1. 在HP的官方網站上下載LoadRunner9.5 的Linux安裝程序[T7177-15009.iso],安裝文檔[hp_man_LRIG9.50_01_pdf.pdf];
安裝程序包括Hp、Ibm、Linux、Solaris系統的支持(LR9.0對應安裝文件為[TLRNUX900WC_00.zip])。
2. 安裝包的處理:
1. ZIP解壓:unzip TLRNUX900WC_00.zip
2. 掛載ISO:mkdir /mnt/LoadRunner ; mount -t iso9660 -o loop T7177-15009.iso /mnt/LoadRunner
3. 開始安裝,以LR9.5為例:
/mnt/LoadRunner/Linux/installer.sh
按提示操作,直接Next到完成。
4. 添加用戶和環境變量:
useradd -g 0 -s /bin/csh higkoo
cat /opt/HP/HP_LoadGenerator/env.csh > /etc/.login
cat /opt/HP/HP_LoadGenerator/env.csh >~higkoo/.cshrc
touch ~root/.rhosts ~higkoo/.rhosts
5. 檢查運行環境(在本機或使用VNC執行):
su - higkoo
cd /opt/HP/HP_LoadGenerator/bin/
./verify_generator
6. 啟動服務(用新增的用戶higkoo):
cd /opt/HP/HP_LoadGenerator/bin/
./m_daemon_setup start
7. 檢查是否啟動:
ps aux | grep m_agent_daemon
netstat -naop | grep 54345
8. 注意事項:
開啟端口54345或關閉防火墻(service iptables stop)
正確設置后用verify_generator的檢測結果是:
| ./verify_generator =================================================== HP Vuser Environment Verification Utility =================================================== Product: HP LoadRunner 9.50 Version: 09.50.0000 Build: 3378 higkoolincn100ce5: verify_generator...OK verify_generator...OK verify_generator...OK Don't forget to make sure that the name of the controller machine is also in .rhosts verify_generator...OK verify_generator...OK verify_generator...OK verify_generator...OK verify_generator...OK verify_generator...OK verify_generator...OK _______________________________________________ Summary: ________ Vuser Host higkoolincn100ce5: OK |
使用Controller連接,在“UNIX Environment Tab”下選擇“Don't use RSH ”即可連接Linux負載機。

若使用RSH連接,則負載機必須安裝RSH并正確配置,正如檢測過程中描述的“Don't forget to make sure that the name of the controller machine”。
補充,Linux下似乎只支持Web/Http協議的腳本。譬如WinSock協議,從名稱上都知道只適合Windows:
“Error (-81024): LR_VUG: The 'WinSock' type is not supported on 'LINUX' platforms .”
另外試了Java協議,確實不行,報錯如下:
Error (-81024): LR_VUG: The 'General-Java' type is not supported on 'LINUX' platforms .
依賴庫:yum -y --disablerepo=\* --enablerepo=AutoInstaller --nogpgcheck --skip-broken localinstall /mnt/CentOS_Final/CentOS/compat-libstdc++-33-3.2.3-61.i386.rpm
否則會報:m_agent_daemon: error while loading shared libraries: libstdc++.so.5: cannot open shared object file: No such file or directory
注意hosts文件的配置,如果機器名和hosts里配置不一致也會導致LoadRunner啟動失敗,
譬如:Error: Communication error: Failed to get the server host IP by calling the gethostbyname function.。
附上給LoadRunner定制的系統服務腳本(/etc/init.d/loadrunner):
#!/bin/bash # /etc/init.d/loadrunner# Loadrunner負載生成器服務DAEMON=m_daemon_setupARGV="$@"DIR=/opt/HP/HP_LoadGenerator/bin/USER=higkooUBIT="su - $USER -c "
$UBIT "cd $DIR && ./$DAEMON $ARGV" 運行服務:
service loadrunner start
m_agent_daemon ( 1808 ),
1、目的
缺陷記錄是軟件測試生命周期中最重要的可用產出之一。因此,怎么填寫有效的缺陷是非常重要的。一般來說,一條好的缺陷記錄至少有以下3個方面的積極作用。
(1)減少測試人員和開發人員的溝通成本。
(2)加快缺陷修復的速度。
(3)增加測試的可信度。
缺陷記錄的最終目的是準確地傳達測試人員的思想或缺陷的真正所在。只要遵循本規范中的一些簡單原則,我們就可以輕松的填好每一條缺陷記錄,從而提高工作效率。
2、適用范圍
3、填寫缺陷規范
3.1 缺陷概要規范
缺陷概要需以簡潔的語言表述準確的信息。那么能準確表達意義的縮略語在描述中則具有更高的優先級,一些關鍵詞如“程序崩潰”、“系統無反應”和“文字錯誤”等,在把缺陷概要作為檢索條件的時候,顯得非常必要。
3.2 缺陷描述規范
缺陷描述需要遵循以下7個要點:精練、正確、中立、準確、普遍性、可再現和有證據。
3.2.1 精練
缺陷記錄的描述需簡單明了。不加入與問題無關的敘述,去除不必要的信息。但同時,要涵蓋所有必要的信息。
3.2.2 正確
一定要清楚你所記錄的缺陷的確存在。在提交前,請先考慮如下5個問題:
(1)我對系統需求是否真正理解?
(2)是否安裝和系統相關的軟件?我的機器設置有沒有問題?
(3)是不是我手動設置的某個地方不合適(被測軟件本身的設置)?
(4)是不是我以前測試時遺留的錯誤數據導致的錯誤?
(5)會不會是網絡狀況變化引起的問題?或者其它外在環境因素(如防火墻)引起的錯誤?
以上這些都對測試的結果有很大的影響,確認這些問題是否存在。
3.2.3 中立
客觀地描述每一個缺陷,不要帶任何情緒化的語言。在提交一個缺陷記錄前首先把它通讀一遍,確信你的描述沒有傷害到任何人員。
3.2.4 準確
缺陷記錄需要準確的描述缺陷發生的位置,產生條件和結果。最好做到讓閱讀缺陷記錄者不需要親自上機操作就知道問題所在。
例子 | 缺陷描述 |
不準確的描述 | 查詢中按項目來源查詢發生錯誤。 |
準確的描述 | 科技項目計劃下達中,在查詢頁面按“項目來源”字段的“資金”查詢條件進行查詢時,查詢結果顯示出了屬于“資金”和“結轉”的項目,應只顯示出屬于“資金”的項目。 |
3.2.5 普遍性
記錄缺陷需要明確的描述出該問題在整個系統中普遍存在的地方。通常,當開發人員修改缺陷的時候,他可能只是修復了你提到的一些特定情況,他并不知道這個問題具有普遍性,尚需更大范圍的修復。
3.2.6 可再現 原則上所提交的缺陷都應該能夠重現。對很難重現的Bug,你應該記錄下什么情況下可以再現它,列出再現Bug的所有步驟,執行次序以及所需要的數據等。
如果你無法再現這個Bug,或者是你懷疑某些條件你還沒有想到,你應盡可能的把那些認為可能有用的信息描述清楚。
一個缺陷在你重現它以前,不要假設它是可以重現的,如果你確實無法重現它,在缺陷記錄中明確說明也是很重要的。
在考慮對缺陷的重現時我們應該注意以下3點:
(1)怎樣才能以最簡單的方式把缺陷重現。對于難重現的缺陷,這常常是個漫長而費時的過程。
(2)是否有外在的原因在測試中導致了該缺陷。例如是否和其它軟件相沖突的情況。
(3)如果在測試中要輸入很多值,盡量在大量的輸入中找出導致缺陷的那些特定值,并準確地寫出那些導致缺陷的輸入。
3.2.7 證據
對于一些數值型的、暫時不能重現的和難以描述的缺陷等,最好提供可以證明它存在的數據、圖片和文擋等證據。對記錄的缺陷,就應該確信這里的確存 在缺陷并提供所有你能提供的證據,說服別人這里確實存在缺陷。這些證據可能來自于系統數據、現場截圖以及需求文擋等。當然這也有利于關閉缺陷和做回歸測試 的時候重現該缺陷。
3.3 缺陷屬性規范
缺陷屬性需要根據不同的軟件項目定制不同的屬性值。
必須的屬性值有:DefectID、Subject、Status、Severity、AssignedTo、Summary、DetectedBy、DetectedonDate、DetectedinVersion和Detectedphase。
3.4 缺陷填寫建議
在填寫一條缺陷記錄的時候,提醒你參考以下2點建議:
(1)在提交一條缺陷前,需檢查缺陷庫中是否已經存在此缺陷。力求避免重復提交。
(2)對于一些難以理解的、自己還有些模糊的和對缺陷的正確性難以肯定的問題,在記錄你的缺陷以前,就需要和有經驗的測試人員或開發人員進行討論。
4、缺陷等級分類與示例
4.1 概述
測試當中發現的缺陷,嚴重程度劃分為三級:High(高)、Medium(中)和Low(低)。在《軟件系統測試規程》中已對這三個級別進行了 定義性描述,High等級是指功能不能使用或在使用中出現的問題影響了系統的穩定性、造成數據存儲錯誤或將錯誤數據帶入下一環節、一些重要特性或性能不能 達到指定的要求等。Medium等級是指功能可以使用、在出錯后做出一定處理,操作能夠繼續進行或功能實現有誤,但問題的出現應不影響本功能或其他功能的 實質性使用。Low等級是指用戶界面顯示、對齊、文字錯誤等。
本文結合實際工作情況,對已發現的大量缺陷數據進行歸納,對缺陷的各個等級進行分類,并在每個分類中列舉比較典型的例子。以后測試人員在設定缺 陷嚴重等級時將據此進行參考,使缺陷嚴重等級的定位更加規范統一,同時也使測試人員和開發人員對缺陷等級的定位更容易達成一致。本次分類重點關注系統業務 功能在正常操作下可能出現的問題,而有意識地降低了邊界值測試發現的缺陷和非正常操作下發現缺陷的等級。
我們主要考慮High等級和Medium等級的情況。因為Low等級的缺陷主要指界面上的顯示、對齊、文字錯誤等,在這里就不再詳細列出。
4.2 High等級的分類與示例
(1)關鍵數據錯誤。
例:
(a)統計報表中的項目數量和資金統計不正確。
(b)巡視工作任務中,將缺陷記錄中的缺陷上報生產,在缺陷登記模塊中可看到3條一樣的數據。
(c)物資采購數為10,現場和倉庫可分別到貨10件。
(2)所有功能在正常操作下報錯(如500或404等)。
例:
(a)打開計劃下達審批頁面,系統報500。
(b)點擊查詢按鈕,系統報404。
(3)主要功能在正常操作下沒有實現。
例:新增、保存、刪除、發送、回退、撤回、導出和查詢等操作不成功。
(4)主要功能在正常操作下結果不正確。
例:
(a)檢查不通過的項目可以上報成功。
(b)選擇全部項目發送,只發走部分。
(c)導出功能,導出的文件格式錯亂、內容跟列名不對應,以及內容不正確等。
(d)在多個入庫單同時上報時,將入庫倉庫為觀瀾倉庫的入庫單上報給水貝倉庫的管理員審批。
(e)在新增兩票錄入記錄時,在新增頁面點擊一次保存操作就會新增一條記錄。
(f)PDA中,缺陷表象的信息錯誤了,嚴重等級也沒有下下來;設備信息中,有些字段沒有下下來。比如“安裝日期”、“廠家”、“電壓等級”等等。
(5)主要功能存在性能問題。
例:
(a)分發多個項目時,系統響應很慢,如分發30個項目,系統1分鐘還沒處理完。
(b)單據過帳時,系統出現白屏,顯示時間超過10秒。(系統響應時間應符合需求規格說明書的要求,不同系統的響應時間的要求可能不一致。)
(6)系統管理權限錯亂,對系統安全造成威脅的。
例:
(a)沒有授權用戶菜單,但用戶登錄系統后,能通過該菜單進入相關模塊,并對模塊的數據進行操作。
(b)未授權的用戶可以進行廠家配額。
(c)在角色管理中取消了新增功能位置的權限按鈕,在設備臺賬中變電設施、中心站、設備下還有新增下一級功能位置按鈕。
(7)系統業務邏輯關系處理不正確,引起主要功能錯誤。 例:
(a)項目驗收后,已驗收狀態的項目在待下達庫中可被獲取繼續下達。
(b)生成操作票中,對于已審核通過的操作票,還可以增加操作步驟,應該是不能再編輯操作步驟的。
(c)搶修領料在審批過程中可以上報。
(d)領料退庫時,導入的領料單列表中即有現場到貨單也有現場領料單,造成同一物資多次退庫的現象。
4.3 Medium等級的分類與示例
(1)非主要功能在正常操作下沒有實現。
例:
(a)查詢頁面有某些查詢條件查不出相應的數據。
(b)巡視項目定義中,當只有2條巡視內容時,上下移動巡視內容操作不成功。
(c)在單據中物資明細沒有超鏈接。
(2)非主要功能在正常操作下結果不正確。
例:
(a)標題排序不正確。
(b)新增主變壓器并修改其技術參數高壓額定容量值之后,該設備的上級變電站頁面中主變壓器總容量的值沒有修改。
(3)非主要功能存在性能問題。
例:物資系統中上傳附件速度很慢,1M的文件需要30秒以上。
(4)所有功能進行邊界值測試,系統報錯的。
例:
(a)大文本框輸滿,保存報500。
(b)資金輸入最大值,保存報500。
(c)上傳大型文件,系統老處于上傳狀態。
(d)選中大量項目導出,導出不正確。
(5)模塊中的信息顯示不正確,起誤導用戶作用。
例:
(a)資金單位顯示不對。
(b)新增推薦單位后,列表中顯示的“關聯類型”與新增時的輸入不一致。
(c)在單據的物資明細列表中將物資明細顯示為項目名稱。
(d)停電計劃查詢中的導出字段中,“停電原因”應該是“停電終止原因”。
(6)關鍵提示不正確,起誤導用戶作用。
例:
(a)實際操作成功卻提示操作失敗。
(b)智能操作票系統中,在狀態檢查時,提示的不合法設備名稱不正確。
(c)操作票中,導入操作步驟成功了,但是提示卻為不成功。
(7)非主要模塊的權限控制不正確。
例:
(a)合同管理的授權給相關人員后,相關人員看不到相應的數據。
(b)領料單在材料員審批時不能填寫領料原因。
(8)系統業務邏輯關系處理不正確,引起非主要功錯誤。
例:項目歸檔后,在項目申請的已上報頁面和申請書的查詢頁面還能看到該項目。
4.4 Low等級的分類與示例
(1)頁面和記錄定位。
例:變更申請選中列表中的第2條項目新增變更,新增完返回時系統自動定位到列表中的第一條項目。
(2)用戶界面顯示、對齊、文字錯誤等。
例:
(a)頁面太小沒有將內容顯示完整,只要把頁面調大即可。
(b)系統將“帳號”顯示成“賬號”。
(3)報javascript錯誤,但能操作成功。
(4)用戶幾乎不太可能進行的操作,導致系統報錯。
4.5 填寫缺陷時的注意事項
(1)同類型的缺陷只錄一條。例如項目審批模塊的發送不成功,其他審批模塊也有同樣的問題,只錄一條缺陷就可以,因為都屬于工作流的問題。
(2)同一模塊的頁面顯示有幾個問題,也只錄一條缺陷,并在缺陷的描述里列出各個問題。因為都是同一模塊頁面顯示的問題,放在一起,開發人員可一次將問題改全。
(3)測試中要經常查看同組測試員填寫的缺陷,及時了解已存在的缺陷,如有補充可在注釋里填寫。
(4)查看同組測試員填寫的缺陷時,注意其他人對缺陷嚴重等級的定義,保持同組人員對嚴重等級定位的一致性。
存儲過程的功能非常強大,在某種程度上甚至可以替代業務邏輯層,接下來就一個小例子來說明,用存儲過程插入或更新語句。
1、數據庫表結構
所用數據庫為Sql Server2008。
2、創建存儲過程
(1)實現功能:
有相同的數據,直接返回(返回值:0);
有主鍵相同,但是數據不同的數據,進行更新處理(返回值:2);
沒有數據,進行插入數據處理(返回值:1)。
根據不同的情況設置存儲過程的返回值,調用存儲過程的時候,根據不同的返回值,進行相關的處理。
(2)下面編碼只是實現的基本的功能,具體的Sql代碼如下:
- Create proc sp_Insert_Student
- @No char(10),
- @Name varchar(20),
- @Sex char(2),
- @Age int,
- @rtn int output
- as
- declare
- @tmpName varchar(20),
- @tmpSex char(2),
- @tmpAge int
-
- if exists(select * from Student where No=@No)
- begin
- select @tmpName=Name,@tmpSex=Sex,@tmpAge=Age from Student where No=@No
- if ((@tmpName=@Name) and (@tmpSex=@Sex) and (@tmpAge=@Age))
- begin
- set @rtn=0 --有相同的數據,直接返回值
- end
- else
- begin
- update Student set Name=@Name,Sex=@Sex,Age=@Age where No=@No
- set @rtn=2 --有主鍵相同的數據,進行更新處理
- end
- end
- else
- begin
- insert into Student values(@No,@Name,@Sex,@Age)
- set @rtn=1 --沒有相同的數據,進行插入處理
- end
|
3、調用存儲過程
這里在Sql Server環境中簡單的實現了調用,在程序中調用也很方便。
具體的代碼如下:
- declare @rtn int
- exec sp_Insert_Student '1101','張三','男',23,@rtn output
- if @rtn=0
- print '已經存在相同的。'
- else if @rtn=1
- print '插入成功。'
- else
- print '更新成功'
|
一個存儲過程就實現了3中情況,而且效率很高,使用靈活。希望對大家有所幫助。
在成長學習的過程中,我會不斷發一些自己的心得體會,和大家共享。
http://yp.oss.org.cn/software/show_resource.php?resource_id=406
http://www.ltesting.net/ceshi/open/kygncsgj/selenium/2012/0207/204032.html
http://blog.163.com/florazhang800@126/blog/static/210707272008119111818988/
如果你是那種極不情愿寫文檔的程序員,那么,你并不孤單。然而當你的上司在檢查你的
工作時,他才不想看你那一堆一堆的代碼,他需要看文檔,這時的你需要的是Concordion——一個符合Specification By Example的
自動化測試框架,通過自然語言來描述軟件功能,即項目中所有成員都能看懂的而又具備測試功能的html文檔。
(一)Concordion的工作原理
簡單的說,Concordion測試只是對JUnit的擴展,但是它可以從你寫好的測試文檔(html)中讀取測試數據,通過傳統的JUnit來跑測試,并將測試結果輸出為具有紅綠標記(表示失敗或成功)的html文檔(基于原測試文檔)。

在上圖中,Specification即為我們寫的html測試文檔,與普通的html文檔不同的是,我們需要在其中加入一些名為concordion 的標簽,瀏覽器將忽略這些標簽,但Concordion用這些標簽來執行測試指令,比如調用Fixture中的測試函數等。Fixture為繼承自 ConcordionTestCase(最終繼承自JUnit測試類)的測試用例,這些測試用例將調用我們自己所開發的功能代碼。
(二)Concordion的Hello World
下面就通過一個簡單的Hello World例子來演示Concordion。
下載Concordion和其所依賴的包。
首先寫一個html測試用例HelloWorld.html:
<html xmlns:concordion=http://www.concordion.org/2007/concordion>
<body>
<p>Should print:</p>
<p concordion:assertEquals="sayHello()">HelloWorld</p>
</body>
</html> |
此html文檔可以通過瀏覽器正常打開,由于瀏覽器并不知道concordion標簽,故將其忽略:
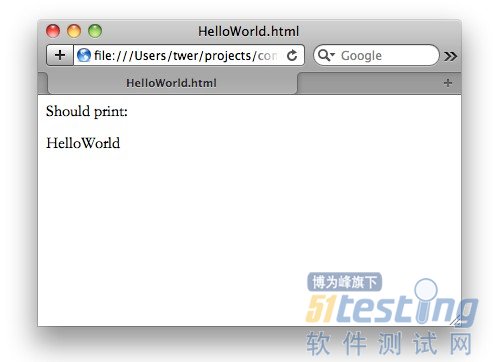
可以看到,以上加入的concordion標簽的html測試文檔和普通的html文檔并無區別,同時我們也看到在concordion標簽后有一個 sayHello()函數調用,此函數從什么地方來呢——這就是Concordion的約定,要求在該html文檔的同目錄下有一個名為 HelloWorldTest.java的測試用例類存在,并且該類有一個測試函數名為sayHello()。約定規則為:如果html文檔名為 Foo.html,那么測試用例類應該為FooTest.java。此時Concordion便通過名字匹配去找名為HelloWorldTest類的 sayHello()函數并調用之。
我們還注意到,在concordion標簽后有assertEquals,此時Concordion將把helloWorld()函數的輸出與之后的“HelloWorld”字符串相比,如果相等,測試成功,否則失敗。
接下來實現HelloWorldTest類,在HelloWorld.html同目下創建HelloWorldTest.java文件:
package com.thoughtworks.davenkin.concordion;
import org.concordion.integration.junit3.ConcordionTestCase;
public class HelloWorldTest extends ConcordionTestCase {
public String sayHello()
{
return new HelloWorld().sayHelloWorld();
}
}
在HelloWorldTest.java文件中實例化了一個HelloWorld對象,并調用其sayHelloWorld()方法,于是寫一個需要測試的HelloWorld類如下:
| package com.thoughtworks.davenkin.concordion; public class HelloWorld
{
public String sayHelloWorld()
{
return "HelloWorld";
}
} |
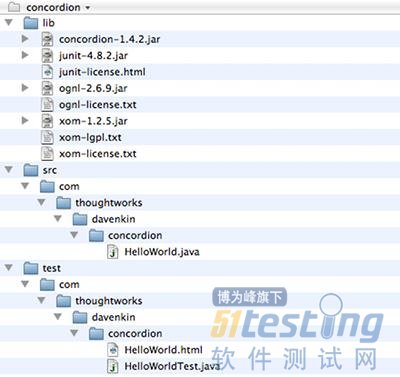
最終生成的工程目錄結構如下:
(三)編譯并運行測試
打開終端,將目錄切換到 concordion(這是筆者為此helloworld創建的工程根目錄,請不要與上文提到的concordion混淆)下,編譯:
| javac -cp lib/*:src:test test/com/thoughtworks/davenkin/concordion/HelloWorldTest.java |
用JUnit運行測試:
| java -cp lib/*:src:test org.junit.runner.JUnitCore com.thoughtworks.davenkin.concordion.HelloWorldTest |
運行結果如下:
| JUnit version 4.8.2
./var/folders/wM/wMUC8-0FEsq-MMkTzdzYA++++TI/-Tmp-/concordion/com/thoughtworks/davenkin/concordion/HelloWorld.html
Successes: 1, Failures: 0 Time: 0.307 OK (1 test) |
運行成功,并且顯示測試輸出的html文件的全路徑名稱(此時應該去掉最前面的那個點"."):
| /var/folders/wM/wMUC8-0FEsq-MMkTzdzYA++++TI/-Tmp-/concordion/com/thoughtworks/davenkin/concordion/HelloWorld.html |
打開該文件:
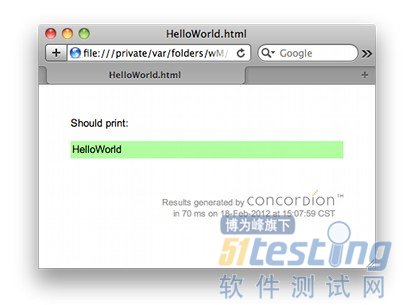
測試運行成功。
http://mirrors.163.com/centos/6.2/isos/i386/
Java查詢一次性查詢幾十萬,幾百萬數據解決辦法。
很早的時候寫工具用的一個辦法,當時是用來把百萬數據打包成rar文件。
所以用了個笨辦法。 希望高手指導一下,有什么好方法沒有啊。
1、先批量查出所有數據,例子中是一萬條一批。
2、在查出數據之后把每次的數據按一定規則存入本地文件。
3、獲取數據時,通過批次讀取,獲得大批量數據。
以下是查詢數據庫。按批次查詢
- public static void getMonthDataList() {
- ResultSet rs = null;
- Statement stat = null;
- Connection conn = null;
- List<DataBean> list = new ArrayList<DataBean>();
- try {
- conn = createConnection();
- if(conn!=null){
- SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
- SimpleDateFormat timesdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- String nowDate = sdf.format(new Date());
- Config.lasttimetext = timesdf.format(new Date());
- String lastDate = sdf.format(CreateData.addDaysForDate(new Date(), 30));
- stat = conn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_UPDATABLE);
- int lastrow = 0;
- int datanum = 0;
- String countsql = "SELECT count(a.id) FROM trip_special_flight a" +
- " where a.dpt_date >= to_date('"+nowDate+"','yyyy-mm-dd') " +
- "and a.dpt_date <= to_date('"+lastDate+"','yyyy-mm-dd') and rownum>"+lastrow+" order by a.get_time desc";
- rs = stat.executeQuery(countsql);
- while (rs.next()) {
- datanum = rs.getInt(1);
- }
- int onerun = 10000;
- int runnum = datanum%onerun==0?(datanum/onerun):(datanum/onerun)+1;
- for(int r =0;r<runnum;r++){
- System.out.println("getMonthDataList--"+datanum+" 開始查詢第"+(r+1)+"批數據");
- String sql = "SELECT * FROM (SELECT rownum rn, a.dpt_code, a.arr_code,a.dpt_date,a.airways,a.flight," +
- "a.cabin,a.price FROM trip_special_flight a" +
- " where a.dpt_date >= to_date('"+nowDate+"','yyyy-mm-dd') " +
- "and a.dpt_date <= to_date('"+lastDate+"','yyyy-mm-dd') order by rownum asc) WHERE rn > "+lastrow;
- stat.setMaxRows(onerun);
- stat.setFetchSize(1000);
- rs = stat.executeQuery(sql);
- String text = "";
- int i = 1;
- while (rs.next()) {
- text += rs.getString(2)+"|"+rs.getString(3)+"|"+rs.getDate(4)+"|"+rs.getString(5)+"|"+rs.getString(6)+"|"+rs.getString(7)+"|"+rs.getString(8)+"||";
- if(i%1000==0){
- FileUtil.appendToFile(Config.tempdatafile, text);
- text = "";
- }
- i++;
- }
- if(text.length()>10){
- FileUtil.appendToFile(Config.tempdatafile, text);
- }
- lastrow+=onerun;
- }
- }
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- closeAll(rs, stat, conn);
- }
- }
-----java一次性查詢幾十萬,幾百萬數據解決辦法
存入臨時文件之后,再用讀取大量數據文件方法。
設置緩存大小BUFFER_SIZE ,Config.tempdatafile是文件地址。
- package com.yjf.util;
- import java.io.File;
- import java.io.RandomAccessFile;
- import java.nio.MappedByteBuffer;
- import java.nio.channels.FileChannel;
-
- public class Test {
- public static void main(String[] args) throws Exception {
- final int BUFFER_SIZE = 0x300000; // 緩沖區為3M
- File f = new File(Config.tempdatafile);
- // 來源博客http://yijianfengvip.blog.163.com/blog/static/175273432201191354043148/
- int len = 0;
- Long start = System.currentTimeMillis();
- for (int z = 8; z >0; z--) {
- MappedByteBuffer inputBuffer = new RandomAccessFile(f, "r")
- .getChannel().map(FileChannel.MapMode.READ_ONLY,
- f.length() * (z-1) / 8, f.length() * 1 / 8);
- byte[] dst = new byte[BUFFER_SIZE];// 每次讀出3M的內容
- for (int offset = 0; offset < inputBuffer.capacity(); offset += BUFFER_SIZE) {
- if (inputBuffer.capacity() - offset >= BUFFER_SIZE) {
- for (int i = 0; i < BUFFER_SIZE; i++)
- dst[i] = inputBuffer.get(offset + i);
- } else {
- for (int i = 0; i < inputBuffer.capacity() - offset; i++)
- dst[i] = inputBuffer.get(offset + i);
- }
- int length = (inputBuffer.capacity() % BUFFER_SIZE == 0) ? BUFFER_SIZE
- : inputBuffer.capacity() % BUFFER_SIZE;
- len += new String(dst, 0, length).length();
- System.out.println(new String(dst, 0, length).length()+"-"+(z-1)+"-"+(8-z+1));
- }
- }
- System.out.println(len);
- long end = System.currentTimeMillis();
- System.out.println("讀取文件文件花費:" + (end - start) + "毫秒");
- }
-
- }
|
讀取大量數據文件方法。
首先,請原諒我用了一個很土,很有爭議的標題。小弟才思枯竭,實在想不出來什么文雅的了,抱歉~~
前言
換了東家后,從一個死忠C# Fans搖身一變,客串了一把Java程序員,可能是受老趙的《Why Java Sucks》系列博文影響太大,剛開始那幾天有很大的抵觸情緒,后來想想,何不乘此機會深入了解一下Java。
扮演Java程序員兩個月以來,受到的折磨比較多,由于以前習慣了微軟的飯來張口,衣來伸手的策略,咋角色一轉變還真有點不適應,什么都得自己動手。雖然Java社區開源項目無數,框架一大把,但可能是選擇太多就更迷茫,還是有點不適應。
我想寫《Java中有些好的特性》這個系列文章,主要是抱著從一個C#程序員的角度,向Java學習的態度,決沒有任何吵架的意思。汲取精華,去其糟粕嘛,呵呵。當然,這個系列是不是寫的下去,要看看我是否真的碰到了我覺得Java比C#好的地方,碰到了一個我就會記錄一篇~~
靜態導入
優點
前言就說到這兒,現在進入今兒這篇文章的正題:靜態導入(static import)。
先看下面這段示例代碼:
1: public class SayHelloTest{
2: @Test
3: public void should_say_hello_when_given_your_name(){
4: gotoPage("hello");
5:
6: input("name","yuyijq");
7:
8: click("sayButton");
9:
10: assertThat(helloPage.getLabel(),is("hello yuyijq"));
11: }
12: } |
這是一段典型的功能測試代碼。對于功能測試來說,關鍵的就是要模擬用戶場景,而不涉及技術細節,用領域的語言來表達出測試。上面的測試用很清晰的步驟表達出了測試的意圖,要注意的是這里的gotoPage,input,click以及assertThat方法都不是SayHelloTest類的實例方法,都是定義在別的類甚至是第三方框架中的靜態方法。通過Java的靜態導入特性,使得現在代碼的可讀性更高:
| 1: import static com.cnblogs.yuyijq.functionalTest.gotoPage; |
弊端
通過靜態導入,我們可以去掉類名的前綴,這樣就可以將代碼寫得更自然,更像是在描述一件事兒。但靜態導入也并不是沒有缺點。在軟件開發中,很多特性適當的使用都很好,但是一旦使用過度就有可能變成壞事,這就是那個名言:不要拿著錘子,就把啥都當釘子。請看下面的代碼:
1: map.get(MOST_VIEWED.toString());
2: map.get(LAST_VIEWED.toString());
3: map.get(IS_LAST_ARTICLE.toString());
4: map.get(IS_SHOW_PICTURE.toString());
5: //....下面有類似代碼若干行 |
咋一看還以為這些MOST_VIEWED什么的全部是常量,但最后發現這些都是枚舉PortalOptions里的項,都是通過靜態導入導進來的。但由于沒了PortalOptions這個具有說明信息的枚舉名作為前綴,丟失了很多信息,造成這段代碼不是很容易看懂,不知道map.get出來的到底是什么。代碼雖然短了很多,但是如果加上PortalOptions,那么就能很直觀的直到我們需要從這個map里獲得PortalOptions相關的東東。
在C#里畫瓢
好的東西是要學習的,那我們如何在C#里照樣畫個瓢呢。可惜C#目前還不支持這種靜態導入,我也沒想到什么好法子能畫這個瓢。在C#里不要類名或實例名這個前綴,那除非這個方法是本類的方法,但我們肯定不可能為了使用這樣的東東,就給每個類添加這些方法,不過C#里有一個擴展方法特性,我們看看是不是能用擴展方法來畫這個瓢:
1: public static class UnitTestExtensions
2: {
3: public static T mock<T>(this object o,Type mockType)
4: {
5: return (T)NMock.Mock(mockType);
6: }
7:
11:
12:
13: } |
由于我們是給object類擴展的方法,所以在所有的類中都可以像是自己的方法一樣使用,也就可以寫下下面這樣的代碼了:
1: public class SayHelloControllerTest
2: {
3: [Test]
4: public void should_load_user_when_given_username()
5: {
6: User user = new UserBuilder()
7: .withUserName("yuyijq")
8: .withAge(80)
9: .withSex(male)
10: .build();
11: UserDAO userDAO = mock(typeof(UserDAO));
12: when(userDAO.findByUserName("yuyijq")).thenReturn(user);
13: replay(userDAO);
14: SayHelloController controller = new SayHelloController(userDAO);
15: verify(userDAO);
16: ModelAndView mv = controller.show("yuyijq");
17:
18: assertModelAttribute(mv,"user",user);
19: }
20: } |
不過給object添加擴展方法實在不是一個好主意,污染太大了。目前也沒有想出更好的辦法,所以就此作罷~~
后語
靜態導入就記敘到這里,兩個月以來我還是對Java的語法嗤之以鼻,不過對Java社區對開源的采納程度卻是由衷的感嘆。
附加說明
我在這里沒有任何意思表明Java好于C#,只是我在使用Java過程中發現的一些挺好的地方。這些地方能讓我寫出我自己覺得更好的代碼,而且在我心里C#遠超過Java的
地方多得多,這是毋庸置疑的。
Java核心技術卷I里有一個結論我覺得挺有意思的:java中沒有引用傳遞,只有值傳遞
首先看定義:
值傳遞,是指方法接收的是調用者提供的值
引用傳遞,是指方法接收的是調用者提供的變量地址
以前學習C++時把參數傳遞分為值傳遞和引用傳遞,國內的不少java教材愿意把對象的傳遞理解是引用傳遞,為什么它們會這么說呢?可以看下面一個例子:
- import java.util.Calendar;
- public class ChangeValue {
- public static void main(String[] args) {
- Calendar oc = Calendar.getInstance();
- System.out.println("origin:"+oc.getTime());
- changeDate(oc);
- System.out.println("after:"+oc.getTime());
- }
-
- static void changeDate(Calendar pd){
- pd.set(1970, 1, 1);
- }
- }
|
某時刻程序輸出:
origin:Thu Jan 05 21:15:59 CST 2012
after:Sun Feb 01 21:15:59 CST 1970 |
oc對象的值改變了,很多人就認為java對象傳遞實際上是引用傳遞。
過程應該是這樣的:
運行changeDate這個函數時,方法得到的是對象引用的拷貝,oc和pd同時引用同一個對象,所以函數運行結束后,pd已經消失了,但是對引用對象的更改卻也影響了oc所引用的同一對象,結合對之前的定義理解,這應該是值傳遞的過程(傳遞的是對象引用的拷貝)。
以下附上另一個例子,兩個對象的交換函數(C++中可以輕易實現):
- public class Swap {
- public static void main(String[] args) {
- ObjectSample o1 = new ObjectSample("hello");
- ObjectSample o2 = new ObjectSample("你好");
- System.out.println("before swap o1:"+o1.getTitle()+" o2:"+o2.getTitle());
- Swap.swapObject(o1, o2);
- System.out.println("after swap o1:"+o1.getTitle()+" o2:"+o2.getTitle());
- }
- static void swapObject(ObjectSample o1, ObjectSample o2){
- ObjectSample temp = new ObjectSample("temp");
- temp = o1;
- o1 = o2;
- o2 = temp;
- }
- }
- class ObjectSample{
- private String title;
-
- ObjectSample(String title){
- this.title = title;
- }
-
- public String getTitle(){
- return title;
- }
- }
|
輸出結果:
before swap o1:hello o2:你好
after swap o1:hello o2:你好 |
Java在交換程序中并沒有交換兩個對象的值,交換的是兩個對象的拷貝,不能實現讓對象參數引用一個新對象,究其原因還是因為Java是采用了值傳遞而非引用傳遞。
還有不少和以前自己接觸的觀點不一樣的地方,當然需要借鑒的吸收并且經過自己的實踐來辨別。