以前使用官方Subversion搭建SVN版本控制環境,感覺很繁瑣,需要手動該文件,很麻煩,今天在網上看到了VisualSVN搭建版本控制環境的方法,寫出來和大家分享一下。歡迎提出問題O(∩_∩)O~
1、下載安裝文件(服務器端和客戶端)
服務器端采用VisualSVN,一個可用的下載地址是:http://idc218b.newhua.com/down/VisualSVN-Server-2.1.2.zip,如果鏈接失效,從百度谷歌搜索就可以了,很多下載地址。
客戶端采用大家熟悉的Tortoisesvn,沒錯,就是那個小烏龜,官方下載地址是:http://tortoisesvn.net/
服務器端用來存放提交的文件,客戶端用來連接服務器端,提交和下載服務器端的文件,(這個不用我多說了吧,下一話題^_^)
2、安裝服務器端,解壓縮下載的文件VisualSVN-Server-2.1.2.zip,雙擊VisualSVN-Server-2.1.2.msi進行安裝
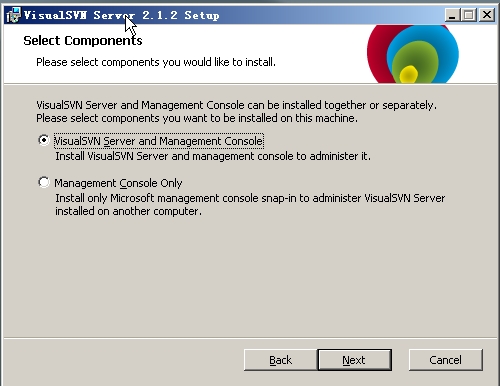
安裝過程中有一個界面是選擇安裝的組件,選擇第一個“VisualSVN Server and Management Console”就可以了。如圖
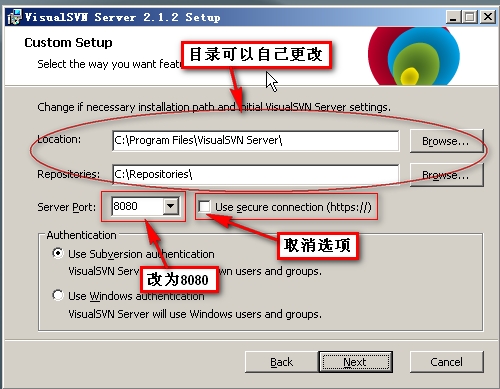
下一個界面的設置如圖:
可以更改目錄,也可以更改端口,注意,端口不要和已經使用的端口沖突,去掉“use secure connnection https://”的選項
這里的C:/Repositories是服務器文檔目錄,也就是我們提交到SVN里的文檔的存放目錄,這個目錄大家可以更改
點擊下一步,默認安裝完成即可。
3、安裝客戶端軟件TortoiseSVN-1.5.3.13783-win32-svn-1.5.2.msi,雙擊默認安裝就可以了,安裝完成可能要重啟,重啟即可。
4、配置服務器端
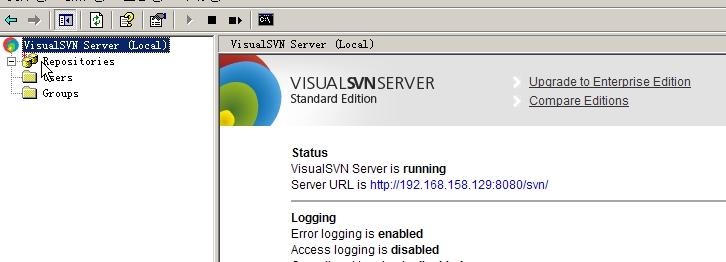
點擊開始-->程序->VisualSVN-->VisuaSVN Server Manager啟動服務器管理器,右鍵選擇VisualSVN Server(Local),選擇Properties,在彈出窗口中選擇NetWork標簽,在ServerName處輸入本機的IP地址,我的地址為 192.168.158.129,端口我選擇8080.,確定保存,再點擊VisualSVN Server可以看到右面的界面,我們的訪問地址就是Sever URL http://192.168.158.129:8080/svn/
現在我們新建兩個目錄,右鍵選擇Repositories,選擇Create new Repository,輸入名字document,保存
新建用戶,右鍵選擇 Users,選擇Create User,輸入用戶密碼test,test,這個口令將在客戶端連接SVN服務器時使用
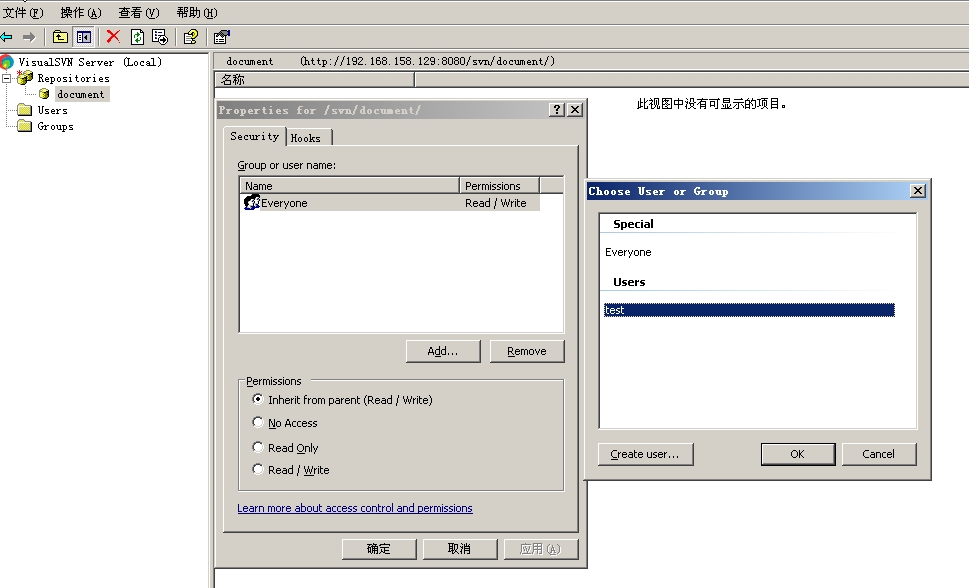
為剛才創建的document Repository添加用戶,右鍵選擇document,選擇Properties,點擊Add按鈕,選擇剛才添加的用戶,保存,如圖
這樣,服務器端就配置好了,回到客戶端
因為已經安裝了客戶端軟件Tortoisesvn,在D盤下,新建文件夾testsvn,打開文件夾,右鍵選擇check out(檢出),
在彈出窗口的版本庫URL處輸入,http://192.168.158.129:8080/svn/document
如圖

確定,保存。注意上面的檢出至目錄是D:/testsvn,
在testsvn中新建一個文本文檔,新建文本文檔.txt,在testsvn空白處,點擊右鍵,選擇提交,(commit),則文件會被傳到文檔服務器,其他人就可以下載了。
subversion程序,和mysql很類似,是c/s結構的,有客戶端和服務器端。服務器端和客戶端都是通過命令行方式啟動和執行的。本文只會使用到客戶端的命令。
第三方提供了各種圖形界面的客戶端工具,比如eclipse插件subclipse,windows圖形界面工具tortoiseSVN。這些后面會提到它們的基本使用。
subversion資源
安裝subversion
有關subversion和subclise的安裝暫略,因為目前提供的虛擬機開發環境已經安裝和配置。
tortoiseSVN,可到官方網站上下載最新版本的windows安裝包,默認安裝,不需要做其他設置,安裝后需要重啟計算機。能在資源管理器中鼠標右鍵菜單看到如下圖所示條目,就說明安裝成功。

使用subversion
日常工作中使用subversion僅僅是幾個命令或者操作,并不復雜。但是它內部的一些機制需要逐漸去理解。
檢出代碼
在剛開始進入一個開發隊伍的時候,已經有版本控制和軟件項目,使用的第一個命令往往是檢出(checkout)代碼。或者當使用和研究開源軟件的時候,也是第一個要用到這個命令。這個命令的作用是把項目的源代碼下載到用戶本地,并且帶有版本控制信息。
比如,執行以下命令獲取一個項目的源代碼:
svn co http://easymorse.googlecode.com/svn/trunk/vfs.demo/
這個命令將在本地當前目錄建vfs.demo目錄并將該服務器目錄下的所有文件下載到本地,并且,會生成隱藏文件.SVN目錄,用于記錄版本控制信息。
tortoiseSVN有圖形界面的檢出操作,但是命令行方便快捷,建議使用命令行。
如果使用eclipse并安裝了subclipse插件,可以通過插件導入項目。

然后,

選擇或者新建資源庫位置,

選擇資源庫中的項目目錄。

然后,就可以完成(finish)了。

初始導入
何時使用初始導入,比如,對于java開發人員來說,在eclipse中編寫了一個項目,并決定把項目共享到版本控制器上,這時就需要初始導入操作了。
以下以subclipse為例說明初始導入的步驟。
第一步,選擇share project,共享你的項目:

選擇通過svn共享項目:

填寫svn提交的url:

這個url,需要subversion的管理員告知你,還有用戶名和密碼。如果想練習一下,google提供了免費的svn,你可以通過:http://code.google.com 申請項目,這樣就會有類似我上面的url和權限。
然后可以直接點擊finish,完成初始提交。選擇next,可以做定制模塊名和初始提交的信息,一般不需要。
如果你的svn服務器使用了https協議,需要接受一個數字證書,一般選擇永久接受。

之后,會要求輸入用戶名和密碼。建議勾選保存密碼,否則會很麻煩。

這樣,再看項目,會發現條目上多了問號,這時需要選擇哪些目錄和文件需要提交,哪些需要忽略,比如生成的class文件等。

選擇需要忽略的文件或者目錄,這時需要切換到導航視圖下才能看到所有文件和目錄:

從導航視圖看到的情況:

選中需要忽略的目錄和文件,操作svn:

然后提交整個項目即可。有關提交的操作見下文。
更新項目
項目在提交前,應該先做更新項目操作。比如有一個文件a.txt,已經提交到svn中,這樣,可能有其他用戶提交了新的改動到a.txt,你現在又 修改了a.txt,準備提交你的改動。先操作更新a.txt,這樣如果該文件在svn服務器已經改動,會將改動加入到當前本地的a.txt中。
在subclipse中的操作:

提交代碼
提交代碼,一般會級聯當前目錄下所有改動的內容。

刪除代碼
對于不再使用的代碼,可以直接刪除掉,比如通過windows刪除文件,通過ubuntu的rm命令或者通過eclipse的delete功能,然后提交項目,subclipse會知道哪個文件被刪除了,并將這個變化通知給svn服務器。
還原代碼
如果代碼做了改動,可以是多個文件,也可以刪除了文件或者新增了文件,但是沒有提交到svn服務器,可以通過還原功能恢復到改動前的樣子。

版本的分支與合并
版本的分支和合并,是版本控制的核心功能。
比如,軟件通過版本的分支,將項目分配給多人做分工開發,通過版本合并,將這些分工實現的代碼合并到新的版本中;或者,修改代碼bug的時候,可以 先打出一個版本分支,保留出現bug的版本,比如分支版本名稱為pre_fix_bug_2201,這里2201表示bug的代號,然后針對這個分支做修 改fix這個bug,再將修改后的內容提交到一個新的分支版本,比如post_fix_bug_2201,再到適當時候將這個分支合并到代碼主干中去。
以上說了一下版本分支與合并的用途,這里簡單說一下svn版本分支合并的基本原理。
首先是版本分支,實際上是將當前版本“copy”到分支上,非常類似windows下,將某個目錄的快捷方式復制到其他路徑。這種copy,可以說 是輕量級copy或者叫廉價copy,不是復制版本內容,而是做一個內部的引用。這樣的copy很快,對服務器也沒有空間上的開銷。
版本的合并,是svn開發中的難點,當做版本合并的時候,服務器會試圖智能的合并同一個文件的不同版本,可能會帶來版本沖突,這需要操作者做手工的處理,消除版本沖突。合理分工的項目應該可以通過管理手段盡量避免這種情況。
以下是通過subclipse演示版本分支的操作。首先,項目文檔應該已經全部提交,然后,選擇

然后,填寫url,一般是在tags/目錄下:

然后默認選項,next即可,然后選擇finish按鈕。在svn的相應路徑下就會有一個同名的項目。

打分支,實際上就是建立了一個項目的輕量級copy。
如何從版本的一個分支切換到另外一個分支,這也是很重要的,它能幫助你輕松在不同的項目版本中自動切換,而不必在eclipse里維持多個項目。

選擇要切換的項目版本路徑,或者直接輸入亦可。

然后點擊ok后,項目即可切換到該版本下。
在分支上做了改動,并且已經提交(一般tags目錄下的項目約定是只讀的,不建議改動,這里是為了舉例方便),那么,可以將這個版本合并到trunk(主干)代碼中,讓主干也擁有最新的代碼。

選擇需要合并的源,比如從tags上面一個版本,合并到主干(trunk)代碼中。

之后,需要設置一些合并的特性,這里默認配置即可。

執行完畢后,會有一個合并報告,可見沒有出現沖突情況。

這時候看源代碼,可以發現有改動,這些改動就是合并過來的代碼。

改動如果沒有問題,就可以提交,這樣就完成了一次版本的合并工作。
“還原”已經提交的改動
如果文檔沒有提交,還原是很容易的,只需執行還原(revert)就可以了。有時候,已經提交了代碼,結果發現了問題,需要回退到之前提交的版本,就不是很容易了。
這時候的還原,其實是將以前的某個修訂本(revision)覆蓋當前的本地工作拷貝。然后再提交這些改動,成為新的修訂本。
下面演示一下。
首先提交了一個版本的改動,這是以后需要還原回來,這里,為了以后還原方便,要在提交的消息中說明改動了什么。(這一步在開發中是必須的,是紀律)

下面,再修改一下項目,然后提交一次,這里故意增加一個文件。

提交以后,后悔了,想恢復到前一個修訂版。雖然可以通過版本號進行覆蓋還原,但是一般人是無法記憶這個版本號的,另外就是實際情況往往更復雜,不會像示例中那樣是相鄰的兩個修訂版。
所以提交修訂版時的注解消息就顯得特別重要。
這時可以通過svn的日志功能查看到這些版本和它們的注釋消息。

看到歷次版本的消息內容。

這樣,根據注釋,我們很容易找到需要還原到以前的那個修訂版。如果不放心,我們還可以根據上下文菜單,對比兩個修訂版的區別。

看比較結果。可以看出,增加了一個文件,另外一個文件中有一處差異。

那么,可以確定是從125修訂版恢復(還原)。

更改后的項目,相當于用125修訂版還原了126修訂版。

可以看到126版本添加的文件不見了,另外VfsDemo.java文件也還原到125版本的內容。這時提交將成為127版本,這個版本其實就是125版本。算是還原了主干(trunk)上的代碼。

刷新歷史,可以看到修訂版已經生效。

參考:
http://blog.ofriend.cn/post/95.html
Windows下安裝SVN(Subversion)獨立服務器步驟:
安裝之前需要準備的軟件:
1、Setup-Subversion-1.7.0.msi
2、TortoiseSVN-1.7.0.22068-win32-svn-1.7.0.msi
3、LanguagePack_1.7.0.22068-win32-zh_CN.msi
下載地址:
1、http://sourceforge.net/projects/win32svn/files/
2、http://sourceforge.net/projects/tortoisesvn/files/
安裝步驟及簡要配置:
1、安裝Setup-Subversion-1.7.0.msi
2、安裝TortoiseSVN-1.7.0.22068-win32-svn-1.7.0.msi
3、安裝LanguagePack_1.7.0.22068-win32-zh_CN.msi
4、添加subversion環境變量:c:\program files\subversion\bin
5、創建版本庫:
a、svnadmin create c:\svn\repository
b、創建空目錄repository->右鍵->TortoiseSVN->Create Repository here...
6、配置用戶和認證:
Svnserve.conf:核心配置文件:
# password-db = passwd >password-db = passwd
# authz-db = authz >authz-db = authz
Authz:配置用戶權限的文件
Passwd:新加用戶名和密碼的文件
啟動subversion:
在dos命令下,輸入:> svnserve exe -d -r d:\svn_repo(這行自己加的)
7、運行Subversion:c:\svn\repository>svnserve --daemon
或者:c:\svn\repository>svnserve --daemon --root c:\svn
注:運行的時候不能關閉命令行窗口,關閉服務就退出了!因此可以添加到系統服務項隨機啟動即可!
8、添加系統服務,隨系統啟動:
sc create svnservice binpath= "c:\program files\subversion\bin\svnserve.exe --service --root c:\svn" displayname= "Subversion" depend= tcpip start= auto
9、刪除服務:
sc delete svnservice
注:在Windows XP SP3下測試通過!其他平臺暫未測試!
http://www.vogella.com/articles/OSGi/article.html#OSGi_firstbundle
http://www.vogella.com/articles/OSGi/article.html#exportbundle
http://wiki.eclipse.org/Gemini/Web
值得說明一點:
網頁的目錄不會放在webapps(tomcat)目錄下的,是根據MANIFEST.MF 的
Web-ContextPath: /osgi-web-app的屬性來訪問的,如http://domain:port/osgi-web-app
Install file: plugins/myplugins.jar
Osgi> start xx
讓你的plugin自安裝
在C:\adempiere\configuration\org.eclipse.equinox.simpleconfigurator 目錄下的bundles.info
最后一行增加
osgi.web.app,0.0.1,plugins/osgi.web.app.war,4,false(名字,版本號,路徑,啟動優先級)
有些情況下,bundle沒有能自啟動,狀態不是active,要在
要在config.ini設置bundle @start,就可以了
==
另如果自己寫了一個plugin,想通過buckminster來自動打包,要在cspec文件中增加,仿wstore樣式。
http://www.globalqss.com/wiki/index.php/IDempiere
http://kenai.com/projects/hengsin/pages/Building
下載Eclipse 3.6以上版本
Eclipse IDE for Java EE Developers 3.6+
我這這里下的是3.7
安裝Mecurial插件
(1.)打開Mercurial Eclipse Plugin 1.6+
(2.)復制紅色方框中的地址

(3.)在Eclipse的Help->Install New Software

(4.)如果你不懂怎么安裝插件,請看這里
http://download.eclipse.org/tools/buckminster/updates-3.7
安裝Mercurial 2.1.1客戶端
Mercurial Client
http://mercurial.selenic.com/downloads/
因我的操作系統是XP的,所以下載X86, 如果是win7 就要下載X64的。
安裝完成后,下載原代碼:
cd D:\idempiere\
hg clone https://bitbucket.org/idempiere/idempiere
1. 從 adempiere的根目錄 下面搜索一下 Test.sql
2. 在 adempiere的根目錄 下面新建 utils\oracle\ 文件夾。
3. 將搜索到的Test.sql放到 utils\oracle\ 文件夾下就可以。
啟動server/client 參考:
http://www.adempiere.com/OSGI_HengSin
exec sp_addlinkedserver 'PA_EHR','','SQLOLEDB','10.110.8.41'
exec sp_addlinkedsrvlogin 'PA_EHR','false',null,'sa','123456'
exec sp_dropserver 'PA_EHR' 如果刪除不了,去企業管理器中刪除。
select * from PA_EHR.tongxehr.dbo.AdvQueryProject
摘要: Hibernate Tools 簡介: Hibernate Tools是由JBoss推出的一個Eclipse綜合開發工具插件,該插件可以簡化ORM框架Hibernate,以及JBoss Seam,EJB3等的開發工作。Hibernate Tools可以以Ant Task以及Eclipse插件的形式運行。 Mapping Editor(映射文件編輯器):...
閱讀全文
1、DB的存儲層次(在其他文章中已經介紹過了,這里只是簡述)
1)blocks:是data file I/O的最小單位,也是空間分配的最小單位。一個Oracle block是由一個或多個連續的OS blocks組成。
2)extents:是由多個連續的data blocks組成的擁有存儲空間分配的邏輯單位。一個或多個extents組成了一個segment。當在一個segment中的所有空間都被用完時,Oracle server會給segment分配新的extent。
3)segments:一個segment是一個extents的集合,存放了tablespace中具體的邏輯存儲結構的所有數據。例如,每個 table,Oracle server會分配一個或多個extents用于組成該table的data segments。對于indexes,Oracle server分配一個或多個extents用于組成index segment。
2、extents的分配:為了盡可能降低動態分配extent的弊端,應該如下:
* 使用本地管理表空間的方法。
* 適當的評估segments的大小:確定object的最大size;創建object時,選擇恰當的存儲參數用于分配足夠的空間給相應的data。
* 監控segments的動態extend的情況。
select owner, table_name, blocks, empty_blocks from dba_tables where empty_blocks/(blocks+empty_blocks)<.1;
alter table hr.employees allocate extent;
①創建本地管理extents的tablespace,其實自9i以來,系統默認的表空間都是本地管理的表空間。
create tablespace tsp_name datafile ‘/path/datafile.dbf’ size nM
extent management local uniform size mM;
本地管理表空間在其datafile內部創建一個位圖用于記錄每個block的使用狀態。當extent被分配或釋放重用,bitmap的相應值會被修 改,用于顯示其中blocks的新狀態。這些修改不會產生rollback information,因為沒有修改data dictionary。
②大extents的優點:DBA應該分配適當的size給segments和extents,一般原則是大extents優于小extents,主要表現在:
* large extents在一定程度上降低了segments動態的分配extents的可能性
* large extents可以稍微的提高I/O的性能,因為Oracle server從磁盤讀取一個連續的large extent的多個blocks應該比從幾個small extents不連續的blocks的速度快。為了避免分離的multiblock的讀取,可以考慮將extents設置為 5*DB_FILE_MULTIBLOCK_READ_COUNT。但是對于不經常進行全表掃描的table,這種設置不會有太大的性能改觀。
* 對于非常large的tables,OS在文件大小上的限制可能使DBA不得不將object分配到multiple extents。
* 使用index查找的性能不會受到index是否在一個或多個extents中的影響。
* Extent maps存放了某個segment中所有extents的信息。如果MAXEXTENTS設置為UNLIMITED,這些maps可以存放在多個 blocks中,從性能角度講,應該盡可能在一次I/O中讀取該extent map。此外多個extents也會降低dictionary的性能,因為每個extent都會占用dictionary cache的少量空間。
附注:①在ASSM表空間中,每個segment的 segment header都有一個extent map,記錄著segment所屬的所有extents的第一個塊的位置和區的大小,如果segment header中容納不下所有的extents信息,oracle會另外添加專門的extents map塊,保存segment中extents的位置大小信息。全表掃描時oracle會根據extents map中所記錄的信息,掃描高水標記之下的所有extents的所有blocks.每個extents map block都有一個指向下一個extents map block的地址,segment header中的extents map信息也有指向第一個extents map block的地址.也就是說所有的extents map block構成了一個鏈表.全表掃描時就依據這個鏈表中所記錄的block的位置信息進行掃描.extents map的主要作用是用于全表掃描.
②FLM段(Free List Managed Segment),其段頭存放著段中Extent的信息,包括Extent的起始地址,Extent的長度。如果由于segment擴展過 多,segment header不能容下所有EXTENT的信息,則會用新的稱之為EXTENT MAP BLOCK的塊來專門存放EXTENT的信息。段頭與各Extent Map Block之間用鏈表形式連接起來。它與ASSM中的extent map鏈表作用不同。
③large extents的缺點:因為需要更多連續的blocks,Oracle server可能很難找到足夠的連接的空間用于對其的分配。
3、高水位線(High-Water Mark)
在空間分配中,有兩類空閑blocks:曾經被占用過,但相應的數據被刪除了,這些blocks將被記錄到相應的free list中,當有insert操作時進程reuse,在high-water mark以下;另一類是自分配給相應的segment后,從來沒有被使用過的,所以在high-water mark之上。
①high-water mark:被記錄在segment header block中;在segment被創建時設置:當插入rows時,每次增加five-block;truncate tables會重置high-water mark,但delete不會。
②在table level,可以將high-water 瑪瑞咖之上的空間收回:
alter table t_name deallocate unused …
全表掃描中,Oracle server會讀取high-water mark以下的所有blocks,high-water mark以上的空閑blocks不會影響性能。
③在cluster中,空間是為所有的cluster keys分配的,無論其是否含有data。分配的空間依靠cluster在創建時參數size指定的大小和cluster的類型:
* 在hash cluster中,因為hash keys的數量在cluster被創建是已經被確定了,所以每個hash key所占用的空間都在high-water mark之下。
* 在index cluster中,空間被分配給每個cluster index。
4、table statistics
可以使用analyze語句或是dbms_stats對table的當前狀況進行統計并保存在數據字典中,隨后通過查看dba_tables獲得相關信息。
eg:
analyze table t_name compute statistics;
select num_rows, blocks, empty_blocks as empty, avg_space, chain_cnt, avg_row_len from dba_tables where table_name=’T_NAME’;
其中dba_tables中不同的字段具體含義如下:
Num_Rows – Number of rows in the table
Blocks – Number of blocks below the high-water mark of the table
Empty_blocks – Number of blocks above the high-water mark of the table
Avg_space – Average free space in bytes in the blocks below the highwater mark
Avg_row_len – Average row length, including row overhead
Chain_cnt – Number of chained, or migrated, rows in the table
Avg_space_freelist_blocks – The average freespace of all blocks on a freelist
Num_freelist_blocks – The number of blocks on the freelist
5、DBMS_SPACE包:可用于獲得segments中的space的狀態信息,常用的有以下兩個procedures:
* UNUSED_SPACE:用于獲得分配給object未使用的space。
* FREE_BLOCKS:用于獲得object的空閑的space。在運行時,必須提供相應的FREELIST_GROUP_ID,一般使用1,除非你使用的是Oracle Parallel server。
該DBMS_SPACE包是由dbmsutil.sql創建的。
6、恢復表空間:
1)對于在high-water mark以下的空間:
方法一:export the table;drop or truncate the table;import the table
在選擇是drop還是truncate的時候,要考慮:drop將table在data dictionary中的所有information刪除,并且space被收回;而truncate沒有,并保留了相應已經分配的space等待 reused;如果使用的是data dictionary管理tablespace,則影響空間收回與分配的時間開銷的主要因素是extents的數量(而不是size);如果使用的是 drop方法,則考慮在import時使用compress選項,因為整個空間的分配可能不是在一個連續的大空間上。
方法二:alter table t_name move;此方法執行之后,所有相關的indexes都為unusable狀態,必須rebuild。
2)對于在high-water mark之上的unused block可使用:alter table t_name deallocate unused語句進行收回。
7、DB的block size設置
1)減少訪問block的數量,這是DB tuning的一個目標。DBA對此調節的方法主要有:增大block size;盡可能緊湊的將rows放在block中,避免row的遷移現象。
2)database block size是在DB創建時由參數DB_BLOCK_SIZE指定的,是I/O讀取datafile的最小單元。當前有些OS允許block size達到64KB,可以查看相應的OS,從而調整DB的block size。block size一旦設置就不能改變,除非對DB重建或是duplicate,在9i中已經進行了相應的改進,可以使用多中block sizes,但是對于base data size仍不可變。DB的block size應該是OS的整數倍。如果application中有大量的全表掃描,可以考慮增大block size,但不要超過OS的I/O size。
3)小block size的優劣:
* 優:降低了block 的沖突;有利于small rows;有利于隨機訪問,因為可以在一定程度上提高buffer cache的利用率,特別是在內存資源不足的情況下。
* 劣:small blocks管理所用的空間開銷大;每個block存放的row較少,也會加大I/O的開銷;可能造成更多的index blocks被讀入。
在OLTP環境中,經常存在large object的隨機訪問時,small blocks相對更好。
4)large block size的優劣:
* 優:所用的管理空間開銷小,更多的空間可用于存放具體的data;有利于順序的讀取;有利于large rows;改善了index讀取的性能,因為大的block可以降低index的level數量,從而減少I/O的次數。
* 劣:在OLTP環境中不利于index blocks,可能會引起index leaf blocks的爭用沖突;如果存在大量隨機訪問可能會造成buffer cache的浪費。
在DSS環境中,連續讀取大量數據操作較多,使用large block更好。
8、PCTREE和PCTUSED(具體內容在其他文章中介紹過了,這里不累述了)
只有兩類DML語句可以影響free blocks和used blocks的數量:delete和update。
釋放的空間在一個block中很可能不是連續的,Oracle server只在下面情況同時出現時進行free space的合并:insert或update操作試圖向一個有足夠空間的block中插入數據;free space存在碎片,以至于row piece無法被寫入。
具體設置:
①PCTFREE:默認情況下是10;如果不存在update操作,可以使用0;PCTFREE = 100 * UPD / (Average row length)
②PCTUSED:默認是40;PCTUSED = 100 – PCTFREE – 100 * Rows * ( average row length) / block size
其中:
UPD = update操作平均增加的bytes數量。
average row length和rows都可以在analyze之后從dba_tables表中獲得。
當對一個已經存在的表進行這兩個參數的修改,不會有馬上的影響,只是在后續的DML操作中才發生作用。
9、migration和chaining(具體原因也在其他的文章中介紹過了)
①migration和chaining對性能的影響:一方面,引起這兩種現象的insert和update本身性能比較差;另一方面,在查詢此類記錄的操作會因為額外的I/O造成性能較差。
migration現象過的,主要是由于PCTFREE參數設置過低引起的,對此可以考慮增大該值。
②對兩者的檢測,主要是通過analyze相應的表,隨后從dba_tables表中觀察其chain_cnt字段。此外可以從v$sysstat視圖或 是statspack report中的“instance activity stats for DB”獲得“table fetch continued row”的值。
還可以收集每個表中發生了migration和chaining的具體的rows:首先執行utlchain.sql腳本創建chained_rows統計表,隨后執行語句:
analyze table t_name list chained rows;
③消除migration rows:
* export/import
* alter table t_name move
* 執行遷移腳本,具體見Oracle 9i Performance Tuning SG的P398
• Find migrated rows using ANALYZE.
• Copy migrated rows to new table.
• Delete migrated rows from original table.
• Copy rows from new table to original table.
此方法執行時,必須注意與original table相關的外鍵約束,應將其disable。
10、索引的重組
在經常發生DML的table上,indexes往往是帶來性能問題的原因。
在data blocks中,Oracle server會將delete row釋放的空間重新分配給insert rows,但是對于index blocks,Oracle server的應用時連續的。即使一個index block中只有一個index,也要維護該block。如果刪除了block中的所有index,該block才會被送入free list。因此,必要時需要進行index的rebuild。
①對index space的監控:
* analyze index i_name validate structure;
* select name, (del_lf_rows_len / lf_rows_len) * 100 as wastage from index_stats;
在index_stats視圖中,各字段含義如下:
• Lf_rows – Number of values currently in the index
• Lf_rows_len – Sum of all the length of values, in bytes
• Del_lf_rows – Number of values deleted from the index
• Del_lf_rows_len – Length of all deleted values
note:index_stats視圖只保存最近一次analyze的結果,并且當前session只能看到當前session的分析結果。
* alter index emp_name_ix rebuild;
* alter index emp_name_ix coalesce;
如果如果已刪除的index 記錄超過20%,則應該選用rebuild。
rebuild會以原有的index作為基礎,重建索引,可以重新指定STORAGE, TABLESPACE, INITRANS參數,同時可以用下面的參數加快重建的效率:
* PARALLEL/NOPARALLEL(NOPARALLEL是默認值)
* RECOVERABLE/UNRECOVERABLE ( RECOVERABLE是默認的):當使用unrecoverable時速度將更快,因為它不產生redo log,只在index創建是起作用,而不是設置參數,不記錄到dictionary中。它使用隱含式的logging參數,意味著在index創建結束 后插入index項時,仍然會記錄redo log。
* LOGGING/NOLOGGING:如果設置為NOLOGGING,該參數表明在index運行使用期間,將不產生任何redo log。它將記錄到dictionary中。可以用alter index 進行修改。
注意:unrecoverable和logging是不兼容的。
alter index rebuild要快于index的drop后re-create,因為它使用了full scan的方法。
②監控index的使用情況
* EXECUTE DBMS_STATS.GATHER_INDEX_STATS(‘SECHMA_NAME’, ‘T_NAME’);
* create index … compute statistics;
* alter index .. rebuild compute statistics;
③此外,還可以用下面的方法查看沒有使用的index:
從9i開始,對index的使用情況可以被收集到視圖v$object_usage中。輔助DBA刪除未使用的index,提高性能:
* 打開監控:alter index i_name monitoring usage;
* 停止監控:alter index i_name nomonioring usage;
隨后查看v$object_usage:select index_name, used from v$object_usage;
在v$object_usage中各個字段的意義:
• index_name – The index name
• table_name – The corresponding table
• monitoring – Indicates whether monitoring is “ON or OFF”
• used – Indicates (YES or NO) the index has been used during the monitoring time
• start_monitoring – Time at which monitoring began on index
• stop_monitoring – Time at which monitoring stopped on index