本文由微信技術(shù)團隊仇弈彬分享,原題“微信海量數(shù)據(jù)查詢?nèi)绾螐?000ms降到100ms?”,本文進行了內(nèi)容修訂和排版優(yōu)化。
1、引言
微信的多維指標監(jiān)控平臺,具備自定義維度、指標的監(jiān)控能力,主要服務(wù)于用戶自定義監(jiān)控。作為框架級監(jiān)控的補充,它承載著聚合前 45億/min、4萬億/天的數(shù)據(jù)量。
當前,針對數(shù)據(jù)層的查詢請求也達到了峰值 40萬/min,3億/天。較大的查詢請求使得數(shù)據(jù)查詢遇到了性能瓶頸:查詢平均耗時 > 1000ms,失敗率居高不下。
針對大數(shù)據(jù)量帶來的查詢性能問題,微信團隊對數(shù)據(jù)層查詢接口進行了針對性的優(yōu)化,將平均查詢速度從1000ms+優(yōu)化到了100ms級別。本文為各位分享優(yōu)化過程,希望對你有用!
2、技術(shù)背景
微信多維指標監(jiān)控平臺(以下簡稱多維監(jiān)控),是具備靈活的數(shù)據(jù)上報方式、提供維度交叉分析的實時監(jiān)控平臺。
在這里,最核心的概念是“協(xié)議”、“維度”與“指標”。
例如:如果想要對某個【省份】、【城市】、【運營商】的接口【錯誤碼】進行監(jiān)控,監(jiān)控目標是統(tǒng)計接口的【平均耗時】和【上報量】。在這里,省份、城市、運營商、錯誤碼,這些描述監(jiān)控目標屬性的可枚舉字段稱之為“維度”,而【上報量】、【平均耗時】等依賴“聚合計算”結(jié)果的數(shù)據(jù)值,稱之為“指標”。而承載這些指標和維度的數(shù)據(jù)表,叫做“協(xié)議”。
多維監(jiān)控對外提供 2 種 API:
1)維度枚舉查詢:用于查詢某一段時間內(nèi),一個或多個維度的排列組合以及其對應(yīng)的指標值。它反映的是各維度分布“總量”的概念,可以“聚合”,也可以“展開”,或者固定維度對其它維度進行“下鉆”。數(shù)據(jù)可以直接生成柱狀圖、餅圖等。
2)時間序列查詢:用于查詢某些維度條件在某個時間范圍的指標值序列。可以展示為一個時序曲線圖,橫坐標為時間,縱坐標為指標值。
然而,不管是用戶還是團隊自己使用多維監(jiān)控平臺的時候,都能感受到明顯的卡頓。主要表現(xiàn)在看監(jiān)控圖像或者是查看監(jiān)控曲線,都會經(jīng)過長時間的數(shù)據(jù)加載。
團隊意識到:這是數(shù)據(jù)量上升必然帶來的瓶頸。
目前:多維監(jiān)控平臺已經(jīng)接入了數(shù)千張協(xié)議表,每張表的特點都不同。維度組合、指標量、上報量也不同。針對大量數(shù)據(jù)的實時聚合以及 OLAP 分析,數(shù)據(jù)層的性能瓶頸越發(fā)明顯,嚴重影響了用戶體驗。
于是這讓團隊人員不由得開始思考:難道要一直放任它慢下去嗎?答案當然是否定的。因此,微信團隊針對數(shù)據(jù)層的查詢進行了優(yōu)化。
3、優(yōu)化分析1:用戶查詢行為分析
要優(yōu)化,首先需要了解用戶的查詢習(xí)慣,這里的用戶包含了頁面用戶和異常檢測服務(wù)。
于是微信團隊盡可能多地上報用戶使用多維監(jiān)控平臺的習(xí)慣,包括但不限于:常用的查詢類型、每個協(xié)議表的查詢維度和查詢指標、查詢量、失敗量、耗時數(shù)據(jù)等。
在分析了用戶的查詢習(xí)慣后,有了以下發(fā)現(xiàn):
1)時間序列查詢占比 99% 以上:
出現(xiàn)如此懸殊的比例可能是因為:調(diào)用一次維度枚舉,即可獲取所關(guān)心的各個維度。
但是針對每個維度組合值,無論是頁面還是異常檢測都會在查詢維度對應(yīng)的多條時間序列曲線中,從而出現(xiàn)「時間序列查詢」比例遠遠高于「維度枚舉查詢」。
2)針對1天前的查詢占比約 90%:
出現(xiàn)這個現(xiàn)象可能是因為每個頁面數(shù)據(jù)都會帶上幾天前的數(shù)據(jù)對比來展示。異常檢測模塊每次會對比大約 7 天數(shù)據(jù)的曲線,造成了對大量的非實時數(shù)據(jù)進行查詢。
4、優(yōu)化分析2:數(shù)據(jù)層架構(gòu)
分析完用戶習(xí)慣,再看下目前的數(shù)據(jù)層架構(gòu)。
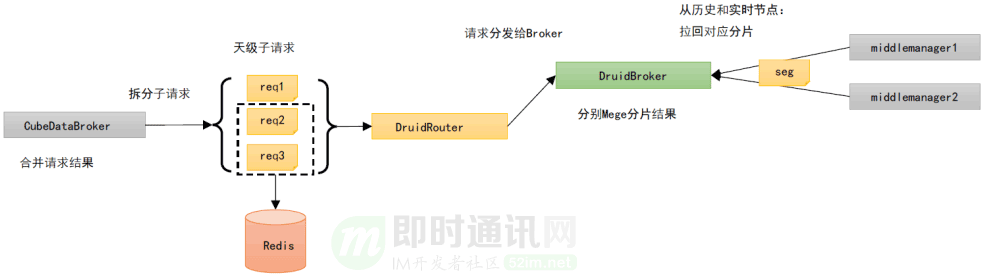
多維監(jiān)控底層的數(shù)據(jù)存儲/查詢引擎選擇了 Apache-Druid 作為數(shù)據(jù)聚合、存儲的引擎,Druid 是一個非常優(yōu)秀的分布式 OLAP 數(shù)據(jù)存儲引擎,它的特點主要在于出色的預(yù)聚合能力和高效的并發(fā)查詢能力。
它的大致架構(gòu)如圖:

具體解釋就是:
5、優(yōu)化分析3:為什么查詢會慢
查詢慢的核心原因,經(jīng)微信團隊分析如下:
1)協(xié)議數(shù)據(jù)分片存儲的數(shù)據(jù)片段為 2-4h 的數(shù)據(jù),每個 Peon 節(jié)點消費回來的數(shù)據(jù)會存儲在一個獨立分片。
2)假設(shè)異常檢測獲取 7 * 24h 的數(shù)據(jù),協(xié)議一共有 3 個 Peon 節(jié)點負責消費,數(shù)據(jù)分片量級為 12*3*7 = 252,意味著將會產(chǎn)生 252次 數(shù)據(jù)分片 I/O。
3)在時間跨度較大時、MiddleManager、Historical 處理查詢?nèi)菀壮瑫r,Broker 內(nèi)存消耗較高。
4)部分協(xié)議維度字段非常復(fù)雜,維度排列組合極大(>100w),在處理此類協(xié)議的查詢時,性能就會很差。
6、優(yōu)化實踐1:拆分子查詢請求
根據(jù)上面的分析,團隊確定了初步的優(yōu)化方向:
- 1)減少單 Broker 的大跨度時間查詢;
- 2)減少 Druid 的 Segments I/O 次數(shù);
- 3)減少 Segments 的大小。
在這個方案中,每個查詢都會被拆解為更細粒度的“子查詢”請求。例如連續(xù)查詢 7 天的時間序列,會被自動拆解為 7 個 1天的時間序列查詢,分發(fā)到多個 Broker,此時可以利用多個 Broker 來進行并發(fā)查詢,減少單個 Broker 的查詢負載,提升整體性能。
但是這個方案并沒有解決 Segments I/O 過多的問題,所以需要在這里引入一層緩存。
7、優(yōu)化實踐2:拆分子查詢請求+Redis Cache
7.1概述
這個方案相較于 v1,增加了為每個子查詢請求維護了一個結(jié)果緩存,存儲在 Redis 中(如下圖所示)。
假設(shè)獲取 7*24h 的數(shù)據(jù),Peon 節(jié)點個數(shù)為 3,如果命中緩存,只會產(chǎn)生 3 次 Druid 的 Segments I/O (最近的 30min)數(shù)據(jù),相較幾百次 Segments I/O 會大幅減少。
接下來看下具體方法。
7.2時間序列子查詢設(shè)計
針對時間序列的子查詢,子查詢按照「天」來分解,整個子查詢的緩存也是按照天來聚合的。
以一個查詢?yōu)槔?/strong>
{
"biz_id": 1, // 查詢協(xié)議表ID:1
"formula": "avg_cost_time", // 查詢公式:求平均
"keys": [
// 查詢條件:維度xxx_id=3
{"field": "xxx_id", "relation": "eq", "value": "3"}
],
"start_time": "2020-04-15 13:23", // 查詢起始時間
"end_time": "2020-04-17 12:00"http:// 查詢結(jié)束時間
}
其中 biz_id、 formula,、keys 了每個查詢的基本條件。但每個查詢各不相同,不是這次討論的重點。
本次優(yōu)化的重點是基于查詢時間范圍的子查詢分解,而對于時間序列子查詢分解的方案則是按照「天」來分解,每個查詢都會得到當天的全部數(shù)據(jù),由業(yè)務(wù)邏輯層來進行合并。
舉個例子:04-15 13:23 ~ 04-17 08:20 的查詢,會被分解為 04-15、04-16、04-17 三個子查詢,每個查詢都會得到當天的全部數(shù)據(jù),在業(yè)務(wù)邏輯層找到基于用戶查詢時間的偏移量,處理結(jié)果并返回給用戶。
每個子查詢都會先嘗試獲取緩存中的數(shù)據(jù),此時有兩種結(jié)果:

經(jīng)過上述分析不難看出:對于距離現(xiàn)在超過一天的查詢,只需要查詢一次,之后就無需訪問 DruidBroker 了,可以直接從緩存中獲取。
而對于一些實時熱數(shù)據(jù),其實只是查詢了cache_update_time-threshold_time 到 end_time 這一小段的時間。在實際應(yīng)用里,這段查詢時間的跨度基本上在 20min 內(nèi),而 15min 內(nèi)的數(shù)據(jù)由 Druid 實時節(jié)點提供。
7.3維度組合子查詢設(shè)計
維度枚舉查詢和時間序列查詢不一樣的是:每一分鐘,每個維度的量都不一樣。
而維度枚舉拿到的是各個維度組合在任意時間的總量,因此基于上述時間序列的緩存方法無法使用。在這里,核心思路依然是打散查詢和緩存。
對此,微信團隊使用了如下方案。
緩存的設(shè)計采用了多級冗余模式,即每天的數(shù)據(jù)會根據(jù)不同時間粒度:天級、4小時級、1 小時級存多份,從而適應(yīng)各種粒度的查詢,也同時盡量減少和 Redis 的 IO 次數(shù)。
每個查詢都會被分解為 N 個子查詢,跨度不同時間,這個過程的粗略示意圖如下:
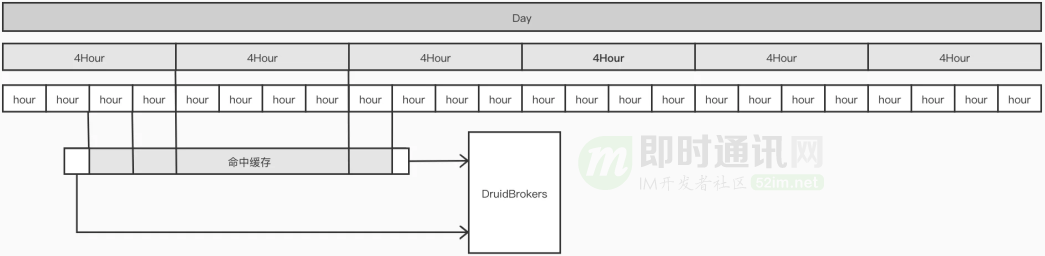
舉個例子:例如 04-15 13:23 ~ 04-17 08:20 的查詢,會被分解為以下 10 個子查詢:
04-15 13:23 ~ 04-15 14:00
04-15 14:00 ~ 04-15 15:00
04-15 15:00 ~ 04-15 16:00
04-15 16:00 ~ 04-15 20:00
04-15 20:00 ~ 04-16 00:00
04-16 00:00 ~ 04-17 00:00
04-17 00:00 ~ 04-17 04:00
04-17 00:00 ~ 04-17 04:00
04-17 04:00 ~ 04-17 08:00
04-17 08:00 ~ 04-17 08:20
這里可以發(fā)現(xiàn):查詢 1 和查詢 10,絕對不可能出現(xiàn)在緩存中。因此這兩個查詢一定會被轉(zhuǎn)發(fā)到 Druid 去進行。2~9 查詢,則是先嘗試訪問緩存。如果緩存中不存在,才會訪問 DruidBroker,在完成一次訪問后將數(shù)據(jù)異步回寫到 Redis 中。
維度枚舉查詢和時間序列一樣,同時也用了 update_time 作為數(shù)據(jù)可信度的保障。因為最細粒度為小時,在理想狀況下一個時間跨越很長的請求,實際上訪問 Druid 的最多只有跨越 2h 內(nèi)的兩個首尾部查詢而已。
8、優(yōu)化實踐3:更進一步(子維度表)
通過子查詢緩存方案,我們已經(jīng)限制了 I/O 次數(shù),并且保障 90% 的請求都來自于緩存。但是維度組合復(fù)雜的協(xié)議,即 Segments 過大的協(xié)議,仍然會消耗大量時間用于檢索數(shù)據(jù)。
所以核心問題在于:能否進一步降低 Segments 大小?
維度爆炸問題在業(yè)界都沒有很好的解決方案,大家要做的也只能是盡可能規(guī)避它,因此這里,團隊在查詢層實現(xiàn)了子維度表的拆分以盡可能解決這個問題,用空間換時間。
具體做法為:
- 1) 對于維度復(fù)雜的協(xié)議,抽離命中率高的低基數(shù)維度,建立子維度表,實時消費并入庫數(shù)據(jù);
- 2) 查詢層支持按照用戶請求中的查詢維度,匹配最小的子維度表。
9、優(yōu)化成果
9.1緩存命中率>85%
在做完所有改造后,最重要的一點便是緩存命中率。因為大部分的請求來自于1天前的歷史數(shù)據(jù),這為緩存命中率提供了保障。
具體是:
- 1)子查詢緩存完全命中率(無需查詢Druid):86%;
- 2)子查詢緩存部分命中率(秩序查詢增量數(shù)據(jù)):98.8%。
9.2查詢耗時優(yōu)化至 100ms
在整體優(yōu)化過后,查詢性能指標有了很大的提升:
平均耗時 1000+ms -> 140ms;P95:5000+ms -> 220ms。
10、相關(guān)文章
[1] 微信后臺基于時間序的海量數(shù)據(jù)冷熱分級架構(gòu)設(shè)計實踐
[2] IM開發(fā)基礎(chǔ)知識補課(三):快速理解服務(wù)端數(shù)據(jù)庫讀寫分離原理及實踐建議
[3] 社交軟件紅包技術(shù)解密(六):微信紅包系統(tǒng)的存儲層架構(gòu)演進實踐
[4] 微信后臺基于時間序的新一代海量數(shù)據(jù)存儲架構(gòu)的設(shè)計實踐
[5] 陌陌技術(shù)分享:陌陌IM在后端KV緩存架構(gòu)上的技術(shù)實踐
[6] 現(xiàn)代IM系統(tǒng)中聊天消息的同步和存儲方案探討
[7] 微信海量用戶背后的后臺系統(tǒng)存儲架構(gòu)(視頻+PPT) [附件下載]
[8] 騰訊TEG團隊原創(chuàng):基于MySQL的分布式數(shù)據(jù)庫TDSQL十年鍛造經(jīng)驗分享
[9] IM全文檢索技術(shù)專題(四):微信iOS端的最新全文檢索技術(shù)優(yōu)化實踐
[10] 微信Windows端IM消息數(shù)據(jù)庫的優(yōu)化實踐:查詢慢、體積大、文件損壞等
[11] 微信技術(shù)分享:揭秘微信后臺安全特征數(shù)據(jù)倉庫的架構(gòu)設(shè)計
[12] 現(xiàn)代IM系統(tǒng)中聊天消息的同步和存儲方案探討
11、微信團隊的其它文章
《Android版微信安裝包“減肥”實戰(zhàn)記錄》
《iOS版微信安裝包“減肥”實戰(zhàn)記錄》
《移動端IM實踐:iOS版微信界面卡頓監(jiān)測方案》
《微信“紅包照片”背后的技術(shù)難題》
《IPv6技術(shù)詳解:基本概念、應(yīng)用現(xiàn)狀、技術(shù)實踐(上篇)》
《微信技術(shù)分享:微信的海量IM聊天消息序列號生成實踐(算法原理篇)》
《微信團隊分享:Kotlin漸被認可,Android版微信的技術(shù)嘗鮮之旅》
《社交軟件紅包技術(shù)解密(二):解密微信搖一搖紅包從0到1的技術(shù)演進》
《社交軟件紅包技術(shù)解密(十一):解密微信紅包隨機算法(含代碼實現(xiàn))》
《QQ設(shè)計團隊分享:新版 QQ 8.0 語音消息改版背后的功能設(shè)計思路》
《微信團隊分享:極致優(yōu)化,iOS版微信編譯速度3倍提升的實踐總結(jié)》
《IM“掃一掃”功能很好做?看看微信“掃一掃識物”的完整技術(shù)實現(xiàn)》
《微信團隊分享:微信支付代碼重構(gòu)帶來的移動端軟件架構(gòu)上的思考》
《IM開發(fā)寶典:史上最全,微信各種功能參數(shù)和邏輯規(guī)則資料匯總》
《微信團隊分享:微信直播聊天室單房間1500萬在線的消息架構(gòu)演進之路》
《企業(yè)微信的IM架構(gòu)設(shè)計揭秘:消息模型、萬人群、已讀回執(zhí)、消息撤回等》
《微信團隊分享:微信后臺在海量并發(fā)請求下是如何做到不崩潰的》
《IM跨平臺技術(shù)學(xué)習(xí)(九):全面解密新QQ桌面版的Electron內(nèi)存優(yōu)化實踐》
《企業(yè)微信針對百萬級組織架構(gòu)的客戶端性能優(yōu)化實踐》
《揭秘企業(yè)微信是如何支持超大規(guī)模IM組織架構(gòu)的——技術(shù)解讀四維關(guān)系鏈》
《微信團隊分享:詳解iOS版微信視頻號直播中因幀率異常導(dǎo)致的功耗問題》
(本文已同步發(fā)布于:http://www.52im.net/thread-4629-1-1.html)