Posted on 2014-05-31 14:30
tangtb 閱讀(2543)
評論(0) 編輯 收藏 所屬分類:
Hadoop

之前漏掉了一些小細節,已經補上,不再修改內容,請直接下載附件
1. 安裝環境
1) 操作系統

2) SSH連接工具:XShell及XManager
新建連接:點擊窗口左上方“新建”按鈕,在彈出窗口填寫名稱(自定義)及主機IP,如下圖所示:

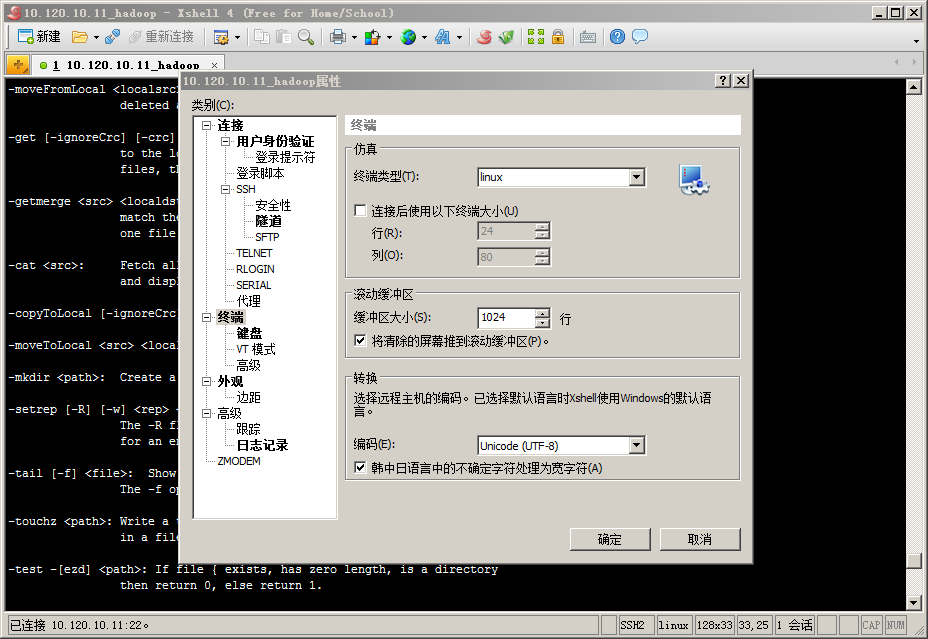
設置中文顯示(中文亂碼):選擇彈出窗口左側“終端”菜單,右側“終端類型”選擇“linux”,“編碼”選擇“UTF-8”,如下圖所示:
設置使用XManager:選擇彈出窗口左側“隧道”菜單,右側”X11轉移”選中“Xmanager”,如下圖所示:‘

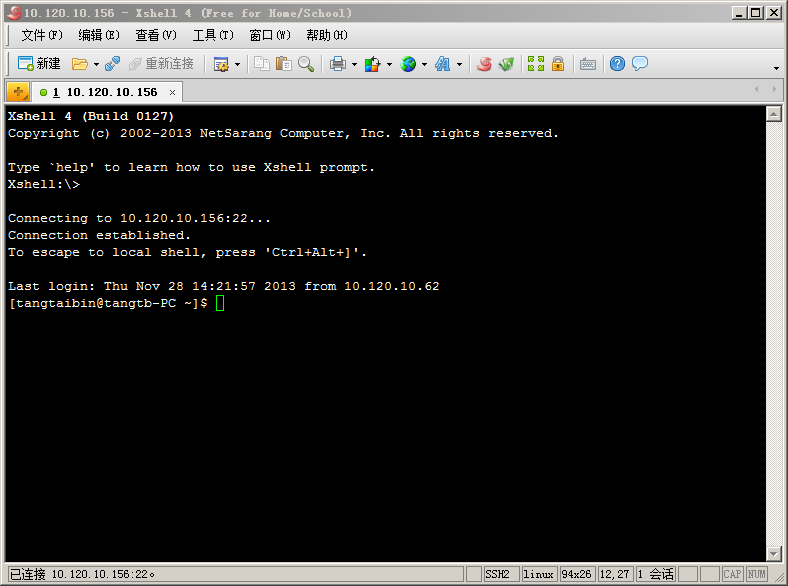
點擊“確定”,輸入用戶名和密碼,進入終端命令行,如下圖所示:
3) 配置SecureCRTSecureFX
點擊左上角”快速連接”快捷按鈕,填寫“主機名”和用戶名,點擊“連接”按鈕,輸入用戶名對應密碼,如下圖所示:
選擇“視圖”菜單下的“本地窗口”,左側顯示本地目錄,右側為服務器目錄,如下圖所示:
2. 安裝配置JDK
1) 安裝JDK

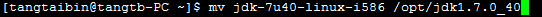

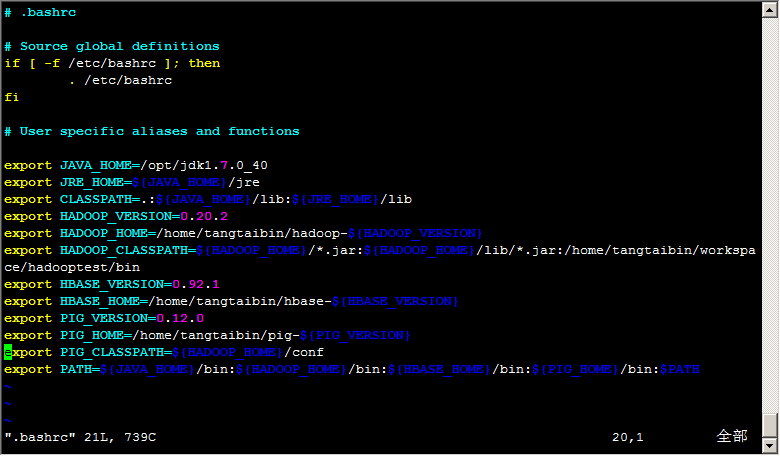
2) 設置環境變量:vim .bashrc

3. 安裝配置Hadoop (單一節點)
1) 配置ssh免密碼及環境準備
生成公鑰:ssh-keygen -t rsa
添加公鑰到authorized_keys文件:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
解壓Hadoop安裝包:tar –zxvf hadoop-0.20.2.tar.gz
2) 配置Hadoop環境變量:vim .bashrc
3) 修改Hadoop配置文件
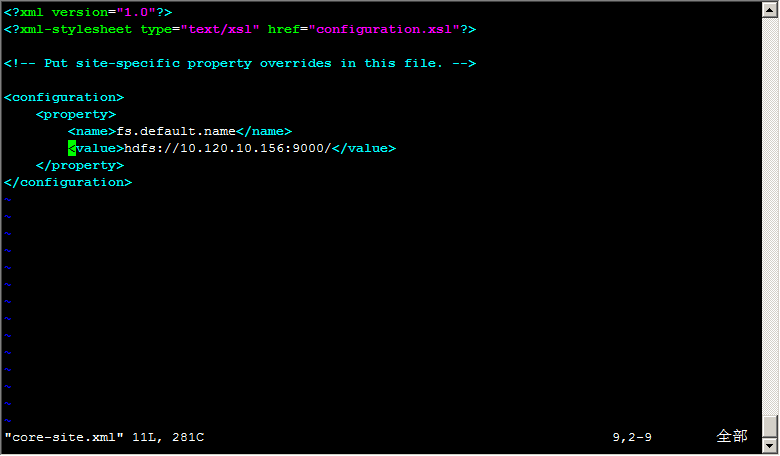
編輯:vim core-site.xml
編輯:vim mapred-site.xml

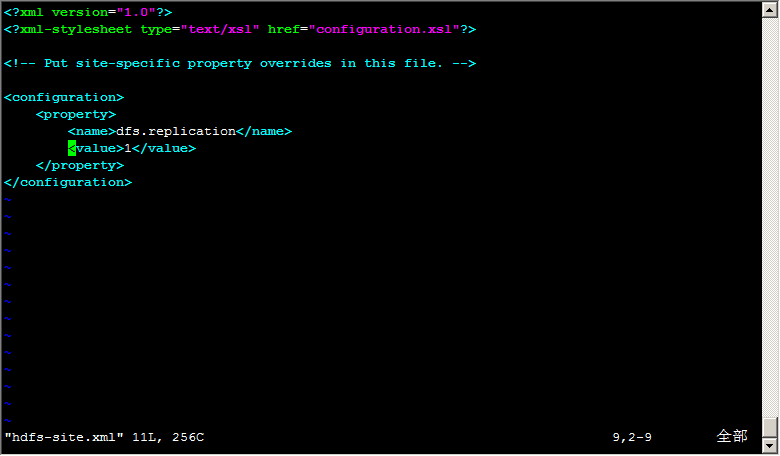
編輯:vim hdfs-site.xml
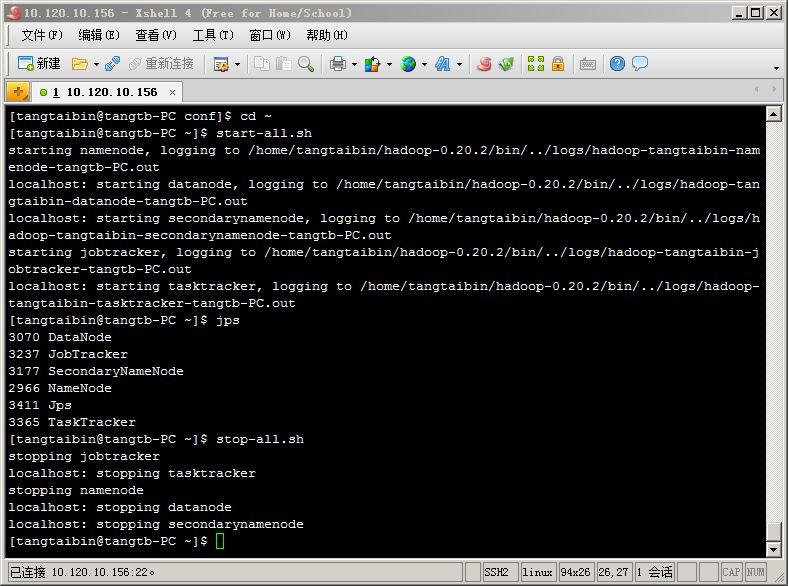
4. 啟動/停止Hadoop
5. 安裝配置Hadoop (多節點,非生成環境,不使用DNS和NFS)
1) 配置ssh免密碼
生成公鑰:ssh-keygen -t rsa
添加公鑰到authorized_keys文件:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
注意:以上操作需要在每個節點執行,并將各自的公鑰添加到authorized_keys文件
2) 配置Hadoop環境變量:vim .bashrc
同3.2
3) 修改Hadoop配置文件
同3.3
在HADOOP_HOME/conf目錄下的masters文件中添加SecondaryNameNode節點地址,slaves文件中添加TaskTracker和DataNode節點地址
4) 向各節點復制Hadoop
生成批量拷貝腳本
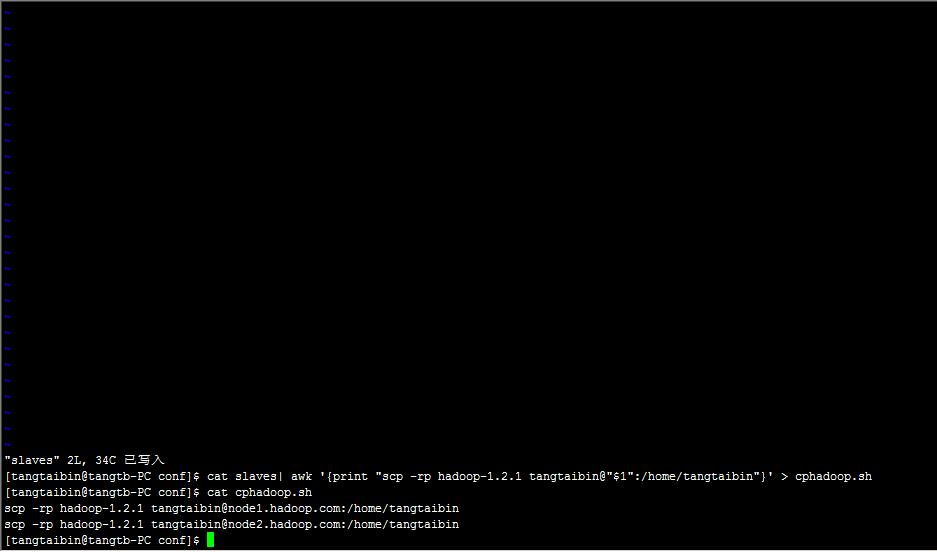
給腳本添加可執行權限
[tangtaibin@tangtb-PC conf]$ chmod 755 cphadoop.sh
拷貝完畢,格式化文件系統并啟動集群
[tangtaibin@tangtb-PC hadoop-1.2.1]$ bin/hadoop namenode -format
[tangtaibin@tangtb-PC hadoop-1.2.1]$ bin/start-all.sh
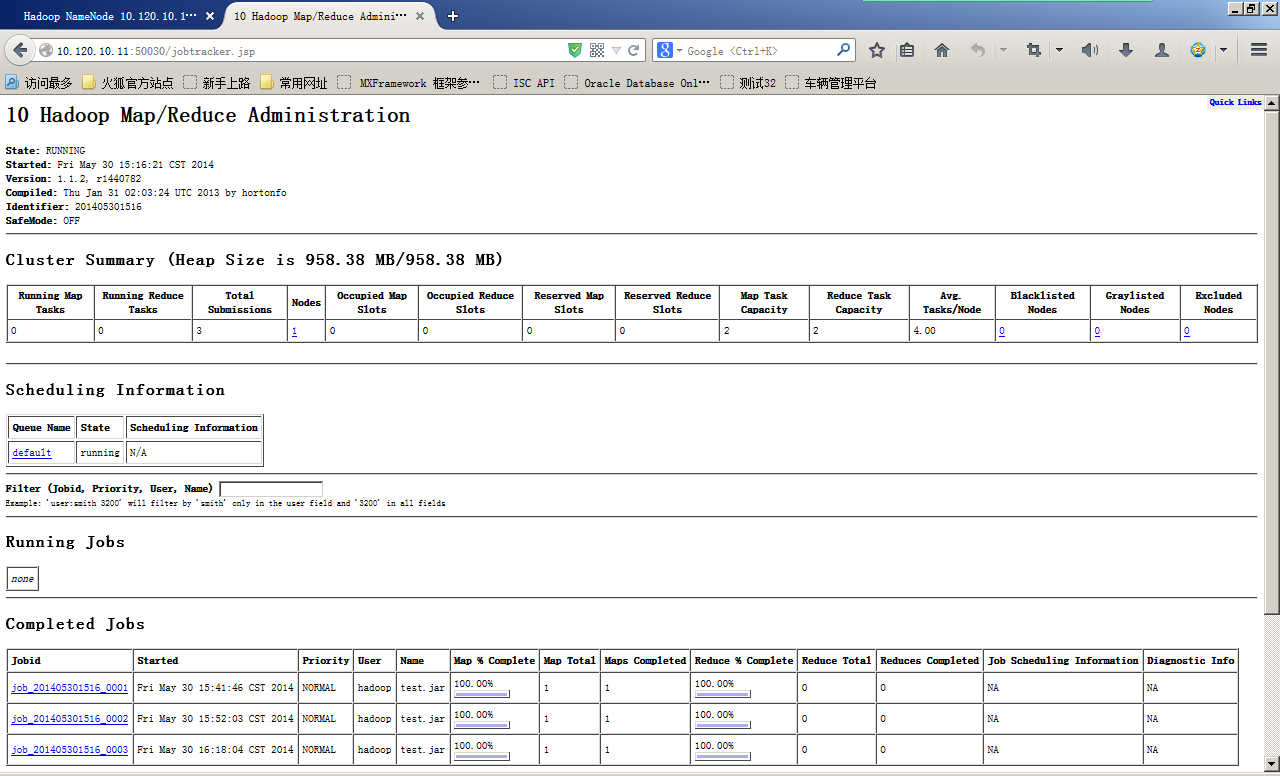
從Web頁面監控Hadoop集群及Map/Reduce任務
http://10.120.10.11:50070/dfshealth.jsp

http://10.120.10.11:50030/jobtracker.jsp