1. 序
在數據集成類的項目中,最難的過程就是數據分析了,數據分析過程位于數據集成類項目整個過程(前期準備調研-----數據分析-----接口實現)的第二步,它為第三步接口實現提供了充分的準備,因此數據分析的正確與否很大程度上決定了數據集成能否成功的實現和完成。
怎么樣有效的進行數據分析呢,怎么樣提前在數據分析中盡量避免問題等到實現時才出現呢?這是一個行之有效的數據分析方法論的評判的關鍵。
經過幾個項目的經歷,反思了一下在做這些項目時比較有效的方法和失妥的方法,總結了一套目前個人覺得可行的數據分析方法,此套數據分析方法只適用于數據庫---文件---數據庫或數據庫---數據庫的分析,對于接口式的集成(例如調用對方的webservice、EJB接口等)并不適用,在這樣的一套數據分析的方法中,為數據分析的步驟以及需要注意的問題事項提出了指導,編寫此blog以希望有同行的同學們多多交流。
2. 數據分析方法論
此方法論中涉及的名詞的解釋:
l 目標數據源
指在數據集成中需要導入數據的數據源,此數據源可能是數據庫,也有可能是文件。
l 源數據源
指在數據集成中獲取數據的數據源,此數據源可能是數據庫,也有可能是文件。
l 字典代碼
在數據庫中以代碼的方式(如數字、英文字母等)來代替中文意思進行存儲,其中的這些代碼就稱為字典代碼。
2.1. 步驟
2.1.1. 分析目標數據源的數據結構
目標數據源既有可能是數據庫也有可能是文件,但無論是哪種,它都是有數據結構的,首先要做的就是分析目標數據源的數據結構,在分析目標數據源的數據結構時,要分析清楚的有:
l 表
目標數據源中需要交換的有哪些表,這些表的含義分別是什么。
l 字段
這些表中包含的字段、字段的類型以及長度。
l 字段含義
分析每個字段的含義,包括字段的中文含義、字段涉及到的字典代碼以及字段的規則(如業務規則、生成規則)。
在分析了上面所提及的表、字段、字段含義后,形成如下結構的文檔:
表名
|
字段
|
字段類型及長度
|
中文含義
|
涉及到的字典代碼
|
字段規則
|
|
id
|
number(10)
|
主鍵流水號
|
--
|
流水號,通過表名_SEQ的Sequence來獲取
|
|
unitcode
|
varchar2(19)
|
單位編碼
|
單位編碼字典
|
--
|
2.1.2. 分析目標數據源的表關系
在完成了第一步后,需要接著分析目標數據源的表關系,分析表關系最重要的在于分析各個表之間的關聯關系(例如一對一、一對多,通過這里可以分析出的為主鍵、外鍵的關聯關系),其次就是需要根據業務來分析其各個表之間的隱性關聯,如只有當A表中的某個值為03時才關聯到B表。
在分析完畢目標數據源的表關系后,形成如下Rose圖:
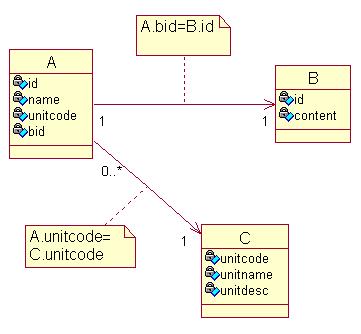
2.1.3. 分析源數據源的數據結構
方法同2.1.1,分析的對象改變為源數據源,分析完畢后形成同2.1.1中的文檔。
2.1.4. 分析源數據源的表關系
方法同2.1.2,分析的對象改變為源數據源,分析完畢后形成同2.1.2中的Rose圖。
2.1.5. 根據目標數據源的表關系分析其和源數據源的表的對應關系
根據目標數據源的表關系,來分析其和源數據源表的對應關系,在這個步驟中需要分析清楚的是目標數據源的表的數據來源于源數據源的哪些表,怎么獲取到這些數據,分析完畢后可形成校驗數據集成是否正確的一個標準,那就是目標數據源的表的數據量和其來源的源數據源的那些表的數據量應該是一致的,分析時仍然是根據目標表的業務含義去源數據源中的表中尋找具備相同含義的表,在分析的過程中可能會碰到如下幾種情況:
l 含義相同的表
這種情況通常是目標數據源和源數據源均為使用一張表存儲,含義相同的表通常都是一對一的數據關系,例如目標數據源中有一張表為常住人口基本信息,源數據源中有張常住人員基本信息,兩張表就可以對應上了,當然,有些時候并不一定是意義相同就一定相同,這需要從業務層面去判斷。
l 具備包含意義的表
這種情況通常是目標數據源為一張表,源數據源為多張表,這個時候就形成多對一的關系,例如目標數據源中有張表為物品表,源數據源中為手機、證券等幾張表,這個時候就需要將手機、證券這些表對應到物品表。
又或者可能會碰到這樣的現象,目標數據源為一張表,源數據源也是一張表,但源數據源的這張表的每行記錄包含了目標表的兩種類型的記錄,這種情況下就需要將源數據源的一行記錄拆分為兩條導入到目標表中,例如目標數據源有張表為遷入遷出表,其存儲方式為遷入和遷出都為單獨的記錄來存儲的,源數據源有張表也為遷入遷出表,但其存儲方式為遷入和遷出在同一條記錄,這個時候就要將源數據源的這張遷入遷出表的一行記錄拆分為兩條進行導入了。
l 被包含意義的表
和之上的具備包含意義的表相反。
l 根據業務的對應關系
這張是最為復雜的,例如可能會碰到這樣的現象,當源數據源的某張表的某個字段的值為多個的時候,就需要拆分為兩條記錄導入到目標表中。
綜合上面所述,目標數據源的表和源數據源的表可能會存在一對一、一對多、多對一、多對多、條件式的對應幾種關系,在分析完畢后形成如下的文檔:
|
目標數據源
|
源數據源
|
校驗標準
|
|
A
|
A
|
A.數據量==A.數據量(變動(新增、編輯、刪除)的數據)
|
|
B
|
B
C
|
B.數據量==B.數據量+C.數據量
|
|
C
D
|
D
|
C.數據量+D.數據量=D.數據量
C.數據量=D.數據量(D.wplx=’03’)
D.數據量=D.數據量(D.wplx=’05’)
|
|
E
|
E
|
E.數據量=E.數據量*2
|
|
F
|
F
|
F.數據量=F.數據量/2(F.qrsj=F.qcsj)
|
|
G
|
G
|
G.數據量=G.數據量+G.數據量(G.name包含的,的總數-1)
|
2.1.6. 根據表的對應關系分析字段的對應關系以及轉化規則
在對應了表的對應關系后,根據表的單一對應關系(如目標數據源的B表對應到了源數據源的B、C表,則需要分為B對應B以及B對應C兩個步驟來分析)來分析每個表中的字段的對應關系以及轉化規則了,對應的方法為:
l 先在對應的表中尋找相應的字段
l 如尋找不到則到相關的表中尋找相應的字段
l 如還是尋找不到則需要從業務含義方面去推測
從業務含義角度分析此字段是否需要合并多個字段或拆分字段,又或根據某種業務規則來生成這個字段的值。
在尋找到了相應的字段后,首先根據類型、長度來分析是否需要進行類型和長度的處理,之后需要分析該字段是否為通過關聯到其他表來獲取的,接著再分析此字段是否涉及到字典代碼,如涉及則需要對照兩邊的字典代碼是否一致,如不一致則需要形成兩邊的字典代碼的對應關系,最后分析該字段是否涉及業務含義,如涉及則需注明如何進行處理。
在分析完畢后,形成如下文檔:
表名
|
字段
|
字段類型及長度
|
源數據源字段
|
字段類型及長度
|
轉化規則
|
|
id
|
number(10)
|
表名.id
|
number(10)
|
|
|
unitcode
|
varchar2(19)
|
表名.xzqh+表名.unit
|
Varchar2(8)+varchar2(20)
|
單位代碼字典映射
|
|
content
|
Varchar2(100)
|
Substr(表名.content,0,50)
|
Varchar2(100)
|
|
|
ifmonth
|
Varchar2(1)
|
If(表名.createdate.月份==’系統時間的月份’)
Return ‘1’;
Else
Return ‘2’.
|
|
|
|
unitname
|
Varchar2(100)
|
UnitNames.unitName
|
Varchar2(100)
|
表名.xzqh+表名.unit=UnitNames.UnitCode
|
2.2. 需注意的問題
由于數據集成涉及的為系統中最為重要的基礎—數據,那么在做數據集成時就特別需要仔細考慮不要對數據產生了破壞性的影響,這也是數據分析過程中需要慎重考慮的問題。
2.2.1. 數據覆蓋/混亂的問題
在做數據分析時需要考慮,這樣集成數據后是否會將已存在的數據非法的覆蓋或造出混亂,出現這種問題通常都是由于主鍵的原因,這個在做數據分析時需要考慮。
2.2.2. 制定錯誤出現時的彌補方案
在做數據分析時需要考慮在進行數據集成后可能會出現的錯誤,對于這些可能出現的錯誤需要制定相應的彌補方案,以避免數據的被破壞。
2.2.3. 源數據源數據質量造成的問題的處理方案
需要考慮如源數據源本身的數據質量出現問題時,應如何處理或者如何避免。
2.2.4. 業務專家的支持
在整個數據分析的過程中,可以看出業務專家起到了非常大的作用,可以說如果缺少業務專家的話,數據分析很可能會失敗,或需要走很多的彎路才能最后摸索出來,有一點可以肯定,在缺少業務專家的支持下整個數據分析的過程將會大大的延長,從這點可以看出,在進行數據分析時要盡量獲取到業務專家的支持。
3. 總結
如上的方法論對數據分析的過程和避免問題的方法做出了一定的描述,在實際的進行數據分析時,最重要的還是負責數據分析的人對于系統的理解,有過系統設計經驗的人來做數據分析成功的幾率會高很多,有些非常專業的系統的話還得依賴有相應的設計經驗的人才做才能做得了,類如流程系統的數據集成。
在一個數據分析過程中,已經可以制定出判斷數據集成是否成功的標準了,這也可以列為TDD的入口條件,J。
方法論始終都還是理論,我本來就不是一個那么講理論的人,但也不否認理論對于實際是有很好的指導作用的,避免在實踐過程中走過多的彎路,能做到理論結合實踐那是最好的,理論指導實踐,實踐改進理論。