
試用例設計是測試過程中非常重要的一個活動,不管是文檔化的設計輸出,還是只是存在于他們腦海中的測試思想,其質量都會直接影響測試執行的質量。
盡管每個測試人員都掌握了不少的測試用例設計技術與方法,例如:等價類劃分、狀態轉換測試等,但是如何將它們應用到具體的測試對象測試中去,很多測試人員都會感覺有些力不從心,甚至有無從下手的感覺。
下面是針對某個功能模塊的一個簡單的需求描述:該基本功能是為了創建某個條目,它的基本需求如下:
假如dataBit0 = 0, 并且cBPDU或者pBPDU的值不為1,那么創建請求會被拒絕。假如dataBit0 = 0, 并且cBPDU = 1或者pBPDU = 1,在滿足下面條件下可以創建成功: (1)其他的bit不能為1; (2)TD的取值必須是Guranteed; (3)VLANpop的取值必須是disabled; |
假如你得到這樣的一個需求描述,你準備如何來設計該功能模塊的測試用例?通常來說,測試人員拿到需求規格說明之后,會根據其中定義的需求條目設計測試用例,類似于如下過程。

圖1 通常的測試用例設計
針對上面的需求描述,根據圖1直接設計測試用例,會不會覺得有些迷茫呢?即使測試人員設計了多個測試用例,覆蓋了每條測試需求,是不是也會覺得評估測試覆蓋率比較困難?
實際上,需求規格說明通常是針對開發人員而寫的,并不一定直接適合測試的要求。因此,假如測試人員希望能夠更好的進行測試用例設計,需要將需求規格說明轉化成為測試人員可以方便使用的語言很重要,即在需求規格說明和設計測試用例之間增加一個橋梁:模型。在建立模型的過程中,測試人員不僅需要學習需求規格說明,同時也需要了解各種測試設計技術與方法,并能將兩者數量的結合起來。圖2是增加了“模型”概念的測試用例設計過程。

圖2 改進的測試用例設計
還是以上面的需求描述為例,我通過學習該需求之后,發現它可能可以與決策表技術結合起來。因此,我將上述需求翻譯為適合決策表技術的各種條件與輸出,并根據它們的不同組合得到不同的結果。圖3是我針對上述需求描述,基于決策表技術得到的初始決策表,然后可以基于此進行決策表優化,直至得到概要和詳細的測試用例列表。

圖3 初始決策表
根據圖2的過程得到的圖3的結果,是否覺得整個測試設計過程更加清楚,而且更加容易進行測試覆蓋率等方面的評估?注意:這里只是根據需求描述得到的一些測試用例,并沒有考慮其他方面的測試用例,例如非功能測試用例等。
需求規格說明對測試人員很重要,測試設計技術與方法也很重要,但更重要的是測試人員如何能夠將兩者有效的結合起來,并在此基礎之上建立適合測試設計和評估的“模型”。而這通常是測試用例設計的難點所在,同時也是體現測試人員技術含量的地方。下面是測試人員在建立模型過程中可以參考的一些方向:
1、基于黑盒測試技術,例如:決策表模型、狀態轉換模型、正交矩陣模型等;
2、基于測試類型,例如:質量特性模型、缺陷分類模型等;
3、基于全局因素的全局因素模型;
4、基于功能交互的功能交互模型;
測試設計過程中建立有效的“模型”,測試人員設計測試用例相對會比較容易,并且可以很好的提高測試覆蓋率,從而幫助提升產品質量。另一方面,通過建立模型,也可以幫助測試人員有效的評審測試對象功能的描述,例如可以發現需求中定義不清楚、遺漏等方面的問題。
摘要: Action() { int rc; int db_connection; // 數據庫連接 int query_result; // 查詢結果集 MYSQL_RES char** result_row; // 查詢的數據衕 &nbs...
閱讀全文
摘要: 方法一:要想使用LoadRunner監測MySQL數據庫的性能,LoadRunner沒有提供直接監測 MySQL的功能,所以,我們需要借助sitescope監控,然后在LoadRunner顯示sitescope監測結果,這樣間接地監控MySQL性能。 相信大家對LoadRunner應該十分熟悉了,所以在這里,我大概介紹下sitescope的安裝和使用。 s...
閱讀全文
用例設計的著眼點
1、測試的依據是需求規格說明書,首先應根據需求規格說明書對軟件進行需求分解,然后針對每個測試需求去編寫相應的測試用例;
2、測試用例的編寫時,應按照需求規格說明書的內容,設計合理的測試用例,同時更重要的是考慮不合理的輸入情況;
3、除了設計各子測試需求的測試用例外,還應考慮業務流程測試用例,業務流程測試用例主要由各種以驗證業務流程正確性為主的測試用例組成。
測試用例的必備要素
1、項目名稱和模塊名稱
當前用例所屬的項目及被測的功能模塊。
2、測試用例編號:是由字符和數字組合成的字符串,用例編號應具有唯一性、易用性。作為測試用例的唯一標識,命名方式采用“測試類別簡稱-項目名稱-模塊名稱-序號”。
舉例:F-RSXT-ZJJL-001
F是功能測試用例的縮寫(S-安全測試 P-性能測試)
RSXT是項目“人事系統”的簡稱
ZJJL是模塊“增加簡歷”的簡稱
001是具體的用例編號
3、用例名稱
測試用例的具體名稱
4、預置條件
執行當前測試用例需要的前提條件,描述要執行該用例,被測目標須達到的狀態,例如,用具備正確權限的人員登錄系統。
5、編制者和編制日期
當前用例的編制人員以及編制用例的日期(格式為“年-月-日”)。
6、測試步驟:執行當前測試用例需要經過的操作步驟,需要明確的給出每一個步驟的描述,測試用例執行人員可以根據該操作步驟完成測試用例執行
7、預期結果:當前測試用例的預期輸出結果,包括返回值的內容、界面的響應結果、輸出結果的規則符合度等等。 在我們的測試培訓中,有具體的功能測試實踐課程,課程中會選擇一個實際的項目,讓學員親身去體驗整個測試的流程,包括測試計劃
1、測試計劃階段:
理解測試需求,編寫測試計劃,并根據需求規格說明書,完成系統的需求分解;
2、測試設計階段:
為第一步中分解得出的具體的測試需求,設計相應的測試用例;
3、測試執行階段:
按照自己設計的測試用例,執行測試,并記錄用例執行結果,提交測試過程中發現的缺陷;
4、測試總結階段:
對測試過程中發現的缺陷進行整理分析,完成測試報告。
在這個過程中,每個環節工作產品的評審是由老師和學員共同完成的,其中問題最多的環節就是測試設計階段,部分學員在上課時都會跟我說,“老師,設計測試用例好煩,為什么要設計測試用例,真正做測試項目時也要向這樣設計測試用例嗎?”我總是笑笑,很肯定的對他們說:“要的”。
軟件測試也是一個工程,也需要按照工程的角度去認識它,即在具體的測試實施之前,需要我們需要明白我們測什么,怎么測試等等,也就是說通過制定測試用例指導測試的實施。
其實設計測試用例并不是想象中的那么復雜,只要條理清晰,有耐心,并掌握基本的功能測試用例設計方法,設計出好的測試用例并不是件復雜的事情。
培訓中,我也發現其實有兩類學員,一類是總抱怨要設計的用例太多,什么時候才能設計完成,就一直停留在閱讀需求說明書的階段,而不愿意動手去做;而另一類呢,則是不管結果怎樣,我先開始著手做起來。很顯然,后一種是收益較多的一類,因為只有自己去動手做了,才會發現事情的難易程度到底怎樣,才會了解事情的本質,以及自己在哪方面有所欠缺,而且,也只有當你有了中間結果時,老師才會去幫你檢查,指導你測試用例設計時存在的一些不足或欠考慮的地方。
什么事情不要只是去想,想著它有多么的困難和復雜,一切事情都有解決的辦法,不管事情有多復雜,它也是一點一點完成的,夸張點說,我們應本著愚公移山的精神,等到過程中,說不定也就會有神仙來幫忙呢。
下面簡單介紹下設計測試用例時的幾個注意點:
測試用例基本準則
1、測試用例應具有代表性:能夠代表并覆蓋各種合理的和不合理的、合法的和非法的、邊界的和越界的以及極限的輸入數據、操作、環境設置等;
2、測試結果應具有可判定性:即測試執行結果的正確性是可以判定的,每一個測試用例都應有相應得期望結果;
3、測試結果應是可再現的:即對同樣的測試用例,系統的執行結果應當是相同的。
2)可靠性測試。根據軟件需求和設計提出的要求,對軟件容錯性、易恢復性、錯誤處理能力進行測試。
3)易用性測試。根據軟件設計中提出的要求,對軟件的易理解性、易學性和易操作性進行檢查和測試。
4)性能測試。根據軟件需求和設計中提出的要求,進行軟件的時間特性、資源特性測試。
5)維護性測試。根據軟件需求和設計中提出的要求,對軟件的易修改性進行測試。
6)可移植性測試。根據軟件需求和設計中提出的要求,對軟件在不同操作系統環境下被使用的正確性進行測試。
11、軟件測試分為哪幾個階段?每個階段都是干什么的?
測試階段 | 主要依據 | 測試人員及方式 | 測試內容 |
單元測試 | 系統設計文檔 | 開發人員。白盒測試 | 又叫模塊測試。 主要測試軟件模塊的源代碼,接口、路徑 |
集成測試 | 概要設計、需求文檔 | 開發人員。白盒測試 | 又叫組裝測試、聯合測試、灰盒測試。 將一些“構件”集成一起時,測試它們能否正常運行,接口、路徑、功能、性能 |
系統測試 | 需求說明書 | 一般由獨立的測試人員執行。黑盒測試 | 測試軟件系統是否符合所有需求,包括功能性需求和非功能性需求,功能、健壯性、性能、用戶界面。 |
確認測試 | 規格說明書 | 第三方。黑盒測試 | 又叫有效性測試。 驗證軟件的功能和性能及其他特性是否與用戶的要求一致。 |
驗收測試 (UAT) | 需求文檔 | 由客戶或最終用戶執行。黑盒測試 | 確定產品是否能夠滿足合同或用戶所規定需求的測試。 |
12、測試中的木桶原理是什么?在軟件產品生產方面就是全面質量管理(TQM)的概念。產品質量的關鍵因素是分析、設計和實現,測試應該是融于其中的補充檢查手段,其他管理、支持、甚至文化因素也會影響最終產品的質量。應該說,測試是提高產品質量的必要條件,也是提高產品質量最直接、最快捷的手段,但決不是一種根本手段。反過來說,如果將提高產品質量的砝碼全部押在測試上,那將是一個恐怖而漫長的災難。
13、軟件測試策略和方法有哪些?靜態測試方法:人工測試方法(代碼會審,代碼走查,桌面檢查等);動態測試方法:白盒測試方法、黑盒測試方法、窮舉測試方法。
靜態測試:基本特征是對軟件進行分析,檢查和測試是不實際運行被測試的軟件。
動態測試:通過運行軟來檢驗軟件的動態舉行為和運行結果的正確性,其兩個基本要素是被測試程序、測試數據。
14、測試何時結束?當功能性測試用例通過率達到100%,非功能性測試用例通過率達到90%時,允許正常結束測試。
15、測試用例需要有些什么?測試環境、測試數據、測試步驟、預期結果。
16、用例設計原則是什么?覆蓋軟件需求規格說明書所有的測試點;指出實際輸出值和預期結果;考慮各種輸入輸出條件和邊界值;設計應考慮其可執行性。
17、當在HTML中寫JavaScript腳本的時候可能會造成頁面性能慢或是有錯誤,這個怎么解決呢?
通常,JavaScript腳本寫在HTML頁面中body部分的前面,這可能要在網頁上設置一些可運行腳本之類的配置,或盡可能避免。
18、在測試工作中,你是怎么和開發人員溝通呢?怎么能達到一致目的呢?
當發現問題的時候,描述到bug管理器bug free、Test Track Pro等上面,并提供一些截圖上載作為證據,或當面和開發人員溝通,盡量把問題描述清楚,這些都不存在問題,但關鍵就是有很多開發人員并不承認這是他程序的錯誤或認為not a bug,不予修改,當遇到這種情況我會盡可能跟他溝通,盡可能去重現問題,根據需求講道理,此時根據需求是很重要的,當我們實在溝通不下去的時候,在這種不明確bug性質情況下會發郵件讓項目經理大家一起評審,是他的問題就改,not a bug就打回。
19、假如項目已完成差不多,但客戶的需求不明確,在我們內部也沒有定義,這種情況怎么辦呢?
我會把自己當客戶,設身處地的為客戶提出問題或建議,比如最常見的是易用性操作,軟件規范等。
20、你是怎么理解測試的?測試的目的是發現程序中有錯,是為了證明程序有錯,而不是證明程序無錯,盡可能發現并改正被測試軟件中的錯誤,提高軟件的可靠性。測試能發現錯誤的測試是成功的測試,否則是失敗的測試。
21、你對自己做測試是怎么個想法?我想一直做下去會有收獲的吧,會去不斷完善自己的技能,把自己沒學會的技能都去學習下,會不斷完善自己。 1、軟件的生命周期是什么?指從軟件產生到報廢整個周期包括:可行性分析、項目計劃、需求分析、概設、詳設、編碼、調試、維護。
2、軟件開發模型有哪些?瀑布模型、漸增模型、演化模型、迭代模型、原型模型、螺旋模型、噴泉模型、智能模型、混合模型。
3、一套完整的測試包括哪些?測試計劃、測試設計、測試開發、測試執行、測試評估。
4、軟件測試生命周期是什么?從測試項目計劃建立到bug提交的整個測試過程,包括:軟件項目測試計劃、測試需求分析、測試用例設計、測試用例執行、bug提交五個階段。
5、一個典型B/S架構由哪三個組件構成?數據訪問層、業務邏輯層、實體層。
6、OSI網絡七層協議及每一層的功能是什么?OSI網絡七層協議從下向上的順序為:物理層、數據鏈路層、網絡層、傳輸層、會話層、表示層、和應用層。
物理層:本層規范了各網絡媒體的定義、網絡的連接方式等內容。
數據鏈路層:本層定義了幀(frame)的格式及通過網絡的方式。幀中有MAC地址(網卡的號),幀要傳送的來源與目的地是依據MAC進行傳送的。該層有個重要的ARP(Address Resolution Protocol)協議,用它來對應MAC和IP地址。
網絡層:IP 是網絡層的重要內容。本層的功能是讓數據包(Packet)可以在不同的網絡間進行傳遞;這層包括IP協議、ICMP協議、ARP協議、RARP協議。
傳輸層:將計算機數據打包為數據包(packet),然后提供給網絡層進行包頭的建立;這層包括TCP協議、UDP協議。
會話層:本層中定義的兩個地址間的信道的連接與掛斷,即計算機與計算機之間的溝通方式。兩個計算機在通信前先要進行會話,確認是否可以進行傳輸。如三次握手協議。
表示層:將用戶本地的數據格式轉換為網絡的標準格式,然后交給傳輸層的協議處理。同時把遠程的數據轉換成本地應用程序的格式,然后將給應用程序處理。即本層定義了數據的語法及格式,當數據不符合要求時進行格式的轉換。
應用層:本層完全與應用程序有關。這層包括FTP、Telnet、SMTP、HTTP、RIP、NFS、DNS。
7、什么是網絡協議?它的三要素是什么?常見的網絡協議有哪些?
網絡協議是網絡上所有設備(網絡服務器、計算機及交換機、路由器、防火墻等)之間通信規則的集合,它規定了通信時信息必須采用的格式和這些格式的意義。
網絡協議的三要素是:語法(用來規定信息格式);語義(用來說明通信雙方應當怎么做);時序(詳細說明事件的先后順序)。
當今局域網中最常見的三個協議是:Microsoft的NetBeui、Novell的IPX/SPX、交叉平臺的TCP/IP協議。NetBeui即NetBios Enhanced User Interface,是為IBM開發的非路由協議,用于攜帶Netbios通信.。IPX是Novell用于Netware客戶端/服務器的協議群組,避免了NetBeui的弱點,它具有完全的路由能力,可用于大型企業網。TCP/IP即Transmission Control Protocol/Internet Protocol,中文譯名為傳輸控制協議/互聯網絡協議協議,TCP/IP(傳輸控制協議/網間協議)是一種網絡通信協議,它規范了網絡上的所有通信設備,尤其是一個主機與另一個主機之間的數據往來格式以及傳送方式。具有可擴展性和可靠性需求。
8、關系數據庫的三個基本要素是什么?相關數據、一定組織方式、共享。
9、目前linux操作系統提供一個常用文本編輯器是什么?有幾種模式?vi編輯器。有(文本輸入)(命令)兩種模式。
10、測試計劃的目的是什么?測試計劃工作的內容都包括什么?其中哪些是最重要的?
測試的目的是發現程序中有錯,是為了證明程序有錯,而不是證明程序無錯,盡可能發現并改正被測試軟件中的錯誤,提高軟件的可靠性。測試能發現錯誤的測試是成功的測試,否則是失敗的測試。
軟件集成測試具體內容包括:
1)功能性測試
(1)程序的功能測試。檢查各個子功能組合起來能否滿足設計所要求的功能。
(2)一個程序單元或模塊的功能是否會對另一個程序單元或模塊的功能產生不利影響。
(3)根據計算精度的要求,單個程序模塊的誤差積累起來,是否仍能夠達到要求的技術指標。
(4)程序單元或模塊之間的接口測試。把各個程序單元或模塊連接起來時,數據在通過其接口時是否會出現不一致情況,是否會出現數據丟失。
(5)全局數據結構的測試。檢查各個程序單元或模塊所用到的全局變量是否一致、合理。
(6)對程序中可能有的特殊安全性要求進行測試。
淺談軟件的質量意識
“質量問題是關鍵,但是現在又有多少企業是重視質量的,反倒是年年都生產出一大堆的垃圾。一個企業質量意識形態是由上而下的,領導注重質量才能把質量提上去,單單是靠下層員工有質量意識而領導要求的卻是數量,要求的是短期效益,這樣的質量是根本提升不了,中國建筑壽命縮短到30到40年就是一個事例”
那我想說的是:這樣的環境,我們無法改變。但是我們可以選擇,如果你愿意暫時犧牲一些所謂的管理職務,進入真正的重視質量的企業。你就可以在正確的路上走完人生未來的職場之路。但世上無完美的事,即使一個重視質量的企業,在內部也會有部分中基層人員局部的不夠重視質量,只要數量和進度。大多數情況下公司高層(最高的那幾個)是重視質量的,因為他們更在乎長期利益,更在乎賣出去的產品或服務的品質代表他在客戶面前的面子和人品。所以,如果高層不是投機取巧型,上市撈一把就跑的投機分子,足可以在環境中堅持。這個堅持不是1-2個月會改變的,有可能會是1-2年才會改變的,畢竟產品的bug很可能要在放量上市時,才會大量暴露,這時公司的高層中層都不得不開始重
視質量,來亡羊補牢,否則所有先前的投資就有可能付之東流。在此我分享2個我幾年前的經歷吧。
N年前我參與一個項目時,在看了該項目的需求,了解了項目成員和項目技術積累現狀后,看到項目的計劃時間表時,我心里就敢肯定決不可能按時交付項目的。當然,我內心也希望能發生奇跡該項目能幸運的按時交付。在后續的產品設計階段,我看到了產品架構文檔和部分設計文檔后發現架構師設計時思考的過于簡單,很多場景未考慮,或考慮時選取的算法過于簡單,當時就給架構師提出了幾十個可能的設計問題,在架構師確認了二十多個后,郵件正式發給了PM。可惜,PM和架構師都沒有采取行動去改進(因為項目的基本功能實現的時間和人力太緊張了),我心里只能是暗暗的祝福他們好運,但這時我可以肯定這個項目不可能按時完成了。 結果在1年后,碰到該產品的測試人員,他告訴我那個項目幾乎延期了60%的工期,而且產品測試時發現了大量設計的問題,為了修改和驗證這些設計問題,開發和測試都加了很多班阿。此時,我既喜既憂。喜的是我的判斷,我的質量預言兌現了。憂的是這個項目的所有參與人,公司都付出了太多的代價了,如果當初架構師和PM能把我發現的設計缺陷及早修正,或許也能減少后期所付出的代價。
M年前,我到一個新公司后發現很多測試人員和測試經理為了與開發人員有一個良好的人際關系,對bug要求不嚴。甚至有的組出現不做壓力測試的情況,理由是壓力測試出來的bug開發改不了,測了也沒有意義。同時項目中PM和開發經理權力過大,只要進度,進度和質量沖突時,一定是犧牲質量,測試經理早已習慣,也不堅持質量了。整個氛圍普遍是等出了問題后再亡羊補牢,提前做的預防性工作都不受支持,認為是浪費。 很多開發領導認為,只要我有測試部這個組織,找來了幾十個測試人員,我的質量就OK了,可是在一個測試人員都對開發人員過于偏軟的氛圍中,測試人員在很多關口也隨大流了。雖然我當時很看不慣,但無奈我個人的力量是有限的,我只有盡可能地在我的領域做好工作。并
在心中期盼我的預測不要兌現。可是M+1年后公司很多產品在市場上忽然出現了很多問題,PM日子過得難受,開發和測試經理日子過的也難受。我的預言又一次兌現了。從此以后這個公司的開發人員和PM們痛定思痛,終于把質量放在了第一位,進度可以延遲但質量不會讓步了。同時測試人員也被要求必須嚴格地做黑臉。M+2年后,該公司的產品因為價格便宜質量又高,銷量猛漲了幾倍。
我想我的答案已在分享的2個案例中了。真的是應了《無間道》中的那句話“出來混遲早要還的!” 我現在往往只需要幾天時間就能提前預判該項目最后的進度和質量結局,雖然我心里依然希望該項目能走大運,能創造奇跡,希望我的預言是錯誤的。
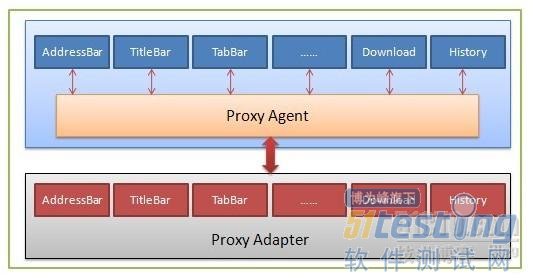
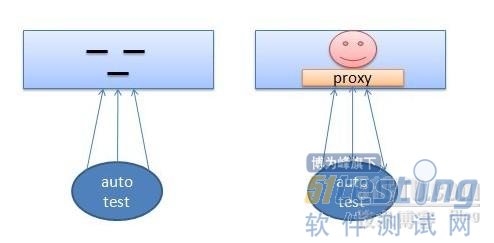
基于以上面臨的問題,一種“開后門”的方法引起了我們的注意,“后門”是指RD在程序中專門為了某些目的開設的訪問通道,通過這些隱秘不為人知的數據訪問通道,可以實現特殊的產品功能。對于自動化來說,我們可以通過這種方式將程序的一些界面信息暴露,當然也不局限于UI的信息,我們也可以將任意測試程序需要的信息通過后門的方式暴露給我們自己的測試程序即可以實現自動化相關的需求。
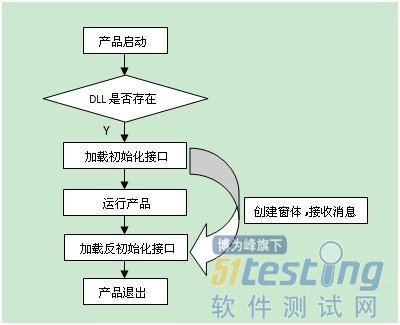
這個想法在后期的實踐中逐步優化,最終形成了一套基于Proxy架構的自動化解決方案。當被測程序啟動時,加載Proxy,并將皮膚引擎的指針(全局變量)傳入Proxy中,自動化腳本通過與Proxy通信,實時獲取UI的各種信息該框架包含兩大部分:
1、一部分是以Pywinauto(Pywinauto是一些用于自動化測試Windows標準圖形界面的模塊的集合。它可以允許你很容易的發送鼠標、鍵盤動作給Windows的對話框和控件)為操作基礎,pyunittest為case組織框架的python腳本部分,這部分包含了關鍵字的封裝,case的實現。
2、另一部分是植入到被測程序內部的Proxy,當被測程序啟動時,加載Proxy,并將皮膚引擎的指針(單例)傳入Proxy中,自動化腳本通過與Proxy通信,實時獲取UI的各種信息,從而達到自動化的操作以及驗證的目的。
整個自動化框架圖如下:
執行
穩定性測試不同于功能測試的自動化,它屬于一種概率性的測試,需要長期運行過后才能得出最后的測試結論,即使穩定性測試通過,也不能保證系統實際運行的時候不出問題。所以要盡可能的提高測試的可靠性,我們可以通過多次測試,延長測試時間,增大測試壓力來提高測試的可靠性。
當穩定性場景存在多組時,為了保證運行的及時性與可靠性,同時也為了滿足測試環境的豐富性,穩定性測試的執行需要多臺機器才行。如果條件允許,可以使用不同環境及配置的物理機進行測試,也可以使用虛擬機,構建豐富的環境中心來滿足穩定性測試的需求。
當存在多個運行環境和多組case時,為了保證測試場景組合的多樣性,各組case要階段性的循環在每個運行環境中執行,因此需要一個清晰明確的執行計劃和記錄:
 客戶端穩定性測試
客戶端穩定性測試
穩定性測試是在保證功能完整正確的前提下,必不可少的一項測試內容,通過對軟件穩定性的測試可以觀察在一個運行周期內、一定的壓力條件下,軟件的出錯機率、性能劣化趨勢等。進而大大減少軟件上線后的崩潰卡死等現象,為軟件的逐步優化提供方向及驗證。
無論是服務器端還是客戶端,對穩定性的測試無非是就是測試系統的長期穩定運行能力。在系統運行過程中,對系統施壓,觀察系統的各種性能指標,以及服務器的指標。不同于服務器端的穩定性測試的是,客戶端軟件是運行在單機環境下,所以不存在并發用戶數的概念,取而代之的是一些多進程長時間的操作,以及各種復雜的并發場景的組合。一款客戶端軟件,它的穩定性測試需求基本包括:
1、長時間運行及各種操作下,軟件的穩定性以及各種性能指標的劣化趨勢。
2、多進程或多線程運行時的穩定性。
3、不同操作系統,在不同宿主軟件下運行的穩定性。
穩定性測試實施
整個穩定性測試的包括三大部分:
1、場景的設計及實現
2、穩定性測試的執行
3、最后結果的校驗
場景設計
測試場景一般是指模擬平常的壓力,以及模擬實際中用戶的日常操作,如果包含數據庫,那么數據庫要存有一定的數據。一般來說客戶端產品的穩定性測試包括:
自動化腳本
自動化測試是穩定性測試的基礎,對于使用標準控件的客戶端軟件來說,可以使用市面上較為通用的自動化及性能測試軟件QTP或LoadRunner,這些軟件對標準控件支持較好,可以很方便快速的搭建起自動化測試的框架,為穩定性測試提供基礎。
但由于目前客戶端軟件的界面開發為了更加快速,同時融入業界前沿的皮膚技術,為用戶創建更加高效,專業的界面,大多數都采用了DirectUI的技術,這種方式是直接在父窗口上繪圖。即子窗口不以窗口句柄的形式創建,只是邏輯上的窗口,繪制在父窗口之上。對于這種非標準控件如果使用QTP等自動化測試工具就會顯得力不從心了。
結果
從穩定性的測試目的中可以得出在對穩定性結果的判斷需要從以下幾個方面進行:
1、判斷是否崩潰
a)對于能夠被崩潰上報進程捕獲的的崩潰比較好辦,可以通過判斷是否有崩潰上報進程來進行判斷。
b)在測試機上安裝任意的debugger工具(例如windbg)就可以檢測各種類型的崩潰情況(只要有崩潰就會觸發debugger的調用,檢測是否出現debugger進程就ok)
c)對于那種運行在宿主程序中的插件,單獨插件的崩潰有時不會導致宿主程序的整個崩潰,所以對插件崩潰的檢測需要記錄運行正常時的pid或tid,發現其消失就判斷為崩潰,因為插件運行在宿主程序中不是一個進程就是一個線程。
2、判斷是否假死
a)對于單進程程序,只要主窗口發消息即可,找對主窗口是關鍵,通過枚舉某個進程的全部窗口句柄,找parent為null,visible 為true,不是托盤程序的那個窗口句柄。
b)強制主窗口重繪(這個重繪方式各產品可能不一樣,有的發消息就可以,有的需要移動位置),然后截圖,白色的就是假死(判斷白色的已有現成的代碼)
3、判斷是否存在性能劣化的趨勢
a)這點也屬于性能測試中資源占用情況的測試,可以再穩定性測試的同時使用性能檢測工具進行檢測。
待改進點
1、自動化判斷,定位異常信息。目前一些偶現的卡死和崩潰無法捕獲到堆棧信息,對定位意義的不大,需要在崩潰或卡死時保留住現場,不能連續的執行后續的case。
2、操作步驟及數據選取的隨機性。可以考慮引入Fuzzy以及解析用戶日志的方式增加操作步驟及測試數據選取的隨機性。
3、測試case在各個執行環境中循環切換的自動化。目前這種循環還是靠手工保證,后續可以考慮從在每臺測試機器上動態調用測試腳本,代替手工的切換及運行。
4、測試腳本的穩定性:穩定性的測試不僅是對被測程序穩定性的驗證,同時也考驗我們自動化測試腳本運行的是否穩定,而且在長時間的運行過程中可能會出現各種阻礙腳本運行的但卻是正常的情況,所以需要增加各種判斷和輪詢的機制,另外為了保證場景的多樣性都需要我們的腳本更加通用和周密,一不小心,被測程序還沒掛呢,我們自己先停了……對于腳本的穩定性一直在測試的過程中不斷完善,積累經驗。
性能測試的主要手段是通過產生模擬真實業務的壓力對被測系統進行加壓,研究被測系統在不同壓力情況下的表現,找出其潛在的瓶頸。
目前,典型的企業IT系統的架構為:系統是由客戶端,網絡,防火墻,負載均衡器,Web服務器,應用服務器(中間件),數據服務器等等環節組成。根據木桶原理,即木桶所能裝的水取決于最短的那塊木板,整個系統的性能要得到提高,每個環節的性能都需要優化。因此,我們需要找到最短的那塊木板(系統瓶頸)來,先對其進行優化。
一個良好的性能測試工具必需能做到以下幾點:
1、提供產生壓力的手段;
2、能夠對后臺系統進行監控;
3、對壓力數據能夠進行分析,快速的找出被測系統的瓶頸。
產生壓力的手段,主要是通過編寫壓力腳本,這些腳本以多個進程或線程的形式在客戶端進行運行,來模擬多用戶對被測系統的并發訪問,以此來達到產生壓力的目的。壓力腳本執行的功能和被測系統客戶端軟件執行的功能應該一樣,從而產生真正的業務壓力。編寫壓力腳本的工作實際上就是重新編寫客戶端軟件。最有效的方式是通過性能測試工具錄制客戶端軟件和服務器之間的通訊包,自動產生腳本,然后在自動生成的腳本的基礎上進行少量修改,如:關聯動態內容,指定批量測試數據等,通常,壓力腳本的準備往往占據整個性能測試項目的50%的時間和工作量。
對后臺數據的監控。監控應該不在被測系統上安裝任何軟件,即達到“無代理”監控。原因有兩個:假若安裝了“代理”軟件,它會對被測系統的分析結果產生影響,造成測試結果的不準確性。二,還會對用戶系統的穩定性造成潛在的影響,引起客戶的反感。“無代理”方式,即不在被測系統上安裝任何軟件,僅僅通過改變被測系統的配置,就可以對被測系統進行監控。
壓力測試完畢后,我們會得到詳盡的性能數據,包括最終用戶的響應時間,后臺系統各個部件的運行數據。由于數據非常龐大,數據分析工具是必要的。它幫助性能測試人員去閱讀,解讀好分析數據,輔助測試人員定位系統的瓶頸。
性能測試工具的組成部分有4個:虛擬用戶腳本產生器Vugen(Virtual User Generator),壓力調度和監控系統Conductor,壓力產生器Player,壓力結果分析工具Analysis。
進行性能測試項目的一般步驟:
1、用戶確定需要錄制的交易,通過用戶操作和Vugen的錄制,記錄并生成自動化腳本。
2、修改腳本,確保腳本可以回放成功。
3、Conductor是一個集中控制平臺,它和壓力產生器player互連,制定腳本在player上分配,并控制player向被測系統的加壓方式和行為。
4、Conductor同時負責搜集被測系統的各個環節的性能數據。各個player會記錄最終用戶響應時間和腳本執行的日記。
5、壓力執行結束后,player將數據傳送到Conductor中,Conductor負責數據的匯總。
6、數據分析工具Analysis讀取壓力測試數據,進行分析工作,確定瓶頸和調優秀方法。
7、針對性地進行系統調優,重復壓力測試數據,進行分析工作,確定性能是否得到提高。
好了,這就是今天的收獲了~~~
那么原型有什么用呢?
先了解下new運算符,如下:
var a1 = new A;
var a2 = new A; |
這是通過構造函數來創建對象的方式,那么創建對象為什么要這樣創建而不是直接var a1 = {};呢?這就涉及new的具體步驟了,這里的new操作可以分成三步(以a1的創建為例):
1、新建一個對象并賦值給變量a1:var a1 = {};
2、把這個對象的[[Prototype]]屬性指向函數A的原型對象:a1.[[Prototype]] = A.prototype
3、調用函數A,同時把this指向1中創建的對象a1,對對象進行初始化:A.apply(a1,arguments)
其結構圖示如下:
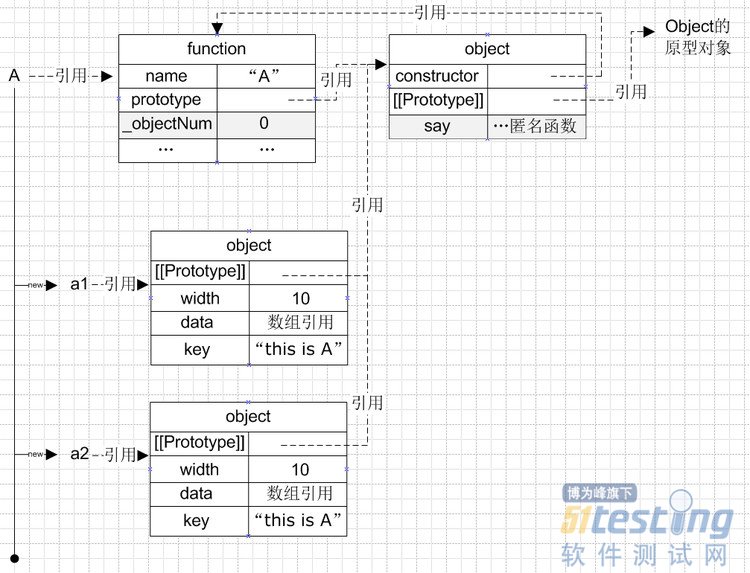
從圖中看到,無論是對象a1還是a2,都有一個屬性保存了對函數A的原型對象的引用,對于這些對象來說,一些公用的方法可以在函數的原型中找到,節省了內存空間。
四、原型鏈
了解了new運算符以及原型的作用之后,一起來看看什么是[[Prototype]]?以及對象如何沿著這個引用來進行屬性的查找?
在js的世界里,每個對象默認都有一個[[Prototype]]屬性,其保存著的地址就構成了對象的原型鏈,它是由js編譯器在對象 被創建 的時候自動添加的,其取值由new運算符的右側參數決定:當我們var object1 = {};的時候,object1的[[Prototype]]就指向Object構造函數的原型對象,因為var object1 = {};實質上等于var object = new Object();(原因可參照上述對new A的分析過程)。
對象在查找某個屬性的時候,會首先遍歷自身的屬性,如果沒有則會繼續查找[[Prototype]]引用的對象,如果再沒有則繼續查找[[Prototype]].[[Prototype]]引用的對象,依次類推,直到[[Prototype]].….[[Prototype]]為undefined(Object的[[Prototype]]就是undefined)
如上圖所示:
| //我們想要獲取a1.fGetName alert(a1.fGetName);//輸出undefined
//1、遍歷a1對象本身
//結果a1對象本身沒有fGetName屬性
//2、找到a1的[[Prototype]],也就是其對應的對象A.prototype,同時進行遍歷
//結果A.prototype也沒有這個屬性
//3、找到A.prototype對象的[[Prototype]],指向其對應的對象Object.prototype
//結果Object.prototype也沒有fGetNam
|
簡單說就是通過對象的[[Prototype]]保存對另一個對象的引用,通過這個引用往上進行屬性的查找,這就是原型鏈。前幾天看了《再談js面向對象編程》,當時就請教哈大神,發現文章有的地方可能會造成誤導(或者說和ECMA有出入),后來自己翻一翻ECMA,總算找到“標準”的理解……
本文適合初學者,特別是對構造函數、原型和原型鏈概念比較模糊的,大牛請路過,好了,讓我們一步步來看看 js 的原型(鏈)到底有多神秘……
一、函數創建過程
在了解原型鏈之前我們先來看看一個函數在創建過程中做了哪些事情,舉一個空函數的例子:
當我們在代碼里面聲明這么一個空函數,js解析的本質是(膚淺理解有待深入):
1、創建一個對象(有constructor屬性及[[Prototype]]屬性),根據ECMA,其中[[Prototype]]屬性不可見、不可枚舉
2、創建一個函數(有name、prototype屬性),再通過prototype屬性 引用 剛才創建的對象
3、創建變量A,同時把函數的 引用 賦值給變量A
如下圖所示:
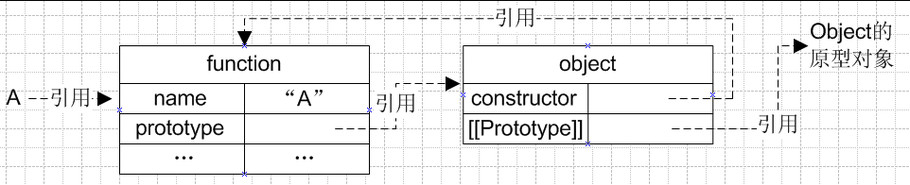
(注意圖中都是“ 引用 ”類型)
每個函數的創建都經歷上述過程。
二、構造函數
那么什么是構造函數呢?
按照ECMA的定義
Constructor is a function that creates and initializes the newly created object.
構造函數是用來新建同時初始化一個新對象的函數。
什么樣的函數可以用來創建同時初始化新對象呢?答案是:任何一個函數,包括空函數。
所以,結論是:任何一個函數都可以是構造函數。
三、原型
根據前面空函數的創建圖示,我們知道每個函數在創建的時候都自動添加了prototype屬性,這就是函數的原型,從圖中可知其實質就是對一個對象的引用(這個對象暫且取名原型對象)。
我們可以對函數的原型對象進行操作,和普通的對象無異!一起來證實一下。
圍繞剛才創建的空函數,這次給空函數增加一些代碼:
functionA() {
this.width = 10;
this.data = [1,2,3];
this.key ="this is A";
}
A._objectNum = 0;//定義A的屬性
A.prototype.say =function(){//給A的原型對象添加屬性
alert("hello world")
}
|
第7~9行代碼就是給函數的原型對象增加一個say屬性并引用一個匿名函數,根據“函數創建”過程,圖解如下:

(灰色背景就是在空函數基礎上增加的屬性)
簡單說原型就是函數的一個屬性,在函數的創建過程中由js編譯器自動添加。
五、繼承
有了原型鏈的概念,就可以進行繼承。
這個時候產生了B的原型B.prototype
原型本身就是一個Object對象,我們可以看看里面放著哪些數據
B.prototype 實際上就是 {constructor : B , [[Prototype]] : Object.prototype}
因為prototype本身是一個Object對象的實例,所以其原型鏈指向的是Object的原型
B.prototype = A.prototype;//相當于把B的prototype指向了A的prototype;這樣只是繼承了A的prototype方法,A中的自定義方法則不繼承
B.prototype.thisisb = "this is constructor B";//這樣也會改變a的prototype |
但是我們只想把B的原型鏈指向A,如何實現?
第一種是通過改變原型鏈引用地址
| B.prototype.__proto__ = A.prototype; |
ECMA中并沒有__proto__這個方法,這個是ff、chrome等js解釋器添加的,等同于EMCA的[[Prototype]],這不是標準方法,那么如何運用標準方法呢?
我們知道new操作的時候,實際上只是把實例對象的原型鏈指向了構造函數的prototype地址塊,那么我們可以這樣操作
這樣產生的結果是:
產生一個A的實例,同時賦值給B的原型,也即B.prototype 相當于對象 {width :10 , data : [1,2,3] , key : "this is A" , [[Prototype]] : A.prototype}
這樣就把A的原型通過B.prototype.[[Prototype]]這個對象屬性保存起來,構成了原型的鏈接
但是注意,這樣B產生的對象的構造函數發生了改變,因為在B中沒有constructor屬性,只能從原型鏈找到A.prototype,讀出constructor:A
var b = new B;
console.log(b.constructor);//output A |
所以我們還要人為設回B本身
B.prototype.constructor = B;
//現在B的原型就變成了{width :10 , data : [1,2,3] , key : "this is A" , [[Prototype]] : A.prototype , constructor : B}
console.log(b.constructor);//output B
//同時B直接通過原型繼承了A的自定義屬性width和name
console.log(b.data);//output [1,2,3]
//這樣的壞處就是
b.data.push(4);//直接改變了prototype的data數組(引用)
var c = new B;
alert(c.data);//output [1,2,3,4]
//其實我們想要的只是原型鏈,A的自定義屬性我們想在B中進行定義(而不是在prototype)
//該如何進行繼承?
//既然我們不想要A中自定義的屬性,那么可以想辦法把其過濾掉
//可以新建一個空函數
function F(){}
//把空函數的原型指向構造函數A的原型
F.prototype = A.prototype;
//這個時候再通過new操作把B.prototype的原型鏈指向F的原型
B.prototype = new F;
//這個時候B的原型變成了{[[Prototype]] : F.prototype}
//這里F.prototype其實只是一個地址的引用
//但是由B創建的實例其constructor指向了A,所以這里要顯示設置一下B.prototype的constructor屬性
B.prototype.constructor = B;
//這個時候B的原型變成了{constructor : B , [[Prototype]] : F.prototype}
|
圖示如下,其中紅色部分代表原型鏈:
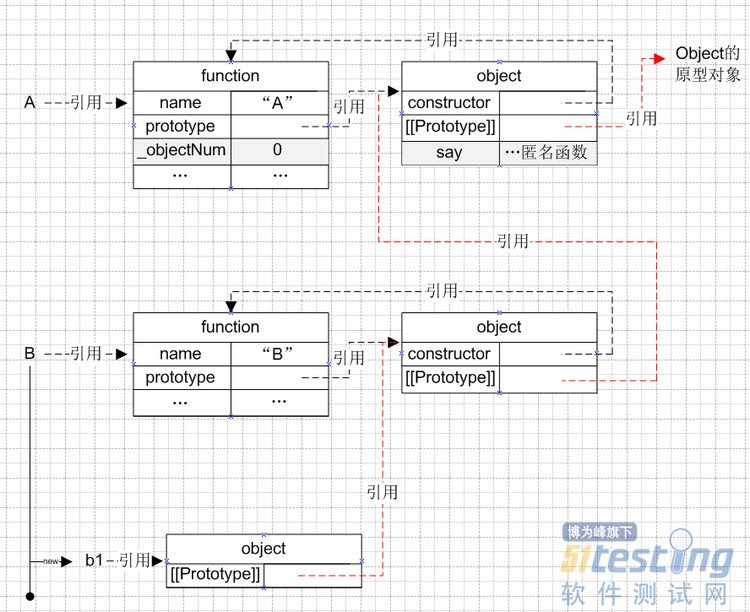
作為初學者淺陋的理解,本文目的在于更具象地去理解js的面向對象,疏漏之處請指正。
前段時間考試系統要新添加一個功能,要把學生表的信息批量導入,也就是需要從excel中導入到數據庫表,小女子不才,找了好長時間才解決。
一、如果表是沒有建立的,我們需要在數據庫表中重新建立一個表盛放excel數據的時候:
在sql server中的導入語句:
SELECT * intocity2 FROM OpenDataSource( 'Micros 前段時間考試系統要新添加一個功能,要把學生表的信息批量導入,也就是需要從excel中導入到數據庫表,小女子不才,找了好長時間才解決。
一、如果表是沒有建立的,我們需要在數據庫表中重新建立一個表盛放excel數據的時候:
在sql server中的導入語句:
SELECT * intocity2 FROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0', 'DataSource="f:\test.xls";User ID=Admin;Password=;Extendedproperties=Excel 5.0')...[Sheet1$]
這里需要注意的是,如果直接寫這個語句,會出現這樣的錯誤:
SQL Server 阻止了對組件'Ad HocDistributed Queries' 的STATEMENT'OpenRowset/OpenDatasource' 的訪問,因為此組件已作為此服務器安全配置的一部分而被關閉。系統管理員可以通過使用sp_configure 啟用'Ad Hoc Distributed Queries'。有關啟用'Ad HocDistributed Queries' 的詳細信息,請參閱SQL Server 聯機叢書中的"外圍應用配置器"。
所以,我們這里需要啟動服務:
啟動語句為:
execsp_configure 'show advanced options',1
reconfigure
execsp_configure 'Ad Hoc Distributed Queries',1
reconfigure |
當然,用完之后要記得關閉:
關閉語句為:
execsp_configure 'Ad Hoc Distributed Queries',0
reconfigure
execsp_configure 'show advanced options',0
reconfigure |
因為考試系統是基于asp.net實現的,所以,一下是asp.net的實現代碼,需要注意的是,因為語句中存在”,\等特殊符號,所以,我們需要使用轉義字符來使這些特殊符號成為字符串類型,這里是一些常用的轉義字符符號:http://baike.baidu.com/view/73.htm
protectedvoid btntoLaad_Click(object sender, EventArgs e)
{
SqlConnectionmycon = new SqlConnection("server=.;database=qingniao;uid=sa;pwd=123");
string sqlstr = "SELECT * into cityFROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0', 'Data Source=\"f:\\test.xls\";User ID=Admin;Password=;Extended properties=Excel5.0')...[Sheet1$]";
SqlCommand cmd = new SqlCommand(sqlstr, mycon);
mycon.Open();
cmd.ExecuteNonQuery();
mycon.Close();
} |
這樣,數據庫中會建立一個city表,來存儲excel中的數據。
二、將excel表導入到已經存在的數據庫表
這里需要注意的是,excel表中的數據必須要和數據庫表中的數據一致
比如,如果數據庫表的字段為
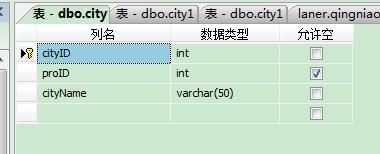
則相應的excel的表字段為:

oft.Jet.OLEDB.4.0', 'DataSource="f:\test.xls";User ID=Admin;Password=;Extendedproperties=Excel 5.0')...[Sheet1$]
這里需要注意的是,如果直接寫這個語句,會出現這樣的錯誤:
SQL Server 阻止了對組件'Ad HocDistributed Queries' 的STATEMENT'OpenRowset/OpenDatasource' 的訪問,因為此組件已作為此服務器安全配置的一部分而被關閉。系統管理員可以通過使用sp_configure 啟用'Ad Hoc Distributed Queries'。有關啟用'Ad HocDistributed Queries' 的詳細信息,請參閱SQL Server 聯機叢書中的"外圍應用配置器"。
所以,我們這里需要啟動服務:
啟動語句為:
execsp_configure 'show advanced options',1
reconfigure
execsp_configure 'Ad Hoc Distributed Queries',1
reconfigure |
當然,用完之后要記得關閉:
關閉語句為:
execsp_configure 'Ad Hoc Distributed Queries',0
reconfigure
execsp_configure 'show advanced options',0
reconfigure |
因為考試系統是基于asp.net實現的,所以,一下是asp.net的實現代碼,需要注意的是,因為語句中存在”,\等特殊符號,所以,我們需要使用轉義字符來使這些特殊符號成為字符串類型,這里是一些常用的轉義字符符號:http://baike.baidu.com/view/73.htm
protectedvoid btntoLaad_Click(object sender, EventArgs e)
{
SqlConnectionmycon = new SqlConnection("server=.;database=qingniao;uid=sa;pwd=123");
string sqlstr = "SELECT * into cityFROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0', 'Data Source=\"f:\\test.xls\";User ID=Admin;Password=;Extended properties=Excel5.0')...[Sheet1$]";
SqlCommand cmd = new SqlCommand(sqlstr, mycon);
mycon.Open();
cmd.ExecuteNonQuery();
mycon.Close();
} |
這樣,數據庫中會建立一個city表,來存儲excel中的數據。
二、將excel表導入到已經存在的數據庫表
這里需要注意的是,excel表中的數據必須要和數據庫表中的數據一致
比如,如果數據庫表的字段為
則相應的excel的表字段為:
protectedvoid btnExist_Click(object sender, EventArgs e)
{
SqlConnection mycon = new SqlConnection("server=.;database=qingniao;uid=sa;pwd=123");
string sqlstr = " insert intocity1 SELECT * FROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0', 'DataSource=\"f:\\test.xls\";User ID=Admin;Password=;Extendedproperties=Excel 5.0')...[Sheet1$]";
SqlCommand cmd = new SqlCommand(sqlstr,mycon);
mycon.Open();
cmd.ExecuteNonQuery();
mycon.Close();
} |
這里同樣需要開啟服務,和第一種的方式一樣。
三、既然已經存在的表,一般都會存在一些設置,比如說主鍵、外鍵或者是其他,如果主鍵或者外鍵沖突,就會出現導入失敗的問題。所以,我們需要對excel表中的數據進行判斷。
則先需要把數據導入到datatable中
protected void btnLeadingIn_Click(objectsender, EventArgs e)
{
DataTable dt=new DataTable();
dt = CreateExcelDataSource("F:\\abc.xls");
SqlConnection sqlCon = con();
sqlCon.Open();
GridView1.DataSource = dt;
GridView1.DataBind();
for (int i = 0; i < dt.Rows.Count;i++)
{
//導入數據庫,把數據寫入數據庫應該就是非常簡單了,這里就不多寫了
}
}
public static DataTableCreateExcelDataSource(string url)
{
DataTable dt = null;
// string connetionStr ="Provider=Microsoft.Ace.OleDb.12.0;" + "Data Source=" + url+ ";" + "Extended Properties='Excel 8.0;HDR=Yes;IMEX=1';";
string connetionStr = "Provider=Microsoft.Jet.OleDb.4.0;"+ "data source=" + url + ";Extended Properties='Excel 8.0;HDR=YES; IMEX=1'";
string strSql = "select * from[Sheet1$]";
OleDbConnection oleConn = new OleDbConnection(connetionStr);
OleDbDataAdapter oleAdapter = new OleDbDataAdapter(strSql,connetionStr);
try
{
dt = new DataTable();
oleAdapter.Fill(dt);
return dt;
}
catch (Exception ex)
{
throw ex;
}
finally
{
oleAdapter.Dispose();
oleConn.Close();
oleConn.Dispose();
}
}
|
當然,我感覺我這里把datatable中的數據一條一條的取出來判斷至少是非常耗時間耗內存的,而且這里最好加上回滾事物,因為在我們導入過程中會經常出現這樣活那樣的問題,采用事物,可以在出錯的時候把數據回滾到沒有導入之前的狀態,防止意外事件發生,這里我就不往上加了。
以上是三種是我們實現了的excel導入,當然,我想方法還不止這些,當然,除了導入,還有的就是從數據庫表導出到excel表中,因為我做的那部分系統沒有涉及到,所以這里就不再提了。
下面說一下我在解決的過程中繞的彎路:
一、我沒有把導入數據庫的種種做法弄清楚,比如是直接創建表呢還是在已經存在的表中導入,所以以至于剛開始總是找不到合適的方法。
二、在后來的查找過程中,我發現我有一個很大的毛病,就是我的關鍵字是在“asp.net中、、、、、”,其實,既然是往數據庫中導入,asp.net只是一個執行一下,所以,因為有了關鍵字的約束,查出來的資料少不說,而且還形成了一種思維定式,除了asp.net之外的其他都一概不看。
三、對查不來的信息不能加以理解,只是能用就用,不能用就換,也就是我因為轉義字符串那一塊弄了很長時間的原因,因為當我們在sql執行查詢語句沒有錯誤的時候,需要把它放在asp.net中執行,因為這些語句需要string字符串來顯示,而這個執行語句中有包含引號,所以需要轉義字符,在解決引號的問題之后,我發現還是不正確,一直折騰了好久才發現是路徑F:\test.xls中“\t“是table的轉義字符,所以這里需要兩個\來轉義\,這就是應該寫成這樣“F:\\test.xls”,而當我寫成這樣的時候,我才想起來,其實最開始查詢的時候所有的代碼都是這樣的,只是那些我沒用上,當時也沒多想,以為路徑就應該是這樣的,最終導致還繼續在這個上面栽跟頭。