#
Date類內部既不存儲年月日也不存儲時分秒,而是存儲一個從1970年1月1日0點0分0秒開始的毫秒數,而真正有用的年月日時分秒毫秒都是從這個毫秒數轉化而來,這是它不容易被使用的地方,尤其是顯示和存儲的場合。但Date類的優勢在于方便計算和比較。
另一點,日常生活中我們習慣用年月日時分秒這樣的文本日期來表示時間,它方便顯示和存儲,也容易理解,但不容易計算和比較。
綜上所述,我們在程序中進行日期時間處理時經常需要在在文本日期和Date類之間進行轉換,為此我們需要借助java.text.SimpleDateFormat類來進行處理,下文列舉了它的幾個常用示例。
1.將Date轉化為常見的日期時間字符串
這里我們需要用到java.text.SimpleDateFormat類的format方法,其中可以指定年月日時分秒的模式字符串格式。
Date date = new Date();
Format formatter = new SimpleDateFormat("yyyy年MM月dd日HH時mm分ss秒");
System.out.println("轉化的時間等于="+formatter.format(date));
其中
yyyy表示四位數的年份
MM表示兩位數的月份
dd表示兩位數的日期
HH表示兩位數的小時
mm表示兩位數的分鐘
ss表示兩位數的秒鐘
2.將文本日期轉化為Date以方便比較
文本日期的優勢在于便于記憶,容易處理,但缺點是不方便比較,這時我們需要借助SimpleDateFormat的parse方法得到Date對象再進行比較,實例如下:
String strDate1="2004年8月9日";
String strDate2="2004年10月5日";
SimpleDateFormat myFormatter = new SimpleDateFormat("yyyy年MM月dd日");
java.util.Date date1 = myFormatter.parse(strDate1);
java.util.Date date2 = myFormatter.parse(strDate2);
// Date比較能得出正確結果
if(date2.compareTo(date1)>0){
System.out.println(strDate2+">"+strDate1);
}
// 字符串比較得不出正確結果
if(strDate2.compareTo(strDate1)>0){
System.out.println(strDate2+">"+strDate1);
}
3.將文本日期轉化為Date以方便計算
文本日期的另一個大問題是不方便計算,比如計算2008年1月9日的100天后是那一天就不容易,此時我們還是需要把文本日期轉化為Date進行計算,再把結果轉化為文本日期:
SimpleDateFormat myFormatter = new SimpleDateFormat("yyyy年MM月dd日");
java.util.Date date = myFormatter.parse("2008年1月9日");
date.setDate(date.getDate()+100);
Format formatter = new SimpleDateFormat("yyyy年MM月dd日");
// 得到2008年04月18日
System.out.println("100天后為"+formatter.format(date));
效果圖:

頁面代碼:
<ul id="nav">
<li><a href="#">首頁</a></li>
<li><a href="#" id="current">次頁</a></li>
<li><a href="#">三頁</a></li>
<li><a href="#">四頁</a></li>
<li><a href="#">五頁</a></li>
</ul>
CSS代碼:
#nav{
margin:0;
height: 26px;
border-bottom:1px solid #2788da;
}
#nav li{
float:left;
}
#nav li a{
color:#000000;
text-decoration:none;
padding-top:4px;
display:block;
width:97px;
height:22px;
text-align:center;
background-color:#ececec;
margin-left:2px;
}
#nav li a:hover{
background-color:#bbbbbb;
color:#ffffff;
}
#nav li a#current{
background-color:#2788da;
color:#ffffff;
}
效果圖:
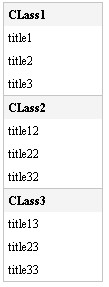
頁面代碼:
<div id="category">
<h1>CLass1</h1>
<h2>title1</h2>
<h2>title2</h2>
<h2>title3</h2>
<h1>CLass2</h1>
<h2>title12</h2>
<h2>title22</h2>
<h2>title32</h2>
<h1>CLass3</h1>
<h2>title13</h2>
<h2>title23</h2>
<h2>title33</h2>
</div>
CSS代碼:
#category{
width:100px;
border-right:1px solid #c5c6c4;
border-bottom:1px solid #c5c6c4;
border-left:1px solid #c5c6c4;
}
#category h1{
margin:0px;
padding:4px;
font-size:12px;
font-weight:bold;
border-top:1px solid #c5c6c4;
background-color: #f4f4f4;
}
#category h2{
margin:0px;
padding:4px;
font-size:12px;
font-weight:normal;
}
以上。
效果圖:
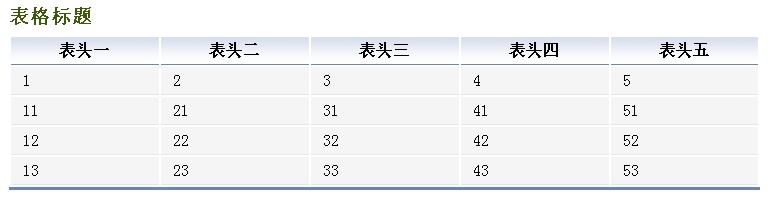
頁面代碼:
<table id="1233" class="Listing" >
<caption>表格標題</caption>
<thead>
<th scope="col">表頭一</th>
<th scope="col">表頭二</th>
<th scope="col">表頭三</th>
<th scope="col">表頭四</th>
<th scope="col">表頭五</th>
</thead>
<tbody id="tbodySample">
<tr>
<td>1</td>
<td>2</td>
<td>3</td>
<td>4</td>
<td>5</td>
</tr>
<tr>
<td>11</td>
<td>21</td>
<td>31</td>
<td>41</td>
<td>51</td>
</tr>
<tr>
<td>12</td>
<td>22</td>
<td>32</td>
<td>42</td>
<td>52</td>
</tr>
<tr>
<td>13</td>
<td>23</td>
<td>33</td>
<td>43</td>
<td>53</td>
</tr>
</tbody>
</table>
CSS代碼:
TABLE.Listing TD {
BORDER-BOTTOM: #e6e6e6 1px solid
}
TABLE.Listing TD {
PADDING-RIGHT: 12px;
PADDING-LEFT: 12px;
PADDING-BOTTOM: 4px;
PADDING-TOP: 4px;
TEXT-ALIGN: left
}
TABLE.Listing TH {
PADDING-RIGHT: 12px;
PADDING-LEFT: 12px;
PADDING-BOTTOM: 4px;
PADDING-TOP: 4px;
TEXT-ALIGN: center
}
TABLE.Listing CAPTION {
PADDING-RIGHT: 12px;
PADDING-LEFT: 12px;
PADDING-BOTTOM: 4px;
PADDING-TOP: 4px;
TEXT-ALIGN: left
}
TABLE.Listing {
MARGIN: 0px 0px 8px;
WIDTH: 92%;
BORDER-BOTTOM: #6b86b3 3px solid
}
TABLE.Listing TR {
BACKGROUND: #f5f5f5;
height:20px;
}
TABLE.Listing caption{
font-weight:bold;
padding:6px 0px;
color:#3d580b;
font-size:20px;
}
TABLE.Listing TH {
FONT-WEIGHT: bold;
background:#ccc url(theadbg.gif) repeat-x left center;
BORDER-BOTTOM: #6b86b3 1px solid
}
TABLE.Listing TD.Header {
FONT-WEIGHT: bold;
BORDER-BOTTOM: #6b86b3 1px solid
BACKGROUND: #ffffff;
}
TABLE.Listing TR.Header TD {
FONT-WEIGHT: bold;
BACKGROUND: #ffffff;
BORDER-BOTTOM: #6b86b3 1px solid
}
TABLE.Listing TR.Alt {
BACKGROUND: #ffffff
}
效果:
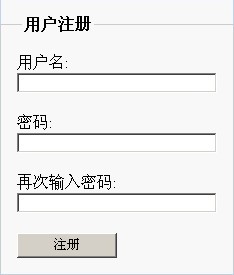
頁面代碼::
<fieldset><legend>用戶注冊</legend>
<p><label for="name">用戶名:</label><input type="text" name="name"
value="" style="width: 200px; height: 20px" /></p>
<p><label for="pswd">密碼:</label><input type="text" name="pswd"
value="" style="width: 200px; height: 20px" /></p>
<p><label for="pswd">再次輸入密碼:</label><input type="text" name="pswd2"
value="" style="width: 200px; height: 20px" /></p>
<p><input type="button"
value="注冊" style="width: 100px; height: 25px" onclick="registerCheck()"/></p>
</fieldset>
CSS代碼:
fieldset{
margin:1em 0;
padding:1em;
border:1px solid #ccc;
background:#f8f8f8;
}
legend{
font-weight:bold;
}
label{
display:block;
}
以上。
JTable是Swing編程中很常用的控件,這里總結了一些常用方法以備查閱.
一.創建表格控件的各種方式:
1) 調用無參構造函數.
JTable table = new JTable();
2) 以表頭和表數據創建表格.
Object[][] cellData = {{"row1-col1", "row1-col2"},{"row2-col1", "row2-col2"}};
String[] columnNames = {"col1", "col2"};
JTable table = new JTable(cellData, columnNames);
3) 以表頭和表數據創建表格,并且讓表單元格不可改.
String[] headers = { "表頭一", "表頭二", "表頭三" };
Object[][] cellData = null;
DefaultTableModel model = new DefaultTableModel(cellData, headers) {
public boolean isCellEditable(int row, int column) {
return false;
}
};
table = new JTable(model);
二.對表格列的控制
1) 設置列不可隨容器組件大小變化自動調整寬度.
table.setAutoResizeMode(JTable.AUTO_RESIZE_OFF);
2) 限制某列的寬度.
TableColumn firsetColumn = table.getColumnModel().getColumn(0);
firsetColumn.setPreferredWidth(30);
firsetColumn.setMaxWidth(30);
firsetColumn.setMinWidth(30);
3) 設置當前列數.
DefaultTableModel tableModel = (DefaultTableModel) table.getModel();
int count=5;
tableModel.setColumnCount(count);
4) 取得表格列數
int cols = table.getColumnCount();
5) 添加列
DefaultTableModel tableModel = (DefaultTableModel) table.getModel();
tableModel.addColumn("新列名");
6) 刪除列
table.removeColumn(table.getColumnModel().getColumn(columnIndex));// columnIndex是要刪除的列序號
三.對表格行的控制
1) 設置行高
table.setRowHeight(20);
2) 設置當前航數
DefaultTableModel tableModel = (DefaultTableModel) table.getModel();
int n=5;
tableModel.setRowCount(n);
3) 取得表格行數
int rows = table.getRowCount();
4) 添加表格行
DefaultTableModel tableModel = (DefaultTableModel) table.getModel();
tableModel.addRow(new Object[]{"sitinspring", "35", "Boss"});
5) 刪除表格行
DefaultTableModel tableModel = (DefaultTableModel) table.getModel();
model.removeRow(rowIndex);// rowIndex是要刪除的行序號
四.存取表格單元格的數據
1) 取單元格數據
DefaultTableModel tableModel = (DefaultTableModel) table.getModel();
String cellValue=(String) tableModel.getValueAt(row, column);// 取單元格數據,row是行號,column是列號
2) 填充數據到表格.
注:數據是Member類型的鏈表,Member類如下:
public class Member{
// 名稱
private String name;
// 年齡
private String age;
// 職務
private String title;
}
填充數據的代碼:
public void fillTable(List<Member> members){
DefaultTableModel tableModel = (DefaultTableModel) table
.getModel();
tableModel.setRowCount(0);// 清除原有行
// 填充數據
for(Member member:members){
String[] arr=new String[3];
arr[0]=member.getName();
arr[1]=member.getAge();
arr[2]=member.getTitle();
// 添加數據到表格
tableModel.addRow(arr);
}
// 更新表格
table.invalidate();
}
2) 取得表格中的數據
public List<Member> getShowMembers(){
List<Member> members=new ArrayList<Member>();
DefaultTableModel tableModel = (DefaultTableModel) table
.getModel();
int rowCount=tableModel.getRowCount();
for(int i=0;i<rowCount;i++){
Member member=new Member();
member.setName((String)tableModel.getValueAt(i, 0));// 取得第i行第一列的數據
member.setAge((String)tableModel.getValueAt(i, 1));// 取得第i行第二列的數據
member.setTitle((String)tableModel.getValueAt(i, 2));// 取得第i行第三列的數據
members.add(member);
}
return members;
}
五.取得用戶所選的行
1) 取得用戶所選的單行
int selectRows=table.getSelectedRows().length;// 取得用戶所選行的行數
DefaultTableModel tableModel = (DefaultTableModel) table.getModel();
if(selectRows==1){
int selectedRowIndex = table.getSelectedRow(); // 取得用戶所選單行
.// 進行相關處理
}
2) 取得用戶所選的多行
int selectRows=table.getSelectedRows().length;// 取得用戶所選行的行數
DefaultTableModel tableModel = (DefaultTableModel) table.getModel();
if(selectRows>1)
int[] selRowIndexs=table.getSelectedRows();// 用戶所選行的序列
for(int i=0;i<selRowIndexs.length;i++){
// 用tableModel.getValueAt(row, column)取單元格數據
String cellValue=(String) tableModel.getValueAt(i, 1);
}
}
六.添加表格的事件處理
view.getTable().addMouseListener(new MouseListener() {
public void mousePressed(MouseEvent e) {
// 鼠標按下時的處理
}
public void mouseReleased(MouseEvent e) {
// 鼠標松開時的處理
}
public void mouseEntered(MouseEvent e) {
// 鼠標進入表格時的處理
}
public void mouseExited(MouseEvent e) {
// 鼠標退出表格時的處理
}
public void mouseClicked(MouseEvent e) {
// 鼠標點擊時的處理
}
});
要使用dom4j讀寫XML文檔,需要先下載dom4j包,dom4j官方網站在 http://www.dom4j.org/
目前最新dom4j包下載地址:http://nchc.dl.sourceforge.net/sourceforge/dom4j/dom4j-1.6.1.zip
解開后有兩個包,僅操作XML文檔的話把dom4j-1.6.1.jar加入工程就可以了,如果需要使用XPath的話還需要加入包jaxen-1.1-beta-7.jar.
以下是相關操作:
一.Document對象相關
1.讀取XML文件,獲得document對象.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
2.解析XML形式的文本,得到document對象.
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
3.主動創建document對象.
Document document = DocumentHelper.createDocument();
Element root = document.addElement("members");// 創建根節點
二.節點相關
1.獲取文檔的根節點.
Element rootElm = document.getRootElement();
2.取得某節點的單個子節點.
Element memberElm=root.element("member");// "member"是節點名
3.取得節點的文字
String text=memberElm.getText();
也可以用:
String text=root.elementText("name");這個是取得根節點下的name字節點的文字.
4.取得某節點下名為"member"的所有字節點并進行遍歷.
List nodes = rootElm.elements("member");
for (Iterator it = nodes.iterator(); it.hasNext();) {
Element elm = (Element) it.next();
// do something
}
5.對某節點下的所有子節點進行遍歷.
for(Iterator it=root.elementIterator();it.hasNext();){
Element element = (Element) it.next();
// do something
}
6.在某節點下添加子節點.
Element ageElm = newMemberElm.addElement("age");
7.設置節點文字.
ageElm.setText("29");
8.刪除某節點.
parentElm.remove(childElm);// childElm是待刪除的節點,parentElm是其父節點
三.屬性相關.
1.取得某節點下的某屬性
Element root=document.getRootElement();
Attribute attribute=root.attribute("size");// 屬性名name
2.取得屬性的文字
String text=attribute.getText();
也可以用:
String text2=root.element("name").attributeValue("firstname");這個是取得根節點下name字節點的屬性firstname的值.
3.遍歷某節點的所有屬性
Element root=document.getRootElement();
for(Iterator it=root.attributeIterator();it.hasNext();){
Attribute attribute = (Attribute) it.next();
String text=attribute.getText();
System.out.println(text);
}
4.設置某節點的屬性和文字.
newMemberElm.addAttribute("name", "sitinspring");
5.設置屬性的文字
Attribute attribute=root.attribute("name");
attribute.setText("sitinspring");
6.刪除某屬性
Attribute attribute=root.attribute("size");// 屬性名name
root.remove(attribute);
四.將文檔寫入XML文件.
1.文檔中全為英文,不設置編碼,直接寫入的形式.
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(document);
writer.close();
2.文檔中含有中文,設置編碼格式寫入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK"); // 指定XML編碼
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"),format);
writer.write(document);
writer.close();
五.字符串與XML的轉換
1.將字符串轉化為XML
String text = "<members> <member>sitinspring</member> </members>";
Document document = DocumentHelper.parseText(text);
2.將文檔或節點的XML轉化為字符串.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String rootXmlText=root.asXML();
Element memberElm=root.element("member");
String memberXmlText=memberElm.asXML();
六.使用XPath快速找到節點.
讀取的XML文檔示例
<?xml version="1.0" encoding="UTF-8"?>
<projectDescription>
<name>MemberManagement</name>
<comment></comment>
<projects>
<project>PRJ1</project>
<project>PRJ2</project>
<project>PRJ3</project>
<project>PRJ4</project>
</projects>
<buildSpec>
<buildCommand>
<name>org.eclipse.jdt.core.javabuilder</name>
<arguments>
</arguments>
</buildCommand>
</buildSpec>
<natures>
<nature>org.eclipse.jdt.core.javanature</nature>
</natures>
</projectDescription>
使用XPath快速找到節點project.
public static void main(String[] args){
SAXReader reader = new SAXReader();
try{
Document doc = reader.read(new File("sample.xml"));
List projects=doc.selectNodes("/projectDescription/projects/project");
Iterator it=projects.iterator();
while(it.hasNext()){
Element elm=(Element)it.next();
System.out.println(elm.getText());
}
}
catch(Exception ex){
ex.printStackTrace();
}
}
通配符^
^表示模式的開始,如^he匹配所有以he開頭的字符串.
例程:
String[] dataArr = { "he", "hero", "here", "hitler"};
for (String str : dataArr) {
String patternStr = "(^he)(\\w*)";
boolean result = Pattern.matches(patternStr, str);
if (result) {
System.out.println("字符串" + str + "匹配模式" + patternStr + "成功");
} else {
System.out.println("字符串" + str + "匹配模式" + patternStr + "失敗");
}
}
通配符$
$表示模式的結束,如ia$匹配所有以ia結尾的單詞.
String[] dataArr = { "ia", "Asia", "China", "Colonbia","America"};
for (String str : dataArr) {
String patternStr = "(\\w*)(ia$)";
boolean result = Pattern.matches(patternStr, str);
if (result) {
System.out.println("字符串" + str + "匹配模式" + patternStr + "成功");
} else {
System.out.println("字符串" + str + "匹配模式" + patternStr + "失敗");
}
}
通配符{}
除了用+表示一次或多次,*表示0次或多次,?表示0次或一次外,還可以用{}來指定精確指定出現的次數,X{2,5}表示X最少出現2次,最多出現5次;X{2,}表示X最少出現2次,多則不限;X{5}表示X只精確的出現5次.
例程:
String[] dataArr = { "google", "gooogle", "gooooogle", "goooooogle","ggle"};
for (String str : dataArr) {
String patternStr = "g(o{2,5})gle";
boolean result = Pattern.matches(patternStr, str);
if (result) {
System.out.println("字符串" + str + "匹配模式" + patternStr + "成功");
} else {
System.out.println("字符串" + str + "匹配模式" + patternStr + "失敗");
}
}
通配符[]中的-
-表示從..到…,如[a-e]等同于[abcde]
String[] dataArr = { "Tan", "Tbn", "Tcn", "Ton","Twn"};
for (String str : dataArr) {
String regex = "T[a-c]n";
boolean result = Pattern.matches(regex, str);
if (result) {
System.out.println("字符串" + str + "匹配模式" + regex + "成功");
} else {
System.out.println("字符串" + str + "匹配模式" + regex + "失敗");
}
}
Pattern類的方法簡述
| 方法 |
說明 |
| static Pettern compile(String regex,int flag) |
編譯模式,參數regex表示輸入的正則表達式,flag表示模式類型(Pattern.CASE_INSENSITIVE 表示不區分大小寫) |
| Matcher match(CharSequence input) |
獲取匹配器,input時輸入的待處理的字符串 |
| static boolean matches(String regex, CharSequence input) |
快速的匹配調用,直接根據輸入的模式regex匹配input |
| String[] split(CharSequence input,int limit) |
分隔字符串input,limit參數可以限制分隔的次數 |
模式類型Pattern.CASE_INSENSITIVE
正則表達式默認都是區分大小寫的,使用了Pattern.CASE_INSENSITIVE則不對大小寫進行區分.
String patternStr="ab";
Pattern pattern=Pattern.compile(patternStr, Pattern.CASE_INSENSITIVE);
String[] dataArr = { "ab", "Ab", "AB"};
for (String str : dataArr) {
Matcher matcher=pattern.matcher(str);
if(matcher.find()){
System.out.println("字符串" + str + "匹配模式" + patternStr + "成功");
}
}
Pattern的split方法示例
注意這里要把復雜的模式寫在前面,否則簡單模式會先匹配上.
String input="職務=GM 薪水=50000 , 姓名=職業經理人 ; 性別=男 年齡=45 ";
String patternStr="(\\s*,\\s*)|(\\s*;\\s*)|(\\s+)";
Pattern pattern=Pattern.compile(patternStr);
String[] dataArr=pattern.split(input);
for (String str : dataArr) {
System.out.println(str);
}
Matcher類的方法簡述
| 方法 |
說明 |
| boolean matches() |
對整個輸入字符串進行模式匹配. |
| boolean lookingAt() |
從輸入字符串的開始處進行模式匹配 |
| boolean find(int start) |
從start處開始匹配模式 |
| int groupCount() |
返回匹配后的分組數目 |
| String replaceAll(String replacement) |
用給定的replacement全部替代匹配的部分 |
| String repalceFirst(String replacement) |
用給定的replacement替代第一次匹配的部分 |
| Matcher appendReplacement(StringBuffer sb,String replacement) |
根據模式用replacement替換相應內容,并將匹配的結果添加到sb當前位置之后 |
| StringBuffer appendTail(StringBuffer sb) |
將輸入序列中匹配之后的末尾字串添加到sb當前位置之后. |
匹配示例一:XML元素文字解析
String regex="<(\\w+)>(\\w+)</\\1>";
Pattern pattern=Pattern.compile(regex);
String input="<name>Bill</name><salary>50000</salary><title>GM</title>";
Matcher matcher=pattern.matcher(input);
while(matcher.find()){
System.out.println(matcher.group(2));
}
替換實例一:將單詞和數字部分的單詞換成大寫
String regex="([a-zA-Z]+[0-9]+)";
Pattern pattern=Pattern.compile(regex);
String input="age45 salary500000 50000 title";
Matcher matcher=pattern.matcher(input);
StringBuffer sb=new StringBuffer();
while(matcher.find()){
String replacement=matcher.group(1).toUpperCase();
matcher.appendReplacement(sb, replacement);
}
matcher.appendTail(sb);
System.out.println("替換完的字串為"+sb.toString());
字符串處理是許多程序中非常重要的一部分,它們可以用于文本顯示,數據表示,查找鍵和很多目的.在Unix下,用戶可以使用正則表達式的強健功能實現這些目的,從Java1.4起,Java核心API就引入了java.util.regex程序包,它是一種有價值的基礎工具,可以用于很多類型的文本處理,如匹配,搜索,提取和分析結構化內容.
java.util.regex介紹
java.util.regex是一個用正則表達式所訂制的模式來對字符串進行匹配工作的類庫包。它包括兩個類:Pattern和Matcher Pattern .
Pattern是一個正則表達式經編譯后的表現模式。
Matcher 一個Matcher對象是一個狀態機器,它依據Pattern對象做為匹配模式對字符串展開匹配檢查。首先一個Pattern實例訂制了一個所用語法與PERL的類似的正則表達式經編譯后的模式,然后一個Matcher實例在這個給定的Pattern實例的模式控制下進行字符串的匹配工作。
Pattern類
在java中,通過適當命名的Pattern類可以容易確定String是否匹配某種模式.模式可以象匹配某個特定的String那樣簡單,也可以很復雜,需要采用分組和字符類,如空白,數字,字母或控制符.因為Java字符串基于統一字符編碼(Unicode),正則表達式也適用于國際化的應用程序.
Pattern的方法
Pattern的方法如下: static Pattern compile(String regex)
將給定的正則表達式編譯并賦予給Pattern類
static Pattern compile(String regex, int flags)
同上,但增加flag參數的指定,可選的flag參數包括:CASE INSENSITIVE,MULTILINE,DOTALL,UNICODE CASE, CANON EQ
int flags()
返回當前Pattern的匹配flag參數.
Matcher matcher(CharSequence input)
生成一個給定命名的Matcher對象
static boolean matches(String regex, CharSequence input)
編譯給定的正則表達式并且對輸入的字串以該正則表達式為模開展匹配,該方法適合于該正則表達式只會使用一次的情況,也就是只進行一次匹配工作,因為這種情況下并不需要生成一個Matcher實例。
String pattern()
返回該Patter對象所編譯的正則表達式。
String[] split(CharSequence input)
將目標字符串按照Pattern里所包含的正則表達式為模進行分割。
String[] split(CharSequence input, int limit)
作用同上,增加參數limit目的在于要指定分割的段數,如將limi設為2,那么目標字符串將根據正則表達式分為割為兩段。
一個正則表達式,也就是一串有特定意義的字符,必須首先要編譯成為一個Pattern類的實例,這個Pattern對象將會使用matcher()方法來生成一個Matcher實例,接著便可以使用該 Matcher實例以編譯的正則表達式為基礎對目標字符串進行匹配工作,多個Matcher是可以共用一個Pattern對象的。
Matcher的方法
Matcher appendReplacement(StringBuffer sb, String replacement)
將當前匹配子串替換為指定字符串,并且將替換后的子串以及其之前到上次匹配子串之后的字符串段添加到一個StringBuffer對象里。
StringBuffer appendTail(StringBuffer sb)
將最后一次匹配工作后剩余的字符串添加到一個StringBuffer對象里。
int end()
返回當前匹配的子串的最后一個字符在原目標字符串中的索引位置 。
int end(int group)
返回與匹配模式里指定的組相匹配的子串最后一個字符的位置。
boolean find()
嘗試在目標字符串里查找下一個匹配子串。
boolean find(int start)
重設Matcher對象,并且嘗試在目標字符串里從指定的位置開始查找下一個匹配的子串。
String group()
返回當前查找而獲得的與組匹配的所有子串內容
String group(int group)
返回當前查找而獲得的與指定的組匹配的子串內容
int groupCount()
返回當前查找所獲得的匹配組的數量。
boolean lookingAt()
檢測目標字符串是否以匹配的子串起始。
boolean matches()
嘗試對整個目標字符展開匹配檢測,也就是只有整個目標字符串完全匹配時才返回真值。
Pattern pattern()
返回該Matcher對象的現有匹配模式,也就是對應的Pattern 對象。
String replaceAll(String replacement)
將目標字符串里與既有模式相匹配的子串全部替換為指定的字符串。
String replaceFirst(String replacement)
將目標字符串里第一個與既有模式相匹配的子串替換為指定的字符串。
Matcher reset()
重設該Matcher對象。
Matcher reset(CharSequence input)
重設該Matcher對象并且指定一個新的目標字符串。
int start()
返回當前查找所獲子串的開始字符在原目標字符串中的位置。
int start(int group)
返回當前查找所獲得的和指定組匹配的子串的第一個字符在原目標字符串中的位置。
一個Matcher實例是被用來對目標字符串進行基于既有模式(也就是一個給定的Pattern所編譯的正則表達式)進行匹配查找的,所有往 Matcher的輸入都是通過CharSequence接口提供的,這樣做的目的在于可以支持對從多元化的數據源所提供的數據進行匹配工作。
使用Pattern類檢驗字符匹配
正則式是最簡單的能準確匹配一個給定String的模式,模式與要匹配的文本是等價的.靜態的Pattern.matches方法用于比較一個String是否匹配一個給定模式.例程如下:
String data="java";
boolean result=Pattern.matches("java",data);
字符類和表示次數的特殊字符
對于單字符串比較而言,使用正則表達式沒有什么優勢.Regex的真正強大之處在于體現在包括字符類和量詞(*,+,?)的更復雜的模式上.
字符類包括:
\d 數字
\D 非數字
\w 單字字符(0-9,A-Z,a-z)
\W 非單字字符
\s 空白(空格符,換行符,回車符,制表符)
\S 非空白
[] 由方括號內的一個字符列表創建的自定義字符類
. 匹配任何單個字符
下面的字符將用于控制將一個子模式應用到匹配次數的過程.
? 重復前面的子模式0次到一次
* 重復前面的子模式0次或多次
+ 重復前面的子模式一次到多次
復雜匹配例一:重復次數匹配
String[] dataArr = { "moon", "mon", "moon", "mono" };
for (String str : dataArr) {
String patternStr="m(o+)n";
boolean result = Pattern.matches(patternStr, str);
if (result) {
System.out.println("字符串"+str+"匹配模式"+patternStr+"成功");
}
else{
System.out.println("字符串"+str+"匹配模式"+patternStr+"失敗");
}
}
模式是”m(o+)n”,它表示mn中間的o可以重復一次或多次,因此moon,mon,mooon能匹配成功,而mono在n后多了一個o,和模式匹配不上.
注:
+表示一次或多次;?表示0次或一次;*表示0次或多次.
復雜匹配二:單個字符匹配
String[] dataArr = { "ban", "ben", "bin", "bon" ,"bun","byn","baen"};
for (String str : dataArr) {
String patternStr="b[aeiou]n";
boolean result = Pattern.matches(patternStr, str);
if (result) {
System.out.println("字符串"+str+"匹配模式"+patternStr+"成功");
}
else{
System.out.println("字符串"+str+"匹配模式"+patternStr+"失敗");
}
}
注:方括號中只允許的單個字符,模式“b[aeiou]n”指定,只有以b開頭,n結尾,中間是a,e,i,o,u中任意一個的才能匹配上,所以數組的前五個可以匹配,后兩個元素無法匹配.
方括號[]表示只有其中指定的字符才能匹配.
復雜匹配三:多個字符匹配
String[] dataArr = { "been", "bean", "boon", "buin" ,"bynn"};
for (String str : dataArr) {
String patternStr="b(ee|ea|oo)n";
boolean result = Pattern.matches(patternStr, str);
if (result) {
System.out.println("字符串"+str+"匹配模式"+patternStr+"成功");
}
else{
System.out.println("字符串"+str+"匹配模式"+patternStr+"失敗");
}
}
如果需要匹配多個字符,那么[]就不能用上了,這里我們可以用()加上|來代替,()表示一組,|表示或的關系,模式b(ee|ea|oo)n就能匹配been,bean,boon等.
因此前三個能匹配上,而后兩個不能.
復雜匹配四:數字匹配
String[] dataArr = { "1", "10", "101", "1010" ,"100+"};
for (String str : dataArr) {
String patternStr="\\d+";
boolean result = Pattern.matches(patternStr, str);
if (result) {
System.out.println("字符串"+str+"匹配模式"+patternStr+"成功");
}
else{
System.out.println("字符串"+str+"匹配模式"+patternStr+"失敗");
}
}
注:從前面可以知道,\\d表示的是數字,而+表示一次或多次,所以模式\\d+就表示一位或多位數字.
因此前四個能匹配上,最后一個因為+號是非數字字符而匹配不上.
復雜匹配五:字符數字混合匹配
String[] dataArr = { "a100", "b20", "c30", "df10000" ,"gh0t"};
for (String str : dataArr) {
String patternStr="\\w+\\d+";
boolean result = Pattern.matches(patternStr, str);
if (result) {
System.out.println("字符串"+str+"匹配模式"+patternStr+"成功");
}
else{
System.out.println("字符串"+str+"匹配模式"+patternStr+"失敗");
}
}
模式\\w+\\d+表示的是以多個單字字符開頭,多個數字結尾的字符串,因此前四個能匹配上,最后一個因為數字后還含有單字字符而不能匹配.
使用正則表達式劈分字符串-使用字符串的split方法
String str="薪水,職位 姓名;年齡 性別";
String[] dataArr =str.split("[,\\s;]");
for (String strTmp : dataArr) {
System.out.println(strTmp);
}
String類的split函數支持正則表達式,上例中模式能匹配”,”,單個空格,”;”中的一個,split函數能把它們中任意一個當作分隔符,將一個字符串劈分成字符串數組.
使用Pattern劈分字符串
String str="2007年12月11日";
Pattern p = Pattern.compile("[年月日]");
String[] dataArr =p.split(str);
for (String strTmp : dataArr) {
System.out.println(strTmp);
}
Pattern是一個正則表達式經編譯后的表現模式 ,它的split方法能有效劈分字符串.
注意其和String.split()使用上的不同.
使用正則表達式進行字符串替換
String str="10元 1000人民幣 10000元 100000RMB";
str=str.replaceAll("(\\d+)(元|人民幣|RMB)", "$1¥");
System.out.println(str);
上例中,模式“(\\d+)(元|人民幣|RMB)”按括號分成了兩組,第一組\\d+匹配單個或多個數字,第二組匹配元,人民幣,RMB中的任意一個,替換部分$1表示第一個組匹配的部分不變,其余組替換成¥.
替換后的str為¥10 ¥1000 ¥10000 ¥100000
使用matcher進行替換
Pattern p = Pattern.compile("m(o+)n",Pattern.CASE_INSENSITIVE);
// 用Pattern類的matcher()方法生成一個Matcher對象
Matcher m = p.matcher("moon mooon Mon mooooon Mooon");
StringBuffer sb = new StringBuffer();
// 使用find()方法查找第一個匹配的對象
boolean result = m.find();
// 使用循環找出模式匹配的內容替換之,再將內容加到sb里
while (result) {
m.appendReplacement(sb, "moon");
result = m.find();
}
// 最后調用appendTail()方法將最后一次匹配后的剩余字符串加到sb里;
m.appendTail(sb);
System.out.println("替換后內容是" + sb.toString());
使用Mather驗證IP地址的有效性
驗證函數:
public static boolean isValidIpAddr(String ipAddr){
String regx="(\\d+).(\\d+).(\\d+) .(\\d+)";
if(Pattern.matches(regx, ipAddr)){
Pattern pattern=Pattern.compile(regx);
Matcher mather=pattern.matcher(ipAddr);
while(mather.find()){
for(int i=1;i<=mather.groupCount();i++){
String str=mather.group(i);
int temp=Integer.parseInt(str);
if(temp>255 || temp<1){
return false;
}
}
}
}
else{
return false;
}
return true;
}
執行語句:
String[] ipArr = { "1.2.3.4", "3.2.1.5", "999.244.17.200", "233.200.18.20",
"2.1.0.18", "0.2.1.19" };
for (String str : ipArr) {
if (isValidIpAddr(str)) {
System.out.println(str + "是合法的IP地址");
} else {
System.out.println(str + "不是合法的IP地址");
}
}
執行結果:
1.2.3.4是合法的IP地址
3.2.1.5是合法的IP地址
999.244.17.200不是合法的IP地址
233.200.18.20是合法的IP地址
2.1.0.18不是合法的IP地址
0.2.1.19不是合法的IP地址