
所謂自動化測試框架,可以解釋為自動化測試的整體解決方案,是由一些假設、概念和為自動化測試提供支持的系統及其最佳實踐等構成的集合。對不同的應用領域或不同的測試水平,自動化測試的框架具有不同的構成,但我們必須清楚如何滿足自動化測試的基本要求,了解自動化測試框架的基本構成,從而在此基礎上,根據自己組織的實際情況來進行擴充,從而構造適應性更強、效率更高、功能更強的自動化測試框架。
為了能開展自動化測試的工作,首先需要基礎設施(infrastructure)來支撐測試工具的運行,這包括Web 服務器、郵件服務器、FTP 服務器等。其次是執行自動化測試,要有一套機制來保證測試腳本的執行。具體地說,就是先建立測試環境,創建和執行測試套件,然后獲取執行狀態并給出測試結果報告。根據這個分析,可以描述一個自動化測試框架的雛形,如圖2-11 所示。

圖2-11 軟件自動化測試框架的雛形
圖2-11 中的雛形給出了自動化測試框架的基本構成要素,包括執行器、腳本管理器、報告生成器等,也比較清楚地描述了這些要素之間的關系。但是,這個框架還沒給出其他一些必要的信息,例如:
測試腳本的層次性,如何分離業務邏輯和系統基本操作?
如何實現自動化測試工具的接口?
如何實現被測試系統的對象映射?
如何事先安排測試任務?
如何管理有效測試資源?
如果要在測試腳本上分離業務邏輯和系統基本操作,必須將各種基本操作封裝為特定的關鍵字,每個關鍵字對應一個函數,而業務邏輯可以由關鍵字和參數來描述,即可以通過圖2-12 來描述這種腳本結構。

圖2-12 關鍵字驅動腳本框架示意圖
事先安排測試任務,也是非常重要的。例如,測試人員在下班前將測試任務安排好,測試實際執行可以在晚上9 點鐘以后或得到新的軟件包后自動開始。這樣,測試人員在第二天上班前就可以得到測試報告。安排完任務,還需要開發具有相應觸發機制的引擎(Engine/ Cron Job)來執行測試任務。它負責完成自動部署軟件包、向各臺遠程測試機器分發腳本并啟動測試工具等工作。對于這部分,可以用圖2-13 來描述,其中底層的基礎設施可以由STAX 實現。

圖2-13 自動化測試任務的安排和執行
介紹
最近忙著趕項目,無暇去寫博客。今天我想知道大家是怎么估算項目時間進度的?
我把我這次項目經歷,嘮叨嘮叨。
情況
要做新的項目,產品經理A來找我,問我,這個項目你需要多長時間完成?
前提條件:我沒看過需求,我只是泛泛的看了下demo,只是知道,頁面上有哪些內容,有多少種情況?我沒有辦法回答她,因為我自己也不知道到底用多長時間。因為我實在沒有辦法估算時間。然后產品經理A告訴我,你差不多2周就能完成。那我說,你給我3周吧?我還得做代碼調試呢!(其實我挺心虛的,我知道這個頁面的功能相當的復雜,但是產品經理A告訴我,數據,接口都是準備好的)。
然后又過了兩天,產品經理B找了我,問我,這個項目你估計多長時間能做完?我說3周。B跟我說,我們這個項目比較緊,老大那里著急要呢?時間拖的太長了(這不是因為你們一直拿不下方案,拖了快半年了,怎么到我這里就剩這么點時間了)。我跟他解釋:差不多代碼2周就能形成,還要一周進行相關調試呢?然后B就回去了。
又過了兩天,項目下來了,時間是維期2周,我的開發時間就2周,怎么會這樣?A跟我說,不是你跟B說,2周嗎?——我冤死了,算了,反正就是做事嗎?自己趕緊點應該能完成。


意外不斷
我周一需要開始開發,A還沒有給我需求。A說,周日他過來加班,然后再給我需求。周一回來了,需求只是一部分,A說,這個估計你也要開發一段時間了。等你開發完了,我后面的需求也就上來了。
就這樣開發了一周。設計人員那里的demo也在同步進行中。
后來,開發一周左右,發現原來使用的模塊,要用新的接口A,但是接口A還不能滿足我現有的需求,必須需要程序員A重新包裝給我,這樣再等了一下午,第二天,問題不斷,不停的跟程序員A進行調試,終于完成此模塊的功能。
臨近項目結束,模塊B又出現問題,產品人員許諾的接口,找了相關技術人員,并沒有準備好。原有的接口B也要拋棄掉,跟產品A商量后,決定先放棄此模塊,項目結束后再繼續開發。
臨近項目上線的前兩天,測試人員才開始真真正正的測試,給我提了一堆的bug。然后第二天,我瘋狂的修改bug。
在項目開發階段,小問題不斷,這里不要這個模塊了,這個模塊需要列表了,這個模塊要移動按鈕要修正了……。
終于項目于昨日匆匆結束。
今天一天,問題不斷,不停修改bug。

感受
這兩周,我快累得吐血了,不停的編碼,幾乎就沒有休息過。
1、產品人員追的太緊了,他們自己不緊不慢的定方案快小半年了,給我的開發時間就2周。——我快瘋了。
2、測試人員,給了他一周的測試時間,結果臨近上線才真正的測試,然后快要上線了,給我提了一堆的bug。——我快神經質了。
3、接口提供的開發人員。不停的把事情推到我這里,我自己這邊的事情越來越多。估計是我嘴笨,老是說不過他們,我也不知道,他們哪里來的那么多道理。——我快氣死了。

痛定思痛
1、在項目開始階段,我并不十分清楚每個模塊詳細情況(如,接口數據的存儲情況,復雜度,以及怎么展現)。因為本身這時根本就沒有需求文檔。
2、項目開始階段,本身就不應該受產品人員的影響,他們說多長時間,你就受他們的影響,而擬定自己的時間計劃,應該讓更熟悉這塊的人來給你擬定時間度(如找我們頭,項目經理)。
3、在開發階段,不應該讓產品不停的修改方案,我本身知道這個道理,但是沒有辦法,因為本身就沒有詳細的需求文檔,想到哪里就做哪里。
4、應該在臨近上線的時候不能讓測試人員提bug,或者此bug(不是緊急的bug)只能上線之后,后期再進行跟蹤修復。——這個我明天找項目經理,反應一下這個情況。否則,明天上線,你還在不停的修改代碼。
5、接口提供的開發人員,必須要求他們給我們詳細的文檔,以郵件的形式發給我們,否則,你根本就無從入手。——此次開發,我不停的去他們那里詢問接口調用細節。
6、同事建議我,把需求打成碎片,一塊一塊的評估。——天,哪有什么需求,他們自己擬定方案的時候,我就參與過一次會議,其他會議我都沒有參與過,無暇知道他們是怎么想的。——估計是有預謀不讓我參加,怕我知道,時間拖得比較長吧?(我猜的)。

總結
以上是我這次項目的經歷,在這過程中,我知道自己有很多的問題,但是我最大的疑慮,也是我5年開發中一直遇到的問題,就是開發周期問題。
我同事跟我說,開發周期,你要預估下時間,然后你再這個時間基礎上再加一周時間。但是我這預估的時間,我自己都沒辦法預估出來。很多時候我都是被自己的項目搞的暈頭暈腦的。——很多道理我懂,但是真正到實際中,實在摸不開面子,既然拿了人家的工資,就要努力給人家做事情。自己吃點虧,累點沒什么。
也許大家會責怪我,這一切都是你自己的錯誤,自己釀下的苦果,自己就要承受。——呵呵,是啊,我寫此文,也是發發牢騷而已,一吐心中的煩悶。
如果大家在時間估算上有什么技巧的話,不妨相授彼人,不慎感激。
3、fillInStackTrace()
我們在前面也提到了這個方法。要說清楚這個方法,首先要講一下捕獲異常之后重新拋出的問題。在catch代碼塊中捕獲到異常,打印棧軌跡,又重新throw出去。在上一級的方法調用中,再捕獲這個異常并且打印出棧軌跡信息。這兩個棧軌跡信息會一樣嗎?我們看一下代碼:
public class TestPrintStackTrace {
public static void f() throws Exception{
throw new Exception("出問題啦!");
}
public static void g() throws Exception{
try {
f();
}catch(Exception e) {
e.printStackTrace();
throw e;
}
}
public static void main(String[] args) {
try {
g();
}catch(Exception e) {
e.printStackTrace();
}
}
} |
在main方法中捕獲的異常,是在g()方法中拋出的,按理說這兩個打印棧軌跡的信息應該不同,第二次打印的信息應該沒有關于f的信息。但是事實上,兩次打印棧軌跡信息是一樣的。輸出結果如下:
java.lang.Exception: 出問題啦!
at TestPrintStackTrace.f(TestPrintStackTrace.java:3)
at TestPrintStackTrace.g(TestPrintStackTrace.java:7)
at TestPrintStackTrace.main(TestPrintStackTrace.java:16)
java.lang.Exception: 出問題啦!
at TestPrintStackTrace.f(TestPrintStackTrace.java:3)
at TestPrintStackTrace.g(TestPrintStackTrace.java:7)
at TestPrintStackTrace.main(TestPrintStackTrace.java:16) |
也就是說,捕獲到異常又立即拋出,在上級方法調用中再次捕獲這個異常,打印的棧軌跡信息是一樣的。原因在于沒有將當前線程當前狀態下的軌跡棧的狀態保存進Throwabe中。現在我們引入fillInStackTrace()方法。這個方法剛好做的就是這樣的保存工作。我們看一下這個方法的原型:
| public Throwable fillInStackTrace() |
這個方法是有返回值的。返回的是保存了當前棧軌跡信息的Throwable對象。我們看看使用fillInStackTrace()方法處理后,打印的棧軌跡信息有什么不同,代碼如下:
public class TestPrintStackTrace {
public static void f() throws Exception{
throw new Exception("出問題啦!");
}
public static void g() throws Exception{
try {
f();
}catch(Exception e) {
e.printStackTrace();
//不要忘了強制類型轉換
throw (Exception)e.fillInStackTrace();
}
}
public static void main(String[] args) {
try {
g();
}catch(Exception e) {
e.printStackTrace();
}
}
} |
輸出如下:
java.lang.Exception: 出問題啦!
at TestPrintStackTrace.f(TestPrintStackTrace.java:3)
at TestPrintStackTrace.g(TestPrintStackTrace.java:7)
at TestPrintStackTrace.main(TestPrintStackTrace.java:17)
java.lang.Exception: 出問題啦!
at TestPrintStackTrace.g(TestPrintStackTrace.java:11)
at TestPrintStackTrace.main(TestPrintStackTrace.java:17) |
我們看到,在main方法中打印棧軌跡已經沒有了f相關的信息了。
以上就是關于Java棧軌跡的一些我之前沒有掌握的內容,記下來備忘。 捕獲到異常時,往往需要進行一些處理。比較簡單直接的方式就是打印異常棧軌跡Stack Trace。說起棧軌跡,可能很多人和我一樣,第一反應就是printStackTrace()方法。其實除了這個方法,還有一些別的內容也是和棧軌跡有關的。
1、printStackTrace()
首先需要明確,這個方法并不是來自于Exception類。Exception類本身除了定義了幾個構造器之外,所有的方法都是從其父類繼承過來的。而和異常相關的方法都是從java.lang.Throwable類繼承過來的。而printStackTrace()就是其中一個。
這個方法會將Throwable對象的棧軌跡信息打印到標準錯誤輸出流上。輸出的大體樣子如下:
java.lang.NullPointerException
at MyClass.mash(MyClass.java:9)
at MyClass.crunch(MyClass.java:6)
at MyClass.main(MyClass.java:3) |
輸出的第一行是toString()方法的輸出,后面幾行的內容都是之前通過fillInStackTrace()方法保存的內容。關于這個方法,我們后面會講。
下面看一個例子:
public class TestPrintStackTrace {
public static void f() throws Exception{
throw new Exception("出問題啦!");
}
public static void g() throws Exception{
f();
}
public static void main(String[] args) {
try {
g();
}catch(Exception e) {
e.printStackTrace();
}
}
} |
這個例子的輸出如下:
java.lang.Exception: 出問題啦!
at TestPrintStackTrace.f(TestPrintStackTrace.java:3)
at TestPrintStackTrace.g(TestPrintStackTrace.java:6)
at TestPrintStackTrace.main(TestPrintStackTrace.java:10) |
在這個例子中,在方法f()中拋出異常,方法g()中調用方法f(),在main方法中捕獲異常,并且打印棧軌跡信息。因此,輸出依次展示了f—>g—>main的過程。
2、getStackTrace()方法
這個方法提供了對printStackTrace()方法所打印信息的編程訪問。它會返回一個棧軌跡元素的數組。以上面的輸出為例,輸出的第2-4行每一行的內容對應一個棧軌跡元素。將這些棧軌跡元素保存在一個數組中。每個元素對應棧的一個棧幀。數組的第一個元素保存的是棧頂元素,也就是上面的f。最后一個元素保存的棧底元素。
下面是一個使用getStackTrace()訪問這些軌跡棧元素并打印輸出的例子:
public class TestPrintStackTrace {
public static void f() throws Exception{
throw new Exception("出問題啦!");
}
public static void g() throws Exception{
f();
}
public static void main(String[] args) {
try {
g();
}catch(Exception e) {
e.printStackTrace();
System.out.println("------------------------------");
for(StackTraceElement elem : e.getStackTrace()) {
System.out.println(elem);
}
}
}
} |
這樣的輸出和printStackTrace()的輸出基本上是一樣的,如下:
java.lang.Exception: 出問題啦!
at TestPrintStackTrace.f(TestPrintStackTrace.java:3)
at TestPrintStackTrace.g(TestPrintStackTrace.java:6)
at TestPrintStackTrace.main(TestPrintStackTrace.java:10)
TestPrintStackTrace.f(TestPrintStackTrace.java:3)
TestPrintStackTrace.g(TestPrintStackTrace.java:6)
TestPrintStackTrace.main(TestPrintStackTrace.java:10) |
數據庫同步過程,最嚴格的指標,第一是效率,即每秒同步SQL條數;其次是一致性,即主庫產生的數據,備庫同步后是否一致;第三就是數據庫同步的完整性如何保證,即當同步各個環節出現問題時,如何考慮出錯處理,下面我們將分別進行討論并進行合理性分析。
第一、效率
數據庫同步過程主要分為三個階段,即抽取、分析、裝載。
抽取過程主要是實時讀取數據庫日志,這部分可以作到毫秒級別間隔,所以不存在效率問題,基本上可以作到實時抽取;
分析過程主要是分析SQL語句并把源日志轉化為備庫的可裝載日志,這部分的主要時間是寫文件時間,由于普通硬盤寫入時間是50M/秒左右,故對于大交易量情況,如果每秒主庫陣列產生日志量上300M/秒左右,那相比之下分析組件還是會有秒級延遲的,因為我們同步軟件一般都不安裝在主庫,無法使用高速陣列的寫入速度,所以秒級別延遲還是會產生的,但是只要不是持續高峰日志量的產生速度,再經過一段時間后數據會自行同步,如果要追求實時抽取的同時又要實時分析,那建議只能給同步服務器配置一個陣列了;
裝載過程主要是根據分析組件的結果進行備庫SQL語句的裝載,所以并發裝載是提高效率的唯一方法,不過對于備庫服務器配置不是很高的情況,建議數據庫長連接的數目需要能夠合理配置,因為備庫有時會作為查詢統計的負載分擔,所以如果備庫的資源有限,對于查詢統計分擔的效果會大打折扣。
第二、一致性
如何能夠保證備庫的數據和主庫一致,這個問題如果在業務層面提出來,大家肯定沒什么好的辦法,一個共同的回答就是“查看備庫”,用應用去連,之后檢查剛剛同步的數據是正確的就可以了,不過這樣的抽查很有可能檢查不出來特殊錯誤的數據,我想從幾個機制方面來分析這個問題。
1、分析日志(Analysis Log)
就是即將裝載到備庫的SQL語句,這部分是裝載正確的根本,這部分數據如果正確了,則保證了數據源的正確。
2、裝載日志(Upload Log)
就是裝載數據時是否出現問題,有時備庫和主庫表定義有不一致,那么在這個日志就會記錄出錯,根據此日志就能夠檢查出問題出現在什么地方。
通過以上兩個日志基本能保證同步過程中的錯誤捕捉,同時再加上同步數據檢查程序(此數據需要主、備庫檢查過程中不能更改數據)和應用程序。
連接備庫抽查是兩個輔助檢查方式,同時備庫作為查詢統計分析進行實時提供服務也會把抽查變成常態,從而保證數據的一致性。
第三、完整性
數據庫的完整性,主要從容錯機制來考慮,例如出現下面錯誤情況時需要同步程序能夠自動恢復:
1、源庫斷電或重起
2、源庫SHUTDOWN
3、源庫網絡斷
4、備庫斷電或重起
5、備庫SHUTDOWN
6、備庫網絡斷
7、數據庫裝載出錯
針對上面主要幾種情況,同步軟件必須進行一一考慮斷點的記錄方式和位置,保證任何情況下同步程序能夠續抽、續傳,甚至對錯誤處理也可以通過人為參與后繼續同步,同時還有兩方面功能必須考慮:
1、不停機初始化
2、日志已經歸檔
3、自身程序停止的重起
4、同步服務器斷電之后斷點啟動
數據庫同步軟件只有充分考慮了以上三個方面的指標,才能為行業客戶提供優秀的、實時的、數據完整一致的同步產品,滿足相關基于數據庫同步的業務需求。
當我們插入一條數據的時候,我們很多時候都想立刻獲取當前插入的主鍵值返回以做它用。我們通常的做法有如下幾種:
1、先 select max(id) +1 ,然后將+1后的值作為主鍵插入數據庫;
2、使用特定數據庫的 auto_increment 特性,在插入數據完成后,使用 select max(id) 獲取主鍵值;
3、對于Oracle,使用 sequence 獲取值。
對于以上3種方法都無法絕對保證在高并發情況下的操作的原子性。
現記錄以下幾種獲取數據庫主鍵值方法:
1、數據庫原生支持的sql方法:
SQLServer:
| INSERT INTO table_name (.....) VALUES(......) SELECT @@IDENTITY AS aliasname; |
上面的語句相當于查詢語句,從結果集中使用 getXXX(aliasname) 方法獲取主鍵值。
Oracle:
| INSERT INTO table_name(......) VALUES(......) RETURNING[primaryKey INTO]:aliasname; |
也是相當于查詢語句,從結果集中使用 getXXX(aliasname) 方法獲取主鍵值。
2、java.sql.Statement 返回鍵獲取:
a: 使用JDBC 3.0提供的 getGeneratedKeys(推薦使用)
Statement stmt = ... ; stmt.executeUpdate("INSERT INTO table_name(......) VALUES(......)", Statement.RETURN_GENERATED_KEYS); ResultSet rs = stmt.getGeneratedKeys(); int keyValue = -1; if (rs.next()) { keyValue = rs.getInt(1); } |
b:使用特定數據庫特有的SQL
Statement stmt = ... ; stmt.executeUpdate("INSERT INTO table_name(......) VALUES(......)", Statement.RETURN_GENERATED_KEYS); ResultSet rs = stmt.executeQuery("SELECT LAST_INSERT_ID()"); int keyValue = -1; if (rs.next()) { keyValue = rs.getInt(1); } |
那么現在我就一個例子來看一下原生的sql怎么能得到執行的返回結果
項目背景:數據庫是oracle數據庫,id生成規則是通過觸發器插入數據的時候自動增長,所以在插入數據的時候在sql中就不需要指明id值。但是另外一張表需要引用這個id值作為外鍵,那么就必須獲得被引用的這個表的ID,為了避免并發問題,我們只能在插入前面那張表的時候就獲得他的ID,所以我使用了下面的方法來處理。
Connection con = DBConnector.getconecttion(); // 取得一個數據庫連接
CallableStatement cst = null;
con.setAutoCommit(false);
String insertSql = "begin insert into TABLE (field_0,field_1) values (value_0,value_1) returning id into ?;end; ";
try {
cst = con.prepareCall(insertSql); //執行存儲過程
cst.registerOutParameter(1, Types.INTEGER); //為存儲過程設定返回值
int count = cst.executeUpdate(); //得到預編譯語句更新記錄或刪除操作的結果
int id = cst.getInt(1); //得到返回值
System.out.println("成功執行了:" + count + "條數據,其ID值:" + id);
} catch (SQLException e1) {
con.rollback();
con.setAutoCommit(true);
}finally{
con.commit();
con.close();
} |
與所有的關系型
數據庫一樣,
MySQL仿佛是一頭讓人難以琢磨的怪獸。它會隨時停擺,讓應用限于停滯,或者讓你的業務處于危險之中。
事實上,許多最常見的錯誤都隱藏在MySQL性能問題的背后。為了確保你的MySQL服務器能夠一直處于全速運行的狀態,提供持續穩定的性能,杜絕這些錯誤是非常重要的。然而,這些錯誤又往往隱藏在工作負載和配置問題之中。
幸運的是,許多MySQL性能問題都有著相似的解決方案,這使得排除故障與調整MySQL成為了一項易于管理的任務。以下就是10個讓MySQL發揮最佳性能的技巧。
1、分析工作負載
通過分析工作負載,你能夠發現進一步調整中最昂貴的查詢。在這種情況下,時間是最重要的東西。因為當你向服務器發出查詢指令時,除了如何快速完成查詢 外,你很少關注其他的東西。分析工作負載的最佳方式是,使用諸如MySQL Enterprise Monitor的查詢分析器,或者Percona Toolkit的pt-query-digest等工具。
這些工具能夠捕捉服務器所執行的查詢,以降序的方式根據響應時間列出任務列 表。它們會將最昂貴的和最耗時的任務置頂,這樣你就能知道自己需要重點關注哪些地方。工作負載分析工具將相似的查詢匯聚在一行中,允許管理者查看速度慢的 查詢,以及查看速度快但已多次執行的查詢。
2、理解四個基本資源
功能性方面,一個數據庫服務器需要四個基本資源:CPU、內存、硬盤和網絡。如果這四個資源中任何一個性能弱、不穩定或超負載工作,那么就可能導致整個數據庫服務器的性能低下。理解基本資源在兩個特定的領域中至關重要:選擇硬件和排除故障。
在為MySQL選擇硬件時,應該確保全部選用性能優異的組件。這些組件相互匹配,彼此間能夠實現合理平衡也很重要。通常情況下,企業會為服務器選擇速度 快的CPU和硬盤,但是內存卻嚴重不足。在一些案例中,大幅提升性能的最廉價方式是增加內存,尤其是對于那些受制于磁盤讀取速度的工作負載。這似乎看起來 有點違背常理,但是在許多案例中,由于沒有充足的內存以保存服務器正在使用的數據,因此導致了硬盤被過度使用。
關于獲取這種平衡的另一 個例子是CPU。在許多案例中,如果CPU速度快,那么MySQL的性能就非常出色,因為每一個查詢都是單線程運行,而無法在CPU間并行運行。在進行故 障排除時,應該檢查這四個資源的性能和使用情況,關注它們是否性能低下或是超負荷工作。這方面的知識能夠幫助你快速地解決問題。
3、不要將MySQL作為隊列使用
隊列以及與隊列相似的訪問方案會在你不知情的情況下悄悄地進入應用之中。例如,你設置了一個項目狀態,以便在執行前,特定的Worker Process(工作進程)能夠對其進行標記,那么你就等于在無意間創建了一個隊列。例如,將電子郵件標記為未發送,然后發送它們,最后再將它們標記為已 發送。
隊列會導致出現一些問題,這里面有兩大主要原因:它們對工作負載進行了序列化,阻礙任務被并行處理。這導致正在處理中的任務和以前在工作中處理過的歷史數據會被根據序列排列在一個表單中。這樣一來既增加了應用的延時,也增加了MySQL的負載。
4、以最廉價的方式過濾結果
優化MySQL的最佳方式是首先要做廉價和不精確的工作,然后再小規模地做困難的精確工作,最后再生成數據集。
例如,假設你計算某一個地理坐標點給定半徑內的面積。在許多程序員的工具箱里第一個工具就是球面半正矢公式,以計算出球面的長度。這一方法的問題是,該 方程式需要許多三角函數運算,需要擁有很強運算能力的CPU。球面半正矢計算不僅運行速度慢,而且會導致機器CPU的使用率飆升。在使用球面半正矢公式 前,你可以先分解計算。有些分解計算并不需要使用三角函數。
5、弄清兩個擴展性死亡陷阱
擴展性可能并不像你認為的那樣模糊。實際上,擴展性有著精確的數學定義,它們以方程式的形式被表示出來。這些方程式既指出了系統無法擴展的原因,同時也 指出了它們應該進行擴展的原因。通用擴展定律(Universal Scalability Law)揭示和量化了系統的擴展性特征。其通過兩個基礎性成本解釋了擴展問題:即序列化與串擾(Crosstalk)。
并行處理要求必 須中止序列化,這就限制了它們的擴展性。同樣的,如果并行處理需要始終進行彼此對話以協調工作,那么它就相互進行了限制。為了避免序列化與串擾,應用進行 了更好的擴展。這些在MySQL內部被翻譯成了什么?結果不盡相同。不過,一些案例應該避免鎖定在特定的行之中。就像第3個技巧中所提到的,隊列擴展性差 的原因就是如此。
6、不要過分關注配置
數據庫管理員會花費許多時間調整配置。調整的結果通常不會有很大的改善,相反有時候會帶來損害。我發現許多經過“優化的”服務器,在進行強度稍微高一點的運算時常常出現崩潰、內存不足和性能低下等問題。
雖然MySQL在交付時的默認設置嚴重過時,但是你并不需要對每一項都進行配置。最好是根據需要,進行基本糾正與設置調整。有10個選項調整正 確,即可讓服務器發揮95%的最大性能。在許多案例中,我們并不推薦所謂的調整工具,因為它們只是提供一個大概設置,對特定案例沒有任何意義。有些工具甚 至包含有危險的和錯誤的設備代碼。
7、注意分頁查詢
分頁查詢應用會使服務器性能大降。這些應用會在網頁上顯示搜索結果,然后通過鏈接跳轉至相應網頁上。通常這些應用無法使用索引進行聚合與分類, 而是使用LIMIT和OFFSET語句,這導致服務器工作負載大幅增加,并放棄行。 在用戶界面上常常會發現優化選項。替代在結果中顯示網頁數量,以及分別與每個網頁相連的鏈接。這樣便可以僅顯示至下一頁的鏈接。你還可以阻止查詢者瀏覽與 首頁過遠的網頁。
8、保存統計數據,提高報警閥值
監控與報警必不可少,但是監控系統被怎么處理了呢?當它們發布假的報警信息時,系統管理員會設置電子郵件過濾規則,以停止這些噪音。很快你的監 控系統就徹底沒用了。個人認為,應該以下面的兩種方式進行監控:捕捉指標與報警。盡可能地捕捉與保存指標非常重要,因為在你試圖搞明白系統中需要做哪些調 整時,你會慶幸之前保存了它們。如果某一天出現奇怪問題時,你會很高興自己有能力繪制出服務器工作負載變化的圖形。
9、了解索引的三大規則
索引可能是數據庫中被誤解最多的一項。因為它們的工作方式有許多種,這導致人們常常對索引如何工作,以及服務器如何使用它們感到困惑。要想徹底搞清楚它們需要花上很大一番功夫。在被正確設計時,索引在數據庫中主要用于實現以下三個重要目的:
1)它們讓服務器尋找相鄰行群組,而不是單個行。許多人認為,索引的目的是尋找單個行,但是尋找單個行會導致隨時磁盤操作,速度很慢。尋找行群組就要好許多,與一次尋找一個行相比,這更具吸引力。
2)它們讓服務器避免以期望的讀行順序對檢索結果排序,排序成本十分高昂。以期望的順序讀行速度將更快。
3)它們能夠滿足來自一個索引的所有查詢,從根本上避免了訪問表單的需求。這被稱為覆蓋索引或索引查詢。
如果你能設計出符合這三個規則的索引與查詢,那么你的查詢速度將大幅提升。
10、利用同行的專業知識
不要孤軍奮戰。如果你在苦苦思考某個問題,并著手制訂明智的解決方案,那么這非常不錯。在20次中,有19次問題會被順利解決。但是其中會有一次讓你不知所措,導致耗費大量的資金和時間,準確地說,是因為你正在嘗試的解決方案只是貌似合理。
創建一個MySQL相關資源網的意義遠遠大于工具集與故障排除指南。許多經驗豐富的專業人員就隱藏在論壇、問答網站之中。會議、展覽以及本地用戶集體活動,都會為我們提供獲得新見解的機會和與同行建立聯系的機會,關鍵時刻這將對你很有幫助。

要想回答這個問題,首先要搞明白另外一個問題。那就是自動化是什么?
首先回答自動化是什么?常見的答案:自動化就是寫代碼。如果是寫代碼,那與軟件開發有什么區別。要想回答這個問題前提是代碼是什么。代碼就是人的知識與邏輯思維的一種固化方式。軟件本身就是人們為解決某一問題所需要知識與做事的處理流程的固化。而測試腳本是人們測試邏輯思維的固化。一旦把知識與邏輯思維固化下來后,就相當于建立一種制度。
自動化能提高效率嗎,是不可以換一種方式問,制度能不能不效率?這樣一問,大家自然也就明白了,制度不一定能提高效率。只有一個好的制度才能效率。因為有了制度之后,人們的就會受制于制度,缺乏了靈活度。就像上一篇文章的自動化測試三 個發展階段:依賴工具階段,依賴人的階段,依賴架構階段。過第一階段之后,這種感覺越明顯。嚴重的話,會出現測試綁架開發的情況。例如軟件想進行重構,但 會引起接口的變化,而接口的改變,測試腳本就要跟著改了并且改動一般都不會是一比一關系,而是一比N(這個N有多大,就看測試case設計的合理性而定 了)。如果測試改動量特別大,可能會迫使軟件放棄重構。就違背了做自動化的初衷了。
現在流行的敏捷開發模式,代碼重構會貫穿于整個開發流程,同樣自動測試是保證敏捷順利進行一個不可或缺的基石。沒有自動化,就不可能快速持續集成。
所以,成也自動化測試,敗也自動化測試。是成是敗就要看自動化框架的設計。
你強化過你的文件服務器了嗎?按照以下方法,可以充分保護你的重要文件,阻止未經授權的入侵。
現在把你公司有價值的機密信息存放在一個或者多個windows文件服務器上,是一個非常安全的做法。可能不太明顯的是,你不知道強化的程度和保護數據防止非法入侵的范圍。
如果你不知道從哪入手的話,沒關系只要按照以下通過實踐得出的十個最佳方法去做就行了:
第一招:確保您的服務器在物理層面上是安全的。
如果入侵者可以物理訪問你的服務器,那么你將會有被帶走整個機器或者一個硬盤的風險。除了要確保物理安全之外,你還應該配置你的系統,讓它只從硬盤內部來引導,防止入侵者從可移動的介質來啟動系統。BIOS和引導加載程序,都應該設置一個強大的密碼來進行保護。
第二招:加密你的驅動器。
使用類似于BitLocker系統來加密你的驅動器,這樣即使你的硬盤被盜或者被替換后扔到不安全的地方,仍能確保你的文件是安全的。在你的服務器上使用可信賴平臺模塊(TPM)確保使用BitLocker在管理員和用戶之間是公開透明的。
第三招:盡可能的讓服務器遠離網絡。
由于大多數文件服務器都無法避免的要連接到互聯網,所以使用防火墻限制外部訪問你的局域網。
第四招:確保服務器更新了最新最全的補丁。
即使你的Windows服務器沒有連接互聯網,你仍然要保證軟件的更新,通過在你網絡上的另一個服務器運行Windows服務器更新服務(WSUS)來 完成。如果讓你的文件服務器,不聯網是不實際的話,那么你應該確保Windows更新設置為自動下載并應用補丁 - 除非你已經有了一套下載和手動測試補丁的程序。
還有一個容易遺漏的地方就是IE瀏覽器的增強安全配置,因為很少會用到IE瀏覽器所以IE瀏覽器的安全往往會被忽略。你可以從控制面板查看互聯網增強的安全配置選項,添加Windows部分組件。
第五招:不要忘了防病毒軟件。
即使你有網關的安全保護,也運行了個人的防病毒軟件,但你仍應該運行企業級的防病毒軟件在你的文件服務器上。大多數企業的產品,允許你從本地服務器更新 病毒數據(甚至是從你網絡上其他用戶運行的軟件上),但如果你的文件服務器沒有聯網的話,那么你可能無法充分利用基于網絡提供的額外保護。
第六招:去掉不必要的軟件。
在你服務器上的那些肯定不需要的軟件如Flash,Silverlight,或Java。安裝這些軟件只會給黑客增加攻擊的機會。你可以從服務器中刪除沒用的控制面板。
第七招:停止不必要的服務。
在Windows中,除非你特別需要這些(像遠程管理),否則你應該停止像傳真服務,Messenger、IIS Admin、SMTP、任務調度器、Telnet、遠程桌面服務、萬維網發布服務等。
第八招:控制文件的訪問。
您可以使用NTFS安全限制文件和文件夾訪問特定的組或個人用戶。你可以通過查看一個文件或文件夾的屬性,選擇“安全選項卡”,然后在“高級”里改變權限。
第九招:使用審計功能。
確保你設置了審計,這樣你可以看到是誰曾嘗試讀取、寫入或刪除你的機密文件或文件夾。你可以通過查看一個文件或文件夾的屬性,選擇“安全選項卡”,然后在“高級”設置里選擇“審核”選項卡來完成。
第十招:使用最少的特權執行管理任務。
盡可能的避開使用管理員特權。同樣,確保具有管理員權限的所有帳戶,即使有密碼策略也要強制執行強密碼保護。
1、現狀分析 如今,國內瀏覽器市場競爭激烈,國外優秀的瀏覽器如Microsoft的Internet Explorer(下簡稱:IE)、Mozilla的Firefox、Google的Chrome、基于Apple Mac OS的Safari,以及號稱世界最快瀏覽器的挪威Opera等,占大量的國內市場份額。如IE瀏覽器,由于在國內引進互聯網初期就被大眾熟悉,且很多銀行、游戲類應用均需要其內核的支持,因此仍擁有大批熱衷者;Firefox、Chrome和Opera,由于其獨特的分頁瀏覽和極具個性的定制設置,也吸引了大量用戶;Safari更是由于Apple系列產品的風靡全球被大家熟知和使用。
國產瀏覽器如Sogou、遨游Maxthon、世界之窗TheWorld,百度瀏 覽器、360安全瀏覽器等,雖然近年來發展迅猛,并且更符合國人的使用特點,逐漸被大眾接受,但是市場份額仍然很低,距國內權威的流量統計技術服務提供商 CNZZ最新統計,國產瀏覽器市場份額仍不足40%。因此,大力發展國產瀏覽器,著重提高其標準支持和性能的能力,逐漸掌握市場主動權仍然是國產瀏覽器廠 商需要迫切解決的問題。
2、測試依據
本文基于某核高基重大專項課題驗收要求中的部分內容,對某互聯網公司自行開發的瀏覽器的性能測試方法進行了研究(為避免引起不必要的糾紛,課題名稱及承擔單位名稱在此均未描述,待測試的瀏覽器下文簡稱A瀏覽器),通過測試考察其實際運行性能,并與主流的瀏覽器IE、Firefox和Chrome進行了性能對比。
本次測試是在實驗室模擬環境下展開的。為保證測試執行過程的公平、公正,本次測試的外部條件是一致的,這包括環境和輸入條件一致。每款瀏覽器測試完成后,直接更換部署下一套瀏覽器產品,測試設備、網絡環境、操作系統版本和設置均保持一致。
3、測試內容
本次瀏覽器性能對比測試,需要考察瀏覽器的啟動、資源消耗、門戶網站訪問、大頁面加載速度等,主要與測試設備硬件CPU、內存、操作系統以及瀏覽器自身 的版本和設置有關,與網速、Flash插件等無關。選擇的版本分別是:IE8.0、Firefox9.0.1、Chrome17.0.963.6和A瀏覽 器1.4。
3.1 資源占用
資源爭用常常是導致應用性能降低的重要因素,瀏覽器 對資源的控制將嚴重影響用戶的訪問速度體驗,因此需要考察各瀏覽器安裝完成后,在默認配置下初次冷啟動不加載頁面運行時,消耗測試設備CPU、內存和磁盤 空間大小的情況。由于內存消耗值的是動態變化的,在實際測試中采用3次啟停測試設備,通過測試進行信息提取,再統計3次取值的平均值獲得。由于CPU消耗 情況均小于1%,因此僅列出內存和磁盤測試對比結果。
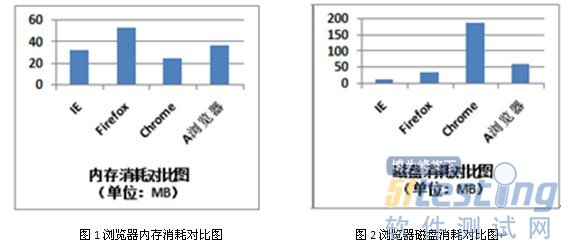
從測試結果可以看出,國產A瀏覽器在內存和磁盤消耗測試中,均排名第3,但是內存的消耗和默認加載的控件有關,磁盤的消耗和程序包的大小有關,因此仍有提升的空間。
3.2 啟動測試
啟動測試項主要考察冷啟動和熱啟動模式下打開瀏覽器訪問保存在本地的帶有文字、圖片和Flash的測試頁面的響應時間。
冷啟動指無緩存情況下開機后第一次打開瀏覽器進行訪問,而熱啟動指測試設備啟動后至少運行過一次瀏覽器訪問操作,再次打開瀏覽器進行訪問。
在測試過程中,為方便統計響應時間,采用了功能測試工具QuickTestPeofesstional來協助完成。通過測試工具錄制打開瀏覽器訪問本地測試文件的操作,然后循環執行十次取平均值獲得操作執行的響應時間。腳本主要內容如下:
……
Services.StartTransaction "click" //定義一個事務點開始
Window("A瀏覽器").WinObject("Aricheditcontrol").Click 85,10 //打開瀏覽器主窗口
For i=1 to 10 //設置10次循環
Window("A瀏覽器").WinObject("WebViewWindowClass").Type “localhost:8001/test.html” //鍵入本地文件訪問地址
wait(5) // 設置5秒等待時間
Window("A瀏覽器").WinObject("WebViewWindowClass").Click 1225,252 //打開網頁中的連接
Window("A瀏覽器").WinObject("WebViewWindowClass").Click 1265,248 //打開網頁中的圖片
Window("A瀏覽器”).WinObject(“WebViewWindowClass”).
Check CheckPoint("WebViewWindowClass") //設置檢查點
Services.EndTransaction "click" //定義一個事務結束
Window("A瀏覽器").Activate
Window("A瀏覽器").Click 1415,7 //關閉瀏覽器
Next |
測試結果如下:
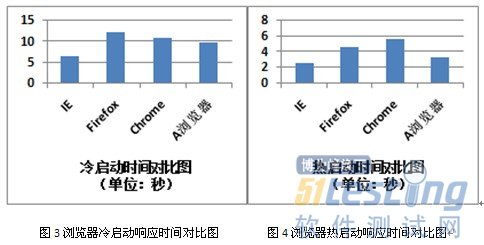
從測試結果對比圖可以看出,國產A瀏覽器在冷啟動和熱啟動測試中,均排名第二,表現出了不錯的啟動速度,IE瀏覽器由于與操作系統同出一家的關系,排名第一;而Firefox和Chrome由于與較多的控件進行綁定,因此啟動速度較慢。
3.3 標簽頁載入速度測試
本項內容主要考察瀏覽器載入主流的門戶網站、搜索引擎網站等用戶訪問率高的網站時的速度,訪問時間的記錄主要通過秒表的方式進行統計,為避免結果失真,均采用取3次測試結果平均值的方式獲得。測試結果如下:
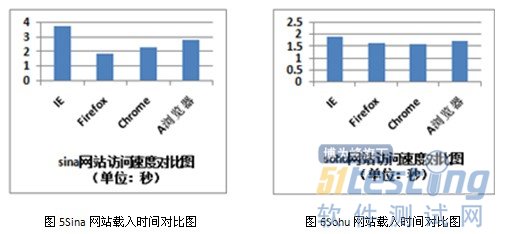
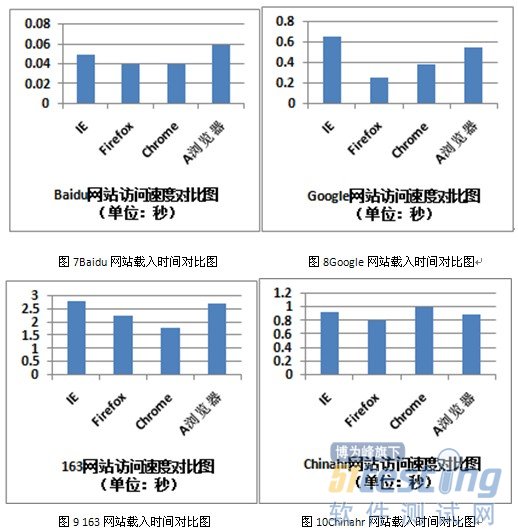
總體來看,Firefox和Chrome瀏覽器訪問門戶網站時速度占優,A瀏覽器居后,IE8.0則響應較慢。
3.4 標準頁面加載測試
本項采用權威的網站http://nontroppo.org/timer/進行測試,主要考核指標如下:
First Access:第一次加載并顯示Dom元素的時間;
Doc load:文本加載的時間;
Doc+Image Load:包括Css、JavaScript以及11張圖片的加載時間;
以上加載時間均越小代表瀏覽器處理越快,測試結果如下:

字體: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿

3.5 硬件加速
許多瀏覽器為加快2D、3D的渲染,采用具有多線程能力的GPU的緩存合成技術來處理圖像合成、縮放、三維特效處理 等操作,這種在顯示芯片內的處理提高了網頁的訪問速度。本項測試采用著名的“海底世界”測試工具來完成,考察設置顯示的魚的條數為1、10、50、100 和500時,瀏覽器的硬件加速能力,通過每秒幀數來能量測試結果,幀越大,硬件加速能力越強。以下圖表中的結果均是在測試過程中測試工具在平穩階段顯示的 每秒幀數。由于IE8.0不支持硬件加速功能,因此僅對Firefox、Firefox和A瀏覽器進行測試。
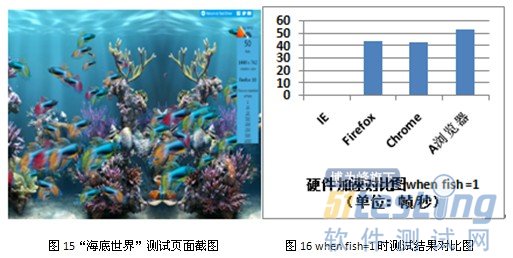
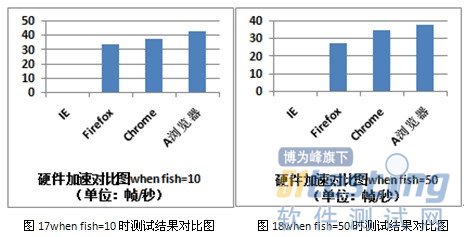

從測試結果得知,A瀏覽器在5項測試中均獲得頭名,但其硬件加速的能力相比Firefox和Chrome優勢較小,還需繼續改進,提升優勢。
4、測試總結
相比于世界著名的瀏覽器產品,國產A瀏覽器由于剛起步不久,用戶群較少,但是其性能表現在本次測試中并未完全處于下風,仍有許多值得稱贊的地方。相信隨著用戶群的增長,會加速A瀏覽器的發展和優化,最終能和世界知名的瀏覽器相抗衡。
另外需說明,本次測試是在實驗室環境下進行,不同的平臺環境和其它因素會導致測試結果大不相同,因此本次測試的結果數據僅用作參考,不作其它用途。
在最近的統計中,
蘋果應用商店中共有超過500,000種應用,而且
Android市場也有超過了300,000種應用,這些還不包括其他平臺上的應用,像RIM Playbook、Microsoft
Windows Phone和Windows Mobile。此外,每一個平臺都可以為各種設備出售各種
操作系統版本。開發應用需要在這些各種型號和操作系統版本的組合上
測試和驗證程序。自動化移動應用測試是唯一的發布時間表可以維持的方式。下面,我們探討一下
自動化測試移動應用程序所面臨的挑戰。
下面是移動應用的自動化測試挑戰:
自動化腳本需求:自動化腳本需求在一個應用程序發布、正在被使用,和隨后需要推出更新時更為緊迫。所有現存的特點需要每次推出更新時被測試,要確保在升級代碼的時候沒有回歸誤差。同時,各種各樣的造型和模型,特別是像Android平臺、自動化腳本、測試就不可避免。
多種語言和環境腳本:企業中通常采用將測試腳本可能需要綜合回到語言和測試環境中,像JUnit、QTP、PERL或者Python。
分布式測試:越來越多的移動測試外包出去,甚至是海外外包。開發人員和測試人員可能地理上是分離的。測試環境下可能需要處理全世界許多地方的多個時區,或者使用不同的當地電信服務供應商。測試環境可能需要24/7/365和互聯網/瀏覽器訪問可用。
發布自動化錯誤和崩潰跟蹤:一兩個崩潰之后,用戶就會放棄移動應用,甚至可能將其刪除。移動應用可能需要在內部測試模式一段時期后,才第一次在應用商店發布。自動化測試工具可能需要監測和跟蹤錯誤和崩潰,這些可能在正式的測試時遺漏掉了,即使在一個正式的發布之后。
測試設備登記管理:測試設備登記,特別是對于iOS設備,是一件苦差事,個人電話ID可能需要在蘋果網站上注冊。安裝包需要以電子郵件的形式發送給測試人員進行安裝和測試。自動化測試工具平穩并自動化地管理注冊,讓這個過程高效和有效。
多個電話模型可用性:打開移動操作系統,如:Android有一大批制造商直銷運行著不同版本操作系統的移動設備。在這種情況下,移動應用測試要求種類繁多的設備制造商和模型可用,用以完成可靠的驗證和認證。
模擬器處理器缺陷:手機模擬器,用筆記本電腦或者臺式電腦運行時可以使用其他的處理器,移動設備上只能使用一個處理器。為了完成可靠的測試,自動化測試需要在實際的電話上操作,而不只是模擬器。
遠程響應測試:移動應用在手機上可以獨立的,或者通過后端服務器在執行期間頻繁訪問。后者中,從多個地理位置進行遠程測試可能需要成為自動化測試的一部分。這是為了確保應用不論在哪里使用,其響應時間是合理的。