在CMMI四五級的軟件公司中,建立過程性能模型是一個重點也是一個難點工作,很多公司無法建立過程性能模型,為什么呢?
1)數據不準
比如:
? 對于評審的會議,評審的參與人有的是來學習的,在統計人數、工作量時就不應該統計在內。
? 有的數據當時沒有采集,而是靠時候回憶采集上來的。
? 有的代碼行數不是通過工具統計上來的,而是靠人估計估計出來的。
2)過程不穩定
過程不穩定的原因可以細分為:
i)過程太大
比如:對于整個項目的工期偏差率建立回歸分析模型,由于影響因子太多,每個因子都有影響,但是影響都不是很大,這樣對于采集數據的要求,過程的穩定性等要求很高,很難建立起回歸方程,因此此時需要劃分項目的階段建立每個階段工期偏差率模型或者不去細致的分析影響因子,而是建立蒙特卡羅的模擬模型,或者分不同類型的項目建立回歸方程。
ii)過程定義不穩定
在過程定義中定義的不夠細致,對于過程成功的要點沒有定義清楚,比如:
對于評審的流程,為了保證評審過程的穩定,應該要求:
● 評審的時長不能超過2小時。
● QA跟著每次評審控制會議不要過多討論。
● 會議開始是要聲明規則。
● 評審會與討論會要分開。
iii)過程執行不穩定
在流程定義中有要求,但是實際執行時沒有做到位,比如:
● 開評審會的時候進行了大量的討論比如設計的評審會,所以會議的工作量、會議的時長都不準。在設計會議上討論了設計方案的合理性。
● 會議的時間超過了2個小時,4個小時的評審會議,后邊的2個小時效率很低的。
● 會議的主持人在會議上沒有討論的現象進行控制。
iv)過程的輸入不穩定
不同的項目在執行過程時,投入差別太大,過程執行的前提條件不穩定,導致過程的輸出也會不穩定。比如:測試過程投入的單位工作量,有的項目投入的多,有的項目投入少,而如果這些輸入沒有被識別出來作為因子的話,則方程就無法建立起來。
3)影響因子(X)識別不全
● 在識別對于Y的影響因子時沒有識別出來關鍵的影響因子,比如測試過程的單位規模的測試工作量等;
● 識別了關鍵影響因子但是不好量化表達,采集數據有難度,比如人員的技術水平;
● 采集了關鍵因子的度量數據,但是數據不全,缺少樣本點;
影響因子的識別需要經驗識別,也需要統計的假設檢驗,也可以進行實驗設計。
4)對于大過程建模,影響因子太多,每個因子相關性都不大
如果是對于大的過程建模,則可能存在如下的問題:
● 影響因子多,每個因子的相關性都不是很大;
● 影響因子多,采集數據有難度,對每個數據都要求很準確;
● 影響因子之間彼此有交互疊加的作用,有相關性,建模困難。
5)樣本量太少
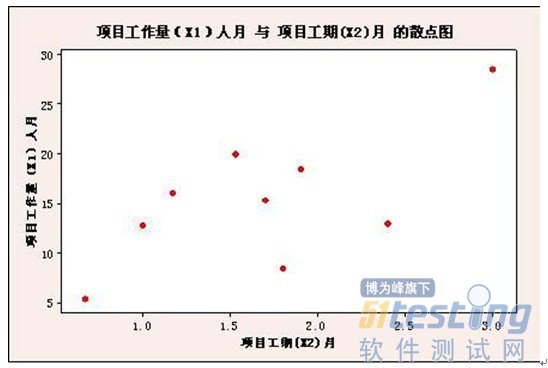
樣本量太少,增加或刪除一個樣本對回歸的結果影響很明顯,則規律不具有典型性。比如,在下圖中如果刪除右上角的一個點,則兩個變量之間就沒有相關性了,如果刪除了右下的2個點則兩個變量之間就是相關的。之所以出現這種現象就是樣本點太少而導致的。
6)樣本不隨機
比如有2個變量X1,X2與Y都應該是正相關的,但是在實際中存在的數據卻是:
| | 正相關 | 正相關 |
| Y | x1 | x2 |
| 中 | 大 | 小 |
| 中 | 小 | 大 |
此時如果對這些類型的數據進行分析,則表現出來Y與X1,X2是不相關的。
以測試過程為例,我們的經驗與常識:
假設或常識1:高水平的測試人員找出的BUG多, 低水平的測試人員找出的BUG少。
假設或常識2:高水平的開發人員犯的錯誤應該少,低水平的開發人員犯的錯誤應該多。
我們的實際數據:
在實踐中常常采用的策略:
策略1:關鍵的模塊應該由高水平的開發人員進行開發,非關鍵的模塊由低水平的開發人員進行開發。
策略2:高水平的測試人員要測關鍵的模塊,低水平的測試人員測試非關鍵的模塊。
如果是這樣,對于測試過程做了度量以后,數據無法證明假設1和2的成立。
以上六個原因就是最常見的原因,這些原因在實際中克服起來并非那么容易,這也是為什么4-5級需要比較長的實施周期的原因。