服務集成平臺5.6的性能測試進入尾聲,這期的優化也算告一段落。這次主要的優化工作還是在三個方面:應用服務器(Apache,JBoss)配置,業務流程,Cache Client包(http://code.google.com/p/memcache-client-forjava/ )。這里把過去和這次優化對于Cache的使用作一個經驗分享,希望大家能夠用好Cache,提速你的應用。
這里還是通過一些點滴的啟示來介紹優化的一些心得,很多時候還是要根據具體情況來判斷如何去具體實施,因此這里所說的僅僅是在一些場景下適用,并非放之四海皆準的教條。同時也希望看此文的各位同學,如果有更好的思路可以給我反饋,技術在交流中才會有發展。
積少成多,集腋成裘
性能提不上去,多半是在一些容易成為瓶頸的“暗點”(IO,帶寬,連接數,資源競爭等等)。Memcached Cache現在已經被大家廣泛使用,但是千萬不要認為對Cache的操作是低損耗的,要知道這類集中式Cache對Socket連接數(會牽涉到linux操作系統文件句柄可用數),帶寬,網絡IO都是有要求的,有要求就意味著會有損失,因此積少成多,集腋成裘。服務集成平臺是一個高速的服務路由器,其大部分的業務數據,訪問控制策略,安全策略以及對應的一些控制閥值被緩存在Cache服務端,因此對于Cache的依賴性很強。每一次對于客戶端的性能提升,總會給服務集成平臺性能帶來不小的影響,但是每一次優化速度后,客戶端可以優化的空間越來越小,這時候需要一些策略來配合,提升應用整體性能。當前主要采用了以下幾點策略:
1. 從數據獲取角度來做優化,采用本地數據緩存。(因為大家的應用需要能夠線形擴展,支持集群,所以才不使用應用服務器本地緩存,但是在某些緩存數據時間性不敏感或者修改幾率較小的情況下,可以采用本地緩存結合集中式緩存,減少對遠端服務器訪問次數,提升應用性能)。
Cache Client的IMemcachedCache 接口中的public Object get(String key,int localTTL)方法就是本地數據緩存結合遠程Cache獲取數據的接口。具體流程參看下圖:

2. 從數據更新角度,采用異步數據更新。(即不等待數據更新結果,直接進行其他業務流程)。這類操作使用場景比較局限,首先數據不會用作判斷(特別是高并發系統中的閥值),其次不需要返回結果作為后續流程處理輸入(例如計數器),時時性要求比較低。(這類操作其實是采用了集群數據傳播的一種策略,原先對于集群中所有節點都想即時傳播到,但是這樣對于性能損失很大,因此采用key對應的主Node采用即時設置數據,其他的通過后臺任務數據傳播來實現,由于key對應的主Node是數據第一操作和讀取節點,因此這類數據傳播操作時時性要求較低,適合這樣處理)。具體接口參見Cache Client 使用文檔。
3. 一次獲取,多次使用。這點和系統設計有關,當前服務集成平臺的安全流程是鏈狀的,一次請求會經歷很多安全攔截器,而在每一個安全攔截器中會根據情況獲取具體的業務數據或者流程控制策略等緩存數據,每一個安全攔截器都是彼此獨立的,在很早以前是每一個安全攔截器各自在需要數據的時候去遠程獲取,但是壓力測試下來發現請求次數相當多,而且好些重復獲取,因此將這些業務數據作為上下文在鏈式檢查中傳遞,按需獲取和設置,最大程度上復用了數據。(其實也是一種減少數據獲取的方式)。
4. 規劃好你的Cache區。有些同學在使用Cache的時候問我是否有什么需要注意的,我覺得在使用Cache之前,針對需要緩存的數據需要做好規劃。那些數據需要放在一個Cache虛擬節點上,那些數據必須分開放。一方面是根據自己業務系統的數據耦合程度(未來系統是否需要合并或者拆分),另一方面根據數據量及讀寫頻繁度來合理分配(畢竟網絡IO還是稀缺資源)。當然有時候業務系統設計者自己也不知道未來的發展,那么最簡單的方式給Key加上前綴,當前可以合并,未來也可以拆分。同時數據粒度也需要考慮,粒度設計太小,那么交互頻繁度就會很高,如果粒度太大,那么網絡流量就會很大,同時將來業務模塊拆分就會有問題。
巧用Memcached Cache特有接口
Memcached Cache提供了計數器一整套接口和add,replace兩個接口。這些特有接口可以很好的滿足一些應用的高并發性處理需求。例如對于資源訪問次數控制,采用Cache的計數器接口就可以實現在集群中的數量控制,原本通過Cache的get和put是無法解決并發問題的(就算是本地緩存一樣),這就是一組原子操作的接口。而Add和Replace可以滿足無需通過get方法獲取內容,就可以對于key是否存在的不同情況作出相應處理,也是一種原子性操作。這些原子操作接口對于高并發系統在集群中的設計會很有幫助。
Cache Client Cluster
Memcached Cache是集中式Cache,它僅僅是支持將數據能夠分片分區的存儲到一臺或者多臺的Cache Server實例中,但是這些數據并沒有作冗余,因此任何一個服務實例不可用,都會導致部分緩存數據丟失。當然很多人采取持久化等方式來保證數據的完整性,但是這種方式對于效率以及恢復的復雜性都會有影響。
簡單的來想,為什么不把數據在多保存一份或者多份呢,當其中一份不可用的情況下,就用另外一份補上。這就是最原始的Cache Client Cluster的構想。在這里具體的設計細節就不多說了,主要說一下幾個要點,也讓使用Cache Client Cluster的同學有大致的一個了解。
先來看看Cache Cluster的結構圖:
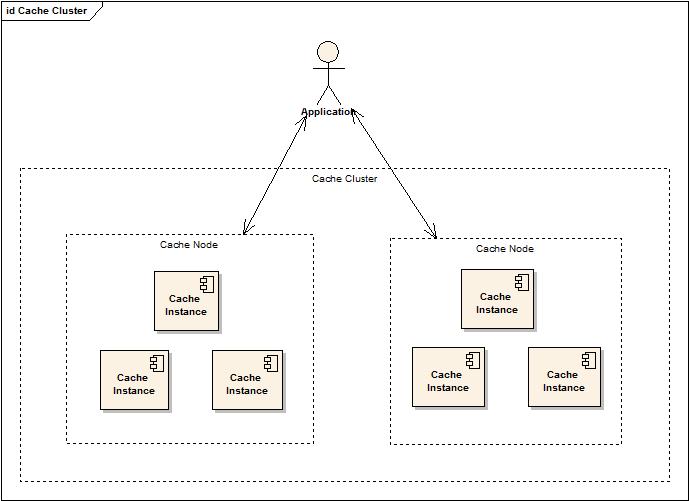
這張圖上需要注意四個角色:Application(使用Cache的應用),Cache Cluster(Cache配置的虛擬集群),Cache Node(Cache的虛擬節點,在同一個Cluster中的Cache Node數據保持完全一致),Cache Instance(Cache虛擬節點中實際包含的Memcached Cache服務端實例)。
應用僅僅操作Cache Node,不了解具體數據存儲或數據獲取是操作哪一個Cache 服務端實例。(這點也就是Memcached Cache可擴展性的基礎設計)。Cache Cluster又將多個Cache Node組成了虛擬的集群,通過數據冗余,保證了服務可用性和數據完整性。
當前 Cache Client Cluster主要有兩種配置模式:active 和 standby。(這里是借鑒了硬件的名詞,其實并不完全一樣,因為還是考慮到了效率問題)
Cache Client Cluster主要的功能點:
1. 容錯。當被分配到讀取或者操作數據的Cache虛擬節點不可用的情況下,集群其他節點支持代替錯誤節點服務于客戶端應用。
2. 數據冗余。當操作集群中某一個Cache虛擬節點時,數據會異步傳播到其他集群節點。
3. 軟負載。客戶端通過對操作的key作算法(當前采用簡單的key hash再取余的方式)選擇集群中的節點,達到集群中節點簡單的負載分擔。同時也由于這種模式,可以使得key都有默認的第一操作節點,此節點的操作保持時時更新,而其他節點可以通過客戶端異步更新來實現效率提升。
4. 數據恢復。當集群中某一節點失效后恢復時,其數據可能已經完全丟失,此時通過配置成為Active模式可以將其他節點上冗余的數據Lazy復制到該節點(獲取一個復制一個,同時只支持一個冗余節點的數據獲取(不采取遍歷,防止低效))。
Active模式擁有1,2,3,4的特性。Standby模式擁用1,2,3特性。(其實本來只考慮讓Standby擁有1特性)。未來不排除還會有更多需要的特性加入。Active在key不存在的情況下會有些低效,因為會判斷一個冗余節點是否存在內容,然后決定是否修復當前節點。(考慮采用短期失敗標示之類的,不過效率不一定高,同時增加了復雜度)
運行期動態擴容部署
Memcached cache客戶端算法中比較出名的是Consistent Hashing算法,其目的也就是為了在節點增加或者減少以后,通過算法盡量減小數據重新分布的代價。采用虛擬節點,環狀和二叉樹等方式可以部分降低節點增加和減少對于數據分布的影響,但是始終還是有部分數據會失效,這點還是由于Memcached Cache是集中式Cache所決定的。
但如果有了Cache Cluster的話,數據有了冗余,就可以通過逐步修改集群中虛擬節點配置,達到對于單個虛擬節點的配置動態擴容。
支持動態部署前提:
配置文件動態加載。(配置文件可以在Classpath中,也可以是Http資源的方式)通過Cache Client 中Cache Manager可以停止Cache 服務,重新加載配置文件,即時生效。
當前動態部署的兩種方式:
1. 修改集群配置中某一套虛擬節點的服務實例配置(socketPool配置),增加或者減少后端數據存儲實例。然后動態加載新的配置文件(可以通過指定遠端的http配置作為新的配置文件),通過集群的lazy的修復方式,逐漸的將數據從冗余節點復制到新的節點上來,最終實現數據遷移。
2. 修改集群配置中某一套虛擬節點的服務實例配置(socketPool配置),增加或者減少后端數據存儲實例。然后動態加載新的配置文件(可以通過指定遠端的http配置作為新的配置文件),在調用Cache Manager主動將數據由某一虛擬節點復制到指定的集群中,實現數據批量遷移,然后根據需要看是否需要修改其他幾套虛擬節點配置。
存在的問題:
1. 當前沒有做到不停止服務來動態部署。(后續考慮實現,當前將編譯配置和重新啟動服務器的工作節省了)
2. 不論是lazy復制還是批量數據遷移,都是會將原本有失效時間的數據變成了無失效時間的數據。(這個問題暫時還沒有一種可行的高效的方式解決)
后話
性能優化這點事還是那句老話,需要了再去做也不遲。同時如果你開發的是一個每天服務訪問量都是上億,甚至更高的系統,那么有時候斤斤計較會收獲不少。(當然是不影響系統本身業務流程的基礎)。
Cache客戶端自從作為開源放在Google上也收到了不少朋友的支持和反饋,同時自己業務系統以及其他部門同學的使用促使我不斷的去優化和滿足必要的一些功能擴展(但是對于Cache來說,還是那句話,簡單就是美,高效是使用Cache的最原始的需求)。
當前Cache Client版本已經到了2.5版本,在Google上有詳細的Demo(單元測試,壓力測試,集群測試)和說明使用文檔。是否速度會慢于其他Memcached客戶端,這不好說的很絕對,反正大家自己拉下去比較一下看看就知道了,當然為了集群和其他的一些必要的附加功能還是做了一些性能犧牲。
項目地址在:http://code.google.com/p/memcache-client-forjava/
在首頁的右側有demo,doc,binary,src的鏈接,直接可以下載使用和察看。希望對需要的同學有幫助。