這篇blog的問題不能算是解決,僅僅只是一種分析和猜測,后續的一些行動可能會證明一些猜想,也可能什么都解決不了。如果有和我相同情況的同學,也知道是什么問題造成的,請不吝賜教。
問題:
上周周末,沒有和同事們出去Outing,在家管孩子,去生產環境觀察了一下集群機器的當前運行狀態,發現應用在這些多核機器上壓力極端不均勻。
Top一下大致狀態如下:
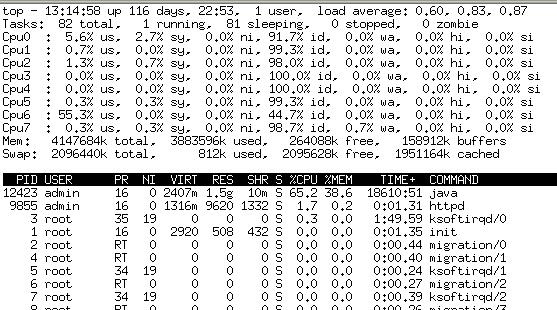
峰值的時候,單CPU的使用率都到了80%,這種情況對于多核服務器來說是很不正常的使用。對于Java的開發者來說,多線程編程是無法控制線程如何在CPU上分配的,因為Java本身不實現線程機制,說是跨平臺的語言,但是性能及特性會根據操作系統的實現有很大的差異,因此Java調優有時候需要對系統配置甚至內核作調優。
分析:
首先在測試環境下作了多次同樣的壓力測試,嘗試了與線上一樣的操作系統版本,相似的配置,但測試結果卻是負載分配很均勻。
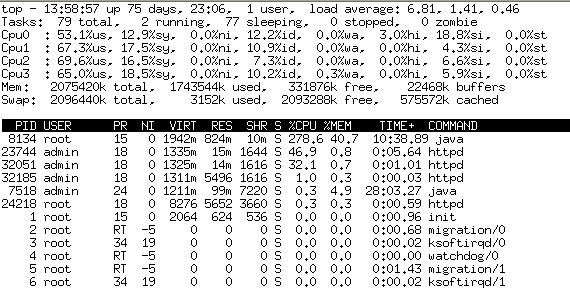
此時重新啟動了一臺問題機器,發現負載降下來了,同時也很均衡,也就是說在當前的壓力下不應該有這樣高的cpu消耗,同時也排除了硬件或者操作系統的一些配置問題。
在CPU滿負荷的情況下,很多時候會認為應該是循環造成的,對于單個CPU的消耗更是。通過Top H查看具體到底哪一個線程會長時間消耗CPU。
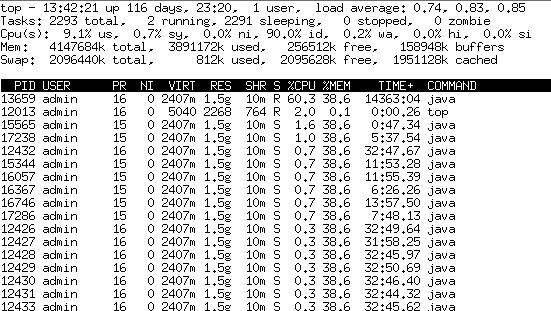
可以看到PID為13659的線程是“罪魁禍首”,但13659究竟在干什么,是應用的線程還是系統的線程,是否是陷入了死循環,不得而知。接著就按照Java的土辦法,Kill -3 pid,然后看看輸出日志。
根據線程號來查找dump出來的日志中nid,發現這個線程是VM Thread,也就是虛擬機線程。(這里作一下轉換,將13659轉換成為16進制就是0x355b)
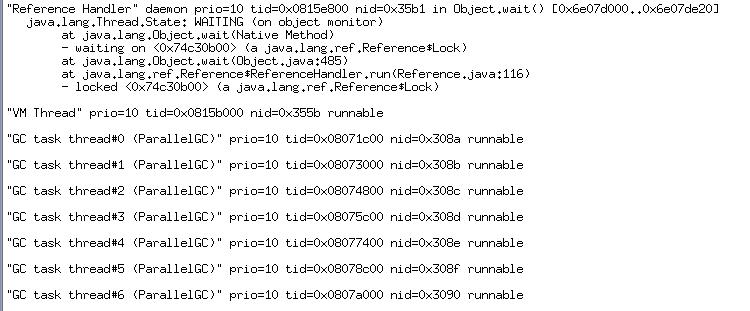
用pstack看了一下這個線程的工作,結果如下:
Thread 2074 (Thread 1846541216 (LWP 13659)):
#0 0x0659fa65 in ObjectSynchronizer::deflate_idle_monitors ()
#1 0x065606e5 in SafepointSynchronize::begin ()
#2 0x06613e83 in VMThread::loop ()
#3 0x06613a6f in VMThread::run ()
#4 0x06506709 in java_start ()
#5 0x00aae3cc in start_thread () from /lib/tls/libpthread.so.0
#6 0x00a1896e in clone () from /lib/tls/libc.so.6
搜索了一下ObjectSynchronizer::deflate_idle_monitors,發現了sun的bug庫中有bug關于jdk1.6中由于這個方法導致運行期問題的說法:http://bugs.sun.com/bugdatabase/view_bug.do;jsessionid=803cb2d95886bffffffff9a626d3b9b28573?bug_id=6781744
然后就直接去openjdk官方網站去查找這個類的代碼,大致了解一下他的作用,具體的代碼鏈接如下:http://xref.jsecurity.net/openjdk-6/langtools/db/d8b/synchronizer_8cpp-source.html
主要工作應該是對資源對象的回收,在加上pstack的結果,應該大致知道是對線程資源的管理。但具體代碼就沒有進一步分析了。
接著就分析一下自己的應用:
壓力測試(高強度、長時間)都做過,沒有發現什么異常。
本身應用是否會存在的缺陷導致問題呢。有人說VM Thread兼顧著GC的工作,因此內存泄露,對象長期積壓過多也可能影響,但其實在dump的結果可以看到,GC有單獨的工作線程,同時我也觀察到GC這些線程的工作時間長度,因此由于GC繁忙導致CPU上去,基本上來說可以排除。
其次在SIP項目中使用了JDK的線程池(ExecutorService)和LinkedBlockingQueue。后者以前的文章里面提到在1.5版本里使用poll方法會有內存泄露,到1.6雖然沒有內存泄露,但是臨時鎖對象增長的很快,會導致GC的頻度增加。
行動:
上面零零散散的一些分析,最終讓我決定有如下的行動:
1. 升級某一臺服務器的JDK,當前是1.6.0_10-b33,打算升級到1.6的14版本。比較觀察多臺機器的表現,看是否升級了JDK可以解決問題。
2. 去除LinkedBlockingQueue作為消息隊列,直接由生產者將生產結果按照算法分配給消費者線程,避免競爭,鎖的消耗,同時也防止LinkedBlockingQueue帶來的資源消耗。
3. 測試環境繼續作長時間的壓力測試,同時可以結合Jprofile之類的工具來分析長時間后可能出現的問題。
后話:
這年頭真的啥都要學一點,求人不如求己。
SA,DBA,測試都需要能夠去學習一些,起碼在初期排查問題上自己能夠做點啥,要不然別人也忙,自己又無從下手。就好比這次壓力測試好不容易排上隊,但是還是滿足不了及時上線的需求,因此自己去LoadRunner壓,好歹給出一個零時的報告先大家看著。應用的異常有時候是應用本身設計問題,也可能是開發語言的問題,也可能是操作系統的問題,因此要去定位這種比較復雜的問題,真的需要有耐心去好好的學習各種知識,現在看來知識還是匱乏啊,要不然就可以分析出openjdk中可能存在的問題。