from:http://zeroturnaround.com/rebellabs/5-command-line-tools-you-should-be-using/
Working on the command line will make you more productive, even on Windows!
There’s an age-old discussion between the usability and friendliness of GUI programs, versus the simplicity and productivity of CLI ones. But this is not a holy war I intend to trigger or fuel. In the past, RebelLabs has discussed built-in JDK tools and received amazing feedback, so I feel an urge to share more non-JDK command line tools which I simply couldn’t live without.
I do firmly believe every developer who’s worth their salt should have at least some notion of how to work with the command line, if only because some tools only exist in CLI variants. Plus, because geek++!
All other nuances that people pour words over, like the choice of operating system (OSX of course, they have beautiful aluminum cases), your favorite shell (really it should be ZSH), or the preference of Vim over Emacs (unless you have more fingers than usual) are much less relevant. OK, that was a little flamewar-like, but I promise that will be the last of it!
So my advice would be that you should learn how to use tools at the command line, as it will have a positive impact on your happiness and productivity at least for half a century!
Anyway, in this post I want to share with you four-five lesser-known yet pretty awesome command line gems. As an added bonus I will also advise the proper way to use shell under Windows, which is a pretty valuable bit of knowledge in itself.
The reason I wanted to write this post in the first place is because I really enjoy using these tools myself, and want to learn about other command line tools that I don’t yet know about. So please, awesome reader, leave me a comment with your favourite CLI tools — that’d be grand! Now, assuming we all have a nice, workable shell, let’s go over some neat command line tools that are worth hearing about.
0. HTTPie
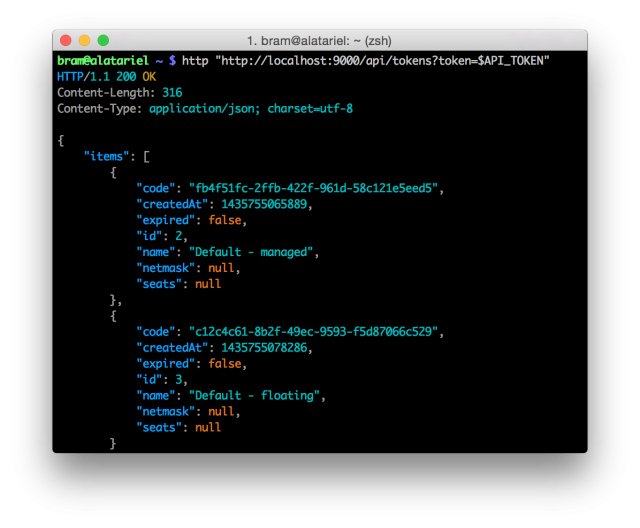
The first on my list is a tool called HTTPie. Fear not, this tool has nothing to do with Internet Explorer, fortunately. In essence HTTPie is a cURL wrapper, the utility that performs HTTP requests from the command line. HTTPie adds nice features like auto-formatting and intelligent colour highlighting to the output making it much more readable and useful to the user. Additionally, it takes a very human-centric approach to its execution, not asking you to remember obscure flags and options. To perform an HTTP GET, you simply run http, to post you http POST, what can be easier or more beautiful?
Almost all command line tools are conveniently packaged for installation. HTTPie is no exception, to install it, run the following command.
- On OSX use homebrew, the best package manager to be found on OSX:
brew install httpie - All other platforms, using Python’s pip:
pip install --upgrade httpie
I personally use HTTPie a lot when developing a REST API, as it allows me to very simply query the API, returning nicely structured, legible data. Without doubt this tool saves me serious work and frustration. Luckily the usage does not stop at just REST APIs. Generally speaking, all interactions over HTTP, whether it’s inputting or outputting data, can be done in a very human-readable format.
I’d encourage you to take a look at the website, spend the 10 seconds it takes to install and give it a go yourself. Try to get the source of any website and be amazed by the output.

Protip: Combine the HTTPie greatness with jq for command line JSON manipulation or pup for HTML parsing and you’ll be unstoppable!
1. Icdiff
At ZeroTurnaround I am blessed to work with Mercurial, a very nice and easy to use VCS. On OSX the excellent GUI program SourceTree makes working with Mercurial an absolute breeze, even with the more complex stuff. Unfortunately I like to keep the number of programs/tabs/windows I have open to an absolute minimum. Since I always have a terminal window opened it makes sense to use the CLI.
All was fine and well apart from one single pitfall in my setup. This was a feature I could barely go without: side-by-side diffs. Introducing icdiff. Of all the tools I use each day, this is the one I most appreciate. Let’s take a look at a screenshot:
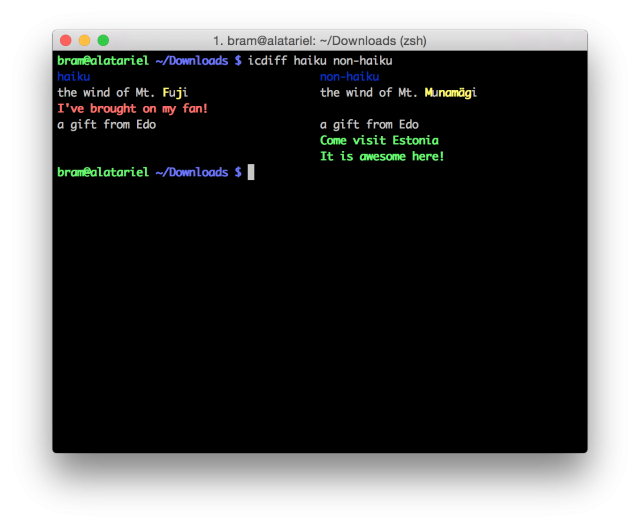
By itself, icdiff is an intelligent Python script, smart at detecting which of the differences are modifications, additions or deletions. The excellent colour highlighting in the tool makes it easy to distinguish between the three types of differences mentioned.
To get going with icdiff, do the following:
- Via homebrew once again:
brew install icdiff - Manually grab the Python script from the site above and put it in your PATH
When you couple icdiff with a VCS such as Mercurial, you’ll see it really shine. To fully integrate it, you’ll need to complete two more configuration steps, already documented here. The gist of the instructions is to first add a wrapping script that allows the one-by-one file diff of icdiff to operate on entire directories. Secondly you need to config your VCS to actually use icdiff. The link above shows the details of configuring it for Mercurial, but porting this to Git shouldn’t be so hard.
2. Pandoc
In the spirit of “practice what you preach” I set out to write this entire blogpost via a CLI. Most of the work was done using MacVim, in iTerm2 on OSX. All of the text was written and formatted using standard MarkDown syntax. The only issue to arise here is that it’s pretty difficult sometimes to accurately guess how your eventual text will come out.
This is where the next tool comes in: Pandoc. A program so powerful and versatile it’s a wonder it was GPL’d in the first place. Let’s take a look at how we might use it.
pandoc -f markdown -t html blogpost.md > blogpost.html
Think of a markup format, any markup format. The chances are, Pandoc can convert it from one format to any other. For example, I’m writing this blogpost in Vim and use Pandoc to convert it from MarkDown into HTML, to actually see the final result. It’s a nice thing, needing only my terminal and a browser, rather than being tied to a particular online platform, fully standalone and offline.
Don’t let yourself be limited by simple formats like MarkDown though, give it some docx files, or perhaps some LaTeX. Export into PDF, epub, let it handle and format your citations. The possibilities are endless.
Once again brew install pandoc does the trick. Did I mention I really like Homebrew? Maybe that should have made my tool list! Anyway, you get the gist of what that does!
3. Moreutils
The next tool in this post is actually a collection of nifty tools that didn’t make it into coreutils:Moreutils. It should be obtainable under moreutils in about any distro you can think of. OSX users can get all this goodness by brewing it like I did throughout this post:
brew install moreutils
Here are a list of the included programs with short descriptions:
- chronic: runs a command quietly unless it fails
- combine: combine the lines in two files using boolean operations
- ifdata: get network interface info without parsing ifconfig output
- ifne: run a program if the standard input is not empty
- isutf8: check if a file or standard input is utf-8
- lckdo: execute a program with a lock held
- mispipe: pipe two commands, returning the exit status of the first
- parallel: run multiple jobs at once
- pee: tee standard input to pipes
- sponge: soak up standard input and write to a file
- ts: timestamp standard input
- vidir: edit a directory in your text editor
- vipe: insert a text editor into a pipe
- zrun: automatically uncompress arguments to command
As the maintainer hints himself sponge is perhaps the most useful tool, in that you can easily sponge up standard input into a file. However, it is not difficult to see the advantages of some of the other commands such as chronic, parallel and pee.
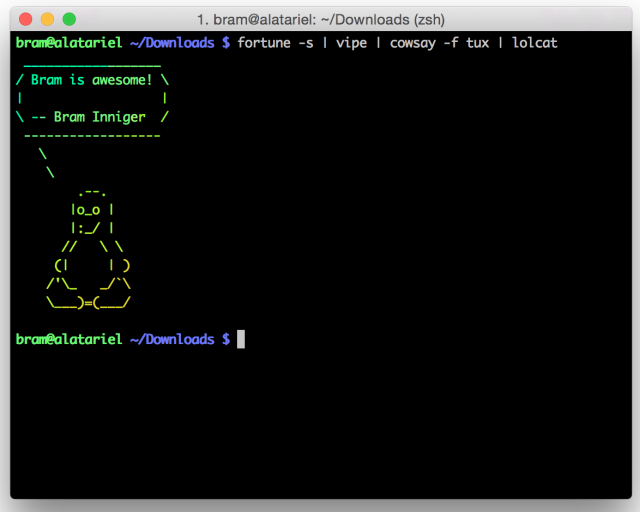
My personal favourite though, and the ultimate reason to include this collection, is without doubtvipe.
You can literally intercept your data as it moves from command to command through the pipe. Even though this is not a useful tool in your scripts, it can be extremely helpful when running commands interactively. Instead of giving you a useful example I will leave you with a modified fortune!
4. Babun
These days the Windows OS comes packaged with two different shells: its classic command line, and PowerShell. Let’s completely ignore those and have a look at the proper way or running command line tools under Windows: Babun! The reason this project is amazingly awesome is because it actually brings all the goodness of the \*NIX command line into Windows in a completely pre-configured no-nonsense manner.
Moreover, its default shell is my beloved ZSH, though it can very easily be changed to use Bash, if that’s your cup of tea. With ZSH it also packages the highly popular oh-my-zsh framework, which combines all the benefits of ZSH with no config whatsoever thanks to some very sane defaults and an impressive plugin system.
By default Babun is loaded with more applications than any sane developer may ever need, and is thus a rather solid 728 MBs(!) when expanded. In return you get essentials like Vim pre-installed and ready to go!
Under the hood Babun is basically a fancy wrapper around Cygwin. If you already have a Cygwin install you can seamlessly re-use that one. Otherwise it will default to its own packaged Cygwin binaries, and supply you with access to those.
Some more points of interest are that Babun provides its own package manager, which again wraps around Cygwin’s, and an update mechanism both for itself and for oh-my-zsh. The best thing is that no actual installation is required, nor is the usual requirement of admin rights necessary, so for those people on a locked down PC this may be just the thing they need!
I hope this small selection of tools gave you at least one new cool toy to play with. As for me, it seems it is time to look at command line browsers before writing a following blogpost, to fully ditch the world of the GUI!
By all means fire up any comments or suggestions that you have, and let’s get some tool-sharing going on. If you just want to chat just ping RebelLabs on Twitter: @ZeroTurnaround, they are pretty chatty, but great smart people.