如果你不了解PipeComet,請(qǐng)先看看:
http://blog.csdn.net/cenwenchu79/archive/2011/05/27/6450427.aspx
PipeComet這個(gè)支持長(zhǎng)連接,異步請(qǐng)求事件處理框架做了測(cè)試也快有5天了,這里做一個(gè)簡(jiǎn)單的總結(jié),但這個(gè)文檔中的數(shù)字不能作為最終容量的定論,后續(xù)還會(huì)在優(yōu)化后有進(jìn)一步的測(cè)試。同時(shí)這個(gè)文檔更傾向于分享過程中的遇到的一些問題,可以避免走一樣的彎路。
測(cè)試環(huán)境:
1臺(tái)部署了Jetty Web容器作為PipeComet服務(wù)端。
2臺(tái)windows測(cè)試機(jī)部署了兩個(gè)LoadRunner,作為壓力測(cè)試客戶端。(一個(gè)用于建立大量長(zhǎng)連接,一個(gè)用于產(chǎn)生http請(qǐng)求模擬外部事件激發(fā)數(shù)據(jù)片段下發(fā))
服務(wù)端配置如下:
Xen虛擬機(jī),5核(2.40 GHz),8G內(nèi)存。
Jetty 7.1.6版本,jdk 1.6.0_25
JVM配置:-Xms7g -Xmx7g -XX:PermSize=96m -XX:MaxPermSize=256m -Xmn3g
Jetty配置:
<Set name="ThreadPool">
<!-- Default queued blocking threadpool -->
<New class="org.eclipse.jetty.util.thread.QueuedThreadPool">
<Set name="minThreads">400</Set>//最小和最大線程池設(shè)置的都有一點(diǎn)大,后面大致說一下
<Set name="maxThreads">800</Set>
</New>
</Set>
<Call name="addConnector">
<Arg>
<New class="org.eclipse.jetty.server.nio.SelectChannelConnector">
<Set name="host"><Property name="jetty.host" /></Set>
<Set name="port"><Property name="jetty.port" default="8080"/></Set>
<Set name="maxIdleTime">3600000</Set> //無數(shù)據(jù)傳輸?shù)倪B接保持多久,單位毫秒
<Set name="Acceptors">4</Set>
<Set name="statsOn">false</Set>
……
</New>
</Arg>
</Call>
測(cè)試場(chǎng)景描述:
1.啟動(dòng)服務(wù)端,并建立有Condition模式的管道配置。
2.壓力測(cè)試機(jī)A通過LoadRunner并發(fā)啟動(dòng)N個(gè)vuser,與服務(wù)端建立N個(gè)長(zhǎng)連接會(huì)話,服務(wù)端建立N個(gè)事件掛起當(dāng)前多個(gè)請(qǐng)求,等待外部消息激發(fā)下行數(shù)據(jù)片段或者關(guān)閉會(huì)話。
3.壓力測(cè)試機(jī)B通過LoadRunner并發(fā)啟動(dòng)P個(gè)vuser,隨機(jī)的發(fā)起激發(fā)某一個(gè)長(zhǎng)連接會(huì)話下行數(shù)據(jù)片段的請(qǐng)求,服務(wù)端接收請(qǐng)求后,主動(dòng)向下推送數(shù)據(jù)片段。
這里有兩個(gè)參數(shù)N和P,N就代表單機(jī)支持多少長(zhǎng)連接,P代表并發(fā)創(chuàng)建多少個(gè)事件去激發(fā)下行數(shù)據(jù)。
事先環(huán)境準(zhǔn)備:
Linux:(這塊做過高并發(fā)測(cè)試的一般都還是會(huì)比較注意)
調(diào)整一下/etc/sysctl.conf的一些系統(tǒng)參數(shù):(具體不解釋了,看上面的英文注釋)
#add by fangweng
fs.file-max = 65535
#Allow for more PIDs
kernel.pid_max = 65536
#Increase system IP port limits
net.ipv4.ip_local_port_range = 2000 65000
# TCP and memory optimization
# increase TCP max buffer size setable using setsockopt()
net.ipv4.tcp_rmem = 4096 87380 8388608
net.ipv4.tcp_wmem = 4096 87380 8388608
# increase Linux auto tuning TCP buffer limits
net.core.rmem_max = 8388608
net.core.wmem_max = 8388608
net.core.netdev_max_backlog = 5000
修改后:
sysctl -p /etc/sysctl.conf // 作用:重新載入/etc/sysctl.conf文件
Window調(diào)整(這個(gè)一定要注意)
放火墻和殺毒軟件關(guān)掉!!!
注冊(cè)表中修改
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\TCPIP\Parameters
修改里面:
TcpTimedWaitDelay 為1(原來30)
MaxUserPort 65534
LoadRunner參數(shù)調(diào)整:
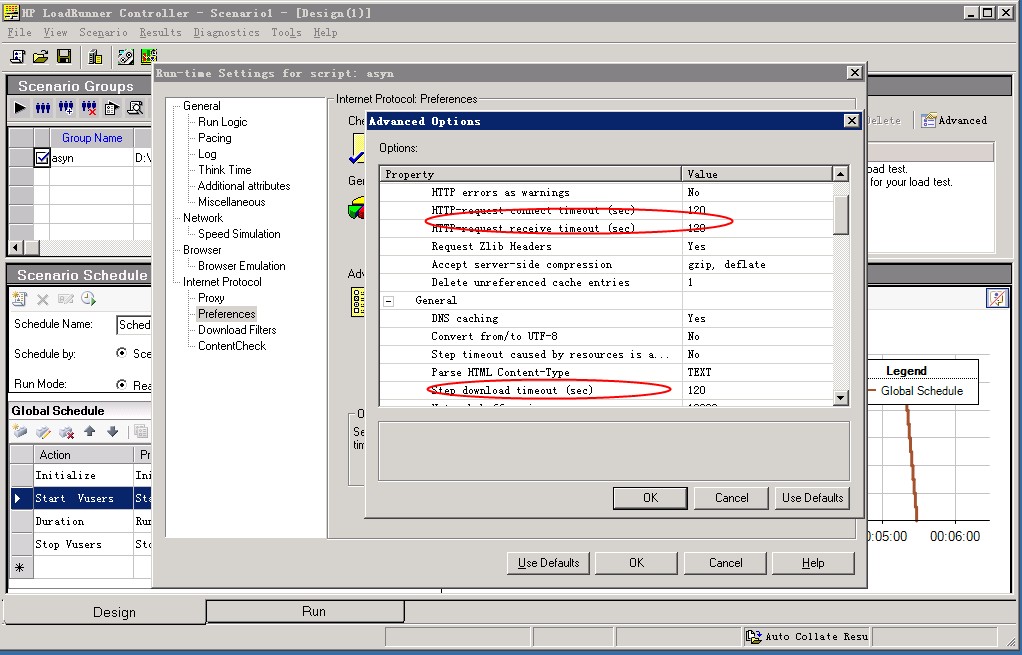
LoadRunner在為長(zhǎng)連測(cè)試的時(shí)候,需要修改Run-time Settings,紅色部分盡量大一些
測(cè)試:
1. 并發(fā)2000個(gè)連接保持會(huì)話。
2. 并發(fā)100個(gè)VUser模擬向100個(gè)長(zhǎng)連接發(fā)起事件驅(qū)動(dòng)消息。
觀察得到的結(jié)果:
1. 建立起2000個(gè)連接過程中load保持在0.1到0.3左右,完全建立好后也就0.1多。(表明建立連接后現(xiàn)在的事件驅(qū)動(dòng)處理方式?jīng)]有空轉(zhuǎn)損耗)
2. 并發(fā)100個(gè)Vuser開始循環(huán)壓測(cè)的時(shí)候,會(huì)有少數(shù)幾個(gè)連接主動(dòng)掉線。(為了看是服務(wù)端主動(dòng)斷連還是客戶端發(fā)起,執(zhí)行了tcpdump,從抓包的結(jié)果可以看到客戶端主動(dòng)的發(fā)起了Fin消息,當(dāng)前只能認(rèn)為在大量數(shù)據(jù)包下行的情況下,系統(tǒng)還是有保護(hù)的將下發(fā)數(shù)據(jù)頻率過高的連接斷開了,當(dāng)防火墻或者殺毒軟件打開的時(shí)候,更是容易屏蔽,這點(diǎn)為將來長(zhǎng)連在客戶端的問題處理也積累經(jīng)驗(yàn))
3. 并發(fā)100個(gè)Vuser測(cè)試時(shí),Load有明顯上升,在1-2.6之間,同時(shí)通過vmstat可以看到上下文切換數(shù)量遞增了兩個(gè)數(shù)量級(jí)。Sar方式統(tǒng)計(jì)也可以很明顯的看到在數(shù)據(jù)大量輸入輸出時(shí),整個(gè)框架的系統(tǒng)消耗不小。
于是,開始判斷哪里出了問題。
Load變高作為java程序員如何判斷哪里出了問題呢,以下是我的經(jīng)驗(yàn)排查方式:
1. GC是否比較頻繁。(直接看gc log或者jstat gcutil)
2. IO消耗是否比較大。(cpu占用率到不高,vmstat)
3. 是否有代碼空轉(zhuǎn)。(cpu占用率很高,往往就幾個(gè)線程長(zhǎng)期持有cpu)
4. 是否有大量的線程Blocked。(dump線程出來看看)
在剛才的測(cè)試基礎(chǔ)上做了一個(gè)簡(jiǎn)單的對(duì)比,如果把一百個(gè)并發(fā)請(qǐng)求分散到500個(gè)事件隨機(jī)觸發(fā)上,整理的load要低于100個(gè)事件隨機(jī)模擬,也就是說數(shù)據(jù)越集中到某幾個(gè)連接的事件上,消耗越大。
本地jprofiler測(cè)試了一下,看到大量的blocked線程是在處理消息輸出的時(shí)候。原來當(dāng)時(shí)為了簡(jiǎn)單處理并發(fā),在response上面就增加了一個(gè)寫鎖,保證每次輸出時(shí)候能夠支持并發(fā),但write這個(gè)動(dòng)作被放在鎖里是否適合?其實(shí)就是把一個(gè)時(shí)間消耗較長(zhǎng)的動(dòng)作去做了同步,最終其實(shí)使得在并發(fā)比較高,壓力比較大時(shí),競(jìng)爭(zhēng)和阻塞厲害,導(dǎo)致系統(tǒng)消耗增大。因此還是按照傳統(tǒng)的tcp sendbuffer模式,掛接內(nèi)容支持多線程并發(fā),輸出數(shù)據(jù)為單線程循環(huán)發(fā)送,再簡(jiǎn)單測(cè)試了一下,Load明顯下去了,基本就在1左右。
你可以嘗試著去看vmstat,里面的procs中的r其實(shí)表示統(tǒng)計(jì)瞬時(shí)需要執(zhí)行的任務(wù)隊(duì)列長(zhǎng)度,你會(huì)發(fā)現(xiàn)有時(shí)候通過top看到的load很低,但是r還是會(huì)有些上下波動(dòng),但如果任務(wù)執(zhí)行的快,其實(shí)對(duì)于load影響不大。
繼續(xù)測(cè)試:
|
并發(fā)連接數(shù) |
事件激發(fā)模擬用戶數(shù) |
Load(建立連接過程) |
Load(事件處理過程) |
|
2000 |
100(50個(gè)事件隨機(jī)選取) |
0.1 - 0.3 |
0.6 – 1.2 |
|
5000 |
100(50個(gè)事件隨機(jī)選取) |
0.1 – 0.3 |
0.7 – 1.4 |
|
5000 |
200(100個(gè)事件隨機(jī)選取) |
0.1 – 0.3 |
0.8 – 1.6 |
這個(gè)數(shù)據(jù)并不能反映容量,但是可以說明的是,長(zhǎng)連接數(shù)量對(duì)于系統(tǒng)在高并發(fā)事件處理影響不是很大,建立長(zhǎng)連接和管理長(zhǎng)連接所屬的事件并不消耗系統(tǒng)資源(cpu,內(nèi)存都觀察過)
這篇分享中沒有介紹測(cè)試中對(duì)于并發(fā)處理在異步事件驅(qū)動(dòng)中的修改,具體的后續(xù)可以比較一下上次公布出來的代碼和新代碼的區(qū)別,簡(jiǎn)單來說:
1. 原本可以狀態(tài)不脫離于線程,使得狀態(tài)不比擔(dān)心多線程并發(fā)控制,現(xiàn)在需要關(guān)注狀態(tài)和資源的并發(fā)控制(例如request的lazy解析,response的輸出,ThreadLocal的數(shù)據(jù)傳遞和復(fù)制)。
2. 客戶端可以主動(dòng)斷開服務(wù)端,服務(wù)端網(wǎng)絡(luò)失敗也可以斷開客戶端,因此在任何一個(gè)對(duì)于懸掛起的異步web請(qǐng)求處理時(shí)都需要做好檢查和資源回收處理,防止資源泄露。
3. 系統(tǒng)的事件驅(qū)動(dòng)模型狀態(tài)變更及對(duì)象內(nèi)容變化要提供接口來保證用戶操作時(shí)可以支持多線程并發(fā)處理。
待續(xù)…