
2012年8月18日
什么是索引?
提起索引,應該不會感到陌生,若說它就是目錄,大概都知道了,數據庫的索引與書的目錄很相似,都叫index.書的內容相當于數據庫表中的數據,書的目錄通過頁碼指向書的內容,同樣,索引也記錄了表中的關鍵值,提供了指向表中行的指針.書的目錄使讀者很快的找到想看的內容,而不必翻看書的每一頁,索引使得數據庫應用程序能夠不掃描全表而找到想要的數據.
索引是不是多多益善?
索引可以創建在一列或多列的組合上,也可以在數據庫表的多個列上建立不同的索引,但這些列應該是經常作為查詢條件的列.需要指出的是,并不是表上的索引越多越好,在數據庫設計過程中����,還是需要為表選擇一些合適的索引。寧缺勿爛����,這是建立索引時的一個具體選擇�����。在理論上,雖然一個表可以設置無限的索引����,但表中的索引越多,維護索引所需要的開銷也就越大���。每當數據表中記錄有增加、刪除�����、更新變化的時候�����,數據庫系統都需要對所有索引進行更新���。
索引的分類
索引可以分為三類:聚集索引(clustered index),非聚集索引,唯一性索引(unique index).根據索引字段組成又有復合索引的說法,復合索引可以是唯一索引也可以不是唯一索引.一個表上最多創建一個聚集索引和249個非聚集索引.
創建索引的條件
(1)為經常出現在關鍵字orderby���、group by���、distinct后面的字段�,建立索引���。
(2)在union等集合操作的結果集字段上�����,建立索引����。
(3)為經常用作查詢選擇的字段���,建立索引����。
(4)在經常用作表連接的屬性上��,建立索引�。
(5)考慮使用索引覆蓋���。對數據很少被更新的表�,如果用戶經常只查詢其中的幾個字段,可以考慮在這幾個字段上建立索引�����,從而將表的掃描改變為索引的掃描�。
創建索引的限制
(1)限制索引數目。
(2)唯一性太差的字段不適合單獨創建索引���;
(3)更新頻繁的字段不適合創建索引;
(4)不會做為查詢條件的字段不創建索引
posted @
2012-08-18 23:09 地心引力 閱讀(1481) |
評論 (0) |
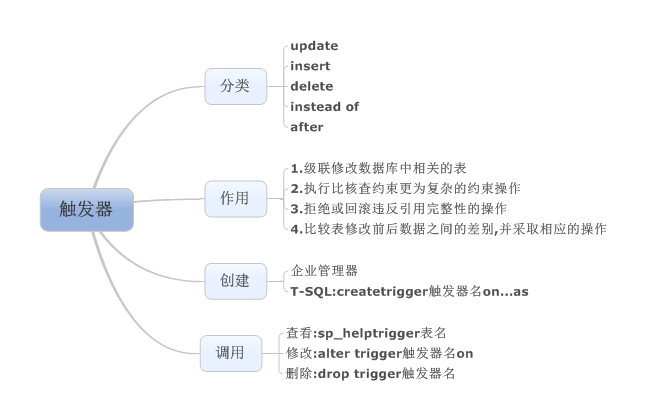
編輯 收藏 存儲過程和觸發器都是一組SQL語句集合,他們在數據庫開發過程中,在對數據庫的維護和管理等任務中,以及在維護數據庫參照完整性等方面,具有不可替代的作用.而觸發器是一種特殊的存儲過程,存儲過程獨立于表,具有訪問和操縱數據庫數據的功能,使應用程序執行效率得到進一步提高.觸發器也是T_SQL語句的集合,它與表密切結合,實現表中更為復雜的業務規則.
存儲過程是以一個名字存儲在數據庫中的,經過預編譯的T_SQL語句集合,可以獨立執行或通過應用程序的調用來執行.
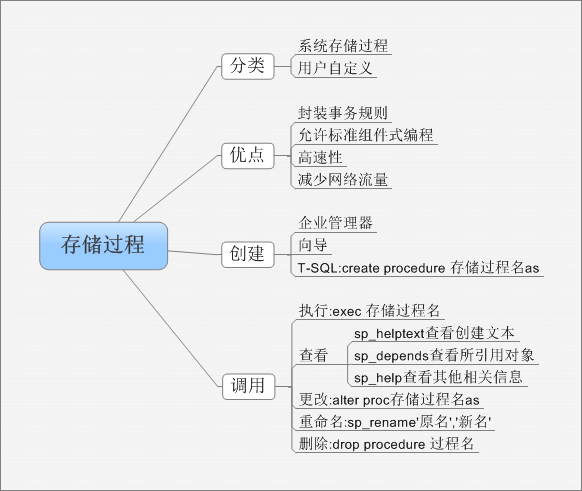
觸發器是不由用戶直接調用的,而是在對表或視圖中數據進行update,insert或者delete操作時自動執行.一個表或視圖可以有多個觸發器,每個觸發器可以包含復雜的SQL語句.數據庫表之間的引用完整性約束,除了可以采用主鍵和外鍵的對應約束來實現之外,還可以使用觸發器,從而實現更復雜的用戶定義完整性約束.
posted @
2012-08-18 23:09 地心引力 閱讀(1179) |
評論 (0) |
編輯 收藏字符函數
這個函數一般接收字符作為參數�����,并且可以返回字符或數字
其中最常用有以下兩個函數
1.CONCAT函數
主要用于字符串的連接�,具體語法如下
CONCAT(c1,c2)
接收兩個參數,將第二個參數連接到第一個參數的末尾����,假如第二個參數是NULL��,
則函數返回第一個參數�,假如第一個參數是NULL�����,則參數返回第二個參數,
假如都為NULL����,則函數返回NULL
為商品價格添加元單位示例如下:

2.NVL函數
這個函數主要用于函數替換
NVL(e1,e2)
接收兩個參數��,假如第一個參數不為NULL時,函數返回第一個參數���,
假如第一個參數為NULL時,函數返回第二個參數
具體的使用示例如下:
查詢商品表的相關信息�,對沒有詳細介紹的商品默認設置顯示“暫無詳細描述”

可使用暫無詳細描述來代替NULL
字符常用函數還有很多���,希望大家能在我的基礎上評論補充
posted @
2012-08-18 23:08 地心引力 閱讀(1158) |
評論 (0) |
編輯 收藏SQL語言是一種高級的非過程化的查詢語言��,用戶使用它主要進行數據庫的操作
可以把SQL語言看成是客戶端與服務器端溝通的一個工具,用來存取����,查詢和更新�����,關系數據庫系統
Insert語句
INSERT語句的語法結構如下:

table值的是要插入數據的表的表名,Column指的是要插入數據的列名��,Value指的是要插入的具體數據值
例如往會員表中插入一個新的會員數據���,可以這樣添加:

前者的優點是可以指定哪些字段添加哪些數據����,缺點是表名后面的小括號中的字段名需要和Value值相對照
后者的優點是書寫簡單,缺點是要把所有的字段都在Value中進行賦值
當需要插入數據包含有空值的時候��,一般使用第一種方法��,而第二種方法進行插入需要使用NULL關鍵字進行填充
假如插入的數據包含時間���,而且時間是當前的時間,

假如插入的是時間�,并且時間是某個具體的時間�,我們可以將上述的語句進行修改如下:

以上操作的都是單行的數據����,而下面的操作是多行的數據
插入多行數據示例如下:

UPDATE語句
UPDATE語句結構如下:

如初始化所有會員密碼:

按條件更新:

做更新操作的時候,WHERE條件一般選擇類似主鍵這樣有唯一性約束的字段,除非特殊情況,
否則的話會引起意想不到的誤操作,比如更新用戶表時以name作為條件的話�,就十分危險���,
因為名字是可以重復的
Select語句
我們對數據庫做得最多的操作是數據檢索
select語句就顯得極其重要
其中最簡單的查詢實例如下:
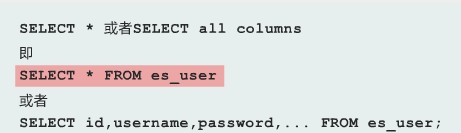
*指的是所有列
而查詢所有VIP數據如下:

查詢兩個條件同時成立的示例如下:

查詢兩個條件成立其中一個���,示例如下:

查詢條件為空的示例如下:

當要查詢會員中所有姓李的會員時��,需要用到模糊查詢:
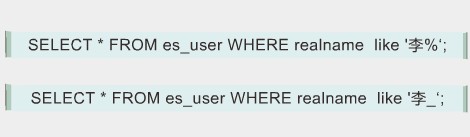
% 能匹配0到多個字符
_ 能任意匹配單個字符
查詢商品表中價格在300-400之間的商品數據;

而查詢會員表中張三、李四、王五的信息方法如下:

使用別名查詢:

其中查詢中可能需要對查詢的結果進行排序���,其結構如下:

查詢商品表,按上架時間進行排序:

如果想去掉查詢結果中的重復數據����,可以使用Distinction關鍵字�����,如下

Delete語句
語法結構如下

其中的table 和 condition在上面已經有提及
刪除示例如下

在實際操作中我們應該使用假刪除,就是再增加一個狀態(一般為status)的字段
在刪除錯誤之后����,我們可以用 ROLLBACK來回滾事務
posted @
2012-08-18 23:08 地心引力 閱讀(1176) |
評論 (0) |
編輯 收藏
摘要: 管理數據完整性一 學習目標 1.實現數據完整性約束 2.管理完整性約束 3.從數據字典中獲取約束信息二 保證數據完整性的方法 1.應用程序代碼控制 2.觸發器控制 3.聲明完整性約束三 約束的類型 (見圖) 1.not null (不能為空) ...
閱讀全文
posted @
2012-08-18 23:07 地心引力 閱讀(1333) |
評論 (0) |
編輯 收藏
2012年8月8日
linux是一個多用戶���,多任務的操作系統�����,對于每一個文件它的屬性中都包括:文件所有者(owner),文件所屬組(group),其他用戶(other),還必須具備與這三個角色對應的讀,寫�����,執行的權限���,如下圖:

在tmp目錄下面有一個a.txt文件�,我們通過ls -l命令可以查看其詳細信息:
-:表示普通文件,d:表示目錄文件,l:鏈接文件,b:設備文件中可以供存儲的接口設備,c:設備文件中串行端口設備如鍵盤��。
由于最前面是-:所以a.txt是普通文件��。
再看 rw-r--r--部分�����,我們將其分為三組,分別對應文件所有者�����,文件所屬組�,其他用戶的權限.
其中r代表讀取權限,w:代表寫權限,x:代表執行權限(這里沒出現),-:代表沒有某種權限��。
那對上面的權限的解釋就是:
owner:可以讀和寫���,不能執行
group:可以讀取不能寫�����,不能執行
other:可以讀取�,不能寫��,不能執行
第一個root代表文件所有者���,第二個root代表文件所屬組
那么現在我如果想修改文件所有者,文件所屬組����,文件權限該怎么做��,請繼續向下閱讀:
chgrp:修改用戶所屬組,chown:修改文件所有者�,chmod:修改文件權限
假設我的系統中又一個叫gavin的組(通過/etc/group查看)

如上圖���,通過chgrp命令將該文件的group修改為了gavin
下面修改其所有者:

修改其權限:

chmod 777 a.txt 這個777代表什么?
在linux中使用數字代表權限:
r:4 w:2 x:1
r-- =4+0+0=4;
rw- =4+2+0=6;
rwx =4+2+1=7
相信寫到這里大家都應該明白了吧����。
權限對于文件和文件夾的意義是不一樣的�����,
對于文件:
r:代表可以讀取文件的內容�����,w:代表可以修改文件的內容,x:可以執行這個文件
對于文件夾:
r:可以獲取文件夾中又哪些文件���,w:可以添加和刪除文件夾中的內容,x:可以進入文件夾�,
如果某個角色對于一個文件夾的權限是rw-;
那么他僅僅可以使用ls獲取文件夾中的內容�,但是不可以使用cd進入該文件夾��。
文件的權限告一段落���,現在來看看linux中的那些常見目錄中的內容:
/bin 系統有很多放置執行文件的目錄�,但是/bin比較特殊���,因為/bin放置的是在單用戶維護模式下還能夠被操作的命令��,在/bin下面的命令可以被root和一般賬戶使用,如:cat,chmod,chown,data,mv,mkdir,cp ,bash等常用命令。
/boot 主要放置開機使用到的文件
/dev 在linux系統中任何設備與接口設備都是以文件的形式存在于這個目錄當中�����,你只要訪問某個文件就相當于訪問該設備
/etc 系統的主要配置文件幾乎都在這個文件夾類。
/home 這是系統默認的用戶主文件夾
/lib 系統的函數庫非常多���,二/lib放置的是開機會使用到的函數庫
/mnt 如果你想臨時掛在一些外部設備(光盤)一般建議放置到這個目錄。
/opt 這是給第三方軟件放置的目錄
/root 系統管理員的主文件夾
/tmp 這是讓一般用戶或者正在執行的程序放置文件的地方����,這個目錄是任何人都可以訪問的����,所以你需要定期清理一下�����,當然重要數據時不能放到這里來的����。
關于文件權限的最后一點就是:文件默認權限umask
現在我們已經知道如何新建或者改變一個目錄的屬性了�,不過你知道當你新建一個新的文件或則目錄是,它的默認權限是什么嗎��?那就是于umask這東西有關了�����,那么umask是在搞什么呢�����,基本上����,umask就是制定目前用戶在新建文件或目錄的時候權限的默認值,如果獲得或設置umask���,方法如下:
#umask 或則 umask -S
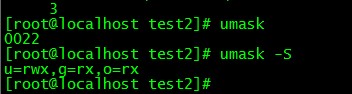
(四位數,第一位我們先不管��,表示特殊權限�����,我們從第二位開始看起)
在默認權限上�,文件和目錄是不一樣的���,對于一個目錄�,x權限是非常重要的 ,而對于一個文件,x權限在默認是不應該有的��,因為文件大多是用來存儲數據的���,所以在linux中�����,文件的默認權限是666,目錄的默認權限是777
要注意的是umask的分數指的是“默認值需要剪掉的權限”,
所以新建文件時權限:rw--r--r--
新建目錄:r-xr-xr-x
posted @
2012-08-08 23:41 地心引力 閱讀(1043) |
評論 (0) |
編輯 收藏#include <stdio.h>
#include <stdlib.h>
/*判斷用戶輸入的字符串是否為回文
*回文是指順讀和反讀都一樣的串
*例:abccba為回文���,abcdab不是回文
*/
int Palindrome(const char *str)
{
int length = strlen(str);
for(int i = 0; i <= length/2; i++)
{
if(str[i] != str[length-i-1])
{
return -1;
}
}
return 1;
}
int main()
{
char s[100];
gets(s);
int result = Palindrome(s);
if(result == 1)
{
printf("字符串是回文");
}
else
{
printf("字符串不是回文");
}
}
posted @
2012-08-08 23:40 地心引力 閱讀(6390) |
評論 (2) |
編輯 收藏package com.xtfggef;
public class SelectSort {
/**
* @param args
*/
public static void main(String[] args) {
int[] data = new int[]{2,3,4,1,9,8};
System.out.println("before sorted:");
for(int k=0; k<data.length; k++){
System.out.print(data[k]+" ");
}
System.out.println();
int length = data.length;
for(int i=0; i<length-1; i++){
int flag = i;
for(int j=i+1; j<length; j++){
if(data[flag]>data[j]){
flag = j;
}
}
if(flag!=i){
int temp=0;
temp=data[i];
data[i]=data[flag];
data[flag]=temp;
}
}
System.out.println("after sorted:");
for(int h=0; h<data.length; h++){
System.out.print(data[h]+" ");
}
System.out.println();
}
}
posted @
2012-08-08 23:39 地心引力 閱讀(835) |
評論 (0) |
編輯 收藏
2012年8月1日
一.單行函數介紹
---單行函數對單行操作
---每行返回一個結果
---有可能返回值與原參數數據類型不一致(轉換函數)
---單行函數可以寫在SELECT,WHERE,ORDER BY子句中
---有些函數沒有參數���,有些函數有一個或多個參數
---函數可以嵌套
分類:字符函數����,數字函數�����,日期函數,轉換函數,通用函數
二.字符函數
1.簡介
定義:主要指參數類型是字符型,不同函數返回值可能是字符或數字類型
<1>.LOWER:全小寫
LOWER('SQL Course')——>sql course
<2>.UPPER:全大寫
UPPER('SQL Course')——>SQL COURSE
<3>.INITCAP:首字母大寫
INITCAP('SQL Course')——>Sql course
<4>.CONCAT:字符串連接
CONCAT('Good','String')——>GoodString
<5>.SUBSTR:字符串截取
SUBSTR('String',1,3)——>Str
<6>.LENGTH:返回字符串長度
LENGTH('String')——>6
<7>.INSTR:返回一個字符串在另一個字符串中的位置
INSTR('String','r')——>3
<8>.LPAD:左填充
LPAD(sal,10,'*')——>******5000
<9>.RPAD:右填充
RPAD(sal,10,'*')——>5000******
<10>.TRIM:去掉左右兩邊指定字符
TRIM('S' FROM 'SSMITH')——>MITH
<11>.REPLACE:替換字符串
REPLACE('abc','b','d')——>adc
三.數字函數
<1>.ROUND:四舍五入函數
ROUND(12.3)——>12
ROUND(12.5)——>13
<2>.TRUNC:截斷函數
TRUNC(65.654,0)——>65
TRUNC(65.654,-1)——>60
<3>.MOD:取余函數
MOD(10,12)——>10
MOD(7,12)——>7
MOD(10,4)——>2
四.日期函數
<1>.SYSDATE:返回系統日期
<2>.MONTHS_BETWEEN:返回兩個日期間隔的月數
select months_between('02-2月-06','02-2月-06') from dual;
<3>.ADD_MONTHS:在指定日期基礎上加上相應的月數
select add_months('02-2月-06',8) from dual;
<4>.NEXT_DAY:返回某一日期的下一個指定日期
select next_day('1-2月-12','星期一') next_day from dual;
<5>.LAST_DAY:返回指定日期當月最后一天的日期
select last_day('1-2月-12') last_day from dual;
<6>.ROUND(date[,'fmt'])對日期進行指定格式的四舍五入操作,按照YEAR、MONTH�、DAY等進行四舍五入
SELECT employee_id, hire_date, ROUND(hire_date, 'MONTH') FROM employees WHERE SUBSTR(hire_date,-2,2)='98';
<7>.TRUNC(date[,'fmt'])對日期進行指定格式的截斷操作���。按照 YEAR����、MONTH、DAY等進行截斷
SELECT employee_id, hire_date, TRUNC(hire_date, 'MONTH') FROM employees WHERE SUBSTR(hire_date,-2,2)='98';
<8>.EXTRACT:返回從日期類型中取出指定年、月��、日
SELECT last_name, hire_date, EXTRACT (MONTH FROM HIRE_DATE) MONTH FROM employees WHERE department_id = 90;
五.轉換函數
---通常在字符類型�、日期類型、數字類型之間進行顯性轉換。
<1>.TO_CHAR(date|number|'fmt'):把日期類型/數字類型的表達式或列轉換為字符類型
--‘fmt’:指的是需要顯示的格式����,需要寫在單引號中��,并且是大小寫敏感,可包含任何有效的日期格式
常用日期格式:
---YYYY:4位數字表示年份 ---DY:星期的英文前三位字母
---YY:兩位數字年份,但是無世紀轉換 ---DAY:星期的英文拼寫
---RR:2位數字表示年份�,有世紀轉換 ---D:數字表示一星期的第幾天����,星期天是一周的第一天
---YEAR:年份的英文拼寫 ---DD:數字表示一個月中的第幾天
---MM:兩位數字表示月份 ---DDD:數字表示一年中的第幾天
---MONTH:月份英文拼寫 ---AM或PM:上下午表示
---HH 或HH12或HH24:數字表示小時 ---MI:數字表示分鐘
HH12代表12小時計時,HH24代表24小時計時 ---SS:數字表示秒���;
特殊格式:
TH:顯示數字表示的英文序數詞��,如:DDTH顯示天數的序數詞
SP:顯示數字表示的拼寫
SPTH:顯示數字表示的序數詞的拼寫
select to_char(sysdate,’ddspth’) from dual;
“字符串”:如在格式中顯示字符串����,需要兩端加雙引號
select to_char(sysdate,’dd “of” month ‘) from dual;
數字到字符型轉換:
進行數字類型到字符型轉換�����,格式中的寬度一定要超過實際列寬度,否則會顯示為###
-- 9:一位數字
-- 0:一位數字或前
-- $:顯示為美元符
-- L:顯示按照區域
-- .:小數點
-- ,:千位分割符
select to_char(9832, '$9,999.00') from dual;
<2>.TO_NUMBER(char[,’fmt’]): 把字符類型列或表達式轉換為數字類型
select to_number('9832', 9999) from dual;
<3>.TO_DATE(char[,‘fmt’]): 把字符類型列或表達式轉換為日期類型
select to_date('20120304', 'yy-mm-dd') from dual;
六.通用函數
<1>NVL(表達式1��,表達式2)函數:該函數功能是空值轉換�,把空值轉換為其他值,解決空值問題��。如果表達式1為空��,則表達式2就是要轉換成的值��。
注意:數據格式可以是日期、字符�、數字��,但數據類型必須匹配
select nvl(null,1) from dual;
select nvl(2,1) from dual;
<2>.NVL2(表達式1, 表達式2, 表達式3)函數:該函數是對第一個參數進行檢查。如果第一個參數不為空��,則輸出第二個參數��,如果第一個參數為空�����,則輸出低三個參數,表達式1可以為任何數據類型��。
select nvl2(null,1,2) from dual;
select nvl2(3,1,2) from dual;
<3>.NULLIF(表達式1����,表達式2)函數:該函數主要完成兩個參數的比較。當兩個參數不相等時��,返回值是第一個參數值�����;當兩個參數相等時�����,返回值是空值��。
select nullif(1,1) from dual;
返回值是: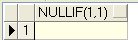 不是null;
不是null;
select nullif(1,2) from dual;
<4>.COALESCE(表達式1, 表達式2, ... 表達式n)函數:該函數是對NVL函數的擴展���。COALESCE函數功能是返回第一個不為空的參數�����,參數個數不受限制。
select coalesce(null,null,0,1) from dual;
<5>.CASE表達式:
SELECT last_name, commission_pct,
(CASE commission_pct
WHEN 0.1 THEN '低'
WHEN 0.2 THEN '中'
WHEN 0.3 THEN '高'
ELSE '無'
END) Commission
FROM employees
WHERE commission_pct IS NOT NULL
ORDER BY last_name;
<6>.DECODE函數:
DECODE(字段|表達式, 條件1,結果1[,條件2,結果2…���,][,缺省值])
select last_name, commission_pct,decode( commission_pct,0.1,'低',0.2,'中',0.3 , '高','無') commission
from employees where commission_pct is not null orderbylast_name;
posted @
2012-08-01 22:05 地心引力 閱讀(761) |
評論 (0) |
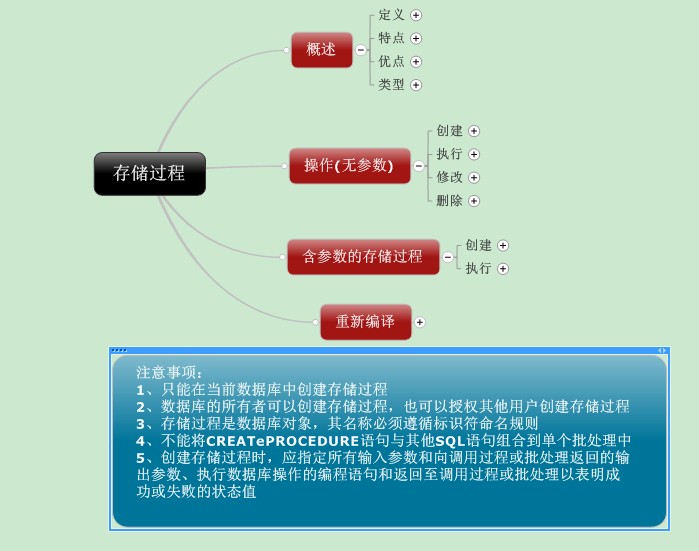
編輯 收藏剛開始學習存儲過程的時候,就把它想象成生活中把一些東西存儲在某些地方,需要的時候再把它取出來使用�����。而在數據庫學習和總結中,才發現存儲過程是一種數據庫對象���,是為了實現某個特定任務,將一組預編譯的SQL語句以一個存儲單元的形式存儲在服務器上����,供用戶調用��。

posted @
2012-08-01 22:04 地心引力 閱讀(674) |
評論 (0) |
編輯 收藏