早在N年多前,給別人做一web應用,期間要使用jsp調客戶提供的Socket客戶端,去獲取遠端數(shù)據(jù)。由于該客戶端是異步處理,所以jsp發(fā)出請求后到底何時能獲得數(shù)據(jù),是個問題。遂想了個辦法,既jsp固定sleep一個足夠長的時間,然后Socket客戶端把數(shù)據(jù)寫到某靜態(tài)變量中,等jsp的sleep超時,jsp再去那個靜態(tài)區(qū)去抓。這種做法倒是能用,只是時好時壞,特別是網絡環(huán)境差的時候,容易得到null的數(shù)據(jù)。當然,最后改成了循環(huán)sleep,直到把數(shù)據(jù)刷出來為止。
問題是解決了,但冒出一個念頭,想把訪問異步環(huán)境的過程轉換為同步,既對Servlet進行wait,然后待異步返回后再notify它。說干就干,Servlet代碼如下,以Tomcat 5.5為例。
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class Rec extends HttpServlet {
private static final long serialVersionUID = 1L;
public String var;
public Rec() {
super();
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doPost(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String tName = Thread.currentThread().getName();
GoProcess p = new GoProcess(this, tName);
p.setName("GoPro");
p.start();
synchronized(this){
try{
System.out.println("servlet "+tName+" 開始等待
 ");
");this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
response.getWriter().write(var);
}
}
Tomcat 5.5默認啟動25個守護線程,來響應瀏覽器請求。所以,當每個請求來了之后,Tomcat都會找個可用線程來響應(根據(jù)測試,在多標簽瀏覽器中,多次打開相同Servlet,Tomcat只會由同一線程響應),我們可以得到該線程的名字,例如“http-8080-Processor25”。來看上面的代碼,比較簡單,把Servlet實例傳遞給異步處理線程,然后處理線程啟動,Servlet線程自己wait。
public class GoProcess extends Thread {
private Rec _rec;
private String _tName;
public GoProcess(Rec rec, String tName){
_rec = rec;
_tName = tName;
}
public void run(){
try {
long lptime = Math.round(Math.random()*100000);
System.out.println("servlet "+_tName+" 進入GoPro線程,開始干活。需要"+lptime+"毫秒");
Thread.sleep(lptime);
System.out.println("處理結束呼喚servlet "+_tName);
synchronized(_rec){
_rec.notify();
_rec.var = new Date().toString()+" done!";
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
處理線程模擬不同的網絡環(huán)境進行sleep,可以把sleep之上的代碼看成進入異步調用,之后的代碼看成異步返回。打開一個firefox和兩個ie6窗口,調試結果如下。
servlet http-8080-Processor24 進入GoPro線程,開始干活。需要49277毫秒
servlet http-8080-Processor25 開始等待
servlet http-8080-Processor25 進入GoPro線程,開始干活。需要7610毫秒
servlet http-8080-Processor23 開始等待
servlet http-8080-Processor23 進入GoPro線程,開始干活。需要20599毫秒
處理結束呼喚servlet http-8080-Processor25
處理結束呼喚servlet http-8080-Processor23
處理結束呼喚servlet http-8080-Processor24
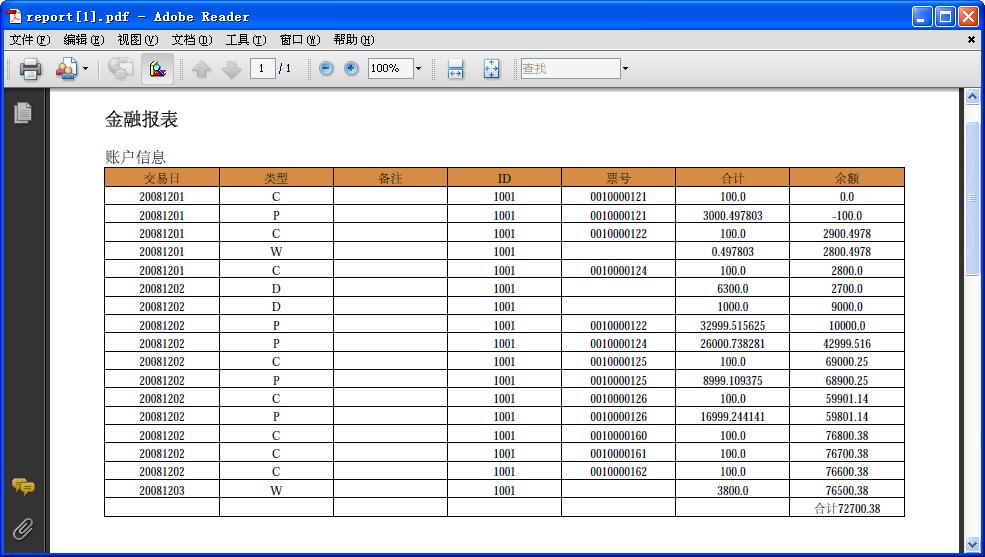
看起來是能實現(xiàn)異步調用轉換為同步阻塞調用的方式。不過就像我在最前面說的,毫無意義!因為一旦網絡環(huán)境很差,有可能會導致瀏覽器長時間處于空白加載狀態(tài),非常糟糕的用戶體驗(BTW:沒有實驗過nio的連接器,猜想這樣阻塞訪問會嚴重影響nio的性能)。所以,在真正遇到怎樣的問題時還不如用ajax的方式處理,在頁面上開辟一小塊信息區(qū)顯示狀態(tài),然后ajax輪詢服務器端異步返回的結果,一旦返回就立刻體現(xiàn)到頁面上。好了,歡迎拍磚。
請注意!引用、轉貼本文應注明原作者:Rosen Jiang 以及出處: http://www.aygfsteel.com/rosen
]]>
有個朋友的項目需要用到 PDF 報表下載,之前我只做過 Excel 的,相信再做一次 PDF 的下載一定很有趣吧。在網上找了一大圈,似乎 iText 比較符合我的要求,而且這個工具很早很早以前就有了,生命力很旺盛。進入 iText 的主頁(http://www.lowagie.com/iText/),發(fā)現(xiàn)作者很勤勞,最近2個月都有新版本發(fā)布。哪知道現(xiàn)在高興得太早了,一堆問題接踵而至。
下載倒是很簡單,一個iText in a Web Application正是我要找的,不過這個例子很簡單。通過 Google 之后,又發(fā)現(xiàn)要下載一個 CJK 的包(iTextAsian.jar)才能正確顯示中文,好吧我去找。很幸運的是在 iText by Example 里找到了這個 jar 的 link,興致勃勃的跑去下載,結果這是個無效鏈接,最后在 sourceForge 上才找到,不容易啊。解決了這些問題,想必能夠安穩(wěn)的使用了吧,由于這個項目比較急,沒什么耐心一個個的翻閱 iText by Example,想找點捷徑,據(jù)說 iText 可以從 html 直接生成 PDF,竊喜!找了 apache common 的 httpclient,動態(tài)模擬 http 請求來抓 html,根據(jù)控制臺的 print,的確把 html 抓到了,然后開始轉換到 PDF,先解決了中文顯示問題,可是后面的問題解決不了了,html 的 table 和 div 這些,轉換到 PDF 都走樣了... ...
很不爽,看來還是只有老老實實的啃 iText by Example實在點。這次稍微耐心點,一點點的看,首先搞清楚了它的 Font 設置,然后是 Table 和 Cell 的關系,經過反復調試,有點效果了。把代碼貼出來,做個標記吧。以免以后又抓狂。
??2?
??3?import?java.awt.Color;
??4?import?java.io.IOException;
??5?import?java.util.HashMap;
??6?import?java.util.List;
??7?import?java.util.Map;
??8?
??9?import?javax.servlet.ServletException;
?10?import?javax.servlet.http.HttpServlet;
?11?import?javax.servlet.http.HttpServletRequest;
?12?import?javax.servlet.http.HttpServletResponse;
?13?
?14?import?org.springframework.web.context.WebApplicationContext;
?15?import?org.springframework.web.context.support.WebApplicationContextUtils;
?16?
?17?import?org.rosenjiang.service.UserService;
?18?import?com.lowagie.text.Document;
?19?import?com.lowagie.text.DocumentException;
?20?import?com.lowagie.text.Font;
?21?import?com.lowagie.text.Paragraph;
?22?import?com.lowagie.text.pdf.BaseFont;
?23?import?com.lowagie.text.pdf.PdfPCell;
?24?import?com.lowagie.text.pdf.PdfPTable;
?25?import?com.lowagie.text.pdf.PdfWriter;
?26?
?27?/*
?28??*?ReportServlet
?29??*?@author?rosen?jiang
?30??*?@since?2008-12
?31???*/?
?32?public?class?ReportServlet?extends?HttpServlet?{
?33????????
?34?????/**
?35??????*?Return?a?PDF?document?for?download.
?36??????*?
?37??????*/
?38?????public?void?doGet?(HttpServletRequest?request,?HttpServletResponse?response)
?39?????throws?IOException,?ServletException?{
?40?????????String?account_id?=?request.getParameter("account_id");
?41?????????String?search_date_from?=?request.getParameter("search_date_from");
?42?????????String?to?=?request.getParameter("to");
?43?????????WebApplicationContext?ctx?=?WebApplicationContextUtils.getWebApplicationContext(this.getServletContext());
?44?????????UserService?userService?=?(UserService)ctx.getBean("userService");
?45?????????List<Map<String,?Object>>?list?=?userService.getAccountActivity(account_id,?search_date_from,?to);
?46?????????//?create?PDF?document
?47?????????Document?document?=?new?Document();
?48?????????try?{
?49?????????????//set?response?info
?50?????????????response.setContentType("application/x-msdownload;charset=UTF-8");
?51?????????????response.setHeader("Content-Disposition","attachment;filename=report.pdf");
?52?????????????//open?output?stream
?53?????????????PdfWriter.getInstance(document,?response.getOutputStream());
?54?????????????//?open?PDF?document
?55?????????????document.open();
?56?????????????//?set?chinese?font
?57?????????????BaseFont?bfChinese?=?BaseFont.createFont("STSong-Light",?"UniGB-UCS2-H",?BaseFont.NOT_EMBEDDED);??
?58?????????????Font?f2?=?new?Font(bfChinese,?2,?Font.NORMAL);
?59?????????????Font?f6?=?new?Font(bfChinese,?6,?Font.NORMAL);
?60?????????????Font?f8?=?new?Font(bfChinese,?8,?Font.NORMAL);
?61?????????????Font?f10?=?new?Font(bfChinese,?10,?Font.NORMAL);
?62?????????????Font?f12?=?new?Font(bfChinese,?12,?Font.BOLD);
?63?????????????//set?title
?64?????????????document.add(new?Paragraph("金融報表",?f12));?
?65?????????????//<br>
?66?????????????document.add(new?Paragraph("?",f6));?
?67?????????????//set?sub?title
?68?????????????document.add(new?Paragraph("賬戶信息",?f10));?
?69?????????????//<br>
?70?????????????document.add(new?Paragraph("?",?f2));
?71?????????????//process?business?data
?72?????????????if(list.size()>0?&&?list.get(0).get("bankbook_no")!=null){
?73?????????????????float?openBalance?=?0;
?74?????????????????//create?table?with?7?columns
?75?????????????????PdfPTable?table?=?new?PdfPTable(7);
?76?????????????????//100%?width
?77?????????????????table.setWidthPercentage(100);
?78?????????????????table.setHorizontalAlignment(PdfPTable.ALIGN_LEFT);
?79?????????????????//create?cells
?80?????????????????PdfPCell?cell?=?new?PdfPCell();
?81?????????????????//set?color
?82?????????????????cell.setBackgroundColor(new?Color(213,?141,?69));
?83?????????????????cell.setHorizontalAlignment(PdfPCell.ALIGN_CENTER);
?84?????????????????//
?85?????????????????cell.setPhrase(new?Paragraph("交易日",?f8));
?86?????????????????table.addCell(cell);
?87?????????????????cell.setPhrase(new?Paragraph("類型",?f8));
?88?????????????????table.addCell(cell);
?89?????????????????cell.setPhrase(new?Paragraph("備注",?f8));
?90?????????????????table.addCell(cell);
?91?????????????????cell.setPhrase(new?Paragraph("ID",?f8));
?92?????????????????table.addCell(cell);
?93?????????????????cell.setPhrase(new?Paragraph("票號",?f8));
?94?????????????????table.addCell(cell);
?95?????????????????cell.setPhrase(new?Paragraph("合計",?f8));
?96?????????????????table.addCell(cell);
?97?????????????????cell.setPhrase(new?Paragraph("余額",?f8));
?98?????????????????table.addCell(cell);
?99?????????????????//create?another?cell
100?????????????????PdfPCell?newcell?=?new?PdfPCell();
101?????????????????newcell.setHorizontalAlignment(PdfPCell.ALIGN_CENTER);
102?????????????????
103?????????????????Map<String,?Object>?map?=?new?HashMap<String,?Object>();
104?????????????????for(int?i?=?0;?i?<?list.size();?i++){
105?????????????????????map?=?list.get(i);
106?????????????????????String?cashInout?=?map.get("cash_inout").toString();
107?????????????????????newcell.setPhrase(new?Paragraph(map.get("trade_date").toString(),?f8));
108?????????????????????table.addCell(newcell);
109?????????????????????newcell.setPhrase(new?Paragraph(map.get("bankbook_type").toString(),?f8));
110?????????????????????table.addCell(newcell);
111?????????????????????newcell.setPhrase(new?Paragraph(map.get("memo").toString(),?f8));
112?????????????????????table.addCell(newcell);
113?????????????????????newcell.setPhrase(new?Paragraph(map.get("account_id").toString(),?f8));
114?????????????????????table.addCell(newcell);
115?????????????????????newcell.setPhrase(new?Paragraph(map.get("ticket_no").toString(),?f8));
116?????????????????????table.addCell(newcell);
117?????????????????????newcell.setPhrase(new?Paragraph(map.get("amount").toString(),?f8));
118?????????????????????table.addCell(newcell);
119?????????????????????newcell.setPhrase(new?Paragraph(openBalance+"",?f8));
120?????????????????????table.addCell(newcell);
121?????????????????????if(cashInout.equals("I")){
122?????????????????????????openBalance?=?openBalance?+?Float.valueOf(map.get("amount").toString());
123?????????????????????}else?if(cashInout.equals("O")){
124?????????????????????????openBalance?=?openBalance?-?Float.valueOf(map.get("amount").toString());
125?????????????????????}
126?????????????????}
127?????????????????//print?total?column
128?????????????????newcell.setPhrase(new?Paragraph("合計"+openBalance,?f8));
129?????????????????table.addCell("");
130?????????????????table.addCell("");
131?????????????????table.addCell("");
132?????????????????table.addCell("");
133?????????????????table.addCell("");
134?????????????????table.addCell("");
135?????????????????table.addCell(newcell);
136?????????????????document.add(table);
137?????????????}else{
138?????????????????PdfPTable?table?=?new?PdfPTable(1);
139?????????????????table.setWidthPercentage(100);
140?????????????????table.setHorizontalAlignment(PdfPTable.ALIGN_LEFT);
141?????????????????PdfPCell?cell?=?new?PdfPCell(new?Paragraph("暫無數(shù)據(jù)"));
142?????????????????cell.setHorizontalAlignment(PdfPCell.ALIGN_CENTER);
143?????????????????table.addCell(cell);
144?????????????????document.add(table);
145?????????????}
146?????????}
147?????????catch(DocumentException?de)?{
148?????????????de.printStackTrace();
149?????????????System.err.println("document:?"?+?de.getMessage());
150?????????}finally{
151?????????????//?close?the?document?and?the?outputstream?is?also?closed?internally
152?????????????document.close();
153?????????}????????
154?????}
155?}
代碼結構清晰,本來也沒什么東西,就是通過 Spring 調用 service 方法,獲取數(shù)據(jù)后按照 iText 結構輸出即可。不過代碼里面有個很愚蠢的動作:document.add(new?Paragraph("?",f6)),主要是找不到如何輸出空白行,所以只好出此下策。如果哪位有解法,請告知一下。
做技術的確不能太著急,慢慢來,總會找到出口的。
請注意!引用、轉貼本文應注明原作者:Rosen Jiang 以及出處:http://www.aygfsteel.com/rosen
]]>
]]>
???
??? 問題的解決之道來了!我們可以在類中處理一張大圖,并縮小它。
??? 前提是需要JDK1.4,這樣才能進行處理。按以下方法做:
???
????? import java.io.File;
????? import java.io.FileOutputStream;
????? import java.awt.Graphics;
????? import java.awt.Image;
????? import java.awt.image.BufferedImage;
????? import com.sun.image.codec.jpeg.JPEGCodec;
????? import com.sun.image.codec.jpeg.JPEGImageEncoder;
?????
????? public class JpgTest {
?
?public void JpgTset() throws Exception{
???? File _file = new File("/Order005-0001.jpg");?????????????????????? //讀入文件
???? Image src = javax.imageio.ImageIO.read(_file);???????????????????? //構造Image對象
???? int wideth=src.getWidth(null);???????????????????????????????????? //得到源圖寬
???? int height=src.getHeight(null);??????????????????????????????????? //得到源圖長
???? BufferedImage tag = new BufferedImage(wideth/2,height/2,BufferedImage.TYPE_INT_RGB);
???? tag.getGraphics().drawImage(src,0,0,wideth/2,height/2,null);?????? //繪制縮小后的圖
???? FileOutputStream out=new FileOutputStream("newfile.jpg");????????? //輸出到文件流
???? JPEGImageEncoder encoder = JPEGCodec.createJPEGEncoder(out);??????
???? encoder.encode(tag);?????????????????????????????????????????????? //近JPEG編碼
???? //System.out.print(width+"*"+height);?????????????????????????????
???? out.close();
?}
????? }
???
??? 過程很簡單,從本地磁盤讀取文件Order005-0001.jpg(2032*1524),變成Image對象src,接著構造目標文件tag,設置tag的長寬為源圖的一半,對tag進行編碼,輸出到文件流out,最后關閉文件流。
???
??? 還有一些問題需要說明:
??? 第一,目前只能支持JPG(JPEG)、GIF、PNG三種格式。(這里有些問題,在最下面解釋)
??? 第二,對于源圖的容量有限制,最好不要超過1M,否則會拋內存不足的錯誤,不過我試驗過1.8M的源圖,可以成功,但是也很容易拋內存不足。
???
??? 引用一位前輩的話:圖象運算本身是密集型運算,需要大量的內存存放象素值。我用VC試了一下,4M的圖象也有問題,而且越是壓縮比大的圖片在內存中還原成BITMAP時需要的內存越大。解決的方法,可以重寫編碼類,先開一定的內存,然后一段一段編碼寫到臨時文件中,輸出的時候再一段一段讀出來。或利用nio的內存映象來操作。JavaMail由于采用了Builder模式,先生成一個郵件的每一個部分,然后合并成一個完整的郵件對象,這樣每個構件都要先生成到內存中,你如果發(fā)送一個上百兆的附件,那么在構造Part時肯定內存溢出,所以我就改寫了BodyPart的構造,讓他和一個臨時文件關聯(lián),然后用臨時文件保存Part而不是構造在內存中,這樣任義大小的附件(硬盤能放得下為限)都可以發(fā)送了。
???
??? 最后,如果大家對圖像處理有更高的要求,不妨關注一下開源項目。比如JMagick,可以使用JMagick來實現(xiàn)圖片的復制、信息獲取、斜角、特效、組合、改變大小、加邊框、旋轉、切片、改變格式、去色等等功能。
2007-06-20更新
其實按照上面的做法只能壓縮jpg格式,gif是不能壓縮的(由于算法版權問題,直到Java 6.0才能壓縮gif),前段時間要用gif壓縮,在網上找了個類,可以解決問題。請參考:http://mindprod.com/jgloss/gifencoder.html。
替換以前代碼的相應部分:
????????????????????size[ 0 ],?size[ 1 ],?BufferedImage.TYPE_INT_RGB);
????????????tag.getGraphics().drawImage(src,? 0 ,? 0 ,?size[ 0 ],?size[ 1 ],? null );?
????????????out? = ? new ?FileOutputStream(path);
????????????GIFEncoder?gifEncoder? = ? new ?GIFEncoder(tag);
????????????gifEncoder.write(out);
當代碼運行完畢,用EditPlus之類的文本編輯器打開之后可以發(fā)現(xiàn)文件頭已經是gif87格式了。
請注意!引用、轉貼本文應注明原作者:Rosen Jiang 以及出處:http://www.aygfsteel.com/rosen
]]>
]]>
面向服務體系
SOA (面向服務體系)是近期推動應用和業(yè)務集成領域產生巨大飛躍的新技術之一。 SOA 定義了一系列詳盡的體系規(guī)范、范例和實現(xiàn)應用程序間進行松散耦合交互的最佳準則。
SOA 基于定義明確的接口,促進多個應用程序間的松散耦合交互。服務的實現(xiàn)是獨立的,且不依賴上下文信息以及其他服務的狀態(tài)。服務間數(shù)據(jù)交換主要基于文本類型的格式,使用基于標準的消息模型。服務自身并不知道服務提供者和服務消費者之間傳輸級的通訊交互。
盡管不是強制要求,當今大部分流行的基于
SOA
的系統(tǒng)都利用了
Web
服務以及近似技術為服務間交互提供必要的管道管理。
WSDL
(
Web
服務定義語言)扮演了主要的通訊模型角色;
SOAP
扮演了消息承載協(xié)議、
HTTP
扮演了網絡傳輸協(xié)議。當然,這并不意味著你必須利用上述技術實現(xiàn)基于
SOA
的系統(tǒng)。另外,有些術語之前就已經存在了,所以很多企業(yè)已利用類似的體系實現(xiàn)了系統(tǒng)的松散耦合交互。不管怎樣,主要的不同點在于我們現(xiàn)在已經有標準協(xié)議、工具集和軟件了,使面向服務體系更健全。
SOA 原則與面向對象范式、原則有著顯著不同。主要不同在于服務間交互的接口被定義了更多面向數(shù)據(jù)的行為。一個孤立的服務也許會采用面向對象原則和技術,但是,服務之間的交互很少采用這些手段。相反,這些接口更適合于基于文檔的交換。面向對象的行為是綁定數(shù)據(jù),而面向服務從行為中分離數(shù)據(jù)。
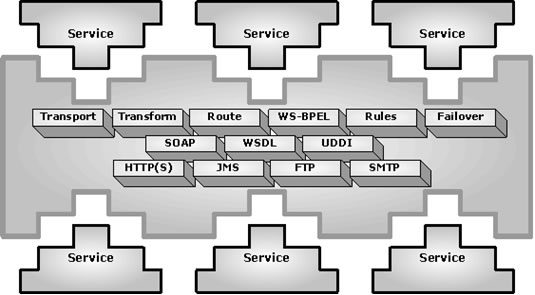
企業(yè)服務總線
ESB (企業(yè)服務總線)為面向服務體系提供了基礎架構。通過設計工具定義服務間交互和規(guī)則, ESB 為部署和發(fā)現(xiàn)服務提供了運行時環(huán)境。
 ?
?
??? 在
ESB
的世界中,服務不會直接彼此交互。“
ESB
運行時”作為一個仲裁者在服務間松散的耦合它們。“
ESB
運行時”將實現(xiàn)協(xié)議綁定、消息傳輸、消息處理,等等。
一個服務總線將包括下列關鍵項:
??? 為服務提供傳輸綁定
??? 定義和發(fā)現(xiàn)已部署服務
??? 在服務間基于規(guī)則的路由和編排消息
??? 包括文檔傳遞在內的增值服務等
大部分的 ESB 提供商基于自己的 SOA 提議來開放標準和技術,包括多種 Web 服務標準和協(xié)議。他們提供多種調用服務的傳輸綁定,包括 HTTP 、 FTP 以及 JMS 等等。大部分 ESB 用戶利用 WS-BPEL ( Web 服務的業(yè)務流程執(zhí)行語言)來了解已部署服務之間是如何實現(xiàn)業(yè)務流程的。 ESB 提供商同時也提供服務質量特性,包括容錯、故障轉移、負載平衡、消息緩沖等等。
Java
業(yè)務集成
???
JBI ( Java 業(yè)務集成)的提出是基于面向服務體系提倡的方法和原則,為了解決 EAI 和 B2B 若干問題的 Java 標準。當前版本( 1.0 )是 2005 年 8 月通過的 JSR ( Java 規(guī)范需求) 208 定案。商業(yè)和開源界都歡迎 JBI 成為他們 ESB 產品的集成標準。
基于仲裁者體系
JBI 定義了基于插件方式的架構,以便服務能融入“ JBI 運行時”環(huán)境。 JBI 提供了詳細的接口,使服務能與“ JBI 運行時”環(huán)境交互。這些服務要為“ JBI 運行時”環(huán)境暴露接口,以便“ JBI 運行時”環(huán)境為服務路由消息。“ JBI 運行時”環(huán)境在部署在 SOA 環(huán)境中的服務間扮演仲裁者的角色。
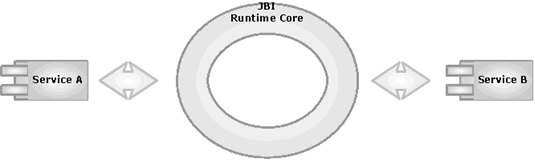
在同一
JVM
中,“
JBI
運行時”核心主要包括如下組件:
??? 組件框架:組件框架把不同類型的組件部署到“ JBI 運行時”。
?? ? 歸一化消息路由器:歸一化消息路由器利用標準機制實現(xiàn)服務間消息交換。
??
?
管理框架:管理框架基于
JMX
進行部署、管理以及監(jiān)控“
JBI
運行時”中的組件。
組件模型
??? JBI 在“ JBI 運行時”環(huán)境中定義了兩種組件:
??? 服務引擎組件:該組件負責實現(xiàn)業(yè)務邏輯和其他服務。服務引擎組件在其內部可使用多種技術和設計模式。服務引擎組件可提供數(shù)據(jù)傳輸和轉換這種簡單的基礎服務,也可實現(xiàn)像 WS-BPEL 實例一樣復雜的業(yè)務處理。
??? 綁定組件:綁定組件主要為已部署服務提供傳輸級綁定。綁定組件有多種類型:
??????? 利用標準傳輸協(xié)議與外部系統(tǒng)進行遠程通訊。
??????? 使已部署服務能在同一個 JVM 內部相互調用。
??????? 服務間可使用標準的 WS-I ( Web 服務協(xié)同工作組織)規(guī)范通訊。
??? JBI 的關鍵是分離服務引擎和綁定組件,以便業(yè)務邏輯不被下面的具體細節(jié)所干擾。這種方式促進了體系的靈活性和可擴展性。綁定組件和服務引擎組件在 JBI 內部都可以是服務提供者和 / 或服務消費者。
???
??? 綁定組件和服務引擎組件為“ JBI 運行時”提供接口以便從“ JBI 運行時”接收消息。同樣的,它們也利用 JBI 提供的接口來和“ JBI 運行時”通訊。
消息傳輸模型
JBI 利用消息傳輸模型分離服務提供者和服務消費者之間的耦合。消息傳輸模型利用了 WSDL 。 WSDL 用于描述暴露的服務引擎組件和綁定組件的業(yè)務處理。另外, WSDL 也用于定義抽象服務處理的傳輸級綁定。
JBI 架構中一個關鍵組件是 NMR (歸一化消息路由器,也譯作“正規(guī)消息路由器”)。 NMR 基于 WSDL 提供了主要的消息傳輸中樞, NMR 為部署在“ JBI 運行時”中的服務引擎組件和綁定組件間的消息傳遞提供松散耦合。服務需要有聚合業(yè)務處理的接口,每個業(yè)務處理由零個或多個消息組成。而一個接口有一個或多個傳輸級綁定。
“ JBI 運行時”利用歸一化格式描述消息。一個歸一化消息由以下部分組成:
??? 消息屬性
??? 消息有效載荷
消息附件
???
利用 NMR , JBI 規(guī)范為服務提供者和消費者的消息交換提供標準接口。 NMR 支持服務生產者和消費者之間單向模式和服務響應模式的調用。
管理
JBI 利用 JMX 實現(xiàn)運行時的服務安裝、配置和監(jiān)控。服務必須實現(xiàn) JBI 接口集,以便這些服務在 JBI 環(huán)境中是可管理的。 JBI 環(huán)境必須提供一套 JMX MBeans 實現(xiàn)“ JBI 運行時”的管理。
“ JBI 運行時”環(huán)境允許服務引擎組件和綁定組件的相關操作如下:
??? 安裝組件:使組件接口可使用歸一化消息路由器。
??? 安裝 artefact 組件:這將允許已部署的 artefacts 組件獲得與已安裝組件同樣的機能。例如,可以部署一個“連接服務”來提供具體的數(shù)據(jù)庫連接。
??? 啟動、停止服務以及進行相關服務分組。
JBI 為組件及 artefact 組件定義了標準的部署描述符以及打包模型。
角色
JBI 為基于 JBI 的端到端 EAI 解決方案定義了如下角色:
? ?? 引擎開發(fā)者:引擎開發(fā)者提供遵循 NMR 和管理約束的服務引擎組件。
??? 綁定開發(fā)者:綁定開發(fā)者提供遵循 NMR 和管理約束的綁定組件。
JBI 環(huán)境提供者: JBI 環(huán)境提供者為“ JBI 運行時”使用 J2EE 1.4 或 J2SE 1.4 或更新的平臺提供支持。
J2EE 平臺提供者: J2EE 平臺提供者把“ JBI 運行時”作為提供應用程序服務的一部分。
JBI 應用程序開發(fā)者: JBI 應用程序開發(fā)者利用服務引擎組件、綁定組件以及 JBI 環(huán)境構建 JBI 應用程序。
結論
???
???
當今業(yè)界走向越來越開放的標準和規(guī)范,
JBI
在使
Java
技術利用面向服務體系和
ESB
基礎架構實現(xiàn)業(yè)務集成方面產生了巨大飛躍。像
Oracle
這樣的商用產品提供商和
ServiceMix
這樣的開源軟件都把
JBI
作為了他們
ESB
方案的一部分。
關于作者
??? Meeraj Kinnumpurath
是位在
VOCA
有限公司(原來叫
BACS
)就職的
Java
架構師,這家公司是英國最大的票據(jù)交換所。他有
8
年的
Java
開發(fā)經驗,主要從事企業(yè)應用程序開發(fā)。他已出版了一些
Java
、
J2EE
以及
Web
服務方面的書籍。
請注意!引用、轉貼本文應注明原譯者:Rosen Jiang 以及出處:
http://www.aygfsteel.com/rosen
]]>
重新?lián)炱?Web Service 是去年的事情,當時評估了多種開源 SSO 實現(xiàn),總覺得不是很方便,遂打算自己實現(xiàn)。為了使通用性更高,決定讓 Web Service 完成。并很自然的選到了 Axis。
SOAP、WSDL、UDDI,這些名詞相信只要了解過 Web Service 的都不陌生,根據(jù) Apache 的定義,Axis 是一種 W3C SOAP 實現(xiàn),國內有些介紹還特別注明了:Axis 并不完全是 SOAP 引擎,它還包括獨立的 SOAP 服務器、嵌入 Servlet 引擎的服務器、支持 WSDL 并提供轉化 WSDL 為 Java 類的工具、例子程序、TCP/IP 數(shù)據(jù)包監(jiān)視工具,等等。Axis 部署 Web Serive 有兩種方式,最簡單的是拷貝 java 源代碼文件到 web 文件夾下把擴展名改為 .jws 直接調用,可參考這篇文章:用Axis 1.1 for Java進行Web Services開發(fā)(1)。另一種方式是通過 WSDD(Web Services描述文檔)部署,可參考:使用Axis發(fā)布簡單的Web服務。在我的應用中,使用的是后者,以便 Axis 進行自動序列化/反序列化處理。
實現(xiàn)一次 SSO 登陸驗證,最少要傳入用戶名、密碼。為了達到這種目的,在客戶端我們構造 User 對象(本文中 User 對象僅包含用戶名和密碼),并通過 Axis 自動序列化傳遞出去;到了 SSO 端,Axis 自動反序列化之后還原成 User 對象;最后返回給客戶端說明本次登陸的結果,返回的結果不僅僅包含例如“登陸成功”之類的簡單信息,也許還有很多其他信息,看來創(chuàng)建一個叫做 Respond 的對象(本文中 Respond 對象僅包含登陸 ID 和結果描述)很有必要了,把 Respond 傳回給客戶端說明登陸結果。
暴露給客戶端供登陸驗證的服務類是 AuthService。該類代碼簡單表示如下:
/**
* 驗證用戶名和密碼
* @param String userName 用戶名
* @param String passWord 密碼
* @return Respond 登陸驗證后返回
*/
public Respond login(User user){
String name = user.getName();
String password = user.password();
//進行數(shù)據(jù)庫驗證
//
 ..
..//
Respond respond = new Respond();
respond.setId("123");
respond.setDesc("登陸成功");
return respond;
}
}
User 和 Respond 以及服務類都寫好了。通過命令行方式,我生成了 server-config.wsdd,內容如下:
<deployment xmlns="http://xml.apache.org/axis/wsdd/" xmlns:java="http://xml.apache.org/axis/wsdd/providers/java">
<globalConfiguration>
<parameter name="sendMultiRefs" value="true"/>
<parameter name="disablePrettyXML" value="true"/>
<parameter name="adminPassword" value="admin"/>
<parameter name="attachments.Directory" value="D:\workspace\SSO\web\WEB-INF\attachments"/>
<parameter name="dotNetSoapEncFix" value="true"/>
<parameter name="enableNamespacePrefixOptimization" value="true"/>
<parameter name="sendXMLDeclaration" value="true"/>
<parameter name="sendXsiTypes" value="true"/>
<parameter name="attachments.implementation" value="org.apache.axis.attachments.AttachmentsImpl"/>
<requestFlow>
<handler type="java:org.apache.axis.handlers.JWSHandler">
<parameter name="scope" value="session"/>
</handler>
<handler type="java:org.apache.axis.handlers.JWSHandler">
<parameter name="scope" value="request"/>
<parameter name="extension" value=".jwr"/>
</handler>
</requestFlow>
</globalConfiguration>
<handler name="LocalResponder" type="java:org.apache.axis.transport.local.LocalResponder"/>
<handler name="URLMapper" type="java:org.apache.axis.handlers.http.URLMapper"/>
<handler name="Authenticate" type="java:org.apache.axis.handlers.SimpleAuthenticationHandler"/>
<service name="AuthService" provider="java:RPC">
<parameter name="allowedMethods" value="*"/>
<parameter name="className" value="com.cdmcs.sso.AuthService"/>
<beanMapping languageSpecificType="java:sso.Respond" qname="ns:resp" xmlns:ns="urn:BeanService"/>
<beanMapping languageSpecificType="java:sso.User" qname="ns:user" xmlns:ns="urn:BeanService"/>
</service>
<service name="AdminService" provider="java:MSG">
<parameter name="allowedMethods" value="AdminService"/>
<parameter name="enableRemoteAdmin" value="false"/>
<parameter name="className" value="org.apache.axis.utils.Admin"/>
<namespace>http://xml.apache.org/axis/wsdd/</namespace>
</service>
<service name="Version" provider="java:RPC">
<parameter name="allowedMethods" value="getVersion"/>
<parameter name="className" value="org.apache.axis.Version"/>
</service>
<transport name="http">
<requestFlow>
<handler type="URLMapper"/>
<handler type="java:org.apache.axis.handlers.http.HTTPAuthHandler"/>
</requestFlow>
<parameter name="qs:list" value="org.apache.axis.transport.http.QSListHandler"/>
<parameter name="qs:wsdl" value="org.apache.axis.transport.http.QSWSDLHandler"/>
<parameter name="qs.list" value="org.apache.axis.transport.http.QSListHandler"/>
<parameter name="qs.method" value="org.apache.axis.transport.http.QSMethodHandler"/>
<parameter name="qs:method" value="org.apache.axis.transport.http.QSMethodHandler"/>
<parameter name="qs.wsdl" value="org.apache.axis.transport.http.QSWSDLHandler"/>
</transport>
<transport name="local">
<responseFlow>
<handler type="LocalResponder"/>
</responseFlow>
</transport>
</deployment>
要說明的是,深究上述配置文件具體含義不是本文的目的,要對其具體了解,請參考 Axis 文檔。其中,只有下面的 XML 才是我們感興趣的:
<parameter name="allowedMethods" value="*"/>
<parameter name="className" value="com.cdmcs.sso.AuthService"/>
<beanMapping languageSpecificType="java:sso.Respond" qname="ns:resp" xmlns:ns="urn:BeanService"/>
<beanMapping languageSpecificType="java:sso.bo.User" qname="ns:user" xmlns:ns="urn:BeanService"/>
</service>
為了完成自動序列化/反序列化,我們使用“beanMapping”元素指定要進行處理的 bean 文件。只有在 WSDD 中定義了這些,才能享受到 Axis 帶來的自動序列化/反序列化優(yōu)勢。
客戶端代碼:
public static void main(String[] args) {
try {
String endpoint = "http://127.0.0.1:8080/services/AuthService?wsdl";
Service service = new Service();
Call call = (Call) service.createCall();
QName qn = new QName("urn:BeanService","resp");
QName qx = new QName("urn:BeanService","user");
//注冊 bean
call.registerTypeMapping(Respond.class,qn,new BeanSerializerFactory(Respond.class, qn),new BeanDeserializerFactory(Respond.class, qn));
call.registerTypeMapping(User.class,qx,new BeanSerializerFactory(User.class, qx),new BeanDeserializerFactory(User.class, qx));
call.setTargetEndpointAddress(new java.net.URL(endpoint));
call.setOperationName(new QName("http://soapinterop.org/","login"));
User user = new User();
mul.setName("test");
mul.setPassword("test");
Respond respond = (Reopond) call.invoke(new Object[] {user});
System.out.println("登陸,返回'" + respond.getDesc() + "'。");
} catch (Exception e) {
e.printStackTrace();
}
}
}
正如我們期望的,打印出“登陸成功”。通過上面的范例,我們發(fā)現(xiàn),Axis 的自動序列化/反序列化機制還是很方便的,除了 bean 以外,其他類型的對象也可以讓 Axis 來完成,具體參考 Axis 文檔,如果要傳遞的對象 Axis 未提供自動序列化/反序列化支持,請考慮人工實現(xiàn),參考:深度編程Axis序列化/反序列化器開發(fā)指南。
請注意!引用、轉貼本文應注明原作者:Rosen Jiang 以及出處:http://www.aygfsteel.com/rosen
]]>

報表介紹
BIRT 是為 Web 應用程序開發(fā)的基于 Eclipse 的開源報表系統(tǒng),特別之處在于它是以 Java 和 J2EE 為基礎。BIRT 有兩個主要組件:基于 Eclipse 的報表設計器,以及部署到應用服務器上的運行時組件。BIRT 也提供了圖標引擎讓你能為應用增加圖標。
當前發(fā)行的版本是 1.0.1。我們鼓勵你下載、試用 BIRT,請通過 newsgroups and Bugzilla 向我們提意見。
有了 BIRT,你可以為應用程序構建豐富的報表。
列表 - 列表是最簡單的報表。當列表變長時,你可以把相關數(shù)據(jù)增加到同一分組(基于客戶的訂單分組,基于供應商的產品分組)。如果數(shù)據(jù)是數(shù)字類型的,你可以輕松的添加到“總數(shù)”、“平均”、或其他匯總中。
圖表 - 當需要圖表表現(xiàn)時,數(shù)字型數(shù)據(jù)比較好理解。BIRT 也提供餅狀、線狀以及柱狀圖標等。
交叉表 - 交叉表(也叫做十字表格或矩陣)用兩種維度展示數(shù)據(jù):sales per quarter or hits per web page。(交叉表在 1.0.1 中沒有提供,但計劃在將來提供。)
信函和文檔 - 通知、信件、以及其他文本文檔都很容易通過 BIRT 方便建立。文檔包括正文、格式、列表、圖表等。
混合報表 - 很多報表需要聯(lián)合以上所有的報表構成單一文檔。例如,一份客戶聲明會列出客戶所需要的信息,為當前促進(promotions)提供文本,以及提供并行的出帳和入帳列表。一份財政報表將包括聲明、圖表、表格,所有這些都將進行全方位的格式化,來匹配共有的配色方案。
剖析一份報表
BIRT 報表包含四個部分:數(shù)據(jù)、數(shù)據(jù)轉換、業(yè)務邏輯、陳述。
數(shù)據(jù) - 數(shù)據(jù)庫、Web 服務、Java 對象,這些都可以作為 BIRT 報表源。1.0.1 版本提供 JDBC 支持,也支持利用編碼來獲取其他地方的數(shù)據(jù)。BIRT 的 ODA(Open Data Access) 框架允許任何人構建新的 UI 以及運行時支持任何類型的表格式數(shù)據(jù)。未來,單一報表可包含從任意多個數(shù)據(jù)源獲取數(shù)據(jù)。
數(shù)據(jù)轉換 - 報表通過對數(shù)據(jù)的分類、統(tǒng)計、過濾以及分組來適應用戶需求。當然,數(shù)據(jù)庫能實現(xiàn)這些功能,當遇到普通文件和 Java 對象時 BIRT 必須以 "simple" 數(shù)據(jù)源方式處理。BIRT 允許復雜的操作,比如總合分組、整體共計的百分比,等等。
業(yè)務邏輯 - 真實世界的數(shù)據(jù)很少提供你理想的結構良好的報表。許多報表要求用具體邏輯把原始數(shù)據(jù)轉換成用戶的有用信息。如果該邏輯僅僅用于該報表,你可以用 BIRT 的 JavaScript 腳本支持。如果你的程序中已包含這些邏輯,你可以調用已有的 Java 代碼。
表現(xiàn) - 一旦數(shù)據(jù)準備好了,你可以在很大的范圍內選擇表現(xiàn)形式。表格、圖表、文字等等都可以。單一數(shù)據(jù)集可以有多種方式表現(xiàn),而單一報表可以表現(xiàn)多個數(shù)據(jù)集。
J2EE 應用中的 BIRT
BIRT 報表引擎以 JAR 文件方式打包,可以方便的添加到你的 J2EE 應用中。報表引擎是一系列的 POJO(Plain Old Java Objects),便于你可以在 JSP 頁面集成報表。

BIRT 與你的應用有四個主要集成點:
UI 參數(shù) - 多數(shù)報表允許用戶指定一些輸入,這些數(shù)據(jù)叫做"報表參數(shù)"。例如,客戶報表要求顯示客戶數(shù)據(jù)。你的參數(shù)頁面可能是靜態(tài)的:為每個報表進行用戶定制設計。或者,可以使用參數(shù)元數(shù)據(jù)提供的動態(tài)頁面,以便該單一頁面為所有的報表提供服務。
運行報表 - 用戶提交表單參數(shù)時,你的 web 應用通過這些參數(shù)向 BIRT 報表引擎說明讀取哪個報表設計文件,并讀取數(shù)據(jù),再產生報表輸出。當引擎運行報表時 BIRT 的術語稱為"工廠"。
數(shù)據(jù)訪問 - 報表如何從你的應用獲得數(shù)據(jù)已在上面解釋了。Java 程序通常利用 Java 對象為 BIRT 工廠提供數(shù)據(jù)。
顯示 - 附加的 JSP 頁面,叫做閱讀器,允許用戶查看報表輸出。
一個報表應用程序包含一個參數(shù)頁,你可以為每個報表創(chuàng)建自定義的 UI,或者使用 BIRT 帶來的參數(shù)元數(shù)據(jù)提供單一報表來處理多種不同報表。
樣品閱讀器
BIRT 項目提供一個樣品 "viewer" 來幫你起步。樣品閱讀器常被用于在 Eclipse 中預覽報表:BIRT 內置一個 Apache Tomcat 服務器,每次預覽報表時調用。閱讀器也可被用于任何與 JSP 兼容的 J2EE 服務器。
BIRT 的 1.0.1 版本提供單一頁面的 web 輸出。計劃在將來的版本中提供多頁面輸出,而且閱讀器 UI 也將提供多頁面之間的導航功能。
報表設計
BIRT 應用開發(fā)從報表設計開始。基于 Eclipse 插件提供多種快速構建報表工具。
數(shù)據(jù)瀏覽器 - 把你的數(shù)據(jù)源(連接)以及數(shù)據(jù)集(查詢)組織起來。數(shù)據(jù)集編輯器允許你測試數(shù)據(jù)集,以確保報表接收數(shù)據(jù)的正確性。
布局視圖 - 所見即所得編輯器為你的報表提供以拽方式來創(chuàng)建表現(xiàn)內容。包含一個標準報表條目調色板。
屬性編輯器 - 以便利的格局表現(xiàn)大多數(shù)通用的用戶屬性使編輯更快速和容易。BIRT 也集成了標準 Eclipse 屬性視圖,為每個條目提供詳細的屬性列表。
報表預覽 - 你可以在任何時間采用真實數(shù)據(jù)測試你的報表。預覽窗口直接內嵌在 Eclipse 中。
代碼編輯器 - 在訪問數(shù)據(jù)以及報表生成或瀏覽時,腳本把業(yè)務邏輯添加給報表。在編輯腳本時代碼編輯器提供標準的 Eclipse 特性:語法加色、自動完成等等。BIRT 用很簡單的腳本來表達,expression builder 能更容易的創(chuàng)建這些表達。
略圖 - BIRT 報表被組織為一個樹型結構作為整體報表的根,并且為樣式、報表內容、數(shù)據(jù)源、數(shù)據(jù)集、報表參數(shù)等分類。略圖視圖提供你整個報表結構緊湊的預覽。
Cheat Sheets - 學習新工具永遠是種挑戰(zhàn),但是 Eclipse 提供一種創(chuàng)新方案:cheat sheets。它們是一些幫助你完成新任務的文檔。
數(shù)據(jù)定制
正如前面所提到的,報表通常為要表現(xiàn)的數(shù)據(jù)添加業(yè)務邏輯。BIRT 提供多個工具來完成這一操作:
欄位計算-數(shù)據(jù)庫為存儲組織數(shù)據(jù),但這些數(shù)據(jù)通常為結合表現(xiàn)層而預先整理好。欄位計算讓你能定義基于業(yè)務邏輯的附加數(shù)據(jù)集欄位。這種邏輯是一個簡單的語法、腳本或調用一個已有的 Java 邏輯。
輸入以及輸出參數(shù)-許多數(shù)據(jù)源都支持參數(shù):在查詢時傳入或傳出數(shù)據(jù)的能力。比如,SQL Select 語句可包含輸入參數(shù)。存儲過程既有傳入又有傳出參數(shù)。
欄位元數(shù)據(jù)-當數(shù)據(jù)源提供的名字是 unintuitive 的,你可以提供欄位別名。
過濾 - 有些數(shù)據(jù)源,尤其是 SQL,提供良好的內置過濾特性。然而,有些數(shù)據(jù)源(單純的文件,應用程序對象)卻沒有提供過濾特性。另外,過濾器條件是定義在腳本或 Java 代碼中的。你可把過濾器定義為報表的一部分,BIRT 引擎會自動調用它們。
腳本化數(shù)據(jù)集 - 有些報表需要訪問專門或不常用的數(shù)據(jù)。你可以在 Java 或腳本創(chuàng)建訪問,利用腳本化數(shù)據(jù)集可在報表中集成這些邏輯。
條件格式化
有些報表有著固定的格式,其他的卻需要條件格式化。例如,某報表列出了交易記錄來表現(xiàn)不同的銷售與利潤之比。或者,一個客戶服務報表要按照不同規(guī)則進行色彩顯示。BIRT 提供多個條件格式化特性:
條件可見度 - 你可以根據(jù)數(shù)據(jù)隱藏報表元素。在上述的交易報表中,你可以創(chuàng)建銷售和交易收入兩部分,接著隱藏報表指定記錄中不需要的部分。
值映射 - 數(shù)據(jù)庫數(shù)據(jù)通常使用代碼值:M/F 代表男性或女性,1/2 代表銷售和收入,等等。值映射讓你定義一個從數(shù)據(jù)庫值到顯示值的映射。例如,我們可把值“1”對應到“Sale”,把“2”對應到“Return”。
加強 - 簡單的標識可讓你對特定報表套用樣式。例如,在客戶服務報表中,我們可以使用綠色表示上一的計劃,紅色表示下一計劃。
腳本
BIRT 提供基于 JavaScript(與知名的 ECMAScript 形式上相同)的腳本。JavaScript 經常作為客戶端腳本語言,但是它也可以用于用于表達業(yè)務邏輯。特別的,JavaScript 能與你的現(xiàn)有 Java 邏輯進行良好集成,能非常輕松地從 BIRT 報表調用業(yè)務邏輯。
BIRT 提供從 JavaScript 對象訪問報表對象模型(Report Object Model)的整套方案:同時表現(xiàn)報表設計和運行時的狀況,允許報表的完全控制處理甚至最復雜的報表格式化工作。
項目管理
BIRT 集成了 Eclipse 項目管理特性來組織相關報表。BIRT 也可以與 Eclipse CVS 協(xié)作進行源碼管理。BIRT 的 XML 報表設計格式讓它能容易的比較兩份報表,或者兩個不同版本的相同報表,并跟蹤變更。
樣式
任何設計 web 頁面的人都知道有時會反復使用相同的樣式。CSS 允許 web 設計者從內容中提取樣式信息,并復用樣式。
BIRT 提供類似的特性。當然,BIRT 樣式也是基于 CSS 的,這樣使得網頁應用開發(fā)人員能容易得設計 BIRT 表現(xiàn)形式。BIRT 樣式可堆疊,允許你在一個地方設置樣式后套用到所有報表或報表的一部分或單一報表中。
庫
典型的應用中會包括許多有關聯(lián)的報表。一個簡單的客戶應用將包括一個按照字母排序的客戶列表、按照地理位置分類的客戶群,為客戶指定的銷售代表,客戶身份篩選等等。總之,用戶不停的地變化報表以解決具體業(yè)務需要。
這樣一來,最終的報表應用將包含多組相關報表。相同的數(shù)據(jù)源、樣式、業(yè)務邏輯、報表條目。
將來的 BIRT 版本將包含組織這些共享資源的支持庫。這些庫可包含任何報表元素,比如樣式、數(shù)據(jù)源、報表條目、腳本等等。
國際化
全世界都可以訪問你的 web 應用程序。BIRT 為國際化和本地化提供良好的支持。
文本本地化 - 你可以建立一份把字符串自動變成用戶本地語言顯示的簡單報表。所有的表單和報表文本都能以標準的 Java 本地化規(guī)則進行翻譯。在運行時,BIRT 使用資源 key 找出文本的正確翻譯。
本地化 - BIRT 提供 locale-aware 格式化數(shù)據(jù),意味著對于美國用戶的日期數(shù)據(jù)可以以 mm/dd/yy 的格式出現(xiàn),而歐洲用戶則是 dd-mm-yy 格式。
動態(tài)格式化 - 中文文本非常緊湊,德文有時又有點冗長,而英文正好是中等大小。BIRT 自動調整報表條目的大小來適合其中的內容,避免每次翻譯都要進行報表測試。
擴展性
報表應用程序的范圍是十分龐大的,BIRT 團隊不能為每個應用提供很具體的特性。可利用 BIRT 腳本來擴展 BIRT,另外還可構建 BIRT 擴展插件到 BIRT 中。
數(shù)據(jù)訪問
BIRT 提供 ODA(Open Data Access) 框架來支持自定義數(shù)據(jù)訪問方法。數(shù)據(jù)訪問的范圍還包括一個獲取數(shù)據(jù)的運行時組件。也包括構建自定義查詢的自定義設計時 UI。例如,打包后的應用程序可以讓 ODA 構建數(shù)據(jù)訪問 UI 并運行在自己的數(shù)據(jù)模型中。
報表欄目
BIRT 為要表現(xiàn)的數(shù)據(jù)提供一致的報表欄目集。可以在應用程序中自定義附件報表欄目,并像 BIRT 自身的報表欄目一樣運行在設計器和引擎中。例如,性能管理應用程序要添加報表欄目來高亮顯示停止項、尺度表以及其他用來衡量性能的可視標志。
圖表類型
BIRT 圖表包提供了很多的圖表類型。但是,一些行業(yè)需要很特殊的圖表樣式。開發(fā)者可以在 BIRT 圖表引擎中創(chuàng)建圖表插件來提供這些圖表樣式。
輸出格式
BIRT 1.0.1 支持輸出到 HTML 和 PDF。當然,也可能需要其他類型輸出:Excel、RTF(Rich Text Format)、SVG(Scalable Vector Graphic)、圖像、等等。BIRT 在今后會提供其中一些,除開這些的其他格式可能需要的用戶就很少了。開發(fā)者可利用 BIRT 引擎接口添加轉換器以達到目的。
請注意!引用、轉貼本文應注明原譯者:Rosen Jiang 以及出處:http://www.aygfsteel.com/rosen
]]>
對于給定的 XML 文件,其結構如下:
| <?xml version="1.0" encoding="GBK" ?> <propertysets> <propertset name="rea_faculty" description="team"> |
為以上 XML 文件構造 Propertys 類:
| public class Propertys { private String name; private String description; private String field; public String getDescription() { public void setDescription(String description) { public String getField() { public void setField(String field) { public String getName() { public void setName(String name) { |
讀取方法(返回包含 Propertys 的列表):
| public List getAll() { List list = new ArrayList(); try { InputStream is = getClass().getResourceAsStream("/navigation.xml"); SAXReader reader = new SAXReader(); Document document = reader.read(is); Element root = document.getRootElement(); Iterator lv = root.elementIterator("propertset"); Element el = null; while (lv.hasNext()) { Propertys property=new Propertys(); el = (Element) lv.next(); property.setName(el.attributeValue("name")); property.setDescription(el.attributeValue("description")); property.setField(el.elementText("field")); list.add(property); } } catch (Exception e) { e.printStackTrace(); } return list; } |
添加新節(jié)點(成功返回 1 否則 0):
| public int saveProperty(Propertys property) { try { InputStream is = getClass().getResourceAsStream("/navigation.xml"); SAXReader reader = new SAXReader(); Document document = reader.read(is); Element root = document.getRootElement(); root.addElement("propertset") .addAttribute("name",property.getName()) .addAttribute("description",property.getDescription()) .addElement("field").addText(property.getField()); OutputFormat outformat = OutputFormat.createPrettyPrint(); outformat.setEncoding("GBK"); FileWriter out = new FileWriter( System.getProperty("user.dir") +"/web/WEB-INF/classes/navigation.xml"); XMLWriter writer=new XMLWriter(out,outformat); writer.write(document); writer.close(); return 1; } catch (Exception e) { e.printStackTrace(); } return 0; } |
更新節(jié)點(按照 name 屬性查找):
| public int updateProperty(String pro,Propertys property) { try { InputStream is = getClass().getResourceAsStream("/navigation.xml"); SAXReader reader = new SAXReader(); Document document = reader.read(is); Element root = document.getRootElement(); Iterator lv = root.elementIterator("propertset"); Element el = null; while (lv.hasNext()) { el = (Element) lv.next(); if (el.attributeValue("name").equals(pro)) { el.setAttributeValue("name",property.getName()); el.setAttributeValue("description",property.getDescription()); el.element("field").setText(property.getField()); } } OutputFormat outformat = OutputFormat.createPrettyPrint(); |
刪除節(jié)點:
| public int delProperty(String pro) { try { InputStream is = getClass().getResourceAsStream("/navigation.xml"); SAXReader reader = new SAXReader(); Document document = reader.read(is); Element root = document.getRootElement(); Iterator lv = root.elementIterator("propertset"); Element el = null; while (lv.hasNext()) { el = (Element) lv.next(); if (el.attributeValue("name").equals(pro)) { el.detach(); } } OutputFormat outformat = OutputFormat.createPrettyPrint(); |
請注意!引用、轉貼本文應注明原作者:Rosen Jiang 以及出處:http://www.aygfsteel.com/rosen
]]>
預 備
測試環(huán)境:
AMD 毒龍1.4G OC 1.5G、256M DDR333、Windows2000 Server SP4、Sun JDK 1.4.1+Eclipse 2.1+Resin 2.1.8,在 Debug 模式下測試。
XML 文件格式如下:
<?xml version="1.0" encoding="GB2312"?>
<RESULT>
<VALUE>
<NO>A1234</NO>
<ADDR>四川省XX縣XX鎮(zhèn)XX路X段XX號</ADDR>
</VALUE>
<VALUE>
<NO>B1234</NO>
<ADDR>四川省XX市XX鄉(xiāng)XX村XX組</ADDR>
</VALUE>
</RESULT>
測試方法:
采用 JSP 端調用Bean(至于為什么采用JSP來調用,請參考:http://blog.csdn.net/rosen/archive/2004/10/15/138324.aspx),讓每一種方案分別解析10K、100K、1000K、10000K的 XML 文件,計算其消耗時間(單位:毫秒)。
JSP 文件:
<%@ page contentType="text/html; charset=gb2312" %>
<%@ page import="com.test.*"%>
<html>
<body>
<%
String args[]={""};
MyXMLReader.main(args);
%>
</body>
</html>
測 試
首先出場的是 DOM(JAXP Crimson 解析器)
DOM 是用與平臺和語言無關的方式表示 XML 文檔的官方 W3C 標準。DOM 是以層次結構組織的節(jié)點或信息片斷的集合。這個層次結構允許開發(fā)人員在樹中尋找特定信息。分析該結構通常需要加載整個文檔和構造層次結構,然后才能做任何工作。由于它是基于信息層次的,因而 DOM 被認為是基于樹或基于對象的。DOM 以及廣義的基于樹的處理具有幾個優(yōu)點。首先,由于樹在內存中是持久的,因此可以修改它以便應用程序能對數(shù)據(jù)和結構作出更改。它還可以在任何時候在樹中上下導航,而不是像 SAX 那樣是一次性的處理。DOM 使用起來也要簡單得多。
另一方面,對于特別大的文檔,解析和加載整個文檔可能很慢且很耗資源,因此使用其他手段來處理這樣的數(shù)據(jù)會更好。這些基于事件的模型,比如 SAX。
Bean文件:
package com.test;
import java.io.*;
import java.util.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
public class MyXMLReader{
public static void main(String arge[]){
long lasting =System.currentTimeMillis();
try{
File f=new File("data_10k.xml");
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document doc = builder.parse(f);
NodeList nl = doc.getElementsByTagName("VALUE");
for (int i=0;i<nl.getLength();i++){
System.out.print("車牌號碼:" + doc.getElementsByTagName("NO").item(i).getFirstChild().getNodeValue());
System.out.println(" 車主地址:" + doc.getElementsByTagName("ADDR").item(i).getFirstChild().getNodeValue());
}
}catch(Exception e){
e.printStackTrace();
}
System.out.println("運行時間:"+(System.currentTimeMillis() - lasting)+" 毫秒");
}
}
10k消耗時間:265 203 219 172
100k消耗時間:9172 9016 8891 9000
1000k消耗時間:691719 675407 708375 739656
10000k消耗時間:OutOfMemoryError
接著是 SAX
這種處理的優(yōu)點非常類似于流媒體的優(yōu)點。分析能夠立即開始,而不是等待所有的數(shù)據(jù)被處理。而且,由于應用程序只是在讀取數(shù)據(jù)時檢查數(shù)據(jù),因此不需要將數(shù)據(jù)存儲在內存中。這對于大型文檔來說是個巨大的優(yōu)點。事實上,應用程序甚至不必解析整個文檔;它可以在某個條件得到滿足時停止解析。一般來說,SAX 還比它的替代者 DOM 快許多。
選擇 DOM 還是選擇 SAX ?
對于需要自己編寫代碼來處理 XML 文檔的開發(fā)人員來說,選擇 DOM 還是 SAX 解析模型是一個非常重要的設計決策。
DOM 采用建立樹形結構的方式訪問 XML 文檔,而 SAX 采用的事件模型。
DOM 解析器把 XML 文檔轉化為一個包含其內容的樹,并可以對樹進行遍歷。用 DOM 解析模型的優(yōu)點是編程容易,開發(fā)人員只需要調用建樹的指令,然后利用navigation APIs訪問所需的樹節(jié)點來完成任務。可以很容易的添加和修改樹中的元素。然而由于使用 DOM 解析器的時候需要處理整個 XML 文檔,所以對性能和內存的要求比較高,尤其是遇到很大的 XML 文件的時候。由于它的遍歷能力,DOM 解析器常用于 XML 文檔需要頻繁的改變的服務中。
SAX 解析器采用了基于事件的模型,它在解析 XML 文檔的時候可以觸發(fā)一系列的事件,當發(fā)現(xiàn)給定的tag的時候,它可以激活一個回調方法,告訴該方法制定的標簽已經找到。SAX 對內存的要求通常會比較低,因為它讓開發(fā)人員自己來決定所要處理的tag。特別是當開發(fā)人員只需要處理文檔中所包含的部分數(shù)據(jù)時,SAX 這種擴展能力得到了更好的體現(xiàn)。但用 SAX 解析器的時候編碼工作會比較困難,而且很難同時訪問同一個文檔中的多處不同數(shù)據(jù)。
Bean文件:
package com.test;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class MyXMLReader extends DefaultHandler {
java.util.Stack tags = new java.util.Stack();
public MyXMLReader() {
super();
}
public static void main(String args[]) {
long lasting = System.currentTimeMillis();
try {
SAXParserFactory sf = SAXParserFactory.newInstance();
SAXParser sp = sf.newSAXParser();
MyXMLReader reader = new MyXMLReader();
sp.parse(new InputSource("data_10k.xml"), reader);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("運行時間:" + (System.currentTimeMillis() - lasting) + " 毫秒");
}
public void characters(char ch[], int start, int length) throws SAXException {
String tag = (String) tags.peek();
if (tag.equals("NO")) {
System.out.print("車牌號碼:" + new String(ch, start, length));
}
if (tag.equals("ADDR")) {
System.out.println(" 地址:" + new String(ch, start, length));
}
}
public void startElement(
String uri,
String localName,
String qName,
Attributes attrs) {
tags.push(qName);
}
}
10k消耗時間:110 47 109 78
100k消耗時間:344 406 375 422
1000k消耗時間:3234 3281 3688 3312
10000k消耗時間:32578 34313 31797 31890 30328
然后是 JDOM http://www.jdom.org/
JDOM 的目的是成為 Java 特定文檔模型,它簡化與 XML 的交互并且比使用 DOM 實現(xiàn)更快。由于是第一個 Java 特定模型,JDOM 一直得到大力推廣和促進。正在考慮通過“Java 規(guī)范請求 JSR-102”將它最終用作“Java 標準擴展”。從 2000 年初就已經開始了 JDOM 開發(fā)。
JDOM 與 DOM 主要有兩方面不同。首先,JDOM 僅使用具體類而不使用接口。這在某些方面簡化了 API,但是也限制了靈活性。第二,API 大量使用了 Collections 類,簡化了那些已經熟悉這些類的 Java 開發(fā)者的使用。
JDOM 文檔聲明其目的是“使用 20%(或更少)的精力解決 80%(或更多)Java/XML 問題”(根據(jù)學習曲線假定為 20%)。JDOM 對于大多數(shù) Java/XML 應用程序來說當然是有用的,并且大多數(shù)開發(fā)者發(fā)現(xiàn) API 比 DOM 容易理解得多。JDOM 還包括對程序行為的相當廣泛檢查以防止用戶做任何在 XML 中無意義的事。然而,它仍需要您充分理解 XML 以便做一些超出基本的工作(或者甚至理解某些情況下的錯誤)。這也許是比學習 DOM 或 JDOM 接口都更有意義的工作。
JDOM 自身不包含解析器。它通常使用 SAX2 解析器來解析和驗證輸入 XML 文檔(盡管它還可以將以前構造的 DOM 表示作為輸入)。它包含一些轉換器以將 JDOM 表示輸出成 SAX2 事件流、DOM 模型或 XML 文本文檔。JDOM 是在 Apache 許可證變體下發(fā)布的開放源碼。
Bean文件:
package com.test;
import java.io.*;
import java.util.*;
import org.jdom.*;
import org.jdom.input.*;
public class MyXMLReader {
public static void main(String arge[]) {
long lasting = System.currentTimeMillis();
try {
SAXBuilder builder = new SAXBuilder();
Document doc = builder.build(new File("data_10k.xml"));
Element foo = doc.getRootElement();
List allChildren = foo.getChildren();
for(int i=0;i<allChildren.size();i++) {
System.out.print("車牌號碼:" + ((Element)allChildren.get(i)).getChild("NO").getText());
System.out.println(" 車主地址:" + ((Element)allChildren.get(i)).getChild("ADDR").getText());
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("運行時間:" + (System.currentTimeMillis() - lasting) + " 毫秒");
}
}
10k消耗時間:125 62 187 94
100k消耗時間:704 625 640 766
1000k消耗時間:27984 30750 27859 30656
10000k消耗時間:OutOfMemoryError
最后是 DOM4J http://dom4j.sourceforge.net/
雖然 DOM4J 代表了完全獨立的開發(fā)結果,但最初,它是 JDOM 的一種智能分支。它合并了許多超出基本 XML 文檔表示的功能,包括集成的 XPath 支持、XML Schema 支持以及用于大文檔或流化文檔的基于事件的處理。它還提供了構建文檔表示的選項,它通過 DOM4J API 和標準 DOM 接口具有并行訪問功能。從 2000 下半年開始,它就一直處于開發(fā)之中。
為支持所有這些功能,DOM4J 使用接口和抽象基本類方法。DOM4J 大量使用了 API 中的 Collections 類,但是在許多情況下,它還提供一些替代方法以允許更好的性能或更直接的編碼方法。直接好處是,雖然 DOM4J 付出了更復雜的 API 的代價,但是它提供了比 JDOM 大得多的靈活性。
在添加靈活性、XPath 集成和對大文檔處理的目標時,DOM4J 的目標與 JDOM 是一樣的:針對 Java 開發(fā)者的易用性和直觀操作。它還致力于成為比 JDOM 更完整的解決方案,實現(xiàn)在本質上處理所有 Java/XML 問題的目標。在完成該目標時,它比 JDOM 更少強調防止不正確的應用程序行為。
DOM4J 是一個非常非常優(yōu)秀的Java XML API,具有性能優(yōu)異、功能強大和極端易用使用的特點,同時它也是一個開放源代碼的軟件。如今你可以看到越來越多的 Java 軟件都在使用 DOM4J 來讀寫 XML,特別值得一提的是連 Sun 的 JAXM 也在用 DOM4J。
Bean文件:
package com.test;
import java.io.*;
import java.util.*;
import org.dom4j.*;
import org.dom4j.io.*;
public class MyXMLReader {
public static void main(String arge[]) {
long lasting = System.currentTimeMillis();
try {
File f = new File("data_10k.xml");
SAXReader reader = new SAXReader();
Document doc = reader.read(f);
Element root = doc.getRootElement();
Element foo;
for (Iterator i = root.elementIterator("VALUE"); i.hasNext();) {
foo = (Element) i.next();
System.out.print("車牌號碼:" + foo.elementText("NO"));
System.out.println(" 車主地址:" + foo.elementText("ADDR"));
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("運行時間:" + (System.currentTimeMillis() - lasting) + " 毫秒");
}
}
10k消耗時間:109 78 109 31
100k消耗時間:297 359 172 312
1000k消耗時間:2281 2359 2344 2469
10000k消耗時間:20938 19922 20031 21078
THE END
JDOM 和 DOM 在性能測試時表現(xiàn)不佳,在測試 10M 文檔時內存溢出。在小文檔情況下還值得考慮使用 DOM 和 JDOM。雖然 JDOM 的開發(fā)者已經說明他們期望在正式發(fā)行版前專注性能問題,但是從性能觀點來看,它確實沒有值得推薦之處。另外,DOM 仍是一個非常好的選擇。DOM 實現(xiàn)廣泛應用于多種編程語言。它還是許多其它與 XML 相關的標準的基礎,因為它正式獲得 W3C 推薦(與基于非標準的 Java 模型相對),所以在某些類型的項目中可能也需要它(如在 JavaScript 中使用 DOM)。
SAX表現(xiàn)較好,這要依賴于它特定的解析方式。一個 SAX 檢測即將到來的XML流,但并沒有載入到內存(當然當XML流被讀入時,會有部分文檔暫時隱藏在內存中)。
無疑,DOM4J是這場測試的獲勝者,目前許多開源項目中大量采用 DOM4J,例如大名鼎鼎的 Hibernate 也用 DOM4J 來讀取 XML 配置文件。如果不考慮可移植性,那就采用DOM4J吧!
參考文獻:
http://www-900.ibm.com/developerWorks/cn/xml/x-injava/index.shtml
http://www-900.ibm.com/developerWorks/cn/xml/x-injava2/index.shtml
請注意!引用、轉貼本文應注明原作者:Rosen Jiang 以及出處:http://www.aygfsteel.com/rosen
]]>
這時候就需要截取我們所需要的長度,后面顯示省略號或其他字符。
由于中文字符占兩個字節(jié),而英文字符占用一個字節(jié),所以,單純地判斷字符數(shù),效果往往不盡如人意
下面的方法通過判斷字符的類型來進行截取,效果還算可以:)
如果大家有其他的解決方法歡迎貼出來,共同學習:)
**********************************************************************
private String str;
private int counterOfDoubleByte;
private byte b[];
/**
* 設置需要被限制長度的字符串
* @param str 需要被限制長度的字符串
*/
public void setLimitLengthString(String str){
this.str = str;
}
/**
* @param len 需要顯示的長度(<font color="red">注意:長度是以byte為單位的,一個漢字是2個byte</font>)
* @param symbol 用于表示省略的信息的字符,如“...”,“>>>”等。
* @return 返回處理后的字符串
*/
public String getLimitLengthString(int len, String symbol) throws UnsupportedEncodingException {
counterOfDoubleByte = 0;
b = str.getBytes("GBK");
if(b.length <= len)
return str;
for(int i = 0; i < len; i++){
if(b[i] < 0)
counterOfDoubleByte++;
}
if(counterOfDoubleByte % 2 == 0)
return new String(b, 0, len, "GBK") + symbol;
else
return new String(b, 0, len - 1, "GBK") + symbol;
}
本文轉貼自網友:focus2004 的文章
]]>
-----------------------------------------------------------------------------
在一個類中,有一個叫做test()的方法需要被JSP端調用(test()主要任務是System.out.print()),于是在test()方法開始的地方加上"long lasting =System.currentTimeMillis(),"在結束的地方加上"System.out.println("運行時間:"+(System.currentTimeMillis() - lasting)+" 毫秒")"。
然后把test()方法改成main()方法,以便單獨測試類,JSP端代碼作出相應調整以便訪問main()方法。奇怪的事情發(fā)生了,經過反復測試,使用JSP訪問main()方法消耗的時間為 451 毫秒,而單獨運行這個類消耗的時間為 2864 毫秒。
為什么會這樣?是不是WEB容器的原因呢?
-----------------------------------------------------------------------------
在一個人氣很高的論壇上,我得到些解答,自己也總結了一些,請各位看官來發(fā)表意見:
第一次請求JSP時,WEB容器將JSP發(fā)送到編譯器,編譯成Servlet。然后把Servlet和其他類(比如自己寫的類)緩存在WEB容器中,再放入內存常駐,最后將響應結果返回給客戶端;而JSP的所有后繼請求,WEB容器將自動載入緩存,除非JSP或者類經過修改,否則WEB容器將不會重新執(zhí)行編譯并構造緩存。而單獨運行類就不一樣了,由于沒有WEB容器緩存支持,每次運行都需要重新編譯再讀入內存才行,所以要慢些了。
另外,根據(jù)測試,在JSP端第一次被調用的時候,時間和單獨運行類差不多,這也印證了上面的解釋吧。
附上源程序
類:
package com.test;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class MyXMLReader extends DefaultHandler{
java.util.Stack tags=new java.util.Stack();
public MyXMLReader(){
super();
}
public static void main(String args[]){
long lasting =System.currentTimeMillis();
try{
SAXParserFactory sf = SAXParserFactory.newInstance();
SAXParser sp = sf.newSAXParser();
MyXMLReader reader = new MyXMLReader();
sp.parse(new InputSource("data.xml"),reader);
}
catch(Exception e){
e.printStackTrace();
}
System.out.println("運行時間:"+(System.currentTimeMillis() - lasting)+" 毫秒");
}
public void characters (char ch[], int start, int length)
throws SAXException
{
//從棧中得到當前節(jié)點的信息
String tag=(String) tags.peek();
if(tag.equals("NO") ){
System.out.print("車牌號碼:" + new String(ch,start,length));
}
if(tag.equals("ADDR")){
System.out.println(" 地址:" + new String(ch,start,length));
}
}
public void startElement(String uri, String localName, String qName, Attributes attrs){
tags.push(qName);
}
}
JSP:
<%@ page contentType="text/html; charset=gb2312" %>
<%@ page import="com.test.*"%>
<%
long lasting =System.currentTimeMillis();
%>
<html>
<body>
<%
String args[]={""};
MyXMLReader.main(args);
%>
</body>
</html>
請注意!引用、轉貼本文應注明原作者:Rosen Jiang 以及出處:http://www.aygfsteel.com/rosen
]]>
????
???????在任何一個綜合性網站,我們往往需要上傳一些圖片資料。但隨著高分辨率DC的普及,上傳的圖片容量會很大,比如300萬象素DC出來的文件基本不下600K。為了管理方便,大家可能不愿意每次都用ACDsee修改它,而直接上傳到服務器。但是這種做法在客戶端看來就沒有那么輕松了,對于撥號上網的用戶簡直是一場惡夢,雖然你可以在圖片區(qū)域設置wide和high!
???
?????? 上一篇文章中(http://www.aygfsteel.com/rosen/archive/2007/06/12/9940.html)我主要介紹了JPG(JEPG)、GIF、PNG圖像的讀取及壓縮方法,遺憾的是不支持BMP圖像。本文一鼓作氣、再接再厲,一舉解決了這個問題!
???
程序代碼
package BMP;
import java.awt.Image;
import java.awt.Toolkit;
import java.awt.image.BufferedImage;
import java.awt.image.MemoryImageSource;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import com.sun.image.codec.jpeg.JPEGCodec;
import com.sun.image.codec.jpeg.JPEGImageEncoder;
public class BMPReader{
??? public String Reader(){?
??????? Image image;??????????????????????????????????? //構造一個目標圖
??????? String result="";?????????????????????????????? //返回結果
?try{
???? FileInputStream fs=new FileInputStream("/test.BMP");
???? int bflen=14;???????????????????????????
???? byte bf[]=new byte[bflen];????????????
???? fs.read(bf,0,bflen);?????????????????????? //讀取14字節(jié)BMP文件頭
???? int bilen=40;?????????????????
???? byte bi[]=new byte[bilen];
???? fs.read(bi,0,bilen);?????????????????????? //讀取40字節(jié)BMP信息頭
???? // 獲取一些重要數(shù)據(jù)
???? int nwidth=(((int)bi[7]&0xff)<<24)???????? //源圖寬度
???? | (((int)bi[6]&0xff)<<16)
???? | (((int)bi[5]&0xff)<<8)
???? | (int)bi[4]&0xff;
???? System.out.println("寬:"+nwidth);
??????????? int nheight=(((int)bi[11]&0xff)<<24)?????? //源圖高度
???? | (((int)bi[10]&0xff)<<16)
???? | (((int)bi[9]&0xff)<<8)
???? | (int)bi[8]&0xff;
???? System.out.println("高:"+nheight);
??????????? //位數(shù)
???? int nbitcount=(((int)bi[15]&0xff)<<8) | (int)bi[14]&0xff;
???? System.out.println("位數(shù):"+nbitcount);
??????????? //源圖大小
???? int nsizeimage=(((int)bi[23]&0xff)<<24)
???? | (((int)bi[22]&0xff)<<16)
???? | (((int)bi[21]&0xff)<<8)
???? | (int)bi[20]&0xff;
???? System.out.println("源圖大小:"+nsizeimage);
??????????? //對24位BMP進行解析
???? if(nbitcount==24){
???????? int npad=(nsizeimage/nheight)-nwidth*3;
???????? int ndata[]=new int[nheight*nwidth];
???????? byte brgb[]=new byte[(nwidth+npad)*3*nheight];
???????? fs.read (brgb,0,(nwidth+npad)*3*nheight);
???????? int nindex=0;
???????? for(int j=0;j<nheight;j++){
????? for(int i=0;i<nwidth;i++){
???????????????? ndata [nwidth*(nheight-j-1)+i]=
????????? (255&0xff)<<24
????????? | (((int)brgb[nindex+2]&0xff)<<16)
????????? | (((int)brgb[nindex+1]&0xff)<<8)
????????? | (int)brgb[nindex]&0xff;
???????????????? nindex+=3;
??????????? }
???? nindex+=npad;
??????????????? }
??Toolkit kit=Toolkit.getDefaultToolkit();
??image=kit.createImage(new MemoryImageSource(nwidth,nheight,
????? ndata,0,nwidth));
??????????????? result="從BMP得到圖像image";
??????????????? System.out.println("從BMP得到圖像image");
???? }else{
???????? result="不是24位BMP,失敗!";
??????????????? System.out.println("不是24位BMP,失敗!");
???????? image=(Image)null;
???? }
??????????? fs.close();??????? //關閉輸入流
???????????
??????????? //開始進行圖像壓縮(對image對象進行操作)
???? int wideth=image.getWidth(null);?????????????????????????????????? //得到源圖寬
???? int height=image.getHeight(null);????????????????????????????????? //得到源圖長
???? BufferedImage tag=new BufferedImage(wideth/2,height/2,BufferedImage.TYPE_INT_RGB);
???? tag.getGraphics().drawImage(image,0,0,wideth/2,height/2,null);???? //繪制縮小后的圖
???? FileOutputStream out=new FileOutputStream("/newfile.jpg");???????? //輸出到文件流
???? JPEGImageEncoder encoder=JPEGCodec.createJPEGEncoder(out);?????
???? encoder.encode(tag);?????????????????????????????????????????????? //進行JPEG編碼
???? out.close();?????? //關閉輸出流?????????????????????
?}catch (Exception e){
???? System.out.println(e);
??????? }
??????? return result;
??? }
}
??? 相信代碼部分應該沒有什么問題吧?通過以下方法,你可以得到更多的信息:
?????? //得到壓縮值
??????? int ncompression = (((int)bi[19])<<24)
??????? | (((int)bi[18])<<16)
??????? | (((int)bi[17])<<8)
??????? | (int)bi[16];
??????? System.out.println("壓縮:"+ncompression);
???????//象素情況
??????? int nxpm = (((int)bi[27]&0xff)<<24)
??????? | (((int)bi[26]&0xff)<<16)
??????? | (((int)bi[25]&0xff)<<8)
??????? | (int)bi[24]&0xff;
??????? System.out.println("X-象素/米:"+nxpm);
??????? int nypm = (((int)bi[31]&0xff)<<24)
??????? | (((int)bi[30]&0xff)<<16)
??????? | (((int)bi[29]&0xff)<<8)
??????? | (int)bi[28]&0xff;
??????? System.out.println("Y-象素/米:"+nypm);
?????? //顏色使用情況
??????? int nclrused = (((int)bi[35]&0xff)<<24)
??????? | (((int)bi[34]&0xff)<<16)
??????? | (((int)bi[33]&0xff)<<8)
??????? | (int)bi[32]&0xff;
??????? System.out.println("顏色使用數(shù):"+nclrused);
??????? int nclrimp = (((int)bi[39]&0xff)<<24)
??????? | (((int)bi[38]&0xff)<<16)
??????? | (((int)bi[37]&0xff)<<8)
??????? | (int)bi[36]&0xff;
??????? System.out.println("顏色顯要:"+nclrimp);
??????? int nplanes = (((int)bi[13]&0xff)<<8) | (int)bi[12]&0xff;
??????? System.out.println("位面:"+nplanes);
???????//信息頭中的圖像大小
??????? int nbisize = (((int)bi[3]&0xff)<<24)?
??????? | (((int)bi[2]&0xff)<<16)
??????? | (((int)bi[1]&0xff)<<8)
??????? | (int)bi[0]&0xff;
??????? System.out.println("BMP信息頭大小:"+nbisize);
?????? //文件大小及種類
??????? int nsize=(((int)bf[5]&0xff)<<24)??????
?????????????? | (((int)bf[4]&0xff)<<16)
??????? | (((int)bf[3]&0xff)<<8)
??????? | (int)bf[2]&0xff;
??????? System.out.println("文件種類:"+(char)bf[0]+(char)bf[1]);
??????? System.out.println("文件大小:"+nsize);
???????
后記
?????? 可以通過變量nbitcount來判斷是否是8位位圖并作出相應處理。限于目前24位位圖應用較為廣泛,所以沒有寫出相應代碼,如有需要可查閱Jeff West與John D.Mitchell之著作《How to read 8- and 24-bit Microsoft Windows bitmaps in Java applications》。
?????? 在此,我謹慎的表示:因為位圖(BMP)沒有經過壓縮,所以對于源圖的容量幾乎沒有限制,不會出現(xiàn)內存不足的情況。
???
?????? 在寫這篇文章時我只進行了9M左右BMP的讀取,其實大家有興趣的話可以利用50M左右的TIF圖轉換為BMP(幾乎還是50M)來做試驗。并歡迎上來指正。
請注意!引用、轉貼本文應注明原作者:Rosen Jiang 以及出處:http://www.aygfsteel.com/rosen
]]>
通過本文,你將能了解到如何配置服務以及Google WebService的語法結構;怎樣個性化你的搜索,例如:國家、語言;怎樣提煉搜索結果。
Google目前已經成了Web上最流行的搜索引擎,為了讓諸如new content watchdog、GUI搜索工具和模式分析之類的應用程序成為可能,現(xiàn)在它們?yōu)?0億個頁面建立了索引,開發(fā)者們可以通過基于SOAP的API進行調用。
WebService 簡介
Web應用的巨大成功和不斷發(fā)展,使其滲透到商業(yè)領域和個人生活的各個方面。人們只要使用瀏覽器,就可以享受到各種各樣的Web服務,例如網上購物,網上交易,網絡游戲,預定車票,網上聊天和交友等等。與此同時,由于Web技術所帶來的優(yōu)勢(統(tǒng)一的客戶端和較好的維護性),使一些傳統(tǒng)的應用紛紛轉型到基于B/S架構的瘦客戶端應用程序,這是因為它能夠避免花在桌面應用程序發(fā)布上的高成本,也能夠很好的解決客戶和服務器之間的通信問題。在客戶端和服務器之間的通信,一個完美的解決方案是使用HTTP協(xié)議來通信。這是因為任何運行Web瀏覽器的機器都使用HTTP協(xié)議,可以很好地透過防火墻進行通信。許多商業(yè)程序還面臨另一個問題,那就是與其他程序的互操作性。目前有很多商業(yè)數(shù)據(jù)仍然在大型主機上以非關系文件(VSAM)的形式存放,并由COBOL語言編寫的大型機程序訪問。而且,還有很多商業(yè)程序使用C++、JAVA、VB和其他各種各樣的語言編寫。現(xiàn)在初了最簡單的程序之外,所有的程序都需要與運行在其他異構平臺上的應用程序集成并進行數(shù)據(jù)交換。在以前,沒有一個應用程序通信標準是獨立于平臺、組建模型和編程語言的。只有通過Web Service、客戶端和服務器才能夠自由的用HTTP進行通信,不論兩個程序的平臺和編程語言是什么。Web Service技術完全基于標準的技術,只有基于標準,所有的開放廠商才能有相同的標準,才能夠在各自的平臺上開發(fā)出具有跨平臺互操作能力的軟件產品和解決方案。標準時達成跨平臺互操作能力的靈魂。
Web是為了程序到用戶的交互,而Web Service是為程序到程序的交互做準備。Web Service使公司可以降低進行電子商務的成本、更快的部署解決方案以及開拓新機遇。達到這個目標的關鍵在于通用的程序到程序通信模型,該模型應建立在現(xiàn)有的和新興的標準之上。其中包括:HTTP,SOAP, WSDL, UDDI
SOAP:是“Simple Object Access Protocol”的縮寫,SOAP是消息傳遞的協(xié)議,它規(guī)定了Web Services之間是怎樣傳遞信息的。
簡單的說,SOAP規(guī)定了:
1. 傳遞信息的格式為XML。這就使Web Services能夠在任何平臺上,用任何語言進行實現(xiàn)。
2. 遠程對象方法調用的格式。規(guī)定了怎樣表示被調用對象以及調用的方法名稱和參數(shù)類型等。
3. 參數(shù)類型和XML格式之間的映射。這是因為,被調用的方法有時候需要傳遞一個復雜的參數(shù),例如,一個Person對象。怎樣用XML來表示一個對象參數(shù),也是SOAP所定義的范圍。
WSDL:是“Web Services Description Language”的縮寫。WSDL是Web Services的定義語言。當實現(xiàn)了某種服務的時候(如:股票查詢服務),為了讓別的程序調用,必須告訴大家服務接口。例如:服務名稱,服務所在的機器名稱,監(jiān)聽端口號,傳遞參數(shù)的類型,個數(shù)和順序,返回結果的類型等等。這樣別的應用程序才能調用該服務。WSDL協(xié)議就是規(guī)定了有關Web Services描述的標準。
UDDI:是“Universal Description, Discovery,and Integration”的縮寫。簡單說,UDDI用于集中存放和查找WSDL描述文件,起著目錄服務器的作用。
快速安裝
本文的運行環(huán)境是JDK1.3+Tomcat4.0+JSP。要使用Google的服務,必須要有“l(fā)icense key”,可以在https://www.google.com/accounts/NewAccount?continue=http://api.google.com/createkey&followup=http://api.google.com/createkey中取得,輸入相應的信息,然后到你的郵箱收取“l(fā)icense key”。接著還需要“Java API for XML Messaging”亦即“JAXM”。它是Java XML Pack的一部分,在http://java.sun.com/xml/downloads/javaxmlpack.html提供。
為了更簡單的表達,我直接用JSP模式,并使用手工編碼,沒有用IDE環(huán)境。
解開剛才下載的java_xml_pack-summer02_01.zip,找到java_xml_pack-summer-02_01\jaxp-1.2_01\xalan.jar文件,用WinRAR解開把org文件夾拷貝到你的應用程序的WEB-INF\classes下。找到java_xml_pack-summer-02_01\jaxm-1.1_01\lib\saaj-api.jar文件,解開它并拷貝javax文件夾到同上的目錄。找到java_xml_pack-summer-02_01\jaxm-1.1_01\lib\jaxm-api.jar文件,解開它并拷貝javax文件夾到相同目錄。找到java_xml_pack-summer-02_01\jaxp-1.2_01\jaxp-api.jar文件,解開它并拷貝javax文件夾到相同目錄。找到java_xml_pack-summer-02_01\jaxm-1.1_01\jaxm\saaj-ri.jar文件,解開并拷貝com文件夾到相同目錄。
程序源代碼
<%@ page contentType="text/html;charset=gb2312"%>
<%@ page import="org.apache.xalan.processor.TransformerFactoryImpl"%>
<%@ page import="javax.xml.soap.SOAPConnectionFactory"%>
<%@ page import="javax.xml.soap.SOAPConnection"%>
<%@ page import="javax.xml.soap.MessageFactory"%>
<%@ page import="javax.xml.soap.SOAPMessage"%>
<%@ page import="javax.xml.soap.SOAPPart"%>
<%@ page import="javax.xml.soap.SOAPEnvelope"%>
<%@ page import="javax.xml.soap.SOAPBody"%>
<%@ page import="javax.xml.soap.SOAPElement"%>
<%@ page import="java.io.FileInputStream"%>
<%@ page import="javax.xml.transform.stream.StreamSource"%>
<%@ page import="javax.xml.messaging.URLEndpoint"%>
<%@ page import="javax.xml.transform.TransformerFactory"%>
<%@ page import="javax.xml.transform.Transformer"%>
<%@ page import="javax.xml.transform.Source"%>
<%@ page import="javax.xml.transform.stream.StreamResult"%>
<html>
<head>
<title>google WebService</title>
</head>
<%
try {
//首先建立一個連接
SOAPConnectionFactory soapConnFactory =
SOAPConnectionFactory.newInstance();
SOAPConnection connection =
soapConnFactory.createConnection();
//接著,創(chuàng)建消息
MessageFactory messageFactory=MessageFactory.newInstance();
SOAPMessage message=messageFactory.createMessage();
//為消息部份創(chuàng)建SOAP對象
SOAPPart soapPart=message.getSOAPPart();
//組裝信息,根據(jù)C盤根目錄下search.msg文件進行搜索
StreamSource preppedMsgSrc=new StreamSource(new FileInputStream("/search.msg"));
soapPart.setContent(preppedMsgSrc);
//保存消息
message.saveChanges();
//發(fā)送到目標地址
URLEndpoint destination=
new URLEndpoint("http://api.google.com/search/beta2");
//發(fā)送消息
SOAPMessage reply=connection.call(message, destination);
//保存輸出,建立傳出信息
TransformerFactory transformerFactory =
TransformerFactory.newInstance();
//根據(jù)樣式文件translate.xsl進行解析
Source styleSheet=new StreamSource("/translate.xsl");
Transformer transformer=
transformerFactory.newTransformer(styleSheet);
//提取收到的內容
Source sourceContent=reply.getSOAPPart().getContent();
//建立輸出文件results.out
StreamResult result=new StreamResult("/results.out");
transformer.transform(sourceContent, result);
out.println("文件已生成C:\results.out");
//關閉連接
connection.close();
}catch(Exception e){
System.out.println(e.getMessage());
}
%>
</body>
</html>
源代碼部分完全按照Google的規(guī)定進行編寫,程序注解部分也在其中,這里就不羅嗦了。
搜索格式
<?xml version='1.0' encoding='UTF-8'?>
<SOAP-ENV:Envelope
xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsi="http://www.w3.org/1999/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/1999/XMLSchema">
<SOAP-ENV:Body>
<ns1:doGoogleSearch xmlns:ns1="urn:GoogleSearch"
SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<key xsi:type="xsd:string">00000000000000000000000000000000</key>
<q xsi:type="xsd:string">CSDN論壇</q>
<start xsi:type="xsd:int">0</start>
<maxResults xsi:type="xsd:int">10</maxResults>
<filter xsi:type="xsd:boolean">false</filter>
<restrict xsi:type="xsd:string"></restrict>
<safeSearch xsi:type="xsd:boolean">false</safeSearch>
<lr xsi:type="xsd:string"></lr>
<ie xsi:type="xsd:string">latin1</ie>
<oe xsi:type="xsd:string">latin1</oe>
</ns1:doGoogleSearch>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
search.msg文件標簽<<key></key>之前的為固定格式,無需費心。標簽<key>就是本文第一部分所提到的“l(fā)icense key”,直接復制過來。標簽<q>是指具體要搜索的內容。標簽<start>是指從第幾個開始搜索。標簽<maxResults>是指每次返回搜索結果的最大值,Google WebService規(guī)定,最大值只能是“10”。標簽<filter>是指過濾掉結果中相似和域名相同的結果。標簽<restrict>是指國家和主題的約束,例如要限制只在國內搜索,就需要輸入countryCN;要限制只在Linux主題內搜索,就輸入linux。標簽<safeSearch>過濾掉成人信息。標簽<lr>搜索的語言,例如只搜索簡體中文,就要輸入lang_zh-CN。標簽<ie>和<oe>分別指輸入和輸出的編碼格式默認為latin1(UTF-8)。
解析格式
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:apply-templates select="http://item"/>
</xsl:template>
<xsl:template match="item">
<xsl:value-of select="title" disable-output-escaping="yes"/>
<xsl:text>
</xsl:text>
<xsl:value-of select="URL"/>
<xsl:text>
</xsl:text>
<xsl:value-of select="summary"/>
</xsl:template>
</xsl:stylesheet>
translate.xsl文件。我們從<xsl:value-of select="title" disable-output-escaping="yes"/>這一句開始,select="title"確定了返回結果的第一部分為標題。接下來,select="URL"解析出URL地址。<xsl:text></xsl:text>暫且理解為換行標簽吧。select="summary"解析出摘要。還有一些標簽,詳情請參考“Google Web APIs Reference”。
后 記
程序運行以后所產生的結果results.out請大家自己去查看,在這里就不一一列舉了。
創(chuàng)作這篇文章的目的純屬個人愛好,完全是對Google引擎的一種喜愛。文章不是很有深度,希望能給各位起到拋磚引玉的作用我就滿足了,更加豐富的功能還有待我們去探索!
請注意!引用、轉貼本文應注明原作者:Rosen Jiang 以及出處:http://www.aygfsteel.com/rosen
]]>