Annotated Lucene(中文版)
Annotated Lucene 作者:naven
3 索引類關(guān)系圖
下面逐個(gè)介紹與建立索引有關(guān)的一些類及它們的關(guān)系。
3.1 org.apache.lucene.store.IndexWriter
一個(gè)IndexWriter對(duì)象只創(chuàng)建并維護(hù)一個(gè)索引。IndexWriter通過指定存放的目錄(Directory)以及文檔分析器(Analyzer)來構(gòu)建,direcotry代表索引存儲(chǔ)(resides)在哪里;analyzer表示如何來分析文檔的內(nèi)容;similarity用來規(guī)格化(normalize)文檔,給文檔算分(scoring);IndexWriter類里還有一些SegmentInfos對(duì)象用于存儲(chǔ)索引片段信息,以及發(fā)生故障回滾等。以下是它們的類圖:
3.2 org.apache.lucene.store.Directory
一個(gè)Directory對(duì)象是一系列統(tǒng)一的文件列表(a flat list of files)。文件可以在它們被創(chuàng)建的時(shí)候一次寫入,一旦文件被創(chuàng)建,它再次打開后只能用于讀取(read)或者刪除(delete)操作。并且同時(shí)在讀取和寫入的時(shí)候允許隨機(jī)訪問(random access)。
在這里并不直接使用Java I/O API,但是更確切地說,所有I/O操作都是通過這個(gè)API處理的。這使得讀寫操作方式更統(tǒng)一起來,如基于內(nèi)存的索引(RAM-based indices)的實(shí)現(xiàn)(即RAMDirectory)、通過JDBC存儲(chǔ)在數(shù)據(jù)庫(kù)中的索引、將一個(gè)索引存儲(chǔ)為一個(gè)文件的實(shí)現(xiàn)(即FSDirectory)。
Directory的鎖機(jī)制是一個(gè)LockFactory的實(shí)例實(shí)現(xiàn)的,可以通過調(diào)用Directory實(shí)例的setLockFactory()方法來更改。
3.3 org.apache.lucene.store.FSDirectory
FSDirectory類直接實(shí)現(xiàn)Directory抽象類為一個(gè)包含文件的目錄。目錄鎖的實(shí)現(xiàn)使用缺省的SimpleFSLockFactory,但是可以通過兩種方式修改,即給getLockFactory()傳入一個(gè)LockFactory實(shí)例,或者通過調(diào)用setLockFactory()方法明確制定LockFactory類。
目錄將被緩存(cache)起來,對(duì)一個(gè)指定的符合規(guī)定的路徑(canonical path)來說,同樣的FSDirectory實(shí)例通常通過getDirectory()方法返回。這使得同步機(jī)制(synchronization)能對(duì)目錄起作用。
3.4 org.apache.lucene.store.RAMDirectory
RAMDirectory類是一個(gè)駐留內(nèi)存的(memory-resident)Directory抽象類的實(shí)現(xiàn)。目錄鎖的實(shí)現(xiàn)使用缺省的SingleInstanceLockFactory,但是可以通過setLockFactory()方法修改。
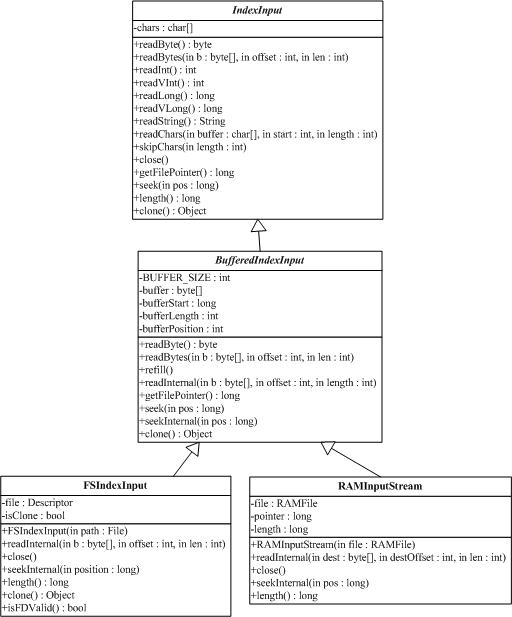
3.5 org.apache.lucene.store.IndexInput
IndexInput類是一個(gè)為了從一個(gè)目錄(Directory)中讀取文件的抽象基類,是一個(gè)隨機(jī)訪問(random-access)的輸入流(input stream),用于所有Lucene讀取Index的操作。BufferedIndexInput是一個(gè)實(shí)現(xiàn)了帶緩沖的IndexInput的基礎(chǔ)實(shí)現(xiàn)。
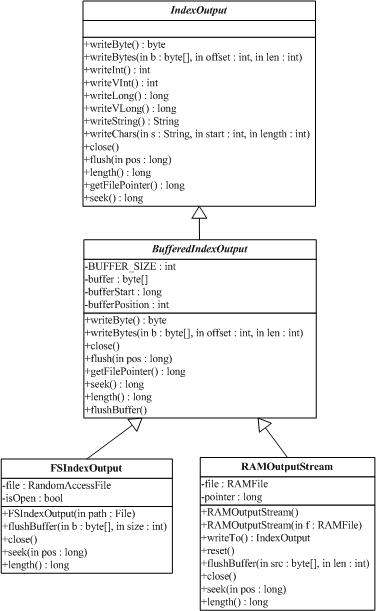
3.6 org.apache.lucene.store.IndexOutput
IndexOutput類是一個(gè)為了寫入文件到一個(gè)目錄(Directory)中的抽象基類,是一個(gè)隨機(jī)訪問(random-access)的輸出流(output stream),用于所有Lucene寫入Index的操作。BufferedIndexOutput是一個(gè)實(shí)現(xiàn)了帶緩沖的IndexOutput的基礎(chǔ)實(shí)現(xiàn)。RAMOuputStream是一個(gè)內(nèi)存駐留(memory-resident)的IndexOutput的實(shí)現(xiàn)類。
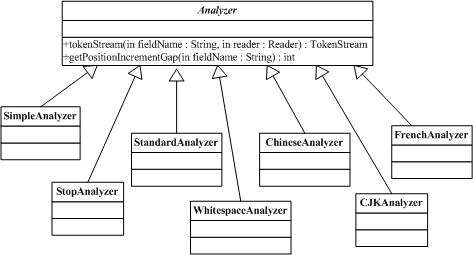
3.7 org.apache.lucene.store.Analyzer
Analyzer類構(gòu)建用于分析文本的TokenStream對(duì)象,因此(thus)它表示(represent)用于從文本中分解(extract)出組成索引的terms的一個(gè)規(guī)則器(policy)。典型的(typical)實(shí)現(xiàn)首先創(chuàng)建一個(gè)Tokenizer,它將那些從Reader對(duì)象中讀取字符流(stream of characters)打碎為(break into)原始的Tokens(raw Tokens)。然后一個(gè)或更多的TokenFilters可以應(yīng)用在這個(gè)Tokenizer的輸出上。警告:你必須在你的子類(subclass)中覆寫(override)定義在這個(gè)類中的其中一個(gè)方法,否則的話Analyzer將會(huì)進(jìn)入一個(gè)無限循環(huán)(infinite loop)中。
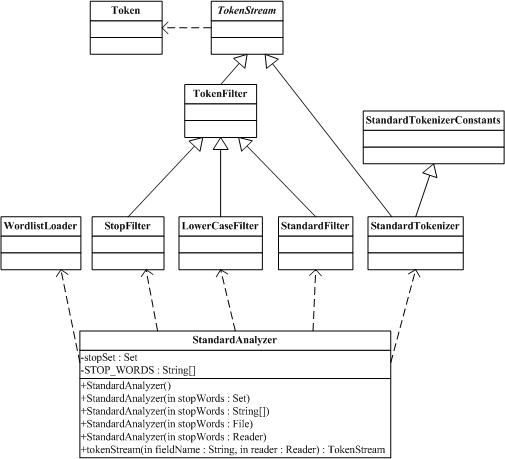
3.8 org.apache.lucene.store.StandardAnalyzer
StandardAnalyzer類是使用一個(gè)English的stop words列表來進(jìn)行tokenize分解出文本中word,使用StandardTokenizer類分解詞,再加上StandardFilter以及LowerCaseFilter以及StopFilter這些過濾器進(jìn)行處理的這樣一個(gè)Analyzer類的實(shí)現(xiàn)。
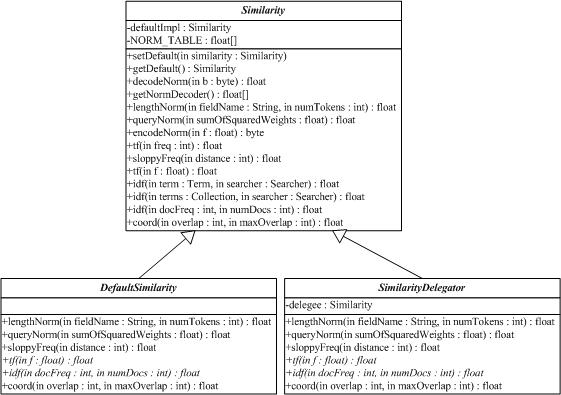
3.9 org.apache.lucene.search.Similarity
Similarity類實(shí)現(xiàn)算分(scoring)的API,它的子類實(shí)現(xiàn)了檢索算分的算法。DefaultSimilarity類是缺省的算分的實(shí)現(xiàn),SimilarityDelegator類是用于委托算分(delegating scoring)的實(shí)現(xiàn),在Query.getSimilarity(Searcher)}的實(shí)現(xiàn)里起作用,以便覆寫(override)一個(gè)Searcher中Similarity實(shí)現(xiàn)類的僅有的確定方法(certain methods)。
查詢q相對(duì)于文檔d的分?jǐn)?shù)與在文檔和查詢向量(query vectors)之間的余弦距離(cosing-distance)或者點(diǎn)乘積(dot-product)有關(guān)系(correlates to),文檔和查詢向量存于一個(gè)信息檢索(Information Retrieval)的向量空間模型(Vector Space Model (VSM))之中。一篇文檔的向量與查詢向量越接近(closer to),它的得分也越高(scored higher),這個(gè)分?jǐn)?shù)按如下公式計(jì)算:
其中:
1. tf(t in d)與term的出現(xiàn)次數(shù)(frequency)有關(guān)系(correlate to),定義為(defined as)term t在當(dāng)前算分(currently scored)的文檔d中出現(xiàn)(appear in)的次數(shù)(number of times)。對(duì)一個(gè)給定(gived)的term,那些出現(xiàn)此term的次數(shù)越多(more occurences)的文檔將獲得越高的分?jǐn)?shù)(higher score)。缺省的tf(t in d)算法實(shí)現(xiàn)在DefaultSimilarity類中,公式如下:
2. idf(t) 代表(stand for)反轉(zhuǎn)文檔頻率(Inverse Document Frequency)。這個(gè)分?jǐn)?shù)與反轉(zhuǎn)(inverse of)的docFreq(出現(xiàn)過term t的文檔數(shù)目)有關(guān)系。這個(gè)分?jǐn)?shù)的意義是越不常出現(xiàn)(rarer)的term將為最后的總分貢獻(xiàn)(contribution)更多的分?jǐn)?shù)。缺省idff(t in d)算法實(shí)現(xiàn)在DefaultSimilarity類中,公式如下:
3. coord(q,d) 是一個(gè)評(píng)分因子,基于(based on)有多少個(gè)查詢terms在特定的文檔(specified document)中被找到。通常(typically),一篇包含了越多的查詢terms的文檔將比另一篇包含更少查詢terms的文檔獲得更高的分?jǐn)?shù)。這是一個(gè)搜索時(shí)的因子(search time factor)是在搜索的時(shí)候起作用(in effect at search time),它在Similarity對(duì)象的coord(q,d)函數(shù)中計(jì)算。
4. queryNorm(q)是一個(gè)修正因子(normalizing factor),用來使不同查詢間的分?jǐn)?shù)更可比較(comparable)。這個(gè)因子不影響文檔的排名(ranking)(因?yàn)樗阉髋藕眯虻奈臋n(ranked document)會(huì)增加(multiplied)相同的因數(shù)(same factor)),更確切地說只是(but rather just)為了嘗試(attempt to)使得不同查詢條件(甚至不同索引(different indexes))之間更可比較性。這是一個(gè)搜索時(shí)的因子是在搜索的時(shí)候起作用,由Similarity對(duì)象計(jì)算。缺省queryNorm(q)算法實(shí)現(xiàn)在DefaultSimilarity類中,公式如下:
sumOfSquaredWeights(查詢的terms)是由查詢Weight對(duì)象計(jì)算的,例如一個(gè)布爾(boolean)條件查詢的計(jì)算公式為:
5. t.getBoost()是一個(gè)搜索時(shí)(search time)的代表查詢q中的term t的boost數(shù)值,具體指定在(as specified in)查詢的文本中(參見查詢語法),或者由應(yīng)用程序調(diào)用setBoost()來指定。需要注意的是實(shí)際上(really)沒有一個(gè)直接(direct)的API來訪問(accessing)一個(gè)多個(gè)term的查詢(multi term query)中的一個(gè)term 的boost值,更確切地說(but rather),多個(gè)terms(multi terms)在一個(gè)查詢里的表示形式(represent as)是多個(gè)TermQuery對(duì)象,所以查詢里的一個(gè)term的boost值的訪問是通過調(diào)用子查詢(sub-query)的getBoost()方法實(shí)現(xiàn)的。
6. norm(t,d)是提煉取得(encapsulate)一小部分boost值(在索引時(shí)間)和長(zhǎng)度因子(length factor):
ú document boost – 在添加文檔到索引之前通過調(diào)用doc.setBoost()來設(shè)置。
ú Field boost – 在添加Field到文檔之前通過調(diào)用field.setBoost()來設(shè)置。
ú lengthNorm(field) – 在文檔添加到索引的時(shí)候,根據(jù)(in accordance with)文檔中該field的tokens數(shù)目計(jì)算得出,所以更短(shorter)的field會(huì)貢獻(xiàn)更多的分?jǐn)?shù)。lengthNorm是在索引的時(shí)候起作用,由Similarity類計(jì)算得出。
當(dāng)一篇文檔被添加到索引的時(shí)候,所有上面計(jì)算出的因子將相乘起來(multiplied)。如果文檔擁有多個(gè)相同名字的fields(multiple fields with same name),所有這些fields的boost值也會(huì)被一起相乘起來(multiplied together):
然而norm數(shù)值的結(jié)果在被存儲(chǔ)(stored)之前被編碼成(encoded as)一個(gè)單獨(dú)的字節(jié)(single byte)。在檢索的時(shí)候,這個(gè)norm字節(jié)值從索引目錄(index directory)中讀取出來,并解碼回(decoded back)一個(gè)norm浮點(diǎn)數(shù)值(float value)。這個(gè)編/解碼(encoding/decoding)行為,會(huì)縮減(reduce)索引的大小(index size),這得自于(come with)精度損耗的代價(jià)(price of precision loss)- 它不保證decode(encode(x))=x,舉例來說decode(encode(0.89))=0.75。還有需要注意的是,檢索的時(shí)候再修改評(píng)分(scoring)的這個(gè)norm部分已近太遲了,例如,為檢索使用不同的Similarity。