#
這篇也是轉載,改了中間部分內。
在基于注解方式配置Spring
的配置文件中,你可能會見到<context:annotation-config/>這樣一條配置,他的作用是式地向 Spring
容器注冊
AutowiredAnnotationBeanPostProcessor、CommonAnnotationBeanPostProcessor、
PersistenceAnnotationBeanPostProcessor 以及 RequiredAnnotationBeanPostProcessor 這 4 個BeanPostProcessor。
注冊這4個 BeanPostProcessor的作用,就是為了你的系統能夠識別相應的注解。
例如:
如果你想使用@Autowired注解,那么就必須事先在 Spring 容器中聲明 AutowiredAnnotationBeanPostProcessor Bean。傳統聲明方式如下:
- <bean class="org.springframework.beans.factory.annotation. AutowiredAnnotationBeanPostProcessor "/>
如果想使用@ Resource 、@ PostConstruct、@ PreDestroy等注解就必須聲明CommonAnnotationBeanPostProcessor
如果想使用@PersistenceContext注解,就必須聲明PersistenceAnnotationBeanPostProcessor的Bean。
如果想使用 @Required的注解,就必須聲明RequiredAnnotationBeanPostProcessor的Bean。同樣,傳統的聲明方式如下:
- <bean class="org.springframework.beans.factory.annotation.RequiredAnnotationBeanPostProcessor"/>
一般來說,這些注解我們還是比較常用,尤其是Antowired的注解,在自動注入的時候更是經常使用,所以如果總是需要按照傳統的方式一條一條配置顯得有些繁瑣和沒有必要,于是spring給我們提供<context:annotation-config/>的簡化配置方式,自動幫你完成聲明。
不過,呵呵,我們使用注解一般都會配置掃描包路徑選項
- <context:component-scan base-package=”XX.XX”/>
該配置項其實也包含了自動注入上述processor的功能,因此當使用 <context:component-scan/> 后,就可以將 <context:annotation-config/> 移除了。
本文轉載:http://mushiqianmeng.blog.51cto.com/3970029/723880
有一段時間沒有關注spring了,spring2.5就蠻夠用的,spring3出來后一直沒怎么關注。
這幾天抽空關注一下。干咱這行的還是要緊跟時代變化啊。
下邊這些內容是轉載51cto的一篇文章。
1、項目結構與構建變化
解壓后的立即發現,Spring 3.0的項目結構已經發現了巨大變化:
1、Spring3采用多項目結構源碼組織,不再是以前的單一方式,共26個項目,差不多每個項目對于一個分發的jar包,不過有些項目是空的,或者是為了構建而設。
2、不再提供完整打包文件spring.jar,而是20個jar(或稱bundle),一方面應該也是向osgi靠攏。
Spring 3.0的readme中說道:
Note that this release does not contain a 'spring.jar' file anymore, in contrast to previous Spring generations. Furthermore, the jar file names follow bundle repository conventions now.
(51CTO編輯快譯:與之前的Spring版本相反,此次發布不再包括spring.jar文件了。新版本中的jar文件命名由bundle版本庫的規則所決定。)
3、采用Ivy為主構建方式,當然仍然有Maven,項目結構由Maven管理。另外沒有打包全部的依賴包了,整個下載包比2.5的小了近一半
4、Spring3已經完全采用Java5/6開發和編譯構建,因此應該是不再支持Java1.4及更早版本了
2、框架結構的變化
框架結構的架構圖也進一步演變了,不再是原來那個簡單的方塊圖:

Spring3架構圖
跟原來的相比,DAO、ORM、JEE等模塊被劃歸到了一起,成為“數據訪問/集成”部分,Web層突出了自己的MVC(Servlet)和Portlet,核心容器增加了表達式語言。另外,對測試的支持也放到了整個架構中來了。所以整個框架重新劃分成了五部分。
因此,典型的全應用場景也相應變化,并提示使用自家的Tomcat:

關于eclipse的一些應用,開發過程中用到了就隨手記下。
1.Web App Libraries and Eclipse Build Path
在eclipse下創建web項目,在build path下會對應包含Web App Libraries 動態加載項目下/WebContent/WEB-INF/lib所有的jar文件。
好處是在項目增加或刪除jar包時不用總是修改build path配置文件,從cvs同步代碼的時候保持這部分不變。
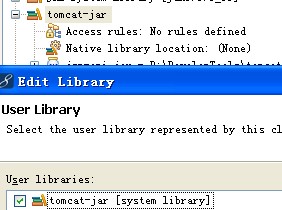
2.system library
有些jar在開發的時候要用到,但是部署的時候不用部署到服務器。
比如:jsp-api.jar,servelet.jar,這些文件在tomcat jboss 下已經包含,重復部署的話會引起錯誤。
我以前的做法是在anr build.xml文件中打包生成war時刪除對應的jar包。
剛發現還有這么一種用法,在eclipse添加system library把jar添加到該庫下就不會部署到服務器。
如圖:主要tomcat-jar 一定要設置成system library
關于在創業公司工作的話題,以前跟同事討論過,剛看到這么一篇,轉載一下。
有人在Quora問了這個問題:What startup could make me a millionaire in four years if I got hired as an emplyee today?
Symbolic Analytics的創始人Brandon Smietana在下面做了很長的回答,內容很精彩,不過請勿對號入座:
大多數創業公司的退出(exit),都是通過M&A(并購),而不是通過IPO(首次公開募股),現在大多數的M&A價格都低于3000萬美元,最典型的價格是1500萬美元,現在我們來假設一個最樂觀的退出案例,從其中的數據中算出,我作為創始人和CEO,能夠拿多少錢;從而計算出,你,作為一個員工可能賺得的利益。
(一)
假定案例
1)我拿到1000萬的投資。
2)投資人擁有公司50%的股權(樂觀估計)。
3)我將公司以3000萬的價格出售。
4)我擁有30%的外流通股(Outstanding Share) ,非常樂觀的估計。
投資人還擁有優先股,通過并購,他們首先把自己投入的錢收回來,然后再參與省下的股權收益分紅。
1)在3000萬的退出中,投資人首先拿回他們投入的1000萬,剩下2000萬。
2)然后,優先股股東吃掉省下2000萬的50%的利益分紅,于是他們拿走另外1000萬。
3)現在,整個脫售的現金只剩下1000萬,分享這份利益的關系者包括大眾股東,公司員工,創始人和管理團隊。
我,作為創始人和CEO,享有最多的普通股股權,價值這1000萬美元的大概600萬。省下的400萬利益歸屬其他所有的普通股股東(包括所有的公司員工)
最典型的早期員工,在利益分紅中能拿到的資產不足CEO的1/30,因此,一位非常重要的早期員工,能夠從脫售中取得20萬美元的利益。
現在,讓我設想得不那么樂觀,相對實際一點。70%進入A輪融資的創業者,除了工資,其他什么利益都無法從公司獲得。因此作為一名員工,
1)有70%的可能,如果你在A輪融資的時候加入創業公司,你的普通股是沒有價值的。
2)與A輪以前的早期員工相比,A輪以后的員工通過股權或者期權能拿到的利益要少很多。
3)在A輪融資以后,新員工能夠拿到的最好的股權大概在0.3%左右。
4)無論什么樣的員工,他們的股權都會在管理層更換或者新一輪融資中被稀釋。
(二)
如果我進入的公司是”下一個Facebook”呢?
硅谷在過去的十年里發生了驚天動地的變化。這些變化,同時作用并且影響著IT員工們能從公司那里獲取的利益。
如果你在1998年以前(包含1998年)加入了一家在將來很成功的創業公司,那你一定已經賺了很多錢。但是,如果你加入的是Facebook,你所能獲取的利益價值可能就無法跟前者媲美了。那么,那些加入“下一個Facebook“的哥們兒,希望可能就更小了,以下是原因:
谷歌的早期員工在加入時,谷歌的估值還很低。
1)谷歌的估值,一路從4000萬漲到了2000億。
2)那些最早加入谷歌的清潔工,從谷歌獲得價值1000美元的股權,在2008年也價值400萬美元。
3)一個獲得了5萬美元股權的工程師,他的股權在2008年價值1億美元。
4)谷歌的大廚也獲得了價值2800萬的股權。
有四點原因說明,谷歌的員工為何能夠金融上收益如此好:
1)他們在公司處于很低估值的時候獲得股票期權。
2)從A輪融資到現在,谷歌的估值漲了4000倍。
3)公司員工以人為的超低協議價格獲得購買期權(大概只相當于每股股價的1/10還要低),因為當時IRS(美國國稅局)的409(a)條款還不存在呢。
4)由于協議價格足夠低,因此員工在行權時,繳納的是資本利得稅15%(Capital Gain Tax),而不是收入稅50%(Income Tax treatment)。
當谷歌發行股票給他的員工時:
1)公司處于低估值階段,而非后來的頂峰估值階段。
2)那時,美國國稅局還沒有執行409(a)條款,409(a)條款明確規定了員工期權的估值。
在十年以前,創業公司都會以低于估值的協議價格發給員工期權,以吸引有識之士。員工因此有可能通過公司IPO而一夜致富,他們行權的協議價格大概之相當于估值價的1/10。
而到今天,這么做就是不合法的了。現在,公司的主管們,依據83(b)條款,依然有權通過限制性股票(restricted stock)獲得低估股票(undervalued stock);但是,現在獲得將理性期權(Incentive Stock Options)的員工,就必須遵循IRS的的409(a)條款。同時,現在的員工,在行權時更可能繳納50%的收入稅,而不是15%的資本利得稅。
隨著更高的早期估值,現在的員工已經不太有可能有現金能夠行權,而且也不太有可能繳納資本利得稅,一般都繳納收入稅。409(a)條款通過明確規定,也防止了員工行權價像十年前那么低。現在,一個創業公司的員工,如果行使價值200萬美元的ISO期權(國際標準期權),在繳納了加州稅或者德州稅之后,仍然可能面臨50%的收入稅。
一般情況下:創始人和主管們獲得的是依據83(b)條款的限制性股票(Restricted Stock),并且繳納的是15%的資本利得稅,員工則更可能時取得福利期權(Incentive Options), 稅率相對更高。
因此,作為一名員工,即便有一天你的公司被賣了,你也可能要繳納50%的收入稅。
200萬瞬間就只剩100萬,而現在,舊金山的房價是300萬。
(三)創業公司估值之于員工的影響
以前所有關于谷歌員工勝出的理由,現在都有可能不復存在了。
新的創業公司,如Facebook,獲得很高的早期估值,因此,早期員工能獲得的利益相比以前的創業公司,就少很多了。
更重要的是,現在只有越來越少的大型IPO,取而代之的是越來越多的小型M&A。
圖片一: 1992年 — 2009年 風險投資也IPO和M&A交易的比例
大多數公司并沒有谷歌和Facebook那樣做得很好。即便在Facebook,也只有一小部分員工積累財富。
Zuckerberg在Facebook的股權大致相當于Facebook所有非主管的員工股權的總和(24%vs30%).。前50個Facebook的非主管員工所獲得的股權,差不多相當于后面25000個員工的總和。
股權就是金字塔,越升一級,差俱就越大。
在一個以3000萬被并購的公司退出案例里(見上),一個很成功的M&A退出。公司的CEO也差不多只能賺600萬美元。
(四)創業領域與員工回報的關系
有很多創業公司扎根在大眾互聯網領域(Customer Internet Space), 但是這個領域的投資回報率也最低。就拿Facebook舉例(最成功的消費者互聯網公司之一),它從每一個月度活躍用戶那里只能產生3美元/年的利益。
很少的大眾互聯網公司能夠通過廣告獲得盈利,像Ad.ly, Digg, Myspace, Twitter,還有很多其他的公司都很難達到大規模盈利,即便是用戶量非常龐大。
一個大眾互聯網公司,如果每個月的活躍用戶數有50萬,依照Facebook的盈利推算,一年的盈利也只有150萬美元。因此,不要把大眾互聯網當做救命稻草。
現如今,B2B/SaaS模式,以及生物技術市場,仍然能夠在市場上攫取上億的資金,但是,很少有人能有能力和經驗在這個市場里把公司做起來。但是,在這領域,卻有比大眾互聯網市場更多的盈利機會。
最有盈利空間的市場,最難發現創業公司。特別是,金融領域每年攫取的利潤占全美公司利益的70%,但是,在硅谷卻很難發現金融創業公司,即便有,也基本是大眾金融服務。
Protip: 從數據和理論上看,如果你是A輪以后加入大眾互聯網公司的員工一枚,你的股權幾乎就不值錢了。
Hadoop最近很火,到處都能看到,查了一下資料大概先了解一下其運行原理。
google在05年公開了Map/Reduce論文,MapReduce在處理巨量數據方面有明顯優勢。
google公司一個技術大牛jefffery Dean提出的這個算法,隨后很多小牛紛紛實現了Mapreduce,Hadoop是它的java實現,MapReduce概念直接推動了云計算概念的火爆。
沒有優秀算法云是沒法搞的。
這篇文章對Map/Reduce原理講的很清楚。
http://www.chinacloud.cn/download/Tech/MapReduceOverview.pdf
這個是Apache關系Hadoop的文檔,安裝、開發示例都有。
http://hadoop.apache.org/common/docs/r0.19.2/cn/mapred_tutorial.html
因為一直在做企業信息化方面的開發,有必要了解一下相關的理論。
同事推薦的幾本書。
霍頓(F.W.Horton)的信息資源管理(IRM)理論
威廉。德雷爾的數據管理(DA)理論
詹姆斯馬丁的信息工程方法論(IEM)
看了之后有些吃驚,很多概念和理論都是上世紀80年代,還有60年代就提出的概念,做了這么久的開發居然沒聽說過,在規劃方面沒有一定的理論指導,都是些野路子方法。
還有許多平時用到的概念和方法找到了淵源,原來是這哥們或那哥們提出,老外的版權意識就是強對幾十年前提出的理論都會整理出哪個觀點是哪個人提出的。
不然很多方法一直覺得理所當然是那么用的,看過這些資料才知道理論提出的背景,除了這種理論解決哪些問題還有哪些方法,各有什么優缺點。
信息工程理論總結起來,就是以數據規劃為基礎,自定向下規劃。并提供了一系列的技術用于自下向上的設計方法。對企業信息化中比較重要的業務流程有很大的篇幅。
目前的收獲是,1.在系統規劃方面有了完整的理論指導;2.了解了規劃、分析、設計階段會有哪些技術,哪些已掌握的技術需要加強、哪些技術需要學習。
老外的書翻譯過來的在中文版看著費勁,找了本國內編譯出版的,寫得不錯。
信息工程與總體規劃概述。
本書討論計算機信息系統總體規劃的方法論,重點是總體數據規劃。
第一章是本文的綜述,目的是使讀者盡快了解信息工程概念和總體數據規劃方法的大意,因此是全書的提綱。
第二章到第四章是信息工程產生的背景和方法論的分析。這三章按三個主題展開:數據處理危機與轉折;信息工程的原理、方法與工具;信息工程與結構化方法。
第五章到第十章比較全面深入地介紹總體數據規劃的一整套方法,是本書的主體。編者根據近幾年參與中大型企業計算機信息系統總體規劃設計工作的實踐,深感探討先進科學的方法論的極端重要性,特別是總體數據規劃的內容、方法,以及與后續開發工作的銜接等問題,更是迫切需要解決的。為此,我們較全面地翻譯介紹了詹姆斯·馬丁所倡導的一整套方法,供有興趣的讀者參考,從而盡快形成適合我國國情的總體規劃方法論。
第一章
從需求分析開始的傳統生命周期開發方法論
數據結構和數據是相對穩定的,而數據的處理過程則是經常變化的。總體數據規劃方法。
軟件工程僅僅是關于計算機軟件的規范說明、設計和編制程序的學科,實際上信息工程的一個組成部分。
信息工程的基本原理和前提是:
1.數據位于數據處理的中心。
2.數據是穩定的,處理是多變的。數據類型是不變的。
只有建立的穩定的數據結構,才能是行政管理或者業務管理上的變化為計算機信息系統所適應,這正是面向數據系統所具有的靈活性,面向過程系統往往不能適應管理上的變化需求。
3.用戶必須真正參與開發工作。Design with,not design for.
第二章
信息工程的組成部分
自定向下規劃和自下向上設計方法論
重點分為三個部分:
企業模型、實體關系分析和數據模型的建立(即主題數據庫的規劃),以及數據分布規劃。
總體數據規劃簡介
四類數據庫環境
1.數據文件;
2.應用數據庫
3.主題數據庫
4.信息檢索系統
規劃方法
1.進行業務分析建立企業模型
2.進行實體分析建立主題數據庫模型
3.進行數據分布分析
第三章
信息工程概貌
1.關于全面開放的規劃
2.關于業務分析
3.關于數據分析,數據可以表達成與使用無關
4.關于自動化工具
信息工程的基本組成
1.企業模型,企業模型的開發是在戰略數據規劃期間進行的。
2.借助實體關系分析,建立信息資源規劃。這是自頂向下的數據類型分析,這些數據是必須被保存起來的,還要分析他們之間是如何聯系的。
3.數據模型的建立,產生詳細的數據庫邏輯設計
導致信息工程產生的一個重要認識,是組織中存在的數據可以描述成與這些數據如何使用無關的形式,而且數據需要建立起一定的結構。這一點較面向對象的思想很接近,可以把數據模型任務是數據對象。
信息工程的建設基礎
戰略的數據規劃工作
信息工程方法論
1.關于企業信息化戰略規劃的方法
2.關于信息系統設計實現的方法
3.關于自動化開發工具
第四章結構化方法與信息工程
信息工程是在進行戰略需求規劃,信息需求規劃,總體數據規劃和數據分布規劃的基礎上,使用結構化設計和結構化編程的方法。
結構化系統分析
數據流圖
結構化系統設計
信息工程是面向數據的方法,結構化方法是面向過程的方法。前者可以使用未來,后者只能使用過去和現在。
戰略需求規劃
戰略需求規劃是信息工程的基礎工作,不僅要對現有需求規劃,還要對未來需求規劃。
1.加強用戶之間的溝通合作。
2.加強高層領導者之間的溝通并為之提供支持。
3.提高資源需求預測和分配的準確性。
4.提供內部mis的可行點。
5.提出新穎而高質量的應用系統。
信息需求規劃
信息需求:
1.事務處理工作的管理信息需求;
2.高層領導者的管理信息需求;
3.企業發展和改革發展方面的信息需求;
傳統的軟件工程和數據庫技術盡管有分析設計方法,但缺乏自頂向下的規劃,不能適應大型復雜系統的建設。信息工程強調總體規劃,形成了一套自頂向下規劃與自下向上設計的完成的方法學,為大型復雜系統的建設提供了保障。
第五章總體數據規劃的組織
戰略規劃
1.戰略業務規劃
2.戰略信息技術規劃
3.戰略數據規劃
戰略數據規劃,即總體數據規劃是信息工程規劃工作的核心和基礎,需要研究它的組織方法。
戰略規劃的目的是使信息系統的各部分能共同工作。
對戰略規劃的詳細程度要有恰當的理解。
第六章 企業模型
..........................
今天看了五章的內容,休息一下。
忙完手頭工作繼續學習,2012-2-28
總體數據規劃的第一步是進行業務分析,建立企業模型。(編者按:目前電信行業都已經建立起了完善的企業模型,其他行業還沒看到)
企業模型是對企業結構和業務活動 本質的、概況的認識。
用職能區域--業務過程--業務活動 這樣的層次結構來描述。
1.研制一個表示企業各職能區域的模型;
2.擴展上述模型,使它能表現企業的各項業務過程;
3.繼續擴展上述模型,使它能夠表現企業的各項業務活動。
依靠企業高層,分析企業的現行業務和長遠目標,按照企業內部的各種業務的邏輯關系,將他們劃分為不同的只能區域,弄清各職能區域包括的全部業務過程,再將各個業務過程細分為一些業務活動。
建立分析企業模型的過程,是對現行業務系統再認識的過程。
職能區域
職能范圍、業務范圍,是指一些主要的業務活動區域,如銷售、市場、財務、認識、生產。
職能模型,職能區域圖表
業務過程
企業模型的二級結構是業務過程的識別、命名、定義。這項工作主要由分析人員來完成。
1.業務過程與組織結構
2.識別業務過程的參考模式
產品、服務和資源四階段生命周期
計劃,獲得,保管,處置(編者按:原書有一張圖表,這里就不列出來了),模式的每一階段都有一些業務過程的類型。
3.業務過程與負責人
4.經驗
業務活動
每個業務過程中都存在一定數量的業務活動
業務活動分析
1.功能分解的程度
2.凝聚性活動,1.產生清晰可識別的結果,2.有清楚的邊界,3.是一個執行單元,4.自封閉的,獨立于其他活動。
3.冗余活動和功能組合,
企業模型的建立過程
可以理解為邏輯模型
企業模型的特點
完整性、適用性、永久性
關鍵成功因素
3~6個決定成功與否的因素
1.關鍵成功因素的確定
關鍵成功因素應該成為最高層管理人員管理控制企業系統的基礎,對一個行業來講關鍵成功因素差不多是相同的。
如食品公司:廣告效果,貨物分發,產品革新
2.關鍵成功因素的審查
第七章主題數據庫
獨立于應用的數據
數據庫環境的原則
1.企業的數據應該得到直接管理,與使用的職能分開;
2.數據描述不應由使用數據的應用包含,而應當由獨立的數據管理員設計;
3.數據應該獨立于現有機器資源;
4.使用統一的工具和設施管理資源;
5.有適當的安全和保密控制;
6.高層管理人員要參與數據庫的總體規劃和決策。
面向過程的系統分析方法
面向數據的系統分析方法
主題數據庫與組織內各類人、事、物相關,而不是與傳統的應用相關。
總的來說這部分沒什么干貨,就是對前面方法論的細化和再次說明。
這本書側重于方法論和理論概念。在規劃部分有具體的指導,在具體分析和設計技術上著墨不多。
第八章實體活動分析
第九章數據分布規劃
第十章規劃與開發建議
這兩天比較忙,后邊章先顧不上看了。
第八章和第九章應該跟軟件工程里的內容是一致的,原來項目開發時經常要用到。第十章討論BSP方法,要了解一下。
因為項目需要做了一個簡單的工作流引擎,用于集成訂單管理(IOM)的生產調度。之前的文章有提到。原想著有這樣一個引擎來進行生產調度,設計好業務流程后就可以面朝大海,春暖花開。在還生產系統對接的時候發現有一部分還是人工處理更好,畢竟不是所有的流程都能那么細致合理。
下面是我們的解決方案,圖片是從wps里另存出來的,不知道咋就變成黑底了。
1.1 問題描述
工作流引擎處理流程調度部分的內容。客戶下訂單之后,協調各生產部門進行工作。
最理想化的情況是對客戶發起的每一種操作都定義一組流程,在流程執行的過程中每種狀下態當有新的操作進來也相應定義一組流程,但這樣一來流程設計工作極其繁瑣,容易出錯,不利于降低管理難度減輕管理工作量。
一個折中的方案是對執行中的流程進行流程合并。選擇對一部分操作不創建新流程,給用戶提示信息,由用戶覺得如何進行手工操作。
1.2 問題分析
1.2.1 概念定義
生產平臺:生產平臺是由人和機器構成的,能將一定輸入轉化為特定輸出的有機整體。對應于工廠中的生產車間概念。
生產線:生產是與相關的一個部門或一組操作對應的組織。類似于項目組的概念,是依據生產流程對生產能力的一種劃分方式。
產品:產品是指中企動力運用營銷手段,將業務或業務組合附加上銷售對象、銷售地域、資費計劃、銷售渠道、服務水平及配套資源屬性后的產物,是向客戶最終交付的、客戶可以購買的產品單元組合實例。
產品單元:產品單元是業務在生產系統的具體表現。
產品單元與生產線之間是多對多的關系。如果一個產品單元需要跨多個生產線,引擎需要調度產品單元在不同生產線的生產過程。
流程組:流程組指由一系列操作流程組成的流程集合,有流程間的先后順序。流程組在此是由產品和操作類型共同決定的。
流程:流程是一系列操作環節的集合。環節間有并行和串行的關系。流程在此處是由平臺和操作類型決定的。
環節:環節是一系列操作的集合。環節此處定義是由一個人的一個或多個可并行的操作決定的。
任務:任務是可執行的最小單位。任務具有原子性,是環節的組成部分。一般一個任務完成一個事務。
一個環節包含多個任務,一個流程包含多個環節,一個流程組包含多個流程。
1.2.2 問題描述
以一件定制服裝的過程為例,只是為了說明問題對流程做了簡化。見下圖。
定制服裝生產流程:

最簡化的情況,客戶在提交了定制服裝生產的要求后便不再干預,生產線就按流程走就可以了。
但是客戶可能會在生產的各個環節提出變更要求,已經制作完成了客戶要求加個兜,已經質檢完成了客戶要求加個紐扣,已經包裝好了客戶要求領子樣式改改。
如果把每一種可能都定義一組流程,就這個簡化流程全部列出來也夠貼一面墻了。所以我們采取了一種折中的方案,在大多數情況下正在生產時客戶要求有變化,通過一個描述性的工單告訴生產線負責人暫停生產、并由負責人來決定回退到那個環節重新進行。
如果都包裝好了客戶還要改,那就暫停當前流程,走和客戶打官司的流程了,這種情況下需要一個流程。
本方案通過對生產中的流程進行合并,減少流程定義的工作量和復雜程性度。
1.3 問題解決
1.3.1 工單
1.3.1.1 邏輯模型
訂單生成工單的過程,稱為合單。
|
訂單工單關系 |
工單屬性 |
|

|

|
現在所描述的都是對同一個訂購實例所下各種訂單的合單處理情況。
1.訂購實例第一次下訂單,根據訂單生成工單和工單明細。
2.訂購實例第二次下訂單
a) 之前生成的工單已經竣工,生成新工單和新工單明細。
b) 之前生成的工單還未生產,廢棄該工單,生成新工單和新工單明細
c) 之前生成的工單生產中,廢棄該工單,繼續沿用原工單編號,合并生成新工單和新工單明細。新工單狀態為生產中。
在工單明細表增加字段“產品單元變更標識”,如果產品單元對應的屬性內容在兩次訂單中沒有變化,引擎不暫定產品單元觸發的流程。
1.3.2 流程實例化
1.3.2.1 邏輯模型
流程定義模型見下圖,概念定義部分對名詞有描述。
|
流程定義 |
流程實例化 |
|

|

|
在業務支撐系統經常使用的一個概念,實例化。
用戶購買一個產品后,就產生一個產品的實例化,區別于別的客戶購買的同類產品,稱為訂購實例。
定義一組流程用來處理產品生產過程,具體到某個訂購實例的生產過程的實例化,就有了流程組實例、流程實例、環節實例和任務實例。
1.3.2.2 流程定義過程
有了流程定義的模型,我們就是可以設計或者叫定義產品的生產流程。
完成一件復雜的工作,總是需要一個步驟一個步驟的完成,每個步驟稱為一個環節,在這個環節下可能需要做幾個事情,每個要做的事情稱為一個任務。
1.根據生產部門劃分生產線
2.根據生產線+操作,定義流程,把流程中的任務根據負責人劃分為不同的環節。
3.按照產品涉及的流程劃分為不同的流程組。
1.3.2.3 流程實例化
1.實例化約束
a) 一個訂購實例當前只有一個運行中的流程組實例;
b) 流程合并前先暫停,避免和引擎并發競爭。
2.實例化過程
a) 接收工單,檢查訂購實例當前是否有流程組實例在運行中;
i. 無,實例化一個新的流程組實例
ii. 檢查是否屬于同一個流程組定義
1. 是同一個流程組,進行流程合并。
2. 不是同一個流程組,暫不實例化,待下一次輪詢再處理。
流程合并細節見《流程合并詳細設計》
1.3.3 流程引擎
1.3.3.1 模型狀態
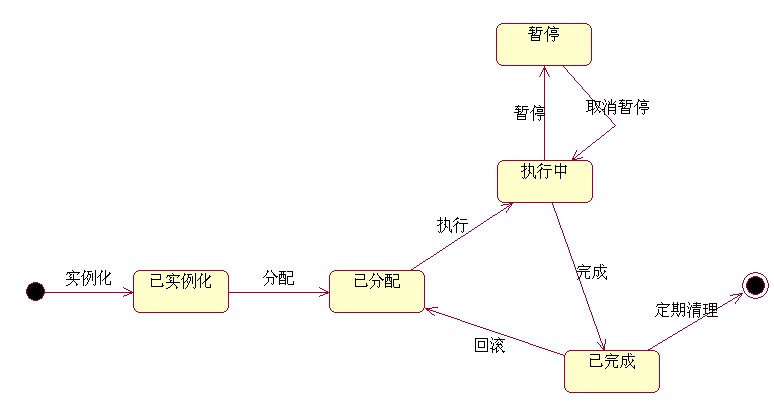
1.已實例化
2.已分配(負責人)
3.執行中
4.暫停
5.已完成
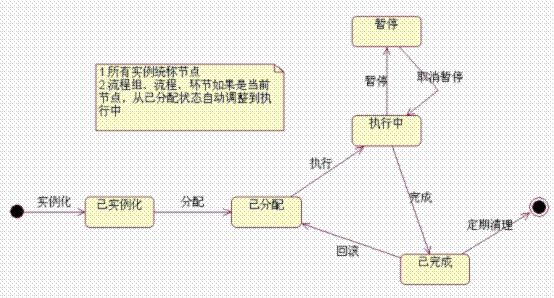
流程啟動后按順序執行,當要回到上一步驟時,監控頁面支持回退和回滾兩種操作。
回退,當前執行中/暫停的環節設置為已分配,上一環節由已完成設置為執行中。
回滾,對任務可以執行其反任務。
1.3.3.2 功能描述
1.引擎輪詢程序,檢查處于執行中狀態的環節,如果環節下所有關鍵任務都已完成則環節進入已完成狀態,下一環節進入執行中狀態。
2.環節實例化后處于已實例化狀態,用戶在任務分配頁面指定環節負責人,環節處于已分配狀態,上一環節完成后由引擎設置本環節進入執行中狀態。
3.鑒于引擎對執行中的環節進行調度工作,實例化程序和頁面監控程序在對執行中的環節操作時,需先暫停環節。
4.監控頁面支持對流程、環節的回退,支持對任務的回滾。
之前做了一個簡單的工作流引擎,干完了活做點理論總結。
項目見
工作流應用---理論基礎篇、
工作流應用---概念、模型這個工作流引擎主要是根據項目需求和網上看到的一些文章提到的概念做出來的,估計比較野路子,想著把概念和名詞向大師靠攏。
過了年剛來不忙,這幾天抽空看了兩本工作流方面的書,《工作流管理技術基礎》和《工作流管理:模型、方法和系統》,講的比較細致、對基礎概念講的很清楚,就是書老了點。
書中對XPDL標準做了詳細描述,對新出的BPEL沒有涉及。
我自己項目中用到的概念和大師們基本一致,大方向不錯,看來網上找到的那幾篇文章挺靠譜的,當時應該隨手整理出來。
工作流引擎做的比較簡單,沒有使用主流的petri技術,只支持項目需求更負責的需求就夠嗆了,回頭有空再改一版。看了書才發現有這么多種模型實現方法早都有人研究很多年了。
這兩本書在超星網站都能找到電子版。
IPO模型,過程中的每一個活動都由輸入(I)、處理(P)、輸出(O)三部分組成。
理論來自《科學管理》提出的科學管理原則:
一個組織的工作可以描述為一系列的任務,每個任務都是工人們具體、嚴謹的活動過程,管理就是在一定的計劃下讓這些任務以最優的方式進行。
常用的工作流模型:
1.基于活動網絡的過程模型
組成模型的元素包括過程、活動、模塊、控制連接弧、數據連接弧和條件。
以活動作為構成過程的基本單元,以連接弧體現過程邏輯,可以靈活的實現企業經營過程的建模,我做的那個基本上采用的就是這種模型。
過程:為完成目標而定義的一系列步驟;
活動:過程中的步驟;
模塊:跟過程的概念類似;區別在于是否可以多次重復使用
控制鏈接弧:定義兩個活動間的執行順序
數據連接弧:定義兩個活動間的信息流
條件:定義過程執行中的約束
定義在控制連接弧上的條件:轉移條件
活動可以執行和活動被執行:開始條件、結束條件。
優點:
從系統分析的角度來看,有利于通過過程模型提取功能視圖和信息視圖、便于深入分析
從系統實現的角度來看,控制流管理和數據流管理分離,是不同性質的流管理獨立。
2.事件驅動的過程鏈模型
兼顧模型描述能力強和模型易讀兩個方面。
業務事件、業務功能、控制流、邏輯操作符、信息對象、組織單元
3.基于語言行為理論的工作流模型
IPO模型對于觀察信息和物流的流動過程比較合適,但不利于不同角色間的委托和承擔行為。
語言行為理論則側重與解決,數據、物、人協作中IPO模型對人直接協作描述不足的情況。
聽上去不錯,實際中沒有看到用這種模型的,google了一下相關資料,還只是一個理論在軟件領域用來進行協作過程建模的很少。
簡單了解一下先,等大師們研究明白了咱再學習。
4.基于petri網的工作流模型
這個東西看著挺復雜的,不過好多人都說是好東西,研究一下先。
找了兩本有關petri的書,都太理論化看不懂。還是《工作流管理:模型、方法和系統》講得比較通俗。
petri基本概念很好理解,不同于過程化分析,更接近面向對象的思想。看起來我在這個項目中采用的分析方法更接近與petri,原來俺們樸素的想法跟大師很接近哦。
一般的面向對象分析更側重與靜態結構,在動態模型部分描述的都不夠清楚。petri在動態過程方面感覺很細致有效。據說還是經過嚴格熟悉驗證的分析方法,不過那些公式沒看懂,太費勁。分析時用petri分析建模方法就可以了。
.....
上一篇講了工作流的主要概念和用途。
知道了要依靠工作流引擎來推動流程向前。
這一篇講一個具體實現的例子,比較簡單,對于復雜的流程關系定義處理不了,上下文參數構建也不支持,這些依賴具體的業務領域模型處理了。
好在工作流基本的概念是有了,對于復雜的應用可以借鑒成熟的產品,知道工作流是怎么回事了其他產品也就容易上手了。
工作流概念這一塊,目前也沒個統一規范,就自己搞了一套,沒采用那些推薦標準太復雜用不上。
要開發一個工作流引擎出來,跟其他開發沒有不同,概念、需求、建模。
一、搞清楚都要用到哪些概念
二、能夠提供哪些功能、準備用例
三、建模
1.靜態模型
依據關鍵流程的用例推導概念、明確概念定義、支持概念所要用到的數據結構
2.動態模型
定義各功能模塊操作,并檢查是否覆蓋所有關鍵用例。
實際例子,懶得敲那么多字了,直接上圖
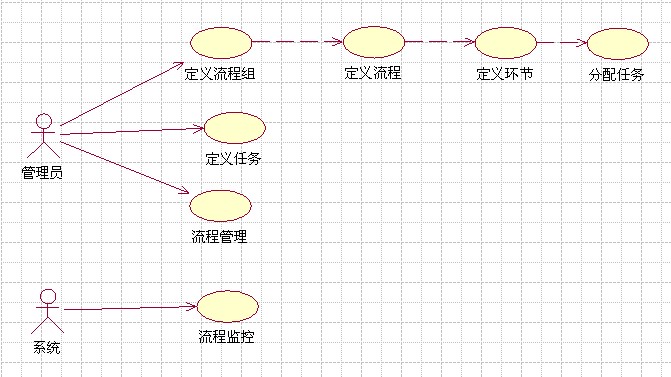
1.用例,用來確定系統邊界
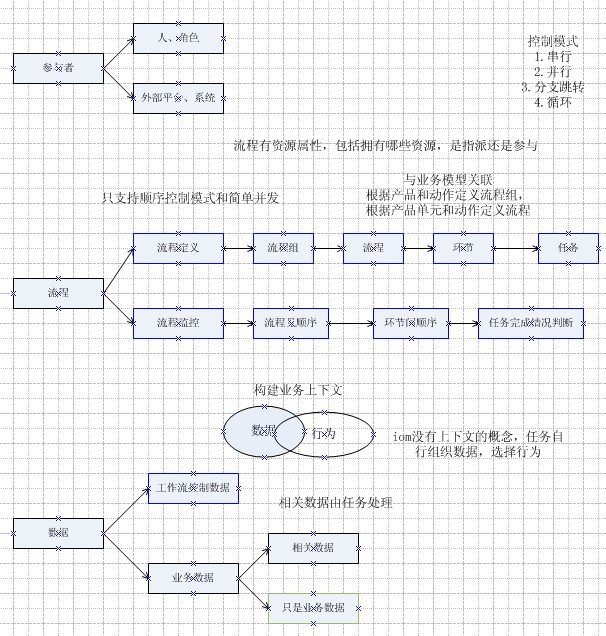
2.主要概念,及概念見關系
3.流程生命周期定義
說明一下,分配狀態和運行狀態是兩個維度的東西,為了省事就定義在一起了。
4.系統架構
描述引擎的內部構成、引擎與外圍系統的關系。
這段時間因為項目需要做了一小的工作流引擎,總結一下經驗。
大概會分為這么幾個階段來介紹。
1.理論基礎
2.實現技術
3.實際開發的一個例子。
如圖:
 一、理論基礎
一、理論基礎
只是簡單的討論原理,詳細數學理論不再這里討論,會在附錄里列出來,有興趣的同學自行查看。
1.概念
為了實現業務過程自動化提出的概念。
以前去政府部門辦過事大家都有體會,那個迷茫啊困惑啊,很多連個辦事指南都沒有。
辦一件小事要蓋十幾個章,材料交上去后你根本不知道現在到了哪個部門,審核通過了沒人通知你,沒通過的話少什么資料也不告訴你,告訴你也不是一次都說,跑一趟說一點。通過了這個部門審核下一步應該去哪也沒人告訴你。
這個時候有個對機關門清的人,知道哪里水深水淺,領著你辦下來該有多好,該請客請客該送禮送禮,少跑很多冤枉路,還能隨時查詢狀態。
這就是工作流引擎要做的事情。
2.發展歷史
工作流技術起源于二十世紀七十年代中期辦公自動化領域的研究,由于當時計算機尚未普及,網絡技術水平還很低以及理論基礎匱乏,這項新技術并未取得成功。
老外也是被扯皮扯怕了試圖改進。
3.作用目標
工作流將作為一個公共基礎子系統服務于整個平臺產品的人力工作流和業務工作流環節。
通過將工作活動分解成定義良好的任務、角色、規則和過程來進行執行和監控,達到提高生產組織水平和工作效率的目的。
人多了事情多了,扯皮的情況也就多了。為了避免扯皮建立一個協調中心,提供辦事指南,負責進度管理,公共信息維護。
處理這種有復雜流程的事情目前有兩種解決思路:
1.針對業務領域開發一個系統,一個模塊處理完成一件事件后根據情況來決定下一步跳到哪個模塊,帶點什么參數。適應于流程比較固定的業務,像財務系統雖然很復雜,但是各種處理規則都清清楚楚明明白白,也不會隨便變動。
2.工作流方式,講流程跳轉規則由工作流引擎統一維護,每個具體執行任務的模塊只管干自己的活,干完了告訴一聲引擎,由引擎通知下一個模塊。目前只能處理相對簡單的一些工作流程,OA公文流轉,IOM生產系統調度這類規則不是很復雜,流程上下文較簡單的情況。
對于特別復雜的流程,開發量反而比定制業務系統還要多。工作流理論需要再有一次提升才能解決這個問題。
4.體系特點
可維護性和可擴展性
與業務系統實際關聯低偶合
可以擴充表達式引擎,與界面綁定由界面引擎決定
可以適應與審核等人力流程,也可以適用在無人干預的商業自動化流程
安全性
易用性
5.模型表示
用例模型
應用用例
擴展用例
分析模型
架構性重要分析元素
架構性重要用例實現
設計模型
組件結構
部署結構
6.定義語言
7.參考資料