運(yùn)用實(shí)證(實(shí)證依賴的是觀察和經(jīng)驗(yàn),而不是理論和純邏輯推理)方法進(jìn)行調(diào)試可以充分利用軟件的獨(dú)特能力來告訴你軟件運(yùn)行的狀態(tài),而發(fā)揮這種能力的關(guān)鍵是找到能夠重現(xiàn)問題的方法。
為什么重現(xiàn)問題如此重要?
不能重現(xiàn)問題,就幾乎不可能取得進(jìn)展,因?yàn)閷?shí)證過程依賴于我們觀察存在缺陷的軟件執(zhí)行的能力。
如何重現(xiàn)?
要做的第一件事很簡單,就是按照缺陷報(bào)告描述(或提示)的步驟做,要做好問題重現(xiàn)就要抓好控制,而需要控制的因素如下:
1、軟件本身:如果缺陷存在于最近修改的地方,那么你應(yīng)該首先保證你調(diào)試運(yùn)行的軟件和缺陷被提交時(shí)使用的軟件是同一個(gè)版本
2、軟件的運(yùn)行環(huán)境:如果要與外部系統(tǒng)進(jìn)行交互,那么可能需要確保你使用的是相同的外部系統(tǒng)
3、你提供的輸入:如果一段代碼的運(yùn)行情況受軟件的配置影響很大,而缺陷又與這段代碼有關(guān),那么應(yīng)該使用用戶的配置來進(jìn)行調(diào)試
控制軟件本身:最好的辦法就是創(chuàng)建一個(gè)自動化的構(gòu)建過程
控制運(yùn)行環(huán)境:要知道缺陷出現(xiàn)時(shí)軟件所使用的環(huán)境,記住:軟件環(huán)境包括了可能影響軟件運(yùn)行的所有因素。
控制輸入:要找出輸入數(shù)據(jù)以便準(zhǔn)確重現(xiàn)問題。如果無法獲得需要的所有信息,有兩種選擇:一是推測一下可能的輸入是什么,二是把它們記錄下來。
推測可能輸入:出發(fā)點(diǎn)是假設(shè)問題確實(shí)存在,然后運(yùn)用逆向工程的方法推測出能夠?qū)е聠栴}的必要條件。
回溯:通常我們知道發(fā)生了什么事,但不清楚為什么會發(fā)生,此時(shí)可以使用回溯法,如果運(yùn)氣好,這個(gè)邏輯可以直接重現(xiàn)問題,即使不能完全重現(xiàn),也可以提供有用的線索,再加上其他異常的現(xiàn)象,就可以排除某些可能性。
探測可能的輸入值:黑盒技術(shù)中邊界值分析可以在這里使用,因?yàn)檩斎胫捣秶倪吔缡亲钣锌赡艹霈F(xiàn)錯(cuò)誤的地方,而相當(dāng)于白盒測試中的邊界值分析的分支覆蓋,也可以在這里派上用場,可以嘗試創(chuàng)建一些輸入,使用這些輸入可以覆蓋同一代碼塊中的不同分支。
有效地識別能重現(xiàn)問題的輸入順序需要你轉(zhuǎn)變思路——你不必證明系統(tǒng)工作正常,而要證明它不正常。
利用錯(cuò)誤條件:當(dāng)試圖重現(xiàn)一個(gè)問題的時(shí)候,考慮一下是否有一些錯(cuò)誤條件出現(xiàn)在運(yùn)行的過程中,并去解釋為什么問題會發(fā)生,然后,想想如何使錯(cuò)誤條件表現(xiàn)出來或模擬出來,并且是否可以使你重現(xiàn)問題。
引入隨機(jī)性:選取一系列不同輸入值的一種方法就是引入一些隨機(jī)輸入值。
在推測重現(xiàn)問題時(shí)需要使用的數(shù)據(jù)過程中,記住:你需要驗(yàn)證與缺陷報(bào)告不符的結(jié)論。你找到了一種使軟件出現(xiàn)缺陷的方法,并不意味著你找出了缺陷報(bào)告中的缺陷(盡管你已經(jīng)清楚地發(fā)現(xiàn)了一個(gè)需要修正的缺陷)。
記錄輸入值:使用日志記錄輸入值。獲取日志最簡單的方法就是在整個(gè)代碼中正確地放置了對System.out.printfln()或類似方法的調(diào)用,當(dāng)然,也可以使用日志框架來完成更為復(fù)雜的功能(此處略去該方法)。
是否應(yīng)該把日志留在代碼中?
答案仁者見仁智者見智,如果在代碼中嵌入日志,無疑,當(dāng)問題再次發(fā)生時(shí)可以快速尋找到它,但是,它卻容易導(dǎo)致代碼變得難以理解,同時(shí),它將類似注釋內(nèi)容而停滯,一成不變。因此,最佳的選擇是注重實(shí)效,一旦將它嵌入代碼,確保你的日志隨時(shí)更新,與代碼保持一致,而非為了日志而做日志。
負(fù)載和壓力:關(guān)于負(fù)載測試工具的問題,通常是找到一個(gè)辦法讓它們重現(xiàn)真實(shí)的負(fù)載,但創(chuàng)建大量簡單的交互行為可能并不會產(chǎn)生足夠的負(fù)載來重現(xiàn)需要調(diào)試的問題。解決方法之一是使用日志記錄真實(shí)的負(fù)載量,然后使用負(fù)載測試工具去重現(xiàn)它。
壓力測試工具也是類似的,只是它不直接產(chǎn)生負(fù)載。
問題重現(xiàn)曾經(jīng)是一個(gè)重要的障礙,下面我們將聊聊如何改進(jìn)問題重現(xiàn)。不管是什么樣的重現(xiàn)問題的方法,只要有,就比沒有強(qiáng)。但是如何讓重現(xiàn)問題既可靠又方便呢?
最小化反饋周期:和軟件開發(fā)的其他眾多領(lǐng)域一樣,問題重現(xiàn)也是要使反饋周期最小,所經(jīng)過的周期越短,反饋就越及時(shí),其相關(guān)性就越高。
因此,最先要關(guān)注的就是找出問題重現(xiàn)中哪些方面是不需要的,將它們剔除掉,稱為將問題重現(xiàn)最小化。那么,哪些元素可以被剔除呢?往往這要靠直覺。你了解軟件,并且知道哪些模塊可能被一些特定輸入所影響,如果直覺不對,那么一些非直接的方法可能會幫助到你。
改進(jìn)問題重現(xiàn)不是一蹴而就的事,而是在整個(gè)診斷過程中要牢記在心的東西。
將不確定的缺陷變?yōu)榇_定的:要做到這一點(diǎn),需要明白不確定性從何來?
1、開始于不可預(yù)知的初始狀態(tài)
當(dāng)你的軟件從未經(jīng)初始化的內(nèi)存讀取數(shù)據(jù)時(shí),通常會出問題。如果你有理由相信,是這個(gè)原因?qū)е铝瞬淮_定性問題,那么你最好的選擇可能是使用調(diào)試內(nèi)存分配器,來強(qiáng)制內(nèi)存被初始化為一個(gè)眾所周知的值,或用內(nèi)存完整性檢驗(yàn)軟件來檢測是否引用了未初始化的內(nèi)存。
2、與外部系統(tǒng)進(jìn)行交互
由此引起的不確定性問題往往不是因?yàn)槎弑憩F(xiàn)不一,而是因?yàn)闀r(shí)間上微妙的不同。解決的策略是能夠精確控制從外部系統(tǒng)接收了什么,以及何時(shí)接收的。最好的選擇可能不是試圖直接控制外部系統(tǒng),而是用你能控制的東西替換它,比如調(diào)試子系統(tǒng)或代替測試。
3、故意地使用隨機(jī)性
由此導(dǎo)致的不確定性聽起來還是很正常的,幸運(yùn)的是,大部分所謂使用隨機(jī)數(shù)的軟件都是通過確定性算法產(chǎn)生的偽隨機(jī)數(shù),因此這個(gè)是完全可以預(yù)測的行為。
4、多線程
由此引起的不確定性最難處理。在多核系統(tǒng)盛行的今天,往往我們處理的并不是真正的并發(fā)。而在缺乏并發(fā)控制的結(jié)構(gòu)化方法下,我們不得不依靠一些特殊的方法。因此,在處理方法中最有效的工具之一就是不起眼的sleep()方法,它允許你強(qiáng)制一個(gè)線程長時(shí)間等待而出現(xiàn)競爭狀態(tài)。
例如,假設(shè)你正在工作的軟件中多個(gè)乖哦工作線程并行處理工作項(xiàng)目,工作線程使用下面的java代碼來獲得工作項(xiàng)目:
if (item=workQueue.lockWorkItem())
{
item.process();
workQueue.writeResultAndUnlock(item);
} |
你試圖跟蹤一個(gè)間歇出現(xiàn)的缺陷,有時(shí)同一個(gè)工作項(xiàng)目會同時(shí)分配給兩個(gè)工作線程。遺憾的事,這種情況極少出現(xiàn),那么,你可以將代碼更改為如下形式來增加重現(xiàn)該問題的幾率:
if (item=workQueue.lockWorkItem())
{
Thread.sleep(1000);
item.process();
workQueue.writeResultAndUnlock(item);
} |
注意:盡管sleep()方法在重現(xiàn)問題和診斷階段很有用,但在修復(fù)缺陷階段它不是一個(gè)適合的方法。
自動化:一個(gè)自定義測試不僅能夠方便的運(yùn)行,而且當(dāng)診斷結(jié)束開始修復(fù)的時(shí)候,對于即將編寫完成的測試來說,它是一個(gè)很好的起點(diǎn)。如果確定缺陷重現(xiàn)需要通過日志,那么可以選擇重放日志文件。
迭代:在診斷的過程中,你構(gòu)建了足夠多關(guān)于如何以及為何軟件如此運(yùn)行的信息,可以用此不斷改進(jìn)重現(xiàn),如下圖:
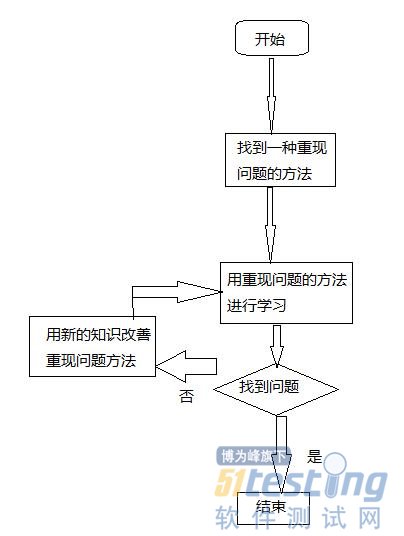
通過如下步驟反復(fù)改進(jìn):
1、你確定一個(gè)特定的模塊已包含在內(nèi),其中有導(dǎo)致缺陷的元素,這樣可以創(chuàng)建一個(gè)更小的文件。
2、進(jìn)一步診斷,發(fā)現(xiàn)能通過用樁模塊替代與第三方服務(wù)器交互的子系統(tǒng),讓問題每次都出現(xiàn),樁模塊可以很容易返回已經(jīng)確定的響應(yīng)。
3、最后,把跟蹤范圍縮小到一個(gè)特定函數(shù),通過設(shè)置一組具體的參數(shù)調(diào)用該函數(shù)來創(chuàng)建單元測試,以便重現(xiàn)問題。
如果真的不能重現(xiàn)問題該怎么辦?
首先,不要輕易給出“缺陷不存在”的結(jié)論,除非盡力獲取了更多額外信息,用盡了所有可用的辦法依然不能重現(xiàn)問題。其次,在相同區(qū)域解決不同的問題,盡管沒有你目前跟蹤的缺陷那么嚴(yán)重和緊急,也許它們蒙蔽了真正缺陷所在,也許會讓你找到重現(xiàn)問題的關(guān)鍵因素,當(dāng)然,也許沒有任何幫助。第三,試著讓其他人參與其中,這樣可以獲取其他人的不同角度看待問題,尤其是反饋錯(cuò)誤的人。第四,充分利用用戶群體,有些時(shí)候,缺陷出現(xiàn)在外部系統(tǒng)而非開發(fā)系統(tǒng)中,但這需要用戶為你收集所需要的信息,從某種角度來說,并不理想。最后,可以使用推測法,你所需要做的是把自己融入到軟件中,在想象中執(zhí)行軟件,執(zhí)行每一步,考慮有哪些出現(xiàn)錯(cuò)誤的可能性,嘗試解釋你跟蹤的缺陷。
正常來說,我們有能力重現(xiàn)問題,而在下一章中,我們將會看到如何用重現(xiàn)來診斷問題。