使用SQL Server Profile GUI工具還是很多優(yōu)勢,首先是減少了我們監(jiān)控的復(fù)雜性,可以款速的建立監(jiān)控,在跟蹤屬性中,可以可以選擇MSSQL為我們提供的模版,包括常用的T-SQL、T-SQL Duration、T-SQL Locks模版分別監(jiān)控當前DB運行的所有查詢,所有查詢的耗時、所有的鎖定狀態(tài)。
在跟蹤屬性 –> 選擇事件選擇 我們可以選擇自己需要的事件,所有的事件在MSDN 都有定義->單擊列篩選器 可以自定義過濾,排序噪點干擾因素
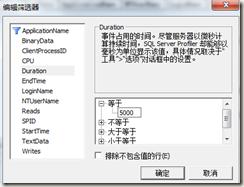
(我隨便選擇了一個耗時 = 500 微妙的過濾條件)
其他的模版大家可以自己看看MSDN 手冊,自己嘗試一下:SQL Server 2008 R2 本機 MSDN
服務(wù)器端跟蹤和物理方式收集
SQL Server Profile 只是對一些存儲過程的封裝,我更傾向于,自己定義常用的腳本,將監(jiān)控結(jié)果保存在本機,用來大量的分析和存檔。
當然涉及4個存儲過程,雖然設(shè)置過濾的腳本非常麻煩,但是SQL Server Profile 可以利用 文件->導(dǎo)出 可以導(dǎo)出監(jiān)控腳本意味著,我們不需要編寫復(fù)雜的T-SQL 腳本,不過還是建議大家熟悉這幾個存儲過程:
sp_trace_create 定義跟蹤 ,創(chuàng)建的跟蹤會在sys.traces查詢的到。
s_trace_setevent 設(shè)置監(jiān)控事件
sp_trace_setfilter 設(shè)置過濾
sp_trace_setstatus 設(shè)置跟蹤的狀態(tài) 常用的是 sp_trace_setstatus @traceid,0 停止功能 、sp_trace_setstatus @traceid,2 移除跟蹤,這將導(dǎo)致sys.traces最終查詢不到該跟蹤
其實整個跟蹤還是比較簡單的。我這里有一個常用的腳本:
用來 監(jiān)控超過指定秒數(shù) 和 數(shù)據(jù)庫 的 批處理和存儲過程 語句(超過5MB的文件,會執(zhí)行ROLLOVER,根據(jù)文件名在后面添加類似_1,_2.trc的跟蹤結(jié)果):
以下是代碼片段:
CREATE PROC [dbo].[sp_trace_sql_durtion] @DatabaseName nvarchar(128), @Seconds bigint, @FilePath nvarchar(260) AS BEGIN DECLARE @rc int,@TraceID int,@MaxFileSize bigint; SET @MaxFileSize = 5; EXEC sp_trace_create @TraceID OUTPUT,2,@FilePath,@MaxFileSize,NULL; IF @rc != 0 RETURN; DECLARE @On bit; SET @On = 1; EXEC sp_trace_setevent @TraceID,10,35,@On; EXEC sp_trace_setevent @TraceID,10,1,@On; EXEC sp_trace_setevent @TraceID,10,13,@On; EXEC sp_trace_setevent @TraceID,41,35,@On; EXEC sp_trace_setevent @TraceID,41,1,@On; EXEC sp_trace_setevent @TraceID,41,13,@On; SET @Seconds = @Seconds * 1000000; EXEC sp_trace_setfilter @TraceID,13,0,4,@Seconds; IF @DatabaseName IS NOT NULL EXEC sp_trace_setfilter @TraceID,35,0,0,@DatabaseName EXEC sp_trace_setstatus @TraceID,1 SELECT TraceID = @TraceID; END |
參數(shù)非常的明了,數(shù)據(jù)庫名稱、執(zhí)行事件超過多少秒、保存的路徑。
當我們運行這個腳本一段事件以后,可以快速的發(fā)現(xiàn)大量耗時的T-SQL,我們可以通過
SELECT * FROM fn_trace_gettable(N'監(jiān)控文件路徑',1);
來查看行方式的結(jié)果。
同樣的富有創(chuàng)造力的讀者可以自己創(chuàng)建監(jiān)控鎖定,監(jiān)控死鎖等方式保存文件,但是我的建議是盡可能的減少噪音,也就是說我們要達到什么目地就在《Microsfot SQL Server 2005 技術(shù)內(nèi)幕: T-SQL 程序設(shè)計》 中有一個正則,用來將類似的語句全部組合成,只有參數(shù)形式替換具體值的SQL CLR,但是我認為那個正則還有bug,等我空了給大家寫一個,自己也能使用的更完善。
使用SQL Server Profile GUI工具還是很多優(yōu)勢,首先是減少了我們監(jiān)控的復(fù)雜性,可以款速的建立監(jiān)控,在跟蹤屬性中,可以可以選擇MSSQL為我們提供的模版,包括常用的T-SQL、T-SQL Duration、T-SQL Locks模版分別監(jiān)控當前DB運行的所有查詢,所有查詢的耗時、所有的鎖定狀態(tài)。
在跟蹤屬性 –> 選擇事件選擇 我們可以選擇自己需要的事件,所有的事件在MSDN 都有定義->單擊列篩選器 可以自定義過濾,排序噪點干擾因素
(我隨便選擇了一個耗時 = 500 微妙的過濾條件)
其他的模版大家可以自己看看MSDN 手冊,自己嘗試一下:SQL Server 2008 R2 本機 MSDN
服務(wù)器端跟蹤和物理方式收集
SQL Server Profile 只是對一些存儲過程的封裝,我更傾向于,自己定義常用的腳本,將監(jiān)控結(jié)果保存在本機,用來大量的分析和存檔。
當然涉及4個存儲過程,雖然設(shè)置過濾的腳本非常麻煩,但是SQL Server Profile 可以利用 文件->導(dǎo)出 可以導(dǎo)出監(jiān)控腳本意味著,我們不需要編寫復(fù)雜的T-SQL 腳本,不過還是建議大家熟悉這幾個存儲過程:
sp_trace_create 定義跟蹤 ,創(chuàng)建的跟蹤會在sys.traces查詢的到。
s_trace_setevent 設(shè)置監(jiān)控事件
sp_trace_setfilter 設(shè)置過濾
sp_trace_setstatus 設(shè)置跟蹤的狀態(tài) 常用的是 sp_trace_setstatus @traceid,0 停止功能 、sp_trace_setstatus @traceid,2 移除跟蹤,這將導(dǎo)致sys.traces最終查詢不到該跟蹤
其實整個跟蹤還是比較簡單的。我這里有一個常用的腳本:
用來 監(jiān)控超過指定秒數(shù) 和 數(shù)據(jù)庫 的 批處理和存儲過程 語句(超過5MB的文件,會執(zhí)行ROLLOVER,根據(jù)文件名在后面添加類似_1,_2.trc的跟蹤結(jié)果):
以下是代碼片段:
CREATE PROC [dbo].[sp_trace_sql_durtion] @DatabaseName nvarchar(128), @Seconds bigint, @FilePath nvarchar(260) AS BEGIN DECLARE @rc int,@TraceID int,@MaxFileSize bigint; SET @MaxFileSize = 5; EXEC sp_trace_create @TraceID OUTPUT,2,@FilePath,@MaxFileSize,NULL; IF @rc != 0 RETURN; DECLARE @On bit; SET @On = 1; EXEC sp_trace_setevent @TraceID,10,35,@On; EXEC sp_trace_setevent @TraceID,10,1,@On; EXEC sp_trace_setevent @TraceID,10,13,@On; EXEC sp_trace_setevent @TraceID,41,35,@On; EXEC sp_trace_setevent @TraceID,41,1,@On; EXEC sp_trace_setevent @TraceID,41,13,@On; SET @Seconds = @Seconds * 1000000; EXEC sp_trace_setfilter @TraceID,13,0,4,@Seconds; IF @DatabaseName IS NOT NULL EXEC sp_trace_setfilter @TraceID,35,0,0,@DatabaseName EXEC sp_trace_setstatus @TraceID,1 SELECT TraceID = @TraceID; END |
參數(shù)非常的明了,數(shù)據(jù)庫名稱、執(zhí)行事件超過多少秒、保存的路徑。
當我們運行這個腳本一段事件以后,可以快速的發(fā)現(xiàn)大量耗時的T-SQL,我們可以通過
SELECT * FROM fn_trace_gettable(N'監(jiān)控文件路徑',1);
來查看行方式的結(jié)果。
同樣的富有創(chuàng)造力的讀者可以自己創(chuàng)建監(jiān)控鎖定,監(jiān)控死鎖等方式保存文件,但是我的建議是盡可能的減少噪音,也就是說我們要達到什么目地就在《Microsfot SQL Server 2005 技術(shù)內(nèi)幕: T-SQL 程序設(shè)計》 中有一個正則,用來將類似的語句全部組合成,只有參數(shù)形式替換具體值的SQL CLR,但是我認為那個正則還有bug,等我空了給大家寫一個,自己也能使用的更完善。
監(jiān)控異常
在上個系列中,講述了具體的SQL Event抓去的異常,可以及時通知,但是具體的異常信息,并不是特別詳細。因此我們可以選擇事件中的Error來添加有關(guān)T-SQL批處理和SP的所有異常,用于分析,這個跟蹤非常有利于我們監(jiān)控一些異常情況!!!我創(chuàng)建了一個跟蹤的腳本,和上面的跟蹤事件的腳本一樣,超過5MB RollOver。我們要定期的執(zhí)行這個跟蹤,雖然不建議長期開啟,但是定期監(jiān)控處理異常是有利我們系統(tǒng)更加長時間運作的。
以下是代碼片段:
CREATE PROC [dbo].[sp_trace_sql_exception] @FilePath nvarchar(260) AS DECLARE @rc int,@TraceID int,@Maxfilesize bigint SET @maxfilesize = 5 EXEC @rc = sp_trace_create @TraceID output, 2, @FilePath, @Maxfilesize, NULL IF (@rc != 0) RETURN; DECLARE @on bit SET @on = 1 EXEC sp_trace_setevent @TraceID, 33, 1, @on EXEC sp_trace_setevent @TraceID, 33, 14, @on EXEC sp_trace_setevent @TraceID, 33, 51, @on EXEC sp_trace_setevent @TraceID, 33, 12, @on EXEC sp_trace_setevent @TraceID, 11, 2, @on EXEC sp_trace_setevent @TraceID, 11, 14, @on EXEC sp_trace_setevent @TraceID, 11, 51, @on EXEC sp_trace_setevent @TraceID, 11, 12, @on EXEC sp_trace_setevent @TraceID, 13, 1, @on EXEC sp_trace_setevent @TraceID, 13, 14, @on EXEC sp_trace_setevent @TraceID, 13, 51, @on EXEC sp_trace_setevent @TraceID, 13, 12, @on DECLARE @intfilter int,@bigintfilter bigint; EXEC sp_trace_setstatus @TraceID, 1 SELECT TraceID=@TraceID GOTO finish ERROR: SELECT ErrorCode=@rc FINISH: |
定期執(zhí)行吧,同志們,找異常。。。
默認跟蹤和黑盒跟蹤
在sys.traces中的TraceID = 1的跟蹤是SQL Server 默認跟蹤,這個跟蹤比較輕量級,一般監(jiān)控服務(wù)器的啟用停止,對象的創(chuàng)建和刪除,日志和數(shù)據(jù)文件自動增長以及其他數(shù)據(jù)庫的變化。(監(jiān)控那些沒事刪錯了表的人,是最好的,當然前提不要都使用一個帳號!)
可以通過
以下是代碼片段:
EXEC sp_configure 'default trace enabled',0; RECONFIGURE WITH OVERRIDE; |
來關(guān)閉默認跟蹤。
黑盒跟蹤,就是可以幫助我們診斷數(shù)據(jù)庫沒事自個奔了的異常,在MSDN 搜索sp_create_trace的時候應(yīng)該也發(fā)現(xiàn)了

的選項,那么我們也能創(chuàng)建一個類似的存儲過程來快速的創(chuàng)建黑盒跟蹤,幫助我們診斷一些異常!
以下是代碼片段:
CREATE PROCEDURE sp_trace_blackbox @FilePath nvarchar(260) AS BEGIN DECLARE @TraceID int,@MaxFileSize bigint SET @MaxFileSize = 25; EXEC sp_trace_create @TraceID OUTPUT,8,@FilePath,@MaxFileSize EXEC sp_trace_setstatus @TraceID,1; END |
我這里提供@FilePath = NULL參數(shù),這個默認就保存在SQL Server的數(shù)據(jù)文件夾中。
結(jié)尾
這里詳細的描述了SQL Server Trace 的各種功能特性,有興趣的朋友可以深入到MSDN研究監(jiān)控,我這是也只是一筆帶過,也參考了MSDN 和《Microsoft SQL Server 2005調(diào)優(yōu)》那本書,下面的監(jiān)控可能和大家講述 DDL觸發(fā)器監(jiān)控,C2審核以及SQL Server的事件通知(涉及的Service Broker我會開一個系列和大家詳細說說Service Broker),最后的結(jié)束可能就是說說2008的數(shù)據(jù)收集監(jiān)控