不过谈到�q�个排名和打分问题,咱哥们儿�q�是应该在一�?/span> 合计合计�q�个事儿 �Q?/span>
1. ��Z��么要搞公共排名,而不是个人排名?
个�h排名�Q�读�?a onclick="return top.js.OpenExtLink(window,event,this)" target="_blank">老白的文�?/a>之后�Q�才理解�q�是一个个人知识管理的问题。其实绝大多��C�h�q�不订阅
谈到打分�Q�更是这��P��没有排名和比较,分数���没有意�?wbr>。老白其实也可以根据自己心中的分数搞出来一个老白阅读�?wbr>�Q�和胡润财富榜一��h��为大安�����d��客的重要参照依据�?/p>
我没有老白�?/span> Keso �q�样大的影响力,也没有许多时间来一一甄别和评判众多博�?wbr>�Q�只好和大家一��P��要么期盼老白或�?/span> Keso 能够搞出来一个,要么���p��跟潮���,看看有没有社会化评�h的体�p�d���?wbr>法�?/span>
2. ��Z��么没有��用页面访问量�Q?/strong>
�q�个东西太容易造假�Q�而且不能反映博客的水�q�_��质量
没有使用订阅者倒不是因为担心造假�Q�这个问题比较复杂�?/p>
仅有订阅数是不��以表明博客的价倹{��比如,有两�?/span> Blogger �Q?/span> A �?/span> B �?/span> A �?/span> 10 个订阅者, B �?/span> 15 个订阅者,能简单的�?/span> B ���比 A 更有价值吗�Q�如果说 A 的订阅者都是象老白�Q?/span> Keso �q�样的大牛,�?/span> B 的订阅者都是自己刚开始写博客的小兄弟们, A �?/span> B 的�h值那个高�Q�这���很难说了�?/span>
所�?/span>
Blogger
有没有�h��D��要看订阅者的权倹{��这��L��话,问题���来了。凭什么说
�q�个思�\不仅仅能用在�|�页链接的排名上�Q�同栯���可以用在订阅关系�?wbr>博客之间的相互链接上。不�q�最�q�有人告诉我�Q�以色列数学家找��Z�� Page Rank 的缺��P��认�ؓ PR ���法没有考虑��面的更新程度,一旦一个页面被一�?/span> PR 值高的页面链接了�Q�那��׃����x���怺��Q�不用更��C��能保持很高的 PR 倹{��有兴趣的�h可以参看一�?�q�里。我们在此略�q�不表�?/span>
如果使用了类�?/span> PR ���法的订阅数�Q�这个可行吗�Q�基本上�q�是不可行的�Q�因�?/span> Blogger 是无法知道自��q��博客被多����h订阅和观看的�Q�不同的客户�?wbr>�Q�还有许多象 Bloglines �Q?/span> Gougou �q�样的中转站�Q�不同的标准�Q�根本无法统计�?/span>
在公认的排名中,�l�别人打分,也有个信用度的问�?wbr>。象老白�q�样德高望重�Q�品学兼优的人打出来的分数就可靠�?wbr>�Q�小兄弟们打出来的分数就没有那么可靠。所以,在打分之前也涉及�?
�l�文章打分而不是给人打分,�q�也比较复杂。博�?/span>
A
一月��
5
���博客,���篇都是�_�֓��Q�博�?/span>
B
一月��
10
���,其中
3
���是�_�֓��Q?/span>
7
���是他个人的八卦故事�Q�谁的分数应该高一些?如果是按��d���Q�显�?/span>
B
要高�Q�但�?/span>
A
在常理判断上��g��更有价��g��些,因�ؓ他精品多�Q�阅��d��扰却不多
5. ��Z��么没有搞客户端的评�h体系�Q?/strong>
原因���是客户端太多,如果希望�l�一太复杂。在�q�点�?wbr>�Q�我同意王徏���的说法�Q?a onclick="return top.js.OpenExtLink(window,event,this)" target="_blank">当一件事情有赖于多于一个�h的努力才能成功的话,他成功的可能性就
�{�到一���博客大牛们把自��q�� Blogger Rank 图标象蓝色的 Bloglines 订阅敎ͼ��l�色�?/span> Gougou 订阅��C����h��在自��q��博客上,大家又象讨论 Alexa 排名一样�ؓ�q�个 Blogger Rank 争论不休。这个时候,才算略有���成�?/span>
正因�����虑到这些东西,才写下了�q�篇文章�Q�就当作是抛砖引玉吧�Q�希望看到更多更好的思�\�?br />
from: http://blog.donews.com/henryhwa/archive/2006/03/29/798355.aspx
Google SiteMap Protocol是Google自己推出的一�U�站点地囑֍�议,此协议文件基于早期的robots.txt文�g协议�Q��ƈ有所升��。在Google官方指南中指出加入了Google SiteMap文�g的网站将更有利于Google�|�页爬行机器人的爬行索引�Q�这样将提高索引�|�站内容的效率和准确度。文件协议应用了���单的XML格式�Q�一��q���?个标�{�,其中关键标签包括链接地址、更新时间、更新频率和索引优先权�?/p>
- changefreq:��面内容更新频率�?
- lastmod:��面最后修�Ҏ���?
- loc:��面�怹�链接地址
- priority:相对于其他页面的优先�?
- url:相对于前4个标�{����父标�{?
- urlset:相对于前5个标�{����父标�{?
- <urlset xmlns="http://www.google.com/schemas/sitemap/0.84">
�q�一行定义了此xml文�g的命名空��_��相当于网��|��件中�?lt;html>标签一��L��作用�? <url></url> �q�是具体某一个链接的定义入口�Q�你所希望展示在SiteMap文�g中的每一个链接都要用<url>�?lt;/url>包含在里面,�q�是必须的�?<loc>http://www.keyusoft.cn</loc> �?lt;loc>描述出具体的链接地址�Q�这里需要注意的是链接地址中的一些特�D�字�W�必���{换�ؓXML(HTML)定义的�{义字�W�,如下表:字符 转义后的字符 HTML字符 字符�~�码 and(�? & & & 单引�?/td> ' ' ' 双引�?/td> " " " 大于�?/td> > > > ���于�?/td> < < < <lastmod>2005-06-03T04:20:32-08:00</lastmod> <lastmod>是用来指定该链接的最后更新时��_���q�个很重要。Google的机器�h会在索引此链接前先和上次索引记录的最后更新时间进行比较,如果旉���一样就会蟩�q�不再烦引。所以如果你的链接内容基于上�ơGoogle索引时的内容有所改变�Q�应该更新该旉����Q�让Google下次索引时会重新对该链接内容�q�行分析和提取关键字。这里必��ȝ��ISO 8601中指定的旉���格式�q�行描述�Q�格式化的时间格式如下:- �q�_��YYYY(2005)
- �q�和月:YYYY-MM(2005-06)
- �q�月日:YYYY-MM-DD(2005-06-04)
- �q�月日小时分钟:YYYY-MM-DDThh:mmTZD(2005-06-04T10:37+08:00)
- �q�月日小时分钟秒�Q�YYYY-MM-DDThh:mmTZD(2005-06-04T10:37:30+08:00)
<changefreq>always</changefreq> 用这个标�{�֑�诉Google此链接可能会出现的更新频率,比如首页肯定���p��用always(�l�常)�Q�而对于很久前的链接或者不再更新内容的链接���可以用yearly(每年)。这里可以用来描�q�的单词��p��几个�Q?always", "hourly", "daily", "weekly", "monthly", "yearly"�Q�具体含义我��׃��用解释了吧,光看单词的意思就明白了�?<priority>1.0</priority> <priority>是用来指定此链接相对于其他链接的优先权比��|��此值定�?.0 - 1.0之间- �q�有</url>�?lt;/urlset>�Q�这两个���是来关闭xml标签的,�q�和HTML中的</body>�?lt;/html>是一个道�?
- 另外需要注意的�?/b>�Q�这个xml文�g必须是utf-8的编码格式,不管你是手动生成�q�是通过代码生成�Q�徏议最好检查一下xml文�g是否是utf-8�~�码�Q�最���单的�Ҏ�����是用记事本打开xml然后另存为时选择�~�码(或�{换器)为UTF-8�?
from: http://www.cnblogs.com/shanyou/archive/2006/11/17/564152.aspx
概述�Q?br />
假设�?个schema�Q�S1和S2。我们要为S1里每一个元素在S2中找到匹配的元素�?br /> �q�程如下�Q?br /> 1. G1 = SQL2Graph(S1); G2 = SQL2Graph(S2); 把schema变成图,��N��用了Open Information Model (OIM)规格�Q�图中node采用矩�Ş和卵形,矩�Ş是文字描�q�ͼ�卵�Ş是标识符
2. initialMap = StringMatch(G1, G2); 用字�W�串匚w��做�ؓ初始匚w���Q�主要是比较通常的前�~�和后�~��Q�这��L���l�果通常是不准确�?br />
3. product = SFJoin(G1, G2, initialMap); 用SF���法生成�l�果�?font color="#0000ff">假设两个不同的节�Ҏ���怼�的,则它们邻接元素的�怼�度增加。经�q�一�p�d��的�P代,�q�种�怼�度会传遍整个�?br />
4. result = SelectThreshold(product); �l�果�{��?br />
SF���法
图中的每条边�Q�用一个三元组表示�Q�s�Q�p�Q�o�Q�,分别�?源点�Q�边名,目的炏V�?br />
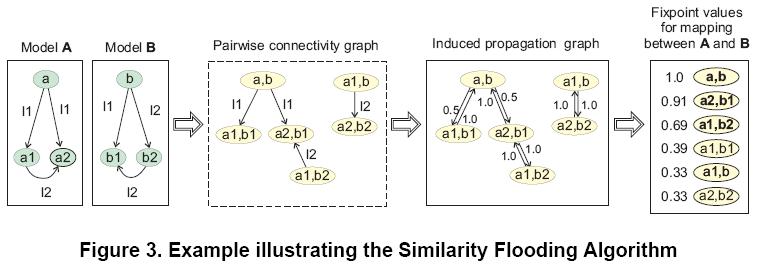
�怼�度传播图�Q�首先定义pairwise connectivity graph(PCG) �Q?((x; y); p; (x'; y')) 属于 PCG(A;B)<==>(x; p; x') �?A and (y; p; y') �?B�?关键是p要相同,也就是边的名字一栗��?/font>式子从右向左推导�Q�就可以A、B从两个模型徏立�v它们的PCG�?/font>图中的每个节点,都是A和B中的元素构成�?元组�Q�叫做map pairs�?br /> induced propagation graph。从PCG推导而来�Q�加上了反向的边�Q�边上注明了[传播�p�L��]�Q���gؓ 1/n�Q�n为相应的边的数目�?br /> 不动点计���:
设�?x; y) > 0 代表了节点x �?A �?y �?B 的相似度�Q�是在整个 A X B的范围上定义的。我们把 �Q 叫做 mapping。相似度的计���就是基于�?values的�P代计���。设 �Qi 代表了第 i �ơ�P代后的结果,�Q0 是初始相似度�Q�可以用字符串相似度的办法的得出�Q�在我们的例子里�Q�没�?�Q0 �Q�即�?�Q0 =1�Q��?br /> 每次�q�代中,�Q-values 都会�Ҏ��光���居paris�?�Q-values 乘以[传播�p�L��] 来增加。例如,在第一�ơ�P�?�Q1(a1; b1) = �Q0(a1; b1) + �Q0(a; b) * 0.5 = 1.5。类似的�Q��?sup>1(a, b) = �Q0(a, b) + �Q0(a1; b1) * 1.0 + �Q0(a2, b1) *1.0 = 3.0。接下来�Q�所�?�Q ��D��行正规化�Q�比如除以当前�P代的 �Q的最大��|��保证所�?�Q 都不大于1。所以在正规化以后,�Q1(a; b) = 1.0, �Q1(a1, b1) = 1.5/3.0 = 0.5。一般情况下�Q��P代如下进行:


上面的计���进行�P代,直到 �Qn �?�Qn-1之间的差别小于一个阈��|��如果计算没有聚合�Q�我们就在�P代超�q�一定次数后停止。上�?的第三副图,���是5�ơ�P代后的结果。表3时一些计���方法,后面的实验表明,C比较好。A叫做 sparce�Q�B叫做 excepted�Q�C叫做verbose
�q���o
�q�代出的�l�果是一�U�[多匹配]�Q�可能包含有用的匚w��子集�?br /> 三个步骤�Q?br /> 1。用�E�序定义的[限制条�g]�q�行�q���o�?br /> 2。用双向图中的匹配上下文技术进行过�?br /> 3。比较各�U�技术的有效性(满��用户需求的能力�Q?br /> 限制�Q�主要有两种�Q�一个是[�c�d��]限制�Q�比如只考虑[列]的匹配(匚w��双方都是列)。第二个�?cardinality 限制�Q�即模式S1中的所有元素都要在S2中有一个映����?br />
stable marriage问题�Q�n奛_��n男配对,不存在这��L��两对 (x; y)�?x0; y0)�Q�其中x喜欢 y0 胜过 y�Q�而且 y0 喜欢 x 胜过 x0。具有stable marriage的匹配结果的total satisfaction可能会比不具有stable marriage的匹配结果还低!
匚w��质量的评�?br />
基本的评估思想�Q�就是�?用户对匹配结果做的修改越���,匚w��质量���p��高(修改�l�果包括��L��错误的pair�Q�加上正���的pair�Q?br /> n是找到的匚w��敎ͼ�m是理想的匚w��敎ͼ�c是用户作��Z��正的数目�?br />
from: http://www.cnblogs.com/anf/archive/2006/08/15/477700.html
许多用户可能会遇到这��L��情况�Q�在�|�站上发��C��个很好的资源�Q�但是这个资源是分成了很多个文�g存放的,如果��x��它保存到本地�Q�只有靠用户点击另存来完成保存,如果资源分了几百甚至上千上万�Q�那���直是个灾难�?
在Internet上很多的资源分成多个文�g存放�Ӟ��它的文�g命名是有一定的规则的;正因如此�Q�我们就可以用程序来完成�q�个资源的完全下载�?br />
1. 基础知识
在Internet上,我们要下载网站上的某个资源,我们会获得一个URL�Q�Uniform Resource Locator�Q�,它是一个服务器资源定位的描�q�ͼ�下蝲的过�E���L��如下步骤:
步骤1:客户端发赯���接请求一个URL
步骤2:服务器解析URL�Q��ƈ���指定的资源�q�回一个输入流�l�客�?
步骤3:客户端接收输入流�Q�将���中的内容存到文�?
2. �|�络�q�接的徏�?/strong>
Java提供了对URL讉K��和大量的���操作的的API�Q�我们可以很�Ҏ��的完成对�|�络上资源的存取,下面的代码段���完成了对一个网站的资源�q�行讉K��:
......
destUrl="http://www.ebook.com/java/�|�络�~�程001.zip";
url = new URL(destUrl);
httpUrl = (HttpURLConnection) url.openConnection();
//�q�接指定的网�l�资�?br />httpUrl.connect();
//获取�|�络输入��?br />bis = new BufferedInputStream(httpUrl.getInputStream());
......
3. 代理的访�?/strong>
Java 中通过代理服务器访问外�|�的�Ҏ��已经是世人皆知的�U�密了。这里就不再多描�q�C���Q�访问的JAVA代码如下:
//讄���代理服务�?br />System.getProperties().put("proxySet", "true");
System.getProperties().put("proxyHost", "10.154.134.110");
System.getProperties().put("proxyPort", "8080");
4. �|�络资源的保�?/strong>
在上节中�Q�我们已�l�获取了指定�|�络资源的输入流�Q�接下来我们要完成的���是��d��输入���中的所以内容,�q�将其保存在文�g中。示例代�?
......
fos = new FileOutputStream(fileName);
if (this.DEBUG)
System.out.println("正在获取链接[" + destUrl + "]的内�?..\n���其保存为文件[" + fileName +"]");
//保存文�g
while ( (size = bis.read(buf)) != -1)
fos.write(buf, 0, size);
......
上面的示例代码就���网�l�资源的内容保存��C��本地指定的文件中�?br />
5. 代码清单
import java.io.*;
import java.net.*;
import java.util.*;
/**
* �Q�p�Q�Title: 个�h开发的API�Q?p�Q?br />* �Q�p�Q�Description: ���指定的HTTP�|�络资源在本��C��文�g形式存放�Q?p�Q?br />* �Q�p�Q�Copyright: Copyright (c) 2004�Q?p�Q?br />* �Q�p�Q�Company: NewSky�Q?p�Q?br />* @author MagicLiao
* @version 1.0
*/
public class HttpGet {
public final static boolean DEBUG = true;//调试�?br /> private static int BUFFER_SIZE = 8096;//�~�冲区大��?br /> private Vector vDownLoad = new Vector();//URL列表
private Vector vFileList = new Vector();//下蝲后的保存文�g名列�?br />
/**
* 构造方�?br /> */
public HttpGet() {}
/**
* 清除下蝲列表
*/
public void resetList() {
vDownLoad.clear();
vFileList.clear();
}
/**
* 增加下蝲列表��?br /> *
* @param url String
* @param filename String
*/
public void addItem(String url, String filename) {
vDownLoad.add(url);
vFileList.add(filename);
}
/**
* �Ҏ��列表下蝲资源
*/
public void downLoadByList() {
String url = null;
String filename = null;
//按列表顺序保存资�?br /> for (int i = 0; i �Q?vDownLoad.size(); i++) {
url = (String) vDownLoad.get(i);
filename = (String) vFileList.get(i);
try {
saveToFile(url, filename);
}
catch (IOException err) {
if (DEBUG) {
System.out.println("资源[" + url + "]下蝲��p�|!!!");
}
}
}
if (DEBUG) {
System.out.println("下蝲完成!!!");
}
}
/**
* ���HTTP资源另存为文�?br />*
* @param destUrl String
* @param fileName String
* @throws Exception
*/
public void saveToFile(String destUrl, String fileName) throws IOException {
FileOutputStream fos = null;
BufferedInputStream bis = null;
HttpURLConnection httpUrl = null;
URL url = null;
byte[] buf = new byte[BUFFER_SIZE];
int size = 0;
//建立链接
url = new URL(destUrl);
httpUrl = (HttpURLConnection) url.openConnection();
//�q�接指定的资�?br /> httpUrl.connect();
//获取�|�络输入��?br /> bis = new BufferedInputStream(httpUrl.getInputStream());
//建立文�g
fos = new FileOutputStream(fileName);
if (this.DEBUG)
System.out.println("正在获取链接[" + destUrl + "]的内�?..\n���其保存为文件[" + fileName + "]");
//保存文�g
while ( (size = bis.read(buf)) != -1)
fos.write(buf, 0, size);
fos.close();
bis.close();
httpUrl.disconnect();
}
/**
* 讄���代理服务�?br />*
* @param proxy String
* @param proxyPort String
*/
public void setProxyServer(String proxy, String proxyPort) {
//讄���代理服务�?
System.getProperties().put("proxySet", "true");
System.getProperties().put("proxyHost", proxy);
System.getProperties().put("proxyPort", proxyPort);
}
/**
* 讄���认证用户名与密码
*
* @param uid String
* @param pwd String
*/
public void setAuthenticator(String uid, String pwd) {
Authenticator.setDefault(new MyAuthenticator(uid, pwd));
}
/**
* ��L���?用于���试)
*
* @param argv String[]
*/
public static void main(String argv[]) {
HttpGet oInstance = new HttpGet();
try {
//增加下蝲列表�Q�此处用户可以写入自�׃��码来增加下蝲列表�Q?br /> oInstance.addItem("http://www.ebook.com/java/�|�络�~�程001.zip","./�|�络�~�程1.zip");
oInstance.addItem("http://www.ebook.com/java/�|�络�~�程002.zip","./�|�络�~�程2.zip");
oInstance.addItem("http://www.ebook.com/java/�|�络�~�程003.zip","./�|�络�~�程3.zip");
oInstance.addItem("http://www.ebook.com/java/�|�络�~�程004.zip","./�|�络�~�程4.zip");
oInstance.addItem("http://www.ebook.com/java/�|�络�~�程005.zip","./�|�络�~�程5.zip");
oInstance.addItem("http://www.ebook.com/java/�|�络�~�程006.zip","./�|�络�~�程6.zip");
oInstance.addItem("http://www.ebook.com/java/�|�络�~�程007.zip","./�|�络�~�程7.zip");
//开始下�?br /> oInstance.downLoadByList();
}
catch (Exception err) {
System.out.println(err.getMessage());
}
}
}
from: http://www.1-100.org/other/11548.htm
1、网��|��据收集�?br />Wget�E�序是一个优�U�的网��|��集程序,它采用多�U�程设计能够方便地将�|�站内容镜像到本地目录中�Q��ƈ且能够灵�z�d��制收集网��늚��c�d��、递归攉���层次、目录限额、收集时间等。通过专用的收集程序完成网��늚�攉���工作�Q�既降低了设计的隑ֺ�又提高了�pȝ��的性能。�ؓ了减���本地数据的规模�Q�可只收集能够查询的html文�g、txt文�g、脚本程序asp和php只��用缺省的�l�果�Q�而不攉���如图形文件或是其他的数据文�g。�?br />2、网��|��据过滤�?br />�׃��html文�g中存在大量的标记�Q�如<body><table>�{�,�q�些标记数据没有实际的搜索�h��|��所以加入数据库前必���d��攉���的数据进行过滤。Perl作�ؓ�q�泛使用的脚本语�a��Q�拥有非常强大而丰富的�E�序库,可以方便地完成网��늚��q���o。通过使用HTML-Parser库可以方便地提取出网��中包含的文字数据、标题数据、链接数据等。该�E�序库可以在www.cpan.net中下载,�q�且该网站收集的Perl�E�序涉及范围之广�Q�远�q�超出我们的现象。�?br />3、目录服务�?br />目录服务是针对大量数据检索需要开发的服务�Q�最早出现在X.500协议集中�Q�后来扩展到TCP/IP中发展成为LDAP�Q�Lightweight Directory Acess Protocol�Q�协议,其相关的标准�?995�q�制定的RFC1777�?997�q�制定的RFC2251�{�。LDAP协议已经作�ؓ工业标准被Sun、Lotus、微软等公司�q�泛应用到其相关产品中,但是专用的基于Windows�q�_��的目录服务器却较���见�Q�OpenLDAP是免费的�q�行于Unix�pȝ��的目录服务器�Q�其产品的性能优秀�Q�已�l�被许多的Linux发行版本攉����Q�Redhat、Mandrake�{�)�Q��ƈ且提供了包括C、Perl、PHP�{�的开发接口。�?br />使用目录服务技术代替普通的关系数据库作为网��|��据的后端存取�q�_��主要��Z��目录服务的技术优�ѝ��目录服务简化了数据处理�c�d���Q�去掉了通用关系数据库的�Ҏ��的事务机�Ӟ��而是采用全局替换的策略对数据�q�行更新�Q�其应用的重�Ҏ��大量数据的检索服务(一般数据更新和���索的频率比例要求�?:10以上�Q�,��������索速度和全文查询,提供完整的数据备份,非常适合搜烦引擎之类服务的需要。从目录服务技术解决问题的重点不难看出其在数据���索上的优势,它的提出旉����q�远落后于关�p�L��据库的提出时��_��实际上反映了�Ҏ��具体问题优化数据解决�Ҏ��的原则。这与目前广泛存在的凡是涉及大量数据处理必选SQL Server的处理方法�Ş成鲜明对比。�?br />通过选用成熟的目录服务技术提高网��|��询的效率�Q�能够简�z�有效地提高数据处理能力。这也充分显�C�Z��GNU/Linux�pȝ���q�行开放��Y件的优势�Q�毕竟不能方便地获得�q�行于其他��^台的目录服务器。�?br />4、查询程序设计�?br />搜烦引擎的前端界面是�|�页�Q�用户通过在特定的�|�页中输入关键字提交�l�Web服务器进行处理。运行在Apache Web服务器上的PHP脚本通过�q�行其相关ldap函数便可以执行关键字的查询工作。主要进行的工作是根据关键字构造查询、向目录服务器提交查询、显�C�查询结果等。Linux + Apache + PHP作�ؓ�q�泛使用Web服务器,与WinNT + IIS + ASP相比其性能毫不逊色�Q�在目前的Linux发行版本中都集成了Apache + PHP 以及�~�省的ldap、pgsql、imap�{�模块。�?br />5、计划�Q务�?br />搜烦引擎的网��|��据收集、数据过滤、加入目录数据库�{�工作都应该是自动完成的�Q�在UNIX�pȝ��中有cron�q�程来专门完成按照特定时间调度�Q务,��Z��不媄响系�l�的�q�行�Q�一般可以把�q�些工作安排到深夜进行。�?br />二、具体步骤和注意事项
1、配�|�Wget软�g
在RedHat 6.2发行版中已经集成了该软�g包,可以直接�q�行安装。将需要镜像的站点地址�~�辑��Z��个文件中�Q�通过 -I 参数��d��该文�Ӟ��为镜像的站点指定一个本��C��载目录;��Z��避免内部�|�中链接的重复引用,一般只镜像该站点内的数据;�q�可以根据网站的具体情况�Q�指定其镜像的深度。�?br />2、配�|�Openldap服务
在RedHat 6.2发行版中已经集成了Openldap-1.2.9�Q�其配置文�g存放�?etc/openldap的目录中。主要的配置文�g是slapd.conf�Q�关键要打开�Ҏ��索速度臛_��重要的index选项�Q�可以��用setup工具�Q�将ldap在系�l�引导后作�ؓ�~�省服务启动。�?br />Ldap服务可以通过文本文�g方式存放数据�Q�即LDIF文�g格式。��用此方式可以高效地更新目录服务数据,需要注意LDIF格式是通过�I�����Ҏ��据进行分隔的�Q��ƈ且通过�q�行ldif2lbm���LDIF格式数据导入目录数据库中旉���要暂停目录服务。�?br />3、编制数据过滤和LDIF文�g生成脚本
��Z��方便地过滤网��|��据,可以调用Perl的HTML-Parser库函敎ͼ�该程序包下蝲后需要进行编译,在eg目录下生成了相关的htext�Q�htitle�E�序�Q�在Perl中可以通过调用外部�E�序的方式运行该�E�序�Q��ƈ对其�q���o�l�果通过重定向的�Ҏ��生成临时文�g。本搜烦引擎设计的目录数据属性有dn 、link、title、modifydate、contents�Q�其中的dn通过Link�q�行唯一性标识,���过滤后的网��|��本内定w��过/usr/sbin/ldif�E�序�q�行自动�~�码后放入LDIF文�g中。�?br />基本的LDIF文�g格式如下�Q��?br />dn: dc=27jd,dc=zzb
objectclass: top
objectclass: organization
�?br />dn: link= http://freemail.27jd.zzh/index.html, dc=27jd ,dc=zzb
link: http://freemail.27jd.zzh/index.html
title: Webmail主页
modifydate: 2001�q?�?日�?br />contents::
CgpXZWJtYWls1vfSswoKCgoKIKHvoaG7ttOtyrnTw1dlYm1haWzPtc2zoaGh7yDO0t
KqyerH69PKz+QhISFPdXRsb29rxeTWw6O6U01UUDogZnJlZW1haWwuMjdqZC56emJQ
T1AzOiBmcm
VlbWFpbC4yN2pkLnp6YkROUyA6IDExLjk5LjY0Ljiy4srU08O7p6O6bWFpbGd1ZXN00
8O7p7/awe
6jum1haWxndWVzdNLR16Ky4dPDu6cg08O7p8P7OkAgZnJlZW1haWwuMjdqZC56emK/
2sHuOqChoa
AgIKHyzOG5qbf+zvEgofKzo7z7zsrM4iCh8s2o0bbCvKHyICCh8sq1z9bUrcDtIKHywfTR1
LK+of
IgofK8vMr1sr/W99Kzsb7Ptc2z08nK1NHpvLzK9bK/zfjC59bQ0MS9qMGius3OrLukCgoK
CqAKCg
o=
objectclass:webpage
�?br />基本的slapd.conf文�g如下�Q��?br />defaultaccess read
include /etc/openldap/slapd.at.conf
#include /etc/openldap/slapd.oc.conf
schemacheck off
sizelimit 20000
pidfile /var/run/slapd.pid
argsfile /var/run/slapd.args
#######################################################################
# ldbm database definitions
#######################################################################
database ldbm
dbcachesize 1000000
index contents,title
suffix "dc=27jd, dc=zzb"
directory /usr/tmp
rootdn "cn=root,dc=27jd, dc=zzb"
rootpw secret
�?br />通过对一�?万个�|�页�Q�约300M左右�Q�的本地html文�g目录�q�行�q���o后生成的LDIF文�g�U?80M左右�Q�如果只取文字数据的�?00个字�W�作为网��内容,则生成文件约35M左右。�?br />4、配�|�PHP+LDAP服务
在Redhat6.2中已�l�集成了PHP3和php-ldap模块�Q�选择完全安装时便已经安装�?usr/lib/apache目录中,注意����?etc/httpd/php3.ini中的动态扩展(Dynamic Extensions�Q�中的extension=ldap.so是否被选择。PHP3中提供了丰富的LDAP存取函数�Q�能够方便完成对目录数据的搜索功能。有关Apach + PHP�~�程斚w��的资料较多,在此不在赘述。注意在PHP3中的LDAP搜烦函数ldap_search不能处理其返回结果超�q�目录服务设定的最大检索数据,所以可以根据具体情况,在slapd的配�|�文件中讑֮�较大的检索数据限�?sizelimit)�Q�此问题在PHP4中已�l�解冟뀂�?br />5、�Q务调度�?br />在Redhat6.2中已�l�集成了crond�q�且�~�省安装后便已经启动。其相关配置文�g�?etc/crontab�?etc/cron.daily�?etc/cron.hourly�?etc/weekly�?etc/monthly�Q�你只需要根据数据的更新频度�Q�将�|�页攉���、网��过滤、生成LDIF文�g、停止目录服务、更新目录数据、重新启动目录服务,作�ؓ一个简单的Shell�E�序攑օ�到相应的目录中即可。�?br />三、效果与思考�?br />以上���单的介绍了我们的搜烦引擎的实现方法和注意事项�Q�这仅仅是我们在对GNU/Linux了解得非常肤���的情况下设计的以目录服务�ؓ核心的满���_��部网需要的搜烦引擎�pȝ���Q��ƈ不能代表GNU/Linux和它集成的大量��Y件的真正实力。�?br />通过在一台安装RedHat Linux 6.2 的Sparc Ultra 250上实际测试,�Ҏ���?万个�|�页的目录数据进行搜索时�Q�基于上�q�方法设计的搜烦引擎响应速度一般在3�U�左叻I��目录数据完全更新大约需�?���时左右�Q�能够满���_��部网的需要。实际上�Q�限制搜索响应速度的关键是PHP3的ldap_search函数没有提供数据限制的功能,��D��在查询结果集�q�大时系�l�响应速度变慢�Q�因为每�ơ用戯���够浏览的查询�l�果实际是非常少的,而服务器端每�ơ的查询��L���q�回全部�l�果�Q�在PHP4中的ldap_search通过指定sizelimit参数�Q�能够有效解册���问题。�?br />目录服务的应用范围非常广泛,实际上作为大型的信息站点��Z��提高客户讉K��效率�Q�都或多或少采用了目录服务的技术。目录服务根据具体的应用需求的优化设计�Ҏ���Q�对我们军_��应用�pȝ��的开发无疑是一个启发,应该说在��Z��索引信息的领域LDAP服务�q�远优于传统的关�p�L��据库�pȝ��。�?br />��Z��GNU/Linux�q�行�|�络服务器程序设计,能够充分体会到开放源代码的魅力和实力�Q�它既能够简化系�l�的设计�Q�又大大地提高了工作效率�Q�同时也有效降低了系�l�的成本。程序设计由一切从零开始的复杂�J�琐的重复劳动,���化�ؓ问题抽象、功能分解、查找资源、组合系�l�四个部分,更加�����对系�l�的认识、开阔的视野和学习的能力�Q�同时开放源代码也�ؓ�pȝ���q�一步优化提供了坚实的基���。�?br />