#
摘要: 單類包含是指一個類是另一個類的成員變量,比如有這樣兩個類,個人(Person)和地址(Addr),Addr是Person的成員變量,類圖如下:
兩個類分別對應數據庫中的Persons和Addrs表,它們的ER圖如下:
具體怎么把OO對象和具體的數據庫實體表無縫聯系起來呢,下面的代碼展示了如何把兩個類映射到數據庫中的表.
Person類代碼:
package c...
閱讀全文
摘要: 類集合包含意味著一個類中的成員變量是另一個類的集合,比如說公司類Company包含成員類Member的集合.
類圖如下:
它們分別對應數據庫中的Companys表和Members表,它們的ER圖如下:
以下代碼演示了如何將類與數據庫映射起來:
Company類代碼:
package com.sitinspring.companymember;
impo...
閱讀全文
摘要: 多對多關系一般指兩個類都擁有對方集合的成員變量,比如說文章類Article和標簽類Tag,一個Arirtle類可以擁有多個Tag,一個Tag也適用于多篇文章,它們的類圖如下:
它們也分別對應數據庫中的實體表Articles和Tags,當然僅靠這兩個表實現多對多能力是有限的,我們還需要第三個表ArticleTag的幫忙,它們的ER圖如下:
實際上多對多關系并不復雜,加入一個中...
閱讀全文
摘要: 本文是 "從薪水計算的例子看一段程序在不同環境中的變化 " 的續文.
如果需求發生如下變化:
如果說國家改變了公民福利制度,具體就是500元以下的每人補充300元,超過20000元的在原有基礎上再扣除20%,請問該如何編程?
具體等級稅率:
等級 &nb...
閱讀全文
摘要: 如果有以下需求,你是一個貨棧的倉庫保管員,貨棧進口以下多種水果,目前主要是蘋果,香蕉和桔子,貨棧不但需要記錄每批次的品種,單價,還要得出每種水果的總個數,總錢數. 請問該如何編制程序.
記錄每批次不難,一個批次鏈表就可以解決問題,有點意思的部分在于得出每種水果的總個數,總錢數,如果說在加入批次信息時進行處理,根據類型分別判斷,用六個量(分別針對每種水果的總個數,總錢數)分別進行統計.這種方法...
閱讀全文
摘要: 抽象單位類,Soldier和TroopUnit的基類:
package com.sitinspring;
/** *//**
* 抽象單位類,Soldier和TroopUnit的基類
* @author sitinspring(junglesong@gmail.com)
*
*&nbs...
閱讀全文
如果你的答案是斬釘截鐵的"不能",那么請你繼續向下看,說不定這篇文章能對你有所用處.
首先請看兩個類的代碼:
BaseClass:
package com.sitinspring;
import java.util.Vector;
/**
* 基類BaseClass,ChildClass類的父類
* @author: sitinspring(junglesong@gmail.com)
* @date: 2007-12-4
*/
public class BaseClass{
// 私有動態數組成員,注意它是"private"的
private Vector objects;
/**
* 在構造函數
*
*/
public BaseClass(){
objects=new Vector();
}
/**
* 公有函數,向動態數組成員objects添加字符串
* @param str
*/
@SuppressWarnings("unchecked")
public void addStr2Obs(String str){
objects.add(str);
}
/**
* 公有函數,打印objects中的諸元素
*
*/
public void printAll(){
for(int i=0;i<objects.size();i++){
System.out.println("序號="+i+"\t元素="+objects.get(i));
}
}
}
ChildClass,BaseClass的派生類:
package com.sitinspring;
/**
* ChildClass,BaseClass的派生類
* @author: sitinspring(junglesong@gmail.com)
* @date: 2007-12-4
*/
public class ChildClass extends BaseClass{
public void printObjects(){
// 下面的句子是不能編譯通過的
/*for(int i=0;i<objects.size();i++){
System.out.println("序號="+i+"\t元素="+objects.get(i));
}*/
}
public static void main(String[] args){
ChildClass childClass=new ChildClass();
childClass.addStr2Obs("Hello");
childClass.addStr2Obs("World");
childClass.addStr2Obs("China");
childClass.addStr2Obs("sitinspring");
childClass.printAll();
}
}
再讓我們把斷點停在main函數中的childClass.printAll()上,看看實例childClass中到底有什么.
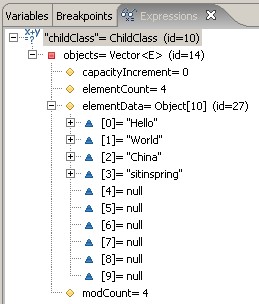
以上截圖證明:
objects確實是ChildClass類實例childClass的成員,而且四個字符串也都被加進去了.
最后執行出來,結果如下:
序號=0 元素=Hello
序號=1 元素=World
序號=2 元素=China
序號=3 元素=sitinspring
這也說明,上面紅字部分的論斷是正確的.
再翻看書籍,關于private限制的成員變量是這樣寫的:
private 只允許來自改類內部的方法訪問.不允許任何來自該類外部的訪問.
我們上面添字符串和遍歷輸出函數都是BaseClass的成員,所以它當然被這兩個函數訪問.而ChildClass的printObjects是BaseClass類外部的函數,結果當然是編譯也不能通過.
實際上,private,public,protected和繼承沒有關系,他們對成員函數和變量的限制只是在成員的可見性上,
public允許來自任何類的訪問;
private只允許來自改類內部的方法訪問,不允許任何來自該類外部的訪問;
protected允許來自同一包中的任何類以及改類的任何地方的任何子類的方法訪問.
而關于成員變量的繼承,
父類的任何成員變量都是會被子類繼承下去的,私有的objects就是明證,這些繼承下來的私有成員雖對子類來說不可見,但子類仍然可以用父類的函數操作他們.
這樣的設計有何意義呢?我們可以用這個方法將我們的成員保護得更好,讓子類的設計者也只能通過父類指定的方法修改父類的私有成員,這樣將能把類保護得更好,這對一個完整的繼承體系是尤為可貴的. jdk源碼就有這樣的例子,java.util.Observable就是這樣設計的.
本文例子下載:
http://www.aygfsteel.com/Files/sitinspring/PrivatePuzzle20071204210542.rar
首先解釋一下,文本中的信息指的是 對象在文本文件中的描述,如"名稱:Bill 職位:SSE 年齡:45 薪水:10000"這個形式的.要求把這樣的信息轉換到對象Member中,對錄入出錯的情況如年齡薪水有非數字字符需要加以鑒別.
對象基本信息如下:

 public class Member implements Comparable
public class Member implements Comparable {
{
 // 名稱
// 名稱
private String name;
// 年齡
private int age;
// 職位
private String title;
// 薪水
private int salary;
.
 }
}
從這段字符串中找到相關的信息并設置到Member對象的相關屬性中并不難,但有幾個地方需要多加考慮:
1.名稱職位薪水年齡的順序不一定一致.
2.職位薪水年齡三個字段和值有可能沒有.
3.有可能需要增加字段,此時類也需要修改.
處理程序需要考慮解析,驗證,賦值三個環節,如果耦合在一起處理當然也能做出來,但這樣做可讀性和可維護性都不好,也背離了面向對象的初衷.好的方案應該把這三部分分開制作函數處理.
文本解析部分:
我的想法是首先將"名稱:Bill 職位:SSE 年齡:45 薪水:10000"以空格劈分成包含這樣元素的鏈表:
名稱:Bill
職位:SSE
年齡:45
薪水:10000
然后在用冒號":"劈分單個元素,前半部分作為鍵,后半部分作為值,放入一個Hashtable中:
key value
名稱 Bill
職位 SSE
年齡 45
薪水 10000
解析部分代碼如下:
/** *//**
* 將分段字符串鏈表轉化成成員鏈表,不成功者記入錯誤鏈表
*
* @param segmentList
* 分段字符串鏈表
*/
private void changeSegmentToMember(List<String> segmentList) {

 for (String segment : segmentList) {
for (String segment : segmentList) {
Map<String, String> ht = StringUtil.parseStr2Map(segment, " ", ":");
Member member = new Member();
if (member.setHtToProperties(ht)) {
// 成功賦值,將成員放入成員列表
memberList.add(member);
} else {
// 有任何錯誤,將分段信息放入錯誤鏈表
errorList.add(segment);
 }
}
}
}
賦值和驗證部分:
然后把這個Hashtable傳入到Member的一個函數setHtToProperties中,這個函數的任務是對Hashtable中的鍵值對進行遍歷,在調用函數setValueToProperty對字段進行賦值:
代碼如下:
/** *//**
* 將哈息表中成對的值按規則輸入屬性
* @param ht
* @return
*/
public boolean setHtToProperties(Map<String,String> ht){
Iterator it=ht.keySet().iterator();
while(it.hasNext()){
String key=(String)it.next();
String value=(String)ht.get(key);
boolean isSettted=setValueToProperty(key,value);
if(isSettted==false){
return false;
}
}
return true;
}

/** *//**
* 在mapping關系中用屬性名去找屬性對應的變量,是則賦值;如找不到或轉化出錯則返回假
* @param propertyName 屬性名,如name對應的名稱
* @param propertyNalue 屬性值,如那么對應的Bill
* @return
*/
private boolean setValueToProperty(String propertyName,String propertyNalue){
if(propertyName.equals("名稱")){
name=propertyNalue;
}
else if(propertyName.equals("年齡")){
try{
int ageTemp=Integer.parseInt(propertyNalue);
age=ageTemp;
}
catch(Exception e){
return false;
}
}
else if(propertyName.equals("職位")){
title=propertyNalue;
}
else if(propertyName.equals("薪水")){
try{
int salaryTemp=Integer.parseInt(propertyNalue);
salary=salaryTemp;
}
catch(Exception e){
return false;
}
}
else{
return false;
}
return true;
}
建立setValueToProperty函數的初衷是,用分支語句建立起鍵值與字段的對應關系,對應上了則進行賦值,這和Mapping有點類似,有些轉化和驗證工作也在分支內進行,只要驗證出現問題即退出處理.
這樣的處理方法帶來了如下好處:
1.外界的類只需要解析文本,不需也不應該知道如何向Member的對應字段賦值,這個工作應該由Member自己進行,setHtToProperties函數幫助達成了這一點,有效降低了Member和其它類的耦合程度.
2.即使職位薪水年齡三個字段和值缺失,也不影響其它字段的賦值過程.
3.如果增加字段,setValueToProperty函數中只需要增加一個Mapping分支即可,其它地方無須改動.
4.對數據的校驗工作可以統一在setValueToProperty函數中完成.
進行了如此處理后,代碼量也不見得比混合處理多多少,而程序更加清晰,適應性也增強了,經得起不斷更改. 比解析驗證賦值混合在一起的方案要強的多.
完整代碼下載:
http://www.aygfsteel.com/Files/sitinspring/MemberProcessor20071207163615.rar
面試題中常有HashMap和Hashtable的異同比較題,今天閑著無事,做了一點小比較,實驗結果如下:
| |
HashMap |
Hashtable |
| 允許空鍵 |
允許 |
不允許 |
| 允許空值 |
允許 |
不允許 |
| 以空鍵取值 |
能取到值 |
|
| 取空值 |
能取得 |
|
| 插值速度 |
稍高 |
稍低 |
| 取值速度 |
高 |
低 |
| 遍歷速度 |
兩者差不多 |
兩者差不多
|
測試代碼如下:
package com.sitinspring;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, String> hashMap = new HashMap<String, String>();
Map<String, String> hashTable = new Hashtable<String, String>();
// 測試一:往兩者中放空鍵,hashMap允許,hashTable不允許,第二句會拋出空指針異常
hashMap.put(null, "value");
hashTable.put(null, "value");
// 測試二:往兩者中放空值,hashMap允許,hashTable不允許,第二句也會拋出空指針異常
hashMap.put("key", null);
hashTable.put("key", null);
// 測試三:以空鍵取hashMap中的值,結果能夠取到"value"
String value = hashMap.get(null);
System.out.println("取出的值等于" + value);
// 測試四:以鍵"key"取hashMap中的值,結果能夠取到null
String value2 = hashMap.get("key");
System.out.println("取出的值等于" + value2);
// 測試五:插值速度比較,兩者差別不大
int max=100000;
TimeTest tableTimeTest=new TimeTest();
setValuesToMap(hashTable,max);
tableTimeTest.end("往hashTable插"+max+"值耗時");
hashMap.clear();// 清楚掉原來加入的值
TimeTest mapTimeTest=new TimeTest();
setValuesToMap(hashMap,max);
mapTimeTest.end("往hashMap插"+max+"個值耗時");
// 測試六:取值速度比較,hashTable速度平均約為hashMap的四分之一到七分之一
TimeTest tableTimeTest2=new TimeTest();
getValuesFromMap(hashTable,max);
tableTimeTest2.end("從hashTable取"+max+"值耗時");
TimeTest mapTimeTest2=new TimeTest();
getValuesFromMap(hashMap,max);
mapTimeTest2.end("往hashMap取"+max+"個值耗時");
// 測試七:遍歷速度比較,hashTable速度和hashMap的差不多
TimeTest tableTimeTest3=new TimeTest();
traversalMap(hashTable);
tableTimeTest3.end("遍歷hashTable耗時");
TimeTest mapTimeTest3=new TimeTest();
traversalMap(hashMap);
mapTimeTest3.end("遍歷hashMap耗時");
}
private static void setValuesToMap(Map<String,String> map,int max){
for(int i=0;i<max;i++){
String str=String.valueOf(i);
map.put(str, str);
}
}
private static void getValuesFromMap(Map<String,String> map,int max){
for(int i=0;i<max;i++){
String str=map.get(i);
}
}
private static void traversalMap(Map<String,String> map){
Iterator it=map.keySet().iterator();
while(it.hasNext()){
String key=(String)it.next();
String value=map.get(key);
}
}
}
package com.sitinspring;
import java.util.Calendar;
import java.util.GregorianCalendar;
public class TimeTest {
private Calendar startTime;
public TimeTest() {
startTime = new GregorianCalendar();
}
public void end(String functionName) {
Calendar endTime = new GregorianCalendar();
int miniteSpan = endTime.get(Calendar.MINUTE)
- startTime.get(Calendar.MINUTE);
int secondSpan = endTime.get(Calendar.SECOND)
- startTime.get(Calendar.SECOND);
int msecondSpan = endTime.get(Calendar.MILLISECOND)
- startTime.get(Calendar.MILLISECOND);
System.out.println(functionName + " " + String.valueOf(miniteSpan)
+ " 分 " + String.valueOf(secondSpan) + " 秒 "
+ String.valueOf(msecondSpan) + " 毫秒 ");
}
}
代碼下載:
http://www.aygfsteel.com/Files/sitinspring/HashMapHashtable20071215212107.rar
摘要: 字符串處理是許多程序中非常重要的一部分,它們可以用于文本顯示,數據表示,查找鍵和很多目的.在Unix下,用戶可以使用正則表達式的強健功能實現這些目的,從Java1.4起,Java核心API就引入了java.util.regex程序包,它是一種有價值的基礎工具,可以用于很多類型的文本處理,如匹配,搜索,提取和分析結構化內容.
java.util.regex是一個用正則表達式所訂制的模式來對字符...
閱讀全文