本文由阿里閑魚(yú)技術(shù)團(tuán)隊(duì)逸昂分享,原題“消息鏈路優(yōu)化之弱感知鏈路優(yōu)化”,有修訂和改動(dòng),感謝作者的分享。
1、引言
閑魚(yú)的IM消息系統(tǒng)作為買(mǎi)家與賣(mài)家的溝通工具,增進(jìn)理解、促進(jìn)信任,對(duì)閑魚(yú)的商品成交有重要的價(jià)值,是提升用戶(hù)體驗(yàn)最關(guān)鍵的環(huán)節(jié)。
然而,隨著業(yè)務(wù)體量的快速增長(zhǎng),當(dāng)前這套消息系統(tǒng)正面臨著諸多急待解決的問(wèn)題。
以下幾個(gè)問(wèn)題典型最為典型:
- 1)在線(xiàn)消息的體驗(yàn)提升;
- 2)離線(xiàn)推送的到達(dá)率;
- 3)消息玩法與消息底層系統(tǒng)的耦合過(guò)強(qiáng)。
經(jīng)過(guò)評(píng)估,我們認(rèn)為現(xiàn)階段離線(xiàn)推送的到達(dá)率問(wèn)題最為關(guān)鍵,對(duì)用戶(hù)體驗(yàn)影響較大。
本文將要分享的是閑魚(yú)IM消息在解決離線(xiàn)推送的到達(dá)率方面的技術(shù)實(shí)踐,內(nèi)容包括問(wèn)題分析和技術(shù)優(yōu)化思路等,希望能帶給你啟發(fā)。
(本文已同步發(fā)布于:http://www.52im.net/thread-3748-1-1.html )
2、系列文章
本文是系列文章的第6篇,總目錄如下:
3、通信鏈路類(lèi)型的劃分
從數(shù)據(jù)通信鏈接的技術(shù)角度,我們根據(jù)閑魚(yú)客戶(hù)端是否在線(xiàn),將整體消息鏈路大致分為強(qiáng)感知鏈路和弱感知鏈路。
強(qiáng)感知鏈路由以下子系統(tǒng)或模塊:
- 1)發(fā)送方客戶(hù)端;
- 2)idleapi-message(閑魚(yú)的消息網(wǎng)關(guān));
- 3)heracles(閑魚(yú)的消息底層服務(wù));
- 4)accs(阿里自研的長(zhǎng)連接通道);
- 5)接收方客戶(hù)端組成。
整條鏈路的核心指標(biāo)在于端到端延遲和消息到達(dá)率。
強(qiáng)感知鏈路中的雙方都是在線(xiàn)的,消息到達(dá)客戶(hù)端就可以保證接收方感知到。強(qiáng)感知鏈路的主要痛點(diǎn)在消息的端到端延遲。
弱感知鏈路與強(qiáng)感知鏈路的主要不同在于:弱感知鏈路的接收方是離線(xiàn)的,需要依賴(lài)離線(xiàn)推送這樣的方式送達(dá)。
因此弱感知鏈路的用戶(hù)感知度不強(qiáng),其核心指標(biāo)在于消息的到達(dá)率,而非延遲。
所以當(dāng)前階段,優(yōu)化弱感知鏈路的重點(diǎn)也就是提升離線(xiàn)消息的到達(dá)率。換句話(huà)說(shuō),提升離線(xiàn)消息到達(dá)率問(wèn)題,也就是優(yōu)化弱感知鏈路本身。
4、消息系統(tǒng)架構(gòu)概覽
下圖一張整個(gè)IM消息系統(tǒng)的架構(gòu)圖,感受下整體鏈路:
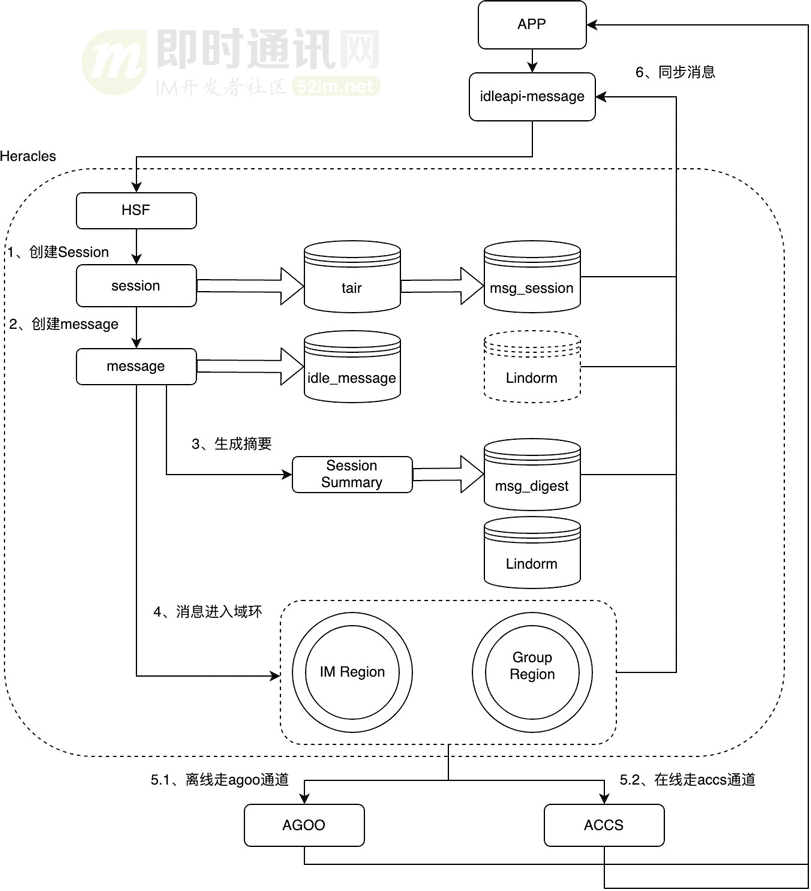
如上圖所示,各主要組件和子系統(tǒng)分工如下:
- 1)HSF是一個(gè)遠(yuǎn)程服務(wù)框架,是dubbo的內(nèi)部版本;
- 2)tair是阿里自研的分布式緩存框架,支持 memcached、Redis、LevelDB 等不同存儲(chǔ)引擎;
- 3)agoo是阿里的離線(xiàn)推送中臺(tái),負(fù)責(zé)整合不同廠商的離線(xiàn)推送通道,向集團(tuán)用戶(hù)提供一個(gè)統(tǒng)一的離線(xiàn)推送服務(wù);
- 4)accs是阿里自研的長(zhǎng)連接通道,為客戶(hù)端、服務(wù)端的實(shí)時(shí)雙向交互提供便利;
- 5)lindorm是阿里自研的NoSQL產(chǎn)品,與HBase有異曲同工之妙;
- 6)域環(huán)是閑魚(yú)消息優(yōu)化性能的核心結(jié)構(gòu),用來(lái)存儲(chǔ)用戶(hù)最新的若干條消息。
強(qiáng)感知鏈路和弱感知鏈路在通道選擇上是不同的:
- 1)強(qiáng)感知鏈路使用accs這個(gè)在線(xiàn)通道;
- 2)弱感知鏈路使用agoo這個(gè)離線(xiàn)通道。
5、弱感知鏈路到底怎么定義
通俗了說(shuō),弱感知鏈路指的就是離線(xiàn)消息推送系統(tǒng)。
相比較于在線(xiàn)消息和端內(nèi)推送(也就是上面說(shuō)的強(qiáng)感知鏈路),離線(xiàn)推送難以確保被用戶(hù)感知到。
典型的情況包括:
- 1)未發(fā)送到用戶(hù)設(shè)備:即推送未送達(dá)用戶(hù)設(shè)備,這種情況可以從通道的返回分析;
- 2)發(fā)送到用戶(hù)設(shè)備但沒(méi)有展示到系統(tǒng)通知欄:閑魚(yú)曾遇到通道返回成功,但是用戶(hù)未看到推送的案例;
- 3)展示到通知欄,并被系統(tǒng)折疊:不同安卓廠商對(duì)推送的折疊策略不同,被折疊后,需用戶(hù)主動(dòng)展開(kāi)才能看到內(nèi)容,觸達(dá)效果明顯變差;
- 4)展示到通知欄,并被用戶(hù)忽略:離線(xiàn)推送的點(diǎn)擊率相比于在線(xiàn)推送更低。
針對(duì)“1)未發(fā)送到用戶(hù)設(shè)備”,原因有:
- 1)離線(xiàn)通道的token失效;
- 2)參數(shù)錯(cuò)誤;
- 3)用戶(hù)關(guān)閉應(yīng)用通知;
- 4)用戶(hù)已卸載等。
針對(duì)“3)展示到通知欄,并被系統(tǒng)折疊”,原因有:
- 1)通知的點(diǎn)擊率;
- 2)應(yīng)用在廠商處的權(quán)重;
- 3)推送的數(shù)量等。
針對(duì)“4)展示到通知欄,并被用戶(hù)忽略”,原因有:
- 1)用戶(hù)不愿意查看推送;
- 2)用戶(hù)看到了推送,但是對(duì)內(nèi)容不感興趣;
- 3)用戶(hù)在忙別的事,無(wú)暇處理。
總之:以上這些離線(xiàn)消息推送場(chǎng)景,對(duì)于用戶(hù)來(lái)說(shuō)感知度不高,我們也便稱(chēng)之為弱感知鏈路。
6、弱感知鏈路的邏輯構(gòu)成
我們的弱感知鏈路分為3部分,即:
- 1)系統(tǒng);
- 2)通道;
- 3)用戶(hù)。
共包含了Hermes、agoo、廠商、設(shè)備、用戶(hù)、承接頁(yè)這幾個(gè)環(huán)節(jié)。具體如下圖所示。
從推送的產(chǎn)生到用戶(hù)最終進(jìn)入APP,共分為如下幾個(gè)步驟:
- 步驟1:Hermes是閑魚(yú)的用戶(hù)觸達(dá)系統(tǒng),負(fù)責(zé)人群管理、內(nèi)容管理、時(shí)機(jī)把控,是整個(gè)弱感知鏈路的起點(diǎn)。;
- 步驟2:agoo是阿里內(nèi)部承接離線(xiàn)推送的中臺(tái),是閑魚(yú)離線(xiàn)推送能力的基礎(chǔ);
- 步驟3:agoo實(shí)現(xiàn)離線(xiàn)推送依靠的是廠商的推送通道(如:蘋(píng)果的apns通道、Google的fcm通道、及國(guó)內(nèi)各廠商的自建通道。;
- 步驟4:通過(guò)廠商的通道,推送最終出現(xiàn)在用戶(hù)的設(shè)備上,這是用戶(hù)能感知到推送的前提條件;
- 步驟5:如果用戶(hù)剛巧看到這條推送,推送的內(nèi)容也很有趣,在用戶(hù)的主動(dòng)點(diǎn)擊下會(huì)喚起APP,打開(kāi)承接頁(yè),進(jìn)而給用戶(hù)展示個(gè)性化的商品。
經(jīng)過(guò)以上5個(gè)步驟,至此弱感知鏈路就完成了使命。
7、弱感知鏈路面臨的具體問(wèn)題
弱感知鏈路的核心問(wèn)題在于:
- 1)推送的消息是否投遞給了用戶(hù);
- 2)已投遞到的消息用戶(hù)是否有感知。
這對(duì)應(yīng)推送的兩個(gè)階段:
- 1)推送消息是否已到達(dá)設(shè)備;
- 2)用戶(hù)是否查看推送并點(diǎn)擊。
其中:到達(dá)設(shè)備這個(gè)階段是最基礎(chǔ)的,也是本次優(yōu)化的核心。
我們可以將每一步的消息處理量依次平鋪,展開(kāi)為一張漏斗圖,從而直觀的查看鏈路的瓶頸。
漏斗圖斜率最大的地方是優(yōu)化的重點(diǎn),差異小的地方不需要優(yōu)化:
通過(guò)分析以上漏斗圖,弱感知鏈路的優(yōu)化重點(diǎn)在三個(gè)方面:
- 1)agoo受理率:是指我們發(fā)送推送請(qǐng)到的數(shù)量到可以通過(guò)agoo(阿里承接離線(xiàn)推送的中臺(tái))轉(zhuǎn)發(fā)到廠商通道的數(shù)量之間的漏斗;
- 2)廠商受理率:是指agoo中臺(tái)受理的量到廠商返回成功的量之間的漏斗;
- 3)Push點(diǎn)擊率:也就通過(guò)以上通道最終已送到到用戶(hù)終端的消息,是否最終轉(zhuǎn)化為用戶(hù)的主動(dòng)“點(diǎn)擊”。
有了優(yōu)化方向,我們來(lái)看看優(yōu)化手段吧。
8、我們的技術(shù)優(yōu)化手段
跟隨推送的視角,順著鏈路看一下我們是如何進(jìn)行優(yōu)化的。
8.1 agoo受理率優(yōu)化
用戶(hù)的推送,從 Hermes 站點(diǎn)搭乘“班車(chē)”,駛向下一站: agoo。
這是推送經(jīng)歷的第一站。到站一看,傻眼了,只有不到一半的推送到站下車(chē)了。這是咋回事嘞?
這就要先說(shuō)說(shuō) agoo 了,調(diào)用 agoo 有兩種方式:
- 1)指定設(shè)備和客戶(hù)端,agoo直接將推送投遞到相應(yīng)的設(shè)備;
- 2)指定用戶(hù)和客戶(hù)端,agoo根據(jù)內(nèi)部的轉(zhuǎn)換表,找到用戶(hù)對(duì)應(yīng)的設(shè)備,再進(jìn)行投遞。
我們的系統(tǒng)不保存用戶(hù)的設(shè)備信息。因此,是按照用戶(hù)來(lái)調(diào)用agoo的。
同時(shí):由于沒(méi)有用戶(hù)的設(shè)備信息,并不知道用戶(hù)是 iOS 客戶(hù)端還是 Android 客戶(hù)端。工程側(cè)不得不向 iOS 和 Android 都發(fā)送一遍推送。雖然保證了到達(dá),但是,一半的調(diào)用都是無(wú)效的。
為了解這個(gè)問(wèn)題:我們使用了agoo的設(shè)備信息。將用戶(hù)轉(zhuǎn)換設(shè)備這一階段提前到了調(diào)用 agoo 之前,先明確用戶(hù)對(duì)應(yīng)的設(shè)備,再指定設(shè)備調(diào)用 agoo,從而避免無(wú)效調(diào)用。

agoo調(diào)用方式優(yōu)化后,立刻剔除了無(wú)效調(diào)用,agoo受理率有了明顯提升。
至此:我們總算能對(duì) agoo 受理失敗的真正原因做一個(gè)高大上的分析了。
根據(jù)統(tǒng)計(jì):推送被 agoo 拒絕的主要原因是——用戶(hù)關(guān)閉了通知權(quán)限。同時(shí),我們對(duì) agoo 調(diào)用數(shù)據(jù)的進(jìn)一步分析發(fā)現(xiàn)——有部分用戶(hù)找不到對(duì)應(yīng)的設(shè)備。 優(yōu)化到此,我們猛然發(fā)現(xiàn)多了兩個(gè)問(wèn)題。
那就繼續(xù)優(yōu)化唄:
- 1)通知體驗(yàn)優(yōu)化,引導(dǎo)打開(kāi)通知權(quán)限;
- 2)與agoo共建設(shè)備庫(kù),解決設(shè)備轉(zhuǎn)換失敗的問(wèn)題。
這兩個(gè)優(yōu)化方向又是一片新天地,我們擇日再聊。
8.2 廠商推送通道受理率優(yōu)化
推送到達(dá) agoo ,分機(jī)型搭乘廠商“專(zhuān)列”,駛向下一站:用戶(hù)設(shè)備。
這是推送經(jīng)歷的第二站。出站查票,發(fā)現(xiàn)竟然超員了。
于是乎:我們每天有大量推送因?yàn)槌^(guò)廠商設(shè)定的限額被攔截。
為什么會(huì)這樣呢?
實(shí)際上:提供推送通道的廠商(沒(méi)錯(cuò),各手機(jī)廠商的自家推送通道良莠不齊),為了保證用戶(hù)體驗(yàn),會(huì)對(duì)每個(gè)應(yīng)用能夠推送的消息總量進(jìn)行限制。
對(duì)于廠商而言,這個(gè)限制會(huì)根據(jù)推送的類(lèi)型和應(yīng)用的用戶(hù)規(guī)模設(shè)定——推送主要分為產(chǎn)品類(lèi)的推送和營(yíng)銷(xiāo)類(lèi)的推送。
廠商推送通道對(duì)于不同類(lèi)型消息的限制是:
- 1)對(duì)于產(chǎn)品類(lèi)推送,廠商會(huì)保證到達(dá);
- 2)對(duì)于營(yíng)銷(xiāo)類(lèi)推送,廠商會(huì)進(jìn)行額度限制;
- 3)未標(biāo)記的推送,默認(rèn)作為營(yíng)銷(xiāo)類(lèi)推送對(duì)待。
我們剛好沒(méi)有對(duì)推送進(jìn)行標(biāo)記,因此觸發(fā)了廠商的推送限制。
這對(duì)我們的用戶(hù)來(lái)說(shuō),會(huì)帶來(lái)困擾。閑魚(yú)的交易,很依賴(lài)買(mǎi)賣(mài)家之間的消息互動(dòng)。這部分消息是需要確保到達(dá)的。
同樣:訂單類(lèi)的消息、用戶(hù)的關(guān)注,也需要保證推送給用戶(hù)。
根據(jù)主流廠商的接口協(xié)議,我們將推送的消息分為以下幾類(lèi),并進(jìn)行相應(yīng)標(biāo)記:
- 1)即時(shí)通訊消息;
- 2)訂單狀態(tài)變化;
- 3)用戶(hù)關(guān)注內(nèi)容;
- 4)營(yíng)銷(xiāo)消息這幾類(lèi)。
同時(shí),在業(yè)務(wù)上,我們也進(jìn)行了推送的治理——將用戶(hù)關(guān)注度不高的消息,取消推送,避免打擾。
經(jīng)過(guò)這些優(yōu)化,因?yàn)槌^(guò)廠商限額而被攔截的推送實(shí)現(xiàn)了清零。
8.3 Push點(diǎn)擊率優(yōu)化
通過(guò)優(yōu)化agoo受理率、廠商受理率,我們解決了推送到達(dá)量的瓶頸。但即使消息被最終送達(dá),用戶(hù)到底點(diǎn)擊了沒(méi)有?這才是消息推送的根本意義所在。
于是,在日常的開(kāi)發(fā)測(cè)試過(guò)程中,我們發(fā)現(xiàn)了推送的兩個(gè)體驗(yàn)問(wèn)題:
- 1)用戶(hù)點(diǎn)擊Push有開(kāi)屏廣告;
- 2)營(yíng)銷(xiāo)Push也有權(quán)限校驗(yàn),更換用戶(hù)登陸后無(wú)法點(diǎn)擊。
對(duì)于開(kāi)屏廣告功能,我們?cè)黾恿薖ush點(diǎn)擊跳過(guò)廣告的能力。
針對(duì)Push的權(quán)限校驗(yàn)功能,閑魚(yú)根據(jù)場(chǎng)景做了細(xì)分:
- 1)涉及個(gè)人隱私的推送,保持權(quán)限校驗(yàn)不變;
- 2)營(yíng)銷(xiāo)類(lèi)的推送,放開(kāi)權(quán)限校驗(yàn)。
以上是點(diǎn)擊體驗(yàn)的優(yōu)化,我們還需要考慮用戶(hù)的點(diǎn)擊意愿。
用戶(hù)點(diǎn)擊量與推送的曝光量、推送素材的有趣程度相關(guān)。推送的曝光量又和推送的到達(dá)量、推送的到達(dá)時(shí)機(jī)有關(guān)。
具體的優(yōu)化手段是:
- 1)在推送內(nèi)容上:我們需要優(yōu)化的是推送的時(shí)機(jī)和相應(yīng)的素材;
- 2)在推送時(shí)機(jī)上:算法會(huì)根據(jù)用戶(hù)的偏好和個(gè)性化行為數(shù)據(jù),計(jì)算每個(gè)用戶(hù)的個(gè)性化推送時(shí)間,在用戶(hù)空閑的時(shí)間推送(避免在不合適的時(shí)間打擾用戶(hù),同時(shí)也能提升用戶(hù)看到推送的可能性)。
- 3)在推送素材上:算法會(huì)根據(jù)素材的實(shí)時(shí)點(diǎn)擊反饋,對(duì)素材做實(shí)時(shí)賽馬。只發(fā)用戶(hù)感興趣的素材,提高用戶(hù)點(diǎn)擊意愿。
9、實(shí)際優(yōu)化效果
通過(guò)以上我們的分析和技術(shù)優(yōu)化手段,整體弱推送鏈路鏈路有了不錯(cuò)的提升,離線(xiàn)消息的到達(dá)率相對(duì)提升了兩位數(shù)。
10、寫(xiě)在最后
本篇主要和大家聊的是只是IM消息系統(tǒng)鏈路中的一環(huán)——弱感知鏈路的優(yōu)化,落地到到具體的業(yè)務(wù)也就是離線(xiàn)消息送達(dá)率問(wèn)題。
整體IM消息系統(tǒng),還是一個(gè)比較復(fù)雜的領(lǐng)域。
我們?cè)谙⑾到y(tǒng)的發(fā)展過(guò)程中,面臨著如下問(wèn)題:
這些問(wèn)題,我們?cè)谝郧暗奈恼轮杏兴窒恚院笠矔?huì)陸續(xù)分享更多,敬請(qǐng)期待。
附錄:相關(guān)資料
[1] Android P正式版即將到來(lái):后臺(tái)應(yīng)用保活、消息推送的真正噩夢(mèng)
[2] 一套高可用、易伸縮、高并發(fā)的IM群聊、單聊架構(gòu)方案設(shè)計(jì)實(shí)踐
[3] 一套億級(jí)用戶(hù)的IM架構(gòu)技術(shù)干貨(上篇):整體架構(gòu)、服務(wù)拆分等
[4] 一套億級(jí)用戶(hù)的IM架構(gòu)技術(shù)干貨(下篇):可靠性、有序性、弱網(wǎng)優(yōu)化等
[5] 從新手到專(zhuān)家:如何設(shè)計(jì)一套億級(jí)消息量的分布式IM系統(tǒng)
[6] 企業(yè)微信的IM架構(gòu)設(shè)計(jì)揭秘:消息模型、萬(wàn)人群、已讀回執(zhí)、消息撤回等
[7] 融云技術(shù)分享:全面揭秘億級(jí)IM消息的可靠投遞機(jī)制
[8] 移動(dòng)端IM中大規(guī)模群消息的推送如何保證效率、實(shí)時(shí)性?
[9] 現(xiàn)代IM系統(tǒng)中聊天消息的同步和存儲(chǔ)方案探討
[10] 新手入門(mén)一篇就夠:從零開(kāi)發(fā)移動(dòng)端IM
[11] 移動(dòng)端IM開(kāi)發(fā)者必讀(一):通俗易懂,理解移動(dòng)網(wǎng)絡(luò)的“弱”和“慢”
[12] 移動(dòng)端IM開(kāi)發(fā)者必讀(二):史上最全移動(dòng)弱網(wǎng)絡(luò)優(yōu)化方法總結(jié)
[13] IM消息送達(dá)保證機(jī)制實(shí)現(xiàn)(一):保證在線(xiàn)實(shí)時(shí)消息的可靠投遞
[14] IM消息送達(dá)保證機(jī)制實(shí)現(xiàn)(二):保證離線(xiàn)消息的可靠投遞
[15] 零基礎(chǔ)IM開(kāi)發(fā)入門(mén)(一):什么是IM系統(tǒng)?
[16] 零基礎(chǔ)IM開(kāi)發(fā)入門(mén)(二):什么是IM系統(tǒng)的實(shí)時(shí)性?
[17] 零基礎(chǔ)IM開(kāi)發(fā)入門(mén)(三):什么是IM系統(tǒng)的可靠性?
[18] 零基礎(chǔ)IM開(kāi)發(fā)入門(mén)(四):什么是IM系統(tǒng)的消息時(shí)序一致性?
本文已同步發(fā)布于“即時(shí)通訊技術(shù)圈”公眾號(hào)。
同步發(fā)布鏈接是:http://www.52im.net/thread-3748-1-1.html