一、Memcache內存分配機制
關于這個機制網上有很多解釋的,我個人的總結如下。
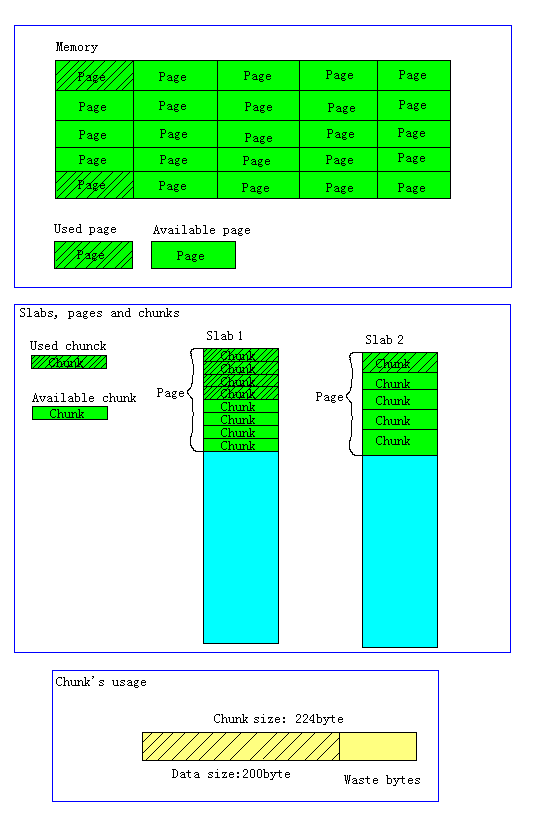
- Page為內存分配的最小單位。
Memcached的內存分配以page為單位,默認情況下一個page是1M,可以通過-I參數在啟動時指定。如果需要申請內存時,memcached會劃分出一個新的page并分配給需要的slab區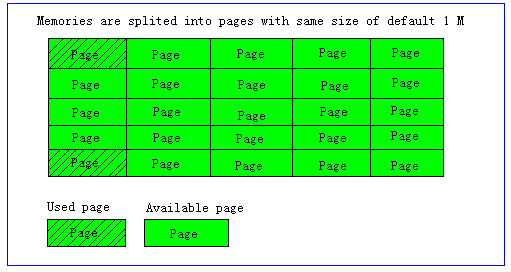
-
-
-
-
域。page一旦被分配在重啟前不會被回收或者重新分配(page ressign已經從1.2.8版移除了)
- Slabs劃分數據空間。
Memcached并不是將所有大小的數據都放在一起的,而是預先將數據空間劃分為一系列slabs,每個slab只負責一定范圍內的數據存儲。如下圖,每個slab只存儲大于其上一個slab的size并小于或者等于自己最大size的數據。例如:slab 3只存儲大小介于137 到 224 bytes的數據。如果一個數據大小為230byte將被分配到slab 4中。從下圖可以看出,每個slab負責的空間其實是不等的,memcached默認情況下下一個slab的最大值為前一個的1.25倍,這個可以通過修改-f參數來修改增長比例。 
-
-
- Chunk才是存放緩存數據的單位。
Chunk是一系列固定的內存空間,這個大小就是管理它的slab的最大存放大小。例如:slab 1的所有chunk都是104byte,而slab 4的所有chunk都是280byte。chunk是memcached實際存放緩存數據的地方,因為chunk的大小固定為slab能夠存放的最大值,所以所有分配給當前slab的數據都可以被chunk存下。如果時間的數據大小小于chunk的大小,空余的空間將會被閑置,這個是為了防止內存碎片而設計的。例如下圖,chunk size是224byte,而存儲的數據只有200byte,剩下的24byte將被閑置。 
-
-
-
- Slab的內存分配。
Memcached在啟動時通過-m指定最大使用內存,但是這個不會一啟動就占用,是隨著需要逐步分配給各slab的。
如果一個新的緩存數據要被存放,memcached首先選擇一個合適的slab,然后查看該slab是否還有空閑的chunk,如果有則直接存放進去;如果沒有則要進行申請。slab申請內存時以page為單位,所以在放入第一個數據,無論大小為多少,都會有1M大小的page被分配給該slab。申請到page后,slab會將這個page的內存按chunk的大小進行切分,這樣就變成了一個chunk的數組,在從這個chunk數組中選擇一個用于存儲數據。如下圖,slab 1和slab 2都分配了一個page,并按各自的大小切分成chunk數組。 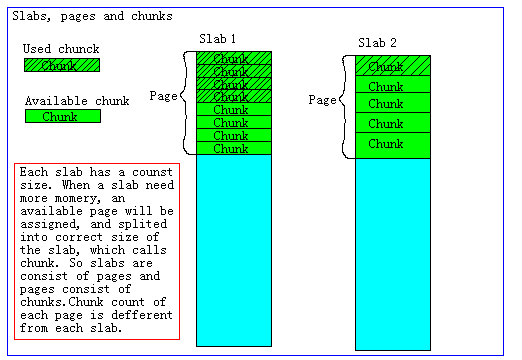
-
-
-
- Memcached內存分配策略。
綜合上面的介紹,memcached的內存分配策略就是:按slab需求分配page,各slab按需使用chunk存儲。
這里有幾個特點要注意,
- Memcached分配出去的page不會被回收或者重新分配
- Memcached申請的內存不會被釋放
- slab空閑的chunk不會借給任何其他slab使用
每一個slab=1M 切分的chunk個數=1M/最小的chunk大小
下一個chunk=上一個chunk大小*增長因子
知道了這些以后,就可以理解為什么總內存沒有被全部占用的情況下,memcached卻出現了丟失緩存數據的問題了。
*******************
當存儲的值item大于1M的時候:
按照官方解釋,當大于1M時,按現有的 slab allocation內存分配管理機制,memcache的存取效率會下降很多,就失去了使用memcache的意義,之所以用memcache,一大原因就是它比數據庫速度快,如果失去了速度優勢,就沒意思了。
支持大于1M的方法 官方也給出了:一個是還是使用slab allocation 機制修改源代碼中 POWER_BLOCK 的值,然后重新編譯。另一個方法是使用低效的 malloc/free 分配機制。
如果某個常用slab滿了 而且又沒開啟LRU,會出現命中低的情況·
1M/最小的chunk=存儲的個數
然后第二個chunk=第一個chunk*1.25
這樣1M被不斷的分
切到最后1M只能存一個chunk
1M 用完會申請一個新的 1M
但是 不能超過你的最大內存數
超過了 就開始回收
也就是LRU
當memcache每次在get的時候會檢測key所對應的value過期時間 那么當檢測到此item過期了 value會被清除 key呢 保留 還是也會被清除 ?
不會被清除,只會返回空
直到lru覆蓋這個過期值
那就是當我程序棄用了大量的key時 cmd_get時 這些key 還會被掃描到?
不會
只是還存在內存里 占著內存