摘要: JDBC模板類 概述 Spring JDBC抽象框架core包提供了JDBC模板類,其中JdbcTemplate是core包的核心類,所以其他模板類都是基于它封裝完成的,JDBC模板類是第一種工作模式。 JdbcTemplate類通過模板...
閱讀全文
posted @
2012-02-26 09:39 todayx.org 閱讀(2723) |
評論 (0) |
編輯 收藏 在軟件這個行業里有些規則是很有殺傷力的,比如很有名的摩爾定律。
總結出這些規則的意義在于可以大致的照明方向,免得努力來努力去卻走到了陰溝里。
現實中種種利益紛爭、觀點之爭看似紛繁,但在大時間尺度下來看卻都是規則的實現手段。
這就好比下圍棋,每一手都要為謀得利益而計算,但結局卻只有三種:贏、輸或和,這就是規則的力量。
民以食為天,所以第一定律從收入開始。
程序員第一定律可以表述為:程序員的收入是技能復雜度和技能實現可能程度的函數。
如果程序員的工資是S,社會平均水平的工資為A,程序員掌握的技能復雜度為C,實現程度為P。
那么S = A x C x P。
這里面的實現程度P不太好理解,額外做點說明。
好比說有人在東北種了很多白菜,并獲得了大豐收。與此同時廣州也確實需要大白菜,按批發價他的這批白菜可以買10萬。
但關鍵是這個人找不到車皮,大白菜就只能在當地零售,這個時候這批大白菜就只能買1萬塊錢。
這就是實現程度。
大白菜內蘊了既定的價值,這種價值并不因為賣多少錢而改變,但這種價值能實現到什么程度則依賴于現實的可能性。
這視乎很簡單,但其實不是,很多人的一生就籠罩在這條定律下面,我們來基于這第一定律繼續做些推導。
技能的復雜度C可以大致等價于掌握一門技術所需要的時間。
各種集成的開發環境,各種容易學習的類庫等使軟件開發的門檻降得很低,這對整個產業是有利的,但對個體而言則是不利的。
你花5個月可以學會的技術,其他人花5個月也可以學會,而5個月可以學會的東西所蘊含的價值一定是低的。
與之相對5年才可以學會的東西,其內蘊價值一定是高的。
內蘊價值低,所對應的收入必然偏低。
為避免爭議,我這里就不寫技術的名字了,但大家可以從學習所需要的時間上來對各種技術做個分類。
有時候很多人會有一種錯覺,認為越熱門的技術收益越好。
這在大多時候是錯的。
越熱的技術,越成熟的技術越是大眾的,而越是大眾的技術內蘊價值越低,所以收益越不好。
熱度能夠幫助找到工作,但對技能復雜度C沒有影響。
- 推論2:單純的涉獵廣泛,沒有專精,對收入的影響是負面的。
各種技術的復雜度大概是呈指數增長的,越到后面前進一步越困難。
好比說學會5門語言所需要的時間大多時候遠比學精一門語言要短。
在特定年紀尚,每樣技術都會一點,對提高實現程度P略有幫助,但自身可替代性很強,對技能復雜度C的影響為負面。
長期來看得不償失。
有些技術領域很窄,上手也慢,實現程度卻高,比如顯卡驅動,打印驅動等。
但這類工作好比在鋼絲上跳舞:只要能實現自己的價值,那么回報大體不錯,但最怕技術更迭。
技術一換代,可能多年積累十去六七。
總結來看,程序員要想獲得不錯的收入,第一要掌握稀缺的技術,即技術的內蘊價值要高;第二要找到實現稀缺技術的場景。
《微軟的秘密》一書中提到,微軟里面優秀的程序員是可以擁有許多輛保時捷的。
用上面兩條做分解,就會發現原因很簡單:
一是這樣的人是NT的核心開發人員,這類人員內蘊價值極高,處于稀缺狀態;二是微軟提供了實現這種技能內蘊價值的機會。
這二者缺一不可。
#根據大家的回復做了點修改把"實現可能性"替換成了"實現程度"。
2012世界末日暨環境保護主題站,關注國內外最新2012世界末日信息,旨在通過關注,收集,展示2012世界末日相關資料的方式,喚醒并提高人們保護環境與愛護地球的意識,引導人類保護環境.
posted @
2012-02-14 22:03 todayx.org 閱讀(557) |
評論 (4) |
編輯 收藏什么是HTTP協議
協議是指計算機通信網絡中兩臺計算機之間進行通信所必須共同遵守的規定或規則,超文本傳輸協議(HTTP)是一種通信協議,它允許將超文本標記語言(HTML)文檔從Web服務器傳送到客戶端的瀏覽器
目前我們使用的是HTTP/1.1 版本
Web服務器,瀏覽器,代理服務器
當我們打開瀏覽器,在地址欄中輸入URL,然后我們就看到了網頁。 原理是怎樣的呢?
實際上我們輸入URL后,我們的瀏覽器給Web服務器發送了一個Request, Web服務器接到Request后進行處理,生成相應的Response,然后發送給瀏覽器, 瀏覽器解析Response中的HTML,這樣我們就看到了網頁,過程如下圖所示

我們的Request 有可能是經過了代理服務器,最后才到達Web服務器的。
過程如下圖所示

代理服務器就是網絡信息的中轉站,有什么功能呢?
1. 提高訪問速度, 大多數的代理服務器都有緩存功能。
2. 突破限制, 也就是翻-墻了
3. 隱藏身份。
URL詳解
URL(Uniform Resource Locator) 地址用于描述一個網絡上的資源, 基本格式如下
schema://host[:port#]/path/.../[?query-string][#anchor]
scheme 指定低層使用的協議(例如:http, https, ftp)
host HTTP服務器的IP地址或者域名
port# HTTP服務器的默認端口是80,這種情況下端口號可以省略。如果使用了別的端口,必須指明,例如 http://www.cnblogs.com:8080/
path 訪問資源的路徑
query-string 發送給http服務器的數據
anchor- 錨
URL 的一個例子
http://www.mywebsite.com/sj/test/test.aspx?name=sviergn&x=true#stuff Schema: http host: www.mywebsite.com path: /sj/test Query String: name=sviergn&x=true Anchor: stuff
HTTP協議是無狀態的
http協議是無狀態的,同一個客戶端的這次請求和上次請求是沒有對應關系,對http服務器來說,它并不知道這兩個請求來自同一個客戶端。 為了解決這個問題, Web程序引入了Cookie機制來維護狀態.
HTTP消息的結構
先看Request 消息的結構, Request 消息分為3部分,第一部分叫Request line, 第二部分叫Request header, 第三部分是body. header和body之間有個空行, 結構如下圖

第一行中的Method表示請求方法,比如"POST","GET", Path-to-resoure表示請求的資源, Http/version-number 表示HTTP協議的版本號
當使用的是"GET" 方法的時候, body是為空的
比如我們打開博客園首頁的request 如下
GET http://www.cnblogs.com/ HTTP/1.1 Host: www.cnblogs.com
下面我們打開Fiddler 捕捉一個博客園登錄的Request 然后分析下它的結構, 在Inspectors tab下以Raw的方式可以看到完整的Request的消息, 如下圖

我們再看Response消息的結構, 和Request消息的結構基本一樣。 同樣也分為三部分,第一部分叫Response line, 第二部分叫Response header,第三部分是body. header和body之間也有個空行, 結構如下圖

HTTP/version-number表示HTTP協議的版本號, status-code 和message 請看下節[狀態代碼]的詳細解釋.
我們用Fiddler 捕捉一個博客園首頁的Response然后分析下它的結構, 在Inspectors tab下以Raw的方式可以看到完整的Response的消息, 如下圖

Get和Post方法的區別
Http協議定義了很多與服務器交互的方法,最基本的有4種,分別是GET,POST,PUT,DELETE. 一個URL地址用于描述一個網絡上的資源,而HTTP中的GET, POST, PUT, DELETE就對應著對這個資源的查,改,增,刪4個操作。 我們最常見的就是GET和POST了。GET一般用于獲取/查詢資源信息,而POST一般用于更新資源信息.
我們看看GET和POST的區別
1. GET提交的數據會放在URL之后,以?分割URL和傳輸數據,參數之間以&相連,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的數據放在HTTP包的Body中.
2. GET提交的數據大小有限制(因為瀏覽器對URL的長度有限制),而POST方法提交的數據沒有限制.
3. GET方式需要使用Request.QueryString來取得變量的值,而POST方式通過Request.Form來獲取變量的值。
4. GET方式提交數據,會帶來安全問題,比如一個登錄頁面,通過GET方式提交數據時,用戶名和密碼將出現在URL上,如果頁面可以被緩存或者其他人可以訪問這臺機器,就可以從歷史記錄獲得該用戶的賬號和密碼.
狀態碼
Response 消息中的第一行叫做狀態行,由HTTP協議版本號, 狀態碼, 狀態消息 三部分組成。
狀態碼用來告訴HTTP客戶端,HTTP服務器是否產生了預期的Response.
HTTP/1.1中定義了5類狀態碼, 狀態碼由三位數字組成,第一個數字定義了響應的類別
1XX 提示信息 - 表示請求已被成功接收,繼續處理
2XX 成功 - 表示請求已被成功接收,理解,接受
3XX 重定向 - 要完成請求必須進行更進一步的處理
4XX 客戶端錯誤 - 請求有語法錯誤或請求無法實現
5XX 服務器端錯誤 - 服務器未能實現合法的請求
看看一些常見的狀態碼
200 OK
最常見的就是成功響應狀態碼200了, 這表明該請求被成功地完成,所請求的資源發送回客戶端
如下圖, 打開博客園首頁

302 Found
重定向,新的URL會在response 中的Location中返回,瀏覽器將會自動使用新的URL發出新的Request
例如在IE中輸入, http://www.google.com. HTTP服務器會返回304, IE取到Response中Location header的新URL, 又重新發送了一個Request.

304 Not Modified
代表上次的文檔已經被緩存了, 還可以繼續使用,
例如打開博客園首頁, 發現很多Response 的status code 都是304

提示: 如果你不想使用本地緩存可以用Ctrl+F5 強制刷新頁面
400 Bad Request 客戶端請求與語法錯誤,不能被服務器所理解
403 Forbidden 服務器收到請求,但是拒絕提供服務
404 Not Found
請求資源不存在(輸錯了URL)
比如在IE中輸入一個錯誤的URL, http://www.cnblogs.com/tesdf.aspx

500 Internal Server Error 服務器發生了不可預期的錯誤
503 Server Unavailable 服務器當前不能處理客戶端的請求,一段時間后可能恢復正常
HTTP Request header
使用Fiddler 能很方便的查看Reques header, 點擊Inspectors tab ->Request tab-> headers 如下圖所示.

header 有很多,比較難以記憶,我們也按照Fiddler那樣把header 進行分類,這樣比較清晰也容易記憶。
Cache 頭域
If-Modified-Since
作用: 把瀏覽器端緩存頁面的最后修改時間發送到服務器去,服務器會把這個時間與服務器上實際文件的最后修改時間進行對比。如果時間一致,那么返回304,客戶端 就直接使用本地緩存文件。如果時間不一致,就會返回200和新的文件內容。客戶端接到之后,會丟棄舊文件,把新文件緩存起來,并顯示在瀏覽器中.
例如:If-Modified-Since: Thu, 09 Feb 2012 09:07:57 GMT
實例如下圖

If-None-Match
作用: If-None-Match和ETag一起工作,工作原理是在HTTP Response中添加ETag信息。 當用戶再次請求該資源時,將在HTTP Request 中加入If-None-Match信息(ETag的值)。如果服務器驗證資源的ETag沒有改變(該資源沒有更新),將返回一個304狀態告訴客戶端使用 本地緩存文件。否則將返回200狀態和新的資源和Etag. 使用這樣的機制將提高網站的性能
例如: If-None-Match: "03f2b33c0bfcc1:0"
實例如下圖

Pragma
作用: 防止頁面被緩存, 在HTTP/1.1版本中,它和Cache-Control:no-cache作用一模一樣
Pargma只有一個用法, 例如: Pragma: no-cache
注意: 在HTTP/1.0版本中,只實現了Pragema:no-cache, 沒有實現Cache-Control
Cache-Control
作用: 這個是非常重要的規則。 這個用來指定Response-Request遵循的緩存機制。各個指令含義如下
Cache-Control:Public 可以被任何緩存所緩存()
Cache-Control:Private 內容只緩存到私有緩存中
Cache-Control:no-cache 所有內容都不會被緩存
還有其他的一些用法, 我沒搞懂其中的意思, 請大家參考其他的資料
Client 頭域
Accept
作用: 瀏覽器端可以接受的媒體類型,
例如: Accept: text/html 代表瀏覽器可以接受服務器回發的類型為 text/html 也就是我們常說的html文檔,
如果服務器無法返回text/html類型的數據,服務器應該返回一個406錯誤(non acceptable)
通配符 * 代表任意類型
例如 Accept: */* 代表瀏覽器可以處理所有類型,(一般瀏覽器發給服務器都是發這個)
Accept-Encoding:
作用: 瀏覽器申明自己接收的編碼方法,通常指定壓縮方法,是否支持壓縮,支持什么壓縮方法(gzip,deflate),(注意:這不是只字符編碼);
例如: Accept-Encoding: gzip, deflate
Accept-Language
作用: 瀏覽器申明自己接收的語言。
語言跟字符集的區別:中文是語言,中文有多種字符集,比如big5,gb2312,gbk等等;
例如: Accept-Language: en-us
User-Agent
作用:告訴HTTP服務器, 客戶端使用的操作系統和瀏覽器的名稱和版本.
我們上網登陸論壇的時候,往往會看到一些歡迎信息,其中列出了你的操作系統的名稱和版本,你所使用的瀏覽器的名稱和版本,這往往讓很多人感到很神 奇,實際上,服務器應用程序就是從User-Agent這個請求報頭域中獲取到這些信息User-Agent請求報頭域允許客戶端將它的操作系統、瀏覽器 和其它屬性告訴服務器。
例如: User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C; InfoPath.2; .NET4.0E)
Accept-Charset
作用:瀏覽器申明自己接收的字符集,這就是本文前面介紹的各種字符集和字符編碼,如gb2312,utf-8(通常我們說Charset包括了相應的字符編碼方案);
例如:
Cookie/Login 頭域
Cookie:
作用: 最重要的header, 將cookie的值發送給HTTP 服務器
Entity頭域
Content-Length
作用:發送給HTTP服務器數據的長度。
例如: Content-Length: 38
Content-Type
作用:
例如:Content-Type: application/x-www-form-urlencoded
Miscellaneous 頭域
Referer:
作用: 提供了Request的上下文信息的服務器,告訴服務器我是從哪個鏈接過來的,比如從我主頁上鏈接到一個朋友那里,他的服務器就能夠從HTTP Referer中統計出每天有多少用戶點擊我主頁上的鏈接訪問他的網站。
例如: Referer:http://translate.google.cn/?hl=zh-cn&tab=wT
Transport 頭域
Connection
例如: Connection: keep-alive 當一個網頁打開完成后,客戶端和服務器之間用于傳輸HTTP數據的TCP連接不會關閉,如果客戶端再次訪問這個服務器上的網頁,會繼續使用這一條已經建立的連接
例如: Connection: close 代表一個Request完成后,客戶端和服務器之間用于傳輸HTTP數據的TCP連接會關閉, 當客戶端再次發送Request,需要重新建立TCP連接。
Host(發送請求時,該報頭域是必需的)
作用: 請求報頭域主要用于指定被請求資源的Internet主機和端口號,它通常從HTTP URL中提取出來的
例如: 我們在瀏覽器中輸入:http://www.guet.edu.cn/index.html
瀏覽器發送的請求消息中,就會包含Host請求報頭域,如下:
Host:http://www.guet.edu.cn
此處使用缺省端口號80,若指定了端口號,則變成:Host:指定端口號
HTTP Response header
同樣使用Fiddler 查看Response header, 點擊Inspectors tab ->Response tab-> headers 如下圖所示

我們也按照Fiddler那樣把header 進行分類,這樣比較清晰也容易記憶。
Cache頭域
Date
作用: 生成消息的具體時間和日期
例如: Date: Sat, 11 Feb 2012 11:35:14 GMT
Expires
作用: 瀏覽器會在指定過期時間內使用本地緩存
例如: Expires: Tue, 08 Feb 2022 11:35:14 GMT
Vary
作用:
例如: Vary: Accept-Encoding
Cookie/Login 頭域
P3P
作用: 用于跨域設置Cookie, 這樣可以解決iframe跨域訪問cookie的問題
例如: P3P: CP=CURa ADMa DEVa PSAo PSDo OUR BUS UNI PUR INT DEM STA PRE COM NAV OTC NOI DSP COR
Set-Cookie
作用: 非常重要的header, 用于把cookie 發送到客戶端瀏覽器, 每一個寫入cookie都會生成一個Set-Cookie.
例如: Set-Cookie: sc=4c31523a; path=/; domain=.acookie.taobao.com

Entity頭域
ETag
作用: 和If-None-Match 配合使用。 (實例請看上節中If-None-Match的實例)
例如: ETag: "03f2b33c0bfcc1:0"
Last-Modified:
作用: 用于指示資源的最后修改日期和時間。(實例請看上節的If-Modified-Since的實例)
例如: Last-Modified: Wed, 21 Dec 2011 09:09:10 GMT
Content-Type
作用:WEB服務器告訴瀏覽器自己響應的對象的類型和字符集,
例如:
Content-Type: text/html; charset=utf-8
Content-Type:text/html;charset=GB2312
Content-Type: image/jpeg
Content-Length
指明實體正文的長度,以字節方式存儲的十進制數字來表示。在數據下行的過程中,Content-Length的方式要預先在服務器中緩存所有數據,然后所有數據再一股腦兒地發給客戶端。
例如: Content-Length: 19847
Content-Encoding
WEB服務器表明自己使用了什么壓縮方法(gzip,deflate)壓縮響應中的對象。
例如:Content-Encoding:gzip
Content-Language
作用: WEB服務器告訴瀏覽器自己響應的對象的語言者
例如: Content-Language:da
Miscellaneous 頭域
Server:
作用:指明HTTP服務器的軟件信息
例如:Server: Microsoft-IIS/7.5
X-AspNet-Version:
作用:如果網站是用ASP.NET開發的,這個header用來表示ASP.NET的版本
例如: X-AspNet-Version: 4.0.30319
X-Powered-By:
作用:表示網站是用什么技術開發的
例如: X-Powered-By: ASP.NET
Transport頭域
Connection
例如: Connection: keep-alive 當一個網頁打開完成后,客戶端和服務器之間用于傳輸HTTP數據的TCP連接不會關閉,如果客戶端再次訪問這個服務器上的網頁,會繼續使用這一條已經建立的連接
例如: Connection: close 代表一個Request完成后,客戶端和服務器之間用于傳輸HTTP數據的TCP連接會關閉, 當客戶端再次發送Request,需要重新建立TCP連接。
Location頭域
Location
作用: 用于重定向一個新的位置, 包含新的URL地址
實例請看304狀態實例
HTTP協議是無狀態的和Connection: keep-alive的區別
無狀態是指協議對于事務處理沒有記憶能力,服務器不知道客戶端是什么狀態。從另一方面講,打開一個服務器上的網頁和你之前打開這個服務器上的網頁之間沒有任何聯系
HTTP是一個無狀態的面向連接的協議,無狀態不代表HTTP不能保持TCP連接,更不能代表HTTP使用的是UDP協議(無連接)
從HTTP/1.1起,默認都開啟了Keep-Alive,保持連接特性,簡單地說,當一個網頁打開完成后,客戶端和服務器之間用于傳輸HTTP數據的TCP連接不會關閉,如果客戶端再次訪問這個服務器上的網頁,會繼續使用這一條已經建立的連接
Keep-Alive不會永久保持連接,它有一個保持時間,可以在不同的服務器軟件(如Apache)中設定這個時間
posted @
2012-02-14 21:58 todayx.org 閱讀(331) |
評論 (3) |
編輯 收藏 作為一個開發者,尤其是web開發人員,我想你有必要去了解這一系列的處理流程,在這期間,瀏覽器和服務器到底是如何打交道的?服務器又是如何處理的?瀏覽器又是如何將網頁顯示給用戶的呢?......
疑惑和細節真是太多了。坦白講,要想徹徹底底的弄清楚以上每個疑惑和處理細節,至少需要十本書的厚度,所謂“底層無極限”嘛,而且不同的web服務 器和服務器端編程語言的實現和處理流程不盡相同(但本質都是相通的)。本文中,我將根據http協議的有關知識,跟大家講解一些web開發的本質。不管你 是從事.NET,還是J2EE或者php開發等等,都離不開這些本質。希望你讀完本文,能有新的收獲和見解。由于本人水平和經驗有限,難免有誤,望讀者見 諒。
何為http協議(Hypertext Transfer Protocol,超文本傳輸協議)?
所謂協議,就是指雙方遵循的規范。http協議,就是瀏覽器和服務器之間進行“溝通”的一種規范。我們在看空間,刷微博...都是在使用http協議,當然,遠遠不止這些應用。
筆者一直聽說http是屬于“應用層的協議”,而且是基于TCP/IP協議的。這個不難理解,如果你上大學時候學過“計算機網絡”的課程,就一定知 道OSI七層參考協議(我當時是死記硬背的)。如果你接觸過socket網絡編程,就應該明白TCP和UDP這兩種使用廣泛的通信協議(建立連接、三次握 手等等,當然,這不是本文討論的重點)。如圖:

既然TCP/UDP是廣泛使用的網絡通信協議,那為啥有多出個http協議來呢?
筆者曾自己動手寫過一個簡單的web服務器處理軟件,根據我的推斷(不一定準確)。UDP協議具有不可靠性和不安全性,顯然這很難滿足web應用的需要。
而TCP協議是基于連接和三次握手的,雖然具有可靠性,但人具有一定的缺陷。但試想一下,普通的C/S架構軟件,頂多上千個Client同時連接,而B/S架構的網站,十萬人同時在線也是很平常的事兒。如果十萬個客戶端和服務器一直保持連接狀態,那服務器如何滿足承載呢?
這就衍生出了http協議。基于TCP的可靠性連接。通俗點說,就是在請求之后,服務器端立即關閉連接、釋放資源。這樣既保證了資源可用,也吸取了TCP的可靠性的優點。
正因為這點,所以大家通常說http協議是“無狀態”的,也就是“服務器不知道你客戶端干了啥”,其實很大程度上是基于性能考慮的。以至于后來有了session之類的玩意。
實戰準備工作:
在監視網絡方面,windows平臺上有一款叫做Sniffer的優秀軟件,這也是很多“黑客”經常使用的嗅探工具。 在研究http協議時,推薦大家使用一款
叫作httpwatch的工具。(遺憾的是,該工具是收費的。該咋辦就咋辦,你懂的)。安裝完成后,可以在IE瀏覽器的tools中直接打開(目前也支持firefox)。如圖所示:

點擊Record,就可以開始監視并記錄http消息了。stop、Clear等等按鈕的功能,這里就不一一介紹了。拿實例來說話,下面就是我記錄訪問main.aspx頁面的時候記錄的,能夠清晰的看到http報文消息的詳細信息,如圖:

學習http協議,主要需要了解http的請求和響應(當然,還有get、post等請求方式,狀態碼、URI、MIME等)
首先看看http請求消息(就是瀏覽器丟給服務器的):
一個http請求代表客戶端瀏覽器向服務器發送的數據。一個完整的http請求消息,包含一個請求行,若干個消息頭(請求頭),換行,實體內容
請求行:描述客戶端的請求方式、請求資源的名稱、http協議的版本號。 例如: GET/BOOK/JAVA.HTML HTTP/1.1
請求頭(消息頭)包含(客戶機請求的服務器主機名,客戶機的環境信息等):
Accept:用于告訴服務器,客戶機支持的數據類型 (例如:Accept:text/html,image/*)
Accept-Charset:用于告訴服務器,客戶機采用的編碼格式
Accept-Encoding:用于告訴服務器,客戶機支持的數據壓縮格式
Accept-Language:客戶機語言環境
Host:客戶機通過這個服務器,想訪問的主機名
If-Modified-Since:客戶機通過這個頭告訴服務器,資源的緩存時間
Referer:客戶機通過這個頭告訴服務器,它(客戶端)是從哪個資源來訪問服務器的(防盜鏈)
User-Agent:客戶機通過這個頭告訴服務器,客戶機的軟件環境(操作系統,瀏覽器版本等)
Cookie:客戶機通過這個頭,將Coockie信息帶給服務器
Connection:告訴服務器,請求完成后,是否保持連接
Date:告訴服務器,當前請求的時間
(換行)
實體內容:
就是指瀏覽器端通過http協議發送給服務器的實體數據。例如:name=dylan&id=110
(get請求時,通過url傳給服務器的值。post請求時,通過表單發送給服務器的值)
再看看HTTP響應消息(服務器返回給瀏覽器的):
一個http響應代表服務器端向客戶端回送的數據,它包括:
一個狀態行,若干個消息頭,以及實體內容
響應頭(消息頭)包含:
Location:這個頭配合302狀態嗎,用于告訴客戶端找誰
Server:服務器通過這個頭,告訴瀏覽器服務器的類型
Content-Encoding:告訴瀏覽器,服務器的數據壓縮格式
Content-Length:告訴瀏覽器,回送數據的長度
Content-Type:告訴瀏覽器,回送數據的類型
Last-Modified:告訴瀏覽器當前資源緩存時間
Refresh:告訴瀏覽器,隔多長時間刷新
Content- Disposition:告訴瀏覽器以下載的方式打開數據。例如: context.Response.AddHeader("Content-Disposition","attachment:filename=aa.jpg"); context.Response.WriteFile("aa.jpg");
Transfer-Encoding:告訴瀏覽器,傳送數據的編碼格式
ETag:緩存相關的頭(可以做到實時更新)
Expries:告訴瀏覽器回送的資源緩存多長時間。如果是-1或者0,表示不緩存
Cache-Control:控制瀏覽器不要緩存數據 no-cache
Pragma:控制瀏覽器不要緩存數據 no-cache
Connection:響應完成后,是否斷開連接。 close/Keep-Alive
Date:告訴瀏覽器,服務器響應時間
理解了以上的http請求消息和響應消息,相信你對于http協議已經理解得足夠深刻了。關于http協議的更多具體細節,可以參照http RFC文檔。
大致步驟就是:瀏覽器先向服務器發送請求,服務器接收到請求后,做相應的處理,然后封裝好響應報文,再回送給瀏覽器。瀏覽器拿到響應報文后,再通過 瀏覽器引擎去渲染網頁,解析DOM樹,javascript引擎解析并執行腳本操作,插件去干插件該干的事兒...關于瀏覽器渲染、解析的原理,可以參考 http://kb.cnblogs.com/page/129756/
說白了,所謂web的本質,無非是:請求/處理/響應 ,任何的web服務器,任何的服務端編程語言,都沒法脫離這個本質。 而瀏覽器端解析html、圖片等靜態內容,呈現給用戶,腳本引擎執行腳本代碼,完成腳本代碼要做的事兒(例如dom操作,css屬性更改,發送ajax請 求等等)。
筆者淺淺的認為,其實瀏覽器就是一種特殊的Client,而B/S架構也是一種特殊的C/S架構。這里值得一提的是,不同的web服務器和編程語 言,又是如何接收用戶http請求。如何處理,如何響應的呢?筆者拿熟悉的ASP.NET為例,通過反編譯工具查看源代碼(微軟這家伙實在封裝的太好了) 從底層進行了剖析,如圖:

由于篇幅有限,無法再繼續將asp.net、iis web服務器的細節及底層實現再做進一步地進行剖析了。因為微軟的asp.net技術體系實在龐大,而且很復雜。有時間筆者會繼續更新系列文章,歡迎讀者繼續關注。
posted @
2012-02-14 21:56 todayx.org 閱讀(279) |
評論 (0) |
編輯 收藏 2012世界末日暨環境保護主題站,關注國內外最新2012世界末日信息,旨在通過關注,收集,展示2012世界末日相關資料的方式,喚醒并提高人們保護環境與愛護地球的意識,引導人類保護環境.
最近一直比較忙,所以一連幾天都沒有更新。本來覺得沒什么,后來有幾個網友都問起為什么沒有更新,才覺得大家對我的博客還是比較關心的。于是覺得挺對不起大家的。終于到了周末,昨天晚上忙乎了一晚上,寫了個Swing演示,今天把它共享出來,算是彌補。
收到一個朋友的郵件說如何在Swing中實現組件的動畫效果,就像JIDE的那些組件一樣。的確Swing框架的靈活性和可擴展性,使得它非常適合做這樣Makeover工作。我簡單總結一了以下,這種組件不外乎要有以下三種元素:
1.外觀華麗。這包括使用漸變色,線條和字體反走樣,圖標設計漂亮搶眼,界面變化要柔和等等。但要避免設計太花哨,給人華而不實的感覺。原則上避免顏色太 碎,圖標應以簡潔為主,不可濫用圖片等。技術上沒有多大要求,主要是美工,你需要掌握各種做圖工具,自己最好有好的審美和設計能力。
2.動畫效果。組件行為變化要柔和化,盡量使用動畫效果,如淡入淡出、滾動彈出等等。技術上最常用的方法是使用javax.swing.Timer。為什 么要使用javax.swing.Timer,這是因為javax.swing.Timer觸發的事件都在EDT上執行,是線程安全的。除此外還需掌握 Java 2D的常用接口及圖像處理的常見技巧。
3.空間布局。這種組件空間布局的特點是立體、動態、拖拽式的。這和人的認知能力有關。人類認知的特點是具體到抽象。二維、靜態和鍵盤式操作對普通用戶來 說太過抽象和專業化,需要一定的輔助學習才能理解的。而三維、動態、拖拽式操作更貼近于感性的認知范疇。因此這類組件經常有浮動式窗口、組件布局動態變化 及拖拽式操作等特征。實現技術包括布局管理器(LayoutManager)、Swing組件分層結構、Swing事件體系結構以及DnD接口等。
美工對于java程序員來說可能比較缺乏,但是華麗外觀不僅僅是美工技術,這包括一些宏觀設計原則。java程序員完全可以通過掌握這些方針原則來提高自 己的設計水平。前面文章介紹那個《Swing外觀設計方針》就是一本這樣的書。至于美工,我覺得如果你有美術天分,那就要充分利用;如果沒有,那么你可以 模仿,熟悉幾種的圖形工具就完全可以不用自己的畫圖做出比較漂亮的圖標、圖片(當然沒有考慮版權問題)。我就是后者,但是我發現我平時只需要PrScrn 鍵(抓圖)、Paint(Windows 畫圖工具,切圖、剪裁、轉換格式)、PowerPoint/OpenOffice Imprise(畫圖)、Google Image(搜索圖片)就已經足夠了。其他所需的技術就需要你掌握Swing和Java 2D方方面面的技術了。當然復雜的組件不僅僅是靠掌握這些技術能解決的,可能你還需要能比較好地熟悉各種編程模式。
這個朋友特別提到Windows上的折疊式操作面板,他說:
另外,我對JIDE中兩個東西很感興趣,一個是CollapsiblePanel(Windows Explorer左邊的常見任務),點擊后折疊、展開子面板,而且是動畫效果
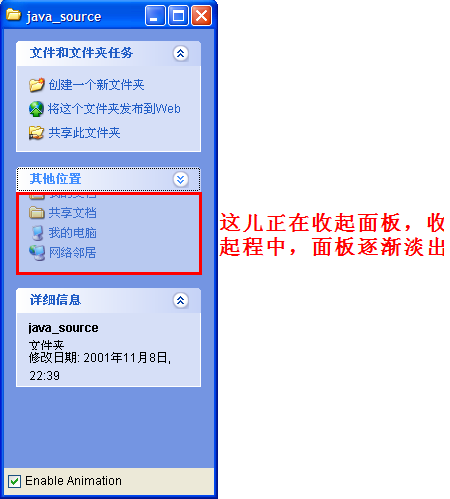
因此昨晚就特地試了一下。雖然以前就大概明白使用Timer和布局管理器以及圖像處理就可以實現這些東西,但一直沒有做。昨晚的實驗還是很成功的,大概花 了兩個小時就實現了這個面板。工作過程大概就是分解這些面板組件、解析那部分需要動畫、應該在哪兒觸發何種事件。另外就是編寫這些組件,不斷調試。這個過 程的大部分時間都被效果調整占去了。你需要不斷的運行程序,抓取屏幕,然后將它帖到Paint中,然后放大,然后和Windows上的抓圖比較,包括大 小、尺寸、顏色、字體、微觀變化等等。最后算是基本實現了Windows這個折疊式的面板組件。下面的是我的演示程序的一個抓圖:

這個是淡出淡入動畫效果:

下面的Enable Animation的JCheckBox可以設置是否使用動畫效果。選擇上折疊和展開就具有動畫效果。
這個組件的類名是dyno.swing.beans.FolderPane。使用比較簡單:
FolderPane fp=new FolderPane();//設置是否有動畫效果,缺省沒有
fp.setAnimated(true);//添加子面板
fp.addFolder("文件和文件夾任務", getFileFolderPane());
fp.addFolder("其他位置", getOtherPlacePane());
fp.addFolder("詳細信息", getDetailsPane());
add(fp, BorderLayout.CENTER); |
主要接口有兩個:
設置是否要動畫效果
public void setAnimated(boolean b)
添加面板,title是面板標題文字,content是應用程序組件
public void addFolder(String title, JComponent content) |
這個演示的源碼可以從這兒下載,是一個NetBeans工程。編譯之后,直接雙擊foldered_pane.jar既可觀看效果。源代碼中有詳細的注解。 更新:剛剛修改了一下,現在可以支持JScrollPane,即能放到JScrollPane,并能在動畫時動態的更新JScrollPane狀態。

posted @
2012-02-08 21:26 todayx.org 閱讀(365) |
評論 (2) |
編輯 收藏程序員到底可以做多久,這個職業是否真的到35歲就終止?帶著這個問題,和所有有此疑問和憂慮的朋友們探討。先說說我自己的觀點吧。要回答這個問題,我們首先要回答另外幾個問題。
1. 人得學習能力是否會隨著年齡的增長而變差?
可能是如此,我兩歲的兒子一首唐詩說兩遍就記住了,很長繞口的兒歌《小熊過橋》幾乎能一字不差的唱完;而我是顯然辦不到的。不過發現一個事實,就是人的學 習能力不僅僅是靠記憶能力,跟邏輯思維能力,還有人的經驗也有很大的關系;我們每個人也許都發現,你如果只是個優秀的Java程序員,如果要你去維護一 個.net的系統,不出兩個月, 你馬上就是一個.net專家。因為你知道相關的知識怎么學習,知道如何才能最快定位問題的一般方法。我個人是個完全不懂php得人,結果被強拉過去搞了個 php的項目,結果被認為是php expert! 所以我的最終答案是,人得記憶力更年齡成反比,但是學習能力跟年齡成正比。
2. 人的年齡越大,精力會跟不上程序員這樣高強度的工作嗎?
我的答案也是否定的。首先這是個偽命題,沒有哪件事情是輕松的;你覺得別人比你輕松,那也只是你覺得而已。大體上個人的回報跟付出是成正比的。其實隨著你 的年齡增長,知識積累越多,經驗越豐富,你的工作效率會更高。5年前你修一個Bug要一個星期,現在也許10分鐘就夠了,并且是又快又好。難道不是這樣 嗎?所以你的工作強度事實上會變得更低,因為你的效率更高,你會有更多時間喝咖啡,也會遭你鄰桌的同事低語“這家伙每天無所事事,咋工資比我高那么多?” 因為你的10分鐘就抵別人的一個星期。
3. 人的年齡越大,就沒有激情學習新知識了嗎?
對有些人是,對有些人不是。計算機科學日新月異,確實更新相當快。你真的會跟不上腳步嗎?可能會,如果你自己不學習。但我一定要亦步亦趨嗎?也不見得,無 論如何,即便是軟件開發,也還是有方向,有領域,你只要更上你需要更上的節奏就夠了。今天請我的一個兄弟給我講了下Struts應用,就是給我搞個最小化 的Struts項目,包含所有Struct的重要知識點,然后搬個椅子坐我旁邊,花上半個小時跟我講解;我現在儼然Struts專家了,不信,我跟你講講 看? 呵呵,開玩笑了。
如果我們覺得每天吃飯不是件枯燥無趣的事,我們應該也不太會拒絕不斷學習;如果我們一定會因為自然規律而失去某些優勢,記得你其實有更多的優勢可以彌補;最重要的是,做你喜歡的事,做你能做的事情。
正月十五,明月高懸;祝福各位龍圖大展!
posted @
2012-02-07 13:46 todayx.org 閱讀(596) |
評論 (0) |
編輯 收藏--核心類主要有:
org.jfree.chart.JFreeChart :圖表對象,任何類型的圖表的最終表現形式都是在該對象進行一些屬性的定制。JFreeChart引擎本身提供了一個工廠類用于創建不同類型的圖表對象
org.jfree.data.category.XXXDataSet: 數據集對象,用于提供顯示圖表所用的數據。根據不同類型的圖表對應著很多類型的數據集對象類
org.jfree.chart.plot.XXXPlot :圖表區域對象,基本上這個對象決定著什么樣式的圖表,創建該對象的時候需要Axis、Renderer以及數據集對象的支持
org.jfree.chart.axis.XXXAxis :用于處理圖表的兩個軸:縱軸和橫軸
org.jfree.chart.render.XXXRender :負責如何顯示一個圖表對象
org.jfree.chart.urls.XXXURLGenerator: 用于生成Web圖表中每個項目的鼠標點擊鏈接
XXXXXToolTipGenerator: 用于生成圖象的幫助提示,不同類型圖表對應不同類型的工具提示類
JFreeChart類:
void setAntiAlias(boolean flag) 字體模糊邊界
void setBackgroundImage(Image image) 背景圖片
void setBackgroundImageAlignment(int alignment) 背景圖片對齊方式(參數常量在org.jfree.ui.Align類中定義)
void setBackgroundImageAlpha(float alpha) 背景圖片透明度(0.0~1.0)
void setBackgroundPaint(Paint paint) 背景色
void setBorderPaint(Paint paint) 邊界線條顏色
void setBorderStroke(Stroke stroke) 邊界線條筆觸
void setBorderVisible(boolean visible) 邊界線條是否可見
-----------------------------------------------------------------------------------------------------------
TextTitle類:
void setFont(Font font) 標題字體
void setPaint(Paint paint) 標題字體顏色
void setText(String text) 標題內容
-----------------------------------------------------------------------------------------------------------
StandardLegend(Legend)類:
void setBackgroundPaint(Paint paint) 圖示背景色
void setTitle(String title) 圖示標題內容
void setTitleFont(Font font) 圖示標題字體
void setBoundingBoxArcWidth(int arcWidth) 圖示邊界圓角寬
void setBoundingBoxArcHeight(int arcHeight) 圖示邊界圓角高
void setOutlinePaint(Paint paint) 圖示邊界線條顏色
void setOutlineStroke(Stroke stroke) 圖示邊界線條筆觸
void setDisplaySeriesLines(boolean flag) 圖示項是否顯示橫線(折線圖有效)
void setDisplaySeriesShapes(boolean flag) 圖示項是否顯示形狀(折線圖有效)
void setItemFont(Font font) 圖示項字體
void setItemPaint(Paint paint) 圖示項字體顏色
void setAnchor(int anchor) 圖示在圖表中的顯示位置(參數常量在Legend類中定義)
-----------------------------------------------------------------------------------------------------------
Axis類:
void setVisible(boolean flag) 坐標軸是否可見
void setAxisLinePaint(Paint paint) 坐標軸線條顏色(3D軸無效)
void setAxisLineStroke(Stroke stroke) 坐標軸線條筆觸(3D軸無效)
void setAxisLineVisible(boolean visible) 坐標軸線條是否可見(3D軸無效)
void setFixedDimension(double dimension) (用于復合表中對多坐標軸的設置)
void setLabel(String label) 坐標軸標題
void setLabelFont(Font font) 坐標軸標題字體
void setLabelPaint(Paint paint) 坐標軸標題顏色
void setLabelAngle(double angle) 坐標軸標題旋轉角度(縱坐標可以旋轉)
void setTickLabelFont(Font font) 坐標軸標尺值字體
void setTickLabelPaint(Paint paint) 坐標軸標尺值顏色
void setTickLabelsVisible(boolean flag) 坐標軸標尺值是否顯示
void setTickMarkPaint(Paint paint) 坐標軸標尺顏色
void setTickMarkStroke(Stroke stroke) 坐標軸標尺筆觸
void setTickMarksVisible(boolean flag) 坐標軸標尺是否顯示
ValueAxis(Axis)類:
void setAutoRange(boolean auto) 自動設置數據軸數據范圍
void setAutoRangeMinimumSize(double size) 自動設置數據軸數據范圍時數據范圍的最小跨度
void setAutoTickUnitSelection(boolean flag) 數據軸的數據標簽是否自動確定(默認為true)
void setFixedAutoRange(double length) 數據軸固定數據范圍(設置100的話就是顯示MAXVALUE到MAXVALUE-100那段數據范圍)
void setInverted(boolean flag) 數據軸是否反向(默認為false)
void setLowerMargin(double margin) 數據軸下(左)邊距
void setUpperMargin(double margin) 數據軸上(右)邊距
void setLowerBound(double min) 數據軸上的顯示最小值
void setUpperBound(double max) 數據軸上的顯示最大值
void setPositiveArrowVisible(boolean visible) 是否顯示正向箭頭(3D軸無效)
void setNegativeArrowVisible(boolean visible) 是否顯示反向箭頭(3D軸無效)
void setVerticalTickLabels(boolean flag) 數據軸數據標簽是否旋轉到垂直
void setStandardTickUnits(TickUnitSource source) 數據軸的數據標簽(可以只顯示整數標簽,需要將AutoTickUnitSelection設false)
NumberAxis(ValueAxis)類:
void setAutoRangeIncludesZero(boolean flag) 是否強制在自動選擇的數據范圍中包含0
void setAutoRangeStickyZero(boolean flag) 是否強制在整個數據軸中包含0,即使0不在數據范圍中
void setNumberFormatOverride(NumberFormat formatter) 數據軸數據標簽的顯示格式
void setTickUnit(NumberTickUnit unit) 數據軸的數據標簽(需要將AutoTickUnitSelection設false)
DateAxis(ValueAxis)類:
void setMaximumDate(Date maximumDate) 日期軸上的最小日期
void setMinimumDate(Date minimumDate) 日期軸上的最大日期
void setRange(Date lower,Date upper) 日期軸范圍
void setDateFormatOverride(DateFormat formatter) 日期軸日期標簽的顯示格式
void setTickUnit(DateTickUnit unit) 日期軸的日期標簽(需要將AutoTickUnitSelection設false)
void setTickMarkPosition(DateTickMarkPosition position) 日期標簽位置(參數常量在org.jfree.chart.axis.DateTickMarkPosition類中定義)
CategoryAxis(Axis)類:
void setCategoryMargin(double margin) 分類軸邊距
void setLowerMargin(double margin) 分類軸下(左)邊距
void setUpperMargin(double margin) 分類軸上(右)邊距
void setVerticalCategoryLabels(boolean flag) 分類軸標題是否旋轉到垂直
void setMaxCategoryLabelWidthRatio(float ratio) 分類軸分類標簽的最大寬度
-----------------------------------------------------------------------------------------------------------
Plot類:
void setBackgroundImage(Image image) 數據區的背景圖片
void setBackgroundImageAlignment(int alignment) 數據區的背景圖片對齊方式(參數常量在org.jfree.ui.Align類中定義)
void setBackgroundPaint(Paint paint) 數據區的背景圖片背景色
void setBackgroundAlpha(float alpha) 數據區的背景透明度(0.0~1.0)
void setForegroundAlpha(float alpha) 數據區的前景透明度(0.0~1.0)
void setDataAreaRatio(double ratio) 數據區占整個圖表區的百分比
void setOutLinePaint(Paint paint) 數據區的邊界線條顏色
void setOutLineStroke(Stroke stroke) 數據區的邊界線條筆觸
void setNoDataMessage(String message) 沒有數據時顯示的消息
void setNoDataMessageFont(Font font) 沒有數據時顯示的消息字體
void setNoDataMessagePaint(Paint paint) 沒有數據時顯示的消息顏色
CategoryPlot(Plot)類:
void setDataset(CategoryDataset dataset) 數據區的2維數據表
void setColumnRenderingOrder(SortOrder order) 數據分類的排序方式
void setAxisOffset(Spacer offset) 坐標軸到數據區的間距
void setOrientation(PlotOrientation orientation) 數據區的方向(PlotOrientation.HORIZONTAL或PlotOrientation.VERTICAL)
void setDomainAxis(CategoryAxis axis) 數據區的分類軸
void setDomainAxisLocation(AxisLocation location) 分類軸的位置(參數常量在org.jfree.chart.axis.AxisLocation類中定義)
void setDomainGridlinesVisible(boolean visible) 分類軸網格是否可見
void setDomainGridlinePaint(Paint paint) 分類軸網格線條顏色
void setDomainGridlineStroke(Stroke stroke) 分類軸網格線條筆觸
void setRangeAxis(ValueAxis axis) 數據區的數據軸
void setRangeAxisLocation(AxisLocation location) 數據軸的位置(參數常量在org.jfree.chart.axis.AxisLocation類中定義)
void setRangeGridlinesVisible(boolean visible) 數據軸網格是否可見
void setRangeGridlinePaint(Paint paint) 數據軸網格線條顏色
void setRangeGridlineStroke(Stroke stroke) 數據軸網格線條筆觸
void setRenderer(CategoryItemRenderer renderer) 數據區的表示者(詳見Renderer組)
void addAnnotation(CategoryAnnotation annotation) 給數據區加一個注釋
void addRangeMarker(Marker marker,Layer layer) 給數據區加一個數值范圍區域
PiePlot(Plot)類:
void setDataset(PieDataset dataset) 數據區的1維數據表
void setIgnoreNullValues(boolean flag) 忽略無值的分類
void setCircular(boolean flag) 餅圖是否一定是正圓
void setStartAngle(double angle) 餅圖的初始角度
void setDirection(Rotation direction) 餅圖的旋轉方向
void setExplodePercent(int section,double percent) 抽取的那塊(1維數據表的分類下標)以及抽取出來的距離(0.0~1.0),3D餅圖無效
void setLabelBackgroundPaint(Paint paint) 分類標簽的底色
void setLabelFont(Font font) 分類標簽的字體
void setLabelPaint(Paint paint) 分類標簽的字體顏色
void setLabelLinkMargin(double margin) 分類標簽與圖的連接線邊距
void setLabelLinkPaint(Paint paint) 分類標簽與圖的連接線顏色
void setLabelLinkStroke(Stroke stroke) 分類標簽與圖的連接線筆觸
void setLabelOutlinePaint(Paint paint) 分類標簽邊框顏色
void setLabelOutlineStroke(Paint paint) 分類標簽邊框筆觸
void setLabelShadowPaint(Paint paint) 分類標簽陰影顏色
void setMaximumLabelWidth(double width) 分類標簽的最大長度(0.0~1.0)
void setPieIndex(int index) 餅圖的索引(復合餅圖中用到)
void setPieIndex(int index) 餅圖的索引(復合餅圖中用到)
void setSectionOutlinePaint(int section,Paint paint) 指定分類餅的邊框顏色
void setSectionOutlineStroke(int section,Stroke stroke) 指定分類餅的邊框筆觸
void setSectionPaint(int section,Paint paint) 指定分類餅的顏色
void setShadowPaint(Paint paint) 餅圖的陰影顏色
void setShadowXOffset(double offset) 餅圖的陰影相對圖的水平偏移
void setShadowYOffset(double offset) 餅圖的陰影相對圖的垂直偏移
void setLabelGenerator(PieSectionLabelGenerator generator) 分類標簽的格式,設置成null則整個標簽包括連接線都不顯示
void setToolTipGenerator(PieToolTipGenerator generator) MAP中鼠標移上的顯示格式
void setURLGenerator(PieURLGenerator generator) MAP中鉆取鏈接格式
PiePlot3D(PiePlot)類:
void setDepthFactor(double factor) 3D餅圖的Z軸高度(0.0~1.0)
MultiplePiePlot(Plot)類:
void setLimit(double limit) 每個餅圖之間的數據關聯(詳細比較復雜)
void setPieChart(JFreeChart pieChart) 每個餅圖的顯示方式(見JFreeChart類個PiePlot類)
-----------------------------------------------------------------------------------------------------------
AbstractRenderer類:
void setItemLabelAnchorOffset(double offset) 數據標簽的與數據點的偏移
void setItemLabelsVisible(boolean visible) 數據標簽是否可見
void setItemLabelFont(Font font) 數據標簽的字體
void setItemLabelPaint(Paint paint) 數據標簽的字體顏色
void setItemLabelPosition(ItemLabelPosition position) 數據標簽位置
void setPositiveItemLabelPosition(ItemLabelPosition position) 正數標簽位置
void setNegativeItemLabelPosition(ItemLabelPosition position) 負數標簽位置
void setOutLinePaint(Paint paint) 圖形邊框的線條顏色
void setOutLineStroke(Stroke stroke) 圖形邊框的線條筆觸
void setPaint(Paint paint) 所有分類圖形的顏色
void setShape(Shape shape) 所有分類圖形的形狀(如折線圖的點)
void setStroke(Stroke stroke) 所有分類圖形的筆觸(如折線圖的線)
void setSeriesItemLabelsVisible(int series,boolean visible) 指定分類的數據標簽是否可見
void setSeriesItemLabelFont(int series,Font font) 指定分類的數據標簽的字體
void setSeriesItemLabelPaint(int series,Paint paint) 指定分類的數據標簽的字體顏色
void setSeriesItemLabelPosition(int series,ItemLabelPosition position) 數據標簽位置
void setSeriesPositiveItemLabelPosition(int series,ItemLabelPosition position) 正數標簽位置
void setSeriesNegativeItemLabelPosition(int series,ItemLabelPosition position) 負數標簽位置
void setSeriesOutLinePaint(int series,Paint paint) 指定分類的圖形邊框的線條顏色
void setSeriesOutLineStroke(int series,Stroke stroke) 指定分類的圖形邊框的線條筆觸
void setSeriesPaint(int series,Paint paint) 指定分類圖形的顏色
void setSeriesShape(int series,Shape shape) 指定分類圖形的形狀(如折線圖的點)
void setSeriesStroke(int series,Stroke stroke) 指定分類圖形的筆觸(如折線圖的線)
AbstractCategoryItemRenderer(AbstractRenderer)類:
void setLabelGenerator(CategoryLabelGenerator generator) 數據標簽的格式
void setToolTipGenerator(CategoryToolTipGenerator generator) MAP中鼠標移上的顯示格式
void setItemURLGenerator(CategoryURLGenerator generator) MAP中鉆取鏈接格式
void setSeriesLabelGenerator(int series,CategoryLabelGenerator generator) 指定分類的數據標簽的格式
void setSeriesToolTipGenerator(int series,CategoryToolTipGenerator generator) 指定分類的MAP中鼠標移上的顯示格式
void setSeriesItemURLGenerator(int series,CategoryURLGenerator generator) 指定分類的MAP中鉆取鏈接格式
BarRenderer(AbstractCategoryItemRenderer)類:
void setDrawBarOutline(boolean draw) 是否畫圖形邊框
void setItemMargin(double percent) 每個BAR之間的間隔
void setMaxBarWidth(double percent) 每個BAR的最大寬度
void setMinimumBarLength(double min) 最短的BAR長度,避免數值太小而顯示不出
void setPositiveItemLabelPositionFallback(ItemLabelPosition position) 無法在BAR中顯示的正數標簽位置
void setNegativeItemLabelPositionFallback(ItemLabelPosition position) 無法在BAR中顯示的負數標簽位置
BarRenderer3D(BarRenderer)類:
void setWallPaint(Paint paint) 3D坐標軸的墻體顏色
StackedBarRenderer(BarRenderer)類:
沒有特殊的設置
StackedBarRenderer3D(BarRenderer3D)類:
沒有特殊的設置
GroupedStackedBarRenderer(StackedBarRenderer)類:
void setSeriesToGroupMap(KeyToGroupMap map) 將分類自由的映射成若干個組(KeyToGroupMap.mapKeyToGroup(series,group))
LayeredBarRenderer(BarRenderer)類:
void setSeriesBarWidth(int series,double width) 設定每個分類的寬度(注意設置不要使某分類被覆蓋)
WaterfallBarRenderer(BarRenderer)類:
void setFirstBarPaint(Paint paint) 第一個柱圖的顏色
void setLastBarPaint(Paint paint) 最后一個柱圖的顏色
void setPositiveBarPaint(Paint paint) 正值柱圖的顏色
void setNegativeBarPaint(Paint paint) 負值柱圖的顏色
IntervalBarRenderer(BarRenderer)類:
需要傳IntervalCategoryDataset作為數據源
GanttBarRenderer(IntervalBarRenderer)類:
void setCompletePaint(Paint paint) 完成進度顏色
void setIncompletePaint(Paint paint) 未完成進度顏色
void setStartPercent(double percent) 設置進度條在整條中的起始位置(0.0~1.0)
void setEndPercent(double percent) 設置進度條在整條中的結束位置(0.0~1.0)
StatisticBarRenderer(BarRenderer)類:
需要傳StatisticCategoryDataset作為數據源
LineAndShapeRenderer(AbstractCategoryItemRenderer)類:
void setDrawLines(boolean draw) 是否折線的數據點之間用線連
void setDrawShapes(boolean draw) 是否折線的數據點根據分類使用不同的形狀
void setShapesFilled(boolean filled) 所有分類是否填充數據點圖形
void setSeriesShapesFilled(int series,boolean filled) 指定分類是否填充數據點圖形
void setUseFillPaintForShapeOutline(boolean use) 指定是否填充數據點的Paint也被用于畫數據點形狀的邊框
LevelRenderer(AbstractCategoryItemRenderer)類:
void setItemMargin(double percent) 每個分類之間的間隔
void setMaxItemWidth(double percent) 每個分類的最大寬度
CategoryStepRenderer(AbstractCategoryItemRenderer)類:
void setStagger(boolean shouldStagger) 不同分類的圖是否交錯
MinMaxCategoryRenderer(AbstractCategoryItemRenderer)類:
void setDrawLines(boolean drawLines) 是否在每個分類線間畫連接線
void setGroupPaint(Paint groupPaint) 一組圖形連接線的顏色
void setGroupStroke(Stroke groupStroke) 一組圖形連接線的筆觸
void setMaxIcon(Icon maxIcon) 最大值的ICON
void setMinIcon(Icon minIcon) 最小值的ICON
void setObjectIcon(Icon objectIcon) 所有值的ICON
AreaRender(AbstractCategoryItemRenderer)類:
沒有特殊的設置
StackedAreaRender(AreaRender)類:
沒有特殊的設置
posted @
2012-02-07 13:46 todayx.org 閱讀(262) |
評論 (0) |
編輯 收藏
摘要: 歷史上的今天回顧歷史的今天,歷史就像生活的一面鏡子;可以了解歷史的這一天發生的事件;借古可以鑒今;歷史是不能忘記的.要記住歷史的每一天http://www.todayx.org/每天在寫Java程序, 其實里面有一些細節大家可能沒怎么注意, 這不, 有人總結了一個我們編程中常見的問題. 雖然一般沒有什么大問題, 但是最好別這樣做. 另外這里提到的很多問題其實可以通過Findbugs( http:/...
閱讀全文
posted @
2012-02-05 22:56 todayx.org 閱讀(232) |
評論 (0) |
編輯 收藏今天我不談抱負理想,也不談具體的技術,我來談幾個看法上的典型錯誤。下面的這些問題都是我曾經遇到,或者是我的朋友們遇到過的問題,這些都是我個人的理解,希望對大家有幫助。
關于設計模式、設計原則
有人認為,熟悉了設計模式、設計原則,就學會了設計。其實,設計模式和設計原則,只是前人根據設計實踐做的總結和提煉,設計,歸根到底是要解決問題的,把具體問題的解決辦法,經過一定的抽象,變成程序員的語言。
我見過一些人,他們知識淵博、見識廣博,甚至理論可以給你闡述得冠冕堂皇,但是到了實際需要解決問題的時候,他們卻拿不出巧妙的、優雅的辦法,這是典型的象牙塔人。
另一方面,也有一些人看不起學習設計模式的人,他們覺得他們已經掌握了軟件設計的奧義,這些對他們來說是毫無意義的詞匯,對此大可以一笑置之。
有時候我們反而被設計模式或設計原則粗暴的掌握束縛了手腳,譬如我遇到這樣一件事情,某位努力的程序員,設計的代碼用遍了組合(例如把User對象 放置到Administrator里面),我好奇地問,有一些類和對象之間的關系很明顯符合繼承的特征,為什么不愿意用它?他說,設計原則告訴我們,要多 用組合,少用繼承。我想,對這些優秀的模式、原則、方法論,如果不能透徹地掌握,不能根據實際場景合適地運用,是不是反而不如對其不了解來的好呢?
關于多種計算機語言的學習
有人覺得學習一種語言就可以了,學習那么多語言沒有必要。事實上,多掌握一門合適的計算機語言不僅僅是多掌握一種謀生的工具,如果一種新的語言能夠很大程度上改變你對編程、對設計的看法,那么興許它就值得你去學習。
譬如C語言,可以培養嚴謹的思維;譬如動態語言,它可以幫助程序員更好地做面向對象的coding;譬如函數式語言,它在工業生產、運算領域有著不可替代的作用。
當然話說回來,所謂術業有專攻,對于某一門計算機語言(包括該語言所需的運行時環境、其中的編譯或解釋的原理)深入的掌握,是很有必要的。
另外,我們時常看到諸多計算機語言孰優孰劣的爭論,計算機語言歸根到底是一種工具,工具是隨著時代發展升級和變更的,單純的優劣爭論沒有太大意義。
關于英語
中國人為什么要學英語,程序員為什么要學英語,當我把那些方法名、變量名全部取成拼音,一樣可以,誰下的這個破規定?
遺憾的是,諸多學習材料、論文、技術資料(尤其是一些剛出不久的技術),都是英語的;另一方面,國際標準、程序員交流的通用方式,都是英文的,我想肯定很難想象,那些有名的framework、lib的源碼,如果用拼音來寫變量名會成什么樣子。
所以,如果你的英語不好(至少讀寫不好),就不要給自己找太借口,英語是一個掌握其他工具的工具,除非你堅信,中文很快就會在計算機界變成世界第一通用的語言。
關于算法
算法有多重要,這一件事的爭議一直都很大。
軟件歸根到底是用來解決問題的,提到算法就不能不提到數學(這也是為什么很多軟件領域的大師都具備相當的數學背景),對于解決問題,這里可以簡單歸納成兩步:
(1)把實際的問題抽象成簡化的數學模型
(2)用算法去解決這個數學問題
算法,在這里應該是一個廣義的概念(這里的算法并不僅僅指大學里學習的狹義的具體算法),算法是解決上述數學問題的辦法。如果工作中你并未意識到它的存在,那只是說明,你抽象出的數學模型比較簡單,解決這個模型的辦法也很簡單,或者有現成的方式可以模仿,或者有現成的框架幫你完成了,以至于你不去關注它、在乎它。
如果你做的事情是充滿創新意義的,是別人從沒有做過的,這時候算法興許就成了決定你成敗的因素。
在當前中國的環境下,視野廣闊和經歷豐富的人很好找,但是企業要招到具備上述兩點能力來解決問題的人,其實是非常困難的。
關于經驗
唯經驗論者的人有很多,他們認為,在軟件企業的職位、薪水、甚至決策能力,都取決于經驗,一個5年經驗的工程師,肯定比3年經驗的工程師能找到更好的飯碗:
“我是老員工,我工作5年了,憑什么工作3年的他薪水比我高那么多”
實際上,很多因素,包括領域積累(這是業務上的,例如互聯網領域、傳統軟件領域,這和所謂的純技術沒有直接關系)、視野、承受壓力的能力等等往往都 在很大程度上取決于“經驗”的積累,但是,這并不是絕對的。有句話叫做“事業一半是干出來的,一半是總結出來的”,也確實有一些出色的程序員,他們善于總 結、善于觀察和積累,并且善于不斷地思考,這樣的程序員就是擁有更多優秀的經驗。
另一方面,程序員是要來解決問題的,經驗不能代替解決問題,有的人具備更優秀的解決問題的能力,他為什么就不能得到更優厚的薪水?
posted @
2012-02-05 22:53 todayx.org 閱讀(256) |
評論 (0) |
編輯 收藏越來越多人開始使用Java,但是他們大多數人沒有做好足夠的思想準備(沒有接受OO思想體系相關培訓),以致不能很好駕馭Java項目,甚至導致 開發后的Java系統性能緩慢甚至經常當機。很多人覺得這是Java復雜導致,其實根本原因在于:我們原先掌握的關于軟件知識(OO方面)不是太貧乏就是 不恰當,存在認識上和方法上的誤區。
軟件的生命性
軟件是有生命的,這可能是老調重彈了,但是因為它事關分層架構的原由,反復強調都不過分。
一個有生命的軟件首先必須有一個靈活可擴展的基礎架構,其次才是完整的功能。
目前很多人對軟件的思想還是焦點落在后者:完整的功能,覺得一個軟件功能越完整越好,其實關鍵還是架構的靈活性,就是前者,基礎架構好,功能添 加只是時間和工作量問題,但是如果架構不好,功能再完整,也不可能包括未來所有功能,軟件是有生命的,在未來成長時,更多功能需要加入,但是因為基礎架構 不靈活不能方便加入,死路一條。
正因為普通人對軟件存在短視誤區,對功能追求高于基礎架構,很多吃了虧的老程序員就此離開軟件行業,帶走寶貴的失敗經驗,新的盲目的年輕程序員 還是使用老的思維往前沖。其實很多國外免費開源框架如ofbiz compiere和slide也存在這方面陷阱,貌似非常符合胃口,其實類似國內那些幾百元的盜版軟件,擴展性以及持續發展性嚴重不足。
那么選擇現在一些流行的框架如Hibernate、Spring/Jdonframework是否就表示基礎架構打好了呢?其實還不盡然,關鍵還是取決于你如何使用這些框架來搭建你的業務系統。
存儲過程和復雜SQL語句的陷阱
首先談談存儲過程使用的誤區,使用存儲過程架構的人以為可以解決性能問題,其實它正是導致性能問題的罪魁禍首之一,打個比喻:如果一個人頻臨死亡,打一針可以讓其延長半年,但是打了這針,其他所有醫療方案就全部失效,請問你會使用這種短視方案嗎?
為什么這樣說呢?如果存儲過程都封裝了業務過程,那么運行負載都集中在數據庫端,要中間J2EE應用服務器干什么?要中間服務器的分布式計算和 集群能力做什么?只能回到過去集中式數據庫主機時代。現在軟件都是面向互聯網的,不象過去那樣局限在一個小局域網,多用戶并發訪問量都是無法確定和衡量, 依靠一臺數據庫主機顯然是不能夠承受這樣惡劣的用戶訪問環境的。(當然搞數據庫集群也只是五十步和百步的區別)。
從分層角度來看,現在三層架構:表現層、業務層和持久層,三個層次應該分割明顯,職責分明:持久層職責持久化保存業務模型對象,業務層對持久層 的調用只是幫助我們激活曾經委托其保管的對象,所以,不能因為持久層是保管者,我們就以其為核心圍繞其編程,除了要求其歸還模型對象外,還要求其做其做復 雜的業務組合。打個比喻:你在火車站將水果和盤子兩個對象委托保管處保管,過了兩天來取時,你還要求保管處將水果去皮切成塊,放在盤子里,做成水果盤給 你,合理嗎?
上面是談過分依賴持久層的一個現象,還有一個正好相反現象,持久層散發出來,開始擠占業務層,腐蝕業務層,整個業務層到處看見的是數據表的影子 (包括數據表的字段),而不是業務對象。這樣程序員應該多看看OO經典PoEAA.PoEAA 認為除了持久層,不應該在其他地方看到數據表或表字段名。
當然適量使用存儲過程,使用數據庫優點也是允許的。按照Evans DDD理論,可以將SQL語句和存儲過程作為規則Specification一部分。
Hibernate等ORM問題
現在使用Hibernate人也不少,但是他們發現Hibernate性能緩慢,所以尋求解決方案,其實并不是 Hibernate性能緩慢,而是我們使用方式發生錯誤:
"最近本人正搞一個項目,項目中我們用到了struts1.2+hibernate3, 由于關系復雜表和表之間的關系很多,在很多地方把lazy都設置false,所以導致數據一加載很慢,而且查詢一條數據更是非常的慢。"
Hibernate是一個基于對象模型持久化的技術,因此,關鍵是我們需要設計出高質量的對象模型,遵循DDD領域建模原則,減少降低關聯,通 過分層等有效辦法處理關聯。如果采取圍繞數據表進行設計編程,加上表之間關系復雜(沒有科學方法處理、偵察或減少這些關系),必然導致 系統運行緩慢,其實同樣問題也適用于當初對EJB的實體Bean的CMP抱怨上,實體Bean是Domain Model持久化,如果不首先設計Domain Model,而是設計數據表,和持久化工具設計目標背道而馳,能不出問題嗎?關于這個問題N多年就在Jdon爭論過。
這里同樣延伸出另外一個問題:數據庫設計問題,數據庫是否需要在項目開始設計?
如果我們進行數據庫設計,那么就產生了一系列問題:當我們使用Hibernate實現持久保存時,必須考慮事先設計好的數據庫表結構以及他們的關系如何和業務對象實現映射,這實際上是非常難實現的,這也是很多人覺得使用ORM框架棘手根本原因所在。
當然,也有腦力相當發達的人可以實現,但是這種圍繞數據庫實現映射的結果必然扭曲業務對象,這類似于兩個板塊(數據表和業務對象)相撞,必然產 生地震,地震的結果是兩敗俱傷,軟的一方吃虧,業務對象是代碼,相當于數據表結構,屬于軟的一方,最后導致業務對象變成數據傳輸對象DTO, DTO滿天飛,性能和維護問題隨之而來。
領域建模解決了上述眾多不協調問題,特別是ORM痛苦使用問題,關于 ORM/Hibernate使用還是那句老話:如果你不掌握領域建模方法,那么就不要用Hibernate,對于這個層次的你:也許No ORM 更是一個簡單之道: No ORM: The simplest solution
Spring分層矛盾問題
Spring是以挑戰EJB面貌出現,其本身擁有的強大組件定制功能是優點,但是存在實戰的一些問題,Spring作為業務層框架,不支持業務層Session 功能。
具體舉例如下:當我們實現購物車之類業務功能時,需要將購物場合保存到 Session中,由于業務層沒有方便的Session支持,我們只得將購物車保存到 HttpSession,而HttpSession只有通過HttpRequest才能獲得,再因為在Spring業務層容器中是無法訪問到 HttpRequest這個對象的,所以,最后我們只能將"購物車保存到HttpSession"這個功能放在表現層中實現,而這個功能明顯應該屬于業務 層功能,這就導致我們的Java項目層次混亂,維護性差。 違背了使用Spring和分層架構最初目的。
領域驅動設計DDD
現在回到我們討論的重點上來,分層架構是我們使用Java的根本原因之一,域建模專家Eric Evans在他的"Domain Model Design"一書中開篇首先強調的是分層架構,整個DDD理論實際是告訴我們如何使用模型對象oo技術和分層架構來設計實現一個Java項目。
我們現在很多人知道Java項目基本有三層:表現層 業務層和持久層,當我們執著于討論各層框架如何選擇之時,實際上我們真正的項目開發工作還沒有開始,就是我們選定了某種框架的組合(如 Struts+Spring+Hibernate或Struts+EJB或Struts+ JdonFramework),我們還沒有意識到業務層工作還需要大量工作,DDD提供了在業務層中再劃分新的層次思想,如領域層和服務層,甚至再細分為 作業層、能力層、策略層等等。通過層次細化方式達到復雜軟件的松耦合。DDD提供了如何細分層次的方式
當我們將精力花費在架構技術層面的討論和研究上時,我們可能忘記以何種依據選擇這些架構技術?選擇標準是什么?領域驅動設計DDD 回答了這樣的問題,DDD會告訴你如果一個框架不能協助你實現分層架構,那就拋棄它,同時,DDD也指出選擇框架的考慮目的,使得你不會人云亦云,陷入復 雜的技術細節迷霧中,迷失了架構選擇的根本方向。
現在也有些人誤以為DDD是一種新的理論,其實DDD和設計模式一樣,不是一種新的理論,而是實戰經驗的總結,它將前人 使用面向模型設計的方法經驗提煉出來,供后來者學習,以便迅速找到駕馭我們軟件項目的根本之道。
posted @
2012-02-04 23:21 todayx.org 閱讀(185) |
評論 (0) |
編輯 收藏 其實寫這篇博客的想法在年前已經有了,但一直在猶豫要不要寫,一是因為寫出來肯定會有人罵的了,剛過完春節的,在自己地頭找罵,實在是晦氣;二是因為我對 行業趨勢的眼光向來不準,估計今天的想法也是十有八九會錯,錯了日后自己的看著也不爽。但是又覺得如果心里有想法,不記錄下來,思緒就飄遠了,年代久了之 后,都忘記自己曾經也有過“看法”,應該會為自己的庸碌后悔吧?所以還是寫了。寫了歸寫了,請各位看官往下讀之前,先整理好心情,做到:一是自己對世界有 自己的看法;二是認同別人的看法可以跟自己不同;三是對別人的看法跟自己不同時不要生氣因為氣的是你自己別人替不了。如果做到了這三點,再往下讀,因為下 文的觀點會很偏激、很有態度,我歡迎你留言討論、發表不同的見解,如果純粹是謾罵(或有很多臟詞),建議你自己開一篇博客或發到你的微博,不要評論本文, 因為我會刪除“純粹是謾罵(或有很多臟詞)”的評論。
ActionScript/MXML
其實就是說 Adobe Flash 平臺不值得進入。在 2011 年,Flash 終于能夠開發 iOS/Android 應用,再加上網頁游戲市場火爆,估計很多人會想要進入這個平臺。但我有不同的看法,列幾點理由:
1、 Adobe 是市場導向的,沒有技術領袖氣質。視頻網站興起后,Flash Player 的新版本就加強視頻播放;網頁游戲興起后,新版本就加強圖形渲染;移動設備開發興起后,新版本就是能夠運行在更多的平臺上。一直在跟隨,從來不能領導;選 擇 Flash 平臺就意味著你永遠都不能走在時代前緣,只能吃別人吃剩下的;選擇 Flash 平臺就意味著你最急切的需求無法滿足,比如最近他們都在忙著支持移動設備,我們做網頁游戲的希望他們加強實時性小數據包網絡傳輸的需求就根本沒有人理會。
2、 HTML5 出來以后,Adobe 這個本來也沒有多少技術人員的公司還分心去支持它,出把 swf 轉為 html+js+css 工具,出圖形化 html5+css3+js 編程的工具。它樂于革掉自己的命,因為它只是個賣工具的,支持 html5 就像是 photoshop 支持多一種圖像格式;但是程序員你呢,你被革命后你的未來在哪里,見過當年的“中年下崗工人”不?
3、從 ActionScript 3 發布之后,這門語言基本上沒有什么變化。你看從 Flash Player 9 發布 AS3 以來,連 C++、C 語言都出了新的標準,java/c# 這類有大公司支持的語言變化巨大,甚至 python 也出了 python 3,更別提 google 公司新出的 go 和 dart 兩門優秀的語言。AS3 作為 ECMAScript 的一種方言,現在 ECMA-262 都發布到 5.1 版本了,它仍然沒有想要跟進的樣子。
4、Flex SDK 類庫狗血地照抄了早期版本的 java 類庫的設計,連缺陷也照抄不誤。你有多少次為了截取 Array 的一部分元素而去看它的手冊的?這也就算了,還有一堆的 bugs。你知不知道 Application.application 是會變的?
5、 虛擬機方面,javascript 都有了 V8 引擎,而 AVM 還是那個 AVM,無數用戶抱怨它慢都沒有用的,優先級高的需求永遠是更能夠直接賺錢的特性。選擇 Flash 就好像你是一個賽車手選了一輛小馬力的車,雖然你彎道轉得很好,也從不撞車,但可能一輛大馬力的車還是從容地超越你。js 有了 V8 后開發出了 Node.js 從前端轉到后端,拓展了更加廣闊的應用領域,AS 在可以預見的未來,還是逃脫不了“寫點小動畫”的命運。
6、Stage 3D 不是救世主。不要忘記“low-level”這個定語,如果你直接使用 Stage 3D APIs 來編寫程序,你知道那得多么痛苦。選擇 A3D、Away3D 能夠減輕一定的工作量,但使用開源引擎支持較差、特性較少。客觀地說,寫 3D 應用現在應該選擇 Unity3D 或 Unrel Engine 3,反正它們也能編譯成 swf 了。
7、2012 年,網頁游戲的冬天不來,起碼也是秋天。網頁游戲的增長將會放緩,其實從 2011 年第四季度可以看到各大公司都開始壓縮產品線,開始不再大量招工,而是轉向消化之前已經招到的技術人員。在 2012 年,將會有更多的頁游創業公司倒閉或轉向移動設備游戲開發,AS 開發人員將會過剩,薪資下降。如果你在 2012 年上半年開始進入 AS 領域,那么下半年剛有所成的時候,就會遇到一大批剛下崗的競爭者,高薪夢肯定要落空。
8、移動設備應用或游戲開發在 2012 年還會受到資本的熱捧,但 AS 在這個領域的競爭力我心存疑慮。Flash 優勢就是跨平臺,而 Unity3D 和 UDK 同樣可以跨平臺,同樣可以使用腳本語言開發,而且性能、效果都更加優秀。隨著 Unity3D 和 UDK 可以編譯成 swf 在 Flash Player 上運行,學習 AS 的必要性進一步降低。
綜上 8 點,可以看到沒有技術基因的 Adobe 公司引導下的 Flash 開發路線圖缺乏方向,前景模糊,再加上 ActionScript 和 Flex SDK 本身的缺陷,又遇上 Unity3D 和 UDK 這樣的強勁外敵,再加上網頁游戲大盤下滑,內憂外患之下,實在不是明智之選。Adobe Flash 當然不會死掉,也不會在 2012 年大量失去市場份額,但 Flash 程序員的 2012 不好過,想活得輕松點,注意距離。線程
線程是指進程中的一個單一順序的控制流,是操作系統能夠調度的最小單位,一個進程中可以有多條線程,分別執行不同的任務。線程有內核線程和用戶線程之分,但在本文中僅指內核線程。在軟件開發中,使用線程有以下好處:
1、在多核或多路 CPU 的機器上多線程程序能夠并發執行,提高運算速度;
2、把 I/O,人機交互等與密集運算部分分離,提升 I/O 吞吐量和增進用戶體驗。
線程的缺點也很明顯:
1、創建一條線程需要較大的內存開銷,導致不能創建海量的線程;
2、線程由操作系統調度(分配時間片),線程切換的 CPU 成本比較高,導致大量線程存在時大量 CPU 資源消耗在線程切換上;
3、同一進程的多條線程共享全部系統資源,在多線程間共享資源需要進入加鎖,大量的鎖開銷不提,重要的是加大了編寫程序的復雜性,這一點你看看有多少書名含有“多線程”三個字就明白寫個多線程應用有多難了;
4、 I/O 方面,多線程幫助有限,以 TCP Socket Server 為例,如果每一個 client connection 由一條專屬的線程服務,那么這個 server 可能并發量很難超過 1000。為了進一步解決并發帶來的問題,現代服務器都使用 event-driven i/o 了。
event-driven i/o 解決了并發量的問題,但引入了“代碼被回調函數分割得零零碎碎”的問題。特別是當 event-driven i/o 跟 multi-threading 結合在一起的時候,麻煩就倍增了。解決這個問題的辦法就使用綠色線程,綠色線程可以在同一個進程中成千上萬地存在,從而可以在異步 I/O 上封裝出同步的 APIs,典型的就是用基于 greenlet + libevent 開發的 python 庫 gevent。綠色線程的缺陷在于操作系統不知道它的存在,需要用戶進行調度,也就無法利用到多核或多路 CPU 了。為了解決這個問題,很多大牛都做出了巨大的努力,并且成果斐然,scala、google go 和 rust 都較好地解決了問題,下文以 rust 的并發模型為例講一下。
rust 提出一個 Task 的概念,Task 有一個入口函數,也有自己的棧,并擁有進程堆內存的一部分,為方便理解,你可以把它看作一條綠色線程。rust 進程可以創建成千上萬個 Tasks,它們由內建的調度器進行調度,因為 Tasks 之間并不共享數據,只通過 channels/ports 通信,所以它們是可并行程度很高。rust 程序啟動時會生成若干條(數量由 CPU 核數決定或運行時指定)線程,這些線程并行執行 Tasks,從而利用多個 CPU 核心。
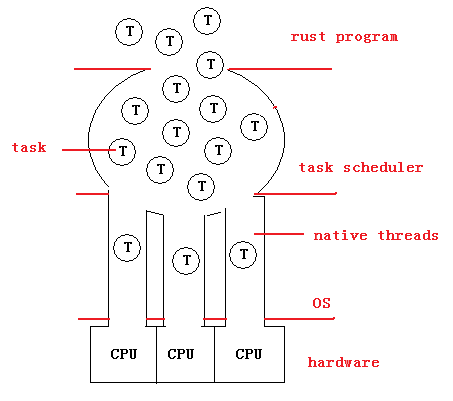
如 上圖,rust 應用程序不停地 spawn 出一個又一個 Tasks,它們由 tasks 調度器管理,在適當的時機,調度器會把某一個 Task 分配給原生線程執行,如果這個 Task 進入 I/O 等待或主動讓出 CPU(sleep),那么這個 Task 會被交回給調度器,而相應的原生線程會執行另一個新分派的 Task。盡管使用 rust 編程語言是不能創建線程的(直接調用 C 函數不算),但 rust 應用程序實際上是多線程的(一般情況下),它能夠充分地利用多核或多路 CPU。
綜上,類似 rust 的 Task 的概念是比線程更好的并發模型,更安全,編寫的代碼也更加容易維護(關于維護性,我相信寫過 gevent 程度或 go 程序的同學會認同的)。線程當然不會消亡,但隨著 scala/go/rust 的成熟,在可以預見的將來,線程會退到它呆著的角落:遠離普通程序員,只有少數人需要了解它的細節。
C++
C++ 在 2011 年其實風頭甚勁,C++2011 標準出臺,gcc/msvc/clang 都很快速地支持了許多新特性,新興的移動設備的性能較差,更是 C++ 的新舞臺,在這個時候唱衰 C++,壓力很大。我使用 C++ 年頭不少,但除了在校的時候寫過兩個小游戲參加過兩個比賽(分別是面向社會和面向大學生的)弄些證書好找工作以外,在工作中只用過大概不到一年半,做《斬 魂》(http://zh.163.com)的早期版本,寫了服務器端的幾條進程和客戶端的 GameAI 部分。經驗少,而且寫得不好,所以基本上有人在 weibo 上問我 C++ 的問題,我都是轉發給 @bnu_chenshuo 和 @miloyip 等真正的行家去回答的。所以實際上今天寫這一篇,我底氣很是不足,但是朋友們給前兩篇很大面子,弄得我騎虎難下,只好硬著頭皮寫了。
前 文提到 C++ 的新標準,很有必要提一下標準化對 C++ 的影響。首先我們要肯定標準定制對 C++ 的積極作用,但標準化過程中的超長流程,一次次將 C++ 推向深淵。C++ 的第一個標準是 1998 年的 ISO/IEC 14882:1998,距離整個 90 年代最流行的 C++ 程序庫 MFC(Microsoft Foundation Class Library)的第一個版本發行時間已經整整 6 年。1998 年,MFC 版本號為 6.0,與其一起發布的 Visual C++ 6.0 占有了巨大的市場。因為 MFC 發布得標準制定的時間早,所以 MFC 內部實現了許多后來標準庫里也有的組件,比如各種數據結構容器。VC6 的市場占有率讓 windows 平臺下開發的許多 C++ 程序員甚至不知道有 STL,同時也無視 C++98 標準,從更兼容標準的 VC2002/2003 的市場占有率就可以看出來,直到今天,我知道國內不少公司還是只用 VC6 的。
其實在 90 年代,計算機的運算能力有限,市場上非常需要一款性能較高、抽象較強的編程語言,C++ 獲得了成功,但它標準化的時間過長,造成各種編譯器有各自互不兼容的“方言”,成了它的第一個軟肋。第一個瞄準這個軟肋的就是 java,java 在 1995 年推出,雖然性能稍遜,但它有更高的抽象能力、也更安全,并且更容易跨平臺,所以迅速獲得了成功;第二個瞄準這個軟肋的是 C#,微軟不能推動 C++ 發展,又不愿 C++ 的市場被 java 鯨吞,于是在 2001 年推出了 C#,經過 10 年的發展和微軟大量的金錢推廣,C# 已經成功獲得了它應有的江湖地位。
雖然 java/c# 都不是善類,但 C++ 在 21 世紀的第一個十年里仍然地位穩固,這是因為 Linux 和 MacOS X 大獲成功,在這兩個平臺上 C++ 都是非常有競爭力的編程語言,C++ 自然水漲船高。但隨著 web2.0 和 web app 概念的興起,以及 CPU 的主頻進一步提升,服務器端編程語言漸漸地對執行效率不再敏感,而是更在意程序員的開發效率,眾多的腳本語言開始蠶食 C++ 的市場份額,從早期的 perl 到后期的 python/php/ruby,在 2005 年以后,C++/java/C# 等靜態類型的編譯型語言的市場份額都下降了,新興的貴族是動態語言。面對動態語言在開發效率上的強勁挑戰,C++ 社區除了在 2003 年對 C++98 做了小小的 patch,基本上睡著了,完全沒有應對之策,哦不,連應用的姿態都沒有。
進入 21 世紀的第二個十年,市場又發生了變化,云計算越走越近,也許我們中的大部分人今天還可以說只聞其聲不見其形,但 The Data Center Is the Computer 這句話大家應該覺得很務實:完成一個用戶操作,在服務器端的進程間通信次數前所未有地多。在這個十年,我們需要這樣的編程語言:
1、能充分利用現代 CPU 的計算能力,不僅僅是多個核心,更是巨大的 L1/L2/L3 Cache、超線程等;
2、能夠大量減小異步 I/O 的性能提升的同時帶來的副作用:異步編程的復雜性以及對可維護性的傷害;
兩 句話其實也可以壓縮為一句:需要有更好的并發模型的語言。一開始大家都在已有的編程語言中尋找,然后找到了 erlang,實踐證明 erlang 自有其局限,所以 google go/scala/rust 等新語言如同雨后春筍般撥地而出。C++2011 標準努力降低 C++ 的編程難度,并提供了線程庫以支持現代 CPU,如果在 2005 年,這個標準絕對有競爭力,但在今天,它只能成為新的編程語言的墊腳石。正如 IE 最大的用處是用來下載其它瀏覽器,不久之后,也許會流行新的冷笑話:C++ 最大的用處就是用來實現其它編程語言。
市場一直在尋找一門中間的高級 語言,它上承 C 語言和匯編語言,下啟腳本語言。C++ 最先搶占了高地,并在與 java/c# 的爭斗中不落下風,但新的十年,它的對手又增加了 google go/scala/rust 等新銳,并且新的標準不可能在兩三年內再次出臺,兩三年內新銳成長起來后,留給它的位置就不多了。
上 文討論的基本上都是服務器編程,有必要再來看一下桌面和移動設備領域。首先看桌面軟件,rust 是 mozilla 基金會開發系統程序語言的,它的定位是部分取代 C++ 開發 firefox 的瀏覽器,所以 rust 會進入桌面開發,google go 肯定會順道啃一口。移動設備方面,主要是 android、ios 和 windows phone,隨著移動設備性能增強,編譯型語言加腳本的模式就會占大頭,編譯型語言方面主要是 C++ 和 Objective-C 在競爭,C++ 會占上風(但需求量遠遠小于腳本,從 lua 在 2011 年的增長速度可以印證),但是誰知道 rust 之類的會不會進入移動設備呢,畢竟移動設備的 CPU 核心也越來越多了呀,C++ 還是前景堪憂。
回首 C++ 的 30 年,展望它的未來,總結起來可能就是:標準化流程拖死人了。如果不是 15 年不能標準化,java/c# 的攪局可能不會出現;如果在 2005 年能夠應對動態語言……如果云時代有更好的并發模型……
題 外話:java/c# 不會有 C++ 的問題,因為它們有自己的平臺,有巨大的財富支撐。特別是平臺的作用非常巨大,你可以想像一下如果 Adobe 有自己的瀏覽器或手機操作系統 ActionScript/MXML 會不會是今天的境地;也可以想像一下 google go 的飛速發展動力是什么。
兩點解釋
1、 我覺得有必要解釋“不宜進入”一下這四個字,我想要表達的意思就是如果你現在不是這三個技術點的專家,并且手上沒有使用這三個技術點的項目,進入這三個技 術點僅為技術儲備,那么就“不宜進入”。另外我不是說用了這三個技術點的項目就死,學了這三個技術點的人就找不到工作,或者這三個技術點明天或明年就 game over,渣都沒得剩,不是這樣的意思,它們還會存在很長一段時間。本文不是叫專家自廢武功,也不是叫已經做好技術造型的項目趕緊兒換技術,舉例說,如果 你選擇了用 java 做服務器端,flash 做客戶端開發一個 webgame,那你最好玩命兒地把 ActionScript/MXML 和 java 多線程編程(及異步 I/O)給鉆透,不然可能隨時掉陷阱里。
2、新年新氣象,工作和家庭都有很重要的事情壓在肩上,大家的評論我不逐條回復了,我會在一兩個星期后再統一寫一篇《2012 不宜進入的三個技術點(Q&A)》統一回答,還請見諒。
posted @
2012-02-04 23:19 todayx.org 閱讀(195) |
評論 (0) |
編輯 收藏勞動密集型公司
這樣的公司以業務為導向,市場團隊在公司中占據較高的地位。每一個技術人員最終被折算到了“人天”里面去,團隊規模相對較大,所有技術人員都比較容 易被替代,能力強的可以做更多的事情,能力弱的就少做一些。通過強有力的制度、政策和流程的規約,團隊有條不紊地運作起來。業務氛圍強勢,技術通道升級較 慢,需要非常長期的積累才可以獲得豐厚的回報,諸多優秀人才脫離編碼,而潛心轉管理、談需求并獲得回報。愿意招納畢業生編碼,以減小運營成本。只鼓勵小范 圍、淺層次的創新,對于優秀的創意、想法,必須轉化為生產力才能夠被認可。
技術密集型公司
這樣的公司較為重視技術和創新,敢于在產品中使用預期能夠帶來收益的技術。公司非常愿意招聘一些有豐富研發經驗、有廣泛閱歷的程序員加入,同時也能 吸引一些比較優秀的技術人才,并且長期為公司工作。團隊人員較少,研發過程無論是從時間還是環境來看,通常比較寬松,用較少約束、任務驅動的形式,鼓勵程 序員按期完成下發的任務。技術人員層次劃分較多,不同層次技術人員在一起辦公,往往都不脫離編碼,和項目結合緊密。愿意招不同層次的研發人員,不愿意招經 驗豐富但脫離技術的人到研發團隊。
思維密集型公司
這樣的公司對研發人員思辨能力要求較高,愿意做一些創造性的產品。公司技術人員的招聘較為嚴格,更看重人員的創新氣質、解決問題的思路、建模和抽象 的能力,而對于具體的某種技術實現,并沒有很高的要求。團隊人員不多,項目壓力不大,任務給定的要求和流程約束較少,需要團隊成員較強的自主能力來解決問 題。技術人員層次劃分不多,討論氣氛濃厚,設計精益求精,創新的點子容易得到認可并嘗試實現。
你所在的公司,屬于哪一種?
posted @
2012-02-04 01:10 todayx.org 閱讀(3306) |
評論 (5) |
編輯 收藏 漁夫 蛇 青蛙的故事
漁夫看到船邊有條蛇,口中正銜著一只青蛙。漁夫動了惻隱之心,把青蛙從蛇的口中救了出來。但漁夫又為蛇將挨餓而難過,便拿出一瓶酒,往蛇的口中滴了幾滴。 蛇高興地游走了,青蛙也為重獲新生而高興,漁夫則為自己的善舉而感到快樂。他想,這真是皆大歡喜!沒料到,僅僅過了幾分鐘,漁夫聽到有東西在叩擊他的船 板。他低頭一看,那條蛇又回來了,而且嘴里咬著兩只青蛙——它來討要更多酒的獎賞!
漁夫的本意是希望蛇不再捕捉青蛙,但是由于憐憫而給了它幾滴酒——這是獎勵而不是懲罰,結果事與愿違。你獎勵了什么行為,就會得到更多這樣的行為。所以,這則寓言要告訴我們的是,別去獎勵那些錯誤的行為。
我們再講一個企業獎勵錯誤行為的故事
一家企業制定了一個規定,如果該企業的員工加班到晚上7 點可以獲得10元錢的晚餐補助,如果加班到8點可以打出租車回家(平常5點下班)。該獎勵制度執行了一段時間之后,公司管理者竟然發現,有很多員工在正常 下班前或者很早就已經完成了工作,但是他們居然不正常下班而是留下來繼續加班,有的待到七點,有的待到八點以后。一個管理者親眼看見一個員工在下午4點前 就完成了文檔整理,然后一直在那里上網聊天一直到晚上8點。
你也行會認為這些員工鉆公司的空子有些不太好,但是這不能完全怪他們,因為早早的完成工作不見的會得到公司的獎勵,相反有意把工作拖到晚上8點之后就可以拿到打車費,并且能免費獲得一頓飯錢,多劃算呀!
管理者一定要牢記住這句話"受到獎勵的事情人們都喜歡去做" 為此管理者應該仔細檢測獎勵制度,哪些是積極的 ,哪些可能帶來消極的影響,修改掉哪些不合理的部分,通過獎勵正確的行為來獲得自己想要的結果。
美國管理專家拉伯福認為,企業在獎勵員工方面最常范的十個錯誤.
1、需要好的結果,卻獎勵了那些看上去最忙碌,工作時間最長的人
2、要求工作的質量,卻設下了不合理的完成工期
3、希望從根本上解決問題,卻獎勵那些治標不治本的人
4、要求員工對公司忠誠,卻支付高薪給新來的員工或威脅要離職的員工
5、要求事情簡單化,卻獎勵制造瑣碎和使事情復雜化的人
6、想要創造和諧的工作環境,卻獎勵那些光說不做并且經常抱怨的人
7、要求員工有創意,卻指責那些公司里有特立獨行的人
8、要求節儉,卻獎勵那些浪費資源的人
9、要求員工有團隊精神,卻犧牲團隊利益獎勵那些投機取巧的人
10、要求創新,卻獎勵保守的人,責罰未能完成的創意
如何改進我們的獎勵行為
孔子云:舉一而不能以三反,不可教也。每一個治理者都可以對照拉伯福所說的這十種錯誤,舉一反三,驗照一下自己是不是犯過類似的錯誤。例如:
1、 我們 是不是口頭上公布講究實績、注重實效,卻往往獎勵了那些專會做表面文章、投機取巧之人?
2、 我們是不是口頭上公布員工考核以業績為主,卻往往憑主觀印象評價和獎勵員工?
3、 我們是不是口頭上公布鼓勵創新,卻往往處罰了敢于創新之人?
4、 我們是不是口頭上公布鼓勵不同意見,卻往往處罰了敢于發表不同意見之人?
5、 我們是不是口頭上公布按章辦事,卻往往處罰了堅持原則的員工?
6、 我們是不是口頭上鼓勵員工勤奮工作、努力奉獻,卻往往獎勵了不干實事、專事搗鬼、鉆營之人?
總結
總之,我們每一個治理者都要牢記:“在表現與獎勵之間建立起正確的連帶關系,是改進組織運作的唯一要訣”。在考核和獎勵員工時非凡要注重的是,要注重其實 際業績,而不要注重其口頭上怎么說。不能獎勵了投機取巧,冷落了埋頭實干,否則以后我們指望誰來做事呢?
治理大師卡耐基說過:我年紀越大,就越不重視別人說些什么,我只看他們做些什么。其實中國古賢更早就說過這樣的話:“始吾于人也,聽其言而信其行;今吾于 人也,聽其言而觀其行”。在獎罰問題上,每個治理者確實不可粗心大意,草率行事。否則,“種瓜得瓜,種豆得豆”,種下了苦果可是要自己吃的!
posted @
2012-02-04 01:08 todayx.org 閱讀(1335) |
評論 (3) |
編輯 收藏博士
有一個博士分到一家研究所,成為學歷最高的一個人。
有一天他到單位后面的小池塘去釣魚,正好正副所長在他的一左一右,也在釣魚。
他只是微微點了點頭,這兩個本科生,有啥好聊的呢?
不一會兒,正所長放下釣竿,伸伸懶腰,蹭蹭蹭從水面上如飛地走到對面上廁所。
博士眼睛睜得都快掉下來了。水上飄?不會吧?這可是一個池塘啊。
正所長上完廁所回來的時候,同樣也是蹭蹭蹭地從水上飄回來了。
怎么回事?博士生又不好去問,自己是博士生哪!
過一陣,副所長也站起來,走幾步,蹭蹭蹭地飄過水面上廁所。這下子博士更是差點昏倒:不會吧,到了一個江湖高手集中的地方?
博士生也內急了。這個池塘兩邊有圍墻,要到對面廁所非得繞十分鐘的路,而回單位上又太遠,怎么辦?
博士生也不愿意去問兩位所長,憋了半天后,也起身往水里跨:我就不信本科生能過的水面,我博士生不能過。
只聽咚的一聲,博士生栽到了水里。
兩位所長將他拉了出來,問他為什么要下水,他問:“為什么你們可以走過去呢?”
兩所長相視一笑:“這池塘里有兩排木樁子,由于這兩天下雨漲水正好在水面下。我們都知道這木樁的位置,所以可以踩著樁子過去。你怎么不問一聲呢?”
這個故事告訴我們:學歷代表過去,只有學習力才能代表將來。尊重經驗的人,才能少走彎路。一個好的團隊,也應該是學習型的團隊。
個人理解和感悟:看學歷更要看能力
招聘廣告上面我們經常會看到“要求本科以上學歷”,很少有企業招聘的時候 是不在乎學歷的,而且在一些正規的企業里,如果沒有足夠的學歷,是不予以考慮加薪升職的。企業在人才的競爭上面出現了一種盲目攀比學歷的不良傾向,現在經 常可以看到在某些企業的官方介紹上面寫“公司的本科以上學歷占有xx比例”的字眼,,似乎聘用的人才學歷越高
越好,在職員工高學歷的越多越好。有一則消息稱研究生學歷的人比本科學歷的人平均年薪要高出2w元,從這里看出,學歷在企業招聘和考核中的重要性。
現在越來越多的人堅持考研或者讀MBA,他們認為一旦有了高的學歷就可以“春風得意馬蹄疾,一頁看遍長安花”了。目前學歷仍然是一個隱形的、力量巨大的“殺手”,生生的把沒有一紙文憑的人拒之門外。
有文憑不等于有水平,沒有學歷不等于沒有能力,大量的事實說明, 不少才華橫溢、能力卓越的人才,他們并沒有高的學歷,有的甚至沒有大學文憑,例如愛迪生、高爾基諾貝爾 比爾蓋茨 喬布斯等,這些人雖然沒有高的學歷,但是他們取得的成就是非凡的,同樣現實中生活中也能輕易的發現,很多擁有高學歷的人在工作中能力平平、毫無建樹、庸庸 碌碌的過萬了一生,管理者在選擇人才時,只能把學歷當作一種參考條件,更重要的是要看這個人的實際能力。如果企業不從實際出發,競相制定一些高學歷的規 定,對學歷的要求過為嚴格,甚至唯學歷取人,很難選拔出優秀的人才,衡量人才既要有文化程度方面的要求,更總要視履行崗位職責的能力,真正使那些有學歷, 有智慧又有能力的人得到重用.
伯 樂相馬,主要是看馬能否跑千里而不是看馬的出身。近有消息說,有些用人單位招聘人才的取向已更加務實,選才標準正在由“學歷型”向“能力型”轉變,這是一 種令人欣慰的轉變。畢竟,千里馬是跑出來的,人才是干出來的。創造業績主要不是靠職前的學歷,而是靠任職后的實踐經歷和創造性努力。但愿我們公開選拔干部 時,能夠更重任職的能力而不是更重職前的學歷。
一個人是否真正的有才能,并不能以學歷作為衡量的唯一標準,管理者在選人、用人時,不要被學歷遮住了視野,二應該把有實際能力的員工放在最重要的位置上
posted @
2012-02-03 00:00 todayx.org 閱讀(1462) |
評論 (3) |
編輯 收藏