《秒殺系統架構優化思路》
上周參加Qcon,有個兄弟分享秒殺系統的優化,其觀點有些贊同,大部分觀點卻并不同意,結合自己的經驗,談談自己的一些看法。
一、為什么難
秒殺系統難做的原因:庫存只有一份,所有人會在集中的時間讀和寫這些數據。
例如小米手機每周二的秒殺,可能手機只有1萬部,但瞬時進入的流量可能是幾百幾千萬。
又例如12306搶票,亦與秒殺類似,瞬時流量更甚。
二、常見架構
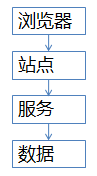
流量到了億級別,常見站點架構如上:
1)瀏覽器端,最上層,會執行到一些JS代碼
2)站點層,這一層會訪問后端數據,拼html頁面返回給瀏覽器
3)服務層,向上游屏蔽底層數據細節
4)數據層,最終的庫存是存在這里的,mysql是一個典型
三、優化方向
1)將請求盡量攔截在系統上游:傳統秒殺系統之所以掛,請求都壓倒了后端數據層,數據讀寫鎖沖突嚴重,并發高響應慢,幾乎所有請求都超時,流量雖大,下單成功的有效流量甚小【一趟火車其實只有2000張票,200w個人來買,基本沒有人能買成功,請求有效率為0】
2)充分利用緩存:這是一個典型的讀多些少的應用場景【一趟火車其實只有2000張票,200w個人來買,最多2000個人下單成功,其他人都是查詢庫存,寫比例只有0.1%,讀比例占99.9%】,非常適合使用緩存
四、優化細節
4.1)瀏覽器層請求攔截
點擊了“查詢”按鈕之后,系統那個卡呀,進度條漲的慢呀,作為用戶,會不自覺的再去點擊“查詢”,繼續點,繼續點,點點點。。。有用么?平白無故的增加了系統負載(一個用戶點5次,80%的請求是這么多出來的),怎么整?
a)產品層面,用戶點擊“查詢”或者“購票”后,按鈕置灰,禁止用戶重復提交請求
b)JS層面,限制用戶在x秒之內只能提交一次請求
如此限流,80%流量已攔
4.2)站點層請求攔截與頁面緩存
瀏覽器層的請求攔截,只能攔住小白用戶(不過這是99%的用戶喲),高端的程序員根本不吃這一套,寫個for循環,直接調用你后端的http請求,怎么整?
a)同一個uid,限制訪問頻度,做頁面緩存,x秒內到達站點層的請求,均返回同一頁面
b)同一個item的查詢,例如手機車次,做頁面緩存,x秒內到達站點層的請求,均返回同一頁面
如此限流,又有99%的流量會被攔截在站點層
4.3)服務層請求攔截與數據緩存
站點層的請求攔截,只能攔住普通程序員,高級黑客,假設他控制了10w臺肉雞(并且假設買票不需要實名認證),這下uid的限制不行了吧?怎么整?
a)大哥,我是服務層,我清楚的知道小米只有1萬部手機,我清楚的知道一列火車只有2000張車票,我透10w個請求去數據庫有什么意義呢?對于寫請求,做請求隊列,每次只透過有限的寫請求去數據層,如果均成功再放下一批,如果庫存不夠則隊列里的寫請求全部返回“已售完”
b)對于讀請求,還用說么?cache來抗,不管是memcached還是redis,單機抗個每秒10w應該都是沒什么問題的
如此限流,只有非常少的寫請求,和非常少的讀緩存mis的請求會透到數據層去,又有99.9%的請求被攔住了
4.4)數據層閑庭信步
到了數據這一層,幾乎就沒有什么請求了,單機也能扛得住,還是那句話,庫存是有限的,小米的產能有限,透過過多請求來數據庫沒有意義。
五、總結
沒什么總結了,上文應該描述的非常清楚了,對于秒殺系統,再次重復下筆者的兩個架構優化思路:
1)盡量將請求攔截在系統上游
2)讀多寫少的常用多使用緩存