數據類型
Java虛擬機中,數據類型可以分為兩類:基本類型和引用類型。基本類型的變量保存原始值,即:他代表的值就是數值本身;而引用類型的變量保存引用值。“引用值”代表了某個對象的引用,而不是對象本身,對象本身存放在這個引用值所表示的地址的位置。
基本類型包括:byte,short,int,long,char,float,double,Boolean,returnAddress
引用類型包括:類類型,接口類型和數組。
堆與棧
堆和棧是程序運行的關鍵,很有必要把他們的關系說清楚。
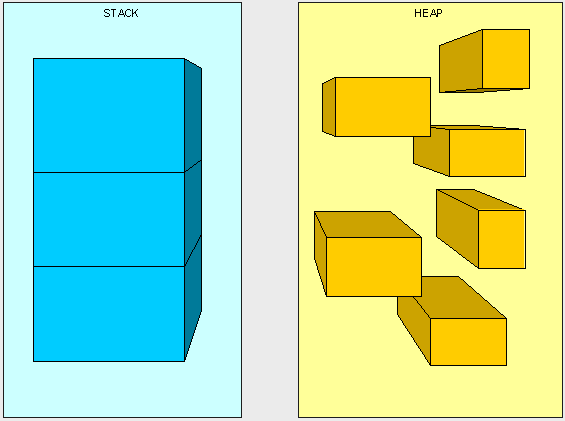
棧是運行時的單位,而堆是存儲的單位。
棧解決程序的運行問題,即程序如何執行,或者說如何處理數據;堆解決的是數據存儲的問題,即數據怎么放、放在哪兒。
在Java中一個線程就會相應有一個線程棧與之對應,這點很容易理解,因為不同的線程執行邏輯有所不同,因此需要一個獨立的線程棧。而堆則是所有線程共享的。棧因為是運行單位,因此里面存儲的信息都是跟當前線程(或程序)相關信息的。包括局部變量、程序運行狀態、方法返回值等等;而堆只負責存儲對象信息。
為什么要把堆和棧區分出來呢?棧中不是也可以存儲數據嗎?
第一,從軟件設計的角度看,棧代表了處理邏輯,而堆代表了數據。這樣分開,使得處理邏輯更為清晰。分而治之的思想。這種隔離、模塊化的思想在軟件設計的方方面面都有體現。
第二,堆與棧的分離,使得堆中的內容可以被多個棧共享(也可以理解為多個線程訪問同一個對象)。這種共享的收益是很多的。一方面這種共享提供了一種有效的數據交互方式(如:共享內存),另一方面,堆中的共享常量和緩存可以被所有棧訪問,節省了空間。
第三,棧因為運行時的需要,比如保存系統運行的上下文,需要進行地址段的劃分。由于棧只能向上增長,因此就會限制住棧存儲內容的能力。而堆不同,堆中的對象是可以根據需要動態增長的,因此棧和堆的拆分,使得動態增長成為可能,相應棧中只需記錄堆中的一個地址即可。
第四,面向對象就是堆和棧的完美結合。其實,面向對象方式的程序與以前結構化的程序在執行上沒有任何區別。但是,面向對象的引入,使得對待問題的思考方式發生了改變,而更接近于自然方式的思考。當我們把對象拆開,你會發現,對象的屬性其實就是數據,存放在堆中;而對象的行為(方法),就是運行邏輯,放在棧中。我們在編寫對象的時候,其實即編寫了數據結構,也編寫的處理數據的邏輯。不得不承認,面向對象的設計,確實很美。
在Java中,Main函數就是棧的起始點,也是程序的起始點。
程序要運行總是有一個起點的。同C語言一樣,java中的Main就是那個起點。無論什么java程序,找到main就找到了程序執行的入口:)
堆中存什么?棧中存什么?
堆中存的是對象。棧中存的是基本數據類型和堆中對象的引用。一個對象的大小是不可估計的,或者說是可以動態變化的,但是在棧中,一個對象只對應了一個4btye的引用(堆棧分離的好處:))。
為什么不把基本類型放堆中呢?因為其占用的空間一般是1~8個字節——需要空間比較少,而且因為是基本類型,所以不會出現動態增長的情況——長度固定,因此棧中存儲就夠了,如果把他存在堆中是沒有什么意義的(還會浪費空間,后面說明)。可以這么說,基本類型和對象的引用都是存放在棧中,而且都是幾個字節的一個數,因此在程序運行時,他們的處理方式是統一的。但是基本類型、對象引用和對象本身就有所區別了,因為一個是棧中的數據一個是堆中的數據。最常見的一個問題就是,Java中參數傳遞時的問題。
Java中的參數傳遞時傳值呢?還是傳引用?
要說明這個問題,先要明確兩點:
1、不要試圖與C進行類比,Java中沒有指針的概念
2、程序運行永遠都是在棧中進行的,因而參數傳遞時,只存在傳遞基本類型和對象引用的問題。不會直接傳對象本身。
明確以上兩點后。Java在方法調用傳遞參數時,因為沒有指針,所以它都是進行傳值調用(這點可以參考C的傳值調用)。因此,很多書里面都說Java是進行傳值調用,這點沒有問題,而且也簡化的C中復雜性。
但是傳引用的錯覺是如何造成的呢?在運行棧中,基本類型和引用的處理是一樣的,都是傳值,所以,如果是傳引用的方法調用,也同時可以理解為“傳引用值”的傳值調用,即引用的處理跟基本類型是完全一樣的。但是當進入被調用方法時,被傳遞的這個引用的值,被程序解釋(或者查找)到堆中的對象,這個時候才對應到真正的對象。如果此時進行修改,修改的是引用對應的對象,而不是引用本身,即:修改的是堆中的數據。所以這個修改是可以保持的了。
對象,從某種意義上說,是由基本類型組成的。可以把一個對象看作為一棵樹,對象的屬性如果還是對象,則還是一顆樹(即非葉子節點),基本類型則為樹的葉子節點。程序參數傳遞時,被傳遞的值本身都是不能進行修改的,但是,如果這個值是一個非葉子節點(即一個對象引用),則可以修改這個節點下面的所有內容。
堆和棧中,棧是程序運行最根本的東西。程序運行可以沒有堆,但是不能沒有棧。而堆是為棧進行數據存儲服務,說白了堆就是一塊共享的內存。不過,正是因為堆和棧的分離的思想,才使得Java的垃圾回收成為可能。
Java中,棧的大小通過-Xss來設置,當棧中存儲數據比較多時,需要適當調大這個值,否則會出現java.lang.StackOverflowError異常。常見的出現這個異常的是無法返回的遞歸,因為此時棧中保存的信息都是方法返回的記錄點。
Java對象的大小
基本數據的類型的大小是固定的,這里就不多說了。對于非基本類型的Java對象,其大小就值得商榷。
在Java中,一個空Object對象的大小是8byte,這個大小只是保存堆中一個沒有任何屬性的對象的大小。看下面語句:
| Object ob = new Object(); |
這樣在程序中完成了一個Java對象的生命,但是它所占的空間為:4byte+8byte。4byte是上面部分所說的Java棧中保存引用的所需要的空間。而那8byte則是Java堆中對象的信息。因為所有的Java非基本類型的對象都需要默認繼承Object對象,因此不論什么樣的Java對象,其大小都必須是大于8byte。
有了Object對象的大小,我們就可以計算其他對象的大小了。
- Class NewObject {
- int count;
- boolean flag;
- Object ob;
- }
- //其大小為:空對象大小(8byte)+int大小(4byte)+Boolean大小(1byte)+空Object引用的大小(4byte)=17byte。
- 但是因為Java在對對象內存分配時都是以8的整數倍來分,因此大于17byte的最接近8的整數倍的是24,因此此對象的大
- 小為24byte。
|
這里需要注意一下基本類型的包裝類型的大小。因為這種包裝類型已經成為對象了,因此需要把他們作為對象來看待。包裝類型的大小至少是12byte(聲明一個空Object至少需要的空間),而且12byte沒有包含任何有效信息,同時,因為Java對象大小是8的整數倍,因此一個基本類型包裝類的大小至少是16byte。這個內存占用是很恐怖的,它是使用基本類型的N倍(N>2),有些類型的內存占用更是夸張(隨便想下就知道了)。因此,可能的話應盡量少使用包裝類。在JDK5.0以后,因為加入了自動類型裝換,因此,Java虛擬機會在存儲方面進行相應的優化。
引用類型
對象引用類型分為強引用、軟引用、弱引用和虛引用。
強引用:就是我們一般聲明對象是時虛擬機生成的引用,強引用環境下,垃圾回收時需要嚴格判斷當前對象是否被強引用,如果被強引用,則不會被垃圾回收
軟引用:軟引用一般被做為緩存來使用。與強引用的區別是,軟引用在垃圾回收時,虛擬機會根據當前系統的剩余內存來決定是否對軟引用進行回收。如果剩余內存比較緊張,則虛擬機會回收軟引用所引用的空間;如果剩余內存相對富裕,則不會進行回收。換句話說,虛擬機在發生OutOfMemory時,肯定是沒有軟引用存在的。
弱引用:弱引用與軟引用類似,都是作為緩存來使用。但與軟引用不同,弱引用在進行垃圾回收時,是一定會被回收掉的,因此其生命周期只存在于一個垃圾回收周期內。
強引用不用說,我們系統一般在使用時都是用的強引用。而“軟引用”和“弱引用”比較少見。他們一般被作為緩存使用,而且一般是在內存大小比較受限的情況下做為緩存。因為如果內存足夠大的話,可以直接使用強引用作為緩存即可,同時可控性更高。因而,他們常見的是被使用在桌面應用系統的緩存。
摘要: 我竟然到現在才發現《Fundamental Networking in Java》這本神作,真有點無地自容的感覺。最近幾年做的都是所謂的企業級開發,免不了和網絡打交道,但在實際工作中,往往會采用框架將底層細節和上層應用隔離開,感覺就像是在一個 Word 模板表單里面填寫內容,做出來也沒什么成就感。雖然沒有不使用框架的理由,但我還真是有點懷念當初直接用套接字做網絡編程的日子,既能掌控更多東西,還可以...
閱讀全文
數據庫是Web大多數應用開發的基礎。如果你是用PHP,那么大多數據庫用的是MYSQL也是LAMP架構的重要部分。
PHP看起來很簡單,一個初學者也可以幾個小時內就能開始寫函數了。但是建立一個穩定、可靠的數據庫確需要時間和經驗。下面就是一些這樣的經驗,不僅僅是MYSQL,其他數據庫也一樣可以參考。
1、使用MyISAM而不是InnoDB
MySQL有很多的數據庫引擎,單一般也就用MyISAM和InnoDB。
MyISAM 是默認使用的。但是除非你是建立一個非常簡單的數據庫或者只是實驗性的,那么到大多數時候這個選擇是錯誤的。MyISAM不支持外鍵的約束,這是保證數據完整性的精華所在啊。另外,MyISAM會在添加或者更新數據的時候將整個表鎖住,這在以后的擴展性能上會有很大的問題。
解決辦法很簡單:使用InnoDB。
2、使用PHP的mysql方法
PHP從一開始就提供了MySQL的函數庫。很多程序都依賴于mysql_connect、mysql_query、mysql_fetch_assoc等等,但是PHP手冊中建議:
如果你使用的MySQL版本在4.1.3之后,那么強烈建議使用mysqli擴展。
mysqli,或者說MySQL的高級擴展,有一些優點:
有面向對象的接口
prepared statements(預處理語句,可以有效防止SQL-注入攻擊,還能提高性能)
支持多種語句和事務
另外,如果你想支持多數據庫那么應該考慮一下PDO。
3、不過濾用戶輸入
應該是:永遠別相信用戶的輸入。用后端的PHP來校驗過濾每一條輸入的信息,不要相信Javascript。像下面這樣的SQL語句很容易就會被攻擊:
- $username = $_POST["name"];
- $password = $_POST["password"];
- $sql = "SELECT userid FROM usertable WHERE username='$username'AND password='$password';"; // run query...
|
這樣的代碼,如果用戶輸入”admin’;”那么,就相當于下面這條了:
| SELECT userid FROM usertable WHERE username='admin'; |
這樣入侵者就能不輸入密碼,就通過admin身份登錄了。
4、不使用UTF-8
那些英美國家的用戶,很少考慮語言的問題,這樣就造成很多產品就不能在其他地方通用。還有一些GBK編碼的,也會有很多的麻煩。
UTF-8解決了很多國際化的問題。雖然PHP6才能比較完美的解決這個問題,但是也不妨礙你將MySQL的字符集設置為UTF-8。
5、該用SQL的地方使用PHP
如果你剛接觸MySQL,有時候解決問題的時候可能會先考慮使用你熟悉的語言來解決。這樣就可能造成一些浪費和性能比較差的情況。比如:計算平均值的時候不適用MySQL原生的AVG()方法,而是用PHP將所有值循環一遍然后累加計算平均值。
另外還要注意SQL查詢中的PHP循環。通常,在取得所有結果之后再用PHP來循環的效率更高。
一般在處理大量數據的時候使用強有力的數據庫方法,更能提高效率。
6、不優化查詢
99%的PHP性能問題都是數據庫造成的,一條糟糕的SQL語句可能讓你的整個程序都非常慢。MySQL的EXPLAIN statement,Query Profiler,many other tools的這些工具可以幫你找出那些調皮的SELECT。
7、使用錯誤的數據類型
MySQL提供一系列數字、字符串、時間等的數據類型。如果你想存儲日期,那么就是用DATE或者DATETIME類型,使用整形或者字符串會讓事情更加復雜。
有時候你想用自己定義的數據類型,例如,使用字符串存儲序列化的PHP對象。數據庫的添加可能很容易,但是這樣的話,MySQL就會變得很笨重,而且以后可能導致一些問題。
8、在SELECT查詢中使用*
不要使用*在表中返回所有的字段,這會非常的慢。你只需要取出你需要的數據字段。如果你需要取出所有的字段,那么可能你的表需要更改了。
9、索引不足或者過度索引
一般來說,應該索引出現在SELECT語句中WHERE后面所有的字段。
例如,假如我們的用戶表有一個數字的ID(主鍵)和email地址。登錄之后,MySQL應該通過email找到相應的ID。通過索引,MySQL可以通過搜索算法很快的定位email。如果沒有索引,MySQL就需要檢查每一項記錄直到找到。
這樣的話,你可能想給每一個字段都添加索引,但是這樣做的后果就是在你更新或者添加的時候,索引就會重新做一遍,當數據量大的時候,就會有性能問題。所以,只在需要的字段做索引。
10、不備份
也許不常發生,但是數據庫損毀,硬盤壞了、服務停止等等,這些都會對數據造成災難性的破壞。所以你一定要確保自動備份數據或者保存副本。
11、另外:不考慮其他數據庫
MySQL可能是PHP用的最多的數據庫了,但是也不是唯一的選擇。 PostgreSQL和Firebird也是競爭者,他們都開源,而且不被某些公司所控制。微軟提供SQL Server Express,Oracle有10g Express,這些企業級的也有免費版。SQLite對于一些小型的或者嵌入式應用來說也是不錯的選擇。
以前學習面向對象的時候,常聽到介紹對象之間的各種關系,常見的有關聯,組合與聚合。
關聯:
關聯是一種最普遍和常見的關系形式。一般是指一個對象可以發消息給另外一個對象。典型的實現情況下指某個對象有一個指針或者引用指向一個實體變量,當通過方法的參數來傳遞或者創建本地變量來訪問這種情況也可以稱之為關聯。
典型的代碼如下:
- class A
- {
- private B itemB;
- }
|
也可能有如下的形式:
- class A
- {
- void test(B b) {...}
- }
|
籠統的情況下,一般兩個對象的引用,參數傳遞等形式產生的關系,我們都可以稱之為關聯關系。
聚合(aggregation):
聚合表示的是一種has-a的關系,同時,它也是一種整體-部分關系。它的特點在于,它這個部分的生命周期并不由整體來管理。也就是說,當整體這個對象已經不存在的時候,部分的對象還是可能繼續存在的。它的uml圖表示形式如下:

我們用一個空心的箭頭來表示聚合關系。
籠統的說聲明周期管理還是比較模糊。我們就以如圖的Person和Address類來進一步的解釋。假設我們要定義這兩個對象,對于每個人來說,他有一個關聯的地址。人和地址的關系是has-a的關系。但是,我們不能說這個地址是這個人的一個組成部分。同時,我們建立地址對象和人的對象是可以相對獨立存在的。
用代碼來表示的話,典型的代碼樣式如下:
- public class Address
- {
- . . .
- }
- public class Person
- {
- private Address address;
- public Person(Address address)
- {
- this.address = address;
- }
- . . .
- }
|
我們通常通過如下的方式來使用Person對象:
- Address address = new Address();
- Person person = new Person(address);
|
或者:
| Person person = new Person( new Address() ); |
我們可以看到,我們是創建了一個獨立的Address對象,然后將這個對象傳入了Person的構造函數。當Person對象聲明周期結束的時候,Address對象如果還有其他指向它的引用,是可能繼續存在的。也就是說,他們的聲明周期是相對獨立的。
組合(Composition):
當理解了聚合的關系之后,再來看組合的關系就相對來說要好很多。和聚合比起來,組合是一種更加嚴格的has-a關系。它表示一種嚴格的組成關系。以汽車和引擎為例子,引擎是汽車的一個組成部分。他們是一種嚴格的部分組成關系,因此他們的聲明周期也應該是一致的。也就是說引擎的聲明周期是通過汽車對象來管理。
組合的uml圖表示如下:

一般用一個實心的箭頭表示組合。
組合代碼的典型示例如下:
- public class Engine
- {
- . . .
- }
-
- public class Car
- {
- Engine e = new Engine();
- .......
- }
|
Engine對象是在Car對象里面創建的,所以在Car對象生命周期結束的時候,Engine對象的生命周期也同樣結束了。
http://wenku.baidu.com/view/43d702600b1c59eef8c7b4fb.html
http://baike.baidu.com/view/1094245.htm
http://down.51cto.com/data/241953
“青花瓷Java版”為北京師范大學教育學部蔡蘇作詞原創,覆蓋教育技術學院專業選修課《面向對象程序設計》教學大綱中的所有知識點。
視頻:http://player.youku.com/player.php/sid/XMjU3Mjk2NzA0/v.swf
歌詞:
JDK 和JRE 莫要混淆去
環境變量的配置有時讓人迷
初學的人莫貪圖上來I D E
先用J D K +文本編輯器
面向對象仨特點一定要牢記
封裝繼承和多態一個不能離
接口為多重繼承
抽象類一定要有實例
O b je c t呀 所有類爹地
package在類中只能有唯一
注釋命名時要既規范又明晰
就當為好程序員伏筆
G U I 不是鬼 千萬別恐懼
四大布局管理 多練才熟悉
勤能補拙熟能生巧到考試時
你眼帶笑意
三整兩浮一布爾再加字節符
基本數據Byte數了然于心底
碰到異常一定記得try/catch
要打包發布使用jar命令
線程何時被調用全看調度器
睡眠同步和死鎖使用要仔細
網頁中Applet
獨立程序Application
ApplicationO b je c t呀所有類爹地
package在類中只能有唯一
注釋命名時要既規范又明晰就當為好程序員伏筆
(這樣程序員才是好樣滴)
G U I 不是鬼
千萬別恐懼四大布局管理
多練才熟悉
勤能補拙熟能生巧到考試時你眼帶笑意
歌詞理解:
JDK 和JRE 莫要混淆去
JRE(Java Runtime Environment):即Java運行環境,運行JAVA程序所必須的環境的集合,包含JVM標準實現及Java核心類庫。
JDK(Java Development Kit):是整個Java的核心,包括了Java運行環境,Java工具和Java基礎的類庫。
環境變量的配置有時讓人迷
JAVA_HOME、CLASSPATH、PATH
記得加入當前目錄“.”
初學的人莫貪圖上來IDE
IDE(Integrated Development,集成開發環境)
不錯的Java IDE:Eclipse、Netbeans、Jbuilder、 Jcreator
先用JDK +文本編輯器
vim、javac、java
面向對象仨特點一定要牢記,封裝繼承和多態一個不能離
封裝:隱藏對象的屬性和實現細節,僅對外公開接口,控制在程序中屬性的讀和修改的訪問級別
繼承:對已有類的復用和修改
多態:指一個程序中,同名的不同方法共存的情況
接口為多重繼承
抽象類一定要有實例
Object呀,所有類爹地
所有類都是從Object類繼承而來的。
package在類中只能有唯一
package 語句必須是文件中除注釋以外的第一句程序代碼
package 將文件中的類都遮蔽到一定的名字空間下,別的文件導入須用到import關鍵字
注釋命名時要既規范又明晰,就當為好程序員伏筆
GUI 不是鬼,千萬別恐懼
四大布局管理 多練才熟悉
勤能補拙熟能生巧到考試時,你眼帶笑意
三整兩浮一布爾再加字節符
三整:short int long
兩浮:float double
一布爾:boolean
字節符:byte char
基本數據Byte數了然于心底
boolean:特殊,表示1 bit的信息,但不明確指定占用內存空間的大小。
char:2 Byte
byte:1 Byte
short:2 Byte
int:4 Byte
long:8 Byte
float:4 Byte
double:8 Byte
碰到異常一定記得try/catch
要打包發布使用jar命令
線程何時被調用全看調度器
睡眠同步和死鎖使用要仔細
網頁中Applet
獨立程序Application
對于系統管理員來說如何管理自己的服務器已經是再簡單不過,但是如何管理好服務器卻不是一個簡單的事情。對于管理員來說重啟服務器可不是一件鬧著玩的事情。對于Windows服務器管理員來說經常性重啟Windows設備已經成為一種生活常態,但在Unix系統中這種辦法卻難以奏效——在默認情況下重新啟動不會帶來任何形式的改善。
我打算借此機會跟大家詳細聊聊重啟的問題。對于每一位服務器管理員來說這都算得上熱門話題,但在Unix極客們眼中它則屬于一種層次更深的課題——可能因為Windows管理員們往往把重啟當成故障排查工作的首要步驟之一,而Unix團隊則一般只在束手無策的情況下才進行嘗試。
Unix服務器重啟的兩種情況
實際情況是:服務器重啟操作應該極少出現——請注意是極少。在這里我列舉內核更新與硬件更換作為例子,因為它們是Unix領域中引發重新啟動的兩大主要原因。有些人一直在鼓吹什么不重啟服務器的話會帶來某些嚴重的安全風險,這簡直是一派胡言。如果服務項目與應用程序中確實存在安全風險,那么打上漏洞補丁就能解決問題了,而且補丁往往不要求重啟設備。而如果安全風險存在于內核模塊中,一般來說只需卸載對應模塊、安裝補丁,最后重新加載模塊。沒錯,我承認一旦內核中存在安全風險,那么重啟操作的確是必要的。但在這種情況之外,大家根本沒有切實的理由重新啟動Unix服務器。
有些人認為如果不進行重啟操作,其它形式的風險往往會接踵而至,例如某些關鍵性服務項目在開機時沒有得到正確啟用,而這將導致一系列隱患。當然,這種說法本身是正確的,但只要管理工作執行到位,這其實根本就是種杞人憂天。只有剛剛接掌服務器設備的菜鳥才會忘記正確設置服務項目的啟動參數。不過話說回來,如果大家的服務器正處于構建階段,且其中還不涉及任何生產方面的內容,那么不妨隨意進行各類重啟測試,這不會帶來任何不良影響。而且我認為這正是熟悉重啟機制的最好時機。
但還有另一方面需要考慮:那些將重啟操作當成故障排查重要步驟之一的家伙是抱著死豬不怕開水燙的心態,打算一次性把問題都暴露出來。就說一套已經出現問題的Unix設備吧,某些還處于運行中的服務項目實際上已經無法再次啟動,而這一點在重啟之后就會顯現出來——也許是由于分段故障或者其它稀奇古怪的原因。
造成Unix服務器重啟的原因
如果我們只是簡單查看幾分鐘之后就一拍腦門決定重啟設備,那么也許故障的真正原因就徹底湮沒在時光中了——也許是某位初級管理員在運行一套自己編寫的愚蠢腳本時無意中刪除了/boot目錄或者/etc、/usr/lib64目錄下的部分內容。這正是引發分段故障以及設備不穩定情況的罪魁禍首。然而一旦我們選擇直接重啟服務器而沒有深入挖掘問題,那么顯然問題會變得更加嚴重,接下來不出意外的話大家應該會啟動恢復鏡像——這就代表需要面對大量恢復工作——而與此同時生產服務器也將陷入停機狀態。
以上只是我們在Unix領域中應該盡量避免重啟操作的原因之一。與其說這算是種故障排查方法,不如把它看作一類孤注一擲的豪賭——要么發現問題,要么親手毀掉一切再慢慢重建。總之,沒人能利用/var分區重啟設備就完全修正錯誤。(另外請別提什么打開文件句柄這類迂腐的蠢話——我想大家應該理解我的意思)
服務器重啟前請做完你該做的工作
在大多數情況下,不進行重啟是極其重要的,因為系統中能夠幫助我們修復問題的關鍵性內容在重啟前是一定存在的,但在重啟后卻未必還在。重啟之后問題絕對會再次出現,然而一旦解決方案隨重啟行為而煙消云散,那么故障本身就陷入了無解的死循環中。除非有人決定不進行重啟,而是嘗試找出問題的根源。遺憾的是,能做了這種明智選擇的人實在少之又少。實際情況是:一根小小的故障內存條就能給系統正常運行與設備啟動狀態帶來極大的麻煩。而這個時候,對癥下藥才是上策,一味重啟只會帶來額外的損失。
因此,今后大家在面對問題時,如果有某個家伙說什么“嘿,不如先重啟一下看看”,不妨直接給他兩個大嘴巴。重啟當然是方案之一,但在實施重啟前請務必確保我們已經采取了一切能夠想到的處理措施;畢竟節省下來的都是咱們自己的時間跟精力嘛。
JNDI 是什么
JNDI是 Java 命名與目錄接口(Java Naming and Directory Interface),在J2EE規范中是重要的規范之一,不少專家認為,沒有透徹理解JNDI的意義和作用,就沒有真正掌握J2EE特別是EJB的知識。
那么,JNDI到底起什么作用?
要了解JNDI的作用,我們可以從“如果不用JNDI我們怎樣做?用了JNDI后我們又將怎樣做?”這個問題來探討。
沒有JNDI的做法:
程序員開發時,知道要開發訪問MySQL數據庫的應用,于是將一個對 MySQL JDBC 驅動程序類的引用進行了編碼,并通過使用適當的 JDBC URL 連接到數據庫。
就像以下代碼這樣:
- Connection conn=null;
- try {
- Class.forName("com.mysql.jdbc.Driver",
- true, Thread.currentThread().getContextClassLoader());
- conn=DriverManager.getConnection("jdbc:mysql://MyDBServer?user=qingfeng&password=mingyue");
- /* 使用conn并進行SQL操作 */
- ......
- conn.close();
- }
- catch(Exception e) {
- e.printStackTrace();
- }
- finally {
- if(conn!=null) {
- try {
- conn.close();
- } catch(SQLException e) {}
- }
- }
|
這是傳統的做法,也是以前非Java程序員(如Delphi、VB等)常見的做法。這種做法一般在小規模的開發過程中不會產生問題,只要程序員熟悉Java語言、了解JDBC技術和MySQL,可以很快開發出相應的應用程序。
沒有JNDI的做法存在的問題:
1、數據庫服務器名稱MyDBServer 、用戶名和口令都可能需要改變,由此引發JDBC URL需要修改;
2、數據庫可能改用別的產品,如改用DB2或者Oracle,引發JDBC驅動程序包和類名需要修改;
3、隨著實際使用終端的增加,原配置的連接池參數可能需要調整;
4、......
解決辦法:
程序員應該不需要關心“具體的數據庫后臺是什么?JDBC驅動程序是什么?JDBC URL格式是什么?訪問數據庫的用戶名和口令是什么?”等等這些問題,程序員編寫的程序應該沒有對 JDBC 驅動程序的引用,沒有服務器名稱,沒有用戶名稱或口令 —— 甚至沒有數據庫池或連接管理。而是把這些問題交給J2EE容器來配置和管理,程序員只需要對這些配置和管理進行引用即可。
由此,就有了JNDI。
用了JNDI之后的做法:
首先,在在J2EE容器中配置JNDI參數,定義一個數據源,也就是JDBC引用參數,給這個數據源設置一個名稱;然后,在程序中,通過數據源名稱引用數據源從而訪問后臺數據庫。
具體操作如下(以JBoss為例):
1、配置數據源
在JBoss的 D:/jboss420GA/docs/examples/jca 文件夾下面,有很多不同數據庫引用的數據源定義模板。將其中的 mysql-ds.xml 文件Copy到你使用的服務器下,如 D:/jboss420GA/server/default/deploy。
修改 mysql-ds.xml 文件的內容,使之能通過JDBC正確訪問你的MySQL數據庫,如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <datasources>
- <local-tx-datasource>
- <jndi-name>MySqlDS</jndi-name>
- <connection-url>jdbc:mysql://localhost:3306/lw</connection-url>
- <driver-class>com.mysql.jdbc.Driver</driver-class>
- <user-name>root</user-name>
- <password>rootpassword</password>
- <exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.MySQLExceptionSorter</exception-sorter-class-name>
- <metadata>
- <type-mapping>mySQL</type-mapping>
- </metadata>
- </local-tx-datasource>
- </datasources>
|
這里,定義了一個名為MySqlDS的數據源,其參數包括JDBC的URL,驅動類名,用戶名及密碼等。
2、在程序中引用數據源:
- Connection conn=null;
- try {
- Context ctx=new InitialContext();
- Object datasourceRef=ctx.lookup("java:MySqlDS"); //引用數據源
- DataSource ds=(Datasource)datasourceRef;
- conn=ds.getConnection();
- /* 使用conn進行數據庫SQL操作 */
- ......
- c.close();
- }
- catch(Exception e) {
- e.printStackTrace();
- }
- finally {
- if(conn!=null) {
- try {
- conn.close();
- } catch(SQLException e) { }
- }
- }
|
直接使用JDBC或者通過JNDI引用數據源的編程代碼量相差無幾,但是現在的程序可以不用關心具體JDBC參數了。
在系統部署后,如果數據庫的相關參數變更,只需要重新配置 mysql-ds.xml 修改其中的JDBC參數,只要保證數據源的名稱不變,那么程序源代碼就無需修改。
由此可見,JNDI避免了程序與數據庫之間的緊耦合,使應用更加易于配置、易于部署。
JNDI的擴展:JNDI在滿足了數據源配置的要求的基礎上,還進一步擴充了作用:所有與系統外部的資源的引用,都可以通過JNDI定義和引用。
所以,在J2EE規范中,J2EE 中的資源并不局限于 JDBC 數據源。引用的類型有很多,其中包括資源引用(已經討論過)、環境實體和 EJB 引用。特別是 EJB 引用,它暴露了 JNDI 在 J2EE 中的另外一項關鍵角色:查找其他應用程序組件。
EJB 的 JNDI 引用非常類似于 JDBC 資源的引用。在服務趨于轉換的環境中,這是一種很有效的方法。可以對應用程序架構中所得到的所有組件進行這類配置管理,從 EJB 組件到 JMS 隊列和主題,再到簡單配置字符串或其他對象,這可以降低隨時間的推移服務變更所產生的維護成本,同時還可以簡化部署,減少集成工作。 外部資源”。
具體操作如下(以JBoss為例):
1、配置數據源
在JBoss的 D:/jboss420GA/docs/examples/jca 文件夾下面,有很多不同數據庫引用的數據源定義模板。將其中的 mysql-ds.xml 文件Copy到你使用的服務器下,如 D:/jboss420GA/server/default/deploy。
修改 mysql-ds.xml 文件的內容,使之能通過JDBC正確訪問你的MySQL數據庫,如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <datasources>
- <local-tx-datasource>
- <jndi-name>MySqlDS</jndi-name>
- <connection-url>jdbc:mysql://localhost:3306/lw</connection-url>
- <driver-class>com.mysql.jdbc.Driver</driver-class>
- <user-name>root</user-name>
- <password>rootpassword</password>
- <exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.MySQLExceptionSorter</exception-sorter-class-name>
- <metadata>
- <type-mapping>mySQL</type-mapping>
- </metadata>
- </local-tx-datasource>
- </datasources>
|
這里,定義了一個名為MySqlDS的數據源,其參數包括JDBC的URL,驅動類名,用戶名及密碼等。
2、在程序中引用數據源:
- Connection conn=null;
- try {
- Context ctx=new InitialContext();
- Object datasourceRef=ctx.lookup("java:MySqlDS"); //引用數據源
- DataSource ds=(Datasource)datasourceRef;
- conn=ds.getConnection();
- /* 使用conn進行數據庫SQL操作 */
- ......
- c.close();
- }
- catch(Exception e) {
- e.printStackTrace();
- }
- finally {
- if(conn!=null) {
- try {
- conn.close();
- } catch(SQLException e) { }
- }
- }
|
直接使用JDBC或者通過JNDI引用數據源的編程代碼量相差無幾,但是現在的程序可以不用關心具體JDBC參數了。
在系統部署后,如果數據庫的相關參數變更,只需要重新配置 mysql-ds.xml 修改其中的JDBC參數,只要保證數據源的名稱不變,那么程序源代碼就無需修改。
由此可見,JNDI避免了程序與數據庫之間的緊耦合,使應用更加易于配置、易于部署。
JNDI的擴展:JNDI在滿足了數據源配置的要求的基礎上,還進一步擴充了作用:所有與系統外部的資源的引用,都可以通過JNDI定義和引用。
所以,在J2EE規范中,J2EE 中的資源并不局限于 JDBC 數據源。引用的類型有很多,其中包括資源引用(已經討論過)、環境實體和 EJB 引用。特別是 EJB 引用,它暴露了 JNDI 在 J2EE 中的另外一項關鍵角色:查找其他應用程序組件。
EJB 的 JNDI 引用非常類似于 JDBC 資源的引用。在服務趨于轉換的環境中,這是一種很有效的方法。可以對應用程序架構中所得到的所有組件進行這類配置管理,從 EJB 組件到 JMS 隊列和主題,再到簡單配置字符串或其他對象,這可以降低隨時間的推移服務變更所產生的維護成本,同時還可以簡化部署,減少集成工作。 外部資源”。
從我們日常生活中去理解目錄服務的概念可以從電話簿說起,電話簿本身就是一個比較典型的目錄服務,如果你要找到某個人的電話號碼,你需要從電話簿里找到這個人的名稱,然后再看其電話號碼。

理解了命名服務和目錄服務再回過頭來看JDNI,它是一個為Java應用程序提供命名服務的應用程序接口,為我們提供了查找和訪問各種命名和目錄服務的通用統一的接口.通過JNDI統一接口我們可以來訪問各種不同類型的服務.如下圖所示,我們可以通過JNDI API來訪問剛才談到的DNS。
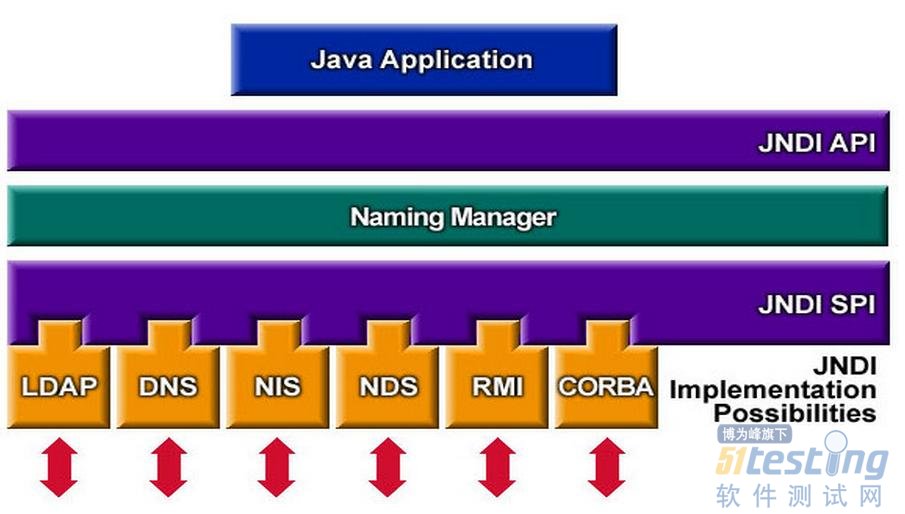
至此已經對JNDI有了一個初步認識,如果想要進一步了解JNDI,并對使用JDNI給我們帶來哪些便利之處,我推薦兩篇關于JDNI的文章,寫的非常的好,兩篇文章從“如果不用JNDI我們怎樣做?用了JNDI后我們又將怎樣做?”這個角度來加深對JNDI的認識。
數據庫是存放數據、經常是那些高敏感度數據的寶庫,因此它也毫無疑問的是合規檢查程序的重點區域。幾乎所有的企業合規都會對哪些人、能在什么時間、訪問什么數據庫作出規定,并且需要一個專職人員來管理這些權限。本文,我們將討論針對數據庫合規的基本數據庫安全要求,如PCI DSS和HIPAA,以及為了遵守合規要求用于管理數據庫權限和維護的最佳實踐。
最常見的五大企業核心數據庫環境是:1、微軟的SQL Server數據庫;2、IBM的DB2數據庫;3、MySQL數據庫;4、Oracle數據庫;5、Postgres數據庫。這些數據庫在首次實施安裝時都能夠恰當地配置、加固、保護及鎖定。真正的挑戰是理解那些實際上需要到位的重要組件。這不只是對數據庫本身,還有容納操作系統和數據庫的服務器。
PCI DSS當前對于數據庫要求有下述明確的控制措施:
◆ 對訪問任意數據庫的所有用戶進行認證。
◆ 所有用戶訪問任何數據庫時,用戶的查詢和操作(例如移動、拷貝和刪除)只能通過編程性事務(例如存儲過程)。
◆ 數據庫和應用的配置設置為只限于給DBA(數據庫管理員)的直接用戶訪問或是查詢。
◆ 對于數據庫應用和相關的應用ID,應用ID只能被應用使用,而不能被單獨的用戶或是其它進程使用。
就HIPAA法案來說,上述的措施沒有作為HIPAA合規要求的內容特別寫出來,但是應當看作是用于合規遵從的最佳安全控制組合,并且最終有助于滿足HIPAA中安全條款的需要。具體來說,HIPAA的規定條款如下:
◆ 確保所有新建、接收、維護或是傳輸中的電子個人健康信息(e-PHI)的保密性、完整性和可用性。
◆ 辨識和防范那些對信息的安全性或完整性來說合理的、可預見的威脅。
◆ 防范那些合理的、可預見的、不允許的濫用或是泄漏;并且
◆ 確保他們所有員工的合規性。
此外,除了滿足像PCI DSS這樣的合規要求外,下述是應該考慮的最佳實踐、可用來確保上面列出的所有數據庫環境的安全。
就運行數據庫的主機的操作系統來說,以下的最佳實踐應該到位:
1、系統管理員和其他相關的IT人員應該擁有充分的知識、技能并理解所有關鍵操作系統的安全要求。
2、當部署操作系統到受管理的服務環境中時,應采用行業領先的配置標準和配套的內部文檔。
3、在操作系統上應該只啟用那些必需的和安全的服務、協議、守護進程和其它必要的功能。
4、操作系統上所有不需要的功能和不安全的服務及協議應該有效地禁用。