昨天上網找一個同步工具,windows同步到linux,額,ms不少,但是配置實在是麻煩,而且很多按照步驟做下來 都不能使用,(估計rp問題),最郁悶的事莫過如此,經過一個下午的努力,額,原來真的行的,分享給大家。(估計很多人會覺得啰嗦)
一.介紹 (不想看直接可以跳過)
Rsync是一個遠程數據同步工具,可通過LAN/WAN快速同步多臺主機間的文件。Rsync本來是用以取代rcp的一個工具,它當前由 rsync.samba.org維護。Rsync使用所謂的“Rsync演算法”來使本地和遠程兩個主機之間的文件達到同步,這個算法只傳送兩個文件的不同部分,而不是每次都整份傳送,因此速度相當快。運行Rsync server的機器也叫backup server,一個Rsync server可同時備份多個client的數據;也可以多個Rsync server備份一個client的數據。
Rsync可以搭配rsh或ssh甚至使用daemon模式。Rsync server會打開一個873的服務通道(port),等待對方Rsync連接。連接時,Rsync server會檢查口令是否相符,若通過口令查核,則可以開始進行文件傳輸。第一次連通完成時,會把整份文件傳輸一次,下一次就只傳送二個文件之間不同的部份。
Rsync支持大多數的類Unix系統,無論是Linux、Solaris還是BSD上都經過了良好的測試。此外,它在windows平臺下也有相應的版本,比較知名的有cwRsync和Sync2NAS。
Rsync的基本特點如下:
1.可以鏡像保存整個目錄樹和文件系統;
2.可以很容易做到保持原來文件的權限、時間、軟硬鏈接等;
3.無須特殊權限即可安裝;
4.優化的流程,文件傳輸效率高;
5.可以使用rcp、ssh等方式來傳輸文件,當然也可以通過直接的socket連接;
6.支持匿名傳輸。
核心算法介紹:
假定在名為α和β的兩臺計算機之間同步相似的文件A與B,其中α對文件A擁有訪問權,β對文件B擁有訪問權。并且假定主機α與β之間的網絡帶寬很小。那么rsync算法將通過下面的五個步驟來完成:
1.β將文件B分割成一組不重疊的固定大小為S字節的數據塊。最后一塊可能會比S 小。
2.β對每一個分割好的數據塊執行兩種校驗:一種是32位的滾動弱校驗,另一種是128位的MD4強校驗。
3.β將這些校驗結果發給α。
4.α通過搜索文件A的所有大小為S的數據塊(偏移量可以任選,不一定非要是S的倍數),來尋找與文件B的某一塊有著相同的弱校驗碼和強校驗碼的數據塊。這項工作可以借助滾動校驗的特性很快完成。
5.α發給β一串指令來生成文件A在β上的備份。這里的每一條指令要么是對文件B經擁有某一個數據塊而不須重傳的證明,要么是一個數據塊,這個數據塊肯定是沒有與文件B的任何一個數據塊匹配上的。
命令:
rsync的命令格式可以為以下六種:
rsync [OPTION]... SRC DEST
rsync [OPTION]... SRC [USER@]HOST:DEST
rsync [OPTION]... [USER@]HOST:SRC DEST
rsync [OPTION]... [USER@]HOST::SRC DEST
rsync [OPTION]... SRC [USER@]HOST::DEST
rsync [OPTION]... rsync://[USER@]HOST[:PORT]/SRC [DEST]
對應于以上六種命令格式,rsync有六種不同的工作模式:
1)拷貝本地文件。當SRC和DES路徑信息都不包含有單個冒號":"分隔符時就啟動這種工作模式。
2)使用一個遠程shell程序(如rsh、ssh)來實現將本地機器的內容拷貝到遠程機器。當DST路徑地址包含單個冒號":"分隔符時啟動該模式。
3)使用一個遠程shell程序(如rsh、ssh)來實現將遠程機器的內容拷貝到本地機器。當SRC地址路徑包含單個冒號":"分隔符時啟動該模式。
4)從遠程rsync服務器中拷貝文件到本地機。當SRC路徑信息包含"::"分隔符時啟動該模式。
5)從本地機器拷貝文件到遠程rsync服務器中。當DST路徑信息包含"::"分隔符時啟動該模式。
6)列遠程機的文件列表。這類似于rsync傳輸,不過只要在命令中省略掉本地機信息即可。
二.安裝
1.從原始網站下載:[url]http://rsync.samba.org/ftp/rsync/[/url] (http://rsync.samba.org/ftp/rsync/rsync-3.0.7.tar.gz目前是這個版本)
windows版本:
客戶端:cwRsync_2.0.10_Installer http://blogimg.chinaunix.net/blog/upfile/070917224721.zip
服務端:cwRsync_Server_2.0.10_Installer http://blogimg.chinaunix.net/blog/upfile/070917224837.zip
對于client 和 server都是windows的,那么可以直接安裝如上2個,然后可以通過建 windows的任務,實現定時處理,可以參考:
http://blog.csdn.net/daizhj/archive/2009/11/03/4765280.aspx
2.[root@localhost bin]#./configure
[root@localhost bin]#make
[root@localhost bin]#make install
這里可能會有權限問題,切換到root用戶
Rsync配置
/etc/rsyncd.conf (默認是沒有的,可以手工創建)
#全局選項
strict modes =yes #是否檢查口令文件的權限
port = 873 #默認端口873
log file = /var/log/rsyncd.log #日志記錄文件 原文中有的,我沒有使用,日志文件
pid file = /usr/local/rsync/rsyncd.pid #運行進程的ID寫到哪里 原文中有的,我沒有使用,日志文件
#模塊選項
[test] # 這里是認證的模塊名,在client端需要指定
max connections = 5 #客戶端最大連接數,默認0(沒限制)
uid = root #指定該模塊傳輸文件時守護進程應該具有的uid
gid = root #指定該模塊傳輸文件時守護進程應該具有的gid
path = /home/admin/testrsync # 需要做備份的目錄
ignore errors # 可以忽略一些無關的IO錯誤
read only = no #no客戶端可上傳文件,yes只讀
write only = no #no客戶端可下載文件,yes不能下載
hosts allow = * #充許任何主機連接
hosts deny = 10.5.3.77 #禁止指定的主機連接
auth users = root # 認證的用戶名,如果沒有這行,則表明是匿名
secrets file = /home/admin/security/rsync.pass # 指定認證口令文件位置
生成rsync密碼文件
在server端生成一個密碼文件/home/admin/security/rsync.pass
vi rsync.pass
root:hell05a
注意:密碼文件的權限,是由rsyncd.conf里的參數
strict modes =yes/no 來決定
Rsync 的啟動
rsycn 的啟動方式有多種,我們在這里介紹以下幾種:
●. 守護進程方式:(我現在只使用這個)
/usr/local/bin/rsync --daemon
驗證啟動是否成功
ps -aux |grep rsync
root 59120 0.0 0.2 1460 972 ?? Ss 5:20PM 0:00.00 /usr/local/rsync/bin/rsync –daemon
netstat -an |grep 873
tcp4 0 0 *.873 *.* LISTEN
結束進程:kill -9 pid的值
kill -15 進程名
如果是linux之間同步,只需要安裝rsync,如果是需要linux與windows之間同步,安裝 cwrsync
三.客戶端訪問:(客戶端也需要安裝 rsync,如果是windows,安裝cwrsync)
實例演示使用:
下載文件:
./rsync -vzrtopg --progress --delete root@xxx.xxx.xxx.xxx::backup /home/admin/getfile
上傳文件:
/usr/bin/rsync -vzrtopg --progress /home/admin/getfile root@xxx.xxx.xxx.xxx::backup
Rsync 同步參數說明
-vzrtopg里的v是verbose,z是壓縮,r是recursive,topg都是保持文件原有屬性如屬主、時間的參數。
--progress是指顯示出詳細的進度情況
--delete是指如果服務器端刪除了這一文件,那么客戶端也相應把文件刪除
root@xxx.xxx.xxx.xxx中的root是指定密碼文件中的用戶名,xxx為ip地址
backup 是指在rsyncd.conf里定義的模塊名
/home/admin/getfile 是指本地要備份目錄
可能出現的問題:
@ERROR: auth failed on module backup
rsync error: error starting client-server protocol (code 5) at main.c(1506) [Receiver=3.0.7]
那估計是密碼文件沒有設置權限哦: chmod 600 /home/admin/security/rsync.pass
應該差不多就可以了。
(2)打開rsync服務
#chkconfig xinetd on
#chkconfig rsync on
(4)啟動基于xinetd進程的rsync服務t
#/etc/init.d/xinetd start
3、配置windows的rsync客戶端
(1)安裝client端的rsync包
(2)打開cmd,執行同步計劃:
cd C:\Program Files\cwRsync\bin
下載同步(把服務器上的東東下載當前目錄)
rsync -vzrtopg --progress --delete root@xxx.xxx.xxx.xxx::backup ./ff
(此時須輸入root用戶的密碼,就可進行同步了。)
上傳同步(把本地東東上傳到服務器)
rsync -vzrtopg --progress ./get/ root@xxx.xxx.xxx.xxx::backup
參數說明
-v, --verbose 詳細模式輸出
-q, --quiet 精簡輸出模式
-c, --checksum 打開校驗開關,強制對文件傳輸進行校驗
-a, --archive 歸檔模式,表示以遞歸方式傳輸文件,并保持所有文件屬性,等于-rlptgoD
-r, --recursive 對子目錄以遞歸模式處理
-R, --relative 使用相對路徑信息
-b, --backup 創建備份,也就是對于目的已經存在有同樣的文件名時,將老的文件重新命名為~filename。可以使用--suffix選項來指定不同的備份文件前綴。
--backup-dir 將備份文件(如~filename)存放在在目錄下。
-suffix=SUFFIX 定義備份文件前綴
-u, --update 僅僅進行更新,也就是跳過所有已經存在于DST,并且文件時間晚于要備份的文件。(不覆蓋更新的文件)
-l, --links 保留軟鏈結
-L, --copy-links 想對待常規文件一樣處理軟鏈結
--copy-unsafe-links 僅僅拷貝指向SRC路徑目錄樹以外的鏈結
--safe-links 忽略指向SRC路徑目錄樹以外的鏈結
-H, --hard-links 保留硬鏈結 -p, --perms 保持文件權限
-o, --owner 保持文件屬主信息 -g, --group 保持文件屬組信息
-D, --devices 保持設備文件信息 -t, --times 保持文件時間信息
-S, --sparse 對稀疏文件進行特殊處理以節省DST的空間
-n, --dry-run現實哪些文件將被傳輸
-W, --whole-file 拷貝文件,不進行增量檢測
-x, --one-file-system 不要跨越文件系統邊界
-B, --block-size=SIZE 檢驗算法使用的塊尺寸,默認是700字節
-e, --rsh=COMMAND 指定使用rsh、ssh方式進行數據同步
--rsync-path=PATH 指定遠程服務器上的rsync命令所在路徑信息
-C, --cvs-exclude 使用和CVS一樣的方法自動忽略文件,用來排除那些不希望傳輸的文件
--existing 僅僅更新那些已經存在于DST的文件,而不備份那些新創建的文件
--delete 刪除那些DST中SRC沒有的文件
--delete-excluded 同樣刪除接收端那些被該選項指定排除的文件
--delete-after 傳輸結束以后再刪除
--ignore-errors 及時出現IO錯誤也進行刪除
--max-delete=NUM 最多刪除NUM個文件
--partial 保留那些因故沒有完全傳輸的文件,以是加快隨后的再次傳輸
--force 強制刪除目錄,即使不為空
--numeric-ids 不將數字的用戶和組ID匹配為用戶名和組名
--timeout=TIME IP超時時間,單位為秒
-I, --ignore-times 不跳過那些有同樣的時間和長度的文件
--size-only 當決定是否要備份文件時,僅僅察看文件大小而不考慮文件時間
--modify-window=NUM 決定文件是否時間相同時使用的時間戳窗口,默認為0
-T --temp-dir=DIR 在DIR中創建臨時文件
--compare-dest=DIR 同樣比較DIR中的文件來決定是否需要備份
-P 等同于 --partial
--progress 顯示備份過程
-z, --compress 對備份的文件在傳輸時進行壓縮處理
--exclude=PATTERN 指定排除不需要傳輸的文件模式
--include=PATTERN 指定不排除而需要傳輸的文件模式
--exclude-from=FILE 排除FILE中指定模式的文件
--include-from=FILE 不排除FILE指定模式匹配的文件
--version 打印版本信息
--address 綁定到特定的地址
--config=FILE 指定其他的配置文件,不使用默認的rsyncd.conf文件
--port=PORT 指定其他的rsync服務端口
--blocking-io 對遠程shell使用阻塞IO
-stats 給出某些文件的傳輸狀態
--progress 在傳輸時現實傳輸過程
--log-format=formAT 指定日志文件格式
--password-file=FILE 從FILE中得到密碼
--bwlimit=KBPS 限制I/O帶寬,KBytes per second -h, --help 顯示幫助信息
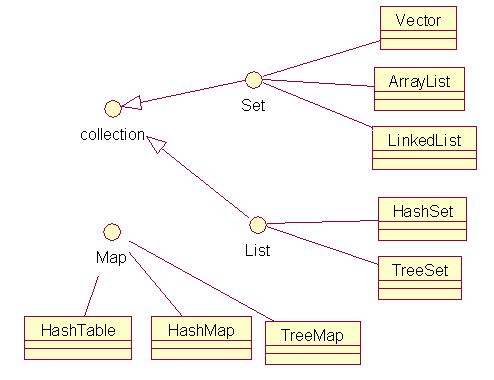
Collection接口 由 Set接口 和 List接口 繼承。
Set 被 Vector . ArrayList LinkedList 實現。
List 被 HashSet TreeSet 實現。
Map接口 由 HashTable HashMap TreeMap 實現。
下面看下每個實現類的特征;;;--》(轉的。)
1. List (有重復、有序)
Vector基于Array的List,性能也就不可能超越Array,并且Vector是“sychronized”的,這個也是Vector和ArrayList的唯一的區別。
ArrayList:同Vector一樣是一個基于Array的,但是不同的是ArrayList不是同步的。所以在性能上要比Vector優越一些,但是當運行到多線程環境中時,可需要自己在管理線程的同步問題。從其命名中可以看出它是一種類似數組的形式進行存儲,因此它的隨機訪問速度極快。
數據增長:當需要增長時,Vector默認增長為原來一培,而ArrayList卻是原來的一半
LinkedList:LinkedList不同于前面兩種List,它不是基于Array的,所以不受Array性能的限制。它每一個節點(Node)都包含兩方面的內容:1.節點本身的數據(data);2.下一個節點的信息(nextNode)。所以當對LinkedList做添加,刪除動作的時候就不用像基于Array的List一樣,必須進行大量的數據移動。只要更改nextNode的相關信息就可以實現了所以它適合于進行頻繁進行插入和刪除操作。這就是LinkedList的優勢。Iterator只能對容器進行向前遍歷,而 ListIterator則繼承了Iterator的思想,并提供了對List進行雙向遍歷的方法。
用在FIFO,用addList()加入元素 removeFirst()刪除元素
用在FILO,用addFirst()/removeLast()
ListIterator 提供雙向遍歷next() previous(),可刪除、替換、增加元素
List總結: 1. 所有的List中只能容納單個不同類型的對象組成的表,而不是Key-Value鍵值對。例如:[ tom,1,c ]; 2. 所有的List中可以有相同的元素,例如Vector中可以有 [ tom,koo,too,koo ]; 3. 所有的List中可以有null元素,例如[ tom,null,1 ]; 4. 基于Array的List(Vector,ArrayList)適合查詢,而LinkedList(鏈表)適合添加,刪除操作。
2. Set
HashSet:雖然Set同List都實現了Collection接口,但是他們的實現方式卻大不一樣。List基本上都是以Array為基礎。但是Set則是在HashMap的基礎上來實現的,這個就是Set和List的根本區別。HashSet的存儲方式是把HashMap中的Key作為Set的對應存儲項,這也是為什么在Set中不能像在List中一樣有重復的項的根本原因,因為HashMap的key是不能有重復的。HashSet能快速定位一個元素,但是放到HashSet中的對象需要實現hashCode()方法0。
TreeSet則將放入其中的元素按序存放,這就要求你放入其中的對象是可排序的,這就用到了集合框架提供的另外兩個實用類Comparable和Comparator。一個類是可排序的,它就應該實現Comparable接口。有時多個類具有相同的排序算法,那就不需要重復定義相同的排序算法,只要實現Comparator接口即可。TreeSet是SortedSet的子類,它不同于HashSet的根本就是TreeSet是有序的。它是通過SortedMap來實現的。
Set總結: 1. Set實現的基礎是Map(HashMap); 2. Set中的元素是不能重復的,如果使用add(Object obj)方法添加已經存在的對象,則會覆蓋前面的對象; Set里的元素是不能重復的,那么用什么方法來區分重復與否呢? 是用==還是equals()? 它們有何區別? Set里的元素是不能重復的,即不能包含兩個元素e1、e2(e1.equals(e2))。那么用iterator()方法來區分重復與否。equals()是判讀兩個Set是否相等。==方法決定引用值(句柄)是否指向同一對象。
3. Map
Map是一種把鍵對象和值對象進行關聯的容器,Map有兩種比較常用的實現: HashTable、HashMap和TreeMap。
HashMap也用到了哈希碼的算法,以便快速查找一個鍵,TreeMap則是對鍵按序存放,因此它有一些擴展的方法,比如firstKey(),lastKey()等。
只有HashMap可以讓你將空值作為一個表的條目的key或value
HashMap和Hashtable的區別。 HashMap是Hashtable的輕量級實現(非線程安全的實現),他們都完成了Map接口。主要區別在于HashMap允許空(null)鍵(key)或值(value),非同步,由于非線程安全,效率上可能高于Hashtable。 Hashtable不允許空(null)鍵(key)或值(value),Hashtable的方法是Synchronize的,在多個線程訪問Hashtable時,不需要自己為它的方法實現同步,而HashMap 就必須為之提供外同步。 Hashtable和HashMap采用的hash/rehash算法都大概一樣,所以性能不會有很大的差異。
HashMap:
散列表的通用映射表,無序,可在初始化時設定其大小,自動增長。
只有HashMap可以讓你將空值作為一個表的條目的key或value
LinkedHashMap:
擴展HashMap,對返回集合迭代時,維護插入順序
WeakHashMap:
基于弱引用散列表的映射表,如果不保持映射表外的關鍵字的引用,則內存回收程序會回收它
TreeMap:
基于平衡樹的映射表
內存泄漏幾種常見的方式:
1. 無意識的對象保持。 就是接下來的例子。
2. 使用緩存。(很長一段時間仍然留在緩存中)
一旦你把對象引用放到緩存中,它就很容易被遺忘掉,從而使得它不再有用之后很長一段時間內仍然留在緩存中。對于這個問題,有幾種可能的解決方案。如果你正好要實現這樣的緩存:只要在緩存之外存在對某個項的鍵的引用,該項就有意義,那么就可以用WeakHashMap代表緩存;當緩存中的項過期之后,它們就會自動被刪除。記住只有當所要的緩存項的生命周期是由該鍵的外部引用而不是由值決定時,WeakHashMap才有用處。
更為常見的情形則是,"緩存項的生命周期是否有意義"并不是很容易確定,隨著時間的推移,其中的項會變得越來越沒有價值。在這種情況下,緩存應該時不時地清除掉沒用的項。這項清除工作可以由一個后臺線程(可能是Timer或者ScheduledThreadPoolExecutor)來完成,或者也可以在給緩存添加新條目的時候順便進行清理。LinkedHashMap類利用它的removeEldestEntry方法可以很容易地實現后一種方案。對于更加復雜的緩存,必須直接使用java.lang.ref。
3. 監聽器和其他回調
如果你在實現的是客戶端注冊回調卻沒有顯式地取消注冊的API,除非你采取某些動作,否則它們就會積聚。確保回調立即被當作垃圾回收的最佳方法是只保存它們的弱引用(weak
reference),例如,只將它們保存成WeakHashMap中的鍵。
對于 1.無意識的對象保持,代碼:
1 public class Stack {
2 private Object[] elements;
3 private int size = 0;
4 private static final int DEFAULT_INITIAL_CAPACITY = 16;
5
6 public Stack() {
7 elements = new Object[DEFAULT_INITIAL_CAPACITY];
8 }
9
10 public void push(Object e) {
11 ensureCapacity();
12 elements[size++] = e;
13 }
14
15 public Object pop() {
16 if (size == 0)
17 throw new EmptyStackException();
18 return elements[--size];
19 }
20
21 /**
22 * * Ensure space for at least one more element, roughly* doubling the
23 * capacity each time the array needs to grow.
24 */
25 private void ensureCapacity() {
26 if (elements.length == size)
27 elements = Arrays.copyOf(elements, 2 * size + 1);
28 }
29 }
修改方式:
把上面的pop方法修改成如下:
public Object pop() {
if (size == 0)
throw new EmptyStackException();
Object result = elements[--size];
elements[size] = null;
return result;
}
清空過期引用的另一個好處是,如果它們以后又被錯誤地解除引用,程序就會立即拋出NullPointerException異常,而不是悄悄地錯誤運行下去。盡快地檢測出程序中的錯誤總是有益的。
第二條 遇到多個構造器參數時要考慮用構造器
這里考慮的是參數多的情況,如果參數個數比較少,那直接采用一般的構造方法就可以了。
書中介紹了寫構造方法的時候幾種方式:
1. 重疊構造方法模式:
缺點:有許多參數的時候,客戶端代碼會很難寫,而且較難以閱讀。
2. javaBeans模式:
缺點:
在構造過程中JavaBean可能處于不一致的狀態,類本身無法判斷是否有效性。
類做成不可變的可能。
3. builder模式:
優點:
在build方法生成對象的時候,可以做檢查,判斷是否符合要求
參數靈活
缺點:
創建對象必須先創建構造器,如果對性能要求非常高的應用少用為妙
具體實現代碼:
1.重疊構造方法模式:
public class NutritionFacts {
private final int servingSize;
private final int serviings;
private final int calories;
private final int fat;
private int sodium;
private int carbohydrate;
public NutritionFacts(int servingSize, int serviings){
this(servingSize, serviings, 0);
}
public NutritionFacts(int servingSize, int serviings, int calories){
this(servingSize, serviings, calories, 0);
}
public NutritionFacts(int servingSize, int serviings, int calories, int fat){
this(servingSize, serviings, calories, fat,0);
}
public NutritionFacts(int servingSize, int serviings, int calories, int fat, int sodium){
this(servingSize, serviings, calories, fat, sodium,0);
}
public NutritionFacts(int servingSize, int serviings, int calories, int fat, int sodium, int carbohydrate){
this.servingSize = servingSize;
this.serviings = serviings;
this.calories = calories;
this.fat = fat;
this.sodium = sodium;
this.carbohydrate = carbohydrate;
}
}
2. javaBeans模式 代碼:
public class NutritionFacts {
private int servingSize;
private int serviings;
private int calories;
private int fat;
private int sodium;
private int carbohydrate;
public NutritionFacts(){}
public void setServingSize(int servingSize) {
this.servingSize = servingSize;
}
public void setServiings(int serviings) {
this.serviings = serviings;
}
public void setCalories(int calories) {
this.calories = calories;
}
public void setFat(int fat) {
this.fat = fat;
}
public void setSodium(int sodium) {
this.sodium = sodium;
}
public void setCarbohydrate(int carbohydrate) {
this.carbohydrate = carbohydrate;
}
3. builder模式
public class NutritionFacts {
private final int servingSize;
private final int serviings;
private final int calories;
private final int fat;
private final int sodium;
private final int carbohydrate;
public static class Builder {
private final int servingSize;
private final int serviings;
// 可以為空
private int calories = 0;
private int fat = 0;
private int sodium = 0;
private int carbohydrate = 0;
public Builder(int servingSize, int serviings) {
this.servingSize = servingSize;
this.serviings = serviings;
}
public Builder calories(int val){
calories = val;
return this;
}
public Builder fat(int val){
fat = val;
return this;
}
public Builder sodium(int val){
sodium = val;
return this;
}
public Builder carbohydrate(int val){
carbohydrate = val;
return this;
}
public NutritionFacts build(){
return new NutritionFacts(this);
}
}
public NutritionFacts(Builder builder) {
servingSize = builder.servingSize;
serviings = builder.serviings;
calories = builder.calories;
fat = builder.fat;
sodium = builder.sodium;
carbohydrate = builder.carbohydrate;
}
}
這個調用的時候:
NutritionFacts cocaCola = new NutritionFacts.Builder(11,22).calories(1).fat(2).calories(3).build();
在Java中設置變量值的操作,除了long和double類型的變量外都是原子操作,也就是說,對于變量值的簡單讀寫操作沒有必要進行同步。
這在JVM 1.2之前,Java的內存模型實現總是從主存讀取變量,是不需要進行特別的注意的。而隨著JVM的成熟和優化,現在在多線程環境下volatile關鍵字的使用變得非常重要。
在當前的Java內存模型下,線程可以把變量保存在本地內存(比如機器的寄存器)中,而不是直接在主存中進行讀寫。這就可能造成一個線程在主存中修改了一個變量的值,而另外一個線程還繼續使用它在寄存器中的變量值的拷貝,造成數據的不一致。
要解決這個問題,只需要像在本程序中的這樣,把該變量聲明為volatile(不穩定的)即可,這就指示JVM,這個變量是不穩定的,每次使用它都到主存中進行讀取。一般說來,多任務環境下各任務間共享的標志都應該加volatile修飾。
Volatile修飾的成員變量在每次被線程訪問時,都強迫從共享內存中重讀該成員變量的值。而且,當成員變量發生變化時,強迫線程將變化值回寫到共享內存。這樣在任何時刻,兩個不同的線程總是看到某個成員變量的同一個值。
Java語言規范中指出:為了獲得最佳速度,允許線程保存共享成員變量的私有拷貝,而且只當線程進入或者離開同步代碼塊時才與共享成員變量的原始值對比。
這樣當多個線程同時與某個對象交互時,就必須要注意到要讓線程及時的得到共享成員變量的變化。
而volatile關鍵字就是提示VM:對于這個成員變量不能保存它的私有拷貝,而應直接與共享成員變量交互。
使用建議:在兩個或者更多的線程訪問的成員變量上使用volatile。當要訪問的變量已在synchronized代碼塊中,或者為常量時,不必使用。
由于使用volatile屏蔽掉了VM中必要的代碼優化,所以在效率上比較低,因此一定在必要時才使用此關鍵字。
文章出處:DIY部落(http://www.diybl.com/course/3_program/java/javaxl/20090302/156333.html)
同時查看下IBM中的詳細解釋:
Java 理論與實踐: 正確使用 Volatile 變量
http://www.ibm.com/developerworks/cn/java/j-jtp06197.html
今天在熟悉我們的項目的時候,sql中看到FORCE INDEX,額,都不知道什么東東,有什么特別用處嗎? 查了下資料,原來是這樣啊,發現一般不搞復雜sql,而且復雜sql DBA也不允許,但優化的sql 還是有必要了解下。(一般來說也不太會使用,總被DBA pk了)
下面部分轉:
對于經常使用oracle的朋友可能知道,oracle的hint功能種類很多,對于優化sql語句提供了很多方法。同樣,在mysql里,也有類似的hint功能。下面介紹一些常用的。
1。強制索引 FORCE INDEX
SELECT * FROM TABLE1 FORCE INDEX (FIELD1) …
以上的SQL語句只使用建立在FIELD1上的索引,而不使用其它字段上的索引。
2。忽略索引 IGNORE INDEX
SELECT * FROM TABLE1 IGNORE INDEX (FIELD1, FIELD2) …
在上面的SQL語句中,TABLE1表中FIELD1和FIELD2上的索引不被使用。
3。關閉查詢緩沖 SQL_NO_CACHE
SELECT SQL_NO_CACHE field1, field2 FROM TABLE1;
有一些SQL語句需要實時地查詢數據,或者并不經常使用(可能一天就執行一兩次),這樣就需要把緩沖關了,不管這條SQL語句是否被執行過,服務器都不會在緩沖區中查找,每次都會執行它。
4。強制查詢緩沖 SQL_CACHE
SELECT SQL_CALHE * FROM TABLE1;
如果在my.ini中的query_cache_type設成2,這樣只有在使用了SQL_CACHE后,才使用查詢緩沖。
5。優先操作 HIGH_PRIORITY
HIGH_PRIORITY可以使用在select和insert操作中,讓MYSQL知道,這個操作優先進行。
SELECT HIGH_PRIORITY * FROM TABLE1;
6。滯后操作 LOW_PRIORITY
LOW_PRIORITY可以使用在insert和update操作中,讓mysql知道,這個操作滯后。
update LOW_PRIORITY table1 set field1= where field1= …
7。延時插入 INSERT DELAYED
INSERT DELAYED INTO table1 set field1= …
INSERT DELAYED INTO,是客戶端提交數據給MySQL,MySQL返回OK狀態給客戶端。而這是并不是已經將數據插入表,而是存儲在內存里面等待排隊。當mysql有空余時,再插入。另一個重要的好處是,來自許多客戶端的插入被集中在一起,并被編寫入一個塊。這比執行許多獨立的插入要快很多。壞處是,不能返回自動遞增的ID,以及系統崩潰時,MySQL還沒有來得及插入數據的話,這些數據將會丟失。
8 。強制連接順序 STRAIGHT_JOIN
SELECT TABLE1.FIELD1, TABLE2.FIELD2 FROM TABLE1 STRAIGHT_JOIN TABLE2 WHERE …
由上面的SQL語句可知,通過STRAIGHT_JOIN強迫MySQL按TABLE1、TABLE2的順序連接表。如果你認為按自己的順序比MySQL推薦的順序進行連接的效率高的話,就可以通過STRAIGHT_JOIN來確定連接順序。
9。強制使用臨時表 SQL_BUFFER_RESULT
SELECT SQL_BUFFER_RESULT * FROM TABLE1 WHERE …
當我們查詢的結果集中的數據比較多時,可以通過SQL_BUFFER_RESULT.選項強制將結果集放到臨時表中,這樣就可以很快地釋放MySQL的表鎖(這樣其它的SQL語句就可以對這些記錄進行查詢了),并且可以長時間地為客戶端提供大記錄集。
10。分組使用臨時表 SQL_BIG_RESULT和SQL_SMALL_RESULT
SELECT SQL_BUFFER_RESULT FIELD1, COUNT(*) FROM TABLE1 GROUP BY FIELD1;
一般用于分組或DISTINCT關鍵字,這個選項通知MySQL,如果有必要,就將查詢結果放到臨時表中,甚至在臨時表中進行排序。SQL_SMALL_RESULT比起SQL_BIG_RESULT差不多,很少使用。
其實這篇文章很早看到的,但仔細想想其實沒多大意思,有一次維護代碼的時候,發現一些看似有意思的寫法,就在本博記錄下,容易遺忘。
小技巧感覺上很有意思,但并不是很實用,容易理解的配合,方便維護的配置,才是最好的代碼。搞點小技巧,不方便維護。
在BeanFactory的配置中,<bean>是我們最常見的配置項,它有兩個最常見的屬性,即id和name,最近研究了一下,發現這兩個屬性還挺好玩的,特整理出來和大家一起分享。
1.id屬性命名必須滿足XML的命名規范,因為id其實是XML中就做了限定的。總結起來就相當于一個Java變量的命名:不能以數字,符號打頭,不能有空格,如123,?ad,"ab
"等都是不規范的,Spring在初始化時就會報錯,
org.xml.sax.SAXParseException: Attribute value "?ab" of type ID must be a name.
2.name屬性則沒有這些限定,你可以使用幾乎任何的名稱,如?ab,123等,但不能帶空格,如"a b","
abc",,這時,雖然初始化時不會報錯,但在getBean()則會報出諸如以下的錯誤:
org.springframework.beans.factory.NoSuchBeanDefinitionException: No bean named 'a b' is defined
3.配置文件中不允許出現兩個id相同的<bean>,否則在初始化時即會報錯,如:
org.xml.sax.SAXParseException: Attribute value "aa" of type ID must be unique within the document.
4.但配置文件中允許出現兩個name相同的<bean>,在用getBean()返回實例時,后面一個Bean被返回,應該是前面那個<bean>被后面同名的
<bean>覆蓋了。有鑒于此,為了避免不經意的同名覆蓋的現象,盡量用id屬性而不要用name屬性。
5.name屬性可以用,隔開指定多個名字,如<bean name="b1,b2,b3">,相當于多個別名,這時通過getBean("a1")
getBean("a2") getBean("a3")返回的都是同一個實例(假設是singleton的情況)
6.如果id和name都沒有指定,則用類全名作為name,如<bean
class="com.stamen.BeanLifeCycleImpl">,則你可以通過
getBean("com.biao.GroupThreadImpl")返回該實例。
7.如果存在多個id和name都沒有指定,且實例類都一樣的<bean>,如:
<bean class="com.biao.GroupThreadImpl"/>
<bean class="com.biao.GroupThreadImpl"/>
<bean class="com.biao.GroupThreadImpl"/>
則第一個bean通過getBean("com.biao.GroupThreadImpl")獲得,
第二個bean通過getBean("com.biao.GroupThreadImpl#1")獲得,
第三個bean通過getBean("com.biao.GroupThreadImpl#2")獲得,以此類推。
Cookie是在Web上用于存儲客戶系統信息的對象。所有的信息都以每行一個Cookie的形式存放在客戶端的一個名為cookies.txt的文件里。Cookie在HTTP頭標(客戶和服務器用來標識自身的分組)中在客戶機與服務器之間傳輸。
Cookie由某個WWW網頁在某客戶機上進行設置。比如,某個WWW網頁已在一個用戶的計算機上設置了一個Cookie,其中存儲的信息是該用戶的身份號(隨機賦予該用戶的唯一標識),當該用戶的瀏覽器連接該WWW站點時,站點要求瀏覽器將Cookie送回,他的身份號就通過Cookie 傳遞給該網頁所在的WWW服務器。服務器上的一個CGI程序查找一個服務器端的文件以確定關于他的預設內容。
當某個服務器在客戶的計算機上設置Cookie后,請注意如果要讓Cookie信息確實寫入文件,必須關閉瀏覽器。在瀏覽器未關閉之前,任何新的或變化的Cookie都存放在內存中。
二、Cookie的特性
每個Cookie包含有6個元素,常用的有:name、value、expires、domain和secure。這些元素存放了這個Cookie的作用范圍及實際的數據。
1.name 這是每一個Cookie必須有的元素,它是該Cookie的名字。name元素是一個不含分號、逗號和空格的字符串。其命名方式與變量命名相同。
2.value value也是每個Cookie必須有的元素,它是該Cookie的值。value元素是實際存放于Cookie中的信息。它是由任何字符構成的字符串。
3.expires expires是一個Cookie的過期時間。沒有設置expires元素的Cookie在用戶斷開連接后過期,但在用戶關閉瀏覽器之前Cookie依然存在。
Cookie有一個過期時間并等于它會從Cookie.txt文件中被刪除。在它的位置被用來存放另一個Cookie前,它依然存在著。過期的Cookie只是不被送往要求使用它的服務器。
expire是一個串,它的形式如下:
Wdy, DD-Mon-YY HH:MM:SS GMT
expires元素是可選的。
4.domain domain是設置某個Cookie的Web網頁所在的計算機的域名。這樣,由一個站點創建的Cookie不會影響到另一個站點上的程序。對于較高層的域名如.com, .edu,或.mil,域名中至少有兩個分隔符(.)。而對于較低層的域名如.cn, .uk或.ca,域名中至少有3個分隔符。demain元素自動地被設為網頁所在站點的基本域名。比如,你的網頁位于http://www.abc.com/~user,則該網頁創建的Cookie缺省地對域abc.com有效。如果你希望你的Cookie 只應用于服務器www3.abc.com,那么你必須在設置Cookie的時候指定。
只有擁有域名的站點才能為那個域名設置Cookie
5.path 一個Cookie可以被指定為只針對一個站點的某一層次。如果一個Web站點要區分已注冊的和未注冊的客戶,就可以為已經注冊的客戶設置Cookie,當注冊過的客戶訪問該站點時,他就可以訪問到只對注冊客戶有效的頁面。path是可選項,如果沒有指定path,將被缺省地設置為設置Cookie的頁面的路徑。
6.secure標志 secure是一個布爾值(真或假)。它的缺省值為假。如果它被設為真值, 這個Cookie只被瀏覽器認為是安全的服務器所記住。
三、關于Cookie的一些限制
一個站點能為一個單獨的客戶最多設置20個Cookie。如果一個站點有兩個服務器(如www.abc.com和www3.abc.com)但沒有指定域名,Cookie的域名缺省地是abc.com。如果指定了確切的服務器地址,則每個站點可以設置20個Cookie--而不是總共20個。不僅每個服務器能設置的Cookie數目是有限的,而且每個客戶機最多只能存儲300個Cookie。如果一個客戶機已有300個Cookie,并且一個站點在它上面又設置了一個新Cookie,那么,先前存在的某一個Cookie將被刪除。
每個Cookie也有自身的限制。Cookie不得超過4KB(4096bytes),其中包括名字和其他信息。
四、javascript和Cookie
現在大家已經了解有關Cookie的一些基本概念了,讓我們更進一步討論Cookie。可以用javascript來很方便地編寫函數用來創建、讀取和刪除Cookie。下面,我們就介紹這些函數
1.創建Cookie
我們要進行的第一件事就是要創建一個Cookie。下面給出的SctCookie()函數將完成這一功能。
function SetCookit (name, value) {
var argv=SetCookie.arguments;
var argc=SetCookie.arguments.length;
var expires=(argc>2)?argv[2]: null;
var path=(argc>3)? argv[3]: null;
var domain=(argc>4)? argv[4]: null;
var secure=(argc>5)? argv[5]: false;
documents.cookie=name+"="+escape
(value)+
((expires==null)?"":(";expires="
+expires.toGMTString()))+
((path==null)?"":(";path="+path))+
((domain==null)?"":(";domain="+
domain))+
((secure==true)?";secure":"");
}
SetCookie()只要求傳遞被設置的Cookie的名字和值,但如果必要的話你可以設置其他4 個參數而不必改變這個函數。可選的參數必須用正確的次序使用。如果不想設置某個參數, 必須設置一個空串。比如,如果我們創建的一個Cookie需要指定secure域,但不想設置expires, patb或domain,就可以像這樣調用SetCokie(): SetCookie("MyNewCookie","Myvalue" ,"",","tyue);
2.讀取Cookie
下面給出的函數GetCookie()用來讀取一個Cookie。當一個Cookie的請求被客戶機收到時,該客戶機查找它的cookies.txt文件以進行匹配。這個函數首先匹配這個Cookie的名字。如果有多個同名的Cookie,它再匹配路徑。函數完成匹配后返回這個Cookie的值。如果客戶機中沒有這個Cookie,或者路徑不匹配,該函數返回一個NULL。
function GetCookie(name) {
var arg=name+ "=";
var alen=arg.length;
var clen=documents.cookie.length;
var i=0;
while (i<clen) {
var j=i+alen;
if(documents.cookie.substring(i,j)
==arg)
return getCookieVal(j);
i=documents.cookie.indexOf("",i)+1;
if(i==0)break;
}
return null;
}
函數中使用了getCookieVal()函數,它是GetCookie()函數的補充。getCookieVal()將C ookies.txt文件分解為片斷,并從一批Cookie中讀出正確的Cookie。該函數的實現如下:
function getCookieVal(offset) {
var endstr=documents.cookie.indexOf
(";",offset);
if(endstr==-1) //沒有指定其他元素
endstr=documents.cookie.length;
return unescape(documents.cookie.substring
(offset,endstr));
}
3.刪除Cookie
刪除一個Cookie很簡單,只需將它的過期時間設為NULL。當用戶斷開連接后,這個Cooki e就過期了(沒有過期時間的Cookie將在瀏覽器關閉時被刪除)。下面的函數DeleteCookie() 說明了如何刪除一個
Cookie:
function DeleteCookie(name) {
var exp=new Date();
exp.setTime(exp.getTime()-1);
//將exp設為已過期的時間
var cval=GetCookie(name);
documents.cookie=name+"="+cval+";
expires="+exp.toGMTString();
}
網上的解釋原因:
Iterator 是工作在一個獨立的線程中,并且擁有一個 互斥 鎖。 Iterator 被創建之后會建立一個指向原來對象的單鏈索引表,當原來的對象數量發生變化時,這個索引表的內容不會同步改變,所以當索引指針往后移動的時候就找不到要迭代的對象,所以按照 fail-fast 原則 Iterator 會馬上拋出 java.util.ConcurrentModificationException 異常。
所以 Iterator 在工作的時候是不允許被迭代的對象被改變的。但你可以使用 Iterator 本身的方法 remove() 來刪除對象, Iterator.remove() 方法會在刪除當前迭代對象的同時維護索引的一致性。
廖雪峰 大師 Java源碼分析:深入探討Iterator模式
http://gceclub.sun.com.cn/yuanchuang/week-14/iterator.html
在工作碰到這個問題所有看看:
List list = ...;
for(Iterator iter = list.iterator(); iter.hasNext();) {
Object obj = iter.next();
...
if(***) {
list.remove(obj); //list.add(obj) 其實也是一樣的。
}
}
在執行了remove方法之后,再去執行循環,iter.next()的時候,報java.util.ConcurrentModificationException(當然,如果remove的是最后一條,就不會再去執行next()操作了),
下面來看一下源碼
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
public interface Collection<E> extends Iterable<E> {
...
Iterator<E> iterator();
boolean add(E o);
boolean remove(Object o);
...
}
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
//AbstractCollection和List都繼承了Collection
protected transient int modCount = 0;
private class Itr implements Iterator<E> { //內部類Itr
int cursor = 0;
int lastRet = -1;
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size();
}
public E next() {
checkForComodification(); //該方法中檢測到改變,從而拋出異常
try {
E next = get(cursor);
lastRet = cursor++;
return next;
} catch(IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public void remove() {
if (lastRet == -1)
throw new IllegalStateException();
checkForComodification();
try {
AbstractList.this.remove(lastRet); //執行remove對象的操作
if (lastRet < cursor)
cursor--;
lastRet = -1;
expectedModCount = modCount; //重新設置了expectedModCount的值,避免了ConcurrentModificationException的產生
} catch(IndexOutOfBoundsException e) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount) //當expectedModCount和modCount不相等時,就拋出ConcurrentModificationException
throw new ConcurrentModificationException();
}
}
}
remove(Object o)在ArrayList中實現如下:
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++; //只增加了modCount
....
}
所以,產生ConcurrentModificationException的原因就是:
執行remove(Object o)方法之后,modCount和expectedModCount不相等了。然后當代碼執行到next()方法時,判斷了checkForComodification(),發現兩個數值不等,就拋出了該Exception。
要避免這個Exception,就應該使用remove()方法,但是沒有add()方法了,只能另建一個list來處理這個問題了。

