如果你不了解PipeComet,請先看看:
http://blog.csdn.net/cenwenchu79/archive/2011/05/27/6450427.aspx
PipeComet這個支持長連接,異步請求事件處理框架做了測試也快有5天了,這里做一個簡單的總結,但這個文檔中的數字不能作為最終容量的定論,后續還會在優化后有進一步的測試。同時這個文檔更傾向于分享過程中的遇到的一些問題,可以避免走一樣的彎路。
測試環境:
1臺部署了Jetty Web容器作為PipeComet服務端。
2臺windows測試機部署了兩個LoadRunner,作為壓力測試客戶端。(一個用于建立大量長連接,一個用于產生http請求模擬外部事件激發數據片段下發)
服務端配置如下:
Xen虛擬機,5核(2.40 GHz),8G內存。
Jetty 7.1.6版本,jdk 1.6.0_25
JVM配置:-Xms7g -Xmx7g -XX:PermSize=96m -XX:MaxPermSize=256m -Xmn3g
Jetty配置:
<Set name="ThreadPool">
<!-- Default queued blocking threadpool -->
<New class="org.eclipse.jetty.util.thread.QueuedThreadPool">
<Set name="minThreads">400</Set>//最小和最大線程池設置的都有一點大,后面大致說一下
<Set name="maxThreads">800</Set>
</New>
</Set>
<Call name="addConnector">
<Arg>
<New class="org.eclipse.jetty.server.nio.SelectChannelConnector">
<Set name="host"><Property name="jetty.host" /></Set>
<Set name="port"><Property name="jetty.port" default="8080"/></Set>
<Set name="maxIdleTime">3600000</Set> //無數據傳輸的連接保持多久,單位毫秒
<Set name="Acceptors">4</Set>
<Set name="statsOn">false</Set>
……
</New>
</Arg>
</Call>
測試場景描述:
1.啟動服務端,并建立有Condition模式的管道配置。
2.壓力測試機A通過LoadRunner并發啟動N個vuser,與服務端建立N個長連接會話,服務端建立N個事件掛起當前多個請求,等待外部消息激發下行數據片段或者關閉會話。
3.壓力測試機B通過LoadRunner并發啟動P個vuser,隨機的發起激發某一個長連接會話下行數據片段的請求,服務端接收請求后,主動向下推送數據片段。
這里有兩個參數N和P,N就代表單機支持多少長連接,P代表并發創建多少個事件去激發下行數據。
事先環境準備:
Linux:(這塊做過高并發測試的一般都還是會比較注意)
調整一下/etc/sysctl.conf的一些系統參數:(具體不解釋了,看上面的英文注釋)
#add by fangweng
fs.file-max = 65535
#Allow for more PIDs
kernel.pid_max = 65536
#Increase system IP port limits
net.ipv4.ip_local_port_range = 2000 65000
# TCP and memory optimization
# increase TCP max buffer size setable using setsockopt()
net.ipv4.tcp_rmem = 4096 87380 8388608
net.ipv4.tcp_wmem = 4096 87380 8388608
# increase Linux auto tuning TCP buffer limits
net.core.rmem_max = 8388608
net.core.wmem_max = 8388608
net.core.netdev_max_backlog = 5000
修改后:
sysctl -p /etc/sysctl.conf // 作用:重新載入/etc/sysctl.conf文件
Window調整(這個一定要注意)
放火墻和殺毒軟件關掉!!!
注冊表中修改
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\TCPIP\Parameters
修改里面:
TcpTimedWaitDelay 為1(原來30)
MaxUserPort 65534
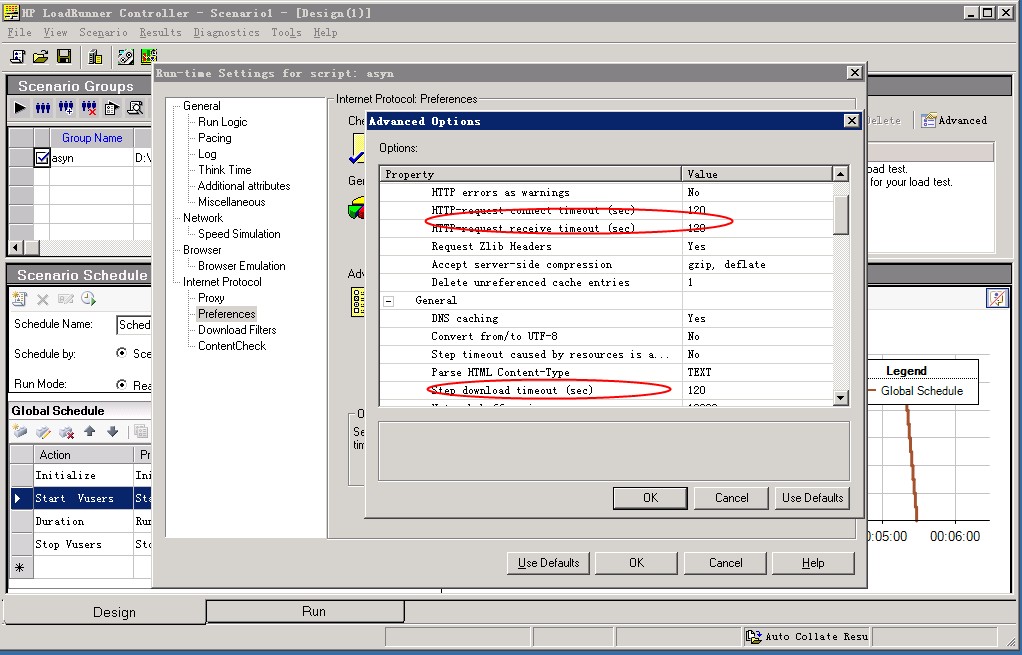
LoadRunner參數調整:
LoadRunner在為長連測試的時候,需要修改Run-time Settings,紅色部分盡量大一些
測試:
1. 并發2000個連接保持會話。
2. 并發100個VUser模擬向100個長連接發起事件驅動消息。
觀察得到的結果:
1. 建立起2000個連接過程中load保持在0.1到0.3左右,完全建立好后也就0.1多。(表明建立連接后現在的事件驅動處理方式沒有空轉損耗)
2. 并發100個Vuser開始循環壓測的時候,會有少數幾個連接主動掉線。(為了看是服務端主動斷連還是客戶端發起,執行了tcpdump,從抓包的結果可以看到客戶端主動的發起了Fin消息,當前只能認為在大量數據包下行的情況下,系統還是有保護的將下發數據頻率過高的連接斷開了,當防火墻或者殺毒軟件打開的時候,更是容易屏蔽,這點為將來長連在客戶端的問題處理也積累經驗)
3. 并發100個Vuser測試時,Load有明顯上升,在1-2.6之間,同時通過vmstat可以看到上下文切換數量遞增了兩個數量級。Sar方式統計也可以很明顯的看到在數據大量輸入輸出時,整個框架的系統消耗不小。
于是,開始判斷哪里出了問題。
Load變高作為java程序員如何判斷哪里出了問題呢,以下是我的經驗排查方式:
1. GC是否比較頻繁。(直接看gc log或者jstat gcutil)
2. IO消耗是否比較大。(cpu占用率到不高,vmstat)
3. 是否有代碼空轉。(cpu占用率很高,往往就幾個線程長期持有cpu)
4. 是否有大量的線程Blocked。(dump線程出來看看)
在剛才的測試基礎上做了一個簡單的對比,如果把一百個并發請求分散到500個事件隨機觸發上,整理的load要低于100個事件隨機模擬,也就是說數據越集中到某幾個連接的事件上,消耗越大。
本地jprofiler測試了一下,看到大量的blocked線程是在處理消息輸出的時候。原來當時為了簡單處理并發,在response上面就增加了一個寫鎖,保證每次輸出時候能夠支持并發,但write這個動作被放在鎖里是否適合?其實就是把一個時間消耗較長的動作去做了同步,最終其實使得在并發比較高,壓力比較大時,競爭和阻塞厲害,導致系統消耗增大。因此還是按照傳統的tcp sendbuffer模式,掛接內容支持多線程并發,輸出數據為單線程循環發送,再簡單測試了一下,Load明顯下去了,基本就在1左右。
你可以嘗試著去看vmstat,里面的procs中的r其實表示統計瞬時需要執行的任務隊列長度,你會發現有時候通過top看到的load很低,但是r還是會有些上下波動,但如果任務執行的快,其實對于load影響不大。
繼續測試:
|
并發連接數 |
事件激發模擬用戶數 |
Load(建立連接過程) |
Load(事件處理過程) |
|
2000 |
100(50個事件隨機選取) |
0.1 - 0.3 |
0.6 – 1.2 |
|
5000 |
100(50個事件隨機選取) |
0.1 – 0.3 |
0.7 – 1.4 |
|
5000 |
200(100個事件隨機選取) |
0.1 – 0.3 |
0.8 – 1.6 |
這個數據并不能反映容量,但是可以說明的是,長連接數量對于系統在高并發事件處理影響不是很大,建立長連接和管理長連接所屬的事件并不消耗系統資源(cpu,內存都觀察過)
這篇分享中沒有介紹測試中對于并發處理在異步事件驅動中的修改,具體的后續可以比較一下上次公布出來的代碼和新代碼的區別,簡單來說:
1. 原本可以狀態不脫離于線程,使得狀態不比擔心多線程并發控制,現在需要關注狀態和資源的并發控制(例如request的lazy解析,response的輸出,ThreadLocal的數據傳遞和復制)。
2. 客戶端可以主動斷開服務端,服務端網絡失敗也可以斷開客戶端,因此在任何一個對于懸掛起的異步web請求處理時都需要做好檢查和資源回收處理,防止資源泄露。
3. 系統的事件驅動模型狀態變更及對象內容變化要提供接口來保證用戶操作時可以支持多線程并發處理。
待續…