本文為原創(chuàng),如需轉(zhuǎn)載,請(qǐng)注明作者和出處,謝謝!
一、Java編碼是怎么回事?
對(duì)于使用中文以及其他非拉丁語(yǔ)系語(yǔ)言的開(kāi)發(fā)人員來(lái)說(shuō),經(jīng)常會(huì)遇到字符集編碼問(wèn)題。對(duì)于Java語(yǔ)言來(lái)說(shuō),在其內(nèi)部使用的是UCS2編碼(2個(gè)字節(jié)的Unicode編碼)。這種編碼并不屬于某個(gè)語(yǔ)系的語(yǔ)言編碼,它實(shí)際上是一種編碼格式的世界語(yǔ)。在這個(gè)世界上所有可以在計(jì)算機(jī)中使用的語(yǔ)言都有對(duì)應(yīng)的UCS2編碼。
正是因?yàn)?/span>Java采用了UCS2,因此,在Java中可以使用世界上任何國(guó)家的語(yǔ)言來(lái)為變量名、方法名、類起名,如下面代碼如下:
class 中國(guó)
{
public String 雄起()
{
return "中國(guó)雄起";
}
}
中國(guó) 祖國(guó) = new 中國(guó)();
System.out.println(祖國(guó).雄起());
哈哈,是不是有點(diǎn)象“中文編程”。實(shí)際上,也可以使用其他的語(yǔ)言來(lái)編程,如下面用韓文和日文來(lái)定義個(gè)類:
class ???
{
public void スーパーマン() {  }
}
}
實(shí)際上,由于Java內(nèi)部使用的是UCS2編碼格式,因?yàn)椋?/span>Java并不關(guān)心所使用的是哪種語(yǔ)言,而只要這種語(yǔ)言在UCS2中有定義就可以。
在UCS2編碼中為不同國(guó)家的語(yǔ)言進(jìn)行了分頁(yè),這個(gè)分頁(yè)也叫“代碼頁(yè)”或“編碼頁(yè)”。中文根據(jù)包含中文字符的多少,分了很多代碼頁(yè),如cp935、cp936等,然而,這些都是在UCS2中的代碼頁(yè)名,而對(duì)于操作系統(tǒng)來(lái)說(shuō),如微軟的windows,一開(kāi)始的中文編碼為GB2312,后來(lái)擴(kuò)展成了GBK。其實(shí)GBK和cp936是完全等效的,用它們哪個(gè)都行。
二、Java編碼轉(zhuǎn)換
上面說(shuō)了這么多,在這一部分我們做一些編碼轉(zhuǎn)換,看看會(huì)發(fā)生什么事情。
先定義一個(gè)字符串變量:
String gbk = "中國(guó)"; // “中國(guó)”在Java內(nèi)部是以UCS2格式保存的
用下面的語(yǔ)言輸出一定會(huì)輸出中文:
System.out.println(gbk);
實(shí)現(xiàn)上,當(dāng)我們從IDE輸入“中國(guó)”時(shí),用的是java源代碼文件保存的格式,一般是GBK,有時(shí)也可是utf-8,而在Java編譯程序時(shí),會(huì)不由分說(shuō)地將所有的編碼格式轉(zhuǎn)換成utf-8編碼,讀者可以用UltraEdit或其他的二進(jìn)制編輯器打開(kāi)上面的“中國(guó).class”,看看所生成的二進(jìn)制是否有utf-8的編碼(utf-8和ucs2之間的轉(zhuǎn)換非常容易,因?yàn)?/span>utf-8和ucs2之間是用公式進(jìn)行轉(zhuǎn)換的,而不是到代碼頁(yè)去查,這就相當(dāng)于將二進(jìn)制轉(zhuǎn)成16進(jìn)制一樣,4個(gè)字節(jié)一組)。如“中國(guó)”的utf-8編碼按著GBK解析就是“涓 浗”。如下圖所示。
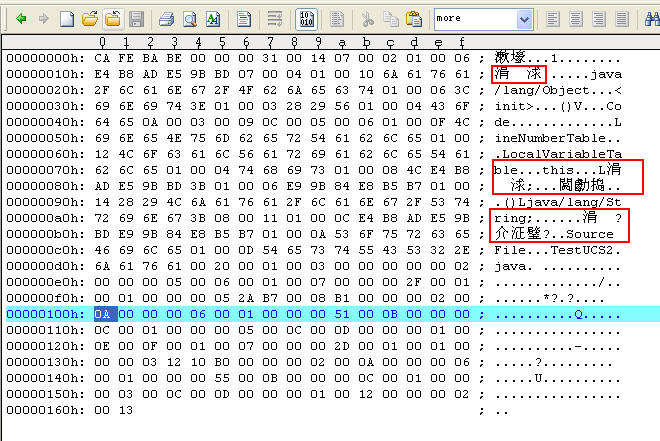
如果使用下面的語(yǔ)言可以獲得“中國(guó)”的utf-8字節(jié),結(jié)果是6(一個(gè)漢字由3個(gè)字節(jié)組成)
System.out.println(gbk.getBytes("utf-8").length);
下面的代碼將輸出“涓 浗”。
System.out.println(new String(gbk.getBytes("utf-8"),
"gbk"));
由于將“中國(guó)“的utf-8編碼格式按著gbk解析,所以會(huì)出現(xiàn)亂碼。
如果要返回中文的UCS2編碼,可以使用下面的代碼:
System.out.println(gbk.getBytes("unicode")[2]);
System.out.println(gbk.getBytes("unicode")[3]);
前兩個(gè)字節(jié)是標(biāo)識(shí)位,要從第3個(gè)字節(jié)開(kāi)始。還有就是其他的語(yǔ)言使用的編碼的字節(jié)順序可能不同,如在C#中可以使用下面的代碼獲得“中國(guó)“的UCS2編碼:
String s = "中";
MessageBox.Show(ASCIIEncoding.Unicode.GetBytes(s)[0].ToString());
MessageBox.Show(ASCIIEncoding.Unicode.GetBytes(s)[1].ToString());
使用上面的java代碼獲得的“中“的16進(jìn)制UCS2編碼為4E2D,而使用C#獲得的相應(yīng)的ucs2編碼為2D4E,這只是C#和Java編碼內(nèi)部使用的問(wèn)題,并沒(méi)有什么關(guān)系。但在C#和Java互操作時(shí)要注意這一點(diǎn)。
如果使用下面的java編碼將獲得16進(jìn)制的“中”的GBK編碼:
System.out.println(Integer.toHexString(0xff
& xyz.getBytes("gbk")[0]));
System.out.println(Integer.toHexString(0xff
& xyz.getBytes("gbk")[1]));
“中”的ucs2編碼為2D4E,GBK編碼為D6D0
讀者可訪問(wèn)如下的url自行查驗(yàn):
http://unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/CP936.TXT
當(dāng)然,感興趣的讀者也可以試試其他語(yǔ)言的編碼,如“人類”的韓語(yǔ)是“???”,如下面的代碼將輸出“???”的cp949和ucs2編碼,其中cp949是韓語(yǔ)的代碼頁(yè)。
String korean = "???"; // 共三個(gè)韓文字符,我們只測(cè)試第一個(gè)“?”
System.out.println(Integer.toHexString(0xff & korean.getBytes("unicode")[2]));
System.out.println(Integer.toHexString(0xff & korean.getBytes("unicode")[3]));
System.out.println(Integer.toHexString(0xff & korean.getBytes("Cp949")[0]));
System.out.println(Integer.toHexString(0xff & korean.getBytes("Cp949")[1]));
上面代碼的輸出結(jié)果如下:
c7
78
c0
ce
也就是說(shuō)“?”的ucs2編碼為C778,cp949的編碼為C0CE,要注意的是,在cp949中,ucs2編碼也有C0CE,不要弄混了。讀者可以訪問(wèn)下面的url來(lái)驗(yàn)證:
http://unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/CP949.TXT
Java支持的編碼格式
三、屬性文件
Java中的屬性文件只支持iso-8859-1編碼格式,因此,要想在屬性文件中保存中文,就必須使用UCS2編碼格式("uxxxx),因此,出現(xiàn)了很多將這種編碼轉(zhuǎn)換成可視編碼和工具,如Eclipse中的一些屬性文件編輯插件。
實(shí)際上,"uxxxx編碼格式在java和C#中都可以使用,如下面的語(yǔ)句所示:
String name= ""u7528"u6237"u540d"u4e0d"u80fd"u4e3a"u7a7a"
;
System.out.println(name);
上面代碼將輸出“用戶名不能為空”的信息。將"uxxxx格式顯示成中文非常簡(jiǎn)單,那么如何將中文還原成"uxxxxx格式呢?下面的代碼完成了這個(gè)工作:
String ss = "用戶名不能為空";
byte[] uncode = ss.getBytes("Unicode");
int x = 0xff;
String result ="";
for(int i= 2; i < uncode.length; i++)
{
if(i % 2 == 0) result += "\\u";
String abc = Integer.toHexString(x & uncode[i]);
result += abc.format("%2s", abc).replaceAll(" ", "0");
}
System.out.println(result);
上面的代碼將輸出如下結(jié)果:
\u7528\u6237\u540d\u4e0d\u80fd\u4e3a\u7a7a
好了,現(xiàn)在可以利用這個(gè)技術(shù)來(lái)實(shí)現(xiàn)一個(gè)屬性文件編輯器了。
四、Web中的編碼問(wèn)題
大家碰到最多的編碼問(wèn)題就是在Web應(yīng)用中。先讓我們看看下面的程序:
<!-- main.jsp -->
<%@ page language="java" pageEncoding="utf-8"%>
<html>
<head>
</head>
<body>
<form action="servlet/MyPost" method="post">
<input type="text" name="user" />
<p/>
<input type="submit" value="提交"/>
</form>
</body>
</html>
下面是個(gè)Servlet:
package servlet;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class MyPost extends HttpServlet
{
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException
{
String user = request.getParameter("user");
System.out.println(user);
}
}
如果中main.jsp中輸入中文后,向MyPost提交,在控制臺(tái)中會(huì)輸出“ä¸å?½”,一看就是亂碼。如果將IE的當(dāng)前編碼設(shè)成其他的,如由utf-8改為gbk,仍然會(huì)出現(xiàn)亂碼,只是亂得不一樣而已。這是因?yàn)榭蛻舳颂峤粩?shù)據(jù)時(shí)是根據(jù)瀏覽器當(dāng)前的編碼格式來(lái)提交的,如瀏覽器當(dāng)前為gbk編碼,就以gbk編碼格式來(lái)提交。 這本身是不會(huì)出現(xiàn)亂碼的,問(wèn)題就出在Web服務(wù)器接收數(shù)據(jù)的時(shí)候,HttpServletRequest在將客戶端傳來(lái)的數(shù)據(jù)轉(zhuǎn)成ucs2碼上出了問(wèn)題。在默認(rèn)情況下,是按著iso-8859-1編碼格式來(lái)轉(zhuǎn)的,而這種編碼格式并不支持中文,所以也就無(wú)法正常顯示中文了,解決這個(gè)問(wèn)題的方法是用和客戶端瀏覽器當(dāng)前編碼格式一致的編碼來(lái)轉(zhuǎn)換,如果是utf-8,則在doPost方法中應(yīng)該用以下的語(yǔ)句來(lái)處理:
request.setCharacterEncoding("utf-8");
為了對(duì)每一個(gè)Servlet都起作用,可以將上面的語(yǔ)句加到filter里。
另外,我們一般使用象MyEclipse一樣的IDE來(lái)編寫jsp文件,這樣的工具會(huì)根據(jù)pageEncoding屬性將jsp文件保存成相應(yīng)的編碼格式,但如果要使用象記事本一樣的簡(jiǎn)單的編輯器來(lái)編寫jsp文件,如果pageEncoding是utf-8,而在默認(rèn)時(shí),記事本會(huì)將文件保存成iso-8859-1(ascii)格式,但在myeclipse里,如果文件中有中文,它是不允許我們保存成不支持中文的編碼格式的,但記事本并不認(rèn)識(shí)jsp,因此,這時(shí)在ie中就無(wú)法正確顯示出中文了。除非用記事本將其保存在utf-8格式。如下圖:
新浪微博:http://t.sina.com.cn/androidguy 昵稱:李寧_Lining