#
這幾天抽空把How tomcat works看了一遍。
這本書寫得很好,把tomcat這么一個牛B的大家伙拆成一堆零件,然后告訴你怎么組裝,真是做到了掰開了揉碎了講。
簡單記一下
第一章講web服務器,如何接受和響應http請求,還舉了個sokcet的例子。算是入門,從很底層的技術講起。
第二章講servlet容器,javax.servlet.Servle接口,接受到http請求后如何查找servlet,執行servlet。
第三章講連接器的概念,前兩章看下來你會覺得把http請求接受響應跟容器放在一起太亂了,這章就講如何把http操作提出來作為一個連接器。
第四章講tomcat默認連接器,http協議操作講得很詳細,不過我沒怎么看哈,用的時候直接把tomcat這段代碼拿過來就是了。
第五章講容器,在第三章的基礎上對容器進行分層分類,事情復雜了就分成幾部分,“治眾如治寡,分數是也”這個我們都知道。
tomcat講容器分成這幾個概念:
Engine:表示整個Catalina的servlet引擎
Host:表示一個擁有數個上下文的虛擬主機
Context:表示一個Web應用,一個context包含一個或多個wrapper
Wrapper:表示一個獨立的servlet
類型復雜了,要做的事情也復雜了。
不僅僅是執行service()方法,還要前邊執行一堆,后邊再來一堆。引入了流水線任務Pipelining Tasks的概念,在流水線上可以執行多個Valve(有翻譯成閥),類似于攔截器的概念。
第六章講生命周期,人多了要講究個步調統一,引入了Lifecycle接口的概念,方法包括啟動之前干什么、啟動之后干什么、啟動后把子容器也啟動了。
包括引入監聽接口,都是些java常見實現方式,沒什么特殊。
第七章講日志系統,沒看。
第八章講加載器,可以參考
tomcat類加載器及jar包沖突問題分析 http://www.aygfsteel.com/zyskm/archive/2011/12/06/365653.html 就不重復了。
第九章講session管理,沒什么特別的。
第十章講安全,沒看。
第十一章講StandardWrapper,在第五章的基礎上重點分析了wrapper的運作機制。
其余章節目前工作中用不到,有空再看了。
作者:zyskm
http://www.aygfsteel.com/zyskm
上一篇說明了一種spring事務配置方式,這次補上另一種。
見配置文件:
 <!-- 事務攔截 -->
<!-- 事務攔截 -->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="get*" propagation="REQUIRED" read-only="true" />
<tx:method name="find*" propagation="REQUIRED" read-only="true" />
<tx:method name="search*" propagation="REQUIRED" read-only="true" />
<tx:method name="save*" propagation="REQUIRED" />
<tx:method name="modify*" propagation="REQUIRED" />
<tx:method name="send*" propagation="REQUIRED" />
<tx:method name="revoke*" propagation="REQUIRED" />
<tx:method name="del*" propagation="REQUIRED" />
<tx:method name="logging*" propagation="NOT_SUPPORTED" read-only="true" />
<tx:method name="*" propagation="SUPPORTS" read-only="true" />
</tx:attributes>
</tx:advice>
<aop:config>
<aop:pointcut id="projectServiceOperation" expression="execution(* cn.ceopen.bss..*.service..*(..))" />
<aop:advisor pointcut-ref="projectServiceOperation" advice-ref="txAdvice" />
</aop:config>重點說明兩點:
1.<aop:pointcut id="projectServiceOperation" expression="execution(* cn.ceopen.bss..*.service..*(..))" />
表示你要進行事務控制的類名。詳細資料可以查下 aspectj語法。
配置完成一定要實際測試一下,我配置過 expression="execution(* cn.ceopen.bss..*.service.*(..))" 少了一個點,導致事務不起作用。
導致項目很長一段時間事務方面沒經過嚴格測試。
2.
Spring的AOP事務管理默認是針對unchecked exception回滾。
也就是默認對RuntimeException()異常極其子類進行事務回滾。
在項目中定義公共的RuntimeException異常,避免每個開發人員隨意拋出異常。
不然的話沒新定義一個異常,就要修改tx:method rollback-for 太麻煩了。
總結:
1.對事務配置進行檢查,對復雜嵌套的事務邏輯必要的時候debug到spring源碼中確認。
2.定義統一異常類型
3.同一個類調用自身方法,子方法的事務配置不起作用。解決方法見上一篇文章。
http://www.aygfsteel.com/zyskm/archive/2011/11/11/363535.html作者: zyskm
本文地址:
http://www.aygfsteel.com/zyskm/archive/2011/11/30/365225.html
在開發中緩存是經常要用到的,什么東西都一遍遍的找數據庫問,數據庫表示壓力很大。
緩存方案常見的有兩種,一種是在客戶端,也就是web開發中的瀏覽器。一種是在服務器端,以memcached為代表。
瀏覽器緩存
這幾天因為項目需了解了下瀏覽器緩存相關的知識。
重點說一下HTML5 Storage技術,之前的那些技術都是浮云,存不了什么東西還賊難用,各瀏覽器不兼容。
聽名字就知道這是這兩年剛出來的技術,相應的也就對瀏覽器版本要求比較高,低版本的瀏覽器不支持。對用公司內部用的話這個技術還是很不錯的。
最多支持5M的容量,是個xml文件,備注:
Html5 storage最大支持5M容量
文件位置,根據系統用戶位置會有區別。
C:\Documents and Settings\Administrator\Local Settings\Application Data\Microsoft\Internet Explorer\DOMStore\KF2G0R0O
也就是說別人都能看到你的數據,所以不能存放需要保密的內容。
每次用戶登錄的時候最好檢查一下緩存版本是否跟服務器一致。
現在的項目中有個業務受理環節,設置的過程中需要大量使用一些基礎數據。類似分公司、部門、產品列表這類數據,不經常變動,反復到服務器請求的話對服務器來講是不小的壓力。
業務受理的步驟很多,得點好幾個下一步才能把操作完成,半截數據放到數據庫里維護起來結構就復雜了。
因此考慮采用本地緩存技術,比較來比較去HTML5 Storage是不錯的選擇,反正都是公司同事可以要求都使用IE8以上瀏覽器。
下邊這段是js中用到的代碼
//用jquery方式,為加載緩存到本地按鈕綁定方法

 $('#loadBtn').bind('click',function(event)
$('#loadBtn').bind('click',function(event) {
{

 if(supports_html5_storage()){
if(supports_html5_storage()){
 localStorage.clear();
localStorage.clear();
load();
alert("數據已經緩存到本地!");
initCorpSelect();
initDptSelect("-1");
}else{
alert("You're out!");
 }
}
 }) ;
}) ;
//清空緩存
$('#clearBtn').bind('click',function(event){
if(supports_html5_storage()){
localStorage.clear();
alert("本地緩存已經清空!");
initCorpSelect();
initDptSelect("-1");
}else{
alert("You're out!");
}
}) ;
//加載緩存到本地瀏覽器
function load(){
var params = {
url:"${ctx}/crm/product/product/webstorage!ajaxLoad.do",
type: "post",
dataType: "json",
data: null,
success: function(response){
var corps = response.corps;
var dpts = response.dpts;
var stations = response.stations;
for(var i=0;i<corps.length;i++){
var corp = corps[i];
var jsCorp = new Corp(corp.corpCode,corp.corpName);
localStorage.setItem("corp."+corp.corpCode, jsCorp.toJSONString());
}
for(var i=0;i<dpts.length;i++){
var dpt = dpts[i];
localStorage.setItem("dpt."+dpt.dptCode, dpt.toJSONString());
}
for(var i=0;i<stations.length;i++){
var station = stations[i];
localStorage.setItem("station."+station.stationCode, station.toJSONString());
}
}
};
ajax(params);
}
服務器緩存
緩存解決方案很多了,只說剛剛用到的memcached。
memcached很好用了
1.安裝啟動memcached
2.寫一個memcached客戶端工具類,我用的是com.danga.MemCached.MemCachedClient 比較穩定,至于其他性能更高的目前沒有需求沒用到。
3.加載數據到memcached
4.程序中需要基礎數據的時候從memcached獲取。
/** *//**
* memcached接口
* @author ce
*
*/
public interface Imemcached {
/** *//**
* 可增加,可覆蓋
*/
public abstract boolean set(Object key, Object value);
public abstract boolean set(Object key, Object value,Date expire);
/** *//**
* 只能增加;如果增加的key存在返回“false”
*/
public abstract boolean add(Object key, Object value);
public abstract boolean add(Object key, Object value,Date expire);
public abstract boolean delete(Object key);
/** *//**
* 只能修改;如果修改不存在的key返回“false”
*/
public abstract boolean modify(Object key, Object value);
/** *//**
* 如果key不存在返回null
*/
public abstract Object getKey(Object key);
/** *//**
* 清除服務器上所有數據
*/
public abstract boolean flushAll();
/** *//**
* 判斷服務器上是否存在key
*/
public abstract boolean keyExists(Object key);
/** *//**
* 一次獲取多個數據,減少網絡傳輸時間
*/
public abstract Map<String, Object> getKeys(String[] keys);
/** *//**
* 設置是否使用字符串方式
*/
public abstract void setPrimitiveAsString(boolean flag);
}
實際測試結果
查詢一張人員表,同時需要根據分公司編號,部門編號從分公司、部門表獲取名稱。
使用緩存技術的時候,不管客戶端還是服務器端,因為只查詢單表,速度明顯比多表聯合查詢要快的多。
在系統使用高峰的時候這種差別明顯能改善用戶的操作體驗。
實際測試了以下幾種情況:
1.查詢:
直接通過表關聯的方式進行查詢,速度最慢,開發最簡便
查詢結果列表中的公司名稱、部門名稱直接從數據庫查出。
2.查詢(本地緩存),緩存數據到本地,清除本地緩存:
速度最快,數據同步有一定工作量,需要高版本瀏覽器支持
查詢結果列表中的公司名稱、部門名稱從本地緩存獲取,增加_IE標識以區別。
3.查詢(服務器緩存),緩存數據到服務器,清除服務器緩存:
速度也很快,也有數據同步問題,緩存數據到服務器比本地慢
查詢結果列表中的公司名稱、部門名稱從服務器緩存獲取,增加_mem標識以區別。

緩存使用總結
1.采用緩存技術后系統性能有明顯改善,可以從性能測試工具明顯感受到(這不是廢話嘛,呵呵)。
2.緩存的數據同步問題必須解決好
3.項目中采用緩存技術需要統一規劃,各系統不能互相干擾。
4.性能壓力不明顯的情況下,緩存開發要顯得復雜一點。
作者: zyskm
本文地址:
http://www.aygfsteel.com/zyskm/archive/2011/11/30/364722.html
聲明性事務是spring一個很重要的功能,可以避免開發陷入繁瑣的事務控制邏輯中。
但是可能是用著太方便了很多人對spring事務原理并不清楚,有必要做一番分析。
下邊以攔截器配置方式進行說明,tx標簽配置方式將在接下來另一篇文章做分析。
一、首先看配置文件:
<bean id="transactionManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
<bean id="matchAllTxInterceptor" class="org.springframework.transaction.interceptor.TransactionInterceptor">
<property name="transactionManager">
<ref bean="transactionManager" />
</property>
<property name="transactionAttributes">
<props>
<prop key="get*">PROPAGATION_REQUIRED,readOnly,-Exception </prop>
<prop key="find*">PROPAGATION_REQUIRED,readOnly,-Exception </prop>
<prop key="search*">PROPAGATION_REQUIRED,readOnly,-Exception </prop>
<prop key="save*">PROPAGATION_REQUIRED,-Exception </prop>
<prop key="modify*">PROPAGATION_REQUIRED,-Exception </prop>
<prop key="send*">PROPAGATION_REQUIRED,-Exception </prop>
<prop key="revoke*">PROPAGATION_REQUIRED,-Exception </prop>
<prop key="del*">PROPAGATION_REQUIRED,-Exception </prop>
<prop key="logging*">PROPAGATION_NOT_SUPPORTED,readOnly,-Exception </prop>
<prop key="*">PROPAGATION_SUPPORTS,-Exception </prop>
</props>
</property>
</bean>
<bean id="autoProxyCreator"
class="org.springframework.aop.framework.autoproxy.BeanNameAutoProxyCreator">
<property name="interceptorNames">
<list><idref local="matchAllTxInterceptor" /></list>
</property>
<property name="proxyTargetClass"><value>true</value></property>
<property name="beanNames">
<list><value>*Service</value></list>
</property>
</bean> 配置第一步引入AOP代理autoProxyCreator,使用的是spring默認的jdk動態代理BeanNameAutoProxyCreator。
有兩個屬性要介紹一下:
1.攔截范圍beanNames;例子中攔截范圍是*Service,表示IOC容器中以Service結尾的bean,一般配置在spring.xml,serviceContext.xml之類的spring配置文件。
要注意這里不是值src下邊的類。
bean配置信息:
 <bean id="menuService" class="cn.ceopen.bss..service.impl.MenuServiceImpl"/>
<bean id="menuService" class="cn.ceopen.bss..service.impl.MenuServiceImpl"/>有圖有真相,下邊是BeanNameAutoProxyCreator 調試信息。

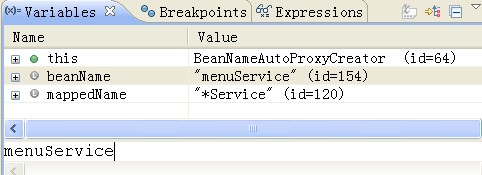
2.截器interceptorNames
interceptorNames定義事務屬性和事務管理器
配置第二步就是定義事務屬性:事務傳播范圍、事務隔離級別
事務屬性沒什么好說的,使用spring進行事務管理的都了解,不在這里詳細說了網上有大量資料。
配置第三步,指定事務管理器
這里用的是HibernateTransactionManager,spring提供對常見orm的事務支持。從spring源碼可以看出HibernateTransactionManager.doGetTransaction()同時支持hibernate和jdbc。
支持hibernate和jdbc混合事務,不使用jta方式的話有個前提條件:使用同一個數據源,
這里所說的同一個數據源,不僅僅指物理上是同一個,在spring配置文件中也要是同一個。
我在開發中遇到過這個問題,最早定義了一個數據baseDataSource,hibernate和jdbc都使用此數據源,后來項目要求使用動態數據源就又配了一個數據源dynamicDataSource
僅在hibernate下做了改動,未改動jdbc對應配置,出現了事務控制問題。
出錯了事務配置:
<bean id="sessionFactory"
class="com.sitechasia.webx.dao.hibernate3.NamedMoudleHbmLocalSessionFactoryBean">
<property name="dataSource" ref="dynamicDataSource" />
<!--與主題無關,省略部分內容-->
</bean>
<bean id="dynamicDataSource" class="cn.ceopen.bss.pub.base.dao.RoutingDataSource">
<property name="targetDataSources">
<map key-type="java.lang.String">
<entry key="baseDataSource" value-ref="baseDataSource"/>
</map>
</property>
<property name="defaultTargetDataSource" ref="baseDataSource"/>
</bean>
<bean id="baseDataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close">
<!--與主題無關,省略部分內容-->
</bean>
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<!--dataSource應該與sessionFactor一致-->
<property name="dataSource"><ref bean="baseDataSource"/></property>
</bean>
<bean id="abstractJdbcDao" abstract="true">
<property name="jdbc" ref="jdbcTemplate" />
</bean> dao配置文件:
<bean id="actDao" class="cn.ceopen.bss.impl.ActDaoImpl" parent="abstractJdbcDao"/> dao中同時支持hibernate操作和jdbc操作。
二、事務屬性傳播
先看這樣一個列子:
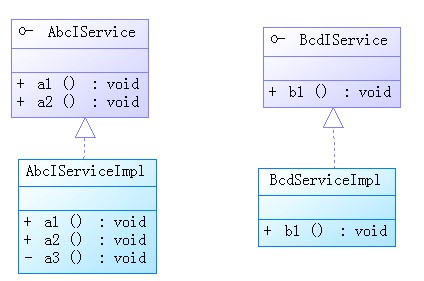
1.基于jdk動態代理的AOP事務控制,只能針對接口。
在上邊的配置文件中設置的事務屬性對a3()都不起作用,a3()不能單獨設計事務屬性,只能繼承接口方法的事務屬性。
2.類自身事務嵌套
第一種情況:
AbcIService abcService;
BcdIService bcdService;
abcService.a1();
abcService.a2();
bcdService.b1();
這三個方法對應的事務屬性都起作用。
第二種情況:
方法定義
public void a1() {
bcdService.b1();
}
調用:
abcService.a1();
結果:
abcService.a1();
bcdService.b1();
這兩個方法對應的事務屬性都起作用。
第三種情況:
方法定義
public void a1() {
this.a2();
}
調用:
abcService.a1();
結果:
abcService.a1();
abcService.a2();
a2()對應的事務屬性配置不起作用。
解決辦法:
1.把a2()拆到另一個類中去;
缺點:麻煩,會把相關業務邏輯拆分了
2.調用是不用this.a2(),用abcService.a2();
public void a1() {
abcService.a2();
}
缺點:要在類中注入自身引用。
原因分析:
為什么會出現這種情況呢?
我們在調用abcService.a1();時abcService是從IOC容器獲取的,并AbcServiceImpl而是它的動態代理AbcServiceProxy。
示意圖如下,spring不一定是這么實現的但原理一樣.
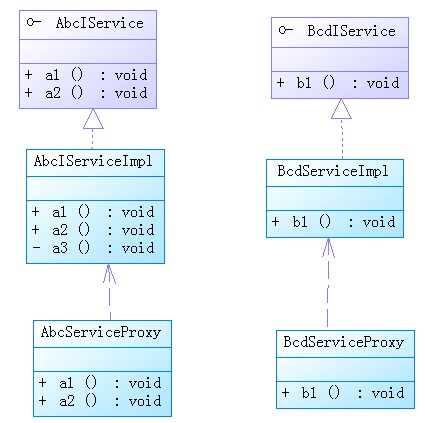
AbcServiceProxy.a()方法進行了AOP增強,根據配置文件中事務屬性增加了事務控制。
public void a1() {
this.a2();
}
this.a2()這里this指的是AbcIServiceImpl并沒用進行AOP增強,所以沒用應用事務屬性,只能繼承a1()的事務屬性。
public void a1() {
abcService.a2();
}
abcService則實際是AbcServiceProxy.a2()所以可以應用事務屬性。
所以在類內部進行方法嵌套調用,如果被嵌套的方法a2()需要區別于嵌套方法a1()的事務屬性,需要:1.在接口公開;2.通過代理調用。
作者:zyskm
http://www.aygfsteel.com/zyskm
上周在西單圖書城看到本不錯的書<<七步掌握業務分析>>,系統的講了些業務分析方面的知識,以前看到業務分析方面的資料都是站在需求捕獲分析的角度來寫,向這么完整系統介紹業務分析概念方法的不多。本著書非借不能讀的精神,我用了兩個周末在西單圖書大廈看完了整本書。記錄一下閱讀感受,同時結合一些自己的理解。
目錄結構見下圖,大概是這個意思,名詞記得不是很準確。

一個個說一下。
1.什么是業務分析
一般來講"什么是...?"這種問題都可以細分為這幾個問題,什么是業務分析、業務分析做什么(工作范圍)、跟系統分析有什么區別、什么人能做業務分析。
讓大家明白組織是怎么運作的,為了實現組織的目標提供解決方案。
實際開發過程中誰都可以做業務分析工作,目前很少看到這門業務分析師這一角色,一般是需求和系統分析師主要來做。根據個人能力的不同介入的程度不同。
說到范圍,業務分析主要從業務需求的角度來考慮,區別于系統分析更多的從系統能否實現、怎么實現的角度來考慮。很多時候系統分析師是同時兼這兩個角色的,優勢是考慮問題有統一方向,缺點的是容易互相干擾。通用的解決思路是顏色帽子法,做哪塊工作時戴那個帽子只想這部分的事情,先不想別的部分怎么辦,先過今天再說明天。每一部分單獨考慮后再進行綜合考慮,這樣工作才好開展,要不然一次想太多了事情就變得太復雜。
2.什么人來做
有人的地方就有江湖,既然在江湖里混就要了解這個江湖是什么人組成的,每個人的立場、對事情的認識程度、角色、權利、影響。對這些人有了認識,才能更好的認識人做的事情。
這一點一般的需求書上只是提了一下,不想這本書就組織架構、角色關系、溝通技巧各方面做了闡述。有個理論認識實際操作起來更容易有方向感。
3.項目做什么
很多開發人員經常是領導讓做什么就做什么,作為一個業務分析師顯然不能這么干。
業務分析師很多時候起的是一個導游的角色,探險的時候大家全兩眼一抹黑只能掉溝里了。
誰發起的項目,項目要達成什么目標,對哪些人有益,對哪些人不利。這些都要了解,在項目的過程中才知道從哪方面去推動,避開可能會引起的麻煩。
4.了解業務
這個是當然了,業務分析師嘛,具體方法先不寫了,都是寫常見的,重要的是要經常實際總結提高。
5.了解業務環境
這也是一個江湖,更多的是從事情的角度進行分類
6.了解技術環境
業務分析雖然不用寫代碼技術還是要懂一點的,好的服裝設計師都會自己做衣服(這可不是隨便說的,我見過幾個,呵呵)。
7.提升自身價值
洞悉事態,能夠提出完整解決方案,這樣的人當然是有價值的。做得越好越有價值。
書中提到了幾種提高技能方法:時間管理和一些分析技術,包括溝通技巧。
先寫這么多。
作者:zyskm
http://www.aygfsteel.com/zyskm
基于spring的動態數據源
項目過程中遇到這樣一個需求,系統啟動后動態設置數據源,不同用戶登錄系統后訪問的數據庫不同。
好在所有書庫結構一致。
用spring 的AbstractRoutingDataSource解決了這個問題。
原理如圖:
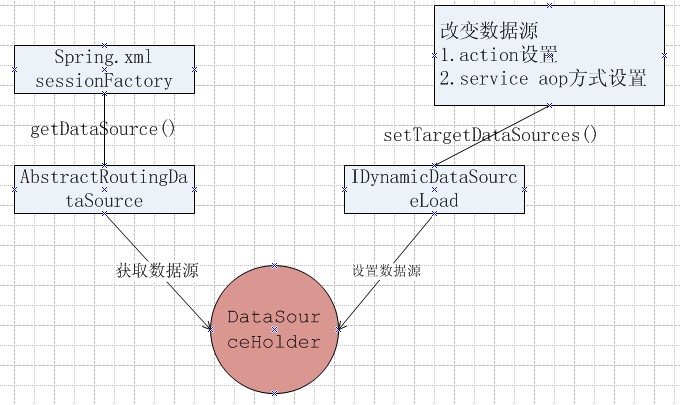
項目采用的是hibernate,直接在spring.xml設置sessionFactory的dataSource屬性為動態數據源即可。
因為項目所有數據庫結構都一致,為了避免每次設置數據源的時候要改一堆參數,修改了spring AbstractRoutingDataSource類增加了一個getTargetDataSources方法,獲取當前數據源詳細信息,在其基礎上修改數據庫名稱、用戶名、密碼即可,不用每次設置一堆參數。
Map<String,ComboPooledDataSource> targetDataSources=dynamicDataSource.getTargetDataSources();
if(targetDataSources==null){
targetDataSources=new HashMap<String, ComboPooledDataSource>();
targetDataSources.put("baseDataSource", baseDataSource);
}
targetDataSources.put(dataSourceName, subSystemDataSource);
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.afterPropertiesSet(); 另外,設置AbstractRoutingDataSource參數后要調用afterPropertiesSet()方法,spring容器才會進行加載操作。
在動態設置數據源方面,可以通過兩種方式實現:
1.在action(項目使用struts)中進行設置,可以確保在每個servlet線程中數據源是一致的。
2.以aop方式,對service方法進行攔截,根據需求設置不同數據源。
在開發過程中數據庫的操作和使用要有一定規范,不然會引起混亂。
下邊是我們開發中具體例子,因為涉及公司在用項目詳細代碼就不列出來了,整個思路可供參考。
1.初始化腳本
各子系統建立自己的數據庫初始化腳本,格式可參照附件產品管理初始化腳本sql.rar(需要解壓到c:/sql才能在命令行執行,見init.sql說明)
包括兩部分內容:1.建表語句(ddl);2.基礎數據初始化(data)
建表語句由數據庫設計文檔(PowerDesigner)導出,基礎數據由excel文件導出(sql.rar提供示例,開發框架提供工具支持DbUtilTest.testExcel2Sql ())
作用:
1.數據庫結構和基礎數據文檔化
2.便于快速搭建開發測試環境,新建一套環境時不用拷貝原數據庫而是執行腳本
3.便于獨立開發測試,有一個干凈的數據,避免開發測試依賴歷史數據和調試過程中互相影響
2.數據庫結構比對
在部署多套數據庫時,懷疑表結構不一致,可使用DbUtilTest.testCompareDataBase ()進行檢查。
執行后會在子系統根目錄生成dbcompare.html 文件,參加附件。
說明:紅色表示兩個表結構不一致,綠色表示多出一表,黑色表示一致
3.數據庫字符集(UTF-8)
create database dbname CHARACTER SET utf8 COLLATE utf8_bin
不單獨對表和字段設置字符集,整個庫統一使用utf-8
4.表名字段名
建庫腳本中表名和字段名不區分大小寫
5.數據庫引擎(InnoDb)
目前主要使用的兩種引擎MyIsam,InnoDb。MyIsam查詢較快,不支持事務。InnoDb支持事務。
在建表sql指明引擎。
create table ***
(
id bigint(11) not null auto_increment,
.........
primary key (id)
)
type = innodb;
powerdesiner按如下方式設置:
字符集的概念大家都清楚,校對規則很多人不了解,一般數據庫開發中也用不到這個概念,mysql在這方便貌似很先進,大概介紹一下。
簡要說明
字符集和校對規則
字符集是一套符號和編碼。校對規則是在字符集內用于比較字符的一套規則。
MySql在collation提供較強的支持,oracel在這方面沒查到相應的資料。
不同字符集有不同的校對規則,命名約定:以其相關的字符集名開始,通常包括一個語言名,并且以_ci(大小寫不敏感)、_cs(大小寫敏感)或_bin(二元)結束
校對規則一般分為兩類:
binary collation,二元法,直接比較字符的編碼,可以認為是區分大小寫的,因為字符集中'A'和'a'的編碼顯然不同。
字符集_語言名,utf8默認校對規則是utf8_general_ci
mysql字符集和校對規則有4個級別的默認設置:服務器級、數據庫級、表級和連接級。
具體來說,我們系統使用的是utf8字符集,如果使用utf8_bin校對規則執行sql查詢時區分大小寫,使用utf8_general_ci 不區分大小寫。不要使用utf8_unicode_ci。
如create database demo CHARACTER SET utf8; 默認校對規則是utf8_general_ci 。
Unicode與UTF8
Unicode只是一個符號集,它只規定了符號的二進制代碼,卻沒有規定這個二進制代碼應該如何存儲.
UTF8字符集是存儲Unicode數據的一種可選方法。 mysql同時支持另一種實現ucs2。
詳細說明
字符集(charset):是一套符號和編碼。
校對規則(collation):是在字符集內用于比較字符的一套規則,比如定義'A'<'B'這樣的關系的規則。不同collation可以實現不同的比較規則,如'A'='a'在有的規則中成立,而有的不成立;進而說,就是有的規則區分大小寫,而有的無視。
每個字符集有一個或多個校對規則,并且每個校對規則只能屬于一個字符集。
binary collation,二元法,直接比較字符的編碼,可以認為是區分大小寫的,因為字符集中'A'和'a'的編碼顯然不同。除此以外,還有更加復雜的比較規則,這些規則在簡單的二元法之上增加一些額外的規定,比較就更加復雜了。
mysql5.1在字符集和校對規則的使用比其它大多數數據庫管理系統超前許多,可以在任何級別進行使用和設置,為了有效地使用這些功能,你需要了解哪些字符集和 校對規則是可用的,怎樣改變默認值,以及它們怎樣影響字符操作符和字符串函數的行為。
校對規則一般有這些特征:
兩個不同的字符集不能有相同的校對規則。
每個字符集有一個默認校對規則。例如,utf8默認校對規則是utf8_general_ci。
存在校對規則命名約定:它們以其相關的字符集名開始,通常包括一個語言名,并且以_ci(大小寫不敏感)、_cs(大小寫敏感)或_bin(二元)結束
確定默認字符集和校對
字符集和校對規則有4個級別的默認設置:服務器級、數據庫級、表級和連接級。
數據庫字符集和校對
每一個數據庫有一個數據庫字符集和一個數據庫校對規則,它不能夠為空。CREATE DATABASE和ALTER DATABASE語句有一個可選的子句來指定數據庫字符集和校對規則:
例如:
CREATE DATABASE db_name DEFAULT CHARACTER SET latin1 COLLATE latin1_swedish_ci;
MySQL這樣選擇數據庫字符集和數據庫校對規則:
· 如果指定了CHARACTER SET X和COLLATE Y,那么采用字符集X和校對規則Y。
· 如果指定了CHARACTER SET X而沒有指定COLLATE Y,那么采用CHARACTER SET X和CHARACTER SET X的默認校對規則。
· 否則,采用服務器字符集和服務器校對規則。
在SQL語句中使用COLLATE
•使用COLLATE子句,能夠為一個比較覆蓋任何默認校對規則。COLLATE可以用于多種SQL語句中。
使用WHERE:
select * from pro_product where product_code='ABcdefg' collate utf8_general_ci
Unicode與UTF8
Unicode只是一個符號集,它只規定了符號的二進制代碼,卻沒有規定這個二進制代碼應該如何存儲.Unicode碼可以采用UCS-2格式直接存儲.mysql支持ucs2字符集。
UTF-8就是在互聯網上使用最廣的一種unicode的實現方式。其他實現方式還包括UTF-16和UTF-32,不過在互聯網上基本不用。
UTF8字符集(轉換Unicode表示)是存儲Unicode數據的一種可選方法。它根據 RFC 3629執行。UTF8字符集的思想是不同Unicode字符采用變長字節序列編碼:
· 基本拉丁字母、數字和標點符號使用一個字節。
· 大多數的歐洲和中東手寫字母適合兩個字節序列:擴展的拉丁字母(包括發音符號、長音符號、重音符號、低音符號和其它音符)、西里爾字母、希臘語、亞美尼亞語、希伯來語、阿拉伯語、敘利亞語和其它語言。
· 韓語、中文和日本象形文字使用三個字節序列。