本文由融云技術(shù)團(tuán)隊(duì)原創(chuàng)分享,原題“萬(wàn)字干貨:IM “消息”列表卡頓優(yōu)化實(shí)踐”,為使文章更好理解,內(nèi)容有修訂。
1、引言
隨著移動(dòng)互聯(lián)網(wǎng)的普及,無(wú)論是IM開(kāi)發(fā)者還是普通用戶,IM即時(shí)通訊應(yīng)用在日常使用中都是必不可少的,比如:熟人社交的某信、IM活化石的某Q、企業(yè)場(chǎng)景的某釘?shù)龋瑤缀跏侨巳吮匮b。
以下就是幾款主流的IM應(yīng)用(看首頁(yè)就知道是哪款,我就不廢話了):
正如上圖所示,這些IM的首頁(yè)(也就是“消息”列表界面)對(duì)于用戶來(lái)說(shuō)每次打開(kāi)應(yīng)用必見(jiàn)的。隨著時(shí)間和推移,這個(gè)首頁(yè)“消息”列表里的內(nèi)容會(huì)越來(lái)越多、消息種類也越來(lái)越雜。
無(wú)論哪款I(lǐng)M,隨著“消息”列表里數(shù)據(jù)量和類型越來(lái)越多,對(duì)于列表的滑動(dòng)體驗(yàn)來(lái)說(shuō)肯定會(huì)受到影響。而作為整個(gè)IM的“第一頁(yè)”,這個(gè)列表的體驗(yàn)如何直接決定了用戶的第一印象,非常重要!
有鑒于此,市面上的主流IM對(duì)于“消息”列表的滑動(dòng)體驗(yàn)(主要是卡頓問(wèn)題)問(wèn)題,都會(huì)特別關(guān)注并著重優(yōu)化。
本文將要分享是融云IM技術(shù)團(tuán)隊(duì)基于對(duì)自有產(chǎn)品“消息”列表卡頓問(wèn)題的分析和實(shí)踐(本文以Andriod端為例),為你展示一款I(lǐng)M在解決類似問(wèn)題時(shí)的分析思路和解決方案,希望能帶給你啟發(fā)。
特別說(shuō)明:本文優(yōu)化實(shí)踐的產(chǎn)品源碼可以從公開(kāi)渠道獲取到,感興趣的讀者可以從本文“附錄1:源碼下載”下載,建議僅用于研究學(xué)習(xí)目的哦。
(本文已同步發(fā)布于:http://www.52im.net/thread-3732-1-1.html)
2、相關(guān)文章
IM客戶端優(yōu)化相關(guān)文章:
- 《IM開(kāi)發(fā)干貨分享:我是如何解決大量離線消息導(dǎo)致客戶端卡頓的》
- 《IM開(kāi)發(fā)干貨分享:網(wǎng)易云信IM客戶端的聊天消息全文檢索技術(shù)實(shí)踐》
- 《融云技術(shù)分享:融云安卓端IM產(chǎn)品的網(wǎng)絡(luò)鏈路保活技術(shù)實(shí)踐》
- 《阿里技術(shù)分享:閑魚IM基于Flutter的移動(dòng)端跨端改造實(shí)踐》
融云技術(shù)團(tuán)隊(duì)分享的其它文章:
- 《融云IM技術(shù)分享:萬(wàn)人群聊消息投遞方案的思考和實(shí)踐》
- 《融云技術(shù)分享:全面揭秘億級(jí)IM消息的可靠投遞機(jī)制》
- 《IM消息ID技術(shù)專題(三):解密融云IM產(chǎn)品的聊天消息ID生成策略》
- 《即時(shí)通訊云融云CTO的創(chuàng)業(yè)經(jīng)驗(yàn)分享:技術(shù)創(chuàng)業(yè),你真的準(zhǔn)備好了?》
- 《融云技術(shù)分享:基于WebRTC的實(shí)時(shí)音視頻首幀顯示時(shí)間優(yōu)化實(shí)踐》
3、技術(shù)背景
對(duì)于一款 IM 軟件來(lái)說(shuō),“消息”列表是用戶首先接觸到的界面,“消息”列表滑動(dòng)是否流暢對(duì)用戶的體驗(yàn)有著很大的影響。
隨著功能的不斷增加、數(shù)據(jù)累積,“消息”列表上要展示的信息也越來(lái)越多。
我們發(fā)現(xiàn),產(chǎn)品每使用一段時(shí)間后,比如打完 Call 返回到“消息”列表界面進(jìn)行滑動(dòng)時(shí),會(huì)出現(xiàn)嚴(yán)重的卡頓現(xiàn)象。
于是我們開(kāi)始對(duì)“消息”列表卡頓情況進(jìn)行了詳細(xì)的分析,期待找出問(wèn)題的根源,并使用合適的解決手段來(lái)優(yōu)化。
PS:本文所討論產(chǎn)品的源碼可以從公開(kāi)渠道獲取到,感興趣的讀者可以從本文“附錄1:源碼下載”下載。
4、到底什么是卡頓?
提到APP的卡頓,很多人都會(huì)說(shuō)是因?yàn)樵赨I 16ms 內(nèi)無(wú)法完成渲染導(dǎo)致的。
那么為什么需要在 16ms 內(nèi)完成呢?以及在 16ms 以內(nèi)需要完成什么工作?
帶著這兩個(gè)問(wèn)題,在本節(jié)我們來(lái)深入地學(xué)習(xí)一下。
4.1 刷新率(RefreshRate)與幀率(FrameRate)
刷新率:指的是屏幕每秒刷新的次數(shù),是針對(duì)硬件而言的。目前大部分的手機(jī)刷新率都在 60Hz(屏幕每秒鐘刷新 60 次),有部分高端機(jī)采用的 120Hz(比如 iPad Pro)。
幀率:是每秒繪制的幀數(shù),是針對(duì)軟件而言的。通常只要幀率與刷新率保持一致,我們看到的畫面就是流暢的。所以幀率在 60FPS 時(shí)我們就不會(huì)感覺(jué)到卡。
那么刷新率和幀率之間到底有什么關(guān)系呢?
舉個(gè)直觀的例子你就懂了:
如果幀率為每秒鐘 60 幀,而屏幕刷新率為 30Hz,那么就會(huì)出現(xiàn)屏幕上半部分還停留在上一幀的畫面,屏幕的下半部分渲染出來(lái)的就是下一幀的畫面 —— 這種情況被稱為畫面【撕裂】。相反,如果幀率為每秒鐘 30 幀,屏幕刷新率為 60Hz,那么就會(huì)出現(xiàn)相連兩幀顯示的是同一畫面,這就出現(xiàn)了【卡頓】。
所以單方面的提升幀率或者刷新率是沒(méi)有意義的,需要兩者同時(shí)進(jìn)行提升。
由于目前大部分 Android 機(jī)屏幕都采用的 60Hz 的刷新率,為了使幀率也能達(dá)到 60FPS,那么就要求在 16.67ms 內(nèi)完成一幀的繪制(即:1000ms/60Frame = 16.666ms / Frame)。
4.2 垂直同步技術(shù)
由于顯示器是從最上面一行像素開(kāi)始,向下逐行刷新,所以從最頂端到最底部的刷新是有時(shí)間差的。
常見(jiàn)的有兩個(gè)問(wèn)題:
- 1)如果幀率(FPS)大于刷新率,那么就會(huì)出現(xiàn)前文提到的畫面撕裂;
- 2)如果幀率再大一點(diǎn),那么下一幀的還沒(méi)來(lái)得及顯示,下下一幀的數(shù)據(jù)就覆蓋上來(lái)了,中間這幀就被跳過(guò)了,這種情況被稱為跳幀。
為了解決這種幀率大于刷新率的問(wèn)題,引入了垂直同步的技術(shù),簡(jiǎn)單來(lái)說(shuō)就是顯示器每隔 16ms 發(fā)送一個(gè)垂直同步信號(hào)(VSYNC),系統(tǒng)會(huì)等待垂直同步信號(hào)的到來(lái),才進(jìn)行一幀的渲染和緩沖區(qū)的更新,這樣就把幀率與刷新率鎖定。
4.3 系統(tǒng)是如何生成一幀的
在 Android4.0 以前:處理用戶輸入事件、繪制、柵格化都由 CPU 中應(yīng)用主線程執(zhí)行,很容易造成卡頓。主要原因在于主線程的任務(wù)太重,要處理很多事件,其次 CPU 中只有少量的 ALU 單元(算術(shù)邏輯單元),并不擅長(zhǎng)做圖形計(jì)算。
Android4.0 以后應(yīng)用默認(rèn)開(kāi)啟硬件加速。
開(kāi)啟硬件加速以后:CPU 不擅長(zhǎng)的圖像運(yùn)算就交給了 GPU 來(lái)完成,GPU 中包含了大量的 ALU 單元,就是為實(shí)現(xiàn)大量數(shù)學(xué)運(yùn)算設(shè)計(jì)的(所以挖礦一般用 GPU)。硬件加速開(kāi)啟后還會(huì)將主線程中的渲染工作交給單獨(dú)的渲染線程(RenderThread),這樣當(dāng)主線程將內(nèi)容同步到 RenderThread 后,主線程就可以釋放出來(lái)進(jìn)行其他工作,渲染線程完成接下來(lái)的工作。
那么完整的一幀流程如下:
如上圖所示:
- 1)首先在第一個(gè) 16ms 內(nèi),顯示器顯示了第 0 幀的內(nèi)容,CPU/GPU 處理完第一幀;
- 2)垂直同步信號(hào)到來(lái)后,CPU 馬上進(jìn)行第二幀的處理工作,處理完以后交給 GPU(顯示器則將第一幀的圖像顯示出來(lái))。
整個(gè)流程看似沒(méi)有什么問(wèn)題,但是一旦出現(xiàn)幀率(FPS)小于刷新率的情況,畫面就會(huì)出現(xiàn)卡頓。
圖上的 A 和 B 分別代表兩個(gè)緩沖區(qū)。因?yàn)?CPU/GPU處理時(shí)間超過(guò)了 16ms,導(dǎo)致在第二個(gè) 16ms 內(nèi),顯示器本應(yīng)該顯示 B 緩沖區(qū)中的內(nèi)容,現(xiàn)在卻不得不重復(fù)顯示 A 緩沖區(qū)中的內(nèi)容,也就是掉幀了(卡頓)。
由于 A 緩沖區(qū)被顯示器所占用,B 緩沖區(qū)被 GPU 所占用,導(dǎo)致在垂直同步信號(hào) (VSync) 到來(lái)時(shí) CPU 沒(méi)辦法開(kāi)始處理下一幀的內(nèi)容,所以在第二個(gè) 16ms內(nèi),CPU 并沒(méi)有觸發(fā)繪制工作。
4.4 三緩沖區(qū)(Triple Buffer)
為了解決幀率(FPS)小于屏幕刷新率導(dǎo)致的掉幀問(wèn)題,Android4.1 引入了三級(jí)緩沖區(qū)。
在雙緩沖區(qū)的時(shí)候,由于 Display 和 GPU 各占用了一個(gè)緩沖區(qū),導(dǎo)致在垂直同步信號(hào)到來(lái)時(shí) CPU 沒(méi)有辦法進(jìn)行繪制。那么現(xiàn)在新增一個(gè)緩沖區(qū),CPU 就能在垂直同步信號(hào)到來(lái)時(shí)進(jìn)行繪制工作。
在第二個(gè) 16ms 內(nèi),雖然還是重復(fù)顯示了一幀,但是在 Display 占用了 A 緩沖區(qū),GPU 占用了 B 緩沖區(qū)的情況下,CPU 依然可以使用 C 緩沖區(qū)完成繪制工作,這樣 CPU 也被充分地利用起來(lái)。后續(xù)的顯示也比較順暢,有效地避免了 Jank 進(jìn)一步的加劇。
通過(guò)繪制的流程我們知道,出現(xiàn)卡頓是因?yàn)榈魩耍魩脑蛟谟诖怪蓖叫盘?hào)到來(lái)時(shí),還沒(méi)有準(zhǔn)備好數(shù)據(jù)用于顯示。所以我們要處理卡頓,就要盡量縮短 CPU/GPU 繪制的時(shí)間,這樣就能保證在 16ms 內(nèi)完成一幀的渲染。
5、卡頓問(wèn)題分析
5.1 在中低端手機(jī)中的卡頓效果
有了以上的理論基礎(chǔ),我們開(kāi)始分析“消息”列表卡頓的問(wèn)題。由于 Boss 使用的 Pixel5 屬于高端機(jī),卡頓并不明顯,我們特意從測(cè)試同學(xué)手中借來(lái)了一臺(tái)中低端機(jī)。
這臺(tái)中低端機(jī)的配置如下:
先看一下優(yōu)化之前的效果:
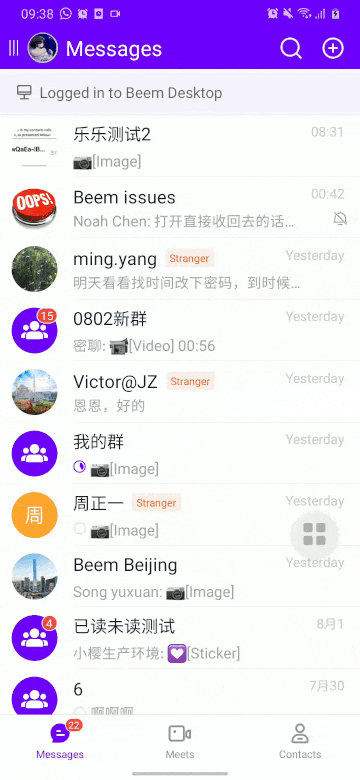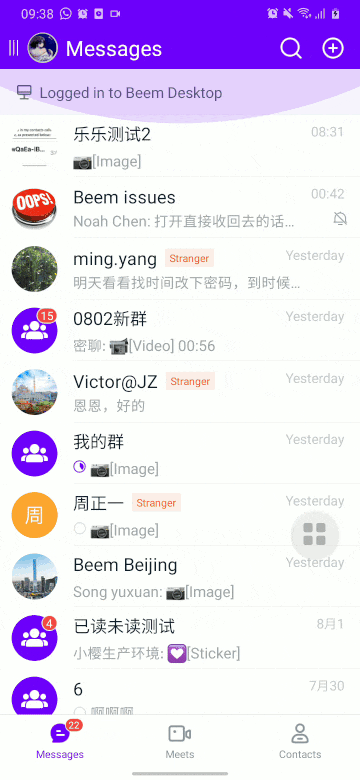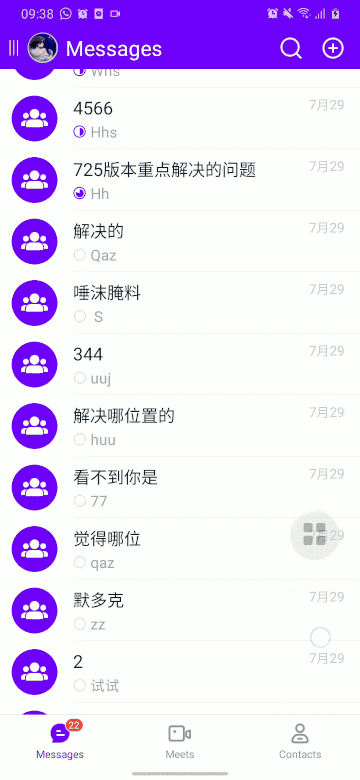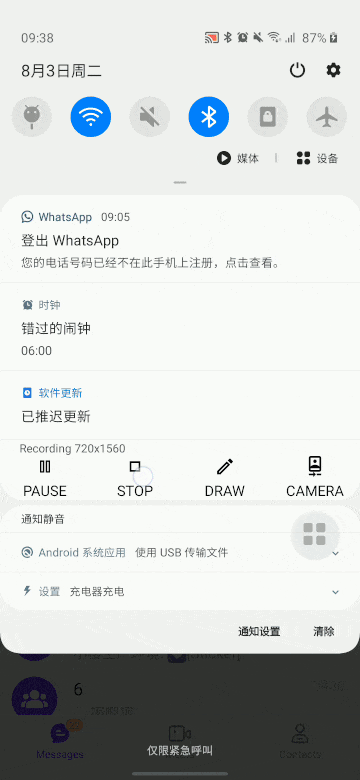
果然是很卡,看看手機(jī)刷新率是多少:

是 60Hz 沒(méi)問(wèn)題。
去高通網(wǎng)站上查詢一下 SDM450 具體的架構(gòu):
可以看該手機(jī)的 CPU 是 8 核 A53 Processor:
A53 Processor 一般在大小核架構(gòu)中當(dāng)作小核來(lái)使用,其主要作用是省電,那些性能要求很低的場(chǎng)景一般由它們負(fù)責(zé),比如待機(jī)狀態(tài)、后臺(tái)執(zhí)行等,而A53 也確實(shí)把功耗做到了極致。
在三星 Galaxy A20s 手機(jī)上,全都采用該 Processor,并且沒(méi)有大核,那么處理速度自然不會(huì)很快,這也就要求我們的 APP 優(yōu)化得更好才行。
在有了對(duì)手機(jī)大致的了解以后,我們使用工具來(lái)查看一下卡頓點(diǎn)。
5.2 分析一下卡頓點(diǎn)
首先打開(kāi)系統(tǒng)自帶的 GPU 呈現(xiàn)模式分析工具,對(duì)“消息”列表進(jìn)行查看。
可以看見(jiàn)直方圖已經(jīng)高出了天際。在圖中最下面有一條綠色的水平線(代表16ms),超過(guò)這條水平線就有可能出現(xiàn)掉幀。

根據(jù) Google 給出的顏色對(duì)應(yīng)表,我們來(lái)看看耗時(shí)的大概位置。
首先我們要明確,雖然該工具叫 GPU 呈現(xiàn)模式分析工具,但是其中顯示的大部分操作發(fā)生在 CPU 中。
其次根據(jù)顏色對(duì)照表大家可能也發(fā)現(xiàn)了,谷歌給出的顏色跟真機(jī)上的顏色對(duì)應(yīng)不上。所以我們只能判斷耗時(shí)的大概位置。
從我們的截圖中可以看見(jiàn),綠色部分占很大比例,其中一部分是 Vsync 延遲,另外一部分是輸入處理+動(dòng)畫+測(cè)量/布局。
Vsync 延遲圖標(biāo)中給出的解釋為兩個(gè)連續(xù)幀之間的操作所花的時(shí)間。
其實(shí)就是 SurfaceFlinger 在下一次分發(fā) Vsync 的時(shí)候,會(huì)往 UI 線程的 MessageQueue 中插入一條 Vsync 到來(lái)的消息,而該消息并不會(huì)馬上執(zhí)行,而是等待前面的消息被執(zhí)行完畢以后,才會(huì)被執(zhí)行。所以 Vsync 延遲指的就是 Vsync 被放入 MessageQueue 到被執(zhí)行之間的時(shí)間。這部分時(shí)間越長(zhǎng)說(shuō)明 UI 線程中進(jìn)行的處理越多,需要將一些任務(wù)分流到其他線程中執(zhí)行。
輸入處理、動(dòng)畫、測(cè)量/布局這部分都是垂直同步信號(hào)到達(dá)并開(kāi)始執(zhí)行 doFrame 方法時(shí)的回調(diào)。
void doFrame(long frameTimeNanos, int frame) {
//...省略無(wú)關(guān)代碼
try{
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame");
AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS);
mFrameInfo.markInputHandlingStart();
//輸入處理
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
mFrameInfo.markAnimationsStart();
//動(dòng)畫
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_INSETS_ANIMATION, frameTimeNanos);
mFrameInfo.markPerformTraversalsStart();
//測(cè)量/布局
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
} finally{
AnimationUtils.unlockAnimationClock();
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
}
這部分如果比較耗時(shí),需要檢查是否在輸入事件回調(diào)中是否執(zhí)行了耗時(shí)操作,或者是否有大量的自定義動(dòng)畫,又或者是否布局層次過(guò)深導(dǎo)致測(cè)量 View 和布局耗費(fèi)太多的時(shí)間。
6、具體優(yōu)化方案及實(shí)踐總結(jié)
6.1 異步執(zhí)行
有了大概的方向以后,我們開(kāi)始對(duì)“消息”列表進(jìn)行優(yōu)化。
在問(wèn)題分析中,我們發(fā)現(xiàn) Vsync 延遲占比很大,所以我們首先想到的是將主線程中的耗時(shí)任務(wù)剝離出來(lái),放到工作線程中執(zhí)行。為了更快地定位主線程方法耗時(shí),可以使用滴滴的 Dokit 或者騰訊的 Matrix 進(jìn)行慢函數(shù)定位。
我們發(fā)現(xiàn)在“消息”列表的 ViewModel 中,使用了 LiveData 訂閱了數(shù)據(jù)庫(kù)中用戶信息表的變更、群信息表的變更、群成員表的變更。只要這三張表有變化,都會(huì)重新遍歷“消息”列表,進(jìn)行數(shù)據(jù)更新,然后通知頁(yè)面刷新。
這部分邏輯在主線程中執(zhí)行,耗時(shí)大概在 80ms 左右,如果“消息”列表多,數(shù)據(jù)庫(kù)表數(shù)據(jù)變更大,這部分的耗時(shí)還會(huì)增加。
mConversationListLiveData.addSource(getAllUsers(), new Observer<List<User>>() {
@Override
public void onChanged(List<User> users) {
if(users != null&& users.size() > 0) {
//遍歷“消息”列表
Iterator<BaseUiConversation> iterable = mUiConversationList.iterator();
while(iterable.hasNext()) {
BaseUiConversation uiConversation = iterable.next();
//更新每個(gè)item上用戶信息
uiConversation.onUserInfoUpdate(users);
}
mConversationListLiveData.postValue(mUiConversationList);
}
}
});
既然這部分比較耗時(shí),我們可以將遍歷更新數(shù)據(jù)的操作放到子線程中執(zhí)行,執(zhí)行完畢以后再調(diào)用 postValue 方法通知頁(yè)面進(jìn)行刷新。
我們還發(fā)現(xiàn)每次進(jìn)入“消息”列表時(shí)都需要從數(shù)據(jù)庫(kù)中獲取“消息”列表數(shù)據(jù),加載更多時(shí)也會(huì)從數(shù)據(jù)庫(kù)中讀取會(huì)話數(shù)據(jù)。
讀取到會(huì)話數(shù)據(jù)以后,我們會(huì)對(duì)獲取到的會(huì)話進(jìn)行過(guò)濾操作,比如不是同一個(gè)組織下的會(huì)話則應(yīng)該過(guò)濾掉。
過(guò)濾完成以后會(huì)進(jìn)行去重:
- 1)如果該會(huì)話已經(jīng)存在,則更新當(dāng)前會(huì)話;
- 2)如果不存在,則創(chuàng)建一個(gè)新的會(huì)話并添加到“消息”列表。
然后還需要對(duì)“消息”列表按一定規(guī)則進(jìn)行排序,最后再通知 UI 進(jìn)行刷新。
這部分的耗時(shí)為 500ms~600ms,并且隨著數(shù)據(jù)量的增大耗時(shí)還會(huì)增加,所以這部分必須放到子線程中執(zhí)行。
但是這里必須注意線程安全問(wèn)題,否則會(huì)出現(xiàn)數(shù)據(jù)多次被添加,“消息”列表上出現(xiàn)多條重復(fù)的數(shù)據(jù)。
6.2 增加緩存
在檢查代碼的時(shí)候,我們發(fā)現(xiàn)有很多地方會(huì)獲取當(dāng)前用戶的信息,而當(dāng)前用戶信息保存在了本地 SP 中(后改為MMKV),并且以 Json 格式存儲(chǔ)。那么在獲取用戶信息的時(shí)候會(huì)從 SP 中先讀取出來(lái)(IO 操作),再反序列化為對(duì)象(反射)。
/**
* 獲取當(dāng)前用戶信息
*/
public UserCacheInfo getUserCache() {
try{
String userJson = sp.getString(Const.USER_INFO, "");
if(TextUtils.isEmpty(userJson)) {
return null;
}
Gson gson = newGson();
UserCacheInfo userCacheInfo = gson.fromJson(userJson, UserCacheInfo.class);
returnuserCacheInfo;
} catch(Exception e) {
e.printStackTrace();
}
return null;
}
每次都這樣獲取當(dāng)前用戶的信息會(huì)非常的耗時(shí)。
為了解決這個(gè)問(wèn)題,我們將第一次獲取的用戶信息進(jìn)行緩存,如果內(nèi)存中存在當(dāng)前用戶的信息則直接返回,并且在每次修改當(dāng)前用戶信息的時(shí)候,更新內(nèi)存中的對(duì)象。
/**
* 獲取當(dāng)前用戶信息
*/
public UserCacheInfo getUserCacheInfo(){
//如果當(dāng)前用戶信息已經(jīng)存在,則直接返回
if(mUserCacheInfo != null){
return mUserCacheInfo;
}
//不存在再?gòu)腟P中讀取
mUserCacheInfo = getUserInfoFromSp();
if(mUserCacheInfo == null) {
mUserCacheInfo = newUserCacheInfo();
}
return mUserCacheInfo;
}
/**
* 保存用戶信息
*/
public void saveUserCache(UserCacheInfo userCacheInfo) {
//更新緩存對(duì)象
mUserCacheInfo = userCacheInfo;
//將用戶信息存入SP
saveUserInfo(userCacheInfo);
}
6.3 減少刷新次數(shù)
在這個(gè)方案里,一方面要減少不合理的刷新,另外一方面要將部分全局刷新改為局部刷新。
在“消息”列表的 ViewModel 中,LiveData 訂閱了數(shù)據(jù)庫(kù)中用戶信息表的變更、群信息表的變更、群成員表的變更。只要這三張表有變化,都會(huì)重新遍歷“消息”列表,進(jìn)行數(shù)據(jù)更新,然后通知頁(yè)面刷新。
邏輯看似沒(méi)問(wèn)題,但是卻把通知頁(yè)面刷新的代碼寫在循環(huán)當(dāng)中,也就是每更新完一條會(huì)話數(shù)據(jù),就通知頁(yè)面刷新一次,如果有 100 條會(huì)話就需要刷新 100 次。
mConversationListLiveData.addSource(getAllUsers(), new Observer<List<User>>() {
@Override
public void onChanged(List<User> users) {
if(users != null&& users.size() > 0) {
//遍歷“消息”列表
Iterator<BaseUiConversation> iterable = mUiConversationList.iterator();
while(iterable.hasNext()) {
BaseUiConversation uiConversation = iterable.next();
//更新每個(gè)item上用戶信息
uiConversation.onUserInfoUpdate(users);
//未優(yōu)化前的代碼,頻繁通知頁(yè)面刷新
//mConversationListLiveData.postValue(mUiConversationList);
}
mConversationListLiveData.postValue(mUiConversationList);
}
}
});
優(yōu)化方法就是:將通知頁(yè)面刷新的代碼提取到循環(huán)外面,等待數(shù)據(jù)更新完畢以后刷新一次即可。
我們 APP 里面有個(gè)草稿功能,每次從會(huì)話里出來(lái),都需要判斷會(huì)話的輸入框中是否存在未刪除文字(草稿),如果有,則保存起來(lái)并在“消息”列表上顯示【Draft】+內(nèi)容,用戶下次再進(jìn)入會(huì)話后將草稿還原。由于草稿的存在,每次從會(huì)話退回到“消息”列表都需要刷新一下頁(yè)面。在未優(yōu)化之前,此處采用的是全局刷新,而我們其實(shí)只需要刷新剛剛退出的會(huì)話對(duì)應(yīng)的 item 即可。
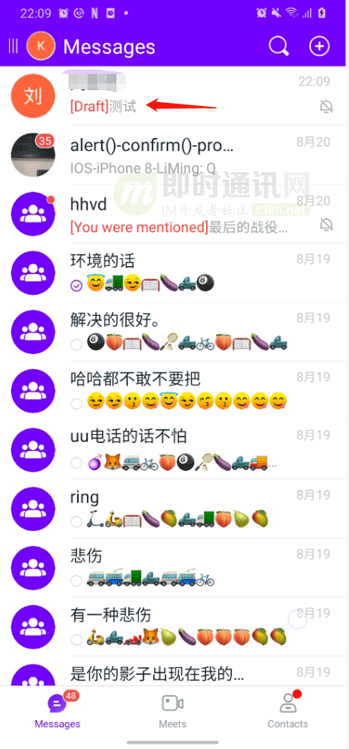
對(duì)于一款 IM 應(yīng)用,提醒用戶消息未讀是一個(gè)常見(jiàn)的功能。在“消息”列表的用戶頭像上面會(huì)顯示當(dāng)前會(huì)話的消息未讀數(shù),當(dāng)我們進(jìn)入會(huì)話以后,該未讀數(shù)需要清零,并且更新“消息”列表。在未優(yōu)化之前,此處采用的也是全局刷新,這部分其實(shí)也可以改為刷新單條 item。
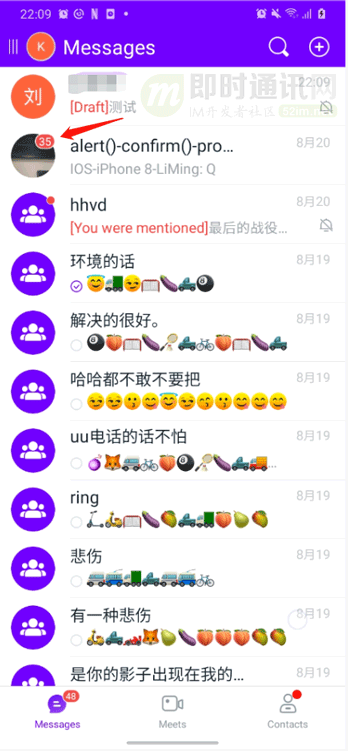
我們的 APP 新增了一個(gè)叫做 typing 的功能,只要有用戶在會(huì)話里面正在輸入文字,在“消息”列表上就會(huì)顯示某某某 is typing...的文案。在未優(yōu)化之前,此處也是采用列表全局刷新,如果在好幾個(gè)會(huì)話中同時(shí)有人 typing,那么基本上整個(gè)“消息”列表就會(huì)一直處于刷新的狀態(tài)。所以此處也改為了局部刷新,只刷新當(dāng)前有人 typing 的會(huì)話 item。
6.4 onCreateViewHolder 優(yōu)化
在分析 Systrace 報(bào)告時(shí),我們發(fā)現(xiàn)了上圖中這種情況:一次滑動(dòng)伴隨著大量的 CreateView 操作。
為什么會(huì)出現(xiàn)這種情況呢?
我們知道 RecyclerView 本身是存在緩存機(jī)制的,滑動(dòng)中如果新展示的 item 布局跟老的一致,就不會(huì)再執(zhí)行 CreateView,而是復(fù)用老的 item,執(zhí)行 bindView 來(lái)設(shè)置數(shù)據(jù),這樣可減少創(chuàng)建 view 時(shí)的 IO 和反射耗時(shí)。
那么這里為什么跟預(yù)期不一樣呢?
我們先來(lái)看看 RecyclerView 的緩存機(jī)制。
RecyclerView 有4級(jí)緩存,我們這里只分析常用的 2級(jí):
- 1)mCachedViews;
- 2)mRecyclerPool。
mCachedViews 的默認(rèn)大小為 2,當(dāng) item 剛剛被移出屏幕可視范圍時(shí),item 就會(huì)被放入 mCachedViews 中,因?yàn)橛脩艉芸赡茉僦匦聦?item 移回到屏幕可視范圍,所以放入 mCachedViews 中的 item 是不需要重新執(zhí)行 createView 和 bindView 操作的。
mCachedViews 中采用 FIFO 原則,如果緩存數(shù)量達(dá)到最大值,那么先進(jìn)入的 item 會(huì)被移出并放入到下一級(jí)緩存中。
mRecyclerPool 是 RecycledViewPool 類型,其中根據(jù) item 類型創(chuàng)建對(duì)應(yīng)的緩存池,每個(gè)緩存池默認(rèn)大小為 5,從 mCachedViews 中移除的 item 會(huì)被清除掉數(shù)據(jù),并根據(jù)對(duì)應(yīng)的 itemType 放入到相應(yīng)的緩存池中。
這里有兩個(gè)值得注意的地方:
- 1)第一個(gè)就是 item 被清除了數(shù)據(jù),這意味著下次使用這個(gè) item 時(shí)需要重新執(zhí)行 bindView 方法來(lái)重設(shè)數(shù)據(jù);
- 2)另外一個(gè)就是根據(jù) itemType 的不同,會(huì)存在多個(gè)緩存池,每個(gè)緩存池的大小默認(rèn)為 5,也就是說(shuō)不同類型的 item 會(huì)放入不同的緩沖池中,每次在顯示新的 item 時(shí)會(huì)先找對(duì)應(yīng)類型的緩存池,看里面是否有可以復(fù)用的 item,如果有則直接復(fù)用后執(zhí)行 bindView,如果沒(méi)有則要重新創(chuàng)建 view,需要執(zhí)行 createView 和 bindView 操作。
Systrace 報(bào)告中出現(xiàn)大量的 CreateView,說(shuō)明在復(fù)用 item 時(shí)出現(xiàn)了問(wèn)題,導(dǎo)致每次顯示新的 item 都需要重新創(chuàng)建。
我們來(lái)考慮一種極端場(chǎng)景,我們“消息”列表中分為 3 種類型的 item:
- 1)群聊 item;
- 2)單聊 item;
- 3)密聊 item。
我們一屏能展示 10 個(gè) item。其中前 10 個(gè) item 都是群聊類型。從 11 個(gè)開(kāi)始到 20 個(gè)都是單聊 item,從 21 個(gè)到 30 個(gè)都是密聊 item。
從圖中我們可以看到群聊 1 和群聊 2 已經(jīng)被移出了屏幕,這時(shí)候會(huì)被放入 mCachedViews 緩存中。而單聊 1 和單聊 2 因?yàn)樵?mRecyclerPool 的單聊緩存池中找不到可以復(fù)用的 item,所以需要執(zhí)行 CreateView 和 BindView 操作。
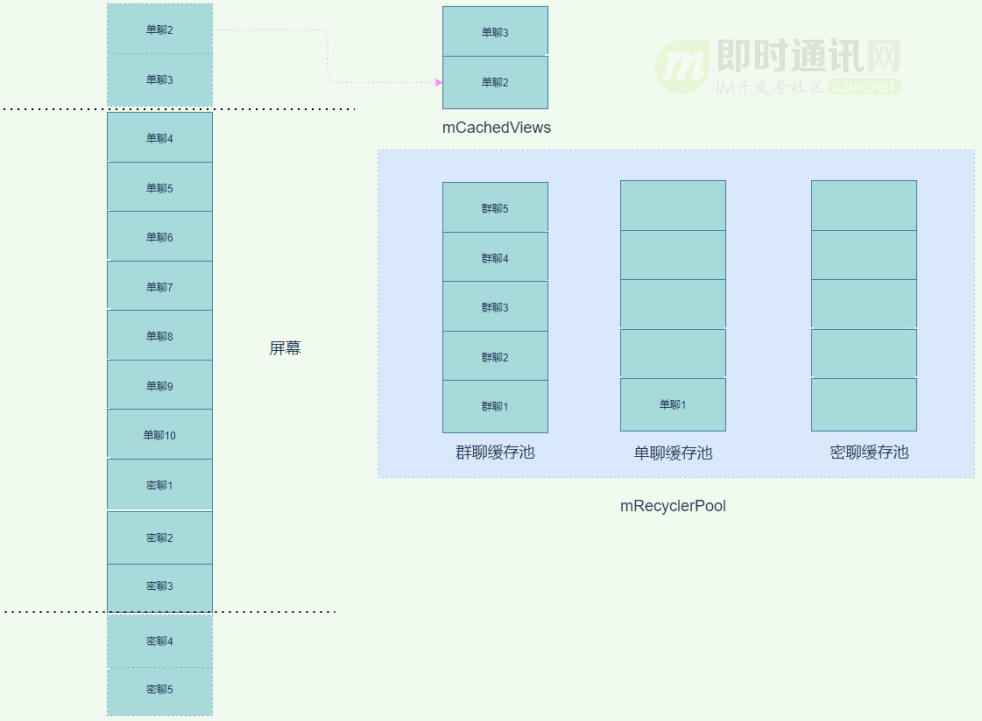
由于之前移出屏幕的都是群聊,所以單聊 item 進(jìn)入時(shí)一直沒(méi)用辦法從單聊緩存池中拿到可以復(fù)用的 item,所以一直需要 CreateView 和 BindView。
直到單聊 1 進(jìn)入到緩存池,也就是上圖所示,如果即將進(jìn)入屏幕的是單聊 item 或者群聊 item,都是可以復(fù)用的,可惜進(jìn)來(lái)的是密聊,由于密聊緩存池中沒(méi)用可以復(fù)用的 item,所以接下來(lái)進(jìn)入屏幕的密聊 item 也都需要執(zhí)行 CreateView 和 BindView。整個(gè) RecyclerView 的緩存機(jī)制在這種情況下,基本失效。
這里額外提一句,為什么群聊緩存池中是群聊 1 ~ 群聊 5,而不是群聊 6 ~ 群聊 10?這里不是畫錯(cuò)了,而是 RecyclerView 判斷,在緩存池滿了的情況下,就不會(huì)再加入新的 item。
/**
* Add a scrap ViewHolder to the pool.
* <p>
* If the pool is already full for that ViewHolder's type, it will be immediately discarded.
*
* @param scrap ViewHolder to be added to the pool.
*/
public void putRecycledView(ViewHolder scrap) {
final int viewType = scrap.getItemViewType();
final ArrayList<ViewHolder> scrapHeap = getScrapDataForType(viewType).mScrapHeap;
//如果緩存池大于等于最大可緩存數(shù),則返回
if(mScrap.get(viewType).mMaxScrap <= scrapHeap.size()) {
return;
}
if(DEBUG && scrapHeap.contains(scrap)) {
throw new IllegalArgumentException("this scrap item already exists");
}
scrap.resetInternal();
scrapHeap.add(scrap);
}
到這里也就可以解釋,為什么我們從 Systrace 報(bào)告中發(fā)現(xiàn)了如此多的 CreateView。知道了問(wèn)題所在,那么我們就需要想辦法解決。多次創(chuàng)建 View 主要是因?yàn)閺?fù)用機(jī)制失效或者沒(méi)有很好的運(yùn)作導(dǎo)致,而失效的原因主要在于我們同時(shí)有 3 種不同的 item 類型,如果我們能將 3 種不同的 item 變?yōu)橐环N,那么我們就能在單聊 4 進(jìn)入屏幕時(shí),從緩存池中拿到可以復(fù)用的 item,從而省去 CreateView 的步驟,直接 BindView 重置數(shù)據(jù)。
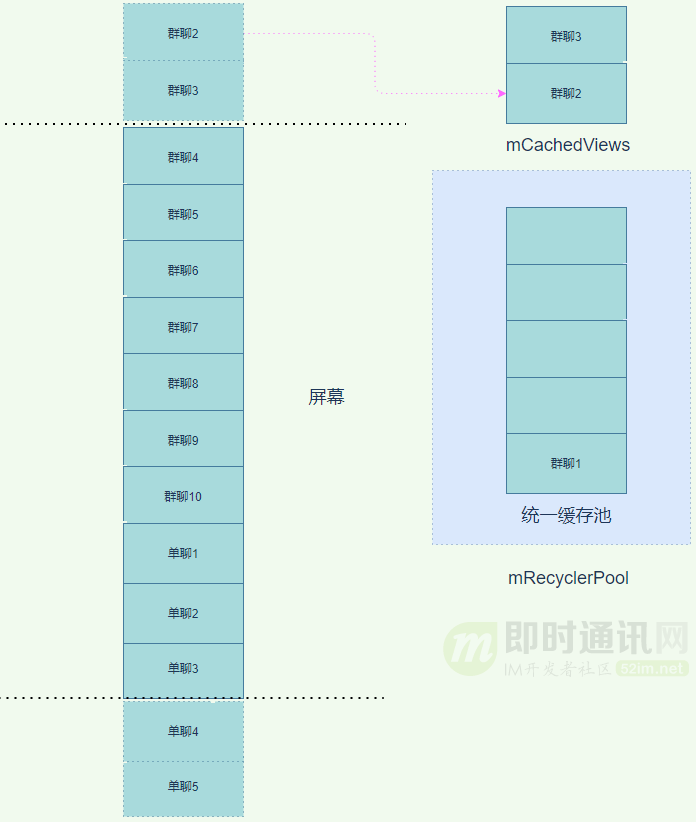
有了思路以后,我們?cè)跈z查代碼時(shí)發(fā)現(xiàn),無(wú)論是群聊、單聊還是密聊,使用的都是同一個(gè)布局,完全可以采用同一個(gè) itemType。以前之所以分開(kāi),是因?yàn)槭褂昧艘恍┰O(shè)計(jì)模式,想讓群聊、單聊、密聊在各自的類中實(shí)現(xiàn),也方便以后如果有新的擴(kuò)展會(huì)更方便清晰。
這時(shí)候就需要在性能和模式上有所取舍,但是仔細(xì)一想,“消息”列表上面不同類型的聊天,布局基本是一致的,不同聊天類型僅僅在 UI 展示上有所不同,這些不同我們可以在 bindView 時(shí)重新設(shè)置。
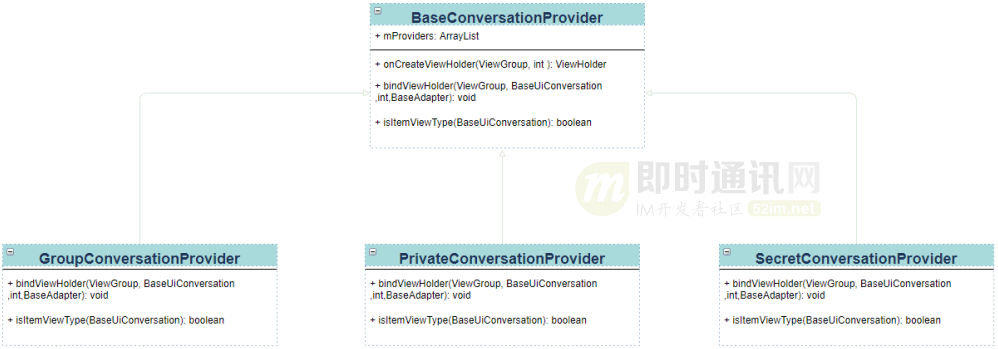
我們?cè)谧?cè)的時(shí)候只注冊(cè) BaseConversationProvider,這樣 itemType 類型就只有這一個(gè)。GroupConversationProvider、PrivateConversationProvider、SecretConversationProvider 都繼承于 BaseConversationProvider 類,onCreateViewHolder 方法只在 BaseConversationProvider 類實(shí)現(xiàn)。
在 BaseConversationProvider 類中包含一個(gè) List,用于保存 GroupConversationProvider、PrivateConversationProvider、SecretConversationProvider 這三個(gè)對(duì)象,在執(zhí)行執(zhí)行 bindViewHolder 方法時(shí),先執(zhí)行父類的方法,在這里面處理一些三種聊天類型公共的邏輯,比如頭像、最后一條消息發(fā)送的時(shí)間等,處理完畢以后通過(guò) isItemViewType 判斷當(dāng)前是哪種聊天,并且調(diào)用相應(yīng)的子類 bindViewHolder 方法,進(jìn)行子類特有的數(shù)據(jù)處理。這里需要注意重用時(shí)導(dǎo)致的頁(yè)面顯示錯(cuò)誤,比如在密聊中修改了會(huì)話標(biāo)題的顏色,但是由于 item 的復(fù)用,導(dǎo)致群聊的會(huì)話標(biāo)題顏色也改變了。
經(jīng)過(guò)改造以后,我們就可以省去大量 的CreateView 操作(IO+反射),讓 RecyclerView 的緩存機(jī)制可以良好的運(yùn)行。
6.5 預(yù)加載+全局緩存
雖然我們減少了 CreateView 的次數(shù),但是我們?cè)谑状芜M(jìn)入時(shí)第一屏還是需要 CreateView,并且我們發(fā)現(xiàn) CreateView 的耗時(shí)也挺長(zhǎng)。
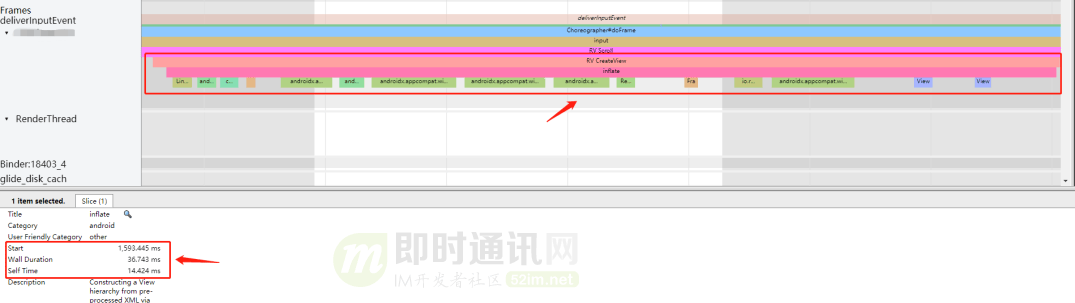
這部分時(shí)間能不能優(yōu)化掉?
我們首先想到的是在 onCreateViewHolder 時(shí)采用異步加載布局的方式,將 IO、反射放在子線程來(lái)做,后來(lái)這個(gè)方案被去掉了(具體原因后文會(huì)說(shuō))。如果不能異步加載,那么我們就考慮將創(chuàng)建 View 的操作提前來(lái)執(zhí)行并且緩存下來(lái)。
我們首先創(chuàng)建了一個(gè) ConversationItemPool 類,該類用于在子線程中預(yù)加載 item,并且將它們緩存起來(lái)。當(dāng)執(zhí)行 onCreateViewHolder 時(shí)直接從該類中獲取緩存的 item,這樣就可以減少 onCreateViewHolder 執(zhí)行耗時(shí)。
/**
* Add a scrap ViewHolder to the pool.
* <p>
* If the pool is already full for that ViewHolder's type, it will be immediately discarded.
*
* @param scrap ViewHolder to be added to the pool.
*/
public void putRecycledView(ViewHolder scrap) {
final int viewType = scrap.getItemViewType();
final ArrayList<ViewHolder> scrapHeap = getScrapDataForType(viewType).mScrapHeap;
//如果緩存池大于等于最大可緩存數(shù),則返回
if(mScrap.get(viewType).mMaxScrap <= scrapHeap.size()) {
return;
}
if(DEBUG && scrapHeap.contains(scrap)) {
throw new IllegalArgumentException("this scrap item already exists");
}
scrap.resetInternal();
scrapHeap.add(scrap);
}
ConversationItemPool 中我們使用了一個(gè)線程安全隊(duì)列來(lái)緩存創(chuàng)建的 item。由于是全局緩存,所以這里要注意內(nèi)存泄漏的問(wèn)題。
那么我們預(yù)加載多少個(gè) item 合適呢?
經(jīng)過(guò)我們對(duì)不同分辨率測(cè)試機(jī)的對(duì)比,首屏展示的 item 數(shù)量一般為 10-12 個(gè),由于在第一次滑動(dòng)時(shí),前 3 個(gè) item 是拿不到緩存的,也需要執(zhí)行 CreateView 方法,那么我們還需要把這 3 個(gè)也算上,所以我們這邊設(shè)置預(yù)加載數(shù)量為 16 個(gè)。之后在 onViewDetachedFromWindow 方法中將 View 進(jìn)行回收再次放入緩存池。
@Override
public ViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
//從緩存池中取item
View view = ConversationListItemPool.getInstance().getItemFromPool();
//如果沒(méi)取到,正常創(chuàng)建Item
if(view == null) {
view = LayoutInflater.from(parent.getContext()).inflate(R.layout.rc_conversationlist_item,parent,false);
}
return ViewHolder.createViewHolder(parent.getContext(), view);
}
注意:在 onCreateViewHolder 方法中要有降級(jí)操作,萬(wàn)一沒(méi)取到緩存 View,需要正常創(chuàng)建一個(gè)使用。這樣我們成功地將 onCreateViewHolder 的耗時(shí)降低到了 2 毫秒甚至更低,在 RecyclerView 緩存生效時(shí),可以做到 0 耗時(shí)。
解決從 XML 創(chuàng)建 View 耗時(shí)的方案,除了在異步線程中預(yù)加載,還可以使用一些開(kāi)源庫(kù)比如 X2C 框架,主要原理就是在編譯期間將 XML 文件轉(zhuǎn)換為 Java 代碼來(lái)創(chuàng)建 View,省去 IO 和反射的時(shí)間。或者使用 jetpack compose 聲明式 UI 來(lái)構(gòu)建布局。
6.6 onBindViewHolder 優(yōu)化
我們?cè)诓榭?Systrace 報(bào)告時(shí)還發(fā)現(xiàn):除了 CreateView 耗時(shí),BindView 竟然也很耗時(shí),而且這個(gè)耗時(shí)甚至超過(guò)了 CreateView。這樣在一次滑動(dòng)過(guò)程中,如果有 10 個(gè) item 新展示出來(lái),那么耗時(shí)將達(dá)到 100 毫秒以上。
這是絕對(duì)不能接受的,于是我們開(kāi)始清理 onBindViewHolder 的耗時(shí)操作。
首先我們必須清楚 onBindViewHolder 方法中只用于 UI 設(shè)置,不應(yīng)該做任何的耗時(shí)操作和業(yè)務(wù)邏輯處理,我們需要把耗時(shí)操作和業(yè)務(wù)處理提前處理好,存入數(shù)據(jù)源中。
我們?cè)跈z查 onBindViewHolder 方法時(shí)發(fā)現(xiàn),如果用戶頭像不存在,會(huì)再生成一個(gè)默認(rèn)的頭像,該頭像會(huì)以用戶名首字母來(lái)生成。在該方法中,首先進(jìn)行了 MD5 加密,然后創(chuàng)建 Bitmap,再壓縮,再存入本地(IO)。這一系列操作非常的耗時(shí),所以我們決定把該操作從 onBindViewHolder 中提取出來(lái),提前將生成數(shù)據(jù)放入數(shù)據(jù)源,用的時(shí)候直接從數(shù)據(jù)源中獲取。
我們的“消息”列表上面,每條會(huì)話都需要顯示最后一條消息的發(fā)送時(shí)間,時(shí)間顯示格式非常復(fù)雜,每次在 onBindViewHolder 中都會(huì)將最后一條消息的毫秒數(shù)格式化成相應(yīng)的 String 來(lái)顯示。這部分也非常耗時(shí),我們把這部分的代碼也提取出來(lái)處理,在 onBindViewHolder 中只需要從數(shù)據(jù)源中取出格式化好的字符串顯示即可。
在我們的頭像上面會(huì)顯示當(dāng)前未讀消息數(shù)量,但是這個(gè)未讀消息數(shù)幾種不同的情況。
比如:
- 1)未讀消息數(shù)是個(gè)位數(shù),則背景圖是圓的;
- 2)未讀消息數(shù)是兩位數(shù),背景圖是橢圓;
- 3)未讀消息數(shù)大于 99,顯示 99+,背景圖會(huì)更長(zhǎng);
- 4)該消息被屏蔽,只顯示一個(gè)小圓點(diǎn),不顯示數(shù)量。
如下圖:
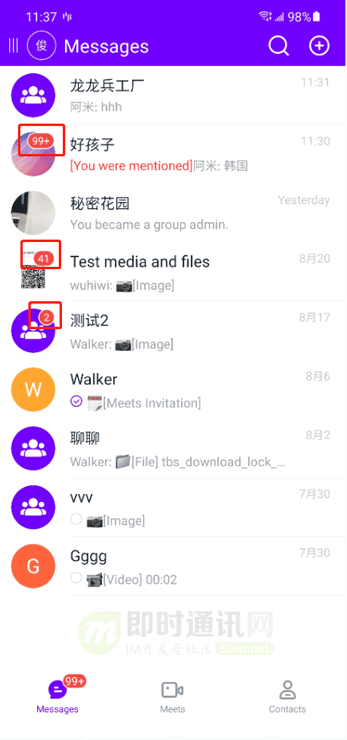
由于存在這幾種情況,此處的代碼直接根據(jù)未讀消息數(shù),設(shè)置了不同的 png 背景圖片。這部分的背景其實(shí)完全可以采用 Shape 來(lái)實(shí)現(xiàn)。
如果使用 png 圖片的話,需要對(duì) png 進(jìn)行解碼,然后再由 GPU 渲染,圖片解碼會(huì)消耗 CPU 資源。而 Shape 信息會(huì)直接傳到底層由 GPU 渲染,速度更快。所以我們將 png 圖片替換為 Shape 實(shí)現(xiàn)。
除了圖片的設(shè)置,在 onBindViewHolder 中用的最多的就是 TextView,TextView 在文本測(cè)量上花費(fèi)的時(shí)間占文本設(shè)置的很大比例,這部分測(cè)量的時(shí)間其實(shí)是可以放在子線程中執(zhí)行的,Android 官方也意識(shí)到了這點(diǎn),所以在 Android P 推出了一個(gè)新的類:PrecomputedText,該類可以讓最耗時(shí)的文本測(cè)量在子線程中執(zhí)行。由于該類是 Android P 才有,所以我們可以使用 AppCompatTextView 來(lái)代替 TextView,在 AppCompatTextView 中做了版本兼容性處理。
AppCompatTextView tv = (AppCompatTextView) view;
// 用這個(gè)方法代替setText
tv.setTextFuture(PrecomputedTextCompat.getTextFuture(text,tv.getTextMetricsParamsCompat(),ThreadManager.getInstance().getTextExecutor()));
使用起來(lái)很簡(jiǎn)單,原理這里就不贅述了,可以自行谷歌。在低版本中還使用了 StaticLayout 來(lái)進(jìn)行渲染,可以加快速度,具體可以看Instagram分享的一篇文章《Improving Comment Rendering on Android》。
4.7 布局優(yōu)化
除了減少 BindView 的耗時(shí)以外,布局的層級(jí)也影響著 onMeasure 和 onLayout 的耗時(shí)。我們?cè)谑褂?GPU 呈現(xiàn)模式分析工具時(shí)發(fā)現(xiàn)測(cè)量和布局花費(fèi)了大量的時(shí)間,所以我們打算減少 item 的布局層級(jí)。
在未優(yōu)化之前,我們 item 布局的最大層級(jí)為 5。其實(shí)有些只是為了控制顯隱方便而多增加了一層布局來(lái)包裹,我們最后使用約束布局,將最大層級(jí)降低到了 2 層。
除此之外我們還檢查了是否存在重復(fù)設(shè)置背景顏色的情況,因?yàn)橹貜?fù)設(shè)置背景顏色會(huì)導(dǎo)致過(guò)度繪制。所謂過(guò)度繪制指的是某個(gè)像素在同一幀內(nèi)被繪制了多次。如果不可見(jiàn)的 UI 也在做繪制操作,這會(huì)導(dǎo)致某些區(qū)域的像素被繪制了多次,浪費(fèi)大量的 CPU、GPU 資源。
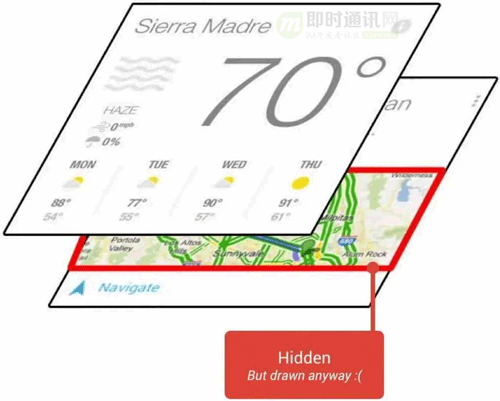
除了去掉重復(fù)的背景,我們還可以盡量減少使用透明度,Android 系統(tǒng)在繪制透明度時(shí)會(huì)將同一個(gè)區(qū)域繪制兩次,第一次是原有的內(nèi)容,第二次是新加的透明度效果。基本上 Android 中的透明度動(dòng)畫都會(huì)造成過(guò)度繪制,所以可以盡量減少使用透明度動(dòng)畫,在 View 上面也盡量不要使用 alpha 屬性。具體原理可以參考谷歌官方視頻。
在使用約束布局來(lái)減少層級(jí),并且去掉重復(fù)背景以后,我們發(fā)現(xiàn)還是會(huì)有點(diǎn)卡。在網(wǎng)上查閱相關(guān)資料,發(fā)現(xiàn)也有網(wǎng)友反饋在 RecyclerView 的 item 中使用約束布局會(huì)有卡頓的問(wèn)題,應(yīng)該是約束布局的 Bug 導(dǎo)致,我們也檢查了一下我們使用的約束布局版本號(hào)。
// App dependencies
appCompatVersion = '1.1.0'
constraintLayoutVersion = '2.0.0-beta3'
用的是 beta 版本,我們改為最新穩(wěn)定版 2.1.0。發(fā)現(xiàn)情況好了很多。所以商業(yè)應(yīng)用盡量不要使用測(cè)試版本。
6.8 其他優(yōu)化
除了上面所說(shuō)的優(yōu)化點(diǎn),還有一些小的優(yōu)化點(diǎn),比如以下這幾點(diǎn)。
1)比如使用高版本的 RecyclerView,會(huì)默認(rèn)開(kāi)啟預(yù)取功能:
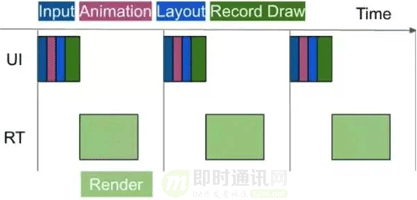
從上圖中我們可以看見(jiàn),UI 線程完成數(shù)據(jù)處理交給 Render 線程以后就一直處于空閑狀態(tài),需要等待個(gè) Vsync 信號(hào)的到來(lái)才會(huì)進(jìn)行數(shù)據(jù)處理,而這空閑時(shí)間就被白白浪費(fèi)了,開(kāi)啟預(yù)取以后就能合理地使用這段空閑時(shí)間。

2)將 RecyclerView 的 setHasFixedSize 方法設(shè)置為 true。當(dāng)我們的 item 寬高固定時(shí),使用 Adapter 的 onItemRangeChanged()、onItemRangeInserted()、onItemRangeRemoved()、onItemRangeMoved() 這幾個(gè)方法更新 UI,不會(huì)重新計(jì)算大小。
3)如果不使用 RecyclerView 的動(dòng)畫,可以通過(guò) ((SimpleItemAnimator) rv.getItemAnimator()).setSupportsChangeAnimations(false) 把默認(rèn)動(dòng)畫關(guān)閉來(lái)提升效率。
7、棄用的優(yōu)化方案
在做“消息”列表卡頓優(yōu)化過(guò)程中,我們采用了一些優(yōu)化方案,但是最終沒(méi)有采用,這里也列出加以說(shuō)明。
7.1 異步加載布局
在前文中有提到,我們?cè)跍p少 CreateView 耗時(shí)的過(guò)程中,最初打算采用異步加載布局的方式來(lái)將 IO、反射放在子線程中執(zhí)行。
我們使用的是谷歌官方的 AsyncLayoutInflater 來(lái)異步加載布局,該類會(huì)將布局加載完成以后回調(diào)通知我們。但是它一般用于 onCreate 方法中。而在 onCreateViewHolder 方法中需要返回 ViewHolder,所以沒(méi)有辦法直接使用。
為了解決這個(gè)問(wèn)題,我們自定義了一個(gè) AsyncFrameLayout 類,該類繼承于 FrameLayout,我們會(huì)在 onCreateViewHolder 方法中將 AsyncFrameLayout 作為 ViewHolder 的根布局添加進(jìn)去,并且調(diào)用自定義的 inflate 方法,進(jìn)行異步加載布局,加載成功以后再把加載成功的布局添加到 AsyncFrameLayout 中,作為 AsyncFrameLayout 的子 View。
public void inflate(int layoutId, OnInflateCompleted listener) {
new AsyncLayoutInflater(getContext()).inflate(layoutId, this, newAsyncLayoutInflater.OnInflateFinishedListener() {
@Override
public void onInflateFinished(@NotNull View view, int resid, @Nullable @org.jetbrains.annotations.Nullable ViewGroup parent) {
//標(biāo)記已經(jīng)inflate完成
isInflated = true;
//加載完布局以后,添加為AsyncFrameLayout中
parent.addView(view);
if(listener != null) {
//加載完數(shù)據(jù)后,需要重新請(qǐng)求BindView綁定數(shù)據(jù)
listener.onCompleted(mBindRequest);
}
mBindRequest = null;
}
});
}
這里注意:因?yàn)槭钱惒綀?zhí)行,所以在 onCreateViewHolder 執(zhí)行完成以后,會(huì)執(zhí)行 onBinderViewHolder 方法,而這時(shí)候布局是很有可能沒(méi)有加載完成的,所以需要用一個(gè)標(biāo)志為 isInflated 來(lái)標(biāo)識(shí)布局是否加載成功,如果沒(méi)有加載完成,就先不綁定數(shù)據(jù)。同時(shí)要記錄本次 BindView 請(qǐng)求,當(dāng)布局加載完成以后,主動(dòng)地調(diào)用一次去刷新數(shù)據(jù)。
沒(méi)有采用此方法的主要原因在于會(huì)增加布局層級(jí),在使用預(yù)加載以后,可以不使用此方案。
7.2 DiffUtil
DiffUtil 是谷歌官方提供的一個(gè)數(shù)據(jù)對(duì)比工具,它可以對(duì)比兩組新老數(shù)據(jù),找出其中的差異,然后通知 RecyclerView 進(jìn)行刷新。
DiffUtil 使用 Eugene W. Myers 的差分算法來(lái)計(jì)算將一個(gè)列表轉(zhuǎn)換為另一個(gè)列表的最少更新次數(shù)。但是對(duì)比數(shù)據(jù)時(shí)也會(huì)耗時(shí),所以也可以采用 AsyncListDiffer 類,把對(duì)比操作放在異步線程中執(zhí)行。
在使用 DiffUtil 中我們發(fā)現(xiàn),要對(duì)比的數(shù)據(jù)項(xiàng)太多了,為了解決這個(gè)問(wèn)題,我們對(duì)數(shù)據(jù)源進(jìn)行了封裝,在數(shù)據(jù)源里添加了一個(gè)表示是否更新的字段,把所有變量改為 private 類型,并且提供 set 方法,在 set 方法中統(tǒng)一將是否更新的字段設(shè)置為 true。這樣在進(jìn)行兩組數(shù)據(jù)對(duì)比時(shí),我們只需要判斷該字段是否為 true,就知道是否存在更新。
想法是美好的,但是在實(shí)際封裝數(shù)據(jù)源時(shí)發(fā)現(xiàn),類中還有類(也就是類中有對(duì)象,不是基本數(shù)據(jù)類型),外部完全可以通過(guò)先 get 到一個(gè)對(duì)象,然后通過(guò)改對(duì)象的引用修改其中的字段,這樣就跳過(guò)了 set 方法。如果要解決這個(gè)問(wèn)題,那么我們需要在封裝類中提供類中類屬性的所有 set 方法,并且不提供類中類的 get 方法,改動(dòng)非常的大。
如果僅僅是這個(gè)問(wèn)題,還可以解決,但是我們發(fā)現(xiàn)“消息”列表上面有一個(gè)功能,就是每當(dāng)其中一個(gè)會(huì)話收到了新消息,那么該會(huì)話會(huì)移動(dòng)到“消息”列表的第一位。由于位置發(fā)生了改變,整個(gè)列表都需要刷新一次,這就違背了使用 DiffUtil 進(jìn)行局部刷新的初衷了。比如“消息”列表第五個(gè)會(huì)話收到了新消息,這時(shí)第五個(gè)會(huì)話需要移動(dòng)到第一個(gè)會(huì)話,如果不刷新整個(gè)列表,就會(huì)出現(xiàn)重復(fù)會(huì)話的問(wèn)題。
由于這個(gè)問(wèn)題的存在,我們棄用了 DiffUtil,因?yàn)榫退憬鉀Q了重復(fù)會(huì)話的問(wèn)題,收益依然不會(huì)很大。
7.3 滑動(dòng)停止時(shí)刷新
為了避免“消息”列表大量刷新操作,我們將“消息”列表滑動(dòng)時(shí)的數(shù)據(jù)更新給記錄了下來(lái),等待滑動(dòng)停止以后再進(jìn)行刷新。
但是在實(shí)際測(cè)試過(guò)程中,停止后的刷新會(huì)導(dǎo)致界面卡頓一次,中低端機(jī)上比較明顯,所以放棄了此策略。
7.4 提前分頁(yè)加載
由于“消息”列表數(shù)量可能很多,所以我們采用分頁(yè)的方式來(lái)加載數(shù)據(jù)。
為了保證用戶感知不到加載等待的時(shí)間,我們打算在用戶將要滑動(dòng)到列表結(jié)束位置之前獲取更多的數(shù)據(jù),讓用戶無(wú)痕地下滑。
想法是理想的,但是實(shí)踐過(guò)程中也發(fā)現(xiàn)在中低端機(jī)上會(huì)有一瞬間的卡頓,所以該方法也暫時(shí)先棄用。
除了以上方案被棄用了,我們?cè)趦?yōu)化過(guò)程中發(fā)現(xiàn),其它品牌相似產(chǎn)品的“消息”列表滑動(dòng)其實(shí)速度并沒(méi)特別快,如果滑動(dòng)速度慢的話,那么在一次滑動(dòng)過(guò)程中需要展示的 item 數(shù)量就會(huì)小,這樣一次滑動(dòng)就不需要渲染過(guò)多的數(shù)據(jù)。這其實(shí)也是一個(gè)優(yōu)化點(diǎn),后面我們可能會(huì)考慮降低滑動(dòng)速度的實(shí)踐。
8、本文小結(jié)
在開(kāi)發(fā)過(guò)程中,隨著業(yè)務(wù)的不斷新增,我們的方法和邏輯復(fù)雜度也會(huì)不斷增加,這時(shí)候一定要注意方法耗時(shí),耗時(shí)嚴(yán)重的盡量提取到子線程中執(zhí)行。
使用 Recyclerview 時(shí)千萬(wàn)不要無(wú)腦刷新,能局部刷的絕不全局刷,能延遲刷的絕不馬上刷。
在分析卡頓的時(shí)候可以結(jié)合工具進(jìn)行,這樣效率會(huì)提高很多,通過(guò) Systrace 發(fā)現(xiàn)大概的問(wèn)題和排查方向以后,可以通過(guò) Android Studio 自帶的 Profiler 來(lái)進(jìn)行具體代碼的定位。
附錄:更多IM干貨文章
《新手入門一篇就夠:從零開(kāi)發(fā)移動(dòng)端IM》
《從客戶端的角度來(lái)談?wù)勔苿?dòng)端IM的消息可靠性和送達(dá)機(jī)制》
《移動(dòng)端IM中大規(guī)模群消息的推送如何保證效率、實(shí)時(shí)性?》
《移動(dòng)端IM開(kāi)發(fā)需要面對(duì)的技術(shù)問(wèn)題》
《IM消息送達(dá)保證機(jī)制實(shí)現(xiàn)(一):保證在線實(shí)時(shí)消息的可靠投遞》
《IM消息送達(dá)保證機(jī)制實(shí)現(xiàn)(二):保證離線消息的可靠投遞》
《如何保證IM實(shí)時(shí)消息的“時(shí)序性”與“一致性”?》
《一個(gè)低成本確保IM消息時(shí)序的方法探討》
《IM單聊和群聊中的在線狀態(tài)同步應(yīng)該用“推”還是“拉”?》
《IM群聊消息如此復(fù)雜,如何保證不丟不重?》
《談?wù)勔苿?dòng)端 IM 開(kāi)發(fā)中登錄請(qǐng)求的優(yōu)化》
《移動(dòng)端IM登錄時(shí)拉取數(shù)據(jù)如何作到省流量?》
《淺談移動(dòng)端IM的多點(diǎn)登錄和消息漫游原理》
《完全自已開(kāi)發(fā)的IM該如何設(shè)計(jì)“失敗重試”機(jī)制?》
《通俗易懂:基于集群的移動(dòng)端IM接入層負(fù)載均衡方案分享》
《微信對(duì)網(wǎng)絡(luò)影響的技術(shù)試驗(yàn)及分析(論文全文)》
《微信技術(shù)分享:微信的海量IM聊天消息序列號(hào)生成實(shí)踐(算法原理篇)》
《自已開(kāi)發(fā)IM有那么難嗎?手把手教你自擼一個(gè)Andriod版簡(jiǎn)易IM (有源碼)》
《融云技術(shù)分享:解密融云IM產(chǎn)品的聊天消息ID生成策略》
《適合新手:從零開(kāi)發(fā)一個(gè)IM服務(wù)端(基于Netty,有完整源碼)》
《拿起鍵盤就是干:跟我一起徒手開(kāi)發(fā)一套分布式IM系統(tǒng)》
《適合新手:手把手教你用Go快速搭建高性能、可擴(kuò)展的IM系統(tǒng)(有源碼)》
《IM里“附近的人”功能實(shí)現(xiàn)原理是什么?如何高效率地實(shí)現(xiàn)它?》
《IM消息ID技術(shù)專題(一):微信的海量IM聊天消息序列號(hào)生成實(shí)踐(算法原理篇)》
《IM開(kāi)發(fā)寶典:史上最全,微信各種功能參數(shù)和邏輯規(guī)則資料匯總》
《IM開(kāi)發(fā)干貨分享:我是如何解決大量離線消息導(dǎo)致客戶端卡頓的》
《零基礎(chǔ)IM開(kāi)發(fā)入門(一):什么是IM系統(tǒng)?》
《零基礎(chǔ)IM開(kāi)發(fā)入門(二):什么是IM系統(tǒng)的實(shí)時(shí)性?》
《零基礎(chǔ)IM開(kāi)發(fā)入門(三):什么是IM系統(tǒng)的可靠性?》
《零基礎(chǔ)IM開(kāi)發(fā)入門(四):什么是IM系統(tǒng)的消息時(shí)序一致性?》
《一套億級(jí)用戶的IM架構(gòu)技術(shù)干貨(下篇):可靠性、有序性、弱網(wǎng)優(yōu)化等》
《IM掃碼登錄技術(shù)專題(三):通俗易懂,IM掃碼登錄功能詳細(xì)原理一篇就夠》
《理解IM消息“可靠性”和“一致性”問(wèn)題,以及解決方案探討》
《阿里技術(shù)分享:閑魚IM基于Flutter的移動(dòng)端跨端改造實(shí)踐》
《融云技術(shù)分享:全面揭秘億級(jí)IM消息的可靠投遞機(jī)制》
《IM開(kāi)發(fā)干貨分享:如何優(yōu)雅的實(shí)現(xiàn)大量離線消息的可靠投遞》
《IM開(kāi)發(fā)干貨分享:有贊移動(dòng)端IM的組件化SDK架構(gòu)設(shè)計(jì)實(shí)踐》
《IM開(kāi)發(fā)干貨分享:網(wǎng)易云信IM客戶端的聊天消息全文檢索技術(shù)實(shí)踐》
>> 更多同類文章 ……
本文已同步發(fā)布于“即時(shí)通訊技術(shù)圈”公眾號(hào)。
同步發(fā)布鏈接是:http://www.52im.net/thread-3732-1-1.html