Apache Shiro 架構
ApacheShiro的設計目標是使程序的安全變得簡單直觀而易于實現,shiro的核心設計參照大多數用戶對安全的思考模式--如何對某人(或某事)在與程序交互的環境中的進行安全控制。
程序設計通常都以用戶為基礎,換句話說,你經常以用戶可以(或者應該)如何與軟件交互為基礎來設計用戶接口或者服務API,例如,你可能說,“如果當前與我程序交互的用戶已經登錄了,我將展示一個按鈕給他,他可以點擊去查看自己的賬戶住處,如果他們沒有登錄,我將顯示一個注冊按鈕。”
這個陳述例子指出我們開發程序很大程度上是為了滿足用戶的需求,即使“用戶(User)”是另外一個軟件系統而并非一個人,你仍然要寫代碼對當前與你軟件交互的誰(或者什么)的動作進行回應。
shiro從它的設計中表現了這種理念,為了與軟件開發者的直覺相配合,Apache Shiro在幾乎所有程序中保留了直觀和易用的特性。
概覽
在概念層,shiro架構包含三個主要的理念:Subject,SecurityManager和Realm。下面的圖展示了這些組件如何相互作用,我們將在下面依次對其進行描述。

subject:就像我們在上一章示例中提到的那樣,subject本質上是當前運行用戶特定的'view',而單詞“user”經常暗指一個人,subject可以是一個人,但也可以是第三方服務、守護進程帳戶、時鐘守護任務或者其它--當前和軟件交互的任何事件。
subject實例都和(也需要)一個SecurityManager綁定,當你和一個subject進行交互,這些交互動作被轉換成SecurityManager下subject特定的交互動作。
SecurityManager:SecurityManager是Shiro架構的核心,配合內部安全組件共同組成安全傘。然而,一旦一個程序配置好了SecurityManager和它的內部對象,SecurityManager通常獨自留下來,程序開發人員幾乎花費的所有時間都集中在Subjet API上。
我們將在以后詳細討論SecurityManager,但當你和一個Subject互動時了解它是很重要的。任何Subject的安全操作中SecurityManager是幕后真正的舉重者,這在上面的圖表中可以反映出來。
Realms:Reamls是Shiro和你的程序安全數據之間的“橋”或者“連接”,它用來實際和安全相關的數據如用戶執行身份認證(登錄)的帳號和授權(訪問控制)進行交互,shiro從一個或多個程序配置的Realm中查找這些東西。
Realm本質上是一個特定的安全DAO:它封裝與數據源連接的細節,得到shiro所需的相關的數據。在配置shiro的時候,你必須指定至少一個Realm來實現認證(authentication)和/或授權(authorization)。SecurityManager可以配置多個復雜的Realm,但是至少有一個是需要的。
Shiro提供out-of-the-box Realms來連接安全數據源(或叫地址)如LDAP、JDBC、文件配置如INI和屬性文件等,如果已有的Realm不能滿足你的需求你也可以開發自己的Realm實現。
和其它內部組件一樣,ShiroSecurityManager管理如何使用Realms獲取Subject實例所代表的安全和身份信息。
詳細架構
下面的圖表展示了Shiro的核心架構思想,下面有簡單的解釋。
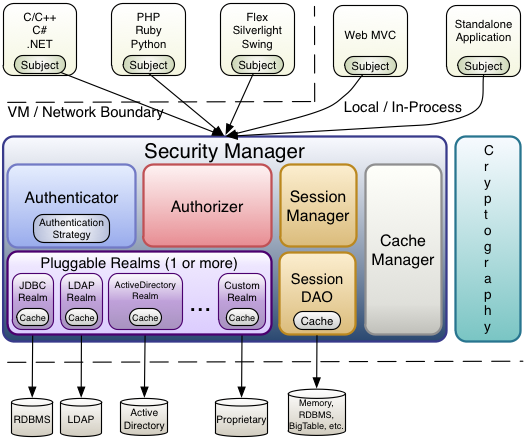
Subject (org.apache.shiro.subject.Subject)
正在與軟件交互的一個特定的實體“view”(用戶、第三方服務、時鐘守護任務等)。
SecurityManager(org.apache.shiro.mgt.SecurityManager)
如同上面提到的,SecurityManager 是Shiro的核心,它基本上就是一把“傘”用來協調它管理的組件使之平穩地一起工作,它也管理著Shiro中每一個程序用戶的視圖,所以它知道每個用戶如何執行安全操作。
Authenticator(org.apache.shiro.authc.Authenticator)
Authenticator是一個組件,負責執行和反饋用戶的認證(登錄),如果一個用戶嘗試登錄,Authenticator就開始執行。Authenticator知道如何協調一個或多個保存有相關用戶/帳號信息的Realm,從這些Realm中獲取這些數據來驗證用戶的身份以確保用戶確實是其表述的那個人。
Authentication Strategy(org.apache.shiro.authc.pam.AuthenticationStrategy)
如果配置了多個Realm,AuthenticationStrategy將會協調Realm確定在一個身份驗證成功或失敗的條件(例如,如果在一個方面驗證成功了但其他失敗了,這次嘗試是成功的嗎?是不是需要所有方面的驗證都成功?還是只需要第一個?)
Authorizer(org.apache.shiro.authz.Authorizer)
Authorizer是負責程序中用戶訪問控制的組件,它是最終判斷一個用戶是否允許做某件事的途徑,像Authenticator一樣,Authorizer也知道如何通過協調多種后臺數據源來訪問角色和權限信息,Authorizer利用這些信息來準確判斷一個用戶是否可以執行給定的動作。
SessionManager(org.apache.shiro.session.mgt.SessionManager)
SessionManager知道如何創建并管理用戶Session生命周期而在所有環境中為用戶提供一個強有力的Session體驗。這在安全框架領域是獨一無二--Shiro具備管理在任何環境下管理用戶Session的能力,即使沒有Web/Servlet或者EJB容器。默認情況下,Shiro將使用現有的session(如Servlet Container),但如果環境中沒有,比如在一個獨立的程序或非web環境中,它將使用它自己建立的session提供相同的作用,sessionDAO用來使用任何數據源使session持久化。
SessionDAO(org.apache.shiro.session.mgt.eis.SessionDAO)
SessionDAO代表SessionManager執行Session持久(CRUD)動作,它允許任何存儲的數據掛接到session管理基礎上。
CacheManager(org.apache.shiro.cache.CacheManager)
CacheManager創建并管理其它shiro組件的catch實例生命周期,因為shiro要訪問許多后端數據源來實現認證、授權和session管理,caching已經成為提升性能的一流的框架特征,任何一個現在開源的和/或企業級的caching產品都可以插入到shiro中實現一個快速而有效的用戶體驗。
Cryptography (org.apache.shiro.crypto.*)
Cryptography在安全框架中是一個自然的附加產物,shiro的crypto包包含了易用且易懂的加密方式,Hashes(亦即digests)和不同的編碼實現。該包里所有的類都亦于理解和使用,曾經用過Java自身的加密支持的人都知道那是一個具有挑戰性的工作,而shiro的加密API簡化了java復雜的工作方式,將加密變得易用。
Realms (org.apache.shiro.realm.Realm)
如同上面提到的,Realm是shiro和你的應用程序安全數據之間的“橋”或“連接”,當實際要與安全相關的數據進行交互如用戶執行身份認證(登錄)和授權驗證(訪問控制)時,shiro從程序配置的一個或多個Realm中查找這些數據,你需要配置多少個Realm便可配置多少個Realm(通常一個數據源一個),shiro將會在認證和授權中協調它們。
SecurityManager
因為shiro API鼓勵以Subject為中心的開發方式,大部分開發人員將很少會和SecurityManager直接交互(盡管框架開發人員也許發現它非常有用),盡管如此,知道SecurityManager如何工作,特別是當在一個程序中進行配置的時候,是非常重要的。
設計
如前所述,程序中SecurityManager執行操作并且管理所有程序用戶的狀態,在shiro基礎的SecurityManager實現中,包含以下內容:
認證(Authentication)
授權(Authorization)
會話管理(Session Management)
緩存管理(Cache Management)
Realm協調(Realm coordination)
事件傳導(Event propagation )
"RememberMe" 服務("Remember Me" Services)
建立Subject(Subject creation)
退出登錄(Logout)
及其它。
但這些功能都在一個單獨的組件中管理,并且,當所有功能集中在一個類中實現是靈活和可定制是非常困難的。
為了實現配置的簡單、靈活、可插拔,shiro在設計時實現了高模塊化--盡管模塊化,SecurityManager(包括它的繼承類)并沒有做到,相反地,SecurityManager實現更像一個輕量級的‘容器(container)’,代表幾乎所有嵌套/封裝組件的行為,這種‘封裝(wrapper)’設計在上面的架構圖表中已有反映。
當組件執行邏輯的時候,SecurityManager知道如何以及何時去協調組件做出正確的動作。
SecurityManager和JavaBean兼容,這允許你(或者配置途徑)通過標準的JavaBean訪問/設置方法(get*/set*)很容易地定制插件,這意味著shiro模塊可以根據用戶行為轉化成簡易的配置。
簡易的配置
因為適合JavaBean,任何支持Javabean配置的組件都有非常簡單的途徑配置SecurityManager,如Spring、Guice、JBoss,等等。
我們將在下一節討論配置(Configuration )
為文檔加把手
我們希望這篇文檔可以幫助你使用Apache Shiro進行工作,社區一直在不斷地完善和擴展文檔,如果你希望幫助shiro項目,請在你認為需要的地方考慮更正、擴展或添加文檔,你提供的任何點滴幫助都將擴充社區并且提升Shiro。
提供你的文檔的最簡單的途徑是將它發送到用戶論壇(http://shiro-user.582556.n2.nabble.com/)或郵件列表(http://shiro.apache.org/mailing-lists.html)
原文地址:http://shiro.apache.org/architecture.html