185 seconds Simple@Pool SET: 13.29 seconds Pipelined@Pool SET: 7.767 seconds
еҲҶеёғејҸдёӯеQҢиҝһжҺҘжұ ж–№ејҸи°ғз”ЁдёҚдҪҶҫUҝзЁӢе®үе…ЁеӨ–пјҢж ТҺҚ®дёҠйқўзҡ„жөӢиҜ•ж•°жҚ®пјҢд№ҹеҸҜд»ҘзңӢеҮшҷҝһжҺҘжұ жҜ”зӣҙҳqһзҡ„ж•ҲзҺҮжӣҙеҘҪгҖ?/p>
еҚҒдёҖгҖҒе®Ңж•ҙзҡ„Ӣ№ӢиҜ•д»Јз Ғ
package com.example.nosqlclient; import java.util.Arrays; import java.util.List; import org.junit.AfterClass; import org.junit.BeforeClass; import org.junit.Test; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPoolConfig; import redis.clients.jedis.JedisShardInfo; import redis.clients.jedis.Pipeline; import redis.clients.jedis.ShardedJedis; import redis.clients.jedis.ShardedJedisPipeline; import redis.clients.jedis.ShardedJedisPool; import redis.clients.jedis.Transaction; import org.junit.FixMethodOrder; import org.junit.runners.MethodSorters; @FixMethodOrder(MethodSorters.NAME_ASCENDING) public class TestJedis { private static Jedis jedis; private static ShardedJedis sharding; private static ShardedJedisPool pool; @BeforeClass public static void setUpBeforeClass() throws Exception { List<JedisShardInfo> shards = Arrays.asList( new JedisShardInfo("localhost",6379), new JedisShardInfo("localhost",6379)); //дҪҝз”ЁзӣёеҗҢзҡ„ip:port,д»…дҪңӢ№ӢиҜ• jedis = new Jedis("localhost"); sharding = new ShardedJedis(shards); pool = new ShardedJedisPool(new JedisPoolConfig(), shards); } @AfterClass public static void tearDownAfterClass() throws Exception { jedis.disconnect(); sharding.disconnect(); pool.destroy(); } @Test public void test1Normal() { long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { String result = jedis.set("n" + i, "n" + i); } long end = System.currentTimeMillis(); System.out.println("Simple SET: " + ((end - start)/1000.0) + " seconds"); } @Test public void test2Trans() { long start = System.currentTimeMillis(); Transaction tx = jedis.multi(); for (int i = 0; i < 100000; i++) { tx.set("t" + i, "t" + i); } //System.out.println(tx.get("t1000").get()); List<Object> results = tx.exec(); long end = System.currentTimeMillis(); System.out.println("Transaction SET: " + ((end - start)/1000.0) + " seconds"); } @Test public void test3Pipelined() { Pipeline pipeline = jedis.pipelined(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { pipeline.set("p" + i, "p" + i); } //System.out.println(pipeline.get("p1000").get()); List<Object> results = pipeline.syncAndReturnAll(); long end = System.currentTimeMillis(); System.out.println("Pipelined SET: " + ((end - start)/1000.0) + " seconds"); } @Test public void test4combPipelineTrans() { long start = System.currentTimeMillis(); Pipeline pipeline = jedis.pipelined(); pipeline.multi(); for (int i = 0; i < 100000; i++) { pipeline.set("" + i, "" + i); } pipeline.exec(); List<Object> results = pipeline.syncAndReturnAll(); long end = System.currentTimeMillis(); System.out.println("Pipelined transaction: " + ((end - start)/1000.0) + " seconds"); } @Test public void test5shardNormal() { long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { String result = sharding.set("sn" + i, "n" + i); } long end = System.currentTimeMillis(); System.out.println("Simple@Sharing SET: " + ((end - start)/1000.0) + " seconds"); } @Test public void test6shardpipelined() { ShardedJedisPipeline pipeline = sharding.pipelined(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { pipeline.set("sp" + i, "p" + i); } List<Object> results = pipeline.syncAndReturnAll(); long end = System.currentTimeMillis(); System.out.println("Pipelined@Sharing SET: " + ((end - start)/1000.0) + " seconds"); } @Test public void test7shardSimplePool() { ShardedJedis one = pool.getResource(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { String result = one.set("spn" + i, "n" + i); } long end = System.currentTimeMillis(); pool.returnResource(one); System.out.println("Simple@Pool SET: " + ((end - start)/1000.0) + " seconds"); } @Test public void test8shardPipelinedPool() { ShardedJedis one = pool.getResource(); ShardedJedisPipeline pipeline = one.pipelined(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { pipeline.set("sppn" + i, "n" + i); } List<Object> results = pipeline.syncAndReturnAll(); long end = System.currentTimeMillis(); pool.returnResource(one); System.out.println("Pipelined@Pool SET: " + ((end - start)/1000.0) + " seconds"); } }е®һйҷ…MySQLжҳҜйҖӮеҗҲҳqӣиЎҢӢ№·йҮҸж•°жҚ®еӯҳеӮЁзҡ„пјҢйҖҡиҝҮMemcachedһ®ҶзғӯзӮТҺ•°жҚ®еҠ иҪҪеҲ°cacheеQҢеҠ йҖҹи®ҝй—®пјҢеҫҲеӨҡе…¬еҸёйғҪжӣҫҫlҸдӢЙз”ЁиҝҮҳqҷж ·зҡ„жһ¶жһ„пјҢдҪҶйҡҸзқҖдёҡеҠЎж•°жҚ®йҮҸзҡ„дёҚж–ӯеўһеҠ еQҢе’Ңи®үK—®йҮҸзҡ„жҢҒз®Ӣеўһй•ҝеQҢжҲ‘们йҒҮеҲоCәҶеҫҲеӨҡй—®йўҳеQ?/p>
MySQLйңҖиҰҒдёҚж–ӯиҝӣиЎҢжӢҶеә“жӢҶиЎЁпјҢMemcachedд№ҹйңҖдёҚж–ӯи·ҹзқҖжү©е®№еQҢжү©е®№е’ҢҫlҙжҠӨе·ҘдҪңеҚ жҚ®еӨ§йҮҸејҖеҸ‘ж—¶й—ҙгҖ?/p>
MemcachedдёҺMySQLж•°жҚ®еә“ж•°жҚ®дёҖиҮҙжҖ§й—®йўҳгҖ?/p>
Memcachedж•°жҚ®е‘ҪдёӯзҺҮдҪҺжҲ–downжңәпјҢеӨ§йҮҸи®үK—®зӣҙжҺҘҪIүKҖҸеҲ°DBеQҢMySQLж— жі•ж”Ҝж’‘гҖ?/p>
и·ЁжңәжҲҝcacheеҗҢжӯҘй—®йўҳгҖ?/p>
дј—еӨҡNoSQLзҷҫиҠұйҪҗж”ҫеQҢеҰӮдҪ•йҖүжӢ©
жңҖҳq‘еҮ тqЯ_јҢдёҡз•ҢдёҚж–ӯж¶ҢзҺ°еҮәеҫҲеӨҡеҗ„ҝUҚеҗ„ж пLҡ„NoSQLдә§е“ҒеQҢйӮЈд№ҲеҰӮдҪ•жүҚиғҪжӯЈјӢ®ең°дҪҝз”ЁеҘҪиҝҷдәӣдс”е“ҒпјҢжңҖеӨ§еҢ–ең°еҸ‘жҢҘе…¶й•ҝеӨ„еQҢжҳҜжҲ‘们йңҖиҰҒж·ұе…Ҙз ”ҪI¶е’ҢжҖқиҖғзҡ„й—?йўҳпјҢе®һйҷ…еҪ’ж №ҫl“еә•жңҖйҮҚиҰҒзҡ„жҳҜдәҶи§Јҳqҷдәӣдә§е“Ғзҡ„е®ҡдҪҚпјҢтq¶дё”дәҶи§ЈеҲ°жҜҸӢЖҫдс”е“Ғзҡ„tradeoffsеQҢеңЁе®һйҷ…еә”з”ЁдёӯеҒҡеҲ°жү¬й•үKҒҝзҹӯпјҢжҖЦMҪ“дёҠиҝҷдәӣNoSQLдё»иҰҒз”ЁдәҺи§ЈеҶі д»ҘдёӢеҮ з§Қй—®йўҳ
һ®‘йҮҸж•°жҚ®еӯҳеӮЁеQҢй«ҳйҖҹиҜ»еҶҷи®ҝй—®гҖӮжӯӨҫcЦMс”е“ҒйҖҡиҝҮж•°жҚ®е…ЁйғЁin-momery зҡ„ж–№ејҸжқҘдҝқиҜҒй«ҳйҖҹи®ҝй—®пјҢеҗҢж—¶жҸҗдҫӣж•°жҚ®иҗҪең°зҡ„еҠҹиғҪпјҢе®һйҷ…ҳqҷжӯЈжҳҜRedisжңҖдё»иҰҒзҡ„йҖӮз”ЁеңәжҷҜгҖ?/p>
Ӣ№·йҮҸж•°жҚ®еӯҳеӮЁеQҢеҲҶеёғејҸҫpИқ»ҹж”ҜжҢҒеQҢж•°жҚ®дёҖиҮҙжҖ§дҝқиҜҒпјҢж–№дҫҝзҡ„йӣҶҫҹӨиҠӮзӮТҺ·»еҠ?еҲ йҷӨгҖ?/p>
ҳqҷж–№йқўжңҖе…·д»ЈиЎЁжҖ§зҡ„жҳҜdynamoе’Ңbigtable 2ҪӢҮи®әж–ҮжүҖйҳҗиҝ°зҡ„жҖқиө\гҖӮеүҚиҖ…жҳҜдёҖдёӘе®Ңе…Ёж— дёӯеҝғзҡ„и®ҫи®ЎпјҢиҠӮзӮ№д№Ӣй—ҙйҖҡиҝҮgossipж–№ејҸдј йҖ’йӣҶҫҹӨдҝЎжҒҜпјҢж•°жҚ®дҝқиҜҒжңҖҫlҲдёҖиҮҙжҖ§пјҢеҗҺиҖ…жҳҜдёҖдёӘдёӯеҝғеҢ–зҡ„ж–№жЎҲи®ҫи®ЎпјҢйҖҡиҝҮ ҫcЦMјјдёҖдёӘеҲҶеёғејҸй”ҒжңҚеҠЎжқҘдҝқиҜҒејЮZёҖиҮҙжҖ?ж•°жҚ®еҶҷе…Ҙе…ҲеҶҷеҶ…еӯҳе’Ңredo logеQҢ然еҗҺе®ҡжңҹcompatеҪ’еЖҲеҲ°зЈҒзӣҳдёҠеQҢе°ҶйҡҸжңәеҶҷдјҳеҢ–дШ“ҷеәеәҸеҶҷпјҢжҸҗй«ҳеҶҷе…ҘжҖ§иғҪгҖ?/p>
Schema freeеQҢauto-shardingҪ{үгҖӮжҜ”еҰӮзӣ®еүҚеёёи§Ғзҡ„дёҖдәӣж–ҮжЎЈж•°жҚ®еә“йғҪжҳҜж”ҜжҢҒschema-freeзҡ„пјҢзӣҙжҺҘеӯҳеӮЁjsonж јејҸж•°жҚ®еQҢеЖҲдё”ж”ҜжҢҒauto-shardingҪ{үеҠҹиғҪпјҢжҜ”еҰӮmongodbгҖ?/p>
йқўеҜ№ҳqҷдәӣдёҚеҗҢҫcХdһӢзҡ„NoSQLдә§е“Ғ,жҲ‘们йңҖиҰҒж №жҚ®жҲ‘们зҡ„дёҡеҠЎеңәжҷҜйҖүжӢ©жңҖеҗҲйҖӮзҡ„дә§е“ҒгҖ?/p>
RedisйҖӮз”ЁеңәжҷҜеQҢеҰӮдҪ•жӯЈјӢ®зҡ„дҪҝз”Ё
еүҚйқўе·Із»ҸеҲҶжһҗҳqҮпјҢRedisжңҖйҖӮеҗҲжүҖжңүж•°жҚ®in-momoryзҡ„еңәжҷҜпјҢиҷҪ然Redisд№ҹжҸҗдҫӣжҢҒд№…еҢ–еҠҹиғҪеQҢдҪҶе®һйҷ…жӣҙеӨҡзҡ„жҳҜдёҖдёӘdisk-backed зҡ„еҠҹиғҪпјҢи·ҹдј ҫlҹж„Ҹд№үдёҠзҡ„жҢҒд№…еҢ–жңүжҜ”иҫғеӨ§зҡ„е·®еҲ«пјҢйӮЈд№ҲеҸҜиғҪеӨ§е®¶һ®Чғјҡжңүз–‘й—®пјҢдјйg№ҺRedisжӣҙеғҸдёҖдёӘеҠ ејәзүҲзҡ„MemcachedеQҢйӮЈд№ҲдҪ•ж—¶дӢЙз”?Memcached,дҪ•ж—¶дҪҝз”ЁRedisе‘ўпјҹ
RedisдёҺMemcachedзҡ„жҜ”иҫ?/h2>ҫ|‘з»ңIOжЁЎеһӢ
MemcachedжҳҜеӨҡҫUҝзЁӢеQҢйқһйҳХdЎһIOеӨҚз”Ёзҡ„зҪ‘ҫlңжЁЎеһӢпјҢеҲҶдШ“зӣ‘еҗ¬дёИқәҝҪEӢе’ҢworkerеӯҗзәҝҪEӢпјҢзӣ‘еҗ¬ҫUҝзЁӢзӣ‘еҗ¬ҫ|‘з»ңҳqһжҺҘеQҢжҺҘеҸ—иҜ·жұӮеҗҺеQҢе°ҶҳqһжҺҘ жҸҸиҝ°еӯ—pipe дј йҖ’з»ҷworkerҫUҝзЁӢеQҢиҝӣиЎҢиҜ»еҶҷIO, ҫ|‘з»ңеұӮдӢЙз”Ёlibeventһ®ҒиЈ…зҡ„дәӢ件еә“еQҢеӨҡҫUҝзЁӢжЁЎеһӢеҸҜд»ҘеҸ‘жҢҘеӨҡж ёдҪңз”ЁеQҢдҪҶжҳҜеј•е…ҘдәҶcache coherencyе’Ңй”Ғзҡ„й—®йўҳпјҢжҜ”еҰӮеQҢMemcachedжңҖеёёз”Ёзҡ„stats е‘ҪдЧoеQҢе®һйҷ…MemcachedжүҖжңүж“ҚдҪңйғҪиҰҒеҜ№ҳqҷдёӘе…ЁеұҖеҸҳйҮҸеҠ й”ҒеQҢиҝӣиЎҢи®Ўж•°зӯүе·ҘдҪңеQҢеёҰжқҘдәҶжҖ§иғҪжҚҹиҖ—гҖ?/p>

еQҲMemcachedҫ|‘з»ңIOжЁЎеһӢеQ?/p>
RedisдҪҝз”ЁеҚ•зәҝҪEӢзҡ„IOеӨҚз”ЁжЁЎеһӢеQҢиҮӘе·ұе°ҒиЈ…дәҶдёҖдёӘз®ҖеҚ•зҡ„AeEventдәӢдҡgеӨ„зҗҶжЎҶжһ¶еQҢдё»иҰҒе®һзҺоCәҶepollгҖҒkqueueе’?selectеQҢеҜ№дәҺеҚ•ҫUҜеҸӘжңүIOж“ҚдҪңжқҘиҜҙеQҢеҚ•ҫUҝзЁӢеҸҜд»Ҙһ®ҶйҖҹеәҰдјҳеҠҝеҸ‘жҢҘеҲ°жңҖеӨ§пјҢдҪҶжҳҜRedisд№ҹжҸҗдҫӣдәҶдёҖдәӣз®ҖеҚ•зҡ„и®Ўз®—еҠҹиғҪеQҢжҜ”еҰӮжҺ’еәҸгҖҒиҒҡеҗҲзӯүеQҢеҜ№дәҺиҝҷдәӣж“Қ дҪңпјҢеҚ•зәҝҪEӢжЁЎеһӢе®һйҷ…дјҡдёҘйҮҚеҪұе“Қж•ҙдҪ“еҗһеҗҗйҮҸпјҢCPUи®Ўз®—ҳqҮзЁӢдёӯпјҢж•ҙдёӘIOи°ғеәҰйғҪжҳҜиў«йҳ»еЎһдҪҸзҡ„гҖ?/p>
еҶ…еӯҳҪҺЎзҗҶж–ҡwқў
MemcachedдҪҝз”Ёйў„еҲҶй…Қзҡ„еҶ…еӯҳжұ зҡ„ж–№ејҸеQҢдӢЙз”Ёslabе’ҢеӨ§һ®ҸдёҚеҗҢзҡ„chunkжқҘз®ЎзҗҶеҶ…еӯҳпјҢItemж ТҺҚ®еӨ§е°ҸйҖүжӢ©еҗҲйҖӮзҡ„chunkеӯ?еӮЁпјҢеҶ…еӯҳжұ зҡ„ж–№ејҸеҸҜд»ҘзңҒеҺ»з”ҢҷҜ·/йҮҠж”ҫеҶ…еӯҳзҡ„ејҖй”ҖеQҢеЖҲдё”иғҪеҮҸе°ҸеҶ…еӯҳј„ҺзүҮдә§з”ҹеQҢдҪҶҳqҷз§Қж–№ејҸд№ҹдјҡеёҰжқҘдёҖе®ҡзЁӢеәҰдёҠзҡ„з©әй—ҙжөӘиҙ№пјҢтq¶дё”еңЁеҶ…еӯҳд»Қ然жңүеҫҲеӨ§ҪIәй—ҙж—УһјҢж–°зҡ„ж•?жҚ®д№ҹеҸҜиғҪдјҡиў«еү”йҷӨеQҢеҺҹеӣ еҸҜд»ҘеҸӮиҖғTimyangзҡ„ж–Үз« пјҡhttp://timyang.net/data/Memcached-lru-evictions/
RedisдҪҝз”ЁзҺ°еңәз”ҢҷҜ·еҶ…еӯҳзҡ„ж–№ејҸжқҘеӯҳеӮЁж•°жҚ®еQҢеЖҲдё”еҫҲһ®‘дӢЙз”Ёfree-listҪ{үж–№ејҸжқҘдјҳеҢ–еҶ…еӯҳеҲҶй…ҚеQҢдјҡеңЁдёҖе®ҡзЁӢеәҰдёҠеӯҳеңЁеҶ…еӯҳј„?зүҮпјҢRedisи·ҹжҚ®еӯҳеӮЁе‘ҪдЧoеҸӮж•°еQҢдјҡжҠҠеёҰҳqҮжңҹж—үҷ—ҙзҡ„ж•°жҚ®еҚ•зӢ¬еӯҳж”‘ЦңЁдёҖиөшPјҢтq¶жҠҠе®ғ们ҝUоCШ“дёҙж—¶ж•°жҚ®еQҢйқһдёҙж—¶ж•°жҚ®жҳҜж°ёҳqңдёҚдјҡиў«еү”йҷӨзҡ„пјҢеҚідҫҝзү©зҗҶеҶ…еӯҳдёҚеӨҹеQҢеҜјиҮ?swapд№ҹдёҚдјҡеү”йҷӨд“QдҪ•йқһдёҙж—¶ж•°жҚ®еQҲдҪҶдјҡе°қиҜ•еү”йҷӨйғЁеҲҶдҸНж—¶ж•°жҚ®пјүеQҢиҝҷзӮ№дёҠRedisжӣҙйҖӮеҗҲдҪңдШ“еӯҳеӮЁиҖҢдёҚжҳҜcacheгҖ?/p>
ж•°жҚ®дёҖиҮҙжҖ§й—®йў?/p>
MemcachedжҸҗдҫӣдәҶcasе‘ҪдЧoеQҢеҸҜд»ҘдҝқиҜҒеӨҡдёӘеЖҲеҸ‘и®ҝй—®ж“ҚдҪңеҗҢдёҖд»Ҫж•°жҚ®зҡ„дёҖиҮҙжҖ§й—®йўҳгҖ?RedisжІЎжңүжҸҗдҫӣcas е‘ҪдЧoеQҢеЖҲдёҚиғҪдҝқиҜҒҳqҷзӮ№еQҢдёҚҳqҮRedisжҸҗдҫӣдәҶдәӢеҠЎзҡ„еҠҹиғҪеQҢеҸҜд»ҘдҝқиҜҒдёҖдё?е‘ҪдЧoзҡ„еҺҹеӯҗжҖ§пјҢдёӯй—ҙдёҚдјҡиў«д“QдҪ•ж“ҚдҪңжү“ж–ӯгҖ?/p>
еӯҳеӮЁж–№ејҸеҸҠе…¶е®ғж–№йқ?/p>
Memcachedеҹәжң¬еҸӘж”ҜжҢҒз®ҖеҚ•зҡ„key-valueеӯҳеӮЁеQҢдёҚж”ҜжҢҒжһҡдӢDеQҢдёҚж”ҜжҢҒжҢҒд№…еҢ–е’ҢеӨҚеҲ¶Ҫ{үеҠҹиғ?/p>
RedisйҷӨkey/valueд№ӢеӨ–еQҢиҝҳж”ҜжҢҒlist,set,sorted set,hashҪ{үдј—еӨҡж•°жҚ®з»“жһ„пјҢжҸҗдҫӣдәҶKEYS
ҳqӣиЎҢжһҡдӢDж“ҚдҪңеQҢдҪҶдёҚиғҪеңЁзәҝдёҠдӢЙз”ЁпјҢеҰӮжһңйңҖиҰҒжһҡдё„ЎәҝдёҠж•°жҚ®пјҢRedisжҸҗдҫӣдәҶе·Ҙе…·еҸҜд»ҘзӣҙжҺҘжү«жҸҸе…¶dumpж–ҮдҡgеQҢжһҡдё‘ЦҮәжүҖжңүж•°жҚ®пјҢRedisҳqҳеҗҢж—¶жҸҗдҫӣдәҶжҢҒд№…еҢ–е’ҢеӨҚеҲ¶Ҫ{үеҠҹиғҪгҖ?/p>
е…ідәҺдёҚеҗҢиҜӯиЁҖзҡ„е®ўжҲпL«Ҝж”ҜжҢҒ
еңЁдёҚеҗҢиҜӯӯaҖзҡ„е®ўжҲпL«Ҝж–ҡwқўеQҢMemcachedе’ҢRedisйғҪжңүдё°еҜҢзҡ„第дёүж–№е®ўжҲ·з«ҜеҸҜдҫӣйҖүжӢ©еQҢдёҚҳqҮеӣ дёәMemcachedеҸ‘еұ•зҡ„ж—¶й—ҙжӣҙд№…дёҖ дәӣпјҢзӣ®еүҚзңӢеңЁе®ўжҲ·з«Ҝж”ҜжҢҒж–№йқўпјҢMemcachedзҡ„еҫҲеӨҡе®ўжҲпL«ҜжӣҙеҠ жҲҗзҶҹҪEӣ_®ҡеQҢиҖҢRedisз”ЧғәҺе…¶еҚҸи®®жң¬нw«е°ұжҜ”MemcachedеӨҚжқӮеQҢеҠ дёҠдҪңиҖ…дёҚж–ӯеўһеҠ ж–° зҡ„еҠҹиғҪзӯүеQҢеҜ№еә”第дёүж–№е®ўжҲ·з«Ҝи·ҹҳqӣйҖҹеәҰеҸҜиғҪдјҡиө¶дёҚдёҠеQҢжңүж—¶еҸҜиғҪйңҖиҰҒиҮӘе·ұеңЁҪW¬дёүж–№е®ўжҲпL«ҜеҹәзЎҖдёҠеҒҡдәӣдҝ®ж”ТҺүҚиғҪжӣҙеҘҪзҡ„дҪҝз”ЁгҖ?/p>
ҫ|‘з»ңIOжЁЎеһӢ
MemcachedжҳҜеӨҡҫUҝзЁӢеQҢйқһйҳХdЎһIOеӨҚз”Ёзҡ„зҪ‘ҫlңжЁЎеһӢпјҢеҲҶдШ“зӣ‘еҗ¬дёИқәҝҪEӢе’ҢworkerеӯҗзәҝҪEӢпјҢзӣ‘еҗ¬ҫUҝзЁӢзӣ‘еҗ¬ҫ|‘з»ңҳqһжҺҘеQҢжҺҘеҸ—иҜ·жұӮеҗҺеQҢе°ҶҳqһжҺҘ жҸҸиҝ°еӯ—pipe дј йҖ’з»ҷworkerҫUҝзЁӢеQҢиҝӣиЎҢиҜ»еҶҷIO, ҫ|‘з»ңеұӮдӢЙз”Ёlibeventһ®ҒиЈ…зҡ„дәӢ件еә“еQҢеӨҡҫUҝзЁӢжЁЎеһӢеҸҜд»ҘеҸ‘жҢҘеӨҡж ёдҪңз”ЁеQҢдҪҶжҳҜеј•е…ҘдәҶcache coherencyе’Ңй”Ғзҡ„й—®йўҳпјҢжҜ”еҰӮеQҢMemcachedжңҖеёёз”Ёзҡ„stats е‘ҪдЧoеQҢе®һйҷ…MemcachedжүҖжңүж“ҚдҪңйғҪиҰҒеҜ№ҳqҷдёӘе…ЁеұҖеҸҳйҮҸеҠ й”ҒеQҢиҝӣиЎҢи®Ўж•°зӯүе·ҘдҪңеQҢеёҰжқҘдәҶжҖ§иғҪжҚҹиҖ—гҖ?/p>
еQҲMemcachedҫ|‘з»ңIOжЁЎеһӢеQ?/p>
RedisдҪҝз”ЁеҚ•зәҝҪEӢзҡ„IOеӨҚз”ЁжЁЎеһӢеQҢиҮӘе·ұе°ҒиЈ…дәҶдёҖдёӘз®ҖеҚ•зҡ„AeEventдәӢдҡgеӨ„зҗҶжЎҶжһ¶еQҢдё»иҰҒе®һзҺоCәҶepollгҖҒkqueueе’?selectеQҢеҜ№дәҺеҚ•ҫUҜеҸӘжңүIOж“ҚдҪңжқҘиҜҙеQҢеҚ•ҫUҝзЁӢеҸҜд»Ҙһ®ҶйҖҹеәҰдјҳеҠҝеҸ‘жҢҘеҲ°жңҖеӨ§пјҢдҪҶжҳҜRedisд№ҹжҸҗдҫӣдәҶдёҖдәӣз®ҖеҚ•зҡ„и®Ўз®—еҠҹиғҪеQҢжҜ”еҰӮжҺ’еәҸгҖҒиҒҡеҗҲзӯүеQҢеҜ№дәҺиҝҷдәӣж“Қ дҪңпјҢеҚ•зәҝҪEӢжЁЎеһӢе®һйҷ…дјҡдёҘйҮҚеҪұе“Қж•ҙдҪ“еҗһеҗҗйҮҸпјҢCPUи®Ўз®—ҳqҮзЁӢдёӯпјҢж•ҙдёӘIOи°ғеәҰйғҪжҳҜиў«йҳ»еЎһдҪҸзҡ„гҖ?/p>
еҶ…еӯҳҪҺЎзҗҶж–ҡwқў
MemcachedдҪҝз”Ёйў„еҲҶй…Қзҡ„еҶ…еӯҳжұ зҡ„ж–№ејҸеQҢдӢЙз”Ёslabе’ҢеӨ§һ®ҸдёҚеҗҢзҡ„chunkжқҘз®ЎзҗҶеҶ…еӯҳпјҢItemж ТҺҚ®еӨ§е°ҸйҖүжӢ©еҗҲйҖӮзҡ„chunkеӯ?еӮЁпјҢеҶ…еӯҳжұ зҡ„ж–№ејҸеҸҜд»ҘзңҒеҺ»з”ҢҷҜ·/йҮҠж”ҫеҶ…еӯҳзҡ„ејҖй”ҖеQҢеЖҲдё”иғҪеҮҸе°ҸеҶ…еӯҳј„ҺзүҮдә§з”ҹеQҢдҪҶҳqҷз§Қж–№ејҸд№ҹдјҡеёҰжқҘдёҖе®ҡзЁӢеәҰдёҠзҡ„з©әй—ҙжөӘиҙ№пјҢтq¶дё”еңЁеҶ…еӯҳд»Қ然жңүеҫҲеӨ§ҪIәй—ҙж—УһјҢж–°зҡ„ж•?жҚ®д№ҹеҸҜиғҪдјҡиў«еү”йҷӨеQҢеҺҹеӣ еҸҜд»ҘеҸӮиҖғTimyangзҡ„ж–Үз« пјҡhttp://timyang.net/data/Memcached-lru-evictions/
RedisдҪҝз”ЁзҺ°еңәз”ҢҷҜ·еҶ…еӯҳзҡ„ж–№ејҸжқҘеӯҳеӮЁж•°жҚ®еQҢеЖҲдё”еҫҲһ®‘дӢЙз”Ёfree-listҪ{үж–№ејҸжқҘдјҳеҢ–еҶ…еӯҳеҲҶй…ҚеQҢдјҡеңЁдёҖе®ҡзЁӢеәҰдёҠеӯҳеңЁеҶ…еӯҳј„?зүҮпјҢRedisи·ҹжҚ®еӯҳеӮЁе‘ҪдЧoеҸӮж•°еQҢдјҡжҠҠеёҰҳqҮжңҹж—үҷ—ҙзҡ„ж•°жҚ®еҚ•зӢ¬еӯҳж”‘ЦңЁдёҖиөшPјҢтq¶жҠҠе®ғ们ҝUоCШ“дёҙж—¶ж•°жҚ®еQҢйқһдёҙж—¶ж•°жҚ®жҳҜж°ёҳqңдёҚдјҡиў«еү”йҷӨзҡ„пјҢеҚідҫҝзү©зҗҶеҶ…еӯҳдёҚеӨҹеQҢеҜјиҮ?swapд№ҹдёҚдјҡеү”йҷӨд“QдҪ•йқһдёҙж—¶ж•°жҚ®еQҲдҪҶдјҡе°қиҜ•еү”йҷӨйғЁеҲҶдҸНж—¶ж•°жҚ®пјүеQҢиҝҷзӮ№дёҠRedisжӣҙйҖӮеҗҲдҪңдШ“еӯҳеӮЁиҖҢдёҚжҳҜcacheгҖ?/p>
ж•°жҚ®дёҖиҮҙжҖ§й—®йў?/p>
MemcachedжҸҗдҫӣдәҶcasе‘ҪдЧoеQҢеҸҜд»ҘдҝқиҜҒеӨҡдёӘеЖҲеҸ‘и®ҝй—®ж“ҚдҪңеҗҢдёҖд»Ҫж•°жҚ®зҡ„дёҖиҮҙжҖ§й—®йўҳгҖ?RedisжІЎжңүжҸҗдҫӣcas е‘ҪдЧoеQҢеЖҲдёҚиғҪдҝқиҜҒҳqҷзӮ№еQҢдёҚҳqҮRedisжҸҗдҫӣдәҶдәӢеҠЎзҡ„еҠҹиғҪеQҢеҸҜд»ҘдҝқиҜҒдёҖдё?е‘ҪдЧoзҡ„еҺҹеӯҗжҖ§пјҢдёӯй—ҙдёҚдјҡиў«д“QдҪ•ж“ҚдҪңжү“ж–ӯгҖ?/p>
еӯҳеӮЁж–№ејҸеҸҠе…¶е®ғж–№йқ?/p>
Memcachedеҹәжң¬еҸӘж”ҜжҢҒз®ҖеҚ•зҡ„key-valueеӯҳеӮЁеQҢдёҚж”ҜжҢҒжһҡдӢDеQҢдёҚж”ҜжҢҒжҢҒд№…еҢ–е’ҢеӨҚеҲ¶Ҫ{үеҠҹиғ?/p>
RedisйҷӨkey/valueд№ӢеӨ–еQҢиҝҳж”ҜжҢҒlist,set,sorted set,hashҪ{үдј—еӨҡж•°жҚ®з»“жһ„пјҢжҸҗдҫӣдәҶKEYS
ҳqӣиЎҢжһҡдӢDж“ҚдҪңеQҢдҪҶдёҚиғҪеңЁзәҝдёҠдӢЙз”ЁпјҢеҰӮжһңйңҖиҰҒжһҡдё„ЎәҝдёҠж•°жҚ®пјҢRedisжҸҗдҫӣдәҶе·Ҙе…·еҸҜд»ҘзӣҙжҺҘжү«жҸҸе…¶dumpж–ҮдҡgеQҢжһҡдё‘ЦҮәжүҖжңүж•°жҚ®пјҢRedisҳqҳеҗҢж—¶жҸҗдҫӣдәҶжҢҒд№…еҢ–е’ҢеӨҚеҲ¶Ҫ{үеҠҹиғҪгҖ?/p>
е…ідәҺдёҚеҗҢиҜӯиЁҖзҡ„е®ўжҲпL«Ҝж”ҜжҢҒ
еңЁдёҚеҗҢиҜӯӯaҖзҡ„е®ўжҲпL«Ҝж–ҡwқўеQҢMemcachedе’ҢRedisйғҪжңүдё°еҜҢзҡ„第дёүж–№е®ўжҲ·з«ҜеҸҜдҫӣйҖүжӢ©еQҢдёҚҳqҮеӣ дёәMemcachedеҸ‘еұ•зҡ„ж—¶й—ҙжӣҙд№…дёҖ дәӣпјҢзӣ®еүҚзңӢеңЁе®ўжҲ·з«Ҝж”ҜжҢҒж–№йқўпјҢMemcachedзҡ„еҫҲеӨҡе®ўжҲпL«ҜжӣҙеҠ жҲҗзҶҹҪEӣ_®ҡеQҢиҖҢRedisз”ЧғәҺе…¶еҚҸи®®жң¬нw«е°ұжҜ”MemcachedеӨҚжқӮеQҢеҠ дёҠдҪңиҖ…дёҚж–ӯеўһеҠ ж–° зҡ„еҠҹиғҪзӯүеQҢеҜ№еә”第дёүж–№е®ўжҲ·з«Ҝи·ҹҳqӣйҖҹеәҰеҸҜиғҪдјҡиө¶дёҚдёҠеQҢжңүж—¶еҸҜиғҪйңҖиҰҒиҮӘе·ұеңЁҪW¬дёүж–№е®ўжҲпL«ҜеҹәзЎҖдёҠеҒҡдәӣдҝ®ж”ТҺүҚиғҪжӣҙеҘҪзҡ„дҪҝз”ЁгҖ?/p>
ж ТҺҚ®д»ҘдёҠжҜ”иҫғдёҚйҡҫзңӢеҮәеQҢеҪ“жҲ‘们дёҚеёҢжңӣж•°жҚ®иў«нtўеҮәеQҢжҲ–иҖ…йңҖиҰҒйҷӨkey/valueд№ӢеӨ–зҡ„жӣҙеӨҡж•°жҚ®зұ»еһӢж—¶еQҢжҲ–иҖ…йңҖиҰҒиҗҪең°еҠҹиғҪж—¶еQҢдӢЙз”ЁRedisжҜ”дӢЙз”ЁMemcachedжӣҙеҗҲйҖӮгҖ?/p>
е…ідәҺRedisзҡ„дёҖдәӣе‘Ёиҫ№еҠҹиғ?/h2>
RedisйҷӨдәҶдҪңдШ“еӯҳеӮЁд№ӢеӨ–ҳqҳжҸҗдҫӣдәҶдёҖдәӣе…¶е®ғж–№йқўзҡ„еҠҹиғҪеQҢжҜ”еҰӮиҒҡеҗҲи®ЎҪҺ—гҖҒpubsubгҖҒscriptingҪ{үпјҢеҜ№дәҺжӯӨзұ»еҠҹиғҪйңҖиҰҒдәҶи§Је…¶е®һзҺ°еҺҹзҗҶеQҢжё… жҘҡең°дәҶи§ЈеҲ°е®ғзҡ„еұҖйҷҗжҖ§еҗҺеQҢжүҚиғҪжӯЈјӢ®зҡ„дҪҝз”ЁеQҢжҜ”еҰӮpubsubеҠҹиғҪеQҢиҝҷдёӘе®һйҷ…жҳҜжІЎжңүд»ЦMҪ•жҢҒд№…еҢ–ж”ҜжҢҒзҡ„еQҢж¶ҲиҙТҺ–№ҳqһжҺҘй—Әж–ӯжҲ–йҮҚҳqһд№Ӣй—ҙиҝҮжқҘзҡ„ж¶ҲжҒҜжҳҜдјҡе…ЁйғЁдёўеӨұзҡ„пјҢ еҸҲжҜ”еҰӮиҒҡеҗҲи®ЎҪҺ—е’ҢscriptingҪ{үеҠҹиғҪеҸ—RedisеҚ•зәҝҪEӢжЁЎеһӢжүҖйҷҗпјҢжҳҜдёҚеҸҜиғҪиҫ‘ЦҲ°еҫҲй«ҳзҡ„еҗһеҗҗйҮҸзҡ„пјҢйңҖиҰҒи°}ж…ҺдӢЙз”ЁгҖ?/p>
жҖИқҡ„жқҘиҜҙRedisдҪңиҖ…жҳҜдёҖдҪҚйқһеёёеӢӨеҘӢзҡ„ејҖеҸ‘иҖ…пјҢеҸҜд»ҘҫlҸеёёзңӢеҲ°дҪңиҖ…еңЁһ®қиҜ•зқҖеҗ„з§ҚдёҚеҗҢзҡ„ж–°йІңжғіжі•е’ҢжҖқиө\еQҢй’ҲеҜ№иҝҷдәӣж–№йқўзҡ„еҠҹиғҪһ®ЮpҰҒжұӮжҲ‘们йңҖиҰҒж·ұе…ҘдәҶи§ЈеҗҺеҶҚдӢЙз”ЁгҖ?/p>
жҖИқ»“еQ?/h2>RedisдҪҝз”ЁжңҖдҪПx–№ејҸжҳҜе…ЁйғЁж•°жҚ®in-memoryгҖ?/p>
RedisжӣҙеӨҡеңәжҷҜжҳҜдҪңдёәMemcachedзҡ„жӣҝд»ЈиҖ…жқҘдҪҝз”ЁгҖ?/p>
еҪ“йңҖиҰҒйҷӨkey/valueд№ӢеӨ–зҡ„жӣҙеӨҡж•°жҚ®зұ»еһӢж”ҜжҢҒж—¶еQҢдӢЙз”ЁRedisжӣҙеҗҲйҖӮгҖ?/p>
еҪ“еӯҳеӮЁзҡ„ж•°жҚ®дёҚиғҪиў«еү”йҷӨж—¶еQҢдӢЙз”ЁRedisжӣҙеҗҲйҖӮгҖ?/p>
RedisдҪҝз”ЁжңҖдҪПx–№ејҸжҳҜе…ЁйғЁж•°жҚ®in-memoryгҖ?/p>
RedisжӣҙеӨҡеңәжҷҜжҳҜдҪңдёәMemcachedзҡ„жӣҝд»ЈиҖ…жқҘдҪҝз”ЁгҖ?/p>
еҪ“йңҖиҰҒйҷӨkey/valueд№ӢеӨ–зҡ„жӣҙеӨҡж•°жҚ®зұ»еһӢж”ҜжҢҒж—¶еQҢдӢЙз”ЁRedisжӣҙеҗҲйҖӮгҖ?/p>
еҪ“еӯҳеӮЁзҡ„ж•°жҚ®дёҚиғҪиў«еү”йҷӨж—¶еQҢдӢЙз”ЁRedisжӣҙеҗҲйҖӮгҖ?/p>
еҗҺз®Ӣе…ідәҺRedisж–Үз« и®ЎеҲ’еQ?/p>
Redisж•°жҚ®ҫcХdһӢдёҺе®№йҮҸ规еҲ’гҖ?/p>
еҰӮдҪ•ж ТҺҚ®дёҡеҠЎеңәжҷҜжҗӯеҫҸҪEӣ_®ҡеQҢеҸҜйқ пјҢеҸҜжү©еұ•зҡ„RedisйӣҶзҫӨгҖ?/p>
RedisеҸӮж•°еQҢд»Јз ҒдјҳеҢ–еҸҠдәҢж¬ЎејҖеҸ‘еҹәјӢҖе®һи·өгҖ?/p>
е…ідәҺдҪңиҖ?/strong>
з”°зҗӘеQҢзӣ®еүҚиҙҹиҙЈж–°Ӣ№Әеҫ®еҚҡег^еҸ°еә•еұӮжһ¶жһ„дёҺз ”еҸ‘е·ҘдҪңеQҢд№ӢеүҚжӣҫжӢ…д“QжҗңзӢҗзҷҪзӨҫдјҡе®һж—¶жёёжҲҸег^еҸ°ж ёеҝғжһ¶жһ„е·ҘдҪңпјҢдё»иҰҒе…ПxіЁwebgame, еҲҶеёғејҸеӯҳеӮЁпјҢnosql е’?erlang Ҫ{үйўҶеҹҹпјҢзӣ®еүҚдё»иҰҒд»ҺдәӢmysqlжәҗд»Јз Ғзҡ„дёҖдәӣж·ұе…Ҙз ”ҪI¶е·ҘдҪңпјҢӢ№Әеҫ®еҚҡпјҡhttp://weibo.com/bachmozartгҖ?/p>
ҪҺЎзҗҶ Redis жңҚеҠЎеҷ?/p>
ҪҺЎзҗҶ Redis data favorite
ҪҺЎзҗҶ Redis ж•°жҚ®
ж–?Redis ж•°жҚ®еQҡstring, list, hash, set, sorted set
йҮҚе‘Ҫеҗ?Redis ж•°жҚ®
еҲ йҷӨ Redis ж•°жҚ®
жӣҙж–° Redis ж•°жҚ®
еүӘеҲҮеQҢеӨҚеҲУһјҢҫ_ҳи„“ Redis ж•°жҚ®
еҜје…ҘеQҢеҜјеҮ?Redis ж•°жҚ®
жҗңзғҰ Redis ж•°жҚ®
йҖҡиҝҮе…ій”®еӯ—пјҢж•°жҚ®ҫcХdһӢеQҢеӨ§һ®ҸжқҘжҺ’еәҸ Redis ж•°жҚ®
еҜЖDҲӘеҺҶеҸІ
RedisClient жҳ? Redis е®ўжҲ·з«?GUI е·Ҙе…·еQҢдӢЙз”?Java swt е’Ңjedis ҫ~–еҶҷгҖӮе®ғһ®Ҷredisж•°жҚ®д»Ҙwindowsиө„жәҗҪҺЎзҗҶеҷЁзҡ„з•ҢйқўйЈҺж је‘ҲзҺ°ҫlҷз”ЁжҲшPјҢеҸҜд»Ҙеё®еҠ©redisејҖеҸ‘дқhе‘ҳе’ҢҫlҙжҠӨдәәе‘ҳж–№дҫҝзҡ„еҫҸз«ӢпјҢдҝ®ж”№еQҢеҲ йҷӨпјҢжҹҘиҜўredisж•°жҚ®еQҢеҸҜд»Ҙи®©з”ЁжҲ·ж–№дҫҝзҡ„зј–иҫ‘ж•°жҚ®пјҢеҸҜд»ҘеүӘеҲҮеQҢжӢ·иҙқпјҢҫ_ҳи„“redisж•°жҚ®еQҢеҸҜд»ҘеҜје…ҘпјҢеҜјеҮәredisж•°жҚ®еQҢеҸҜд»ҘеҜ№redisж•°жҚ®жҺ’еәҸгҖ?/p>

еңЁRedisдёӯпјҢтq¶дёҚжҳҜжүҖжңүзҡ„ж•°жҚ®йғҪдёҖзӣҙеӯҳеӮЁеңЁеҶ…еӯҳдёӯзҡ„гҖӮиҝҷжҳҜе’ҢMemcachedзӣёжҜ”дёҖдёӘжңҖеӨ§зҡ„еҢәеҲ«еQҲжҲ‘дёӘдқhжҳҜиҝҷд№Ҳи®Өдёәзҡ„еQүгҖ?br />
RedisеҸӘдјҡҫ~“еӯҳжүҖжңүзҡ„keyзҡ„дҝЎжҒҜпјҢеҰӮжһңRedisеҸ‘зҺ°еҶ…еӯҳзҡ„дӢЙз”ЁйҮҸӯ‘…иҝҮдәҶжҹҗдёҖдёӘйҳҖеҖы|јҢһ®Ҷи§ҰеҸ‘swapзҡ„ж“ҚдҪңпјҢRedisж ТҺҚ®“swappability = age*log(size_in_memory)”и®Ўз®—еҮәе“ӘдәӣkeyеҜ№еә”зҡ„valueйңҖиҰҒswapеҲ°зЈҒзӣҳгҖӮ然еҗҺеҶҚһ®ҶиҝҷдәӣkeyеҜ№еә”зҡ„valueжҢҒд№…еҢ–еҲ°јӮҒзӣҳдёӯпјҢеҗҢж—¶еңЁеҶ…еӯҳдёӯжё…йҷӨгҖӮиҝҷҝUҚзү№жҖ§дӢЙеҫ—RedisеҸҜд»ҘдҝқжҢҒӯ‘…иҝҮе…¶жңәеҷЁжң¬нw«еҶ…еӯҳеӨ§һ®Ҹзҡ„ж•°жҚ®гҖӮеҪ“з„УһјҢжңәеҷЁжң¬инnзҡ„еҶ…еӯҳеҝ…ҷе»иҰҒиғҪеӨҹдҝқжҢҒжүҖжңүзҡ„keyеQҢжҜ•з«ҹиҝҷдәӣж•°жҚ®жҳҜдёҚдјҡҳqӣиЎҢswapж“ҚдҪңзҡ„гҖ?br />
еҗҢж—¶з”ЧғәҺRedisһ®ҶеҶ…еӯҳдёӯзҡ„ж•°жҚ®swapеҲ°зЈҒзӣҳдёӯзҡ„ж—¶еҖҷпјҢжҸҗдҫӣжңҚеҠЎзҡ„дё»ҫUҝзЁӢе’ҢиҝӣиЎҢswapж“ҚдҪңзҡ„еӯҗҫUҝзЁӢдјҡе…ұдә«иҝҷйғЁеҲҶеҶ…еӯҳеQҢжүҖд»ҘеҰӮжһңжӣҙж–°йңҖиҰҒswapзҡ„ж•°жҚ®пјҢRedisһ®Ҷйҳ»еЎһиҝҷдёӘж“ҚдҪңпјҢзӣҙеҲ°еӯҗзәҝҪEӢе®ҢжҲҗswapж“ҚдҪңеҗҺжүҚеҸҜд»ҘҳqӣиЎҢдҝ®ж”№гҖ?br />
еҸҜд»ҘеҸӮиҖғдӢЙз”ЁRedisзүТҺңүеҶ…еӯҳжЁЎеһӢеүҚеҗҺзҡ„жғ…еҶөеҜ№жҜ”пјҡ
VM on: 300k keys, 4096 bytes values: 73M used
VM off: 1 million keys, 256 bytes values: 430.12M used
VM on: 1 million keys, 256 bytes values: 160.09M used
VM on: 1 million keys, values as large as you want, still: 160.09M used
еҪ“д»ҺRedisдёӯиҜ»еҸ–ж•°жҚ®зҡ„ж—¶еҖҷпјҢеҰӮжһңиҜХdҸ–зҡ„keyеҜ№еә”зҡ„valueдёҚеңЁеҶ…еӯҳдёӯпјҢйӮЈд№ҲRedisһ®ұйңҖиҰҒд»Һswapж–ҮдҡgдёӯеҠ иҪҪзӣёеә”ж•°жҚ®пјҢ然еҗҺеҶҚиҝ”еӣһз»ҷиҜдhұӮж–ҸVҖӮиҝҷйҮҢе°ұеӯҳеңЁдёҖдёӘI/OҫUҝзЁӢжұ зҡ„й—®йўҳгҖӮеңЁй»ҳи®Өзҡ„жғ…еҶөдёӢеQҢRedisдјҡеҮәзҺ°йҳ»еЎһпјҢеҚӣ_®ҢжҲҗжүҖжңүзҡ„swapж–ҮдҡgеҠ иқІеҗҺжүҚдјҡзӣёеә”гҖӮиҝҷҝUҚзӯ–з•ҘеңЁе®ўжҲ·з«Ҝзҡ„ж•°йҮҸиҫғе°ҸеQҢиҝӣиЎҢжү№йҮҸж“ҚдҪңзҡ„ж—¶еҖҷжҜ”иҫғеҗҲйҖӮгҖӮдҪҶжҳҜеҰӮжһңе°ҶRedisеә”з”ЁеңЁдёҖдёӘеӨ§еһӢзҡ„ҫ|‘з«ҷеә”з”ЁҪEӢеәҸдёӯпјҢҳqҷжҳҫ然жҳҜж— жі•ж»ЎиғцеӨ§еЖҲеҸ‘зҡ„жғ…еҶөзҡ„гҖӮжүҖд»ҘRedisҳqҗиЎҢжҲ‘们讄ЎҪ®I/OҫUҝзЁӢжұ зҡ„еӨ§е°ҸеQҢеҜ№йңҖиҰҒд»Һswapж–ҮдҡgдёӯеҠ иҪҪзӣёеә”ж•°жҚ®зҡ„иҜХdҸ–иҜдhұӮҳqӣиЎҢтq¶еҸ‘ж“ҚдҪңеQҢеҮҸһ®‘йҳ»еЎһзҡ„ж—үҷ—ҙгҖ?br />
redisгҖҒmemcacheгҖҒmongoDB еҜТҺҜ”
д»Һд»ҘдёӢеҮ дёӘз»ҙеәҰпјҢеҜ№redisгҖҒmemcacheгҖҒmongoDB еҒҡдәҶеҜТҺҜ”еQҢж¬ўҳqҺжӢҚз ?br />
1гҖҒжҖ§иғҪ
йғҪжҜ”иҫғй«ҳеQҢжҖ§иғҪеҜТҺҲ‘们жқҘиҜҙеә”иҜҘйғҪдёҚжҳҜз“үҷўҲ
жҖЦMҪ“жқҘи®ІеQҢTPSж–ҡwқўredisе’Ңmemcacheе·®дёҚеӨҡпјҢиҰҒеӨ§дәҺmongodb
2гҖҒж“ҚдҪңзҡ„дҫҝеҲ©жҖ?br />memcacheж•°жҚ®ҫl“жһ„еҚ•дёҖ
redisдё°еҜҢдёҖдәӣпјҢж•°жҚ®ж“ҚдҪңж–ҡwқўеQҢredisжӣҙеҘҪдёҖдәӣпјҢиҫғе°‘зҡ„зҪ‘ҫlңIOӢЖЎж•°
mongodbж”ҜжҢҒдё°еҜҢзҡ„ж•°жҚ®иЎЁиҫҫпјҢзҙўеј•еQҢжңҖҫcЦMјје…ізі»еһӢж•°жҚ®еә“еQҢж”ҜжҢҒзҡ„жҹҘиҜўиҜӯиЁҖйқһеёёдё°еҜҢ
3гҖҒеҶ…еӯҳз©әй—ҙзҡ„еӨ§е°Ҹе’Ңж•°жҚ®йҮҸзҡ„еӨ§һ®?br />redisең?.0зүҲжң¬еҗҺеўһеҠ дәҶиҮӘе·ұзҡ„VMзүТҺҖ§пјҢҪHҒз ҙзү©зҗҶеҶ…еӯҳзҡ„йҷҗеҲУһјӣеҸҜд»ҘеҜ№key valueи®„ЎҪ®ҳqҮжңҹж—үҷ—ҙеQҲзұ»дјјmemcacheеQ?br />memcacheеҸҜд»Ҙдҝ®ж”№жңҖеӨ§еҸҜз”ЁеҶ…еӯ?йҮҮз”ЁLRUҪҺ—жі•
mongoDBйҖӮеҗҲеӨ§ж•°жҚ®йҮҸзҡ„еӯҳеӮЁпјҢдҫқиө–ж“ҚдҪңҫpИқ»ҹVMеҒҡеҶ…еӯҳз®ЎзҗҶпјҢеҗғеҶ…еӯҳд№ҹжҜ”иҫғеҺүе®іеQҢжңҚеҠЎдёҚиҰҒе’ҢеҲ«зҡ„жңҚеҠЎеңЁдёҖиө?br />
4гҖҒеҸҜз”ЁжҖ§пјҲеҚ•зӮ№й—®йўҳеQ?br />
еҜ№дәҺеҚ•зӮ№й—®йўҳеQ?br />redisеQҢдҫқиө–е®ўжҲпL«ҜжқҘе®һзҺ°еҲҶеёғејҸиҜХdҶҷеQӣдё»д»ҺеӨҚеҲ¶ж—¶еQҢжҜҸӢЖЎд»ҺиҠӮзӮ№йҮҚж–°ҳqһжҺҘдё»иҠӮзӮҡwғҪиҰҒдҫқиө–ж•ҙдёӘеҝ«з…?ж— еўһйҮҸеӨҚеҲУһјҢеӣ жҖ§иғҪе’Ңж•ҲзҺҮй—®йўҳпјҢ
жүҖд»ҘеҚ•зӮҡw—®йўҳжҜ”иҫғеӨҚжқӮпјӣдёҚж”ҜжҢҒиҮӘеҠЁsharding,йңҖиҰҒдҫқиө–зЁӢеәҸи®ҫе®ҡдёҖиҮҙhash жңәеҲ¶гҖ?br />дёҖҝUҚжӣҝд»Јж–№жЎҲжҳҜеQҢдёҚз”Ёredisжң¬инnзҡ„еӨҚеҲ¶жңәеҲУһјҢйҮҮз”ЁиҮӘе·ұеҒҡдё»еҠЁеӨҚеҲУһјҲеӨҡдҶҫеӯҳеӮЁеQүпјҢжҲ–иҖ…ж”№жҲҗеўһйҮҸеӨҚеҲ¶зҡ„ж–№ејҸеQҲйңҖиҰҒиҮӘе·ұе®һзҺҺНјүеQҢдёҖиҮҙжҖ§й—®йўҳе’ҢжҖ§иғҪзҡ„жқғиЎ?br />
Memcacheжң¬инnжІЎжңүж•°жҚ®еҶ—дҪҷжңәеҲ¶еQҢд№ҹжІЎеҝ…иҰҒпјӣеҜ№дәҺж•…йҡңйў„йҳІеQҢйҮҮз”Ёдҫқиө–жҲҗзҶҹзҡ„hashжҲ–иҖ…зҺҜзҠ¶зҡ„ҪҺ—жі•еQҢи§ЈеҶӣ_Қ•зӮТҺ•…йҡңеј•иөпLҡ„жҠ–еҠЁй—®йўҳгҖ?br />
mongoDBж”ҜжҢҒmaster-slave,replicasetеQҲеҶ…йғЁйҮҮз”ЁpaxosйҖүдӢDҪҺ—жі•еQҢиҮӘеҠЁж•…йҡңжҒўеӨҚпјү,auto shardingжңәеҲ¶еQҢеҜ№е®ўжҲ·з«ҜеұҸи”ҪдәҶж•…йҡңиҪ¬з§»е’ҢеҲҮеҲҶжңәеҲ¶гҖ?br />
5гҖҒеҸҜйқ жҖ§пјҲжҢҒд№…еҢ–пјү
еҜ№дәҺж•°жҚ®жҢҒд№…еҢ–е’Ңж•°жҚ®жҒўеӨҚеQ?br />
redisж”ҜжҢҒеQҲеҝ«з…§гҖҒAOFеQүпјҡдҫқиө–еҝ«з…§ҳqӣиЎҢжҢҒд№…еҢ–пјҢaofеўһејәдәҶеҸҜйқ жҖ§зҡ„еҗҢж—¶еQҢеҜ№жҖ§иғҪжңүжүҖеҪұе“Қ
memcacheдёҚж”ҜжҢҒпјҢйҖҡеёёз”ЁеңЁеҒҡзј“еӯ?жҸҗеҚҮжҖ§иғҪеQ?br />
MongoDBд»?.8зүҲжң¬ејҖе§ӢйҮҮз”Ёbinlogж–№ејҸж”ҜжҢҒжҢҒд№…еҢ–зҡ„еҸҜйқ жҖ?br />
6гҖҒж•°жҚ®дёҖиҮҙжҖ§пјҲдәӢеҠЎж”ҜжҢҒеQ?br />
Memcache еңЁеЖҲеҸ‘еңәжҷҜдёӢеQҢз”ЁcasдҝқиҜҒдёҖиҮҙжҖ?br />
redisдәӢеҠЎж”ҜжҢҒжҜ”иҫғејұпјҢеҸӘиғҪдҝқиҜҒдәӢеҠЎдёӯзҡ„жҜҸдёӘж“ҚдҪңҳqһз®Ӣжү§иЎҢ
mongoDBдёҚж”ҜжҢҒдәӢеҠ?br />
7гҖҒж•°жҚ®еҲҶжһ?br />
mongoDBеҶ…зҪ®дәҶж•°жҚ®еҲҶжһҗзҡ„еҠҹиғҪ(mapreduce),е…¶д»–дёҚж”ҜжҢ?br />
8гҖҒеә”з”Ёеңәжҷ?br />redisеQҡж•°жҚ®йҮҸиҫғе°Ҹзҡ„жӣҙжҖ§иғҪж“ҚдҪңе’ҢиҝҗҪҺ—дёҠ
memcacheеQҡз”ЁдәҺеңЁеҠЁжҖҒзі»ҫlҹдёӯеҮҸе°‘ж•°жҚ®еә“иҙҹиҪҪпјҢжҸҗеҚҮжҖ§иғҪ;еҒҡзј“еӯҳпјҢжҸҗй«ҳжҖ§иғҪеQҲйҖӮеҗҲиҜХdӨҡеҶҷе°‘еQҢеҜ№дәҺж•°жҚ®йҮҸжҜ”иҫғеӨ§пјҢеҸҜд»ҘйҮҮз”ЁshardingеQ?br />
MongoDB:дё»иҰҒи§ЈеҶіӢ№·йҮҸж•°жҚ®зҡ„и®ҝй—®ж•ҲзҺҮй—®йў?img src ="http://www.aygfsteel.com/paulwong/aggbug/403746.html" width = "1" height = "1" />
REDISд№ҰзұҚ
http://abcfy2.gitbooks.io/redis-in-action-reading-notes/getting_to_know_redis/session1.html