JDK 的 HashMap 中使用了一個 hash 方法來做 bit shifting,在注釋中說明是為了防止一些實現(xiàn)比較差的hashCode() 方法,請問原理是什么?JDK 的源碼參見:GrepCode: java.util.HashMap (.java)
/**
* Applies a supplemental hash function to a given hashCode, which
* defends against poor quality hash functions. This is critical
* because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
PS:網(wǎng)上看見有人說作者本人說原理需要參見圣經(jīng)《計算機(jī)程序設(shè)計藝術(shù)》的 Vol.3 里頭的介紹,不過木有看過神書,求達(dá)人介紹
這段代碼叫“擾動函數(shù)”。
題主貼的是Java 7的HashMap的源碼,Java 8中這步已經(jīng)簡化了,只做一次16位右位移異或混合,而不是四次,但原理是不變的。下面以Java 8的源碼為例解釋,
//Java 8中的散列值優(yōu)化函數(shù)staticfinalinthash(Objectkey){inth;return(key==null)?0:(h=key.hashCode())^(h>>>16);//key.hashCode()為哈希算法,返回初始哈希值}
大家都知道上面代碼里的key.hashCode()函數(shù)調(diào)用的是key鍵值類型自帶的哈希函數(shù),返回int型散列值。理論上散列值是一個int型,如果直接拿散列值作為下標(biāo)訪問HashMap主數(shù)組的話,考慮到2進(jìn)制32位帶符號的int表值范圍從-2147483648到2147483648。前后加起來大概40億的映射空間。只要哈希函數(shù)映射得比較均勻松散,一般應(yīng)用是很難出現(xiàn)碰撞的。但問題是一個40億長度的數(shù)組,內(nèi)存是放不下的。你想,HashMap擴(kuò)容之前的數(shù)組初始大小才16。所以這個散列值是不能直接拿來用的。用之前還要先做對數(shù)組的長度取模運算,得到的余數(shù)才能用來訪問數(shù)組下標(biāo)。源碼中模運算是在這個indexFor( )函數(shù)里完成的。
bucketIndex = indexFor(hash, table.length);indexFor的代碼也很簡單,就是把散列值和數(shù)組長度做一個"與"操作,
static int indexFor(int h, int length) { return h & (length-1);}順便說一下,這也正好解釋了為什么HashMap的數(shù)組長度要取2的整次冪。因為這樣(數(shù)組長度-1)正好相當(dāng)于一個“低位掩碼”。“與”操作的結(jié)果就是散列值的高位全部歸零,只保留低位值,用來做數(shù)組下標(biāo)訪問。以初始長度16為例,16-1=15。2進(jìn)制表示是00000000 00000000 00001111。和某散列值做“與”操作如下,結(jié)果就是截取了最低的四位值。
10100101 11000100 00100101& 00000000 00000000 00001111---------------------------------- 00000000 00000000 00000101 //高位全部歸零,只保留末四位
但這時候問題就來了,這樣就算我的散列值分布再松散,要是只取最后幾位的話,碰撞也會很嚴(yán)重。更要命的是如果散列本身做得不好,分布上成等差數(shù)列的漏洞,恰好使最后幾個低位呈現(xiàn)規(guī)律性重復(fù),就無比蛋疼。這時候“擾動函數(shù)”的價值就體現(xiàn)出來了,說到這里大家應(yīng)該猜出來了。看下面這個圖,
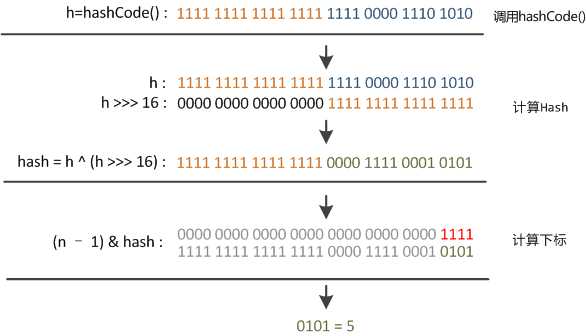
右位移16位,正好是32bit的一半,自己的高半?yún)^(qū)和低半?yún)^(qū)做異或,就是為了混合原始哈希碼的高位和低位,以此來加大低位的隨機(jī)性。而且混合后的低位摻雜了高位的部分特征,這樣高位的信息也被變相保留下來。最后我們來看一下PeterLawley的一篇專欄文章《An introduction to optimising a hashing strategy》里的的一個實驗:他隨機(jī)選取了352個字符串,在他們散列值完全沒有沖突的前提下,對它們做低位掩碼,取數(shù)組下標(biāo)。
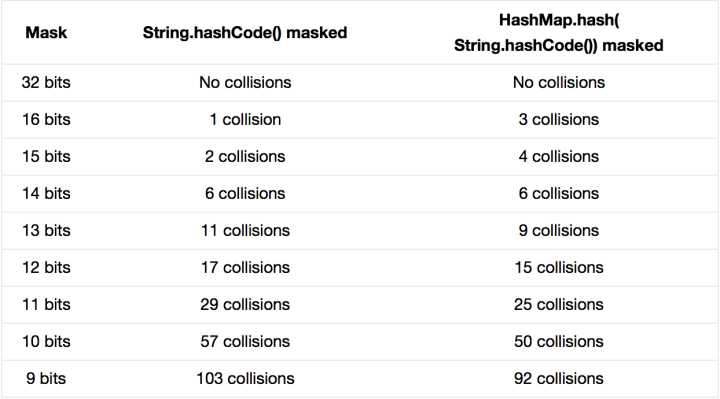
結(jié)果顯示,當(dāng)HashMap數(shù)組長度為512的時候,也就是用掩碼取低9位的時候,在沒有擾動函數(shù)的情況下,發(fā)生了103次碰撞,接近30%。而在使用了擾動函數(shù)之后只有92次碰撞。碰撞減少了將近10%。看來擾動函數(shù)確實還是有功效的。但明顯Java 8覺得擾動做一次就夠了,做4次的話,多了可能邊際效用也不大,所謂為了效率考慮就改成一次了。
------------------------------------------------------
https://www.zhihu.com/question/20733617