1. 父進程(繼續執行)和子進程并行的執行;
2. 父進程等待部分或者全部子進程終止執行;
1. 子進程是父進程的一個COPY了;
2. 載入一個程序來運行;
1. 共享緩沖區提供通信;
2. 消息傳遞;
1. 每對需要通信的進程之間自動建立一條鏈路,進程只需要知道彼此的進程標識符(Pid);
2. 一個連接就只連接到這兩個進程;
1. 只有在兩個進程間有一個共享郵件箱下才能兩者建立一個連接;
2. 一條鏈路可以連接兩個或者更多的進程;
3. 每對通信進程之間可以同時存在多個不同的鏈路,而且每條鏈路對應一個郵箱;
一旦擁有郵箱A的進程終止時,郵箱也就同時要消失,隨后向該郵箱發送消息的進程就會被告知郵箱不存在。這里需要強調的是作為操作系統本身來說擁有一個郵箱是獨立的不依賴于任何進程。所以操作系統有必要提供一種機制允許一個進程來專門做這個工作了,那是什么工作呢?具體有以下特征:
u 創建一個新郵箱;
u 通過這個郵箱發送和接收信息;
u 刪除一個郵箱;
接下來就開始單獨討論所謂的這個“郵箱”的單獨機制能夠引發的一些線索了。
進程同步
通過消息傳送來進程通信,這個是它本質所在。但是消息傳送可能有阻塞或者無阻塞——同步和異步。所以這里就存在對于發送者和接收者的阻塞或無阻塞現象的討論了,對于他們有一下特點:
1. 發送進程阻塞:發送進程被阻塞,直到接收進程接收消息;
2. 發送進程無阻塞:發送進程發送消息并且立刻恢復執行;
3. 接收進程阻塞:接收進程被阻塞,知道一個消息為有效;
4. 接收進程無阻塞:接收進程獲取一個有效或空消息;
以上的方式還可以組合形成。
既然有阻塞和無阻塞現象,那立刻可以聯想到我們的郵箱擴展成一種管道方式呢?沒錯這里就需要講解下面的定義形成。
緩沖
這里只想對于三個定義了解:
u 零長度:無緩沖消息系統;
u 限定長度:
自動緩沖
u 無限長度:
這里單獨把限定長度和無限長度提取出來定義:
限定長度:消息隊列中存在N個消息,發送者在發送未滿的隊列中無阻塞。一旦隊列滿則阻塞直到出現空閑空間。
無線長度:消息隊列有無限個消息,也不會阻塞發送者。
下面我們就要通過這些概念擴展到程序開發中經常會遇到的實例。
(待續。。。。。。)
posted @
2008-12-14 12:42 葉澍成 閱讀(1226) |
評論 (0) |
編輯 收藏在學習Erlang程序過程中,總覺得對于進程還是沒有很好的把握。所以自己對于進程的再次提及讓我不得不重溫操作系統這門看似抽象的課程了。但是總覺得如果單一講解進程或許略顯抽象不夠理解,自己就想把某些經驗和知識片段有個很好的系統聯系起來,我想這樣可以讓自己更好加強記憶理解。長話短說,我們進入主題,既然在Erlang的學習中始終圍繞著進程一詞來深入研究,我們就從進程這個話題談起。
進程概念
1. 進程是運行中的程序。這里我們就可以稍微延伸下以便幫助我們記憶理解了:
在這里我們只要抓住“運動”詞匯,就不然發現進程是個動態的實體,與之對應的是我們常說的程序,程序而是一個靜態實體了。(bw:這里突然想到以前對于認識EJB2中也有一個對應的概念就是EntityBean與SessionBean,它們與之對應的就是一個典型的名詞和動詞概念了,哈哈啰嗦了,轉回正題)。那我們會想是什么來體現我們說的進程為一個動態實體呢?立刻會聯系產生接下來的一個特點了。
2. 進程不僅僅是程序代碼,它包含了當前狀態。而這種狀態由兩個方面來表示:
u 程序計數器(program counter)
u cpu中的寄存器(registers)
就是由于進程中有程序計數器—指明下一條要執行的指令而且擁有一組相關的資源。這里又要繼續反問:到底是一個什么資源呢?那就要看下面會講到的PCB的概念了。
3. 進程還包含進程棧(process stack)。
例如:方法參數(method parameters);返回地址與本地變量等
4. 兩個進程可能會關聯到同樣的程序,剛才我們說到了所謂程序是一個靜態實體。顧名思義就是兩個進程允許使用同樣的代碼段,只是在參數不同而已。但是仍然認為這兩個進程是獨立執行的序列。例如:幾個用戶可能會同事運行主程序的不同拷貝一樣。
進程狀態
注:上面就是一個完整的進程狀態圖了。這里沒有必要多說什么了,圖表給了我們一個輪廓。
進程控制塊(PCB)
這里就是我們要講到的進程控制塊了,對于操作系統都是需要通過PCB來表示進程的。有些資料上也稱作為:任務控制塊。對于PCB的整體描述我們還是以圖表的方式來說明(這也是本人最喜歡也覺得最直觀的一種理解方式了):
|
Pointer(指針)
|
Process state(進程狀態)
|
|
Process number(進程序列號)
|
|
Program counter(程序計數器)
|
|
Register(寄存器)
|
|
Memory limits(主存中受限說明)
|
|
List of open files
|
|
。。。(這里其實還有很多,就不再一一列舉了)
|
PCB描述圖
既然是操作系統都需要通過進程控制塊來調用進程過程,那我們在這里舉例說明下如果有兩個進程結合PCB是如何在CPU之中切換使用進程的。為了更加清晰了解它們的過程,還是老規矩使用一個圖表來展示兩個進程分別為P1,P2怎么運行的。
(這個圖在自己的筆記本上已經用筆畫出來了,可就是找不到一個好的工具,暫時放置在這,待續畫圖了)
進程調度
由于我們目前接觸的其實多半都是以分時系統為主的,其目標也是為了在進程之間頻繁轉換cpu以便由于用戶與運行的程序來交互。
1. 進程進入系統后,都被放在隊列中了,我們稱這個隊列為:作業隊列(也有些書上不是這么稱呼的),所有的進程都在這個其中。
2. 處于就緒進程都被保留在一個列表中——就緒列表
3. 一旦進程獲得了CPU并且執行,就可能發生一下某個事件存在:
u 進程可能發出一個I/O請求,然后被放置在I/O隊列中;
u 進程也可能創建一個新的子進程并且等待它終止;
u 有時候發生一個中斷,導致進程強行從CPU里移除并返回就緒隊列;
調度程序
這里需要了解兩個主要的概念:
1. 長程調度(操作系統調度程序):從一個池中選擇進程并其載入內存中。
注:咋看不是很了解,可能這里需要了解虛擬存儲過程對于這個概念就比較好理解。這里大致說明下。由于過去我們所使用的內存(主存儲器)空間非常有限,在搶占的進程志愿中如果都想放入內存中顯然是不夠科學,而對于我們的后備動力輔助存儲器——磁盤(這里我們說是硬盤,當然也有3.5英寸的小磁盤了,呵呵)來說,就可以充分考慮到使用它來做個過度動態的存儲器。所以這樣一來我們就不需要把一個進程中所有的信息都裝載到內存中,而是在需要是再來考慮換入;而與之相反的就是不需要時就換出了(bw:這里的換入/換出如果比較頻繁也就證明我們的內耗比較嚴重,一般稱作這個叫:抖動現象。大家有時候感興趣的可以觀察我們主機的硬盤燈如果在頻繁的閃動就表示資源在不斷換入換出了,呵呵)。而這也就是虛擬存儲的一個本質過程,當然中間需要通過邏輯轉換表來過度,在這里我們就不再具體復述了。有興趣的可以去看看相關OS方面的書籍。
2. 近程調度(CPU調度程序):從這些進程中選擇就緒進程并為其某個分配CPU
注:說白了這里就是我們的cpu直接通過緩沖通道來調用就緒的程序進入運行。
上下文轉換
前面我們也談到了進程是在CPU中來回切換運行的,既然是一種來回切換運行那勢必需要讓CPU知道我們切換到下一個狀態執行的地址或者說切入點在哪了。這個就是為什么需要一個程序計數器的功效了。那我們把這種來回切換狀態,同時需要保存當前運行進程狀態信息給記錄下來以便下一次能夠定位到的方式稱作是——上下文轉換。
就上面的這樣一次轉換表述在一定程度上需要耗的硬件資源非常大(這里又要我強調下,更多的信息需要你還了解一些計算機組成體系結構了。希望有時間自己也總結一篇關于一個簡單程序在體系中運行過程)。因此上下文轉換在很大程度上就取決于硬件的支持了。
接下來要講到的應該是最核心的也是對以后我們無論是寫程序好還是學習一門新語言好,都需要很好理解的部分了。在這里也盡可能表述清楚。
(待續......)
posted @
2008-12-14 00:25 葉澍成 閱讀(1430) |
評論 (0) |
編輯 收藏云計算應該所具備的特質如下:
1. 高負載
2. 正常運轉
3. 容錯性
4. 分布式
5. 容易伸縮
Erlang(讀音:['?:læ?]厄蘭,中文意思為:占線小時(話務負載單位))正是由于它屬于開放的電信業務平臺,也就不難理解它的意義了。幾乎完全具備以上特質,而且它也是典型的函數式語言。和我們OOP的思想有著截然不同的概念。在以下的學習過程中主要還是以《Erlang程序設計》這本書作為一個學習的依據。
原子
定義:在Erlang中原子用來表示不同的非數字常量值。這里說白了其實就是一種常量的定義。Erlang中原子是全局有效的,不需要像以前c/c++那樣通過宏來定義或者包含文件。在定義原子的時候只需要注意以下一些特點就可以:
1. 一般情況原子是以一串以小寫字母開頭,后面有數字、字母、下劃線、郵件符號(@);
2. 使用單引號引用起來的字符也屬于原子,例如’Monday’;
3. 一個原子的值就是原子本身;
元組(tuple)
定義:首先它是Erlang中具有特質的一個定義,如果說把它和我們java中的一個JavaBean來類比可能稍顯類似,書上引用的是c語言數據結構來解說元組的結構,盡管非強淺顯能看懂。但是作為一個java程序員我覺得采用自己熟悉的語言結構來對比,學習效果更佳吧(對于記憶有很大幫助)。
比如我們一般對于JavaBean的定義是如下結構:
public class Person {
private String name;
private int height;
private int footSize;
private String eyeColor;
// get/set...
}
那在我們引用定義的時候就可以直接:
Person person1=new Person();
person1.setName("yeshucheng");
person1.setHeight(111);
person1.setFootSize(40);
person1.setEyeColor("black");
......
與之相對應的是我們使用Erlang來定義了,對于Erlang的定義就截然和c/c++或者java有著明顯不同,相對于更加精煉明了:(這里我直接使用書上說的所謂二元組)
Person={person,{name,yeshucheng},{height,111},{footsize,40},{eyecolor,black}}.
沒錯,就是這么直截了當的來定義,甚至賦值(嚴格說Erlang不能這么說,但是為了好記憶可以這么理解)
對于以上的定義這里要說明注意的地方:
1. 定義元組,元組中字段沒有名字,通常可以使用一個原子作為元組的第一元素來標明(請注意這里花括號內第一原子都是解釋逗號后面一個說明),這個元組所能代表的含義就是上面列出的程序定義了。
2. 創建元組,在聲明元組的同時其實已經創建了元組,這個也是Erlang的一大特點之一了。如果不再使用,也隨之銷毀。Erlang使用的垃圾搜集器去收回沒有使用的內存。
如:F={firstName,wan}
L={lastName,andy}
P={person,F,L}//這里就應對我們第一條說明的一樣第一個名稱表示就是后面所有逗號的整體列舉,如果在Erlang環境中對于上面寫完后,直接敲回車(語句結束后存在”.”這里稍微注意下)就會得到以下結果,正好印證我們所說明這這個問題了
==》{persong,{firstName,wan},{lastName,andy}}.
如果在創建過程中存在一個未定義的變量,則程序編譯就會產生錯誤。
3. 提取元組的字段值,剛才我們在程序中有定義一個Person的元組而且也設置值了,現在如果我們想得到或者說提取我們的值,那需要如何而做呢?首先我們采用基本的元組方式來試著看看如下:
1> Point={point,10,45}.
2> {point,X,Y}=Point.
3> X.
10
4> Y.
45
注明:這里又再次強調下point逗號后面的都是為他而說明的。
1>Person={person,{name,yeshucheng},{height,111},{footsize,40},{eyecolor,black}}.
2>{_,{_,Who},{_,_},{_,_},{_,_}}=Person.
3>Who.
yeshucheng
說明下,如果上面想得到的是值,那么位置響應對號入座然后Who換成What就成(我開始也犯錯誤,編譯立馬出錯,后來想想用過一個What試試,果然正確,呵呵)。
列表
定義:列表第一個元素稱為列表的頭(head),后部分稱為列表尾(tail),一般[H|T]來標示列表了。
注:列表的頭可以是任何東西,但是列表的尾通常還是一個列表。
至于具體的細節問題還是需要找找相關文檔看下為好,它的概念牽涉到后面的非常多的定義了。
posted @
2008-12-09 10:20 葉澍成 閱讀(1022) |
評論 (0) |
編輯 收藏邊緣技術人員,這里是個人的一個定義闡述而已,所有的售前售后咨詢師、維護人員、培訓講師等都包含在這個頭銜中。咋看感覺自己對這個頭銜有失偏頗的定論,其實不然我對這個行業的人員還是挺敬佩的。為什么這么說呢?因為他們當中多數是在和我們的客戶一線打交道,客戶的喜怒哀樂,喜形于色都能第一時間映入他們的腦海,他們需要學會最大的程度“承受”,即使受到某種輕視或者詆毀的狀態都需要忍受,同時還要很快的去更好處理當時的尷尬場景。某種程度來說他們類似一些公司業務跑單人員,但是他們有更多的技術背景同時這里面也有很多的牛人。這類人員所具備的素養更加強調人性的一面,也正是由于接觸不同社會個階層人員的廣泛,相對于那些整天坐在辦公室電腦前敲代碼的程序員來說是截然不同的天地。程序員的思維縝密這個都是毋庸置疑的,但是也正是這種思維方式讓他們容易陷入規則死板的世界,甚至有些人員會鉆牛角尖(你可別不承認哦?或許就是你自己了,哈哈)而對于這里的邊緣技術人員來說如果遇到同樣的一件事情很有可能他處理的方式會有很大不同,他的某種圓滑處理問題的方式或許就是你需要學習的。而作為公司的老板們也是最多和這類人員交涉的,因為他們了解公司的整體的宗旨方案,也了解客戶的需求,他們的老練思維往往會讓老板更加樂于傾聽。這也不難想象為什么這類人員有時候拿錢或許比你做孺子牛的自己來說更多的緣故了,更加受到器重讓你有嫉妒之嫌。你可曾想過如果老板讓你去做,自己又能否勝任呢?呵呵。
說到這里可能大家會覺得我講的似乎在說一名老練的銷售業務人員嗎?沒錯,如果你想做一個高端的邊緣技術人員(說到這自己都感覺有點不大確切了,呵呵)上面談到的那種圓滑是你必修課程,但是有這些個人認為還遠遠不夠!為什么這么說呢?在我看來,過去一些年確實很多做銷售的人員比做純技術的人員賺錢多這個也是不爭的事實。在未來如果你想在這個職位闖蕩,需要的素養再也不是靠過去的“牛皮嘴”了更多的是需要一個務實的干練大氣者。你需要知道在什么場合說話到位的分寸;你需要知道如何行云流水般的寫一份好材料;你需要有細心的觀察和不失吝嗇的豪邁口才;更甚你還不能缺少酒桌文化。。。。。。所有的這些或許你不具備,每個人都不是天生賦予有這些能力,但是你只要還年輕懂得如何去“學”就是你最大的資本。當然這些前提都是需要你性格已經具備它的潛質所在,不然勸你另擇道路或許也是你的一片天地呢?
寫到這回過頭看看,仿佛這個并不是自己的所謂“總結”了,連我自己都覺得自己都在天馬行空,哈哈。因為我們聽過太多的領導的年終評述,八股文的段落著實讓自己不想再陳詞濫調一番“在這辭舊迎新的新春,借著黨的春風我們回顧過去,展望未來在接下來的09年。。。”
既然09年馬上要到來,我也簡述下吧,俗是俗了點但是形式上還是要走一下的,呵呵。對于個人發展來說,09年自己還是想有個新的環境。人老在一個地方呆容易把自己給“停滯”成為慣性的“懶惰”。盡管自己有很多想法,但是有想法確實是不夠的,需要著實的執行一番。在09年開始有空就寫blog了,做看官N年之久。把自己的一些心得體會寫出來。若干年之后自己回頭看看或許是一種美妙的回憶呢?呵呵。在09年繼續鞏固自己的技術基石,同時也開始學習一門新語言:Erlang。在它的邁進同時還是不忘JAVA給我帶來無窮樂資。最后就是希望上天多給我一些機會,我時刻準備著,哈哈。相信自己一定行!
(唧唧歪歪這么多寫到這算都結束了!不知所云,哈哈)
PS:“有想法是不夠的,執行力度還很差”---崔,我非常謝謝有你這個朋友,你的直率和指點讓我知道太多的無知,也讓我知道人的奮斗目標是什么;盡管有時候你喜歡給我吃“棒棒糖”,內心甜滋滋的,但正是你的這些語言從某些側面刺激了我的思維,很是感謝你!真的。我希望我們09年我們都共勉。
08年總結評述(一)
08年總結評述(二)
08年總結評述(三)
posted @
2008-12-08 01:48 葉澍成 閱讀(1609) |
評論 (1) |
編輯 收藏而至于架構師這里只是作為個人對這個頭銜認定,或許以下對此評述有點片面或者主觀看法。首先我承認我更多的是傾向于它,同時也是我努力的目標(呵呵,或許自己離這個還有很大一段差距),當然我也相信很多朋友都有這個向往,但正是它的淡定、從容務實讓我內心的佩服。很多朋友都認為國內沒有真正的所謂架構師一說,相對于國外的那些牛牛們簡直就是小兒科。這點我首先承認確實目前中國整體大環境不是很好,所以在某些層面上社會的浮躁氣息都會把很多有才華的程序員特別是那些有架構師的氣質的朋友毫無顧忌的抹殺掉。但是如果你靜心坐下來想想,如果你無法改變這個環境何不更加務實的換位思考從自身做起呢?多問問自己:我是否已經具備架構師的特質呢?如果能這么想,那很好說明自己在某些問題首先能夠有淡定的決策感。
首先架構師在我看來需要有“存儲”非常龐大的知識面能力,他可以涉獵非常多技術層次;視野也需要夠廣闊;對于新生技術敏銳的感知度;甚至在技術的角度來說他還是一個狂熱者;在某個特定領域是一個行家(這里我并沒有說是專家,因為在我看來專家是一個非常有壓力的詞匯。呵呵)。所以這個也就印證一些朋友說的:首先你要有知識的廣博,一旦水到渠成后自然能夠從紛亂繁雜的技術中脫穎而出,認知到自己更加對什么感興趣,什么領域才是自己未來的方向。也就不存在很多朋友經常會問一些老鳥一樣的疑問:我該學習什么呢?我該如何學?我適合什么呢?。。。所有的這些看似初哥的問題在架構師的他根本就不存在疑問,因為他自己非常清晰自己下面的路是如何而走。而更多的是務實貼近他去更快更準確的把握問題的所在。計算機的語言對他來說已經是一種超脫思維,他更注重事物的本質所在。語言對架構師來說就是一種工具,而他要選擇的如何更加高效利用好工具。當然架構師也不是神,他也會有很多缺陷。例如在某些基礎知識的欠缺,但是他知道如何回頭去補充他的弱點,而且他也知道自己的欠缺是什么,他也需要別人去揭示他的不足。沒有關系,只要他還是個普通人不是神,他也就有不斷的長足進步可能。這些看上去覺得都挺虛幻,而且感覺自己比較難靠近甚至是覺得難以觸及。但是我覺得如果你連試的勇氣都沒有,何來談及這個詞匯價值呢?呵呵,上面說的這些可能對于我們來說非常淺顯的道理,但是都覺得這樣的人離我們比較遙遠(或許你也可能否認這個問題)。在這里我也就個人的角度來看到這個對于我來說都是“神”一樣的職位。這里沒有多談該如何的步驟成為一個理想的架構師,因為每個人的情況境遇不盡相同。但是對于你自己心中的他,我覺得還是需要有定位的。其實對于要想達到這樣一種也不是太遠及,只要你從現在做起,相信我們都能。
(待續……)
08年總結評述(一)
08年總結評述(二)
08年總結評述(四)
posted @
2008-12-06 11:29 葉澍成 閱讀(1884) |
評論 (1) |
編輯 收藏 對于這一年中自己更加清晰自己想要的是什么,也對技術的定位有著稍許自己的見解。特別是對于我們這些程序員來說,大家談到最多的還是自己未來的歸宿問題。每個人的性格不同對于事情的看法也就自然不一樣,但是個人認為無論你如何去尋求別人幫助來看清自己屬于哪種性格,更適合什么方向,這個還是有難度的。他人的意見更多的是參考,最后決定還是你自己。更多的認知度決定了一種水到渠成的站點。
程序員最終的歸宿在我看來無非就是三大類:項目經理,架構師,邊緣技術人員(這當中包括了:售前售后咨詢師、維護人員、培訓講師)。當然這個概括或許是不準確的,這里只是談到我自己一種認定方式而已。
先來談談項目經理,盡管在我接觸的這些年同行中掛在嘴邊最多的還是這個頭銜,但是大家對于這個職業的定位還是不夠清晰或許每個人心中的項目經理的層次不同。也印證了一句:一百個人看哈姆雷特就有一百個不一樣的哈姆雷特,呵呵。但是在這個行業中大家不得不承認,每個人的水平和對于知識層次的不一樣也造就了這種現象,而且這種現象也是正常的。這里列舉幾個典型對于項目經理描述的觀點:
u 項目經理的職責就是需要把現實中的事件通過你的溝通傳輸與技術人員來溝通翻譯,最終利用有效的資源來高效組合達到客戶預期的目標。
u 項目經理的職責就是需要對行業定位夠勁道,非常熟悉行業的業務流程。技術已經不在是你的講究的資本,如何高效協調組員來完成任務才是本職工作,和客戶溝通好也是最大的責任。
u 項目經理的職責就是需要對業務數據結構夠清晰,業務流程夠明白。
上面只是列舉比較常見的觀點(期間做了些修飾,但是大體意思基本是一樣的)其實它們的觀點理論上來說本質是一樣的,但是在個人看來扣住幾個關鍵詞:溝通、協調、行業業務、組織能力。能夠把它們更加“和諧”的共處發揮到權衡的量度上還是需要一定功力和技巧的。這個職業是需要經驗的累計,他的每次決策行徑都是要靠前一次或者說以前的經驗體會來推進的。在這之前強調更多的還是人性世界的主題,但是這里我發覺很多的程序員在這個職業的論道上缺少或者說盡可能的避免談論:技術知識面的掌控。很多人會說:你一旦做技術到了4,5年再不在項目經理上,那你就廢了。這種說法咋看都詫異,但是現實截然不同在我接觸的人當中有太多人是這種意識。開始我也覺得他們這種認知度是對的,但是隨著時間上的推移我慢慢發覺有這種思路的人多少帶點惰性思維。為什么這么說?很多人都認為程序員在第三年,第五年都是一個坎或者說遇到所謂的瓶頸。而這些人把這些話一推出后,更多的是喜歡和有類似的人員通過近似的思維碰撞找到一個內心的平衡點,繼而思維的“散發”也就慢慢蔓延開。他們就感覺:哦,原來我的想法還是對的原來不止我一個人有這樣的觀點。。。我不在這說有這種想法的人觀點是否正確,但是接下來我要談到的架構師多數的思維還是有不一樣的境界。可以肯定的是如果人云亦云,那只能說明你的惰性在潛意識一直在做塊遮羞布,“瓶頸”的效應能否讓你可曾聯想想到我們的CPU為什么要找突破口,如果你確實能夠坦白這個現實。那說明真正的項目經理才是一種質的升華。(待續……)
08年總結評述(一)
08年總結評述(三)
08年總結評述(四)
posted @
2008-12-05 09:43 葉澍成 閱讀(1803) |
評論 (6) |
編輯 收藏
昨天無意間被朋友問道:你今年的收獲是什么?自己才意識到原來不平凡的08年就要過去了,大到國家小到周圍朋友在這一年都有不同的變遷。這一年國家經歷了前所未有的艱難之路,大雪災、地震、北京奧運、金融海嘯這些都讓每個中國人或多或少的經歷著不同的感受,最起碼你是這當中的一個看似微小的組成原子也感同身受。看著朋友、同學個個都相繼組建家庭,步入幸福的婚姻殿堂。每每參加一次為他們祝福的同時也是憐惜自己的尷尬處境,呵呵。這或許就是一個人隨年齡的變化而不同的思維情緒了。這里就是一種我自認的緣分未到吧。
而這一年對于自己的表象變化不大,工作依然,情緒依舊。但是內心對于事物的認知度覺得有明顯的不一樣。對事情的看法更加的務實也更加的切合實際。人一生中可能會讓自己永遠無法忘記幾個時間點,以前我真的不相信。但是自己著實的經歷過才真切的能夠感受到,08年3月4日,這天讓我對事物的看法層面有著截然扭轉。也是這天對我對今后的技術認知度有著全然不同看法。盡管當天我沒有步入自己夢寐以求的技術殿堂,但是我確實很感謝當時的幾位同仁(PS:這里讓我記憶猶新的就是那位當時給我當頭一棒的女同胞,經歷過這么多交談應該說什么樣的對手都碰到過,但是能讓我真正“汗”顏的就只有她了)給了我一種視野的開闊,也讓我知道浮躁的背面就是堅實的基底,所以非常慶幸這天能給我一個來的稍顯晚點的忠告。也正是這天讓我真正梳理清晰我需要的是什么;我的方向是什么;我的不足是什么;我的目標是什么。這些所有的roadmap非常清晰在腦海里展現。那一刻讓我更加鄙視自己的無知,也讓自己知道:機會一定是留給一個時刻有準備的人。
至此那天之后我清楚的認識到我的不足也讓我有向往的一種超越精神。自己的清晰定位讓我閱讀大量的技術書籍。一旦沒有特別的應酬都只會悶在家中讀書,把以前大學“存儲”高閣的書本全部撿拾溫習(PS:記得在一個QQ群中聊天時候當時有位朋友說,你這么做成本代價會很高,當時說實在的真沒有悟到這個話的內涵,或許自己愚鈍的緣故。但是我相信晚意識比沒有意識要強)。在這種閱讀的過程中,真正讓我了解了互聯網的水有多“深”,需要了解它需要非常夯實的基底。當然在閱讀書籍時,我更多的是帶著問題去尋找答案,所以也就自然感覺越到后面越覺得自己的認知度很渺小。因為一個知識點會牽動到其它問題的入口,自己便馬上停下來找尋涉及到這個問題的入口尋找答案。。。。。。慢慢就知道自己了解的還是在一個圓內,自己不知道的圓都在這之外,自己也在不斷的把所知道的這個圓慢慢的畫大。
(待續……)
08年總結評述(二)
08年總結評述(三)
08年總結評述(四)
posted @
2008-12-03 10:02 葉澍成 閱讀(1004) |
評論 (2) |
編輯 收藏了解HashMap原理對于日后的緩存機制多少有些認識。在網絡中也有很多方面的帖子,但是很多都是輕描淡寫,很少有把握的比較準確的信息,在這里試著不妨說解一二。
對于HashMap主要以鍵值(key-value)的方式來體現,籠統的說就是采用key值的哈希算法來,外加取余最終獲取索引,而這個索引可以認定是一種地址,既而把相應的value存儲在地址指向內容中。這樣說或許比較概念化,也可能復述不夠清楚,來看列式更加清晰:
int hash=key.hashCode();//------------------------1
int index=hash%table.lenth;//table表示當前對象的長度-----------------------2
其實最終就是這兩個式子決定了值得存儲位置。但是以上兩個表達式還有欠缺。為什么這么說?例如在key.hashCode()后可能存在是一個負整數,你會問:是啊,那這個時候怎么辦呢?所以在這里就需要進一步加強改造式子2了,修改后的:
int index=(hash&Ox7FFFFFFF)%table.lenth;
到這里又迷惑了,為什么上面是這樣的呢?對于先前我們談到在hash有可能產生負數的情況,這里我們使用當前的hash做一個“與”操作,在這里需要和int最大的值相“與”。這樣的話就可以保證數據的統一性,把有符號的數值給“與”掉。而一般這里我們把二進制的數值轉換成16進制的就變成了:Ox7FFFFFFF。(注:與操作的方式為,不同為0,相同為1)。而對于hashCode()的方法一般有:
public int hashCode(){
int hash=0,offset,len=count;
char[] var=value;
for(int i=0;i<len;i++){
h=31*hash+var[offset++];
}
return hash;
}
說道這里大家可能會說,到這里算完事了吧。但是你可曾想到如果數據都采用上面的方式,最終得到的可能index會相同怎么辦呢?如果你想到的話,那恭喜你!又增進一步了,這里就是要說到一個名詞:沖突率。是的就是前面說道的一旦index有相同怎么辦?數據又該如何存放呢,而且這個在數據量非常龐大的時候這個基率更大。這里按照算法需要明確的一點:每個鍵(key)被散列分布到任何一個數組索引的可能性相同,而且不取決于其它鍵分布的位置。這句話怎么理解呢?從概率論的角度,也就是說如果key的個數達到一個極限,每個key分布的機率都是均等的。更進一步就是:即便key1不等于key2也還是可能key1.hashCode()=key2.hashCode()。
對于早期的解決沖突的方法有折疊法(folding),例如我們在做系統的時候有時候會采用部門編號附加到某個單據標號后,這里比如產生一個9~11位的編碼。通過對半折疊做。
現在的策略有:
1. 鍵式散列
2. 開放地址法
在了解這兩個策略前,我們先定義清楚幾個名詞解釋:
threshold[閥值],對象大小的邊界值;
loadFactor[加載因子]=n/m ;其中n代表對象元素個數,m表示當前表的容積最大值
threshold=(int)table.length*loadFactor
清晰了這幾個定義,我們再來看具體的解決方式
鍵式散列:
我們直接看一個實例,這樣就更加清晰它的工作方式,從而避免文字定義。我們這里還是來舉一個圖書編號的例子,下面比如有這樣一些編號:
78938-0000
45678-0001
72678-0002
24678-0001
16678-0001
98678-0003
85678-0002
45232-0004
步驟:
1. 把編號作為key,即:int hash=key.hashCode();
2. int index=hash%表大小;
3. 逐步按順序插入對象中
現在問題出現了:對于編號通過散列算法后很可能產生相同的索引值,意味著存在沖突。
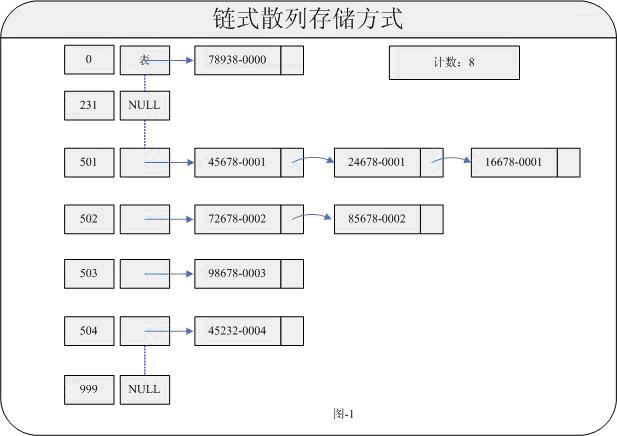
解釋上面的操作:如果對于key.hashCode()產生了沖突(比如途中對于插入24678-0001對于通過哈希算法后可能產生的index或許也是501),既而把相應的前驅有相同的index的對象指向當前引用。這也就是大家認定的單鏈表方式。以此類推…
而這里存在沖突對象的元素放在Entry對象中,Entry具有以下一些屬性:
int hash;
Object key;
Entry next;
對于Entry對象就可以直接追溯到鏈表數據結構體中查閱。
開放地址法:
1. 線性地址探測法:
如何理解這個概念呢,一句話:就是通過算法規則在對象地址N+1中查閱找到為NULL的索引內容。
處理方式:如果index索引與當前的index有沖突,即把當前的索引index+1。如果在index+1已經存在占位現象(index+1的內容不為NULL)試圖接著index+2執行。。。直到找到索引為內容為NULL的為止。這種處理方式也叫:線性地址探測法(offset-of-1)
如果采用線性地址探測法會帶來一個效率的不良影響。現在我們來分析這種方式會帶來哪些不良因素。大家試想下如果一個非常龐大的數據存儲在Map中,假如在某些記錄集中有一些數據非常相似(他們產生的索引在內存的某個塊中非常的密集),也就是說他們產生的索引地址是一個連續數值,而造成數據成塊現象。另一個致命的問題就是在數據刪除后,如果再次查詢可能無法定到下一個連續數字,這個又是一個什么概念呢?例如以下圖片就很好的說明開發地址散列如何把數據按照算法插入到對象中:
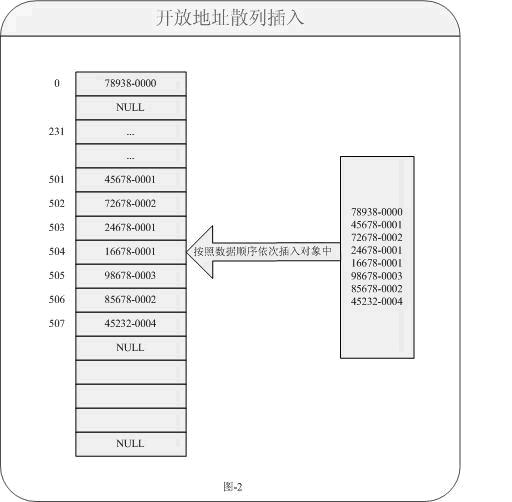
對于上圖的注釋步驟說明:
從數據“78938-0000”開始通過哈希算法按順序依次插入到對象中,例如78938-0000通過換
算得到索引為0,當前所指內容為NULL所以直接插入;45678-0001同樣通過換算得到索引為地址501所指內容,當前內容為NULL所以也可以插入;72678-0002得到索引502所指內容,當前內容為NULL也可以插入;請注意當24678-0001得到索引也為501,當前地址所指內容為45678-0001。即表示當前數據存在沖突,則直接對地址501+1=502所指向內容為72678-0002不為NULL也不允許插入,再次對索引502+1=503所指內容為NULL允許插入。。。依次類推只要對于索引存在沖突現象,則逐次下移位知道索引地址所指為NULL;如果索引不沖突則還是按照算法放入內容。對于這樣的對象是一種插入方式,接下來就是我們的刪除(remove)方法了。按照常理對于刪除,方式基本區別不大。但是現在問題又出現了,如果刪除的某個數據是一個存在沖突索引的內容,帶來后續的問題又會接踵而來。那是什么問題呢?我們還是同樣來看看圖示的描述,對于圖-2中如果刪除(remove)數據24678-0001的方法如下圖所示:
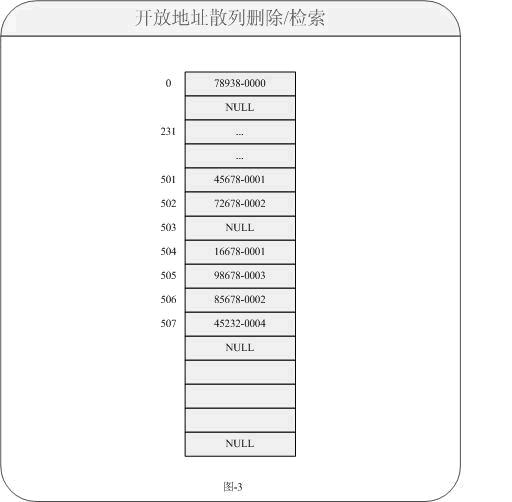
對于我們會想當然的覺得只要把指向數據置為NULL就可以,這樣的做法對于刪除來說當然是沒有問題的。如果再次定位檢索數據16678-0001不會成功,因為這個時候以前的鏈路已經堵上了,但是需要檢索的數據事實上又存在。那我們如何來解決這個問題呢?對于JDK中的Entry類中的方法存在一個:boolean markedForRemoval;它就是一個典型的刪除標志位,對于對象中如果需要刪除時,我們只是對于它做一個“軟刪除”即置一個標志位為true就可以。而插入時,默認狀態為false就可以。這樣的話就變成以下圖所示:
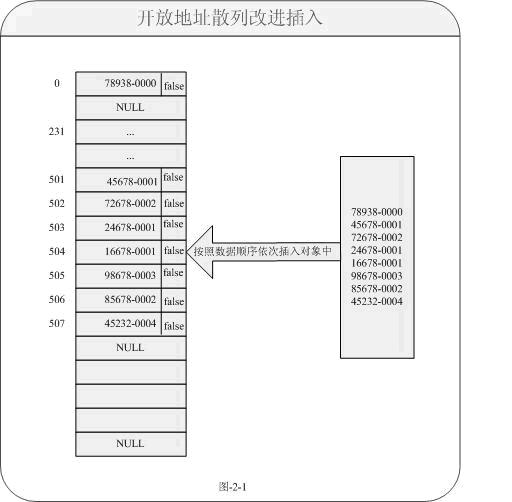
通過以上方式更好的解決沖突地址刪除數據無法檢索其他鏈路數據問題了。
2. 雙散列(余商法)
在了解開放地址散列的時候我們一直在說解決方法,但是大家都知道一個數據結構的完善更多的是需要高效的算法。這當中我們卻沒有涉及到。接下來我們就來看看在開放地址散列中它存在的一些不足以及如何改善這樣的方法,既而達到無論是在方法的解決上還是在算法的復雜度上更加達到高效的方案。
在圖2-1中類似這樣一些數據插入進對象,存在沖突采用不斷移位加一的方式,直到找到不為NULL內容的索引地址。也正是由于這樣一種可能加大了時間上的變慢。大家是否注意到像圖這樣一些數據目前呈現出一種連續索引的插入,而且是一種成塊是的數據。如果數據量非常的龐大,或許這種可能性更大。盡管它解決了沖突,但是對于數據檢索的時間度來說,我們是不敢想象的。所有分布到同一個索引index上的key保持相同的路徑:index,index+1,index+2…依此類推。更加糟糕的是索引鍵值的檢索需要從索引開始查找。正是這樣的原因,對于線性探索法我們需要更進一步的改進。而剛才所描述這種成塊出現的數據也就定義成:簇。而這樣一種現象稱之為:主簇現象。
(主簇:就是沖突處理允許簇加速增長時出現的現象)而開放式地址沖突也是允許主簇現象產生的。那我們如何來避免這種主簇現象呢?這個方式就是我們要來說明的:雙散列解決沖突法了。主要的方式為:
u int hash=key.hasCode();
u int index=(hash&Ox7FFFFFFF)%table.length;
u 按照以上方式得到索引存在沖突,則開始對當前索引移位,而移位方式為:
offset=(hash&Ox7FFFFFFF)/table.length;
u 如果第一次移位還存在同樣的沖突,則繼續:當前沖突索引位置(索引號+余數)%表.length
u 如果存在的余數恰好是表的倍數,則作偏移位置為一下移,依此類推
這樣雙散列沖突處理就避免了主簇現象。至于HashSet的原理基本和它是一致的,這里不再復述。在這里其實還是主要說了一些簡單的解決方式,而且都是在一些具體參數滿足條件下的說明,像一旦數據超過初始值該需要rehash,加載因子一旦大于1.0是何種情況等等。還有很多問題都可以值得我們更加進一步討論的,比如:在java.util.HashMap中的加載因子為什么會是0.75,而它默認的初始大小為什么又是16等等這些問題都還值得說明。要說明這些問題可能又需要更加詳盡的說明清楚。
posted @
2008-09-15 21:53 葉澍成 閱讀(3767) |
評論 (6) |
編輯 收藏前幾天和電信下屬分公司的部門負責人聊天有感,這個無意就讓我自問一些問題:
1.需求分析人員的職責應該是什么
2.架構師的職責是什么
3.需求分析人員是否能等同于架構師
4.如果不是,那他們是一種粘合關系
5.如果是,是一個什么承接關系
而從這個部門負責人聊天感覺他的思路就是:先要有需求分析,才能有架構設計;沒有好的需求分析,再好的架構設計都等于垃圾
不過從他的理解程度,顯然他對架構和框架混為一談。
posted @
2008-08-23 18:32 葉澍成 閱讀(246) |
評論 (1) |
編輯 收藏