|
|
置頂隨筆
2019年4月29日
謹以此文慶祝清華建校108周年,及5字班本科畢業(yè)20周年 作者: Canonical 眾所周知,計算機科學得以存在的基石是兩個基本理論:圖靈于1936年提出的圖靈機理論和丘奇同年早期發(fā)表的Lambda演算理論。這兩個理論奠定了所謂通用計算(Universal Computation)的概念基礎,描繪了具有相同計算能力(圖靈完備),但形式上卻南轅北轍、大相徑庭的兩條技術路線。如果把這兩種理論看作是上帝所展示的世界本源面貌的兩個極端,那么是否存在一條更加中庸靈活的到達通用計算彼岸的中間路徑? 自1936年以來,軟件作為計算機科學的核心應用,一直處在不間斷的概念變革過程中,各類程序語言/系統(tǒng)架構/設計模式/方法論層出不窮,但是究其軟件構造的基本原理,仍然沒有脫出兩個基本理論最初所設定的范圍。如果定義一種新的軟件構造理論,它所引入的新概念本質上能有什么特異之處?能夠解決什么棘手的問題? 本文中筆者提出在圖靈機和lambda演算的基礎上可以很自然的引入一個新的核心概念--可逆性,從而形成一個新的軟件構造理論--可逆計算(Reversible Computation)。可逆計算提供了區(qū)別于目前業(yè)內主流方法的更高層次的抽象手段,可以大幅降低軟件內在的復雜性,為粗粒度軟件復用掃除了理論障礙。 可逆計算的思想來源不是計算機科學本身,而是理論物理學,它將軟件看作是處于不斷演化過程中的抽象實體, 在不同的復雜性層次上由不同的運算規(guī)則所描述,它所關注的是演化過程中產生的微小差量如何在系統(tǒng)內有序的傳播并發(fā)生相互作用。 本文第一節(jié)將介紹可逆計算理論的基本原理與核心公式,第二節(jié)分析可逆計算理論與組件和模型驅動等傳統(tǒng)軟件構造理論的區(qū)別和聯(lián)系,并介紹可逆計算理論在軟件復用領域的應用,第三節(jié)從可逆計算角度解構Docker、React等創(chuàng)新技術實踐。 一. 可逆計算的基本原理可逆計算可以看作是在真實的信息有限的世界中,應用圖靈計算和lambda演算對世界建模的一種必然結果,我們可以通過以下簡單的物理圖像來理解這一點。 首先,圖靈機是一種結構固化的機器,它具有可枚舉的有限的狀態(tài)集合,只能執(zhí)行有限的幾條操作指令,但是可以從無限長的紙帶上讀取和保存數(shù)據(jù)。例如我們日常使用的電腦,它在出廠的時候硬件功能就已經(jīng)確定了,但是通過安裝不同的軟件,傳入不同的數(shù)據(jù)文件,最終它可以自動產生任意復雜的目標輸出。圖靈機的計算過程在形式上可以寫成 
與圖靈機相反的是,lambda演算的核心概念是函數(shù),一個函數(shù)就是一臺小型的計算機器,函數(shù)的復合仍然是函數(shù),也就是說可以通過機器和機器的遞歸組合來產生更加復雜的機器。lambda演算的計算能力與圖靈機等價,這意味著如果允許我們不斷創(chuàng)建更加復雜的機器,即使輸入一個常數(shù)0,我們也可以得到任意復雜的目標輸出。lambda演算的計算過程在形式上可以寫成 
可以看出,以上兩種計算過程都可以被表達為Y=F(X) 這樣一種抽象的形式。如果我們把Y=F(X)理解為一種建模過程,即我們試圖理解輸入的結構以及輸入和輸出之間的映射關系,采用最經(jīng)濟的方式重建輸出,則我們會發(fā)現(xiàn)圖靈機和lambda演算都假定了現(xiàn)實世界中無法滿足的條件。在真實的物理世界中,人類的認知總是有限的,所有的量都需要區(qū)分已知的部分和未知的部分,因此我們需要進行如下分解: 
重新整理一下符號,我們就得到了一個適應范圍更加廣泛的計算模式 
除了函數(shù)運算F(X)之外,這里出現(xiàn)了一個新的結構運算符⊕,它表示兩個元素之間的合成運算,并不是普通數(shù)值意義上的加法,同時引出了一個新的概念:差量△。△的特異之處在于,它必然包含某種負元素,F(xiàn)(X)與△合并在一起之后的結果并不一定是“增加”了輸出,而完全可能是“減少”。 在物理學中,差量△存在的必然性以及△包含逆元這一事實完全是不言而喻的,因為物理學的建模必須要考慮到兩個基本事實: - 世界是“測不準”的,噪聲永遠存在
- 模型的復雜度要和問題內在的復雜度相匹配,它捕獲的是問題內核中穩(wěn)定不變的趨勢及規(guī)律。
例如,對以下的數(shù)據(jù) 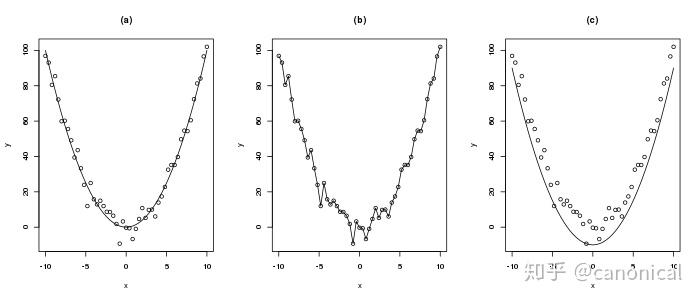 我們所建立的模型只能是類似圖(a)中的簡單曲線,圖(b)中的模型試圖精確擬合每一個數(shù)據(jù)點在數(shù)學上稱之為過擬合,它難以描述新的數(shù)據(jù),而圖(c)中限制差量只能為正值則會極大的限制模型的描述精度。 以上是對Y=F(X)⊕△這一抽象計算模式的一個啟發(fā)式說明,下面我們將介紹在軟件構造領域落實這一計算模式的一種具體技術實現(xiàn)方案,筆者將其命名為可逆計算。 所謂可逆計算,是指系統(tǒng)化的應用如下公式指導軟件構造的一種技術路線 
App : 所需要構建的目標應用程序
DSL: 領域特定語言(Domain Specific Language),針對特定業(yè)務領域定制的業(yè)務邏輯描述語言,也是所謂領域模型的文本表示形式
Generator : 根據(jù)領域模型提供的信息,反復應用生成規(guī)則可以推導產生大量的衍生代碼。實現(xiàn)方式包括獨立的代碼生成工具,以及基于元編程(Metaprogramming)的編譯期模板展開
Biz : 根據(jù)已知模型推導生成的邏輯與目標應用程序邏輯之間的差異被識別出來,并收集在一起,構成獨立的差量描述
aop_extends: 差量描述與模型生成部分通過類似面向切面編程(Aspect Oriented Programming)的技術結合在一起,這其中涉及到對模型生成部分的增加、修改、替換、刪除等一系列操作 DSL是對關鍵性領域信息的一種高密度的表達,它直接指導Generator生成代碼,這一點類似于圖靈計算通過輸入數(shù)據(jù)驅動機器執(zhí)行內置指令。而如果把Generator看作是文本符號的替換生成,則它的執(zhí)行和復合規(guī)則完全就是lambda演算的翻版。差量合并在某種意義上是一種很新奇的操作,因為它要求我們具有一種細致入微、無所不達的變化收集能力,能夠把散布系統(tǒng)各處的同階小量分離出來并合并在一起,這樣差量才具有獨立存在的意義和價值。同時,系統(tǒng)中必須明確建立逆元和逆運算的概念,在這樣的概念體系下差量作為“存在”與“不存在”的混合體才可能得到表達。 現(xiàn)有的軟件基礎架構如果不經(jīng)過徹底的改造,是無法有效的實施可逆計算的。正如圖靈機模型孕育了C語言,Lambda演算促生了Lisp語言一樣,為了有效支持可逆計算,筆者提出了一種新的程序語言X語言,它內置了差量定義、生成、合并、拆分等關鍵特性,可以快速建立領域模型,并在領域模型的基礎上實現(xiàn)可逆計算。 為了實施可逆計算,我們必須要建立差量的概念。變化產生差量,差量有正有負,而且應該滿足下面三條要求: - 差量獨立存在
- 差量相互作用
- 差量具有結構
在第三節(jié)中筆者將會以Docker為實例說明這三條要求的重要性。 可逆計算的核心是“可逆”,這一概念與物理學中熵的概念息息相關,它的重要性其實遠遠超出了程序構造本身,在可逆計算的方法論來源一文中,筆者會對它有更詳細的闡述。 正如復數(shù)的出現(xiàn)擴充了代數(shù)方程的求解空間,可逆計算為現(xiàn)有的軟件構造技術體系補充了“可逆的差量合并”這一關鍵性技術手段,從而極大擴充了軟件復用的可行范圍,使得系統(tǒng)級的粗粒度軟件復用成為可能。同時在新的視角下,很多原先難以解決的模型抽象問題可以找到更加簡單的解決方案,從而大幅降低了軟件構造的內在復雜性。在第二節(jié)中筆者將會對此進行詳細闡述。 軟件開發(fā)雖然號稱是知識密集性的工作,但到目前為止,眾多一線程序員的日常中仍然包含著大量代碼拷貝/粘貼/修改的機械化手工操作內容,而在可逆計算理論中,代碼結構的修改被抽象為可自動執(zhí)行的差量合并規(guī)則,因此通過可逆計算,我們可以為軟件自身的自動化生產創(chuàng)造基礎條件。筆者在可逆計算理論的基礎上,提出了一個新的軟件工業(yè)化生產模式NOP(Nop is nOt Programming),以非編程的方式批量生產軟件。NOP不是編程,但也不是不編程,它強調的是將業(yè)務人員可以直觀理解的邏輯與純技術實現(xiàn)層面的邏輯相分離,分別使用合適的語言和工具去設計,然后再把它們無縫的粘接在一起。筆者將在另一篇文章中對NOP進行詳細介紹。 可逆計算與可逆計算機有著同樣的物理學思想來源,雖然具體的技術內涵并不一致,但它們目標卻是統(tǒng)一的。正如云計算試圖實現(xiàn)計算的云化一樣,可逆計算和可逆計算機試圖實現(xiàn)的都是計算的可逆化。 二. 可逆計算對傳統(tǒng)理論的繼承和發(fā)展軟件的誕生源于數(shù)學家研究希爾伯特第十問題時的副產品,早期軟件的主要用途也是數(shù)學物理計算,那時軟件中的概念無疑是抽象的、數(shù)學化的。隨著軟件的普及,越來越多應用軟件的研發(fā)催生了面向對象和組件化的方法論,它試圖弱化抽象思維,轉而貼近人類的常識,從人們的日常經(jīng)驗中汲取知識,把業(yè)務領域中人們可以直觀感知的概念映射為軟件中的對象,仿照物質世界的生產制造過程從無到有、從小到大,逐步拼接組裝實現(xiàn)最終軟件產品的構造。 像框架、組件、設計模式、架構視圖等軟件開發(fā)領域中耳熟能詳?shù)母拍睿苯觼碜杂诮ㄖI(yè)的生產經(jīng)驗。組件理論繼承了面向對象思想的精華,借助可復用的預制構件這一概念,創(chuàng)造了龐大的第三方組件市場,獲得了空前的技術和商業(yè)成功,即使到今天仍然是最主流的軟件開發(fā)指導思想。但是,組件理論內部存在著一個本質性的缺陷,阻礙了它把自己的成功繼續(xù)推進到一個新的高度。 我們知道,所謂復用就是對已有的制成品的重復使用。為了實現(xiàn)組件復用,我們需要找到兩個軟件中的公共部分,把它分離出來并按照組件規(guī)范整理成標準形式。但是,A和B的公共部分的粒度是比A和B都要小的,大量軟件的公共部分是比它們中任何一個的粒度都要小得多的。這一限制直接導致越大粒度的軟件功能模塊越難以被直接復用,組件復用存在理論上的極限。可以通過組件組裝復用60%-70%的工作量,但是很少有人能超過80%,更不用說實現(xiàn)復用度90%以上的系統(tǒng)級整體復用了。 為了克服組件理論的局限,我們需要重新認識軟件的抽象本質。軟件是在抽象的邏輯世界中存在的一種信息產品,信息并不是物質。抽象世界的構造和生產規(guī)律與物質世界是有著本質不同的。物質產品的生產總是有成本的,而復制軟件的邊際成本卻可以是0。將桌子從房間中移走在物質世界中必須要經(jīng)過門或窗,但在抽象的信息空間中卻只需要將桌子的坐標從x改為-x而已。抽象元素之間的運算關系并不受眾多物理約束的限制,因此信息空間中最有效的生產方式不是組裝,而是掌握和制定運算規(guī)則。 如果從數(shù)學的角度重新去解讀面向對象和組件技術,我們會發(fā)現(xiàn)可逆計算可以被看作是組件理論的一個自然擴展。 - 面向對象 : 不等式 A > B
- 組件 : 加法 A = B + C
- 可逆計算 : 差量 Y = X + △Y
面向對象中的一個核心概念是繼承:派生類從基類繼承,自動具有基類的一切功能。例如老虎是動物的一種派生類,在數(shù)學上,我們可以說老虎(A)這個概念所包含的內容比動物(B)這個概念更多,老虎>動物(即A>B)。據(jù)此我們可以知道,動物這個概念所滿足的命題,老虎自然滿足, 例如動物會奔跑,老虎必然也會奔跑( P(B) -> P(A) )。程序中所有用到動物這一概念的地方都可以被替換為老虎(Liscov代換原則)。這樣通過繼承就將自動推理關系引入到軟件領域中來,在數(shù)學上這對應于不等式,也就是一種偏序關系。 面向對象的理論困境在于不等式的表達能力有限。對于不等式A > B,我們知道A比B多,但是具體多什么,我們并沒有辦法明確的表達出來。而對于 A > B, D > E這樣的情況,即使多出來的部分一模一樣,我們也無法實現(xiàn)這部分內容的重用。組件技術明確指出"組合優(yōu)于繼承",這相當于引入了加法 
這樣就可以抽象出組件C進行重用。 沿著上述方向推演下去,我們很容易確定下一步的發(fā)展是引入“減法”,這樣才可以把 A = B + C看作是一個真正的方程,通過方程左右移項求解出 
通過減法引入的“負組件”是一個全新的概念,它為軟件復用打開了一扇新的大門。 假設我們已經(jīng)構建好了系統(tǒng) X = D + E + F, 現(xiàn)在需要構建 Y = D + E + G。如果遵循組件的解決方案,則需要將X拆解為多個組件,然后更換組件F為G后重新組裝。而如果遵循可逆計算的技術路線,通過引入逆元 -F, 我們立刻得到 
在不拆解X的情況下,通過直接追加一個差量△Y,即可將系統(tǒng)X轉化為系統(tǒng)Y。 組件的復用條件是“相同方可復用”,但在存在逆元的情況下,具有最大顆粒度的完整系統(tǒng)X在完全不改的情況下直接就可以被復用,軟件復用的范圍被拓展為“相關即可復用”,軟件復用的粒度不再有任何限制。組件之間的關系也發(fā)生了深刻的變化,不再是單調的構成關系,而成為更加豐富多變的轉化關系。 Y = X + △Y 這一物理圖像對于復雜軟件產品的研發(fā)具有非常現(xiàn)實的意義。X可以是我們所研發(fā)的軟件產品的基礎版本或者說主版本,在不同的客戶處部署實施時,大量的定制化需求被隔離到獨立的差量△Y中,這些定制的差量描述單獨存放,通過編譯技術與主版本代碼再合并到一起。主版本的架構設計和代碼實現(xiàn)只需要考慮業(yè)務領域內穩(wěn)定的核心需求,不會受到特定客戶處偶然性需求的沖擊,從而有效的避免架構腐化。主版本研發(fā)和多個項目的實施可以并行進行,不同的實施版本對應不同的△Y,互不影響,同時主版本的代碼與所有定制代碼相互獨立,能夠隨時進行整體升級。 模型驅動架構(MDA)是由對象管理組織(Object Management Group,OMG)在2001年提出的軟件架構設計和開發(fā)方法,它被看作是軟件開發(fā)模式從以代碼為中心向以模型為中心轉變的里程碑,目前大部分所謂軟件開發(fā)平臺的理論基礎都與MDA有關。 MDA試圖提升軟件開發(fā)的抽象層次,直接使用建模語言(例如Executable UML)作為編程語言,然后通過使用類似編譯器的技術將高層模型翻譯為底層的可執(zhí)行代碼。在MDA中,明確區(qū)分應用架構和系統(tǒng)架構,并分別用平臺無關模型PIM(Platform Independent Model)和平臺相關模型PSM(Platform Specific Model)來描述它們。PIM反映了應用系統(tǒng)的功能模型,它獨立于具體的實現(xiàn)技術和運行框架,而PSM則關注于使用特定技術(例如J2EE或者dotNet)實現(xiàn)PIM所描述的功能,為PIM提供運行環(huán)境。 使用MDA的理想場景是,開發(fā)人員使用可視化工具設計PIM,然后選擇目標運行平臺,由工具自動執(zhí)行針對特定平臺和實現(xiàn)語言的映射規(guī)則,將PIM轉換為對應的PSM,并最終生成可執(zhí)行的應用程序代碼。基于MDA的程序構造可以表述為如下公式 
MDA的愿景是像C語言取代匯編那樣最終徹底消滅傳統(tǒng)編程語言。但經(jīng)歷了這么多年發(fā)展之后,它仍未能夠在廣泛的應用領域中展現(xiàn)出相對于傳統(tǒng)編程壓倒性的競爭優(yōu)勢。 事實上,目前基于MDA的開發(fā)工具在面對多變的業(yè)務領域時,總是難掩其內在的不適應性。根據(jù)本文第一節(jié)的分析,我們知道建模必須要考慮差量。而在MDA的構造公式中,左側的App代表了各種未知需求,而右側的Transformer和PIM的設計器實際上都主要由開發(fā)工具廠商提供,未知=已知這樣一個方程是無法持久保持平衡的。 目前,工具廠商的主要做法是提供大而全的模型集合,試圖事先預測用戶所有可能的業(yè)務場景。但是,我們知道“天下沒有免費的午餐”,模型的價值在于體現(xiàn)了業(yè)務領域中的本質性約束,沒有任何一個模型是所有場景下都最優(yōu)的。預測需求會導致出現(xiàn)一種悖論: 模型內置假定過少,則無法根據(jù)用戶輸入的少量信息自動生成大量有用的工作,也無法防止用戶出現(xiàn)誤操作,模型的價值不明顯,而如果反之,模型假定很多,則它就會固化到某個特定業(yè)務場景,難以適應新的情況。 打開一個MDA工具的設計器,我們最經(jīng)常的感受是大部分選項都不需要,也不知道是干什么用的,需要的選項卻到處找也找不到。 可逆計算對MDA的擴展體現(xiàn)為兩點: - 可逆計算中Generator和DSL都是鼓勵用戶擴充和調整的,這一點類似于面向語言編程(Language-oriented programming)。
- 存在一個額外的差量定制機會,可以對整體生成結果進行精確的局部修正。
在筆者提出的NOP生產模式中,必須要包含一個新的關鍵組件:設計器的設計器。普通的程序員可以利用設計器的設計器快速設計開發(fā)自己的領域特定語言(DSL)及其可視化設計器,同時可以通過設計器的設計器對系統(tǒng)中的任意設計器進行定制調整,自由的增加或者刪除元素。 面向切面(AOP)是與面向對象(OOP)互補的一種編程范式,它可以實現(xiàn)對那些橫跨多個對象的所謂橫切關注點(cross-cutting concern)的封裝。例如,需求規(guī)格中可能規(guī)定所有的業(yè)務操作都要記錄日志,所有的數(shù)據(jù)庫修改操作都要開啟事務。如果按照面向對象的傳統(tǒng)實現(xiàn)方式,需求中的一句話將會導致眾多對象類中陡然膨脹出現(xiàn)大量的冗余代碼,而通過AOP, 這些公共的“修飾性”的操作就可以被剝離到獨立的切面描述中。這就是所謂縱向分解和橫向分解的正交性。 
AOP本質上是兩個能力的組合: - 在程序結構空間中定位到目標切點(Pointcut)
- 對局部程序結構進行修改,將擴展邏輯(Advice)編織(Weave)到指定位置。
定位依賴于存在良好定義的整體結構坐標系(沒有坐標怎么定位?),而修改依賴于存在良好定義的局部程序語義結構。目前主流的AOP技術的局限性在于,它們都是在面向對象的語境下表達的,而領域結構與對象實現(xiàn)結構并不總是一致的,或者說用對象體系的坐標去表達領域語義是不充分的。例如,申請人和審批人在領域模型中是需要明確區(qū)分的不同的概念,但是在對象層面卻可能都對應于同樣的Person類,使用AOP的很多時候并不能直接將領域描述轉換為切點定義和Advice實現(xiàn)。這種限制反映到應用層面,結果就是除了日志、事務、延遲加載、緩存等少數(shù)與特定業(yè)務領域無關的“經(jīng)典”應用之外,我們找不到AOP的用武之地。 可逆計算需要類似AOP的定位和結構修正能力,但是它是在領域模型空間中定義這些能力的,因而大大擴充了AOP的應用范圍。特別是,可逆計算中領域模型自我演化產生的結構差量△能夠以類似AOP切面的形式得到表達。 我們知道,組件可以標識出程序中反復出現(xiàn)的“相同性”,而可逆計算可以捕獲程序結構的“相似性”。相同很罕見,需要敏銳的甄別,但是在任何系統(tǒng)中,有一種相似性都是唾手可得的,即動力學演化過程中系統(tǒng)與自身歷史快照之間的相似性。這種相似性在此前的技術體系中并沒有專門的技術表達形式。 通過縱向和橫向分解,我們所建立的概念之網(wǎng)存在于一個設計平面當中,當設計平面沿著時間軸演化時,很自然的會產生一個“三維”映射關系:后一時刻的設計平面可以看作是從前一時刻的平面增加一個差量映射(定制)而得到,而差量是定義在平面的每一個點上的。這一圖像類似于范疇論(Category Theory)中的函子(Functor)概念,可逆計算中的差量合并扮演了函子映射的角色。因此,可逆計算相當于擴展了原有的設計空間,為演化這一概念找到了具體的一種技術表現(xiàn)形式。 軟件產品線理論源于一個洞察,即在一個業(yè)務領域中,很少有軟件系統(tǒng)是完全獨特的,大量的軟件產品之間存在著形式和功能的相似性,可以歸結為一個產品家族,把一個產品家族中的所有產品(已存在的和尚未存在的)作為一個整體來研究、開發(fā)、演進,通過科學的方法提取它們的共性,結合有效的可變性管理,就有可能實現(xiàn)規(guī)模化、系統(tǒng)化的軟件復用,進而實現(xiàn)軟件產品的工業(yè)化生產。 軟件產品線工程采用兩階段生命周期模型,區(qū)分領域工程和應用工程。所謂領域工程,是指分析業(yè)務領域內軟件產品的共性,建立領域模型及公共的軟件產品線架構,形成可復用的核心資產的過程,即面向復用的開發(fā)(development for reuse)。而應用工程,其實質是使用復用來開發(fā)( development with reuse),也就是利用已經(jīng)存在的體系架構、需求、測試、文檔等核心資產來制造具體應用產品的生產活動。 卡耐基梅隆大學軟件工程研究所(CMU-SEI)的研究人員在2008年的報告中宣稱軟件產品線可以帶來如下好處: - 提升10倍以上生產率
- 提升10倍以上產品質量
- 縮減60%以上成本
- 縮減87%以上人力需求
- 縮減98%以上產品上市時間
- 進入新市場的時間以月計,而不是年
軟件產品線描繪的理想非常美好:復用度90%以上的產品級復用、隨需而變的敏捷定制、無視技術變遷影響的領域架構、優(yōu)異可觀的經(jīng)濟效益等等。它所存在的唯一問題就是如何才能做到?盡管軟件產品線工程試圖通過綜合利用所有管理的和技術的手段,在組織級別策略性的復用一切技術資產(包括文檔、代碼、規(guī)范、工具等等),但在目前主流的技術體制下,發(fā)展成功的軟件產品線仍然面臨著重重困難。 可逆計算的理念與軟件產品線理論高度契合,它的技術方案為軟件產品線的核心技術困難---可變性管理帶來了新的解決思路。在軟件產品線工程中,傳統(tǒng)的可變性管理主要是適配、替換和擴展這三種方式: 
這三種方式都可以看作是向核心架構補充功能。但是可復用性的障礙不僅僅是來自于無法追加新的功能,很多時候也在于無法屏蔽原先已經(jīng)存在的功能。傳統(tǒng)的適配技術等要求接口一致匹配,是一種剛性的對接要求,一旦失配必將導致不斷向上傳導應力,最終只能通過整體更換組件來解決問題。可逆計算通過差量合并為可變性管理補充了“消除”這一關鍵性機制,可以按需在領域模型空間中構建出柔性適配接口,從而有效的控制變化點影響范圍。 可逆計算中的差量雖然也可以被解釋為對基礎模型的一種擴展,但是它與插件擴展技術之間還是存在著明顯的區(qū)別。在平臺-插件這樣的結構中,平臺是最核心的主體,插件依附于平臺而存在,更像是一種補丁機制,在概念層面上是相對次要的部分。而在可逆計算中,通過一些形式上的變換,我們可以得到一個對稱性更高的公式: 
如果把G看作是一種相對不變的背景知識,則形式上我們可以把它隱藏起來,定義一個更加高級的“括號”運算符,它類似于數(shù)學中的“內積”。在這種形式下,B和D是對偶的,B是對D的補充,而D也是對B的補充。同時,我們注意到G(D)是模型驅動架構的體現(xiàn),模型驅動之所以有價值就在于模型D中發(fā)生的微小變化,可以被G放大為系統(tǒng)各處大量衍生的變化,因此G(D)是一種非線性變換,而B是系統(tǒng)中去除D所對應的非線性因素之后剩余的部分。當所有復雜的非線性影響因素都被剝離出去之后,最后剩下的部分B就有可能是簡單的,甚至能夠形成一種新的可獨立理解的領域模型結構(可以類比聲波與空氣的關系,聲波是空氣的擾動,但是不用研究空氣本體,我們就可以直接用正弦波模型來描述聲波)。 A = (B,D)的形式可以直接推廣到存在更多領域模型的情況 
因為B、D、E等概念都是某種DSL所描述的領域模型,因此它們可以被解釋為A投影到特定領域模型子空間所產生的分量,也就是說,應用A可以被表示為一個“特征向量”(Feature Vector), 例如 
與軟件產品線中常用的面向特征編程(Feature Oriented Programming)相比,可逆計算的特征分解方案強調領域特定描述,特征邊界更加明確,特征合成時產生的概念沖突更容易處理。 特征向量本身構成更高維度的領域模型,它可以被進一步分解下去,從而形成一個模型級列,例如定義 ![D' \equiv [B,D]\ G'(D')\equiv B\oplus G(D)\\](https://www.zhihu.com/equation?tex=D%27+%5Cequiv+%5BB%EF%BC%8CD%5D%5C+G%27%28D%27%29%5Cequiv+B%5Coplus+G%28D%29%5C%5C)
, 并且假設D'可以繼續(xù)分解 
,則可以得到 ![\begin{align} A &= B ⊕ G(D) \\ &= G'(D') \\ &= G'(M'(U'))\\ &= G'(M'([V,U])) \\ \end{align} \\](https://www.zhihu.com/equation?tex=%5Cbegin%7Balign%7D+A+%26%3D+B+%E2%8A%95+G%28D%29+%5C%5C+++%26%3D+G%27%28D%27%29+%5C%5C++%26%3D+G%27%28M%27%28U%27%29%29%5C%5C++%26%3D+G%27%28M%27%28%5BV%2CU%5D%29%29+%5C%5C++%5Cend%7Balign%7D+%5C%5C)
最終我們可以通過領域特征向量U'來描述D’,然后再通過領域特征向量D‘來描述原有的模型A。 可逆計算的這一構造策略類似于深度神經(jīng)網(wǎng)絡,它不再局限于具有極多可調參數(shù)的單一模型,而是建立抽象層級不同、復雜性層級不同的一系列模型,通過逐步求精的方式構造出最終的應用。 在可逆計算的視角下,應用工程的工作內容變成了使用特征向量來描述軟件需求,而領域工程則負責根據(jù)特征向量描述來生成最終的軟件。 三. 初露端倪的差量革命(一)DockerDocker是2013年由創(chuàng)業(yè)公司dotCloud開源的應用容器引擎,它可以將任何應用及其依賴的環(huán)境打包成一個輕量級、可移植、自包含的容器(Container),并據(jù)此以容器為標準化單元創(chuàng)造了一種新型的軟件開發(fā)、部署和交付形式。 Docker一出世就秒殺了Google的親兒子lmctfy (Let Me Contain That For You)容器技術,同時也把Google的另一個親兒子Go語言迅速捧成了網(wǎng)紅,之后Docker的發(fā)展 更是一發(fā)而不可收拾。2014年開始一場Docker風暴席卷全球,以前所未有的力度推動了操作系統(tǒng)內核的變革,在眾多巨頭的跟風造勢下瞬間引爆容器云市場,真正從根本上改變了企業(yè)應用從開發(fā)、構建到部署、運行整個生命周期的技術形態(tài)。  Docker技術的成功源于它對軟件運行時復雜性的本質性降低,而它的技術方案可以看作是可逆計算理論的一種特例。Docker的核心技術模式可以用如下公式進行概括 
Dockerfile是構建容器鏡像的一種領域特定語言,例如 FROM ubuntu:16.04
RUN useradd --user-group --create-home --shell /bin/bash work
RUN apt-get update -y && apt-get install -y python3-dev
COPY . /app RUN make /app
ENV PYTHONPATH /FrameworkBenchmarks
CMD python /app/app.py
EXPOSE 8088
通過Dockerfile可以快速準確的描述容器所依賴的基礎鏡像,具體的構建步驟,運行時環(huán)境變量和系統(tǒng)配置等信息。 Docker應用程序扮演了可逆計算中Generator的角色,負責解釋Dockerfile,執(zhí)行對應的指令來生成容器鏡像。 創(chuàng)造性的使用聯(lián)合文件系統(tǒng)(Union FS),是Docker的一個特別的創(chuàng)新之處。這種文件系統(tǒng)采用分層的構造方式,每一層構建完畢后就不會再發(fā)生改變,在后一層上進行的任何修改都只會記錄在自己這一層。例如,修改前一層的文件時會通過Copy-On-Write的方式復制一份到當前層,而刪除前一層的文件并不會真的執(zhí)行刪除操作,而是僅在當前層標記該文件已刪除。Docker利用聯(lián)合文件系統(tǒng)來實現(xiàn)將多個容器鏡像合成為一個完整的應用,這一技術的本質正是可逆計算中的aop_extends操作。 Docker的英文是碼頭搬運工人的意思,它所搬運的容器也經(jīng)常被人拿來和集裝箱做對比:標準的容器和集裝箱類似,使得我們可以自由的對它們進行傳輸/組合,而不用考慮容器中的具體內容。但是這種比較是膚淺的,甚至是誤導性的。集裝箱是靜態(tài)的、簡單的、沒有對外接口的,而容器則是動態(tài)的、復雜的、和外部存在著大量信息交互的。這種動態(tài)的復雜結構想和普通的靜態(tài)物件一樣封裝成所謂標準容器,其難度不可同日而語。如果沒有引入支持差量的文件系統(tǒng),是無法構建出一種柔性邊界,實現(xiàn)邏輯分離的。 Docker所做的標準封裝其實虛擬機也能做到,甚至差量存儲機制在虛擬機中也早早的被用于實現(xiàn)增量備份,Docker與虛擬機的本質性不同到底在什么地方?回顧第一節(jié)中可逆計算對差量三個基本要求,我們可以清晰的發(fā)現(xiàn)Docker的獨特之處。 - 差量獨立存在:Docker最重要的價值就在于通過容器封裝,拋棄了作為背景存在(必不可少,但一般情況下不需要了解),占據(jù)了99%的體積和復雜度的操作系統(tǒng)層。應用容器成為了可以獨立存儲、獨立操作的第一性的實體。輕裝上陣的容器在性能、資源占用、可管理性等方面完全超越了虛胖的虛擬機。
- 差量相互作用:Docker容器之間通過精確受控的方式發(fā)生相互作用,可通過操作系統(tǒng)的namespace機制選擇性的實現(xiàn)資源隔離或者共享。而虛擬機的差量切片之間是沒有任何隔離機制的。
- 差量具有結構:虛擬機雖然支持增量備份,但是人們卻沒有合適的手段去主動構造一個指定的差量切片出來。歸根結底,是因為虛擬機的差量定義在二進制字節(jié)空間中,而這個空間非常貧瘠,幾乎沒有什么用戶可以控制的構造模式。而Docker的差量是定義在差量文件系統(tǒng)空間中,這個空間繼承了Linux社區(qū)最豐富的歷史資源。每一條shell指令的執(zhí)行結果最終反映到文件系統(tǒng)中都是增加/刪除/修改了某些文件,所以每一條shell指令都可以被看作是某個差量的定義。差量構成了一個異常豐富的結構空間,差量既是這個空間中的變換算符(shell指令),又是變換算符的運算結果。差量與差量相遇產生新的差量,這種生生不息才是Docker的生命力所在。
(二)React2013年,也就是Docker發(fā)布的同一年,F(xiàn)acebook公司開源了一個革命性的Web前端框架React。React的技術思想非常獨特,它以函數(shù)式編程思想為基礎,結合一個看似異想天開的虛擬DOM(Virtual DOM)概念,引入了一整套新的設計模式,開啟了前端開發(fā)的新大航海時代。 class HelloMessage extends React.Component {
constructor(props) {
super(props);
this.state = { count: 0 };
this.action = this.action.bind(this);
}
action(){
this.setState(state => ({
count: state.count + 1
}));
},
render() {
return (
<button onClick={this.action}>
Hello {this.props.name}:{this.state.count}
</button>
);
}
}
ReactDOM.render(
<HelloMessage name="Taylor" />,
mountNode
);
React組件的核心是render函數(shù),它的設計參考了后端常見的模板渲染技術,主要區(qū)別在于后端模板輸出的是HTML文本,而React組件的Render函數(shù)使用類似XML模板的JSX語法,通過編譯轉換在運行時輸出的是虛擬DOM節(jié)點對象。例如上面HelloMessage組件的render函數(shù)被翻譯后的結果類似于 render(){
return new VNode("button", {onClick: this.action,
content: "Hello "+ this.props.name + ":" + this.state.count });
} 可以用以下公式來描述React組件: VDom = render(state) 當狀態(tài)發(fā)生變化以后,只要重新執(zhí)行render函數(shù)就會生成新的虛擬DOM節(jié)點,虛擬DOM節(jié)點可以被翻譯成真實的HTML DOM對象,從而實現(xiàn)界面更新。這種根據(jù)狀態(tài)重新生成完整視圖的渲染策略極大簡化了前端界面開發(fā)。例如對于一個列表界面,傳統(tǒng)編程需要編寫新增行/更新行/刪除行等多個不同的DOM操作函數(shù),而在React中只要更改state后重新執(zhí)行唯一的render函數(shù)即可。 每次重新生成DOM視圖的唯一問題是性能很低,特別是當前端交互操作眾多、狀態(tài)變化頻繁的時候。React的神來之筆是提出了基于虛擬DOM的diff算法,可以自動的計算兩個虛擬DOM樹之間的差量,狀態(tài)變化時只要執(zhí)行虛擬Dom差量對應的DOM修改操作即可(更新真實DOM時會觸發(fā)樣式計算和布局計算,導致性能很低,而在JavaScript中操作虛擬DOM 的速度是非常快的)。整體策略可以表示為如下公式 
顯然,這一策略也是可逆計算的一種特例。 只要稍微留意一下就會發(fā)現(xiàn),最近幾年merge/diff/residual/delta等表達差量運算的概念越來越多的出現(xiàn)在軟件設計領域中。比如大數(shù)據(jù)領域的流計算引擎中,流與表之間的關系可以表示為 
對表的增刪改查操作可以被編碼為事件流,而將表示數(shù)據(jù)變化的事件累積到一起就形成了數(shù)據(jù)表。 現(xiàn)代科學發(fā)端于微積分的發(fā)明,而微分的本質就是自動計算無窮小差量,而積分則是微分的逆運算,自動對無窮小量進行匯總合并。19世紀70年代,經(jīng)濟學經(jīng)歷了一場邊際革命,將微積分的思想引入經(jīng)濟分析,在邊際這一概念之上重建了整個經(jīng)濟學大廈。軟件構造理論發(fā)展到今天,已經(jīng)進入一個瓶頸,也到了應該重新認識差量的時候。 四. 結語筆者的專業(yè)背景是理論物理學,可逆計算源于筆者將物理學和數(shù)學的思想引入軟件領域的一種嘗試,它最早由筆者在2007年左右提出。一直以來,軟件領域對于自然規(guī)律的應用一般情況下都只限于"模擬"范疇,例如流體動力學模擬軟件,雖然它內置了人類所認知的最深刻的一些世界規(guī)律,但這些規(guī)律并沒有被用于指導和定義軟件世界自身的構造和演化,它們的指向范圍是軟件世界之外,而不是軟件世界自身。在筆者看來,在軟件世界中,我們完全可以站在“上帝的視角”,規(guī)劃和定義一系列的結構構造規(guī)律,輔助我們完成軟件世界的構建。而為了完成這一點,我們首先需要建立程序世界中的“微積分”。 類似于微積分,可逆計算理論的核心是將“差量”提升為第一性的概念,將全量看作是差量的一種特例(全量=單位元+全量)。傳統(tǒng)的程序世界中我們所表達的都只是“有”,而且是“所有”,差量只能通過全量之間的運算間接得到,它的表述和操縱都需要特殊處理,而基于可逆計算理論,我們首先應該定義所有差量概念的表達形式,然后再圍繞這些概念去建立整個領域概念體系。為了保證差量所在數(shù)學空間的完備性(差量之間的運算結果仍然需要是合法的差量),差量所表達的不能僅僅是“有”,而必須是“有”和“沒有”的一種混合體。也就是說差量必須是“可逆的”。可逆性具有非常深刻的物理學內涵,在基本的概念體系中內置這一概念可以解決很多非常棘手的軟件構造問題。 為了處理分布式問題,現(xiàn)代軟件開發(fā)體系已經(jīng)接受了不可變數(shù)據(jù)的概念,而為了解決大粒度軟件復用問題,我們還需要接受不可變邏輯的概念(復用可以看作是保持原有邏輯不變,然后增加差量描述)。目前,業(yè)內已經(jīng)逐步出現(xiàn)了一些富有創(chuàng)造性的主動應用差量概念的實踐,它們都可以在可逆計算的理論框架下得到統(tǒng)一的詮釋。筆者提出了一種新的程序語言X語言,它可以極大簡化可逆計算的技術實現(xiàn)。目前筆者已經(jīng)基于X語言設計并實現(xiàn)了一系列軟件框架和生產工具,并基于它們提出了一種新的軟件生產范式(NOP)。
2011年12月25日
瀏覽器前端編程的面貌自2005年以來已經(jīng)發(fā)生了深刻的變化,這并不簡單的意味著出現(xiàn)了大量功能豐富的基礎庫,使得我們可以更加方便的編寫業(yè)務代碼,更重要的是我們看待前端技術的觀念發(fā)生了重大轉變,明確意識到了如何以前端特有的方式釋放程序員的生產力。本文將結合jQuery源碼的實現(xiàn)原理,對javascript中涌現(xiàn)出的編程范式和常用技巧作一簡單介紹。
1. AJAX: 狀態(tài)駐留,異步更新
首先來看一點歷史。
A. 1995年Netscape公司的Brendan Eich開發(fā)了javacript語言,這是一種動態(tài)(dynamic)、弱類型(weakly typed)、基于原型(prototype-based)的腳本語言。
B. 1999年微軟IE5發(fā)布,其中包含了XMLHTTP ActiveX控件。
C. 2001年微軟IE6發(fā)布,部分支持DOM level 1和CSS 2標準。
D. 2002年Douglas Crockford發(fā)明JSON格式。
至此,可以說Web2.0所依賴的技術元素已經(jīng)基本成形,但是并沒有立刻在整個業(yè)界產生重大的影響。盡管一些“頁面異步局部刷新”的技巧在程序員中間秘密的流傳,甚至催生了bindows這樣龐大臃腫的類庫,但總的來說,前端被看作是貧瘠而又骯臟的沼澤地,只有后臺技術才是王道。到底還缺少些什么呢?
當我們站在今天的角度去回顧2005年之前的js代碼,包括那些當時的牛人所寫的代碼,可以明顯的感受到它們在程序控制力上的孱弱。并不是說2005年之前的js技術本身存在問題,只是它們在概念層面上是一盤散沙,缺乏統(tǒng)一的觀念,或者說缺少自己獨特的風格, 自己的靈魂。當時大多數(shù)的人,大多數(shù)的技術都試圖在模擬傳統(tǒng)的面向對象語言,利用傳統(tǒng)的面向對象技術,去實現(xiàn)傳統(tǒng)的GUI模型的仿制品。
2005年是變革的一年,也是創(chuàng)造概念的一年。伴隨著Google一系列讓人耳目一新的交互式應用的發(fā)布,Jesse James Garrett的一篇文章《Ajax: A New Approach to Web Applications》被廣為傳播。Ajax這一前端特有的概念迅速將眾多分散的實踐統(tǒng)一在同一口號之下,引發(fā)了Web編程范式的轉換。所謂名不正則言不順,這下無名群眾可找到組織了。在未有Ajax之前,人們早已認識到了B/S架構的本質特征在于瀏覽器和服務器的狀態(tài)空間是分離的,但是一般的解決方案都是隱藏這一區(qū)分,將前臺狀態(tài)同步到后臺,由后臺統(tǒng)一進行邏輯處理,例如ASP.NET。因為缺乏成熟的設計模式支持前臺狀態(tài)駐留,在換頁的時候,已經(jīng)裝載的js對象將被迫被丟棄,這樣誰還能指望它去完成什么復雜的工作嗎?
Ajax明確提出界面是局部刷新的,前臺駐留了狀態(tài),這就促成了一種需要:需要js對象在前臺存在更長的時間。這也就意味著需要將這些對象和功能有效的管理起來,意味著更復雜的代碼組織技術,意味著對模塊化,對公共代碼基的渴求。
jQuery現(xiàn)有的代碼中真正與Ajax相關(使用XMLHTTP控件異步訪問后臺返回數(shù)據(jù))的部分其實很少,但是如果沒有Ajax, jQuery作為公共代碼基也就缺乏存在的理由。
2. 模塊化:管理名字空間
當大量的代碼產生出來以后,我們所需要的最基礎的概念就是模塊化,也就是對工作進行分解和復用。工作得以分解的關鍵在于各人獨立工作的成果可以集成在一起。這意味著各個模塊必須基于一致的底層概念,可以實現(xiàn)交互,也就是說應該基于一套公共代碼基,屏蔽底層瀏覽器的不一致性,并實現(xiàn)統(tǒng)一的抽象層,例如統(tǒng)一的事件管理機制等。比統(tǒng)一代碼基更重要的是,各個模塊之間必須沒有名字沖突。否則,即使兩個模塊之間沒有任何交互,也無法共同工作。
jQuery目前鼓吹的主要賣點之一就是對名字空間的良好控制。這甚至比提供更多更完善的功能點都重要的多。良好的模塊化允許我們復用任何來源的代碼,所有人的工作得以積累疊加。而功能實現(xiàn)僅僅是一時的工作量的問題。jQuery使用module pattern的一個變種來減少對全局名字空間的影響,僅僅在window對象上增加了一個jQuery對象(也就是$函數(shù))。
所謂的module pattern代碼如下,它的關鍵是利用匿名函數(shù)限制臨時變量的作用域。
var feature =(function() {
// 私有變量和函數(shù)
var privateThing = 'secret',
publicThing = 'not secret',
changePrivateThing = function() {
privateThing = 'super secret';
},
sayPrivateThing = function() {
console.log(privateThing);
changePrivateThing();
};
// 返回對外公開的API
return {
publicThing : publicThing,
sayPrivateThing : sayPrivateThing
}
})();
js本身缺乏包結構,不過經(jīng)過多年的嘗試之后業(yè)內已經(jīng)逐漸統(tǒng)一了對包加載的認識,形成了RequireJs庫這樣得到一定共識的解決方案。jQuery可以與RequireJS庫良好的集成在一起, 實現(xiàn)更完善的模塊依賴管理。http://requirejs.org/docs/jquery.html
require(["jquery", "jquery.my"], function() {
//當jquery.js和jquery.my.js都成功裝載之后執(zhí)行
$(function(){
$('#my').myFunc();
});
});
通過以下函數(shù)調用來定義模塊my/shirt, 它依賴于my/cart和my/inventory模塊,
require.def("my/shirt",
["my/cart", "my/inventory"],
function(cart, inventory) {
// 這里使用module pattern來返回my/shirt模塊對外暴露的API
return {
color: "blue",
size: "large"
addToCart: function() {
// decrement是my/inventory對外暴露的API
inventory.decrement(this);
cart.add(this);
}
}
}
);
3. 神奇的$:對象提升
當你第一眼看到$函數(shù)的時候,你想到了什么?傳統(tǒng)的編程理論總是告訴我們函數(shù)命名應該準確,應該清晰無誤的表達作者的意圖,甚至聲稱長名字要優(yōu)于短名字,因為減少了出現(xiàn)歧義的可能性。但是,$是什么?亂碼?它所傳遞的信息實在是太隱晦,太曖昧了。$是由prototype.js庫發(fā)明的,它真的是一個神奇的函數(shù),因為它可以將一個原始的DOM節(jié)點提升(enhance)為一個具有復雜行為的對象。在prototype.js最初的實現(xiàn)中,$函數(shù)的定義為
var $ = function (id) {
return "string" == typeof id ? document.getElementById(id) : id;
};
這基本對應于如下公式
e = $(id)
這絕不僅僅是提供了一個聰明的函數(shù)名稱縮寫,更重要的是在概念層面上建立了文本id與DOM element之間的一一對應。在未有$之前,id與對應的element之間的距離十分遙遠,一般要將element緩存到變量中,例如
var ea = docuement.getElementById('a');
var eb = docuement.getElementById('b');
ea.style....
但是使用$之后,卻隨處可見如下的寫法
$('header_'+id).style...
$('body_'+id)....
id與element之間的距離似乎被消除了,可以非常緊密的交織在一起。
prototype.js后來擴展了$的含義,
function $() {
var elements = new Array();
for (var i = 0; i < arguments.length; i++) {
var element = arguments[i];
if (typeof element == 'string')
element = document.getElementById(element);
if (arguments.length == 1)
return element;
elements.push(element);
}
return elements;
}
這對應于公式
[e,e] = $(id,id)
很遺憾,這一步prototype.js走偏了,這一做法很少有實用的價值。
真正將$發(fā)揚光大的是jQuery, 它的$對應于公式
[o] = $(selector)
這里有三個增強
A. selector不再是單一的節(jié)點定位符,而是復雜的集合選擇符
B. 返回的元素不是原始的DOM節(jié)點,而是經(jīng)過jQuery進一步增強的具有豐富行為的對象,可以啟動復雜的函數(shù)調用鏈。
C. $返回的包裝對象被造型為數(shù)組形式,將集合操作自然的整合到調用鏈中。
當然,以上僅僅是對神奇的$的一個過分簡化的描述,它的實際功能要復雜得多. 特別是有一個非常常用的直接構造功能.
$("<table><tbody><tr><td>...</td></tr></tbody></table>")....
jQuery將根據(jù)傳入的html文本直接構造出一系列的DOM節(jié)點,并將其包裝為jQuery對象. 這在某種程度上可以看作是對selector的擴展: html內容描述本身就是一種唯一指定.
$(function{})這一功能就實在是讓人有些無語了, 它表示當document.ready的時候調用此回調函數(shù)。真的,$是一個神奇的函數(shù), 有任何問題,請$一下。
總結起來, $是從普通的DOM和文本描述世界到具有豐富對象行為的jQuery世界的躍遷通道。跨過了這道門,就來到了理想國。
4. 無定形的參數(shù):專注表達而不是約束
弱類型語言既然頭上頂著個"弱"字, 總難免讓人有些先天不足的感覺. 在程序中缺乏類型約束, 是否真的是一種重大的缺憾? 在傳統(tǒng)的強類型語言中, 函數(shù)參數(shù)的類型,個數(shù)等都是由編譯器負責檢查的約束條件, 但這些約束仍然是遠遠不夠的. 一般應用程序中為了加強約束, 總會增加大量防御性代碼, 例如在C++中我們常用ASSERT, 而在java中也經(jīng)常需要判斷參數(shù)值的范圍
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
很顯然, 這些代碼將導致程序中存在大量無功能的執(zhí)行路徑, 即我們做了大量判斷, 代碼執(zhí)行到某個點, 系統(tǒng)拋出異常, 大喊此路不通. 如果我們換一個思路, 既然已經(jīng)做了某種判斷,能否利用這些判斷的結果來做些什么呢? javascript是一種弱類型的語言,它是無法自動約束參數(shù)類型的, 那如果順勢而行,進一步弱化參數(shù)的形態(tài), 將"弱"推進到一種極致, 在弱無可弱的時候, weak會不會成為標志性的特點?
看一下jQuery中的事件綁定函數(shù)bind,
A. 一次綁定一個事件 $("#my").bind("mouseover", function(){});
B. 一次綁定多個事件 $("#my").bind("mouseover mouseout",function(){})
C. 換一個形式, 同樣綁定多個事件
$("#my").bind({mouseover:function(){}, mouseout:function(){});
D. 想給事件監(jiān)聽器傳點參數(shù)
$('#my').bind('click', {foo: "xxxx"}, function(event) { event.data.foo..})
E. 想給事件監(jiān)聽器分個組
$("#my").bind("click.myGroup″, function(){});
F. 這個函數(shù)為什么還沒有瘋掉???
就算是類型不確定, 在固定位置上的參數(shù)的意義總要是確定的吧? 退一萬步來說, 就算是參數(shù)位置不重要了,函數(shù)本身的意義應該是確定的吧? 但這是什么?
取值 value = o.val(), 設置值 o.val(3)
一個函數(shù)怎么可以這樣過分, 怎么能根據(jù)傳入?yún)?shù)的類型和個數(shù)不同而行為不同呢? 看不順眼是不是? 可這就是俺們的價值觀. 既然不能防止, 那就故意允許. 雖然形式多變, 卻無一句廢話. 缺少約束, 不妨礙表達(我不是出來嚇人的).
5. 鏈式操作: 線性化的逐步細化
jQuery早期最主要的賣點就是所謂的鏈式操作(chain).
$('#content') // 找到content元素
.find('h3') // 選擇所有后代h3節(jié)點
.eq(2) // 過濾集合, 保留第三個元素
.html('改變第三個h3的文本')
.end() // 返回上一級的h3集合
.eq(0)
.html('改變第一個h3的文本');
在一般的命令式語言中, 我們總需要在重重嵌套循環(huán)中過濾數(shù)據(jù), 實際操作數(shù)據(jù)的代碼與定位數(shù)據(jù)的代碼糾纏在一起. 而jQuery采用先構造集合然后再應用函數(shù)于集合的方式實現(xiàn)兩種邏輯的解耦, 實現(xiàn)嵌套結構的線性化. 實際上, 我們并不需要借助過程化的思想就可以很直觀的理解一個集合, 例如 $('div.my input:checked')可以看作是一種直接的描述,而不是對過程行為的跟蹤.
循環(huán)意味著我們的思維處于一種反復回繞的狀態(tài), 而線性化之后則沿著一個方向直線前進, 極大減輕了思維負擔, 提高了代碼的可組合性. 為了減少調用鏈的中斷, jQuery發(fā)明了一個絕妙的主意: jQuery包裝對象本身類似數(shù)組(集合). 集合可以映射到新的集合, 集合可以限制到自己的子集合,調用的發(fā)起者是集合,返回結果也是集合,集合可以發(fā)生結構上的某種變化但它還是集合, 集合是某種概念上的不動點,這是從函數(shù)式語言中吸取的設計思想。集合操作是太常見的操作, 在java中我們很容易發(fā)現(xiàn)大量所謂的封裝函數(shù)其實就是在封裝一些集合遍歷操作, 而在jQuery中集合操作因為太直白而不需要封裝.
鏈式調用意味著我們始終擁有一個“當前”對象,所有的操作都是針對這一當前對象進行。這對應于如下公式
x += dx
調用鏈的每一步都是對當前對象的增量描述,是針對最終目標的逐步細化過程。Witrix平臺中對這一思想也有著廣泛的應用。特別是為了實現(xiàn)平臺機制與業(yè)務代碼的融合,平臺會提供對象(容器)的缺省內容,而業(yè)務代碼可以在此基礎上進行逐步細化的修正,包括取消缺省的設置等。
話說回來, 雖然表面上jQuery的鏈式調用很簡單, 內部實現(xiàn)的時候卻必須自己多寫一層循環(huán), 因為編譯器并不知道"自動應用于集合中每個元素"這回事.
$.fn['someFunc'] = function(){
return this.each(function(){
jQuery.someFunc(this,...);
}
}
6. data: 統(tǒng)一數(shù)據(jù)管理
作為一個js庫,它必須解決的一個大問題就是js對象與DOM節(jié)點之間的狀態(tài)關聯(lián)與協(xié)同管理問題。有些js庫選擇以js對象為主,在js對象的成員變量中保存DOM節(jié)點指針,訪問時總是以js對象為入口點,通過js函數(shù)間接操作DOM對象。在這種封裝下,DOM節(jié)點其實只是作為界面展現(xiàn)的一種底層“匯編”而已。jQuery的選擇與Witrix平臺類似,都是以HTML自身結構為基礎,通過js增強(enhance)DOM節(jié)點的功能,將它提升為一個具有復雜行為的擴展對象。這里的思想是非侵入式設計(non-intrusive)和優(yōu)雅退化機制(graceful degradation)。語義結構在基礎的HTML層面是完整的,js的作用是增強了交互行為,控制了展現(xiàn)形式。
如果每次我們都通過$('#my')的方式來訪問相應的包裝對象,那么一些需要長期保持的狀態(tài)變量保存在什么地方呢?jQuery提供了一個統(tǒng)一的全局數(shù)據(jù)管理機制。
獲取數(shù)據(jù) $('#my').data('myAttr') 設置數(shù)據(jù) $('#my').data('myAttr',3);
這一機制自然融合了對HTML5的data屬性的處理
<input id="my" data-my-attr="4" ... />
通過 $('#my').data('myAttr')將可以讀取到HTML中設置的數(shù)據(jù)。
第一次訪問data時,jQuery將為DOM節(jié)點分配一個唯一的uuid, 然后設置在DOM節(jié)點的一個特定的expando屬性上, jQuery保證這個uuid在本頁面中不重復。
elem.nodeType ? jQuery.cache[ elem[jQuery.expando] ] : elem[ jQuery.expando ];
以上代碼可以同時處理DOM節(jié)點和純js對象的情況。如果是js對象,則data直接放置在js對象自身中,而如果是DOM節(jié)點,則通過cache統(tǒng)一管理。
因為所有的數(shù)據(jù)都是通過data機制統(tǒng)一管理的,特別是包括所有事件監(jiān)聽函數(shù)(data.events),因此jQuery可以安全的實現(xiàn)資源管理。在clone節(jié)點的時候,可以自動clone其相關的事件監(jiān)聽函數(shù)。而當DOM節(jié)點的內容被替換或者DOM節(jié)點被銷毀的時候,jQuery也可以自動解除事件監(jiān)聽函數(shù), 并安全的釋放相關的js數(shù)據(jù)。
7. event:統(tǒng)一事件模型
"事件沿著對象樹傳播"這一圖景是面向對象界面編程模型的精髓所在。對象的復合構成對界面結構的一個穩(wěn)定的描述,事件不斷在對象樹的某個節(jié)點發(fā)生,并通過冒泡機制向上傳播。對象樹很自然的成為一個控制結構,我們可以在父節(jié)點上監(jiān)聽所有子節(jié)點上的事件,而不用明確與每一個子節(jié)點建立關聯(lián)。
jQuery除了為不同瀏覽器的事件模型建立了統(tǒng)一抽象之外,主要做了如下增強:
A. 增加了自定制事件(custom)機制. 事件的傳播機制與事件內容本身原則上是無關的, 因此自定制事件完全可以和瀏覽器內置事件通過同一條處理路徑, 采用同樣的監(jiān)聽方式. 使用自定制事件可以增強代碼的內聚性, 減少代碼耦合. 例如如果沒有自定制事件, 關聯(lián)代碼往往需要直接操作相關的對象
$('.switch, .clapper').click(function() {
var $light = $(this).parent().find('.lightbulb');
if ($light.hasClass('on')) {
$light.removeClass('on').addClass('off');
} else {
$light.removeClass('off').addClass('on');
}
});
而如果使用自定制事件,則表達的語義更加內斂明確,
$('.switch, .clapper').click(function() {
$(this).parent().find('.lightbulb').trigger('changeState');
});
B. 增加了對動態(tài)創(chuàng)建節(jié)點的事件監(jiān)聽. bind函數(shù)只能將監(jiān)聽函數(shù)注冊到已經(jīng)存在的DOM節(jié)點上. 例如
$('li.trigger').bind('click',function(){}}
如果調用bind之后,新建了另一個li節(jié)點,則該節(jié)點的click事件不會被監(jiān)聽.
jQuery的delegate機制可以將監(jiān)聽函數(shù)注冊到父節(jié)點上, 子節(jié)點上觸發(fā)的事件會根據(jù)selector被自動派發(fā)到相應的handlerFn上. 這樣一來現(xiàn)在注冊就可以監(jiān)聽未來創(chuàng)建的節(jié)點.
$('#myList').delegate('li.trigger', 'click', handlerFn);
最近jQuery1.7中統(tǒng)一了bind, live和delegate機制, 天下一統(tǒng), 只有on/off.
$('li.trigger’).on('click', handlerFn); // 相當于bind
$('#myList’).on('click', 'li.trigger', handlerFn); // 相當于delegate
8. 動畫隊列:全局時鐘協(xié)調
拋開jQuery的實現(xiàn)不談, 先考慮一下如果我們要實現(xiàn)界面上的動畫效果, 到底需要做些什么? 比如我們希望將一個div的寬度在1秒鐘之內從100px增加到200px. 很容易想見, 在一段時間內我們需要不時的去調整一下div的寬度, [同時]我們還需要執(zhí)行其他代碼. 與一般的函數(shù)調用不同的是, 發(fā)出動畫指令之后, 我們不能期待立刻得到想要的結果, 而且我們不能原地等待結果的到來. 動畫的復雜性就在于:一次性表達之后要在一段時間內執(zhí)行,而且有多條邏輯上的執(zhí)行路徑要同時展開, 如何協(xié)調?
偉大的艾薩克.牛頓爵士在《自然哲學的數(shù)學原理》中寫道:"絕對的、真正的和數(shù)學的時間自身在流逝著". 所有的事件可以在時間軸上對齊, 這就是它們內在的協(xié)調性. 因此為了從步驟A1執(zhí)行到A5, 同時將步驟B1執(zhí)行到B5, 我們只需要在t1時刻執(zhí)行[A1, B1], 在t2時刻執(zhí)行[A2,B2], 依此類推.
t1 | t2 | t3 | t4 | t5 ...
A1 | A2 | A3 | A4 | A5 ...
B1 | B2 | B3 | B4 | B5 ...
具體的一種實現(xiàn)形式可以是
A. 對每個動畫, 將其分裝為一個Animation對象, 內部分成多個步驟.
animation = new Animation(div,"width",100,200,1000,
負責步驟切分的插值函數(shù),動畫執(zhí)行完畢時的回調函數(shù));
B. 在全局管理器中注冊動畫對象
timerFuncs.add(animation);
C. 在全局時鐘的每一個觸發(fā)時刻, 將每個注冊的執(zhí)行序列推進一步, 如果已經(jīng)結束, 則從全局管理器中刪除.
for each animation in timerFuncs
if(!animation.doOneStep())
timerFuncs.remove(animation)
解決了原理問題,再來看看表達問題, 怎樣設計接口函數(shù)才能夠以最緊湊形式表達我們的意圖? 我們經(jīng)常需要面臨的實際問題:
A. 有多個元素要執(zhí)行類似的動畫
B. 每個元素有多個屬性要同時變化
C. 執(zhí)行完一個動畫之后開始另一個動畫
jQuery對這些問題的解答可以說是榨盡了js語法表達力的最后一點剩余價值.
$('input')
.animate({left:'+=200px',top:'300'},2000)
.animate({left:'-=200px',top:20},1000)
.queue(function(){
// 這里dequeue將首先執(zhí)行隊列中的后一個函數(shù),因此alert("y")
$(this).dequeue();
alert('x');
})
.queue(function(){
alert("y");
// 如果不主動dequeue, 隊列執(zhí)行就中斷了,不會自動繼續(xù)下去.
$(this).dequeue();
});
A. 利用jQuery內置的selector機制自然表達對一個集合的處理.
B. 使用Map表達多個屬性變化
C. 利用微格式表達領域特定的差量概念. '+=200px'表示在現(xiàn)有值的基礎上增加200px
D. 利用函數(shù)調用的順序自動定義animation執(zhí)行的順序: 在后面追加到執(zhí)行隊列中的動畫自然要等前面的動畫完全執(zhí)行完畢之后再啟動.
jQuery動畫隊列的實現(xiàn)細節(jié)大概如下所示,
A. animate函數(shù)實際是調用queue(function(){執(zhí)行結束時需要調用dequeue,否則不會驅動下一個方法})
queue函數(shù)執(zhí)行時, 如果是fx隊列, 并且當前沒有正在運行動畫(如果連續(xù)調用兩次animate,第二次的執(zhí)行函數(shù)將在隊列中等待),則會自動觸發(fā)dequeue操作, 驅動隊列運行.
如果是fx隊列, dequeue的時候會自動在隊列頂端加入"inprogress"字符串,表示將要執(zhí)行的是動畫.
B. 針對每一個屬性,創(chuàng)建一個jQuery.fx對象。然后調用fx.custom函數(shù)(相當于start)來啟動動畫。
C. custom函數(shù)中將fx.step函數(shù)注冊到全局的timerFuncs中,然后試圖啟動一個全局的timer.
timerId = setInterval( fx.tick, fx.interval );
D. 靜態(tài)的tick函數(shù)中將依次調用各個fx的step函數(shù)。step函數(shù)中通過easing計算屬性的當前值,然后調用fx的update來更新屬性。
E. fx的step函數(shù)中判斷如果所有屬性變化都已完成,則調用dequeue來驅動下一個方法。
很有意思的是, jQuery的實現(xiàn)代碼中明顯有很多是接力觸發(fā)代碼: 如果需要執(zhí)行下一個動畫就取出執(zhí)行, 如果需要啟動timer就啟動timer等. 這是因為js程序是單線程的,真正的執(zhí)行路徑只有一條,為了保證執(zhí)行線索不中斷, 函數(shù)們不得不互相幫助一下. 可以想見, 如果程序內部具有多個執(zhí)行引擎, 甚至無限多的執(zhí)行引擎, 那么程序的面貌就會發(fā)生本質性的改變. 而在這種情形下, 遞歸相對于循環(huán)而言會成為更自然的描述.
9. promise模式:因果關系的識別
現(xiàn)實中,總有那么多時間線在獨立的演化著, 人與物在時空中交錯,卻沒有發(fā)生因果. 軟件中, 函數(shù)們在源代碼中排著隊, 難免會產生一些疑問, 憑什么排在前面的要先執(zhí)行? 難道沒有它就沒有我? 讓全宇宙喊著1,2,3齊步前進, 從上帝的角度看,大概是管理難度過大了, 于是便有了相對論. 如果相互之間沒有交換信息, 沒有產生相互依賴, 那么在某個坐標系中順序發(fā)生的事件, 在另外一個坐標系中看來, 就可能是顛倒順序的. 程序員依葫蘆畫瓢, 便發(fā)明了promise模式.
promise與future模式基本上是一回事,我們先來看一下java中熟悉的future模式.
futureResult = doSomething();
...
realResult = futureResult.get();
發(fā)出函數(shù)調用僅僅意味著一件事情發(fā)生過, 并不必然意味著調用者需要了解事情最終的結果. 函數(shù)立刻返回的只是一個將在未來兌現(xiàn)的承諾(Future類型), 實際上也就是某種句柄. 句柄被傳來傳去, 中間轉手的代碼對實際結果是什么,是否已經(jīng)返回漠不關心. 直到一段代碼需要依賴調用返回的結果, 因此它打開future, 查看了一下. 如果實際結果已經(jīng)返回, 則future.get()立刻返回實際結果, 否則將會阻塞當前的執(zhí)行路徑, 直到結果返回為止. 此后再調用future.get()總是立刻返回, 因為因果關系已經(jīng)被建立, [結果返回]這一事件必然在此之前發(fā)生, 不會再發(fā)生變化.
future模式一般是外部對象主動查看future的返回值, 而promise模式則是由外部對象在promise上注冊回調函數(shù).
function getData(){
return $.get('/foo/').done(function(){
console.log('Fires after the AJAX request succeeds');
}).fail(function(){
console.log('Fires after the AJAX request fails');
});
}
function showDiv(){
var dfd = $.Deferred();
$('#foo').fadeIn( 1000, dfd.resolve );
return dfd.promise();
}
$.when( getData(), showDiv() )
.then(function( ajaxResult, ignoreResultFromShowDiv ){
console.log('Fires after BOTH showDiv() AND the AJAX request succeed!');
// 'ajaxResult' is the server’s response
});
jQuery引入Deferred結構, 根據(jù)promise模式對ajax, queue, document.ready等進行了重構, 統(tǒng)一了異步執(zhí)行機制. then(onDone, onFail)將向promise中追加回調函數(shù), 如果調用成功完成(resolve), 則回調函數(shù)onDone將被執(zhí)行, 而如果調用失敗(reject), 則onFail將被執(zhí)行. when可以等待在多個promise對象上. promise巧妙的地方是異步執(zhí)行已經(jīng)開始之后甚至已經(jīng)結束之后,仍然可以注冊回調函數(shù)
someObj.done(callback).sendRequest() vs. someObj.sendRequest().done(callback)
callback函數(shù)在發(fā)出異步調用之前注冊或者在發(fā)出異步調用之后注冊是完全等價的, 這揭示出程序表達永遠不是完全精確的, 總存在著內在的變化維度. 如果能有效利用這一內在的可變性, 則可以極大提升并發(fā)程序的性能.
promise模式的具體實現(xiàn)很簡單. jQuery._Deferred定義了一個函數(shù)隊列,它的作用有以下幾點:
A. 保存回調函數(shù)。
B. 在resolve或者reject的時刻把保存著的函數(shù)全部執(zhí)行掉。
C. 已經(jīng)執(zhí)行之后, 再增加的函數(shù)會被立刻執(zhí)行。
一些專門面向分布式計算或者并行計算的語言會在語言級別內置promise模式, 比如E語言.
def carPromise := carMaker <- produce("Mercedes");
def temperaturePromise := carPromise <- getEngineTemperature()
...
when (temperaturePromise) -> done(temperature) {
println(`The temperature of the car engine is: $temperature`)
} catch e {
println(`Could not get engine temperature, error: $e`)
}
在E語言中, <-是eventually運算符, 表示最終會執(zhí)行, 但不一定是現(xiàn)在. 而普通的car.moveTo(2,3)表示立刻執(zhí)行得到結果. 編譯器負責識別所有的promise依賴, 并自動實現(xiàn)調度.
10. extend: 繼承不是必須的
js是基于原型的語言, 并沒有內置的繼承機制, 這一直讓很多深受傳統(tǒng)面向對象教育的同學們耿耿于懷. 但繼承一定是必須的嗎? 它到底能夠給我們帶來什么? 最純樸的回答是: 代碼重用. 那么, 我們首先來分析一下繼承作為代碼重用手段的潛力.
曾經(jīng)有個概念叫做"多重繼承", 它是繼承概念的超級賽亞人版, 很遺憾后來被診斷為存在著先天缺陷, 以致于出現(xiàn)了一種對于繼承概念的解讀: 繼承就是"is a"關系, 一個派生對象"is a"很多基類, 必然會出現(xiàn)精神分裂, 所以多重繼承是不好的.
class A{ public: void f(){ f in A } }
class B{ public: void f(){ f in B } }
class D: public A, B{}
如果D類從A,B兩個基類繼承, 而A和B類中都實現(xiàn)了同一個函數(shù)f, 那么D類中的f到底是A中的f還是B中的f, 抑或是A中的f+B中的f呢? 這一困境的出現(xiàn)實際上源于D的基類A和B是并列關系, 它們滿足交換律和結合律, 畢竟,在概念層面上我們可能難以認可兩個任意概念之間會出現(xiàn)從屬關系. 但如果我們放松一些概念層面的要求, 更多的從操作層面考慮一下代碼重用問題, 可以簡單的認為B在A的基礎上進行操作, 那么就可以得到一個線性化的結果. 也就是說, 放棄A和B之間的交換律只保留結合律, extends A, B 與 extends B,A 會是兩個不同的結果, 不再存在詮釋上的二義性. scala語言中的所謂trait(特性)機制實際上采用的就是這一策略.
面向對象技術發(fā)明很久之后, 出現(xiàn)了所謂的面向方面編程(AOP), 它與OOP不同, 是代碼結構空間中的定位與修改技術. AOP的眼中只有類與方法, 不知道什么叫做意義. AOP也提供了一種類似多重繼承的代碼重用手段, 那就是mixin. 對象被看作是可以被打開,然后任意修改的Map, 一組成員變量與方法就被直接注射到對象體內, 直接改變了它的行為.
prototype.js庫引入了extend函數(shù),
Object.extend = function(destination, source) {
for (var property in source) {
destination[property] = source[property];
}
return destination;
}
就是Map之間的一個覆蓋運算, 但很管用, 在jQuery庫中也得到了延用. 這個操作類似于mixin, 在jQuery中是代碼重用的主要技術手段---沒有繼承也沒什么大不了的.
11. 名稱映射: 一切都是數(shù)據(jù)
代碼好不好, 循環(huán)判斷必須少. 循環(huán)和判斷語句是程序的基本組成部分, 但是優(yōu)良的代碼庫中卻往往找不到它們的蹤影, 因為這些語句的交織會模糊系統(tǒng)的邏輯主線, 使我們的思想迷失在疲于奔命的代碼追蹤中. jQuery本身通過each, extend等函數(shù)已經(jīng)極大減少了對循環(huán)語句的需求, 對于判斷語句, 則主要是通過映射表來處理. 例如, jQuery的val()函數(shù)需要針對不同標簽進行不同的處理, 因此定義一個以tagName為key的函數(shù)映射表
valHooks: { option: {get:function(){}}}
這樣在程序中就不需要到處寫
if(elm.tagName == 'OPTION'){
return ...;
}else if(elm.tagName == 'TEXTAREA'){
return ...;
}
可以統(tǒng)一處理
(valHooks[elm.tagName.toLowerCase()] || defaultHandler).get(elm);
映射表將函數(shù)作為普通數(shù)據(jù)來管理, 在動態(tài)語言中有著廣泛的應用. 特別是, 對象本身就是函數(shù)和變量的容器, 可以被看作是映射表. jQuery中大量使用的一個技巧就是利用名稱映射來動態(tài)生成代碼, 形成一種類似模板的機制. 例如為了實現(xiàn)myWidth和myHeight兩個非常類似的函數(shù), 我們不需要
jQuery.fn.myWidth = function(){
return parseInt(this.style.width,10) + 10;
}
jQuery.fn.myHeight = function(){
return parseInt(this.style.height,10) + 10;
}
而可以選擇動態(tài)生成
jQuery.each(['Width','Height'],function(name){
jQuery.fn['my'+name] = function(){
return parseInt(this.style[name.toLowerCase()],10) + 10;
}
});
12. 插件機制:其實我很簡單
jQuery所謂的插件其實就是$.fn上增加的函數(shù), 那這個fn是什么東西?
(function(window,undefined){
// 內部又有一個包裝
var jQuery = (function() {
var jQuery = function( selector, context ) {
return new jQuery.fn.init( selector, context, rootjQuery );
}
....
// fn實際就是prototype的簡寫
jQuery.fn = jQuery.prototype = {
constructor: jQuery,
init: function( selector, context, rootjQuery ) {... }
}
// 調用jQuery()就是相當于new init(), 而init的prototype就是jQuery的prototype
jQuery.fn.init.prototype = jQuery.fn;
// 這里返回的jQuery對象只具備最基本的功能, 下面就是一系列的extend
return jQuery;
})();
...
// 將jQuery暴露為全局對象
window.jQuery = window.$ = jQuery;
})(window);
顯然, $.fn其實就是jQuery.prototype的簡寫.
無狀態(tài)的插件僅僅就是一個函數(shù), 非常簡單.
// 定義插件
(function($){
$.fn.hoverClass = function(c) {
return this.hover(
function() { $(this).toggleClass(c); }
);
};
})(jQuery);
// 使用插件
$('li').hoverClass('hover');
對于比較復雜的插件開發(fā), jQuery UI提供了一個widget工廠機制,
$.widget("ui.dialog", {
options: {
autoOpen: true,...
},
_create: function(){ ... },
_init: function() {
if ( this.options.autoOpen ) {
this.open();
}
},
_setOption: function(key, value){ ... }
destroy: function(){ ... }
});
調用 $('#dlg').dialog(options)時, 實際執(zhí)行的代碼基本如下所示:
this.each(function() {
var instance = $.data( this, "dialog" );
if ( instance ) {
instance.option( options || {} )._init();
} else {
$.data( this, "dialog", new $.ui.dialog( options, this ) );
}
}
可以看出, 第一次調用$('#dlg').dialog()函數(shù)時會創(chuàng)建窗口對象實例,并保存在data中, 此時會調用_create()和_init()函數(shù), 而如果不是第一次調用, 則是在已經(jīng)存在的對象實例上調用_init()方法. 多次調用$('#dlg').dialog()并不會創(chuàng)建多個實例.
13. browser sniffer vs. feature detection
瀏覽器嗅探(browser sniffer)曾經(jīng)是很流行的技術, 比如早期的jQuery中
jQuery.browser = {
version:(userAgent.match(/.+(?:rv|it|ra|ie)[/: ]([d.]+)/) || [0,'0'])[1],
safari:/webkit/.test(userAgent),
opera:/opera/.test(userAgent),
msie:/msie/.test(userAgent) && !/opera/.test(userAgent),
mozilla:/mozilla/.test(userAgent) && !/(compatible|webkit)/.test(userAgent)
};
在具體代碼中可以針對不同的瀏覽器作出不同的處理
if($.browser.msie) {
// do something
} else if($.browser.opera) {
// ...
}
但是隨著瀏覽器市場的競爭升級, 競爭對手之間的互相模仿和偽裝導致userAgent一片混亂, 加上Chrome的誕生, Safari的崛起, IE也開始加速向標準靠攏, sniffer已經(jīng)起不到積極的作用. 特性檢測(feature detection)作為更細粒度, 更具體的檢測手段, 逐漸成為處理瀏覽器兼容性的主流方式.
jQuery.support = {
// IE strips leading whitespace when .innerHTML is used
leadingWhitespace: ( div.firstChild.nodeType === 3 ),
...
}
只基于實際看見的,而不是曾經(jīng)知道的, 這樣更容易做到兼容未來.
14. Prototype vs. jQuery
prototype.js是一個立意高遠的庫, 它的目標是提供一種新的使用體驗,參照Ruby從語言級別對javascript進行改造,并最終真的極大改變了js的面貌。$, extends, each, bind...這些耳熟能詳?shù)母拍疃际莗rototype.js引入到js領域的. 它肆無忌憚的在window全局名字空間中增加各種概念, 大有誰先占坑誰有理, 舍我其誰的氣勢. 而jQuery則扣扣索索, 抱著比較實用化的理念, 目標僅僅是write less, do more而已.
不過等待激進的理想主義者的命運往往都是壯志未酬身先死. 當prototype.js標志性的bind函數(shù)等被吸收到ECMAScript標準中時, 便注定了它的沒落. 到處修改原生對象的prototype, 這是prototype.js的獨門秘技, 也是它的死穴. 特別是當它試圖模仿jQuery, 通過Element.extend(element)返回增強對象的時候, 算是徹底被jQuery給帶到溝里去了. prototype.js與jQuery不同, 它總是直接修改原生對象的prototype, 而瀏覽器卻是充滿bug, 謊言, 歷史包袱并夾雜著商業(yè)陰謀的領域, 在原生對象層面解決問題注定是一場悲劇. 性能問題, 名字沖突, 兼容性問題等等都是一個幫助庫的能力所無法解決的. Prototype.js的2.0版本據(jù)說要做大的變革, 不知是要與歷史決裂, 放棄兼容性, 還是繼續(xù)掙扎, 在夾縫中求生.
2011年5月8日
1. C語言抽象出了軟件所在的領域(domain): 由變量v1,v2,...和函數(shù)f1,f2,...組成的空間
2. 面向對象(OOP)指出,在這一領域上可以建立分組(group)結構:一組相關的變量和函數(shù)構成一個集合,我們稱之為對象(Object)。同時在分組結構上可以定義一個運算(推理)關系: D > B, 派生類D從基類B繼承(inheritance),相應的派生對象符合基類對象所滿足的所有約束。推理是有價值的,因為根據(jù) D > B, B > A 可以自動推導出 D > A,所有針對A的斷言在理論上對D都成立(這也就是我們常說的“派生對象 is a 基類對象”)。編譯器也能有點智能了。
一個有趣的地方是,D > B意味著在D和B之間存在著某種差異,但是我們卻無法把它顯式的表達出來!也就是說在代碼層面上我們無法明確表達 D - B是什么。為了把更多的信息不斷的導入到原有系統(tǒng)中,面向對象內置提供的方法是建立不斷擴展的類型樹,類型樹每增長一層,就可以多容納一些新的信息。這是一種金字塔式的結構,只不過是一種倒立的金字塔,最終基點會被不斷增長的結構壓力所壓垮。
3. 組件技術(Component)本質上是在提倡面向接口(interface),然后通過接口之間的組合(Composition)而不是對象之間的繼承(inheritance)來構造系統(tǒng)。基于組合的觀念相當于是定義了運算關系:D = B + C。終于,我們勉強可以在概念層面上做加法了。
組件允許我們隨意的組合,按照由簡單到復雜的方向構造系統(tǒng),但是組件構成的成品之間仍然無法自由的建立關系。這意味著組件組裝得到的成品只是某種孤立的,偶然的產物。
F = A + B + C ? G = A + D + C。
4. 在數(shù)學上,配備了加法運算的集合構成半群,如果要成為群(Group),則必須定義相應的逆運算:減法。 群結構使得大粒度的結構變換成為可能。
F = A + B + C = A + D - D + B + C = (A + D + C) - D + B = G - D + B
在不破壞原有代碼的情況下,對原有系統(tǒng)功能進行增刪,這就是面向切面(AOP)技術的全部價值。
2011年2月11日
業(yè)務架構平臺的設計與實現(xiàn)要比普通業(yè)務系統(tǒng)困難很多。一個核心難點在于如何建立普遍有效的應用程序模型,如何控制各種偶然性的業(yè)務需求對系統(tǒng)整體架構的沖擊。大多數(shù)現(xiàn)有的業(yè)務架構平臺都是提供了一個龐大的萬能性產品,它預料到了所有可能在業(yè)務系統(tǒng)開發(fā)中出現(xiàn)的可能性,并提供了相應的處理手段。業(yè)務系統(tǒng)開發(fā)人員的能力被限定在業(yè)務架構平臺所允許的范圍之內。如果業(yè)務架構平臺的復雜度為A+,則我們最多只能用它來開發(fā)復雜度為A的業(yè)務系統(tǒng)。一個典型的特征就是使用業(yè)務架構平臺的功能配置非常簡單,但是要開發(fā)相應的功能特性則非常困難,而且必須采用與業(yè)務系統(tǒng)開發(fā)完全不同的技術手段和開發(fā)方式。
采用業(yè)務架構平臺來開發(fā)業(yè)務系統(tǒng),即使看似開發(fā)工作量小,最終產生的各類配置代碼量也可能會大大超過普通手工編程產生的代碼量,這意味著平臺封裝了業(yè)務內在的復雜性,還是意味著平臺引入了不必要的復雜性?很多業(yè)務架構平臺的賣點都是零代碼的應用開發(fā),低水平的開發(fā)人員也可以主導的開發(fā),但是為什么高水平的程序員不能借助于這些開發(fā)平臺極大的提高生產率?
一般的業(yè)務架構平臺無法回答以下問題:
1) 業(yè)務系統(tǒng)可以通過使用設計工具來重用業(yè)務架構平臺已經(jīng)實現(xiàn)的功能,但是業(yè)務系統(tǒng)內部大量相似的模型配置如何才能夠被重用?
2) 特定的業(yè)務領域中存在著大量特殊的業(yè)務規(guī)則,例如“審批串行進行,每一步都允許回退到上一步,而且允許選擇跳轉到任意后一步”。這些規(guī)則如何才能夠被引入設計工具,簡化配置過程?
3) 已經(jīng)開發(fā)好的業(yè)務系統(tǒng)作為產品來銷售的時候,如何應對具體客戶的定制化?如果按照客戶要求修改配置,則以后業(yè)務系統(tǒng)自身是否還能夠實現(xiàn)版本升級?
Witrix平臺提供的基本開發(fā)模型為
App = Biz aop-extends Generator<DSL>
在這一圖景下,我們就可以回答以上三個問題:
1) 業(yè)務模型通過領域特定語言(DSL)來表達,因此可以使用語言中通用的繼承或者組件抽象機制來實現(xiàn)模型重用。
2) 推理機對于所有推理規(guī)則一視同仁,特殊的業(yè)務規(guī)則與通用的業(yè)務規(guī)則一樣都可以參與推理過程,并且一般情況下特殊的業(yè)務規(guī)則更能夠大幅簡化系統(tǒng)實現(xiàn)結構。
3) 相對于原始模型的修改被獨立出來,然后應用面向切面(AOP)技術將這些特定代碼織入到原始模型中。原始模型與差異修改相互分離,因此原始模型可以隨時升級。
Witrix平臺所強調的不是強大的功能,而是一切表象之后的數(shù)學規(guī)律。Witrix平臺通過少數(shù)基本原理的反復應用來構造軟件系統(tǒng),它本身就是采用平臺技術構造的產物。我們用復雜度為A的工具制造復雜度為A+的產品,然后進一步以這個復雜度為A+的產品為工具來構造復雜度為A++的產品。
2011年2月7日
一種技術思想如果確實能夠簡化編程,有效降低系統(tǒng)構造的復雜性,那么它必然具有某種內在的數(shù)學解釋。反之,無論一種技術機制顯得如何華麗高深,如果它沒有
清晰的數(shù)學圖象,那么就很難證明自身存在的價值。對于模型驅動架構(MDA),我長期以來一直都持有一種批判態(tài)度。(Physical Model
Driven http://canonical.javaeye.com/blog/29412
)。原因就在于“由工具自動實現(xiàn)從平臺無關模型(PIM)向平臺相關模型(PSM)的轉換”這一圖景似乎只是想把系統(tǒng)從實現(xiàn)的泥沼中拯救出來,遮蔽特定語
言,特定平臺中的偶然的限制條件,并沒有觸及到系統(tǒng)復雜性這一核心問題。而所謂的可視化建模充其量不過是說明人類超強的視覺模式識別能力使得我們可以迅速
識別系統(tǒng)全景圖中隱含的整體結構,更快的實現(xiàn)對系統(tǒng)結構的理解,并沒有證明系統(tǒng)復雜性有任何本質性的降低。不過如果我們換一個視角,
不把模型局限為某種可視化的結構圖,而將它定義為某種高度濃縮的領域描述,
則模型驅動基本上等價于根據(jù)領域描述自動推導得到最終的應用程序。沿著這一思路,Witrix平臺中的很多設計實際上可以被解釋為模型定義,模型推導以及
模型嵌入等方面的探索。這些具體技術的背后需要的是比一般MDA思想更加精致的設計原理作為支撐。我們可以進行如下抽象分析。(Witrix架構分析 http://canonical.javaeye.com/blog/126467
)
1. 問題復雜?線性切分是削減問題規(guī)模(從而降低問題復雜性)的通用手段,例如模塊(Module)。(軟件中的分析學 http://canonical.javaeye.com/blog/33885
)
App = M1 + M2 + M3 + 
2. 分塊過多?同態(tài)映射是系統(tǒng)約化的一般化策略,例如多態(tài)(polymorphism)。(同構與同態(tài):認識同一性 http://canonical.javaeye.com/admin/blogs/340704
)
(abc,abb,ade,) -> [a], (bbb, bcd,bab,) -> [b]
3. 遞歸使用以上兩種方法,將分分合合的游戲進行到底,推向極致。
4. 以少控多的終極形態(tài)?如果存在,則構成輸入與輸出之間的非線性變換(輸入中局部微小變化將導致輸出中大范圍明顯的變化)。
App = F(M)
5.
變換函數(shù)F可以被詮釋為解釋器(Interpreter)或者翻譯機,例如工作流引擎將工作流描述信息翻譯為一步步的具體操作,工作流描述可以看作是由底
層引擎支撐的,在更高的抽象層面上運行的領域模型。但是在這種觀點下,變換函數(shù)F似乎是針對某種特定模型構造的,引擎內部信息傳導的途徑是確定的,關注的
重點始終在模型上,那么解釋器自身應該如何被構造出來呢?
App ~ M
6.
另外一種更加開放的觀點是將變換函數(shù)F看作是生成器(Generator)或者推理機。F將根據(jù)輸入的信息,結合其他知識,推理生成一系列新的命題和斷
言。模型的力量源于推導。變換函數(shù)F本身在系統(tǒng)構造過程中處于核心地位,M僅僅是觸發(fā)其推理過程的信息源而已。F將榨干M的最后一點剩余價值,所有根據(jù)M
能夠確定的事實將被自動實現(xiàn),而大量單靠M自身的信息無法判定的命題也可以結合F內在的知識作出判斷。生成器自身的構造過程非常簡單--只要不斷向推理系
統(tǒng)中增加新的推理規(guī)則即可。語言內置的模板機制(template)及元編程技術(meta
programming),或者跨越語言邊界的代碼生成工具都可以看作是生成器的具體實例。(關于代碼生成和DSL http://canonical.javaeye.com/blog/275015
)
App = G<M>
7. 生成器G之所以可以被獨立實現(xiàn),是因為我們可以實現(xiàn)相對知識與絕對知識的分離, 這也正是面向對象技術的本質所在。(面向對象之形式系統(tǒng) http://canonical.javaeye.com/blog/37064
)
G<M> ==> G = {m => m.x(a,b,c);m.y(); }
8.
現(xiàn)實世界的不完美,就在于現(xiàn)實決不按照我們?yōu)槠渲付ǖ睦硐肼肪€前進。具體場景中總是存在著大量我們無法預知的“噪聲”,它們使得任何在“過去”確立的方程
都無法在“未來”保持持久的平衡。傳統(tǒng)模型驅動架構的困境就在于此。我們可以選擇將模型M和生成器G不斷復雜化,容納越來越多的偶然性,直至失去對模型整
體結構的控制力。另外一種選擇是模型在不斷膨脹,不斷提高覆蓋能力的過程中,不斷的空洞化,產生大量可插入(plugin)的接入點,最終喪失模型的推理
能力,退化成為一種編碼規(guī)范。Witrix平臺中采用的是第三種選擇:模型嵌入--模型中的多余信息被不斷清洗掉,模型通過精煉化來突出自身存在的合理
性,成為更廣泛的運行環(huán)境中的支撐骨架。(結構的自足性 http://canonical.javaeye.com/blog/482620
)
App != G0<M0> , App != G0<M1>, App = G1<M1>
9.
現(xiàn)在的問題是:如何基于一個已經(jīng)被完美解決的重大問題,來更有效率的搞定不斷出現(xiàn)但又不是重復出現(xiàn)的小問題。現(xiàn)在我們所需要的不是沿著某個維度進行均勻的
切分,而必須是某種有效的降維手段。如果我們可以定義一種投影算子P,
將待解決的問題投射到已經(jīng)被解決的問題域中,則剩下的補集往往可以被簡化。(主從分解而不是正交分解 http://canonical.javaeye.com/blog/196826
)
dA = App - P[App] = App - G0<M0>
10. 要實現(xiàn)以上微擾分析策略,前提條件是可以定義逆元,并且需要定義一種精細的粘結操作,可以將分散的擾動量極為精確的應用到基礎系統(tǒng)的各處。Witrix平臺的具體實現(xiàn)類似于某種AOP(面向切面編程)技術。(逆元:不存在的真實存在 http://canonical.javaeye.com/blog/325051
)
App = A + D + B = (A + B + C) - C + D = App0 + (-C + D) = G0<M0> + dA
11. 模型驅動并不意味著一個應用只能由唯一的一個模型來驅動,但是如果引入多個不同形式的模型,則必須為如下推理提供具體的技術路徑:
A. 將多個模型變換到共同的描述域
B. 實現(xiàn)多個模型的加和
C. 處理模型之間的沖突并填補模型之間的空白
在Witrix平臺中模型嵌入/組合主要依賴于文本化及編譯期運行等機制。(文本化 http://canonical.javaeye.com/blog/309395
)
App = Ga<Ma> + Gb<Mb> + dA
12.
系統(tǒng)的開發(fā)時刻t0和實施時刻t1一般是明確分離的,因此如果我們要建立一個包含開發(fā)與實施時刻信息的模型,則這一模型必須是含時的,多階段的。關于時
間,我們所知道的最重要的事實之一是“未來是不可預知的”。在t0時刻建立的模型如果要涵蓋t1時刻的所有變化,則必須做出大量猜測,而且t1時刻距離
t0時刻越遠,猜測的量越大,“猜測有效”這一集合的測度越小,直至為0。延遲選擇是實現(xiàn)含時系統(tǒng)控制的不二法門。
在Witrix平臺中,所有功能特性的實現(xiàn)都包含某種元數(shù)據(jù)描述或者定制模板,因此結合配置機制以及動態(tài)編譯技術既可實現(xiàn)多階段模型。例如對于一個在未來
才能確定的常量數(shù)組,我們可以定義一個Excel文件來允許實施人員錄入具體的值,然后通過動態(tài)編譯技術在編譯期解析Excel文件,并完成一系列數(shù)值映
射運算,最終將其轉化為編譯期存在的一個常量。這一過程不會引入任何額外的運行成本,也不要求任何特定的緩存機制,最終的運行結構與在未來當所有信息都在
位之后再手寫代碼沒有任何區(qū)別。(D語言與tpl之編譯期動作 http://canonical.javaeye.com/blog/57244
)
App(t1) = G(t0,t1)<M(t0,t1)> + dA(t0,t1)
13. 級列理論提供了一個演化框架,它指出孤立的模型必須被放在模型級列中被定義,被解釋。(關于級列設計理論 http://canonical.javaeye.com/blog/33824
)
M[n] = G<M[n-1]> + dMn
14.
推理的鏈條會因為任何局部反例的出現(xiàn)而中斷。在任意時空點上,我們能夠斷言的事實有哪些?信息越少,我們能夠確定的事實越少,能夠做出的推論也就越少。現(xiàn)
在流行的很多設計實質上是在破壞系統(tǒng)的對稱性,破壞系統(tǒng)大范圍的結構。比如明明ORM容器已經(jīng)實現(xiàn)所有數(shù)據(jù)對象的統(tǒng)一管理,非要將其拆分為每個業(yè)務表一個
的DAO接口。很多對靈活性的追求完全沒有搞清楚信息是對不確定性的消除,而不確定性的減少意味著限制的增加,約束的增加。(From Local To
Global http://canonical.javaeye.com/blog/42874
)
組件/構件技術的宣言是生產即組裝,但是組裝有成本,有后遺癥(例如需要額外的膠水或者螺釘)。軟件的本質并不是物質,而是信息,而信息的本質是抽象的規(guī)
律。在抽象世界中最有效的生產方式是抽象的運算,運算即生產。組件式開發(fā)意味著服從現(xiàn)有規(guī)律,熟練應用,而原理性生產則意味著不斷創(chuàng)造新的規(guī)律。功能模
塊越多,維護的成本越高,是負擔,而推理機制越多,生產的成本越低,是財富。只有恢復軟件的抽象性,明確把握軟件構造過程內在的數(shù)學原理,才能真正釋放軟
件研發(fā)的生產力。(從編寫代碼到制造代碼 http://canonical.javaeye.com/blog/333167
)
注解1:很多設計原則其實是在強調軟件由人構造由人理解,軟件開發(fā)本質上是人類工程學,需要關注人類的理解力與協(xié)作能力。例如共同的建模語言減少交互成本,基于模型減少設計與實現(xiàn)的分離,易讀的代碼比高性能的代碼更重要,做一件事只有唯一的一種方式等。
注解2:生成系統(tǒng)的演繹遠比我們想象的要深刻與復雜得多。例如生命的成長可以被看作是在外界反饋下不斷調整的生成過程。
注解3:領域描述是更緊致但卻未必是更本質的表達。人類的DNA如果表達為ATGC序列完全可以拷貝到U盤中帶走,只要對DNA做少量增刪,就可以實現(xiàn)老
鼠到人類的變換(人類和老鼠都有大約30000條基因,其中約有80%的基因是“完全一樣的”,大約共享有99%的類似基因),但是很難認為人類所有智慧
的本質都體現(xiàn)在DNA中,DNA看起來更像是某種序列化保存形式而已。
注解4:模型轉換這一提法似乎是在強調模型之間的同構對應,轉換似乎總是可以雙向進行的,僅僅是實現(xiàn)難度限制了反向轉換而已。但是大量有用的模型變換卻是單向的,變換過程要求不斷補充新的信息。
注解5:模型驅動在很多人看來就是數(shù)據(jù)庫模型或者對象模型驅動系統(tǒng)界面運行,但實際上模型可以意指任意抽象知識。雖然在目前業(yè)內廣泛流行的對象范式下,所
有知識都可以表達為對象之間的關聯(lián),但是對象關系(名詞之間的關聯(lián)關系)對運算結構的揭示是遠遠不夠充分的。很多時候所謂的領域模型僅僅是表明概念之間具
有相關性,但是如果不補充一大段文字說明,我們對于系統(tǒng)如何運作仍然一知半解。數(shù)學分析其實是將領域內在的意義抽空,僅余下通用的形式化符號。
2010年1月17日
html主要通過內置的<script>,<link>, <img>等標簽引入外部的資源文件,一般的Web框架并沒有對這些資源文件進行抽象,因此在實現(xiàn)組件封裝時存在一些難以克服的困難。例如一個使用傳統(tǒng)JSP Tag機制實現(xiàn)的Web組件中可能用到js1.js, js2.js和css1.css等文件,當在界面上存在多個同樣的組件的時候,可能會生成多個重復的<script>和<link>標簽調用,這將對頁面性能造成嚴重的負面影響。資源管理應該是一個Web框架的內置組成部分之一。在Witrix平臺中,我們主要借助于tpl模板引擎來輸出html文本, 因此可以通過自定義標簽機制重新實現(xiàn)資源相關的html標簽, 由此來提供如下增強處理功能:
1. 識別contextPath
tpl模板中的所有資源相關標簽都會自動拼接Web應用的contextPath, 例如當contextPath=myApp時
<script src="/a.js"></script> 將最終輸出 <script src="/myApp/a.js" ...>
2. 識別重復裝載
<script src="a.js" tpl:once="true"></script>
tpl:once屬性將保證在頁面中script標簽實際只會出現(xiàn)一次.
3. 識別組件內相對路徑
開發(fā)Web組件時,我們希望所有資源文件都應該相對組件目錄進行定位,但是直接輸出的<script>等標簽都是相對于最終的調用鏈接進行相對路徑定位的. 例如在page1.jsp中調用了組件A, 在組件A的實現(xiàn)中, 輸出了<script src="my_control.js"></script>
我們的意圖一般是相對于組件A的實現(xiàn)文件進行定位, 而不是相對于page1.jsp進行定位. tpl模板引擎的相對路徑解析規(guī)則為永遠相對于當前文件進行定位. 例如
<c:include src="sub.tpl" />
在sub.tpl中的所有相對路徑都相對于sub.tpl文件進行定位.
4. 編譯期文件有效性檢查
在編譯期, tpl引擎會檢查所有引入的資源文件的有效性. 如果發(fā)現(xiàn)資源文件丟失, 將直接拋出異常. 這樣就不用等到上線后才發(fā)現(xiàn)文件命名已修改等問題.
5. 緩存控制
瀏覽器缺省會緩存css, js等文件, 因此系統(tǒng)上線后如果修改資源文件可能會造成與客戶端緩存不一致的情況. 一個簡單的處理方式是每次生成資源鏈接的時候都拼接文件的修改日期或者版本號, 這樣既可利用客戶端緩存, 又可以保證總是使用最新版本. 例如
<script src="a.js"></script>將會輸出 <script src="/myApp/myModule/a.js?344566" ...>
6. 字符集選擇
為了簡化國際化處理, 一般提倡的最佳實踐方式是堅持使用UTF-8編碼. 但是很多情況下可能使用系統(tǒng)內置的GBK編碼會更加方便一些, 另外集成一些既有代碼時也存在著不同字符集的問題. 在Witrix平臺中, 所有輸出的資源標簽都會標明對應的字符集, 如果沒有明確設置就取系統(tǒng)參數(shù)中的缺省字符集.
例如 <script src="a.js"></script> 將會輸出 <script ... charset="GBK"></script>
7. 缺省theme支持
為了支持多種頁面風格, 往往不是簡單的替換css文件即可實現(xiàn)的, 它可能意味著整個組件的實現(xiàn)代碼的更換. Witrix平臺中通過一系列缺省判斷來簡化這一過程. 例如如下代碼表明如果設置了ui_theme系統(tǒng)參數(shù), 并且對應的特殊實現(xiàn)存在, 則使用特殊實現(xiàn), 否則系統(tǒng)缺省實現(xiàn).
<c:include src="${cp:ui_theme()}/ctl_my_ctl.tpl" >
<c:include src="default/ctl_my_ctl.tpl" />
</c:include>
2009年12月13日
AOP(Aspect Oriented Programming)早已不是什么新鮮的概念,但有趣的是,除了事務(transaction), 日志(Log)等寥寥幾個樣板應用之外,我們似乎找不到它的用武之地。http://canonical.javaeye.com/blog/34941
很多人的疑惑是我直接改代碼就行了,干嗎要用AOP呢?AOP的定義和實現(xiàn)那么復雜,能夠提供什么特異的價值呢?
Witrix平臺依賴于AOP概念來完成領域模型抽象與模型變換,但是在具體的實現(xiàn)方式上,卻與常見的AOP軟件包有著很大差異。http://canonical.javaeye.com/blog/542622
AOP的具體技術內容包括定位和組裝兩個部分。簡化切點定位方式和重新規(guī)劃組裝空間,是Witrix中有效使用AOP技術的前提。
在Witrix平臺中,對于AOP技術的一種具體應用是支持產品的二次開發(fā)。在產品的實施過程中,經(jīng)常需要根據(jù)客戶的特定需求,修改某些函數(shù)的實現(xiàn)。我們
可以選擇在主版本代碼中不斷追加相互糾纏的if-else語句,試圖去包容所有已知和未知的應用場景。我們也可以選擇主版本代碼和定制代碼獨立開發(fā)的方
式,主版本代碼實現(xiàn)邏輯框架,定制代碼通過AOP機制與主版本代碼融合,根據(jù)具體場景要求對主版本功能進行修正。AOP的這種應用與所謂的橫切概念是有所
區(qū)別的。典型的,一個橫切的切點會涉及到很多類的很多方法,而函數(shù)定制則往往要求準確定位到某個業(yè)務對象的某個特定的業(yè)務方法上。傳統(tǒng)AOP技術的切點定
義方式并不適合這種精確的單點定位。在Witrix平臺中,我們通過直接的名稱映射來定義切點。例如,修正spring中注冊的MyObject對象的
myFunc方法,可以在app.aop.xml文件中增加如下標簽
<myObject.myFunc>
在原函數(shù)執(zhí)行之前執(zhí)行
<aop:Proceed/> <!-- 執(zhí)行原函數(shù)內容 -->
在原函數(shù)執(zhí)行之后執(zhí)行
</myObject.myFunc>
[spring對象名.方法名]這種映射方法比基于正則字符串匹配的方式要簡單明確的多。spring容器本身已經(jīng)實現(xiàn)了對象的全局管理功能,spring對象名稱必然是唯一的,公開發(fā)布的,相互之間不沖突的,沒有必要再通過匹配運算重新發(fā)現(xiàn)出它的唯一性。
對于一些確實存在的橫切需求,我們可以通過Annotation機制來實現(xiàn)切點坐標標定,將復雜的切點匹配問題重新劃歸為[對象名.方法名]。
@AopClass({"myObject","otherObject"})
class SomeClass{
@AopMethod({"myFunc","otherFunc"})
void someFunc(){}
}
針對以上對象,在app.aop.xml文件中可以定義
<I-myObject.I-myFunc>
.
</I-myObject.I-myFunc>
2009年12月6日
結構的穩(wěn)定性,直觀的理解起來,就是結構在存在外部擾動的情況下長時間保持某種形式不變性的能力。穩(wěn)定意味著小的擾動造成的后果也是“小”的。在數(shù)學中,Taylor級數(shù)為我們描繪了變化傳播的基本圖景。
F(x0 + dx) = F(x0) + F'(x0)*dx + 0.5*F''(x0)*dx^2 +
擾動dx可能在系統(tǒng)F中引發(fā)非常復雜的作用過程,在系統(tǒng)各處產生一個個局部變化結果。表面上看起來,似乎這些變化結果存在著無窮多種可能的分組方式,例如 (F'(x0)-2)*dx + 2*dx^2, 但是基于微分分析,我們卻很容易了解到Taylor級數(shù)的每一級都對應著獨立的物理解釋,它們構成自然的分組標準。某一量級下的所有變化匯總歸并到一起,并對應一個明確的整體描述。在抽象的數(shù)理空間中,我們具有一種無所不達的變化搜集能力。變化項可以從基礎結構中分離出來,經(jīng)過匯總后可以對其進行獨立的研究。變化本身并不會直接導致基礎結構的崩潰。
在軟件建模領域,模型的穩(wěn)定性面臨的卻是另一番場景。一個軟件模型一旦被實現(xiàn)之后,種種局部需求變更就都會形成對原有基礎結構的沖擊。一些局部的需求變化可能造成大片原有實現(xiàn)失效,我們將被迫為類似的需求重新編寫類似的代碼。此時,軟件開發(fā)并不像是一種純粹的信息創(chuàng)造,而是宛若某種物質產品的生產(參見從編寫代碼到制造代碼 http://canonical.javaeye.com/blog/333167 )。顯然,我們需要一種能力,將局部變化從基礎結構中剝離出來,經(jīng)過匯總歸并之后再進行綜合分析和處理。這正是AOP(Aspect Oriented Programming)技術的價值所在。
M1 = (G0+dG0)<M0+dM0> ==> M1 = G0<M0> + dM
AOP本質上是軟件結構空間的自由修正機制。只有結合AOP技術之后,軟件模型才能夠重新恢復抽象的本質,在時間之河中逃離隨機變化的侵蝕,保持實現(xiàn)層面的穩(wěn)定性。在這一背景下,建模的目的將不是為了能夠跟蹤最終需求的變動,而是要在某個獨立的層面上能夠自圓其說,能夠具有某種獨立存在的完滿性,成為思維上可以把握的某個穩(wěn)定的基點。模型的真實性將因為自身結構的完備性而得到證明,與外部世界的契合程度不再是價值判斷的唯一標準。 http://canonical.javaeye.com/blog/482620
2009年10月7日
說到軟件建模,一個常見的論調是模型應該符合實際需求,反映問題的本質。但是何謂本質,卻是沒有先驗定義的。在成功的建立一個模型之前,無論在內涵上還是在外延上我們都很難說清楚一個問題的本質是什么。如果將模型看作是對領域結構的一種顯式描述和表達,我們可以首先考察一下一個“合適”的結構應該具備哪些特征。
按照結構主義哲學的觀點,結構具有三個要素:整體性,具有轉換規(guī)律或法則(轉換性),自身調整性(自律性)。整體性意味著結構不能被簡單的切分,其構成要素通過內在的關系運算實現(xiàn)大范圍的關聯(lián)與轉換,整體之所以成為整體正是以轉換/運算的第一性為保證的。這種轉換可以是共時的(同時存在的各元素),也可以是歷時的(歷史的轉換構造過程),這意味著結構總要求一個內在的構造過程,在獨立于外部環(huán)境的情況下結構具有某種自給自足的特性,不依賴于外部條件即可獨立的存在并保持內在的活動。自律性意味著結構內在的轉換總是維持著某種封閉性和守恒性,確保新的成分在無限地構成而結構邊界卻保持穩(wěn)定。注意到這里對結構的評判并不是來自外在規(guī)范和約束,而是基于結構內在的規(guī)律性,所強調的不是結構對外部條件的適應性,而是自身概念體系的完備性。實際上,一個無法直接對應于當前實際環(huán)境的結構仍然可能具有重要的價值,并在解決問題的過程中扮演不可或缺的角色。在合理性這個視角下,我們所關注的不僅僅是當前的現(xiàn)實世界,而是所有可能的世界。一個“合理”的結構的價值必能在它所適應的世界中凸現(xiàn)出來。
在信息系統(tǒng)中,我們可能經(jīng)常會問這個模型是否是對業(yè)務的準確描述,是否可以適應需求的變更,是否允許未來的各種擴展等等。但是如果換一個思維方向,我們會發(fā)現(xiàn)這些問題都是針對最終確立的模型而發(fā)問的,而在模型構建的過程中,那些可被利用的已存在的或者可以存在的模型又是哪些呢。每一個信息模型都對應著某種自動推理機,可以接收信息并做一定的推導綜合工作。一個可行的問題是,如何才能更有效的利用已有的信息進行推導,如何消除冗余并減少各種轉換成本。我們經(jīng)常可以觀察到,某一信息組織方式更充分的發(fā)掘了信息之間的內在關聯(lián)(一個表象是它對信息的使用不是簡單的局域化的,而是在多處呈現(xiàn)為互相糾纏的方式,難以被分解),這種內在關聯(lián)足夠豐富,以至于我們不依賴于外部因素就可以獨立的理解。這種糾纏在一起的信息塊自然會成為我們建模的對象。
如果模型的“覆蓋能力”不再是我們關注的重點,那么建模的思維圖式將會發(fā)生如下的轉化
最終的模型可以由一系列微模型交織構成。模型的遞進構造過程并不同于組件(Component)的實物組裝接口,也不是CAD圖紙堆疊式的架構概念所能容納的。在Witrix平臺中,模型分解和構造表達為如下形式 http://canonical.javaeye.com/blog/333167
Biz[n] = Biz[n+1] aop-extends CodeGenerator<DSLx, DSLy>。
在軟件發(fā)展的早期,所有的程序都是特殊構造的,其必然的假設是【在此情況下】,重用不在考慮范圍之內,開發(fā)可以說是一個盲目試錯的過程。隨著我們逐步積累了一些經(jīng)驗,開始自覺的應用理論分析手段,【在所有情況下】都成立的一些普適的原理被揭示出來,它們成為我們在廣闊的未知世界中跋涉時的向導。當我們的足跡漸漸接近領域的邊界,對領域的全貌有一個總體的認知之后,一種對自身成熟性的自信很自然的將我們導向更加領域特定的分析。很多時候,我們會發(fā)現(xiàn)一個特化假設可以大大提高信息的利用率,推導出眾多未被顯式設定的知識。我們需要那些【在某些情況下】有效的規(guī)則來構成一個完備的模型庫。這就如同有大量備選的數(shù)學定理,面對不同的物理現(xiàn)象,我們會從一系列的數(shù)學工具中選擇一個進行使用一樣。
2009年7月11日
軟件開發(fā)技術的技術本質在于對代碼結構的有效控制. 我們需要能夠有效的分解/重組代碼片斷, 凸顯設計意圖. 面向對象是目前最常見的代碼組織技術. 典型的, 它可以處理如下模式
A1 --> B2, A2 --> B2, A3 --> B3 ...
我們觀察到A1和A2之間, B2和B2之間具有某種概念關聯(lián)性, 同時存在某種抽象結構 [A] --> [B].
對于這種情況, 我們可以定義對象 [A], [B], 它們分別是 A1和A2的聚合, B1和B2的聚合等. 舉例來說, 對于如下表格描述, <ui:Col>所提供的信息在映射為html實現(xiàn)的時候將在多處被應用.
<ui:Table data="${data}">
<ui:Col name="fieldA" label="labelA" width="20" />
<ui:Col name="fieldB" label="labelB" width="10" />
</ui:Table>
這里<ui:Col>提供的信息對應三個部分的內容: 1. 列標題 2. 列樣式(寬度等) 3. 列數(shù)據(jù)
面向對象的常見做法是抽象出 UiCol對象, 它作為UiTable對象的屬性存在, 在生成表頭, 表列樣式和表格數(shù)據(jù)內容時將被使用. 但是我們注意到面向對象要求多個方法通過this指針形成狀態(tài)耦合
,在某種意義上它意味著所有的成員方法在任一時刻都是同時存在著的。它們所代表著的存在的代價必須被接受(存儲空間等)。即使并不同時被使用,我們仍然需要同時持有所有成員函數(shù)指針及
共享的this指針。實際上, 我們并不一定需要A1和A2同時在場. 在這種情況下, 編譯期技術可以提供另一種不同的行為聚合方式.
<table>
<thead>
<sys:CompileTagBody cp:part="thead" />
</thead>
<cols>
<sys:CompileTagBody cp:part="cols" />
</cols>
<tbody>
<sys:CompileTagBody cp:part="tbody" />
</tbody>
</table>
只要<ui:Col>標簽的實現(xiàn)中針對編譯期的cp:part變量進行分別處理, 即可實現(xiàn)信息的部分析取.
|