from:http://huaidan.org/archives/2085.html
一、驗證碼的基本知識
1. 驗證碼的主要目的是強制人機交互來抵御機器自動化攻擊的。
2. 大部分的驗證碼設計者并不得要領,不了解圖像處理,機器視覺,模式識別,人工智能的基本概念。
3. 利用驗證碼,可以發財,當然要犯罪:比如招商銀行密碼只有6位,驗證碼形同虛設,計算機很快就能破解一個有錢的賬戶,很多帳戶是可以網上交易的。
4. 也有設計的比較好的,比如Yahoo,Google,Microsoft等。而國內Tencent的中文驗證碼雖然難,但算不上好。
二、人工智能,模式識別,機器視覺,圖像處理的基本知識
1)主要流程:
比如我們要從一副圖片中,識別出驗證碼;比如我們要從一副圖片中,檢測并識別出一張人臉。 大概有哪些步驟呢?
1.圖像采集:驗證碼呢,就直接通過HTTP抓HTML,然后分析出圖片的url,然后下載保存就可以了。 如果是人臉檢測識別,一般要通過視屏采集設備,采集回來,通過A/D轉操作,存為數字圖片或者視頻頻。
2.預處理:檢測是正確的圖像格式,轉換到合適的格式,壓縮,剪切出ROI,去除噪音,灰度化,轉換色彩空間這些。
3.檢測:車牌檢測識別系統要先找到車牌的大概位置,人臉檢測系統要找出圖片中所有的人臉(包括疑似人臉);驗證碼識別呢,主要是找出文字所在的主要區域。
4.前處理:人臉檢測和識別,會對人臉在識別前作一些校正,比如面內面外的旋轉,扭曲等。我這里的驗證碼識別,“一般”要做文字的切割
5.訓練:通過各種模式識別,機器學習算法,來挑選和訓練合適數量的訓練集。不是訓練的樣本越多越好。過學習,泛化能力差的問題可能在這里出現。這一步不是必須的,有些識別算法是不需要訓練的。
6.識別:輸入待識別的處理后的圖片,轉換成分類器需要的輸入格式,然后通過輸出的類和置信度,來判斷大概可能是哪個字母。識別本質上就是分類。
2)關鍵概念:
圖像處理:一般指針對數字圖像的某種數學處理。比如投影,鈍化,銳化,細化,邊緣檢測,二值化,壓縮,各種數據變換等等。
1.二值化:一般圖片都是彩色的,按照逼真程度,可能很多級別。為了降低計算復雜度,方便后續的處理,如果在不損失關鍵信息的情況下,能將圖片處理成黑白兩種顏色,那就最好不過了。
2.細化:找出圖像的骨架,圖像線條可能是很寬的,通過細化將寬度將為1,某些地方可能大于1。不同的細化算法,可能有不同的差異,比如是否更靠近線條中間,比如是否保持聯通行等。
3.邊緣檢測:主要是理解邊緣的概念。邊緣實際上是圖像中圖像像素屬性變化劇烈的地方。可能通過一個固定的門限值來判斷,也可能是自適應的。門限可能是圖像全局的,也可能是局部的。不能說那個就一定好,不過大部分時候,自適應的局部的門限可能要好點。被分析的,可能是顏色,也可能是灰度圖像的灰度。
機器視覺:利用計算機來模式實現人的視覺。 比如物體檢測,定位,識別。按照對圖像理解的層次的差別,分高階和低階的理解。
模式識別:對事物或者現象的某種表示方式(數值,文字,我們這里主要想說的是數值),通過一些處理和分析,來描述,歸類,理解,解釋這些事物,現象及其某種抽象。
人工智能:這種概念比較寬,上面這些都屬于人工智能這個大的方向。簡單點不要過分學院派的理解就是,把人類的很“智能”的東西給模擬出來協助生物的人來處理問題,特別是在計算機里面。
三、常見的驗證碼的破解分析
以http://libcaca.zoy.org/wiki/PWNtcha這里PWNtcha項目中的資料為例分析,各種驗證碼的破解。(方法很多,僅僅從我個人乍看之下覺得可行的方法來分析)
1)Authimage

使用的反破解技巧:
1.不連續的點組成字符
2.有一定程度的傾斜
設計不好的地方:
1.通過縱橫的直方圖投影,可以找到字幕區域
2.通過Hough變換,適當的參數,可以找到近似的橫線,可以做傾斜矯正
3.字符串的傾斜式面內的,沒有太多的破解難度
4.字母寬度一定,大小一定
2)Clubic

使用的反破解技巧:
1.字符是手寫體
設計不好的地方:
1.檢測切割階段沒有任何技術含量,屬于設計的比較丑的
2.只有數字,而且手寫體變化不大
3.表面看起來對識別階段有難度,仔細分析,發現幾乎不用任何高級的訓練識別算法,就固定的招某些像素點是否有色彩就夠了
3)linuxfr.org

使用的反破解技巧:
1.背景顏色塊
2.前景的橫線或矩形
設計不好的地方:
1.背景色是單一色塊,有形狀,通過Region-Growth區域增長來很容易把背景給去掉
2.前景色是標準的線條,色彩單一
3.字母無粘連
4.都是印刷體
4)Ourcolony

使用的反破解技巧:
1.設計的太低級,不屑于去評價
設計不好的地方:
1.這種驗證碼,設計的最丑,但還是能把菜鳥搞定,畢竟學計算機的少,搞這個破解的更少,正所謂隔行如隔山
5)LiveJournal
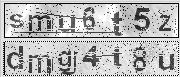
使用的反破解技巧:
1.這個設計略微好點,使用個隨機噪音,而且作為前景
2.字母位置粗細都有變化
設計不好的地方:
1.字母沒有粘連
2.噪音類型單一
3.通過在X軸的直方圖投影,能準確分割字幕
4.然后在Y周作直方圖投影,能準確定位高度
5.識別階段,都是印刷體,簡單地很
四、網上的一些高級驗證碼
1)ICQ

2)IMDb
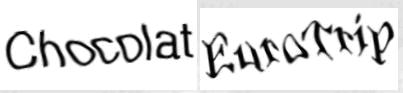
3)MS MVPS

4)MVN Forum

這些類型是被很多人認為比較難得類型,分析一下可以發現,字符檢測,定位和分割都不是難。 唯一影響識別率的是IMDBb和MVPS這兩類,字體變形略大。
總體來說,這些類型的破解也不難,很容易做到50%以上的識別率。
五、高級驗證碼的破解分析
時間關系,我簡單介紹如何利用圖像處理和模式識別技術,自動識別比較高級的驗證碼。
(以風頭正勁的Google為例)

1)至少從目前的AI的發展程度看,沒有簡單的做法能自動處理各種不同的驗證碼,即使能力很強,那么系統自然也十分復雜強大。所以,要想在很簡單的算法實現比較高級的驗證碼破解,必須分析不同驗證碼算法的特點:
作為一般的圖像處理和計算機視覺,會考慮色彩,紋理,形狀等直接的特征,同時也考慮直方圖,灰度等統計特征,還考慮FFT,Wavelet等各種變換后的特征。但最終目標都是Dimension Reduction(降維)然后利于識別,不僅僅是速度的考慮。從圖像的角度看,很多系統都考慮轉換為灰度級甚者黑白圖片。
Google的圖片可以看出,顏色變化是虛晃一槍,不存在任何處理難度。難度是字體變形和字符粘連。
如果能成功的分割字符,那么后期識別無論是用SVM等分類算法,還是分析筆順比劃走向來硬識別,都相對好做。
2)圖像處理和粘連分割
代碼中的part1目錄主要完成圖像預處理和粘連字符分割
001:將圖像從jpg等格式轉換為位圖便于處理
002:采用Fix/Adaptive的Threshold門限算法,將圖片Bin-Value二值化。
(可用003算法)
003:采用OSTU分水嶺算法,將圖片Bin-Value二值化。
(更通用,大部分時候效果更好)
005:獲取ROI感興趣的區域。
006:Edge Trace邊緣跟蹤。
007:Edge Detection邊界檢測。
008:Thin細化去骨架。
009:做了一些Tidy整理。
(這個一般要根據特定的Captcha算法調整)
010:做切割,注意圖片中紅色的交叉點。
011:將邊緣檢測和骨干交叉點監測的圖像合并。
(合并過程可以做分析: 比如X坐標偏移門限分析,交叉點區域紋理分析,線條走勢分析,等等各種方法,找出更可能的切分點和分離后部件的組合管理。)
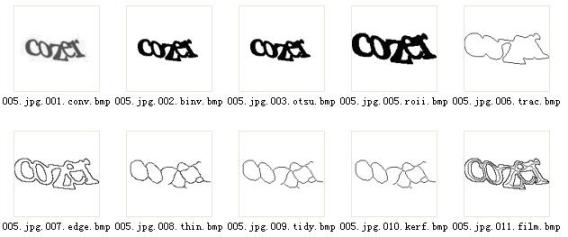
代碼:(代碼質量不高,從其他項目拷貝過來,簡單修改的。)
查看代碼(./pstzine_09_01.txt)
注: 在這里,我們可以看到,基本的部件(字母是分割開了,但可以造成統一字母的被切割成多個Component。 一種做法是:利用先驗知識,做分割; 另外一種做法是,和第二部分的識別結合起來。 比如按照從左至右,嘗試增加component來識別,如果不能識別而且component的總寬度,總面積還比較小,繼續增加。 當然不排除拒識的可能性。 )
3)字符部件組合和識別。
part2的代碼展示了切割后的字母組合,和基于svm的字符識別的訓練和識別過程。Detection.cpp中展示了ImageSpam檢測過程中的一些字符分割和組合,layout的分析和利用的簡單技術。 而Google的驗證碼的識別,完全可以不用到,僅做參考。
SVM及使用:
本質上,SVM是一個分類器,原始的SVM是一個兩類分類的分類器。可以通過1:1或者1:n的方式來組合成一個多類分類的分類器。 天生通過核函數的使用支持高維數據的分類。從幾何意義上講,就是找到最能表示類別特征的那些向量(支持向量SV),然后找到一條線,能最大化分類的Margin。
libSVM是一個不錯的實現。
訓練間斷和識別階段的數據整理和歸一化是一樣的。 這里的簡單做法是:
首先:
#define SVM_MAX +0.999
#define SVM_MIN +0.001
其次:
掃描黑白待識別字幕圖片的每個像素,如果為0(黑色,是字母上的像素),那么svm中該位置就SVM_MAX,反之則反。
最后:
訓練階段,在svm的input的前面,為該類打上標記,即是那一個字母。
識別階段,當然這個類別標記是SVM分類出來。
注意:
如果是SVM菜鳥,最好找一個在SVM外邊做了包裝的工具,比如樣本選擇,交叉驗證,核函數選擇這些,讓程序自動選擇和分析。
代碼:通過ReginGrowth來提取單個單個的字符,然后開始識別。
查看代碼(./pstzine_09_02.txt)
六、對驗證碼設計的一些建議
1.在噪音等類型的使用上,盡力讓字符和用來混淆的前景和背景不容易區分。盡力讓壞人(噪音)長得和好人(字母)一樣。
2.特別好的驗證碼的設計,要盡力發揮人類擅長而AI算法不擅長的。 比如粘連字符的分割和手寫體(通過印刷體做特別的變形也可以)。 而不要一味的去加一些看起來比較復雜的噪音或者其他的花哨的東西。即使你做的足夠復雜,但如果人也難識別,顯然別人認為你是沒事找抽型的。
3. 從專業的機器視覺的角度說,驗證碼的設計,一定要讓破解者在識別階段,反復在低階視覺和高階視覺之間多反復幾次才能識別出來。 這樣可以大大降低破解難度和破解的準確率。
七、個人鄭重申明
1.這個問題,本身是人工智能,計算機視覺,模式識別領域的一個難題。我是蝦米,菜得不能再菜的那種。作為破解者來說,是出于劣勢地位。要做的很好,是很難得。總體來說,我走的是比較學院派的線路,能真正的破解難度比較高的驗證碼,不同于網上很多不太入流的破解方法。我能做的只有利用有限的知識,拋磚引玉而已。 很多OCR的技術,特別是離線手寫體中文等文字識別的技術,個人了解有限的很,都不敢在這里亂寫。
2.希望不要把這種技術用于非法用途。