
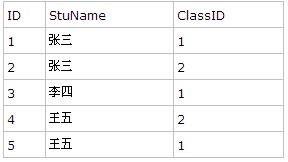
在項目中我們經常能遇到數據庫有“一對多”的關系,比如下面兩張表:
Student:
Class:
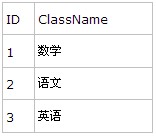
Class-Student就這樣構成了一個簡單的一對多關系。當然在實際的項目中,也可以再建立一張Relation表來保存他們之間的關系,在這里為了簡單,就不做Relation表了。
現在在項目中,我需要將Class表中的數據list顯示,當然也想顯示選擇了這門課的Student的StuName。也可以說是將一對多關系轉換為一對一關系。我所期望的顯示格式是這樣的:
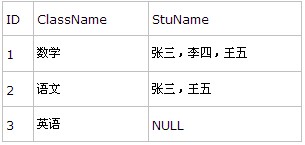
要做到這一點并不難,大體有兩種思路:
1、在數據庫中寫一個函數
2、在程序中獲取表Class與表Student所有數據,然后對比ClassID
那么,那種方法效率比較高呢?于是我寫了下面的代碼來進行一個簡單的測試
View Code
class Program
{
static void Main(string[] args)
{
Sql sql = new Sql();
Stopwatch time1 = new Stopwatch();
Stopwatch time2 = new Stopwatch();
for (int j = 0; j < 10; j++)
{
time2.Start();
for (int i = 0; i < 1000; i++)
{
string sql1 = "select ID,[StuName],[ClassID] FROM [Student]";
string sql2 = " SELECT ID,ClassName from Class";
List<string> item = new List<string>();
string bl="";
DataTable dt1 = sql.getData(sql1);
DataTable dt2 = sql.getData(sql2);
foreach (DataRow dtRow2 in dt2.Rows)
{
foreach (DataRow dtRow1 in dt1.Rows)
{
if (dtRow1["ClassID"].ToString() == dtRow2["ID"].ToString())
{
bl+=dtRow1["StuName"].ToString()+",";
}
}
item.Add(bl);
bl = "";
}
}
time2.Stop();
Console.WriteLine(time2.Elapsed.ToString());
time1.Start();
for (int i = 0; i < 1000; i++)
{
string sql3 = "SELECT C.ID, C.ClassName, dbo.f_getStuNamesByClassID(C.ID)as stuName FROM Class C";
DataTable dt = sql.getData(sql3);
}
time1.Stop();
Console.WriteLine(time1.Elapsed.ToString());
float index = (float)time1.Elapsed.Ticks / (float)time2.Elapsed.Ticks;
Console.WriteLine("效率比" + index.ToString());
Console.WriteLine("=============================");
}
Console.ReadLine();
}
} |
View Code
class Sql
{
public DataTable getData(string sql)
{
SqlConnection conn = new SqlConnection();
conn.ConnectionString = "Data Source=.\\SQLEXPRESS;Initial Catalog=Test;User Id=sa;Password=1;";
SqlCommand comm = new SqlCommand(sql, conn);
conn.Open();
SqlDataAdapter da = new SqlDataAdapter(comm);
DataSet ds = new DataSet();
da.Fill(ds, "ds");
conn.Close();
return ds.Tables[0];
}
}
|
View Code --根據課程ID,返回選此課程的學生的名字,以逗號隔開
ALTER function [dbo].[f_getStuNamesByClassID] (@ID int)
RETURNS nvarchar(50)
begin
declare @Result nvarchar(50);
declare @stuName nvarchar(50);
Set @Result=''; declare cur cursor for
(
SELECT S.StuName FROM Class C
LEFT JOIN Student S ON C.ID=S.ClassID
WHERE C.ID=@ID
)
open cur;
fetch next from cur into @stuName;
while(@@fetch_status=0)
begin
set @Result=@Result+@stuName+',';
fetch next from cur into @stuName;
end;
--去除最后多余的一個逗號
IF @Result <> ''
SET @Result=SUBSTRING(@Result, 1, LEN(@Result)-1);
ELSE
SET @Result=NULL;
return @Result;
en |
測試結果如下:
00:00:00.5466790
00:00:00.7753704
效率比1.418329
=============================
00:00:01.0251996
00:00:01.5594629
效率比1.521131
=============================
00:00:01.5124349
00:00:02.3286227
效率比1.539652
=============================
00:00:01.9882458
00:00:03.1007960
效率比1.559564
=============================
00:00:02.4476305
00:00:03.8717636
效率比1.581842
=============================
00:00:02.9129007
00:00:04.6332828
效率比1.590608
=============================
00:00:03.4006140
00:00:05.3971930
效率比1.587123
=============================
00:00:03.8655281
00:00:06.2574500
效率比1.618783
=============================
00:00:04.4532249
00:00:07.0674710
效率比1.587046
=============================
00:00:04.9540083
00:00:07.8596999
效率比1.586533
=============================
分析一下測試結果,不難發現每一個一千次所用的時間基本符合一個等差數列。當然第一個一千次由于要初始化,所以顯得慢一些。
總體來說,在程序中用處理一對多關系,比在數據庫中用函數處理效率要高35%這樣。
那么如果我們在Student表中再添加一行這樣的數據:

測試結果如下:
00:00:00.5519228
00:00:00.8206084
效率比1.486817
=============================
00:00:01.0263686
00:00:01.5813210
效率比1.540695
=============================
00:00:01.4886327
00:00:02.3516000
效率比1.579705
=============================
00:00:01.9807901
00:00:03.1495472
效率比1.590046
=============================
00:00:02.4613411
00:00:03.9278171
效率比1.595804
=============================
00:00:02.9246678
00:00:04.6961790
效率比1.605714
=============================
00:00:03.3911521
00:00:05.5018374
效率比1.62241
=============================
00:00:03.8737490
00:00:06.2716150
效率比1.619004
=============================
00:00:04.4047347
00:00:07.1796579
效率比1.629986
=============================
00:00:04.8688508
00:00:07.9477787
效率比1.632372
=============================
發現添加數據之后,效率比進一步加大
環境:vs2008,sql 2005
總結:根據測試結果來說,對于大規模高并發的數據庫操作(在這里是10次循環,每次1000次讀取數據),我們應該盡可能的避免使用數據庫函數,而應該將數據全部取出來,在程序中進行處理
寫在最后的話:對于我的程序、代碼、思路等等一切的一切有不同見解者,歡迎留言討論。這是我的第一篇博客,希望大家多多支持,如有不足望海涵。
前言:
● 自動化測試不只是測試的自動化,應當是流程的自動化
● 自動化測試是一種軟件開發交付過程
● 自動化測試成敗在于自動化項目的質量與可維護性
自動化測試對于在黑盒與手工測試工作的大部分人來說,都會比較向往,因為自動化測試很有成就感; 對于直接在自動化測試行業工作的新人來說,會比較迷茫,因為這個較為新生的領域不像開發行業那么成熟;
其實,自動化測試和手工測試一樣,是一種測試方法,只是你智力與思維轉化的結果; 關鍵看你是否適合,心態是否正確。
同時,它的發展前景不亞于任何開發行業,你既可以接觸專業的自動化測試技術,又可以掌握相關的開發技術,并且可以接觸專業的測試專家。
自動化測試的范圍
一般我們很難直接限定自動化測試的內容,但以我的理解,先從不適合的方面排除之,你可以試著看一下。
在混亂的項目流程中,不適合推廣和試行自動化測試。 自動化測試也是一種項目交付過程。
如果被測項目流程不明確,過程責任不清,沒有準確公平的數據度量,
● 開展了自動化測試效果難于評估,做也白搭
● 沒有清晰的交付測試流程,自動化測試經常的變更成本,以及沒有開發支撐的自動化只能從表面下手,導致維護成本過高。
● 自動化測試能夠將流程工具化,這點體現的效果易于得到整體研發的認可與支撐,效果也是極顯著的。
打個比方,本來是在公路上(不完善的流程)運行汽車,你非要改進效率跑火車(自動化),適得其反。
自動化測試的關鍵點之一,在于流程,流程在于人去完善,去改進。然而流程在年少時人的性格,在年長時也改變不了太多,我們自動化要符合流程去做,需要完善的我們去補充完善。而完善流程,不是一味的提要求,而是合理的慣力的要求,更多的時候應該建設平臺來支撐流程,讓人做到最簡化。
一旦流程的完善,自動化隨之正規化,可量化的自動化需求,項目成員明確自動化的成本與成果,以及相關自動化約束(例如某個自動化接口實現)。 自動化的成功自然隨之而然。
所以,自動化測試不只是測試的自動化,而應當是整個流程的一種自動化與完善。
在實施自動化的時候,處理流程相關,最好遵尋:完成相關自動化項目顯示效果 -> 要求改進流程 -> 實現流程過程的自動化
這樣帶來的項目壓力較小,容易獲得所需的資源。
自動化測試的過程
有了流程不代表我們肯定會成功,更何況一般需要我們通過自動化測試的成功來帶動流程的推進。
自動化測試首先是一種軟件開發與交付過程,無論最后的執行與維護是誰!
自動化測試與軟件開發過程基本相同,也要經歷: 需求->設計->編碼->交付 四個核心過程。 與普通的開發過程不一樣的是
● 自動化需求并不是實際的強制性需求,能夠有彈性,最關鍵的是自動化項目所定下的效果,各利益相關者必須在自動化項目效果期望上達成一致。
● 一般自動化設計過程相對較為簡單,如果有可伸縮好的框架,這個設計過程可以在很短時間搞定。
● 自動化的維護周期會比較長,所以設計高維護的自動化腳本是必然的。
在實際中,從手工測試過程中學習自動化的人,甚至有對版本管理工具如何管理代碼不清楚,那么他去做自動化必然是失敗的。
當項目經理對自動化效果期望很高時(這點可以理解,一般人對自動化期望都比較高),而你沒有將實際的風險與效果評估展現與說服給他時,就算自動化再成功,這個項目依然得不到所得的效果。
我們在統計自動化成本時,往往發現執行維護階段最終會超過自動化項目開發階段。
我們應該怎么做自動化項目
看下我們的目標:
● 快速開發與交付
● 高可用維護
選擇一門語言:
根據實際自動化需求,我們選擇了ruby作為基礎開發語言。 實際運用中,推薦使用ruby或python具備完備的模塊管理與純面向對象,,有助于建設高復用的框架與平臺。
實現快速迭代:
每天日結,自動化代碼要有完備的單元測試,這點通過ruby很容易實現,通過極簡潔的單元測試框架讓任何人都愿意做自動化代碼的單元測試,這點很重要,因為你的代碼再也沒有人去手工測試了。
實現DRY與業務邏輯分離
DRY即Don't Repeat Yourself(不要重復自己), 永遠不要讓相同的邏輯代碼復寫兩次。 一旦出現,將其分離封裝,如果是公共代碼(可能大多數項目會用),將其獨立為gem包等形式。
業務邏輯分離,將用例業務層為獨立,邏輯處理再次封裝,MVC的思想作為參考點。
實際上,自動化項目更適合做敏捷模式的開發過程,如果自動化項目都沒有“敏捷”, 你的被測項目又如何“敏捷” ?
我們應該關注什么?
除了自動化項目完成時間是重點外,我們要去關注:
1、質量問題
2、可維護性
質量關乎自動化項目的生命,
一旦自動化項目的經常跑失敗,失敗的原因經常是由于腳本引發,并且不收斂,那后果可想而知:
● 沒有人再相信自動化的運行結果
● 沒有人再愿意嘗試不斷的投入執行與分析一個無法發現有效bug的自動化測試項目中
● 沒有人再愿意投入下一個自動化過程中
可維護性是指后續的產品變更引起的自動化腳本更新快捷方便,做的好的自動化是超前完成維護的,做的爛的自動化是無法維護的。
可維護性表現可在于1,修復一處代碼即可完成相關所有邏輯的處理 2,便于增加新用例與復用代碼。
我們誰也不愿意將自動化的腳步陷入不斷的無限的維護分析的泥潭中。
總結
上面一些感悟,例子不多,但將我認為最重要的東西表達出來了,很多東西并不是死板的,呆滯的。
自動化領域更講究創新思維。
能夠將你所看到最繁瑣,最無聊的事情通過自動化解決了,這就是做好自動化項目的最核心思想。
但自動化之路不是一朝半夕可以掌握,很多彎路也許你是必須要走過。 <異類>一個觀點叫 1萬小時規律, 你不去認真做一萬小時的事情,你是不可能成為高手的。 (1萬小時大概需要5-6年)
在這里共享一些心得,也與剛入門的兄弟姐妹們共勉之。 共同進步。
最后推薦一個最近文章<測試技術專家之路的成長>,我想自動化專家的發展也與此類同:http://www.51testing.com/html/09/n-247209.html
多實踐,找出與自己公司合適的自動化發展之路,而不是好高鶩遠,更不是以技術牛人自居,只有這樣,才能腳踏實地,一步步走好適合自己的發展歷程。任何行業不都這樣嗎?
相關鏈接:
走在自動化軟件測試的道路上
埃及金字塔的神秘,不僅是因為它的規模宏偉、結構精密,而且它的興起和演變至今只是一個傳說,成為千古之謎。而軟件測試,也感覺和金字塔有一種神秘的關系,為什么這樣說呢?
金字塔中有神奇的黃金分割數Φ,其值是個無窮小數,若只取三位小數便是0.618。如用金字塔的高除以底邊長,即1÷1.618 = 0.618。而金字塔許多特征數據,和13世紀數學家法布蘭斯所提到的奇異數字的組合,有許多巧合之處。這些奇異數字的組合是1、1、2、3、5、8、13、21、34、55、89、144、233…它們任何兩個連續的比率都接近0.618,如3/5、5/8、34/55、55/89、89/144等。而且金字塔有一個頂點、五個面、八個邊,總數為十三個層面,這些特征數據也和上述奇異數字非常吻合。
首先,軟件測試的出發點就是質量,軟件測試的一切工作應該圍繞質量而開展。質量是軟件測試的中心,可以看做是金字塔的頂點,如圖1-1所示。測試的其他部分就是支撐這個頂點的測試人員、測試資源、測試技術和測試流程。因此,構成軟件測試的5個要素就是:質量、人員、技術、資源、流程。
這樣,5個要素構成了5個面,每個面由3個要素構成,代表著軟件測試的工作面。具體是怎樣的工作面?請往下看,自然會越來越清楚。
在這金字塔構成中,還有每兩個要素構成的8條邊,每條邊代表兩個要素之間的關系,如何處理這些關系,也就決定著測試能否獲得成功。基于要素、工作面、要素之間的關系,我們確定了13項軟件測試原則、21個關鍵域。針對軟件測試關鍵域,每個軟件組織可以了解自己在這個領域的水平,持續進行改進。最后,列出目前所使用的各種軟件測試方法,并將這些方法應用于軟件測試實際工作之中。所以軟件測試可概括為:

從1個中心到5個要素
質量(quality)是軟件測試的中心,這是毋庸置疑的。測試是質量保證的重要手段之一,測試本身就是為質量服務的。測試能否通過,其檢驗的標準是用戶的需求,也就是質量的標準。所以,在軟件測試的5個要素中,質量是核心,其他4個要素要服務于質量,服從于質量。
如果要問,除了質量,還有什么是最重要的?那自然是測試人員。人是決定的因素,決定了技術和流程的執行。像軟件開發這樣的智力活動,要強調“以人為本”的管理文化,才能真正發揮每個人的潛力,以最有效的方法完成測試工作。
如果繼續追問下去,在軟件測試過程中,哪兩樣東西是我們必須關注的?答案應該是“測試覆蓋率”和“效率(productivity)”。如何保證質量,一個重要的衡量方法就是測試的覆蓋率,包括用戶實際需求的覆蓋率和代碼覆蓋率。在保證質量的前提下,確定任務的優先級,采取正確的策略和方法,包括自動化測試方法,以高效的方法完成測試。
一而再、再而三,關注了“測試覆蓋率”和“效率”,拿什么來保證呢?這不外乎三個方面,就是測試人員、測試流程和測試的技術。就人員來說,要從招聘、培訓和考核等各個環節來培育良好的團隊文化,樹立正確的工作態度,強化質量意識,提高團隊的戰斗力,構建卓越的測試團隊。無論是采用敏捷的測試流程還是傳統的測試流程,一定要結合具體的產品和技術特點,因地制宜,形成適合自己的、有效的測試流程。測試技術比較豐富,因而下面各章的討論會很多,從客戶端到服務器端,從黑盒測試到白盒測試,從靜態測試到動態測試,全力構造一個完整的測試技術體系,使之滿足測試工作的需要。這些內容,可以用圖1-2形象地描述,使我們一目了然。
軟件測試的金字塔體系可以基于上一節的描述進行擴充,得到如下結構,更接近于一串神秘的數字。

圖1-2 軟件測試核心、目標、基礎等關系
最后,總結一下軟件測試的5個要素。
● 質量:軟件質量是軟件測試的目標,也是軟件測試工作的中心,一切從質量出發,也就是一切從客戶需求出發。任何違背質量的東西都是問題,測試就是要找出這些問題。
● 人員:人是決定的因素,測試人員的態度、素質、能力決定著測試的效果,對測試產品的質量也有很大的影響。測試人員因素包括測試組織結構、角色和責任的定義。
● 技術:軟件測試技術,包括方法、工具。
● 資源:主要是指測試環境中所需要的硬件設備、網絡環境,甚至包括測試數據。另外一個重要因素就是測試時間,時間也是測試的資源,但測試人員不能看做資源,每個人的能力千差萬別,不同的測試人員擔任不同的角色,不能相互代替。這也是軟件圖書的經典之作——《人件》的作者反對將人作為資源對待的原因。
● 流程:從測試計劃和測試用例的創建、評審到測試的執行、報告,設定每個階段的進出標準。
5個工作面
基于軟件測試金字塔的構成,我們好好研究其5個工作面,如圖1-3所示。
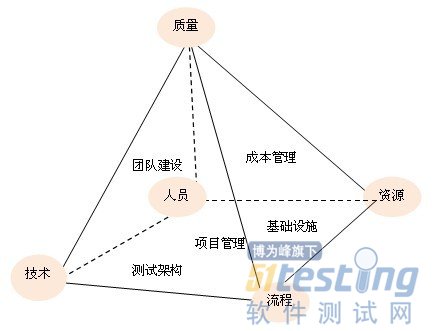
圖1-3 軟件測試的5個基本工作面
● 質量-人員-技術:團隊建設,包括人員的招聘、培訓、考核等。
● 質量-人員-資源:成本管理,人員和軟硬件資源都是測試的投入,但同時必須將人和軟硬件資源區別對待,不要將人也作為軟硬件資源那樣處理,否則會帶來較多的問題。
● 質量-技術-流程:技術和流程結合起來就是一種測試架構或測試框架,通過技術,將流程融入系統或工具中,流程的執行才能穩定、有效。技術通過框架固化,技術才能發揮最大效益。
● 質量-流程-資源:基礎設施,構建測試環境,將測試建立在堅固、流程的基礎設施之上。
● 人員-技術-流程-資源:項目管理,在一定的質量標準下,如何平衡這些要素、如何獲得最大的生產力,就是軟件測試項目管理的主要任務。
本文節選自《完美測試:軟件測試系列最佳實踐》一書,朱少民主編
LoadRunner的HTML與URL錄制方式
2010年02月26日 星期五 15:46
在跟使用Loadrunner工具使用者交流的過程中,經常有人提到這個問題,基于HTML(HyperText Markup Language 超文本置標語言)模式錄制與基于URL(Uniform Resource Locator的縮寫,統一資源定位符,也被稱為網頁地址,是因特網上標準的資源的地址。)錄制模式到底有什么不同?為什么通常情況下我們都會去選擇使用URL模式去錄制我們的業務腳本?所以在這里我把我知道的東西寫出來跟同行分享和交流: HTML是一種高級別的錄制模式,這種模式是基于“瀏覽器”或者說是“內容敏感”的。這種錄制選項是讓瀏覽器去決定在回放下載HTML資源,哪些頁面資源(比如圖片或者Flash內容)是需要被下載。 URL是一種低級別的錄制模式,這種錄制選項不允許瀏覽器去確定哪些頁面資源(比如圖片或者Flash內容)是需要下載的。每項資源在錄制回話的過程中都被錄制到腳本中。這種級別錄制模式同時也會錄制其他任何隱藏的對象,比如session ID(也就是會話ID)信息,包括發給服務端和從服務端收到的session ID信息。 腳本方面的不同,HTML級別錄制模式將生成的是web_submit_form語句來提交終端用戶可以看見或者修改的信息。當基于HTML模式在提交窗體時遇到錯誤,你可以選擇URL模式去錄制任何從服務端發送過來的請求和資源。而URL基本錄制模式將生成的是web_submit_data語句,這些語句記錄的是所有通過瀏覽器實際發送給服務端的信息。值得注意的是URL錄制模式會錄制那些HTML模式沒有能錄制到隱藏信息。通常情況下,隱藏信息里面會包含session ID信息。 寫到這里,熟悉的人可能應該明白為什么在通常的情況下,我們選擇URL模式去錄制我們基于Web(HTTP/HTML)協議的腳本,概括的說就是現在的應用(或者說將來的應用)為了安全性,都會包含像session ID、token等動態信息。簡單的說就是每一訪問,服務端都會給客戶端發送一個描述會話的session信息,而session ID使用的是動態的生成技術。如果要是腳本能夠正常回放,通常需要把這個動態的信息保存下來,這個需要使用到correlation 技術(也就是關聯技術)。在以后我會在我的博客里面繼續寫我對關聯的理解(包括自動關聯、手工關聯、規則等實用技術)。 在Web(HTTP/HTML)錄制中,有2種重要的錄制模式。用戶該選擇那種錄制模式呢? HTML-mode錄制是缺省也是推薦的錄制模式。它錄制當前網頁中的HTML動作。 在錄制會話過程中不會錄制所有的資源。在回放時,HTML-mode腳本積極地解析返回的信息來獲得要下載的資源。 HTML-mode是亦稱上下文敏感方式因為它只能在先前請求的結果的上下文之內執行。由于許多的HTTP 請求數據都是從內存中取出來的,所以語句必須在正確的前個請求之后執行。 HTML-mode錄制的優點是: 1.資源從內存中取出且在回放時下載。因此,腳本比其他的錄制方式更小且更容易閱讀。 2.由于只有較少的硬編碼腳本,因此只有較少的動態數值需要關聯。 3.可以插入圖片檢查之類的語句以檢查結果是否正確。 4.因為HTML模式回放時需要積極地解析返回的信息,因此它可能會比其他錄制模式更加占用資源。然而,HTML模式record/replay有相當大的改善,使得差異最小化且微不足道。 URL-mode選項指導VuGen錄制來自server的所有的請求和資源。它自動錄制每一個HTTP資源為URL的步驟。這種錄制模式甚至抓取非HTML應用程序,例如applets和非瀏覽器的應用程序。推薦使用這種錄制方式錄制以下情況: 1。錄制非browser的應用程序 2。取得在下載或不下載哪些資源上更好的控制,既然你可以在腳本中修改。 3。當使用LR6.x時,錄制使用applet和/或javascript的瀏覽器應用程序 由于URL-模式錄制了所有的請求和資源,需要做更多的關聯。腳本看起來也會相當的長。 ------------------------------------- 我發現用這兩種模式錄制Mercury的網頁( http://www.mercury.com/),結果卻有很大差別,HTML-based的response time是7.4秒左右,而URL-based的卻達到22秒左右。根據MI上面的解釋,估計是由于HTML-based模式的資源占用,從內存中讀數據引起的。 在使用LoadRunner進行WEB腳本錄制的時候,很多人不清楚URL-based 方式和 HTML-based方式的差別,以及何種情況下使用何種錄制方式,這里給出一個簡單的判斷方法。 HTML-based 方式 HTML-based 方式對每個頁面錄制形成一條語句,對LoadRunner來說,在該模式下,訪問一個頁面,首先會與服務器之間建立一個連接獲取頁面的內容,然后從頁面中分解得到其他的元素(component),然后建立幾個連接分別獲取相應的元素。 URL-based 方式 URL-based 方式將每條客戶端發出的請求錄制成一條語句,對LoadRunner來說,在該模式下,一條語句只建立一個到服務器的連接,LoadRunner提供了web_concurrent_start和web_concurrent_end函數模擬HTML-based的工作方式。 如何決定選擇何種錄制方式? 1、如果應用是WEB應用,首選是HTML-based方式; 2、如果應用是使用HTTP協議的非WEB應用,首選是URL-based方式; 3、如果WEB應用中使用了java applet程序,且applet程序與服務器之間存在通訊,選用URL-based方式; 4、如果WEB應用中使用的javascript、vbscript腳本與服務器之間存在通訊(調用了服務端組件),選用URL-based方式。 |
Jaslabs的Justin Silverton列出了十條有關優化
MySQL查詢的語句,我不得不對此發表言論,因為這個清單非常非常糟糕。另外一個Mike也同樣意識到了。所以在這個博客中,我要做兩件事情,第一,指出為什么這個清單很糟糕,第二,列出我的清單,希望我的比較好些。繼續看吧,無畏的讀者們!
為什么那個清單很糟糕
1、他的力氣沒使對地方
我們要遵循的一個準則就是如果你要優化代碼時,應該先找出瓶頸在哪。然而Silverton先生的力氣沒有用對地方。我認為60%的優化是基于清楚理解SQL和數據庫基 礎的。你需要知道join和子查詢的區別,列索引,以及如何將數據規范化等等。另外的35%的優化是需要清楚數據庫選擇時的性能表現,例如 COUNT(*)可能很快也可能很慢,要看你選用什么數據庫引擎。還有一些其他要考慮的因素,例如數據庫在什么時候不用緩存,什么時候存在硬盤上而不存在 內存中,什么時候數據庫創建臨時表等等。剩下的5%就很少會有人碰到了,但Silverton先生恰好在這上面花了大量的時間。我從來就沒用過 SQL_SAMLL_RESULT。
2、很好的問題,但是很糟糕的解決方法
Silverton先生提出了一些很好的問題。MySQL針對長度可變的列如TEXT或BLOB,將會使用動態行格式(dynamic row format),這意味著排序將在硬盤上進行。我們的方法不是要回避這些數據類型,而是將這些數據類型從原來的表中分離開,放入另外一個表中。下面的 schema可以說明這個想法:
- CREATE TABLE posts (
- id int UNSIGNED NOT NULL AUTO_INCREMENT,
- author_id int UNSIGNED NOT NULL,
- created timestamp NOT NULL,
- PRIMARY KEY(id)
- );
-
- CREATE TABLE posts_data (
- post_id int UNSIGNED NOT NULL.
- body text,
- PRIMARY KEY(post_id)
- );
|
3、有點匪夷所思……
他的許多建議都是讓人非常吃驚的,譬如“移除不必要的括號”。你這樣寫SELECT * FROM posts WHERE (author_id = 5 AND published = 1),還是這樣寫SELECT * FROM posts WHERE author_id = 5 AND published = 1 ,都不重要。任何比較好的DBMS都會自動進行識別做出處理。這種細節就好像C語言中是i++快些還是++i快些。真的,如果你把精力都花在這上面了,那 就不用寫代碼了。
我的列表
看看我的列表是不是更好吧。我先從最普遍的開始。
1、建立基準,建立基準,建立基準!
如果需要做決定的話,我們需要數據說話。什么樣的查詢是最糟的?瓶頸在哪?我什么情況下會寫出糟糕的查詢?基準測試可以讓你模擬高壓情況,然后借助性能測評工具,可以讓你發現數據庫配置中的錯誤。這樣的工具有supersmack, ab, SysBench。這些工具可以直接測試你的數據庫(譬如supersmack),或者模擬網絡流量(譬如ab)。
2、性能測試,性能測試,性能測試!
那么,當你能夠建立一些高壓情況之后,你需要找出配置中的錯誤。這就是性能測評工具可以幫你做的了。它可以幫你發現配置中的瓶頸,不論是在內存中,CPU中,網絡中,硬盤I/O,或者是以上皆有。
你要做的第一件事就是開啟慢查詢日志(slow query log),裝上mtop。這樣你就能獲取那些惡意的入侵者的信息了。有需要運行10秒的查詢語句正在破壞你的應用程序嗎?這些家伙會展示給你看他的查詢語句是怎么寫的。
在你發現那些很慢的查詢語句后,你需要用MySQL自帶的工具,如EXPLAIN,SHOW STATUS,SHOW PROCESSLIST。它們會告訴你資源都消耗在哪了,查詢語句的缺陷在哪,譬如一個有三次join子查詢的查詢語句是否在內存中進行排序,還是在硬盤 上進行。當然你也應該使用測評工具如top,procinfo,vmstat等等獲取更多系統性能信息。
3、減小你的schema 在你開始寫查詢語句之前,你需要設計schema。記住將一個表裝入內存所需要的空間大概是行數*一行的大小。除非你覺得世界上的每個人都會在 你的網站注冊2兆8000億次的話,否則你不需要采用BITINT作為你的user_id。同樣的,如果一個文本列是固定大小的話(譬如US郵編,通常 是”XXXXX-XXXX”的形式),采用VARCHAR的話會給每行增加多余的字節。
有些人對數據庫規范化不以為意,他們說這樣會形成相當復雜的schema。然而適當的規范化會減少化冗余數據。(適當的規范化)就意味著犧牲少 許性能,換取整體上更少的footprint,這種性能換取內存在計算機科學中是很常見的。最好的方法是IMO,就是開始先規范化,之后如果性能需要的 話,再反規范化。你的數據庫將會更邏輯化,你也不用過早的進行優化。(譯者注,這一段我不是很理解,可能翻譯錯了,歡迎糾正。)
4、拆分你的表
通常有些表只有一些列你是經常需要更新的。例如對于一個博客,你需要在許多不同地方顯示標題(如最近的文章列表),只在某個特定頁顯示概要或者全文。水平垂直拆分是很有幫助的:
- CREATE TABLE posts_tags (
- relation_id int UNSIGNED NOT NULL AUTO_INCREMENT,
- post_id int UNSIGNED NOT NULL,
- tag_id int UNSIGNED NOT NULL,
- PRIMARY KEY(relation_id),
- UNIQUE INDEX(post_id, tag_id)
- );
|
artificial key完全是多余的,而且post-tag關系的數量將會受到整形數據的系統最大值的限制。
- CREATE TABLE posts_tags (
- post_id int UNSIGNED NOT NULL,
- tag_id int UNSIGNED NOT NULL,
- PRIMARY KEY(post_id, tag_id)
- );
|
6、學習索引
你選擇的索引的好壞很重要,不好的話可能破壞數據庫。對那些還沒有在數據庫學習很深入的人來說,索引可以看作是就是hash排序。例如如果我們 用查詢語句SELECT * FROM users WHERE last_name = ‘Goldstein’,而last_name沒有索引的話,那么DBMS將會查詢每一行,看看是否等于“Goldstein”。索引通常是B- tree(還有其他的類型),可以加快比較的速度。
你需要給你要select,group,order,join的列加上索引。顯然每個索引所需的空間正比于表的行數,所以越多的索引將會占用更 多的內存。而且寫數據時,索引也會有影響,因為每次寫數據時都會更新對應的索引。你需要取一個平衡點,取決每個系統和實施代碼的需要。
7、SQL不是C
C是經典的過程語言,對于一個程序員來說,C語言也是個陷阱,使你錯誤的以為SQL也是一種過程語言(當然SQL也不是功能語言也不是面向對象的)。你不要想象對數據進行操作,而是要想象有一組數據,以及它們之間的關系。經常使用子查詢時會出現錯誤的用法。
- SELECT a.id,
- (SELECT MAX(created)
- FROM posts
- WHERE author_id = a.id)
- AS latest_post
- FROM authors a
|
因為這個子查詢是耦合的,子查詢要使用外部查詢的信息,我們應該使用join來代替。
- SELECT a.id, MAX(p.created) AS latest_post
- FROM authors a
- INNER JOIN posts p
- ON (a.id = p.author_id)
- GROUP BY a.id
|
8、理解你的引擎
MySQL有兩種存儲引擎:MyISAM和InnoDB。它們分別有自己的性能特點和考慮因素。總體來講,MyISAM適合讀數據很多的情況,InnoDB適合寫數據很多的情況,但也有很多情況下正好相反。最大的區別是它們如何處理COUNT函數。
MyISAM緩存有表meta-data,如行數。這就意味著,COUNT(*)對于一個結構很好的查詢是不需要消耗多少資源的。然后對于 InnoDB來說,就沒有這種緩存。舉個例子,我們要對一個查詢來分頁,假設你有這樣一個語句SELECT * FROM users LIMIT 5,10,而運行SELECT COUNT(*) FROM users LIMIT 5,10 時,對于MyISAM很快完成,而對InnoDB就需要和第一個語句相同的時間。MySQL有個SQL_CALC_FOUND_ROWS選項,可以告訴 InnoDB運行查詢語句時就計算行數,之后再從SELECT FOUND_ROWS()來獲取。這是MySQL特有的。但使用InnoDB有時候是非常必要的,你可以獲得一些功能(如行鎖定,stord procedure等)。
9、MySQL特定的快捷鍵
MySQL提供了許多擴展,方便使用。譬如INSERT … SELECT, INSERT … ON DUPLICATE KEY UPDATE, 以及REPLACE。
我能用到它們時是毫不猶豫的,因為它們很方便,能在許多情況下發揮不錯的效果。但是MySQL也有一些危險的關鍵字,應該少用。例如 INSERT DELAYED,它告訴MySQL不需要立即插入數據(例如在寫日志的時候)。但問題是如果在很高數據量的情況下,插入可能會被無限期延遲,導致插入隊列 爆滿。你也可以使用MySQL的索引提示來指出哪些索引是需要使用的。MySQL大部分時間運行是不錯的,但如果schema設計不好的話或語句寫得不好 的話,MySQL的表現可能很糟糕。
10、到這里為止吧
最后,如果你關心MySQL性能優化的話,請閱讀Peter Zaitsev的關于MySQL性能的博客,他寫了許多關于數據庫管理和優化的博客。
探索式
測試(Exploratory
Test)經常被簡稱為ET,由 Cem Kaner 1983年建立的測試概念,這幾年隨著
敏捷方法而大行其道。敏捷方法的迭代頻率很快,每個迭代時間很短,自然想到如何減少文字
工作,避免寫
測試用例,ET自然是一個很好的選擇。ET簡單理解為測試設計與執行同步進行。
不過,我們以前熟悉測試中的錯誤猜測法、Ad hoc測試等方法,不管Cem Kaner承認不承認,ET概念很有可能來源于這些先前的概念,在這些概念的基礎上豐富它,試圖給ET建立一個比較系統的體系,例如引入基于上下文驅動 (Context-driven)、基于session的測試等。想當初,我們用錯誤猜測法、Ad hoc測試方法時,一定也會考慮業務或功能的上下文關系,沒有上下文還做什么測試?也會考慮某些場景,更多會考慮一些特別的場景,如人們常說的 corner case,right? 當然,ET和錯誤猜測法、Ad hoc測試是有區別的。
談談探索式測試與基于腳本的測試(Script-base Test 或 Scripted Testing,ST)之關系,不論是在傳統測試流程還是在敏捷測試中, 這兩者是相輔相成的,誰也不能代替誰,正如James Bach也談到“Balancing Exploratory Testing with Scripted Testing,... two approaches to testing are fully compatible” 。而且在不同的場景有各自的優勢,例如:
● 發現問題來看,探索式測試效率會更高些,甚至高得多;
● 測試樂趣看,也會優先選擇探索式測試;
● 敏捷中新功能測試會選擇探索式測試;
● 探索式測試不易實現自動化,所以自動化測試先需要腳本,然后執行;
● 歸測試比較確定,需要不斷運行,自然會選擇基于腳本的測試(ST);
● 產品線來看,開發周期長,復用會大大提高效率,ST也具有很大優勢。
所以,在一個項目中,經常是同時采用這兩種方法——ST和ET,而且不同的組織環境或項目環境,隨時間的投入是不一樣的,這就是那兩條神奇的曲線:

當初我沒有在線上標ST和ET,就是因為每根線都可能是ET或ST,例如:
1、如果自動化測試水平低或沒有自動化測試,就需要在前期有更多的ET,在發現產品問題的同時學習產品、更深地理解產品,并通過發現問題來完善測試用例。而為了降低產品質量風險,后期需要進行更系統的測試,特別是要完成大量回歸測試、對產品質量有一個完整的評估,需要執行ST。由于自動化水平低,這時人力都投在ST上,就沒有經歷做ET,而且也不必要。
2、如果自動化水平高,前期需要開發腳本,ST的投入自然大。但自動化執行時,雖然會運行大量用例,但解放了生產力,測試人員有更多時間投入ET。

實際環境所處的場景會更多,不管怎樣,先要清楚自己測試工作中有什么問題,然后采用合適的方法來解決問題。或者說,要清楚自己的目標,是讓團隊獲得激情還是讓公司處在穩定的不敗之地、還是為了盡快發現Bug還是提高產品的質量,方法何時使用、如何使用、誰使用等都可能不同。即先問Why?What?然后才考慮How、Who、Where?
關于探索式測試和腳本測試還有許多東西可以談,時間關系,今天就談到這里。
出自:http://blog.csdn.net/kerryzhu/article/details/7489319
大綱: 自動化測試的現狀
自動化測試的發展
1、包含的領域
2、發展的思路
3、觀點: 自動化測試是一種軟件開發交付過程
自動化測試成敗在于自動化項目的質量與可維護性
自動化測試不只是測試的自動化,應當是流程的自動化
自動化的難點:
1、極強的定制性使得引入自動化成為難事
2、預言性的需求設計使得自動化需求變化極快,同時要求開發周期越短越好
3、軟件流程往往成為自動化道路中的拌腳石
我在自動化測試的計劃
未來的自動化測試在哪里?
引用
rubywindy說前面的路: 軟件行業算得上是高科技行業,“零成本”締造了N多帝國公司的神話。 這也從側面說明軟件業還不夠“成熟”,因為在“傳統”的眼里,很難出現一家獨大的局面。 在軟件業中,自動化測試要算是一個很小的分支了。 然而軟件測試往往花費了50%以上的項目周期,而自動化測試正像傳統的自動化流水線工廠一樣,試圖解決這個關鍵問題。 |
我在這個領域不長時間,算上入手開始到現在,大概有1年半有余。一直有一種想分享一些想法的沖動,然而總是感覺時機不成熟,畢竟這個領域在中國是新興的,而我也是一種新入門的感覺,然而,測試領域的混亂狀態與最近越來越清晰的思想使得我也借Ruby大會后的時間梳理一下我的想法。
自動化測試包含的理念是什么?
看了許多51testing上的文章貼子,很多人對此不清楚,我想簡單幾句表達下我的觀點。
為什么出現自動化測試? 因為手工測試效率低下,回歸成本高昂,許多在前期應當控制的代碼質量由于手工測試介入過晚導致測試成本過高。 自動化測試的出現要求提高整體測試效率,極大降低回歸成本,通過單元自動化,接口自動化,自動化代碼檢視,編譯自動化構建,冒煙構建等立體動態的方案從而 可以盡早從測試手段控制版本開發質量,降低后續測試成本,并快速集成回歸。
我想提供一個圖看下變化過程:

這是一個傳統的,也是我們一般人使用的軟件開發模式,國外有個好聽的名字: 瀑布開發模式(你堅著看,很形象吧?)
而自動化測試應當提供什么呢?
看下圖:
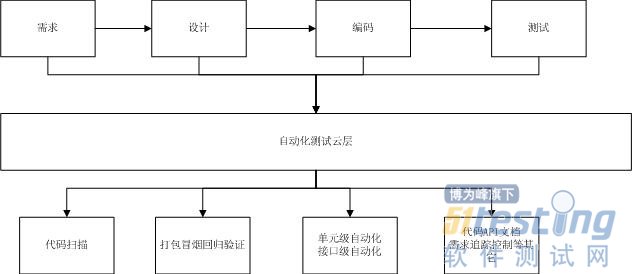
我們今天不討論敏捷,這里的自動化模式是基本不改變開發模式的方式下的開展過程。(我想大部分公司很難強推行大規模的開發模式轉變:大部分原因被冠名風險與人)
這個圖是以自動化云層(叫平臺也行)依靠,提供全方面的自動化測試過程。
● 自動化測試的手段: 以自動化測試代碼為依托,提高高可用的測試方案與立體的測試體系。
● 自動化測試的目的: 讓軟件測試無事可做!
解釋下目的,充足的快速的立體多方位的自動化測試加之規范的開發流程,bug既在編碼中與之前被發現,何來傳統的測試工作?
也許較真的兄弟們會說,軟件測試覆蓋的面可多了,黑盒,模糊,場景,發散等,你怎么取代? 我說的測試工作是特指我們平時花費最長最無味的系統測試。
解釋了自動化測試的所在的領域與基本理念后,下一個問題,
如何發展?
這里就我在工作過程中的一些思路談一談,我們知道自動化測試不具備通用性,明白這點很重要。我再解釋下,假如你在華為的路由器測試,你會使用cli操作命令進行自動化,你的平臺很可能依托在復雜的資源管理平臺上。
而如果你在人人,你會使用selenium等UI工具進行自動化,你可能直接使用了selenium與hudson作集成自動化。
如果你是做企業金融的公司,你會使用flash測試工具,autoit,甚至商業化的RFT等
另外,自動化還有一個特點,投入成本高,產出可能很緩慢。 如果你在預算投入不足時,千萬不要貌然啟動自動化,不要對其報有任何幻想。
如果明白這兩點,你們公司應該會成立專門的自動化團隊了,并且逐步的形成自動化測試的框架與相關的自動化效果產出了。
最后我想重點談談技術在自動化測試發展中的作用。
● 問題一: 選擇商業工具還是自主開發? 商業工具一般很強大,常見的如QTP,RFT,Robot,SilkTest等,并且帶有腳本錄制與快速回放。那我們直接選好了?
No,我的建議是不要去選,至少不要輕易的去選,并不是說你家有錢不讓你去花,因為要知道,自動化測試不具備通用性,我們的產品很難說能適應測試工具,而是應該讓工具去適應產品。
自主開發? No,我的建議也是No,世界上有一批優秀的程序員(測試員),他們開發了一批優秀的開發的自動化工具供我們使用,我們只需要動動手,整合一個框架出來就 ok了。 你會擔心,誰幫我維護?有bug找誰? 你要記住,如果你的技術不足于達到維護這個自動化測試工具時,你的自動化測試基本也宣告失敗了,那么,發現bug提交給相關社區,或者自己去修改并 push請求。達到技術共享的目的。
Java代碼
| 少量推薦的開源項目:
watir: http://watir.com/ Wiki社區: http://wiki.openqa.org/display/WTR/Project+Home
優秀的web自動化工具,采用ruby作為底層語言. API堪稱完美. 維護速度很快
selenium: http://seleniumhq.org/ 當然,采用開源并不是成功的必然條件,你還要根據實際的產品需求逐步的形成適合的自動化測試解決方案而不僅僅是一個工具.
這個解決方案應該能適合絕大部分自動化需求,而且根據DRY原則,做到最簡潔,最易用,最穩定. |
● 問題二: 先開發框架還是先作自動化項目? 有些人上來就想做一套框架搞自動化,生怕技術生銹了,實際上我的建議是:
先有自動化測試代碼,形成簡單的結果報告,代碼復用規范,將自動化效果展示出來。
第二步摸清需求后,進而設計一套合適的框架,這里可充分利用開源的優勢,一個技術好的人甚至花不超過1周可搞定一個框架。我們的ATT框架當時 僅花費了20*3人天完成。(一套關鍵字驅動框架,目前還沒有開源) 另外一個單元級框架花費3天完成,具備腳本規范,日志輸出,等作用。
第三步,設計框架要考慮可擴展性,要有預言性的設計在里面,比如ATT框架對外的接口是一個xmlrpc協議的接口,后來我們花了半年開發了平臺管理項目,與ATT框架完美對接。
最后,從流程上對自動化云層進行整合,梳理各項流程點,把能夠簡化的流程步驟全部由云層處理。(就像喬布斯那樣把iphone的開關都去掉了,因為實在對用戶沒有必要)
問題三:人,我的人應該具備什么樣的能力?<自動化軟件測試實施指南>這本書講的很好。
我就簡單總結下,
1、技術上不要求太精,但一定要廣,并且對新技術具備很高的熱情,我以后如果去面試,會第一個問題問,是否在業余時間開發過項目,如果用到了rails,erlang,云技術,甚至喜歡研究flex,敏捷,那么是我的首選。
2、創新思維,凡事不是第一感覺為否定,而是用研究來驗證自己的想法是否可行,能否做到把不可能自動化的東西也自動化掉。
3、團隊交流與協助,這點不用多說了。
4、改進意識,不甘于不斷的重復工作,如果沒有這點就沒有自動化。
當然,這樣的人有少量就夠了。
最后就我的里程,作一個回顧,也會以上理論的東西作一個實質的歸納,就當聽聽故事吧
大學玩了一半學了一半,學業成績稱不上優秀,但也算不錯。(至少沒有掛課~)
畢業的時候,我直接投了深圳這邊公司的簡歷,當時當然是一心投的開發職位,然而,對開發倒是一種不舒服的感覺,因為畢業設計的時候設計的那個郵件服務器始終存在一個bug,讓我決定可以試試測試職位,最終通過了現在的公司的面試。( 主要是動手能力強, 嘿嘿)
隨便說一下,當時騰訊來過,我去面準備不足(第一次面),直接被一面bs,我就暗下決心,你bs我,我就以后bs你,所以現在聽有人進了騰訊,我就不由分說bs一番。(現在只是說說了,雖然心里知道它現在的霸主地位) 等我以后再真正bs你吧。
那時候,華為還沒有過來,但早就聽說華為的速度(無論面試還是offer)最慢,我是那種不喜歡條條框框的人,直接不等它了。
進了公司后,開始做測試,我的性格里只有兩種事情劃分,要么做好做么不做,開始的測試工作還是蠻有意思的,學習也真的很快,期間也收獲了同事們 的認可,然而時間一長,測試的重復工作和無力的成就感使得我不得不重新考慮以后的計劃,以后的幾天,我向我導師反映了我的心態與計劃,轉崗or離開。 然而,在那時候我堅持了下來,半年后我們的測試主管確定成立自動化測試部,在10年4月的某一天,我全職投入自動化,從基本上是零一直到現在。
因為公司的自動化發展特殊性,我們的自動化投入基本上是:
投入自動化項目 -> review效果 -> 剝離框架 -> 投入自動化項目
目前效果產出比較明顯,好幾個版本ROI超過了2,直逼3。 在這里我建議投入的項目是:
基本功能bvt -> 易于實現的自動化功能 -> 提高部分模塊自動化率, 期間不斷優化框架與平臺,整合出我們的自動化云端。
目前我們有5個人全職自動化,馬上會有新人繼續加入。
寫在這里,這篇已經很長了,接下來就自動化實施的難點加以分析與說明。為自己留下些成長中途的記憶。
在前述的文章中對獨立測試無用論做了“激烈”的回擊,支持者有之,反對者有之,總之能引起大家的思考就好。這篇我打算寫溫和一點的內容,那就是,反向思考,為什么有些獨立測試不招人待見?如果從獨立測試工程師自身出發,我們應該如何避免做“庸俗”的測試工程師?以下是觀點:
1、做發動機,不做拖油瓶。
當碼農那年,剛開始進一項目,對面的核心開發就開始被一個測試大哥“騷擾”,此測試大哥言談高調,目光如炬,最善發現類似頁面倆空格只有一個,倆輸入框不該在一行這類問題。
發現UI錯誤本身沒錯,確實現在好多頁面的界面也夠嗆。但是,哥,咱們是在項目的前期啊,開發腦子里都是核心業務如何實現,三個表四百個字段怎么高效操作,你確定他們該停下來改UI嗎?
UI是重要,UAT(客戶驗收測試)之前抽個幾天就可以做出很大改進,不是嗎?
團隊利益的核心是什么?按時交付。而測試人員的價值是:項目高質量交付。那么團隊利益和測試利益在根本上就可能沖突。這還怎么一塊過?......其實也能過。男人的價值觀和女人還不一樣呢,那么多兩口子不也一過一輩子。
所以,后來做測試經理和團隊負責人時,在項目前期,都要求測試人員提高對這類UI、易用性缺陷的容忍度,這么做有兩個好處:
第一, 開發和測試在前期不會因為這些問題爭執不下,前提是,開發人員必須耐心的給核心測試講清楚,現在重要的是什么。小問題不一定不重要,什么時候你準備把這些東西拾起來?
第二, 測試人員避免心理收到打擊:為什么我辛苦測試出來的bug沒人重視。在這種時候,耐心的把項目的情況解釋清楚,測試人員一般都會接收團隊價值。
不做拖油瓶測試,核心的要求就是:你得知道項目處于什么階段,最大的風險是什么,該做什么不該做什么,不該做的什么時候撿起來做。
在最極端情況下,測試組的結論是“產品質量是狗屎,不能發布”,但是項目經理的要求是“一定要發布,除非從老子尸體上踩過去”,那怎么辦?
三國中關羽失荊州被殺,劉備大怒準備伐吳,諸葛亮勸諫不可,劉備不聽,最后果然劉備大敗。
大概,項目經理有更高的訴求,測試所為,只能是把情況列出,含淚再拉一把:主公,我們還是準備準備在Release吧…Orz
現實就是這樣,決策就有風險,測試就是提供決策支持,至于聽不聽,結局如何,只能讓歷史去評說了。
PS: 文中那位測試大哥,真心不適合做測試,適合去當公務員,當那個圈兒的人,最后他還真去事業單位了。
2、做謝耳朵,不做軟耳朵。
以前面試測試工程師的時候,很喜歡問一個問題,如果你提的bug,開發人員激烈反對,你怎么辦?
注意!這個問題沒有標準答案。只是想通過測試人員的回答檢驗他們對于反對意見的處理方式。
軟耳朵測試要不得:開發說這不是bug,這是特性,好吧那就是特性;開發說這是你用的方式不對,好吧那就是方式不對;開發說這是你點鼠標的姿勢不對,好吧那就是姿勢不對;開發說測試沒技術含量,好吧那就是沒技術含量;開發說不需要測試,好吧那就不需要測試!
拜托,拿著這樣的測試人員寫出來的報告,你晚上能放心的睡覺?
個人喜歡有點小強迫癥的測試工程師:不能復現的一定想辦法復現;開發不接受的一定要據理力爭,真理是越辯越明。
看生活大爆炸嗎?里面的謝耳朵最多人喜歡,他有時候夠討厭,但是他的觀點很多時候也最有價值,不是嗎。
3、不抱怨。
哥上大學的時候最討厭的那種人就是:整天自言自語,如果運氣好一點就去清華了~~喵的,有那功夫倒是退學去復讀啊?
有些庸俗的測試工程師,整天把如下的話掛在嘴邊:
唉,我的工作還真的是沒有技術含量。
如果我運氣好一點我就去做開發了。
我的工作好重復。
整天吐槽這些,你還不如放棄測試,去隨便做個什么你認為可以解放你的職位。哪些你沒有從事的職位就那么好?
你說工作充滿重復,可你知道那些話劇大師的臺詞重復了多少遍?
你說開發有技術含量,可你知道get,set一千遍一點技術含量也沒有嗎?
我尊重那些即使大部分是重復,仍然兢兢業業不放過任何細節,自己尋找新意的工程師;尊重那些別人都在無所事事給淘寶做人肉壓力測試時,自己默默在畫bug魚骨圖的工程師;尊重那些真正熱愛這個職業,維護這個職業的人。
有句話叫做,世間三件好:別人家的飯菜,別人家的媳婦,別人家的工作。
4、爭論,不爭吵。
我們的工作就是給人挑茬,正常人被找茬都會下意識的反應:md,老子才沒有錯。差別就是年輕開發會張嘴而出,成熟開發會在心里默念一遍然后給你一個職業的笑臉。所以開發和測試經常吵起來,所謂的小吵怡情,大吵傷身,一定要在可控范圍。
如何要做到爭論而不爭吵,借用捷克政治家哈維爾的論壇討論守則(個人不同意他的不少政見,但是支持幾個觀點)
《對話守則》: a. 對話的目的是尋求真理,不是為了斗爭。 b、不做人身攻擊。 c、保持主題。 d、辯論時要用證據。 e、有可能承認自己是錯的。 f、要分清對話與只準自己講話的區別。 g、對話要有記錄。 h、盡量理解對方。
另外加一條,能在工程師級別解決的,就不要交給你的老板…
我覺得很多測試和開發之間的矛盾,實際上是溝通的方式不對。就開發人員來說,他們只是不太善于溝通,他們真的是一些單純的好人?
因為寫用例的習慣,一篇爭取只有一個觀點,但是“庸俗”測試者真的是一個大話題,這篇內容多一點,忍耐這看吧。后續對這個話題,我再補充。
PS:有一個工程師有天問,如果把開發和測試對等于工地上的職位,開發是碼磚的,測試就是質檢或者監理嗎?我回答,錯誤,開發是碼磚的,那測試就是那個抹泥的。開發測試是配合關系,絕不是管理關系。
在本篇文章中,我們將集中介紹一些方法,來幫助你在你的環境中使用并確保IIS7服務器和其應用程序的安全。
1、第一步,確保你的Web服務器是強化的OS操作系統。如果你使用的是Windows Server 2008 R2的操作系統,那么服務器核心安裝版本會給你需要的——所有功能,但不能降低被攻擊的風險。如果你正在使用常規版本的Windows Server,可以試著安裝IIS,它只是作用于你目前所需要的裝置。根據你的需要,也可以恢復或者安裝更多你所需要的功能。注意,當你添加了,你不使用的裝置時,這會使你受到的攻擊范圍擴大。
2、使用防火墻可以真正幫助你保護WEB服務器,尤其是面向互聯網的服務器。防火墻能確保服務器只接收有效的有服務的封包。當外部襲擊者試圖對你的服務器進行惡意攻擊時,防火墻就是你的第一道防線。使用入侵預防系統(IPS),可以進一步保障你的系統,尤其是IIS服務器。 如果你的系統不是很大,不需要裝特定的硬件防火墻裝置時,你也可以利用Windows Server 2008的綜合防火墻同樣可以獲得較好的安全性。
3、用IIS7控制ip和域限制訪問你WEB服務器的內容。 例如,你可以只授權組織內部域的訪問。或者添加除合作伙伴以外,管理員家里的IP地址,老板或其他任何你希望可以訪問的組織或者個人。
4、IIS7可讓你更好的過濾需要處理的,需要過濾的信息。利用這一特點你可以對特定規則要求過濾,例如處理帶有特定擴展名的文件,或者處理在URL中的特定短語。
5、當一個有效的包進入IIS處理時,同時也應該會有一個授權的人。IIS7允許你使用一個過程調用 URL授權。 特定的頁面和/或Web服務器的網站,可以授權給不同的用戶。默認情況下,用戶應首先驗證自己,并根據其驗證身份,然后允許或不允許進入他們所要求的網頁/網站。這與之前ISS版本不同,管理員可設置文件系統級別上的權限。使用URL授權IIS7的方式來支持更詳細的授權用戶。
6、確保你的IIS服務器的最佳方法之一是通過使用有證書的SSL通信在用戶和Web服務器之間。如果服務器是公開使用的,你應該要從GoDaddy或Verisign這樣的受信任的證書頒發機構頒發的證書。這個證書在任何瀏覽器上,在任何一臺電腦上,都是可信任的,也是最容易的,但是使用SSL的缺點就是價格較高。如果IIS服務器只在你的組織內部使用,你可以使用自己的PKI證書發出的Web服務器,在你所處的環境。但是,內部用戶訪問時可能存在,在不同的電腦上沒有安裝證書的計算機訪問會出現問題。如果你的IIS服務器只在測試環境中使用,那么你可以在ISS管理工具中,使用自簽名的證書。在以前的ISS版本中沒有集成這一功能,你必須從微軟下載一個工具來創造自己的簽名證書,而在IIS7中,這個過程就容易多了。
7、日志 是一個讓你最有保障的方法。它可幫助你搜索攻擊源或者一個服務器損壞的原因。從一開始就確保你的設置,并在危機關頭協助你的監測工作。
8、如果你感覺你的IIS基礎設施和所有的安全解決方案已經沒有問題的話,那么就要進行測試了。使用測試工具微軟會提供給你大師級的策略來確保你的測試是最好的方法。 做測試最常用的工具是SCW和SCM。下面就來介紹一下:安全配置向導(SCW)——這是根據你的服務器除IIS服務器之外,是否或者還扮演一些其他的角色,而有所不同。 測試結束后SCW會告訴你如何提高服務器安全性的報告和建議。安全合規管理器(SCM)-是微軟給你的服務器做安全測試的工具。在與配置服務器的預定義模板進行對比后,通過改變使用策略來配置服務器。SCM使用更新過的數據庫工具,要比SCW所使用的工具更復雜。從而確保你定期進行初始化安裝服務器后能運行這些工具。
9、上面提到了有關IIS日志記錄功能的作用,但日志最重要的作用是為你監視特定事件可能導致服務器或托管的應用程序中存在的問題。同樣重要的是為你監控服務器本身的運行時間,可用性和性能問題。 也可以監控IIS服務器的一個SLA協議的對象,無論是內部(公司)或外部(客戶端)的SLA要求。 理論上,這種監測可以由一個服務器管理員手動完成,但要更高效、更可靠的話可把這種工作,交給像Monitis的監測公司解決。
說到存儲過程和觸發器,其實在以前做機房收費系統的時候就接觸到了。但是當時總感覺存儲過程和觸發器是比較高級的東西,這個系統不用這些東西也可以。于是就一直沒有好好研究這塊知識。現在看牛腩新聞發布系統,再一次涉及到了這個東東,這才發現,存儲過程和觸發器并沒有想象的那么高深莫測。也許有人會說:那是你沒有深入研究。是,我承認,但個人覺得目前我們還沒有必要那么深入研究。我們要做的就是:用20%的努力,獲得80%的知識。這樣就基本上可以滿足我們日常的需求了。下面就宏觀上說一下存儲過程和觸發器。
什么是存儲過程呢?官方是這樣定義的,存儲過程(Stored Procedure)是在大型數據庫系統中,一組為了完成特定功能的SQL語句集,經編譯后存儲在數據庫中,用戶通過指定存儲過程的名字并給出參數(如果該存儲過程帶有參數)來執行它。
1、創建存儲過程語句如下:
createprocedure 存儲過程名 @[參數名] [類型],@[參數名][類型] as begin 自定義的功能 end |
2、調用存儲過程
exec sp_name [參數名]
3、刪除存儲過程
drop proceduresp_name
其實,說白了,存儲過程就是一類特殊的函數,只要我們給它合適的參數就可以直接調用,跟調用API函數差不多,唯一不同的就是API函數大部分是別人寫的,而存儲過程我們一般都是自己寫。
注意:不能在一個存儲過程中刪除另一個存儲過程,只能調用另一個存儲過程。
那么什么是觸發器呢?嚴格意思上說,觸發器就是存儲過程,只不過它的執行不是由程序調用,也不是手工啟動,而是由事件來觸發。
創建語句如下:
CREATE TRIGGER`<databaseName>`.`<triggerName>` < [ BEFORE |AFTER ] > < [ INSERT | UPDATE | DELETE ] > ON <tableName> FOR EACH ROW BEGIN --do something END | |
這時有人不解了,什么叫由事件來觸發呢?其實這和botton按鈕的點擊事件一樣,只不過觸發器是由Insert、Update、Delete這些動作觸發,而botton的點擊事件是通過點擊的動作來觸發的。
那么存儲過程有哪些優點呢?
1、速度快。
在運行存儲過程前,數據庫已對其進行了語法和句法分析,并給出了優化執行方案。也就是說,存儲過程在調用前就已經編譯好了,所以存儲過程能以極快的速度執行。
2、存儲過程可以重復使用,可減少數據庫開發人員的工作量 。
3、保證數據的安全性。
通過存儲過程可以使沒有權限的用戶在控制之下間接地存取數據庫,從而保證數據的安全。
4、保證數據的完整性。
通過存儲過程可以使相關的動作在一起發生,從而可以維護數據庫的完整性。
既然存儲過程有如此多的好處,那么我們做項目的時候是不是用的越多越好呢?答案肯定是NO。萬事都有個度,存儲過程也一樣。如果在一個程序系統中大量的使用存儲過程,那么必然會導致它的數據結構相當復雜,這樣維護該系統將會是相當困難的一件事。
讓我們合理使用觸發器和存儲過程,盡情享受他們帶給我們的方便。