v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VML);} .shape {behavior:url(#default#VML);}
細(xì)節(jié)優(yōu)化提升資源利用率
Author: 放翁(文初)
Email: fangweng@taobao.com
Mblog:weibo.com/fangweng
這里通過(guò)介紹對(duì)于淘寶開(kāi)放平臺(tái)基礎(chǔ)設(shè)置之一的TOPAnalyzer的代碼優(yōu)化,來(lái)談一下對(duì)于海量數(shù)據(jù)處理的Java應(yīng)用可以共享的一些細(xì)節(jié)設(shè)計(jì)(一個(gè)系統(tǒng)能夠承受的處理量級(jí)別往往取決于細(xì)節(jié),一個(gè)系統(tǒng)能夠支持的業(yè)務(wù)形態(tài)往往取決于設(shè)計(jì)目標(biāo))。
先介紹一下整個(gè)TOPAnalyzer的背景,目標(biāo)和初始設(shè)計(jì),為后面的演變做一點(diǎn)鋪墊。
開(kāi)放平臺(tái)從內(nèi)部開(kāi)放到正式對(duì)外開(kāi)放,逐步從每天幾千萬(wàn)的服務(wù)調(diào)用量發(fā)展到了上億到現(xiàn)在的15億,開(kāi)放的服務(wù)也從幾十個(gè)到了幾百個(gè),應(yīng)用接入從幾百個(gè)增加到了幾十萬(wàn)個(gè)。此時(shí),對(duì)于原始服務(wù)訪問(wèn)數(shù)據(jù)的分析需求就凸現(xiàn)出來(lái):
<!--[if !supportLists]-->1. <!--[endif]-->應(yīng)用維度分析(應(yīng)用的正常業(yè)務(wù)調(diào)用行為和異常調(diào)用行為分析)
<!--[if !supportLists]-->2. <!--[endif]-->服務(wù)維度分析(服務(wù)RT,總量,成功失敗率,業(yè)務(wù)錯(cuò)誤及子錯(cuò)誤等)
<!--[if !supportLists]-->3. <!--[endif]-->平臺(tái)維度分析(平臺(tái)消耗時(shí)間,平臺(tái)授權(quán)等業(yè)務(wù)統(tǒng)計(jì)分析,平臺(tái)錯(cuò)誤分析,平臺(tái)系統(tǒng)健康指標(biāo)分析等)
<!--[if !supportLists]-->4. <!--[endif]-->業(yè)務(wù)維度分析(用戶,應(yīng)用,服務(wù)之間關(guān)系分析,應(yīng)用歸類分析,服務(wù)歸類分析等)
上面只是一部分,從上面的需求來(lái)看需要一個(gè)系統(tǒng)能夠靈活的運(yùn)行期配置分析策略,對(duì)海量數(shù)據(jù)作即時(shí)分析,將接過(guò)用于告警,監(jiān)控,業(yè)務(wù)分析。
下圖是最原始的設(shè)計(jì)圖,很簡(jiǎn)單,但還是有些想法在里面:
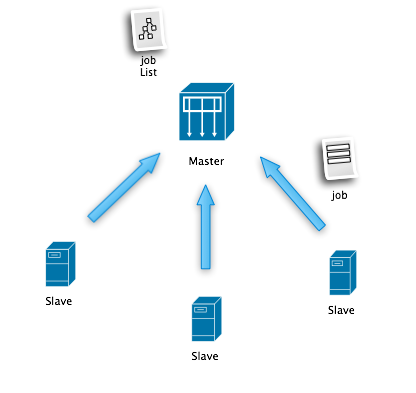
Master:管理任務(wù)(分析任務(wù)),合并結(jié)果(Reduce),輸出結(jié)果(全量統(tǒng)計(jì),增量片段統(tǒng)計(jì))
Slave:Require Job + Do Job + Return Result,隨意加入,退出集群。
Job:(Input + Analysis Rule + Output)的定義。
幾個(gè)設(shè)計(jì)點(diǎn):
<!--[if !supportLists]-->1. <!--[endif]-->后臺(tái)系統(tǒng)任務(wù)分配:無(wú)負(fù)載分配算法,采用細(xì)化任務(wù)+工作者按需自取+粗暴簡(jiǎn)單任務(wù)重置策略。
<!--[if !supportLists]-->2. <!--[endif]-->Slave與Master采用單向通信,便于容量擴(kuò)充和縮減。
<!--[if !supportLists]-->3. <!--[endif]-->Job自描述性,從任務(wù)數(shù)據(jù)來(lái)源,分析規(guī)則,結(jié)果輸出都定義在任務(wù)中,使得Slave適用與各種分析任務(wù),一個(gè)集群分析多種日志,多個(gè)集群共享Slave。
<!--[if !supportLists]-->4. <!--[endif]-->數(shù)據(jù)存儲(chǔ)無(wú)業(yè)務(wù)性(意味著存儲(chǔ)的時(shí)候不定義任何業(yè)務(wù)含義),分析規(guī)則包含業(yè)務(wù)含義(在執(zhí)行分析的時(shí)候告知不同列是什么含義,怎么統(tǒng)計(jì)和計(jì)算),優(yōu)勢(shì)在于可擴(kuò)展,劣勢(shì)在于全量掃描日志(無(wú)預(yù)先索引定義)。
<!--[if !supportLists]-->5. <!--[endif]-->透明化整個(gè)集群運(yùn)行狀況,保證簡(jiǎn)單粗暴的方式下能夠快速定位出節(jié)點(diǎn)問(wèn)題或者任務(wù)問(wèn)題。(雖然沒(méi)有心跳,但是每個(gè)節(jié)點(diǎn)的工作都會(huì)輸出信息,通過(guò)外部收集方式快速定位問(wèn)題,防止集群為了監(jiān)控耦合不利于擴(kuò)展)
<!--[if !supportLists]-->6. <!--[endif]-->Master單點(diǎn)采用冷備方式解決。單點(diǎn)不可怕,可怕的是丟失現(xiàn)場(chǎng)和重啟或重選Master周期長(zhǎng)。因此采用分析數(shù)據(jù)和任務(wù)信息簡(jiǎn)單周期性外部存儲(chǔ)的方式將現(xiàn)場(chǎng)保存與外部(信息盡量少,保證恢復(fù)時(shí)快速),另一方面采用外部系統(tǒng)通知方式修改Slave集群MasterIP,人工快速切換到冷備。
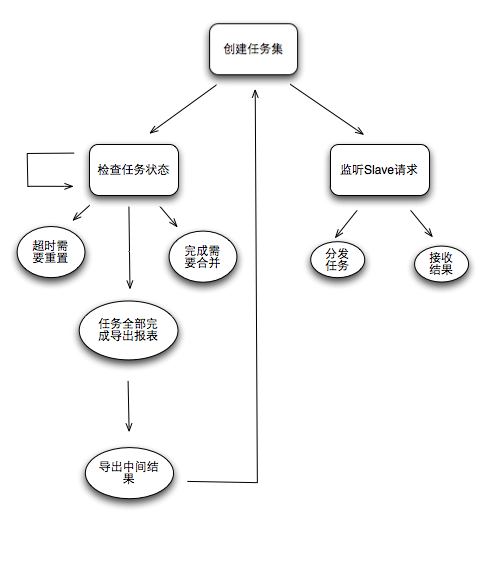
Master的生活軌跡:
Slave的生活軌跡:
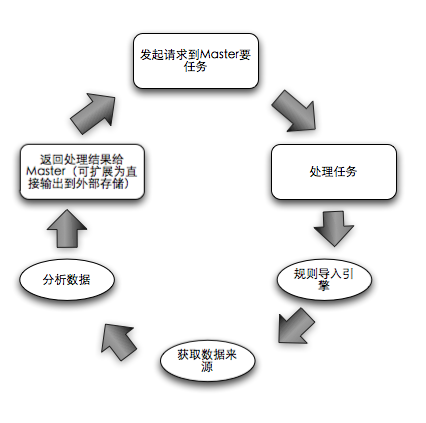
有人會(huì)覺(jué)得這玩意兒簡(jiǎn)單,系統(tǒng)就是簡(jiǎn)單+透明才會(huì)高效,往往就是因?yàn)橄到y(tǒng)復(fù)雜才會(huì)帶來(lái)更多看似很高深的設(shè)計(jì),最終無(wú)非是折騰了自己,苦了一線。廢話不多說(shuō),背景介紹完了,開(kāi)始講具體的演變過(guò)程。
數(shù)據(jù)量:2千萬(wàn) à 1億 à 8億 à15億。報(bào)表輸出結(jié)果:10份配置à30份à60份à100份。統(tǒng)計(jì)后的數(shù)據(jù)量:10k à 10M à 9G。統(tǒng)計(jì)周期的要求:1天à5分鐘à3分鐘à1分半。
從上面這些數(shù)據(jù)可以知道從網(wǎng)絡(luò)和磁盤(pán)IO,到內(nèi)存,到CPU都會(huì)經(jīng)歷很大的考驗(yàn),由于Master是縱向擴(kuò)展的,因此優(yōu)化Master成為每個(gè)數(shù)據(jù)跳動(dòng)的必然要求。由于是用Java寫(xiě)的,因此內(nèi)存對(duì)于整體分析的影響更加嚴(yán)重,GC的停頓直接可以使得系統(tǒng)掛掉(因?yàn)閿?shù)據(jù)在不斷流入內(nèi)存)。
優(yōu)化過(guò)程:
縱向系統(tǒng)的工作的分擔(dān):
從Master的生活軌跡可以看到,它負(fù)荷最大的一步就是要去負(fù)責(zé)Reduce,無(wú)論如何都需要交給一個(gè)單節(jié)點(diǎn)來(lái)完成所有的Reduce,但并不表示對(duì)于多個(gè)Slave的所有的Reduce都需要Master來(lái)做。有同學(xué)給過(guò)建議說(shuō)讓Master再去分配給不同的Slave去做Slave之間的Reduce,但一旦引入Master對(duì)Slave的通信和管理,這就回到了復(fù)雜的老路。因此這里用最簡(jiǎn)單的方式,一個(gè)機(jī)器可以部署多個(gè)Slave,一個(gè)Slave可以一次獲取多個(gè)Job,執(zhí)行完畢后本地合并再匯報(bào)給Master。(優(yōu)勢(shì):Master在Job合并所產(chǎn)生的內(nèi)存消耗可以減輕,因?yàn)檫@是統(tǒng)計(jì),所以合并后數(shù)據(jù)量一定大幅下降,此時(shí)Master合并越少的Job數(shù)量,內(nèi)存消耗越小),因此Slave的生活軌跡變化了一點(diǎn):
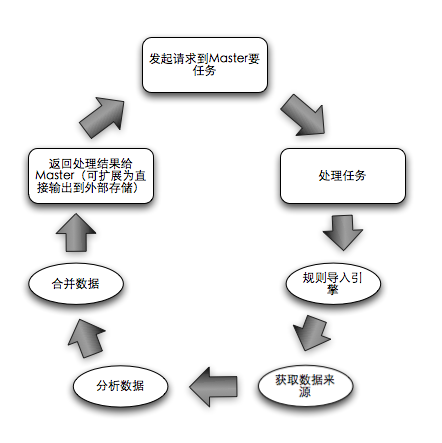
流程中間數(shù)據(jù)優(yōu)化:
這里舉兩個(gè)例子來(lái)說(shuō)明對(duì)于處理中中間數(shù)據(jù)優(yōu)化的意義。
在統(tǒng)計(jì)分析中往往會(huì)有對(duì)分析后的數(shù)據(jù)做再次處理的需求,例如一個(gè)API報(bào)表里面會(huì)有API訪問(wèn)總量,API訪問(wèn)成功數(shù),同時(shí)會(huì)要有API的成功率,這個(gè)數(shù)據(jù)最早設(shè)計(jì)的時(shí)候和普通的MapReduce字段一樣處理,計(jì)算和存儲(chǔ)在每一行數(shù)據(jù)分析的時(shí)候都做,但其實(shí)這類數(shù)據(jù)只有在最后輸出的時(shí)候才有統(tǒng)計(jì)和存儲(chǔ)價(jià)值,因?yàn)檫@些數(shù)據(jù)都可以通過(guò)已有數(shù)據(jù)計(jì)算得到,而中間反復(fù)做計(jì)算在存儲(chǔ)和計(jì)算上都是一種浪費(fèi),因此對(duì)于這種特殊的Lazy處理字段,中間不計(jì)算也不存儲(chǔ),在周期輸出時(shí)做一次分析,降低了計(jì)算和存儲(chǔ)的壓力。
對(duì)于MapReduce中的Key存儲(chǔ)的壓縮。由于很多統(tǒng)計(jì)的Key是很多業(yè)務(wù)數(shù)據(jù)的組合,例如APPAPIUser的統(tǒng)計(jì)報(bào)表,它的Key就是三個(gè)字段的串聯(lián):taobao.user.get—12132342—fangweng,這時(shí)候大量的Key會(huì)占用內(nèi)存,而Key的目的就是產(chǎn)生這個(gè)業(yè)務(wù)統(tǒng)計(jì)中的唯一標(biāo)識(shí),因此考慮這些API的名稱等等是否可以替換成唯一的短內(nèi)容就可以減少內(nèi)存占用。過(guò)程中就不多說(shuō)了,最后在分析器里面實(shí)現(xiàn)了兩種策略:
<!--[if !supportLists]-->1. <!--[endif]-->不可逆數(shù)字摘要采樣。
有點(diǎn)類似與短連接轉(zhuǎn)換的方式,對(duì)數(shù)據(jù)做Md5數(shù)字摘要,獲得16個(gè)byte,然后根據(jù)壓縮配置來(lái)采樣16個(gè)byte部分,用可見(jiàn)字符定義出64進(jìn)制來(lái)標(biāo)識(shí)這些采樣,最后形成較短的字符串。
由于Slave是數(shù)據(jù)分析者,因此用Slave的CPU來(lái)?yè)QMaster的內(nèi)存,將中間結(jié)果用不可逆的短字符串方式表示。弱點(diǎn):當(dāng)最后分析出來(lái)的數(shù)據(jù)量越大,采樣md5后的數(shù)據(jù)越少,越容易產(chǎn)生沖突,導(dǎo)致統(tǒng)計(jì)不準(zhǔn)確。
<!--[if !supportLists]-->2. <!--[endif]-->提供需要壓縮的業(yè)務(wù)數(shù)據(jù)列表。
業(yè)務(wù)方提供日志中需要替換的列定義及一組定義內(nèi)容。簡(jiǎn)單來(lái)說(shuō),當(dāng)日志某一列可以被枚舉,那么就意味者這一列可以被簡(jiǎn)單的替換成短標(biāo)識(shí)。例如配置APIName這列在分析生成key的時(shí)候可以被替換,并且提供了500多個(gè)api的名稱文件載入到內(nèi)存中,那么每次api在生成key的時(shí)候就會(huì)被替換掉名稱組合在key中,大大縮短key。那為什么要提供這些api的名稱呢?首先分析生成key在Slave,是分布式的,如果采用自學(xué)習(xí)的模式,勢(shì)必要引入集中式唯一索引生成器,其次還要做好足夠的并發(fā)控制,另一方面也會(huì)由并發(fā)控制帶來(lái)性能損耗。這種模式雖然很原始,但不會(huì)影響統(tǒng)計(jì)結(jié)果的準(zhǔn)確性,因此在分析器中被使用,這個(gè)列表會(huì)隨著任務(wù)規(guī)則每次發(fā)送到Slave中,保證所有節(jié)點(diǎn)分析結(jié)果的一致性。
特殊化處理特殊的流程:
在Master的生活軌跡中可以看出,影響一輪輸出時(shí)間和內(nèi)存使用的包括分析合并數(shù)據(jù)結(jié)果,導(dǎo)出報(bào)表和導(dǎo)出中間結(jié)果。在數(shù)據(jù)上升到1億的時(shí)候,Slave和Master之間數(shù)據(jù)通信以及Master的中間結(jié)果磁盤(pán)化的過(guò)程中都采用了壓縮的方式來(lái)減少數(shù)據(jù)交互對(duì)IO緩沖的影響,但一直考慮是否還可以再壓榨一點(diǎn)。首先導(dǎo)出中間結(jié)果的時(shí)候最初采用簡(jiǎn)單的Object序列化導(dǎo)出,從內(nèi)存使用,外部數(shù)據(jù)大小,輸出時(shí)間上來(lái)說(shuō)都有不少的消耗,仔細(xì)看了一下中間結(jié)果是Map<String,Map<String,Obj>>,其實(shí)最后一個(gè)Obj無(wú)非只有兩種類型Double和String,既然這樣,序列化完全可以簡(jiǎn)單來(lái)作,因此直接很簡(jiǎn)單的實(shí)現(xiàn)了類似Json簡(jiǎn)化版的序列化,從序列化速度,內(nèi)存占用減少上,外部磁盤(pán)存儲(chǔ)都有了極大的提高,外部磁盤(pán)存儲(chǔ)越小,所消耗的IO和過(guò)程中需要的臨時(shí)內(nèi)存都會(huì)下降,序列化速度加快,那么內(nèi)存中的數(shù)據(jù)就會(huì)被盡快釋放。總體上來(lái)說(shuō)就是特殊化處理了可以特殊化對(duì)待的流程,提高了資源利用率。(同時(shí)中間結(jié)果在前期優(yōu)化階段的作用就是為了備份,因此不需要每個(gè)周期都做,當(dāng)時(shí)做成可配置的周期值輸出)
再接著來(lái)談一下中間結(jié)果合并時(shí)候?qū)τ趦?nèi)存使用的優(yōu)化。Master會(huì)從多個(gè)Slave得到多個(gè)Map<Key,Map<Key,Value>>,合并過(guò)程就是對(duì)多個(gè)Map將第一級(jí)Key相同的數(shù)據(jù)做整合,例如第一級(jí)Key的一個(gè)值是API訪問(wèn)總量,那么它對(duì)應(yīng)的Map中就是不同的api名稱和總量的統(tǒng)計(jì),而多個(gè)Map直接合并就是將一級(jí)key(API訪問(wèn)總量)下的Map數(shù)據(jù)合并起來(lái)(同樣的api總量相加最后保存一份)。最簡(jiǎn)單的做法就是多個(gè)Map<Key,Map<Key,Value>>遞歸的來(lái)合并,但如果要節(jié)省內(nèi)存和計(jì)算可以有兩個(gè)小改進(jìn),首先選擇其中一個(gè)作為最終的結(jié)果集合(避免申請(qǐng)新空間,也避免輪詢這個(gè)Map的數(shù)據(jù)),其次每一次遞歸時(shí)候,將合并后的后面的Map中數(shù)據(jù)移出(減少后續(xù)無(wú)用的循環(huán)對(duì)比,同時(shí)也節(jié)省空間)。看似小改動(dòng),但效果很不錯(cuò)。
再談一下在輸出結(jié)果時(shí)候的內(nèi)存節(jié)省。在輸出結(jié)果的時(shí)候,是基于內(nèi)存中一份Map<Key,Map<Key,Value>>來(lái)構(gòu)建的。其實(shí)將傳統(tǒng)的MapReduce的KV結(jié)果如何轉(zhuǎn)換成為傳統(tǒng)的Report,只需要看看Sql中的Group設(shè)計(jì),將多個(gè)KV通過(guò)Group by key,就可以得到傳統(tǒng)意義上的Key,Value,Value,Value。例如:KV可以是<apiName,apiTotalCount>,<apiName,apiResponse>,<apiName,apiFailCount>,如果Group by apiName,那么就可以得到 apiName,apiTotalCount,apiResponse,apiFailCount的報(bào)表行結(jié)果。這種歸總的方式可以類似填字游戲,因?yàn)槲覀兘Y(jié)果是KV,所以這個(gè)填字游戲默認(rèn)從列開(kāi)始填寫(xiě),遍歷所有的KV以后就可以完整的得到一個(gè)大的矩陣并按照行輸出,但代價(jià)是KV沒(méi)有遍歷完成以前,無(wú)法輸出。因此考慮是否可以按照行來(lái)填寫(xiě),然后每一行填寫(xiě)完畢之后直接輸出,節(jié)省申請(qǐng)內(nèi)存。按行填寫(xiě)最大的問(wèn)題就是如何在對(duì)KV中已經(jīng)處理過(guò)的數(shù)據(jù)打上標(biāo)識(shí),不要重復(fù)處理。(一種方式引入外部存儲(chǔ)來(lái)標(biāo)識(shí)這個(gè)值已經(jīng)被處理過(guò),因?yàn)檫@些KV不可以類似合并的時(shí)候刪除,后續(xù)還會(huì)繼續(xù)要用,另一種方式就是完全備份一份數(shù)據(jù),合并完成后就刪除),但本來(lái)就是為了節(jié)約內(nèi)存的,引入更多的存儲(chǔ),就和目標(biāo)有悖了。因此做了一個(gè)計(jì)算換存儲(chǔ)的做法,例如填充時(shí)輪訓(xùn)的順序?yàn)椋?/span>K1V1,K2V2,K3V3,到K2V2遍歷的時(shí)候,判斷是否要處理當(dāng)前這個(gè)數(shù)據(jù),就只要判斷這個(gè)K是否在K1里面出現(xiàn)過(guò),而到K3V3遍歷的時(shí)候,判斷是否要處理,就輪詢K1K2是否存在這個(gè)K,由于都是Map結(jié)構(gòu),因此這種查找的消耗很小,由此改為行填寫(xiě),逐行輸出。
最后再談一下最重頭的優(yōu)化,合并調(diào)度及磁盤(pán)內(nèi)存互換的優(yōu)化
從Master的生活軌跡可以看到,原來(lái)的主線程負(fù)責(zé)檢查外部分析數(shù)據(jù)結(jié)果狀態(tài),合并數(shù)據(jù)結(jié)果這個(gè)循環(huán),考慮到最終合并后數(shù)據(jù)只有一個(gè)主干,因此采用單線程合并模式來(lái)運(yùn)作,見(jiàn)下圖:
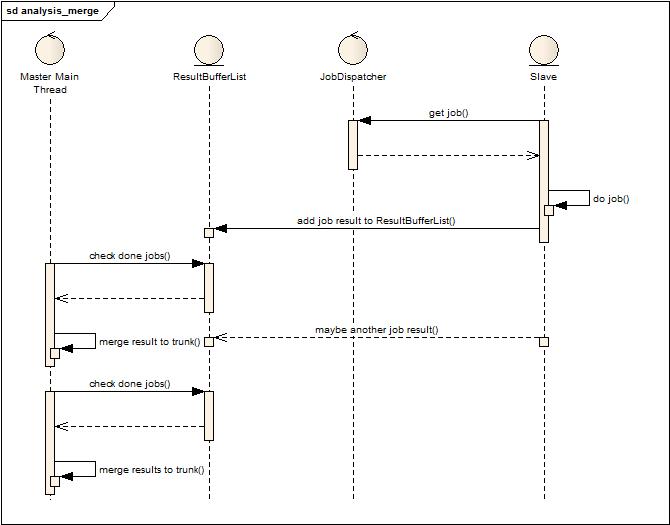
這張圖大致描述了一下處理流程,Slave隨時(shí)都會(huì)將分析后的結(jié)果掛到結(jié)果緩沖隊(duì)列上,然后主線程負(fù)責(zé)批量獲取結(jié)果并且合并。雖然是批量獲取,但是為了節(jié)省內(nèi)存,也不能等待太久,因?yàn)槊恳稽c(diǎn)等待就意味著大量沒(méi)有合并的數(shù)據(jù)將會(huì)存在與內(nèi)存中,但合并的太頻繁也會(huì)導(dǎo)致在合并過(guò)程中,新加入的結(jié)果會(huì)等待很久,導(dǎo)致內(nèi)存吃緊。或許這個(gè)時(shí)候會(huì)考慮,為什么不直接用多線程來(lái)合并,的確,多線程合并并非不可行,但要考慮如何兼顧到主干合并的并發(fā)控制,因?yàn)槎鄠€(gè)線程不可能同時(shí)都合并到數(shù)據(jù)主干上,由此引入了下面的設(shè)計(jì)實(shí)現(xiàn),半并行模式的合并:
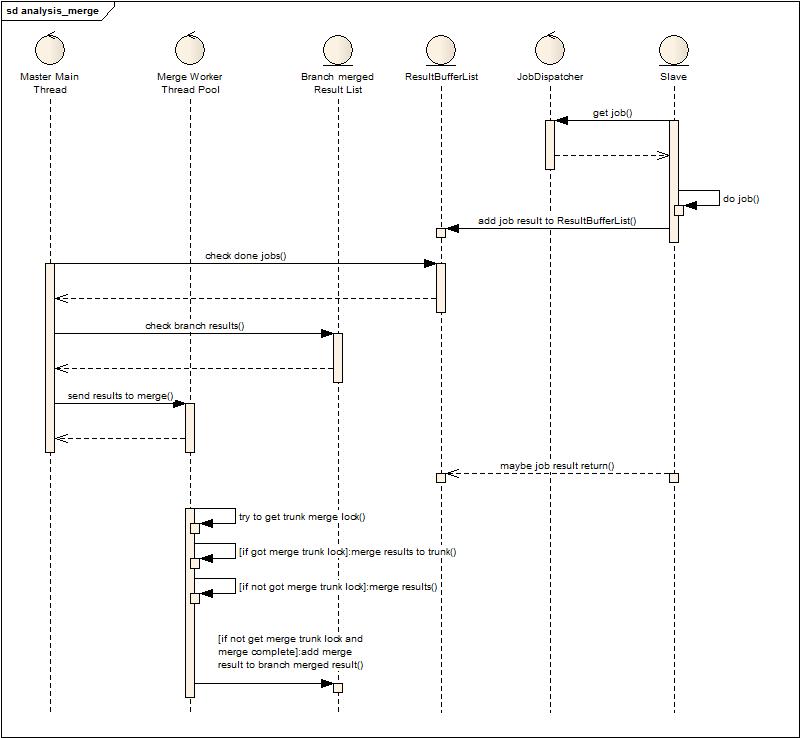
從上圖可以發(fā)現(xiàn)增加了兩個(gè)角色:Merge Worker Thread Pool和Branch merged ResultList,與上面設(shè)計(jì)的差別就在于主線程不再負(fù)責(zé)合并數(shù)據(jù),而是批量的獲取數(shù)據(jù)交給合并線程池來(lái)合并,而合并線程池中的工作者在合并的過(guò)程中會(huì)競(jìng)爭(zhēng)主干合并鎖,成功獲得的就和主干合并,不成功的就將結(jié)果合并后放到分支合并隊(duì)列上,等待下次合并時(shí)被主干合并或者分支合并獲得再次合并。這樣改進(jìn)后,發(fā)現(xiàn)由于數(shù)據(jù)掛在隊(duì)列沒(méi)有得到及時(shí)處理產(chǎn)生的內(nèi)存壓力大大下降,同時(shí)也充分利用了多核,多線程榨干了多核的計(jì)算能力(線程池大小根據(jù)cpu核來(lái)設(shè)置的小一點(diǎn),預(yù)留一點(diǎn)給GC用)。這種設(shè)計(jì)中還多了一些小的調(diào)優(yōu)配置,例如是否允許被合并過(guò)的數(shù)據(jù)多次被再次合并(防止無(wú)畏的計(jì)算消耗),每次并行合并最小結(jié)果數(shù)是多少,等待堆積到最小結(jié)果數(shù)的最大時(shí)間等等。(有興趣看代碼)
至上面的優(yōu)化為止,感覺(jué)合并這塊已經(jīng)被榨干了,但分析日志數(shù)據(jù)的增多,對(duì)及時(shí)性要求的加強(qiáng),使得我又要重新審視是否還有能力繼續(xù)榨出這個(gè)流程的水份。因此有了一個(gè)大膽的想法,磁盤(pán)換內(nèi)存。因?yàn)樵谡{(diào)度合并上已經(jīng)找不到更多可以優(yōu)化的點(diǎn)了,但是有一點(diǎn)還可以考慮,就是主干的那點(diǎn)數(shù)據(jù)是否要貫穿于整個(gè)合并周期,而且主干的數(shù)據(jù)隨著增量分析不斷增大(在最近這次優(yōu)化的過(guò)程中也就是發(fā)現(xiàn)GC的頻繁導(dǎo)致合并速度下降,合并速度下降導(dǎo)致內(nèi)存中臨時(shí)數(shù)據(jù)保存的時(shí)間久,反過(guò)來(lái)又影響GC,最后變成了惡性循環(huán))。盡管覺(jué)得靠譜,但不測(cè)試不得而知。于是得到了以下的設(shè)計(jì)和實(shí)現(xiàn):
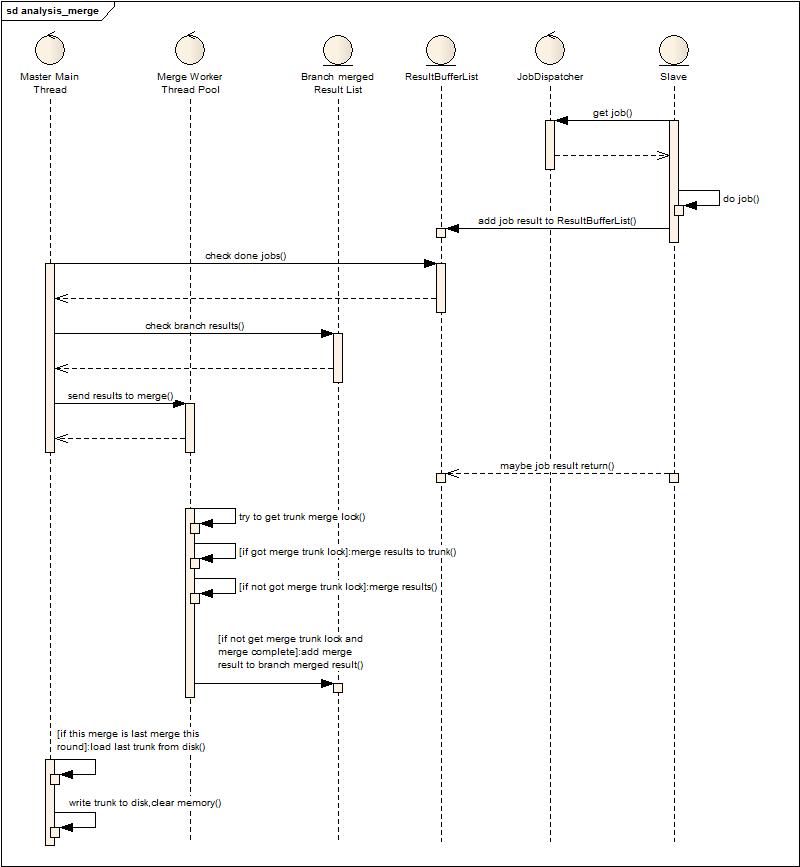
這個(gè)流程發(fā)現(xiàn)和第二個(gè)流程就多了最后兩個(gè)步驟,判斷是否是最后的一次合并,如果是載入磁盤(pán)數(shù)據(jù),然后合并,合并完后將主干輸出到磁盤(pán),清空主干內(nèi)存。(此時(shí)發(fā)現(xiàn)導(dǎo)出中間結(jié)果原來(lái)不是每次必須的,但是這種模式下卻成為每次必須的了)
這個(gè)改動(dòng)的優(yōu)勢(shì)在什么地方?例如一個(gè)分析周期是2分鐘,那么在2分鐘內(nèi),主干龐大的數(shù)據(jù)被外置到磁盤(pán),內(nèi)存大量空閑,極大提高了當(dāng)前時(shí)間片結(jié)果合并的效率(GC少了)。缺點(diǎn)是什么?會(huì)在每個(gè)周期產(chǎn)生兩次磁盤(pán)大量的讀寫(xiě),但配合上優(yōu)化過(guò)的中間結(jié)果載入載出(前面的私有序列化)會(huì)適當(dāng)緩和。
由于線下無(wú)法模擬,就嘗試著線上測(cè)試,發(fā)現(xiàn)GC減少,合并過(guò)程加速達(dá)到預(yù)期,但是每輪的磁盤(pán)和內(nèi)存的換入換出由于也記入在一輪分析時(shí)間之內(nèi),每輪寫(xiě)出最大時(shí)候70m數(shù)據(jù),需要消耗10多秒,甚至20秒,讀入最大需要10s,這個(gè)時(shí)間如果算在要求一輪兩分鐘內(nèi),那也是不可接受的),重新審視是否有疏漏的細(xì)節(jié)。首先載入是否可以異步,如果可以異步,而不是在最后一輪才載入,那么就不會(huì)納入到分析周期中,因此配置了一個(gè)可以調(diào)整的比例值,當(dāng)任務(wù)完成到達(dá)或者超過(guò)這個(gè)比例值的時(shí)候,將開(kāi)始并行載入數(shù)據(jù),最后一輪等到異步載入后開(kāi)始分析,發(fā)現(xiàn)果然可行,因此這個(gè)時(shí)間被排除在周期之外(雖然也帶來(lái)了一點(diǎn)內(nèi)存消耗)。然后再考慮輸出是否可以異步,以前輸出不可以異步的原因是這份數(shù)據(jù)是下一輪分析的主干,如果異步輸出,下一輪數(shù)據(jù)開(kāi)始處理,很難保證下一輪的第一個(gè)任務(wù)是否會(huì)引發(fā)數(shù)據(jù)修改,導(dǎo)致并發(fā)問(wèn)題,所以一直鎖定主干輸出,直到完成再開(kāi)始,但現(xiàn)在每次合并都是空主干開(kāi)始的,因此輸出完全可以異步,主干可以立刻清空,進(jìn)入下一輪合并,只要在下一個(gè)周期開(kāi)始載入主干前異步導(dǎo)出主干完成即可,這個(gè)時(shí)間是很長(zhǎng)的,完全可以把控,因此輸出也可以變成異步,不納入分析周期。
至此完成了所有的優(yōu)化,分析器高峰期的指標(biāo)發(fā)生了改變:一輪分析從2分鐘左右降低到了1分10秒,JVM的O區(qū)在合并過(guò)程中從50-80的占用率下降到20-60的占用率,GC次數(shù)明顯大幅減少。
總結(jié):
<!--[if !supportLists]-->1. <!--[endif]-->利用可橫向擴(kuò)展的系統(tǒng)來(lái)分擔(dān)縱向擴(kuò)展系統(tǒng)的工作。
<!--[if !supportLists]-->2. <!--[endif]-->流程中中間數(shù)據(jù)的優(yōu)化處理。
<!--[if !supportLists]-->3. <!--[endif]-->特殊化處理可以特殊處理的流程。
<!--[if !supportLists]-->4. <!--[endif]-->從整體流程上考慮不同策略的消耗,提高整體處理能力。
<!--[if !supportLists]-->5. <!--[endif]-->資源的快用快放,提高同一類資源利用率。
<!--[if !supportLists]-->6. <!--[endif]-->不同階段不同資源的互換,提高不同資源的利用率。
其實(shí)很多細(xì)節(jié)也許看了代碼才會(huì)有更深的體會(huì),分析器只是一個(gè)典型的消耗性案例,每一點(diǎn)改進(jìn)都是在數(shù)據(jù)和業(yè)務(wù)驅(qū)動(dòng)下不斷的考驗(yàn)。例如縱向的Master也許真的有一天就到了它的極限,那么就交給Slave將數(shù)據(jù)產(chǎn)出到外部存儲(chǔ),交由其他系統(tǒng)或者另一個(gè)分析集群去做二次分析。對(duì)于海量數(shù)據(jù)的處理來(lái)說(shuō)都需要經(jīng)歷初次篩選,再次分析,展示關(guān)聯(lián)幾個(gè)階段,Java的應(yīng)用擺脫不了內(nèi)存約束帶來(lái)對(duì)計(jì)算的影響,因此就要考慮好自己的頂在什么地方。但優(yōu)化一定是全局的,例如磁盤(pán)換內(nèi)存,磁盤(pán)帶來(lái)的消耗在總體上來(lái)說(shuō)還是可以接受的化,那么就可以被采納(當(dāng)然如果用上SSD效果估計(jì)會(huì)更好)。
最后還是想說(shuō)的是,很多事情是簡(jiǎn)單做到復(fù)雜,復(fù)雜再回歸到簡(jiǎn)單,對(duì)系統(tǒng)提出的挑戰(zhàn)就是如何能夠用最直接的方式簡(jiǎn)單的搞定,而不是做一個(gè)臃腫依賴龐大的系統(tǒng),簡(jiǎn)單才看的清楚,看的清楚才有機(jī)會(huì)不斷改進(jìn)。
@import url(http://www.aygfsteel.com/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
java反射機(jī)制的實(shí)現(xiàn)原理
反射機(jī)制:
所謂的反射機(jī)制就是java語(yǔ)言在運(yùn)行時(shí)擁有一項(xiàng)自觀的能力。
通過(guò)這種能力可以徹底的了解自身的情況為下一步的動(dòng)作做準(zhǔn)備。
下面具體介紹一下java的反射機(jī)制。這里你將顛覆原來(lái)對(duì)java的理解。
Java的反射機(jī)制的實(shí)現(xiàn)要借助于4個(gè)類:class,Constructor,F(xiàn)ield,Method;
其中class代表的時(shí)類對(duì)象,
Constructor-類的構(gòu)造器對(duì)象,
Field-類的屬性對(duì)象,
Method-類的方法對(duì)象。
通過(guò)這四個(gè)對(duì)象我們可以粗略的看到一個(gè)類的各個(gè)組 成部分。
Class:程序運(yùn)行時(shí),java運(yùn)行時(shí)系統(tǒng)會(huì)對(duì)所有的對(duì)象進(jìn)行運(yùn)行時(shí)類型的處理。
這項(xiàng)信息記錄了每個(gè)對(duì)象所屬的類,虛擬機(jī)通常使用運(yùn)行時(shí)類型信息選擇正 確的方法來(lái)執(zhí)行(摘自:白皮書(shū))。
但是這些信息我們?cè)趺吹玫桨。鸵柚赾lass類對(duì)象了啊。
在Object類中定義了getClass()方法。我 們可以通過(guò)這個(gè)方法獲得指定對(duì)象的類對(duì)象。然后我們通過(guò)分析這個(gè)對(duì)象就可以得到我們要的信息了。
比如:ArrayList arrayList;
Class clazz = arrayList.getClass();
然后我來(lái)處理這個(gè)對(duì)象clazz。
當(dāng)然了Class類具有很多的方法,這里重點(diǎn)將和Constructor,F(xiàn)ield,Method類有關(guān)系的方法。
Reflection 是 Java 程序開(kāi)發(fā)語(yǔ)言的特征之一,它允許運(yùn)行中的 Java 程序?qū)ψ陨磉M(jìn)行檢查,或者說(shuō)“自審”,并能直接操作程序的內(nèi)部屬性。Java 的這一能力在實(shí)際應(yīng)用中也許用得不是很多,但是個(gè)人認(rèn)為要想對(duì)java有個(gè)更加深入的了解還是應(yīng)該掌握的。
1.檢測(cè)類:
reflection的工作機(jī)制
考慮下面這個(gè)簡(jiǎn)單的例子,讓我們看看 reflection 是如何工作的。
import java.lang.reflect.*;
public class DumpMethods {
public static void main(String args[]) {
try {
//forName("java.lang.String")獲取指定的類的對(duì)象
Class c = Class.forName("java.lang.String");
Method m[] = c.getDeclaredMethods();
for (int i = 0; i < m.length; i++)
System.out.println(m[i].toString());
} catch (Throwable e) {
System.err.println(e);
}
}
}
按如下語(yǔ)句執(zhí)行:
java DumpMethods java.util.ArrayList
這個(gè)程序使用 Class.forName 載入指定的類,然后調(diào)用 getDeclaredMethods 來(lái)獲取這個(gè)類中定義了的方法列表。java.lang.reflect.Methods 是用來(lái)描述某個(gè)類中單個(gè)方法的一個(gè)類。
Java類反射中的主要方法
對(duì)于以下三類組件中的任何一類來(lái)說(shuō)
-- 構(gòu)造函數(shù)、字段和方法
-- java.lang.Class 提供四種獨(dú)立的反射調(diào)用,以不同的方式來(lái)獲得信息。調(diào)用都遵循一種標(biāo)準(zhǔn)格式。以下是用于查找構(gòu)造函數(shù)的一組反射調(diào)用:
Constructor getConstructor(Class[] params) -- 獲得使用特殊的參數(shù)類型的公共構(gòu)造函數(shù),
Constructor[] getConstructors() -- 獲得類的所有公共構(gòu)造函數(shù)
Constructor getDeclaredConstructor(Class[] params) -- 獲得使用特定參數(shù)類型的構(gòu)造函數(shù)(與接入級(jí)別無(wú)關(guān))
Constructor[] getDeclaredConstructors() -- 獲得類的所有構(gòu)造函數(shù)(與接入級(jí)別無(wú)關(guān))
獲得字段信息的Class 反射調(diào)用不同于那些用于接入構(gòu)造函數(shù)的調(diào)用,在參數(shù)類型數(shù)組中使用了字段名:
Field getField(String name) -- 獲得命名的公共字段
Field[] getFields() -- 獲得類的所有公共字段
Field getDeclaredField(String name) -- 獲得類聲明的命名的字段
Field[] getDeclaredFields() -- 獲得類聲明的所有字段
用于獲得方法信息函數(shù):
Method getMethod(String name, Class[] params) -- 使用特定的參數(shù)類型,獲得命名的公共方法
Method[] getMethods() -- 獲得類的所有公共方法
Method getDeclaredMethod(String name, Class[] params) -- 使用特寫(xiě)的參數(shù)類型,獲得類聲明的命名的方法
Method[] getDeclaredMethods() -- 獲得類聲明的所有方法
使用 Reflection:
用于 reflection 的類,如 Method,可以在 java.lang.relfect 包中找到。使用這些類的時(shí)候必須要遵循三個(gè)步驟:
第一步是獲得你想操作的類的 java.lang.Class 對(duì)象。
在運(yùn)行中的 Java 程序中,用 java.lang.Class 類來(lái)描述類和接口等。
下面就是獲得一個(gè) Class 對(duì)象的方法之一:
Class c = Class.forName("java.lang.String");
這條語(yǔ)句得到一個(gè) String 類的類對(duì)象。還有另一種方法,如下面的語(yǔ)句:
Class c = int.class;
或者
Class c = Integer.TYPE;
它們可獲得基本類型的類信息。其中后一種方法中訪問(wèn)的是基本類型的封裝類 (如 Intege ) 中預(yù)先定義好的 TYPE 字段。
第二步是調(diào)用諸如 getDeclaredMethods 的方法,以取得該類中定義的所有方法的列表。
一旦取得這個(gè)信息,就可以進(jìn)行第三步了——使用 reflection API 來(lái)操作這些信息,如下面這段代碼:
Class c = Class.forName("java.lang.String");
Method m[] = c.getDeclaredMethods();
System.out.println(m[0].toString());
它將以文本方式打印出 String 中定義的第一個(gè)方法的原型。
處理對(duì)象:
a.創(chuàng)建一個(gè)Class對(duì)象
b.通過(guò)getField 創(chuàng)建一個(gè)Field對(duì)象
c.調(diào)用Field.getXXX(Object)方法(XXX是Int,Float等,如果是對(duì)象就省略;Object是指實(shí)例).
例如:
import java.lang.reflect.*;
import java.awt.*;
class SampleGet {
public static void main(String[] args) throws Exception {
Rectangle r = new Rectangle(100, 325);
printHeight(r);
printWidth( r);
}
static void printHeight(Rectangle r)throws Exception {
//Field屬性名
Field heightField;
//Integer屬性值
Integer heightValue;
//創(chuàng)建一個(gè)Class對(duì)象
Class c = r.getClass();
//.通過(guò)getField 創(chuàng)建一個(gè)Field對(duì)象
heightField = c.getField("height");
//調(diào)用Field.getXXX(Object)方法(XXX是Int,Float等,如果是對(duì)象就省略;Object是指實(shí)例).
heightValue = (Integer) heightField.get(r);
System.out.println("Height: " + heightValue.toString());
}
static void printWidth(Rectangle r) throws Exception{
Field widthField;
Integer widthValue;
Class c = r.getClass();
widthField = c.getField("width");
widthValue = (Integer) widthField.get(r);
System.out.println("Height: " + widthValue.toString());
}
}
安全性和反射:
在處理反射時(shí)安全性是一個(gè)較復(fù)雜的問(wèn)題。反射經(jīng)常由框架型代碼使用,由于這一點(diǎn),我們可能希望框架能夠全面接入代碼,無(wú)需考慮常規(guī)的接入限制。但是,在其它情況下,不受控制的接入會(huì)帶來(lái)嚴(yán)重的安全性風(fēng)險(xiǎn),例如當(dāng)代碼在不值得信任的代碼共享的環(huán)境中運(yùn)行時(shí)。
由于這些互相矛盾的需求,Java編程語(yǔ)言定義一種多級(jí)別方法來(lái)處理反射的安全性。基本模式是對(duì)反射實(shí)施與應(yīng)用于源代碼接入相同的限制:
從任意位置到類公共組件的接入
類自身外部無(wú)任何到私有組件的接入
受保護(hù)和打包(缺省接入)組件的有限接入
不過(guò)至少有些時(shí)候,圍繞這些限制還有一種簡(jiǎn)單的方法。我們可以在我們所寫(xiě)的類中,擴(kuò)展一個(gè)普通的基本類 java.lang.reflect.AccessibleObject 類。這個(gè)類定義了一種setAccessible方法,使我們能夠啟動(dòng)或關(guān)閉對(duì)這些類中其中一個(gè)類的實(shí)例的接入檢測(cè)。唯一的問(wèn)題在于如果使用了安全性管理 器,它將檢測(cè)正在關(guān)閉接入檢測(cè)的代碼是否許可了這樣做。如果未許可,安全性管理器拋出一個(gè)例外。
下面是一段程序,在TwoString 類的一個(gè)實(shí)例上使用反射來(lái)顯示安全性正在運(yùn)行:
public class ReflectSecurity {
public static void main(String[] args) {
try {
TwoString ts = new TwoString("a", "b");
Field field = clas.getDeclaredField("m_s1");
// field.setAccessible(true);
System.out.println("Retrieved value is " +
field.get(inst));
} catch (Exception ex) {
ex.printStackTrace(System.out);
}
}
}
如果我們編譯這一程序時(shí),不使用任何特定參數(shù)直接從命令行運(yùn)行,它將在field .get(inst)調(diào)用中拋出一個(gè)IllegalAccessException異常。如果我們不注釋 field.setAccessible(true)代碼行,那么重新編譯并重新運(yùn)行該代碼,它將編譯成功。最后,如果我們?cè)诿钚刑砑恿薐VM參數(shù) -Djava.security.manager以實(shí)現(xiàn)安全性管理器,它仍然將不能通過(guò)編譯,除非我們定義了ReflectSecurity類的許可權(quán) 限。
反射性能:(轉(zhuǎn)錄別人的啊)
反射是一種強(qiáng)大的工具,但也存在一些不足。一個(gè)主要的缺點(diǎn)是對(duì)性能有影響。使用反射基本上是一種解釋操作,我們可以告訴JVM,我們希望做什么并且它滿足我們的要求。這類操作總是慢于只直接執(zhí)行相同的操作。
下面的程序是字段接入性能測(cè)試的一個(gè)例子,包括基本的測(cè)試方法。每種方法測(cè)試字段接入的一種形式 -- accessSame 與同一對(duì)象的成員字段協(xié)作,accessOther 使用可直接接入的另一對(duì)象的字段,accessReflection 使用可通過(guò)反射接入的另一對(duì)象的字段。在每種情況下,方法執(zhí)行相同的計(jì)算 -- 循環(huán)中簡(jiǎn)單的加/乘順序。
程序如下:
public int accessSame(int loops) {
m_value = 0;
for (int index = 0; index < loops; index++) {
m_value = (m_value + ADDITIVE_VALUE) *
MULTIPLIER_VALUE;
}
return m_value;
}
public int acces
sReference(int loops) {
TimingClass timing = new TimingClass();
for (int index = 0; index < loops; index++) {
timing.m_value = (timing.m_value + ADDITIVE_VALUE) *
MULTIPLIER_VALUE;
}
return timing.m_value;
}
public int accessReflection(int loops) throws Exception {
TimingClass timing = new TimingClass();
try {
Field field = TimingClass.class.
getDeclaredField("m_value");
for (int index = 0; index < loops; index++) {
int value = (field.getInt(timing) +
ADDITIVE_VALUE) * MULTIPLIER_VALUE;
field.setInt(timing, value);
}
return timing.m_value;
} catch (Exception ex) {
System.out.println("Error using reflection");
throw ex;
}
}
在上面的例子中,測(cè)試程序重復(fù)調(diào)用每種方法,使用一個(gè)大循環(huán)數(shù),從而平均多次調(diào)用的時(shí)間衡量結(jié)果。平均值中不包括每種方法第一次調(diào)用的時(shí)間,因此初始化時(shí)間不是結(jié)果中的一個(gè)因素。下面的圖清楚的向我們展示了每種方法字段接入的時(shí)間:
圖 1:字段接入時(shí)間 :
我們可以看出:在前兩副圖中(Sun JVM),使用反射的執(zhí)行時(shí)間超過(guò)使用直接接入的1000倍以上。通過(guò)比較,IBM JVM可能稍好一些,但反射方法仍舊需要比其它方法長(zhǎng)700倍以上的時(shí)間。任何JVM上其它兩種方法之間時(shí)間方面無(wú)任何顯著差異,但I(xiàn)BM JVM幾乎比Sun JVM快一倍。最有可能的是這種差異反映了Sun Hot Spot JVM的專業(yè)優(yōu)化,它在簡(jiǎn)單基準(zhǔn)方面表現(xiàn)得很糟糕。反射性能是Sun開(kāi)發(fā)1.4 JVM時(shí)關(guān)注的一個(gè)方面,它在反射方法調(diào)用結(jié)果中顯示。在這類操作的性能方面,Sun 1.4.1 JVM顯示了比1.3.1版本很大的改進(jìn)。
如果為為創(chuàng)建使用反射的對(duì)象編寫(xiě)了類似的計(jì)時(shí)測(cè)試程序,我們會(huì)發(fā)現(xiàn)這種情況下的差異不象字段和方法調(diào)用情況下那么顯著。使用newInstance()調(diào) 用創(chuàng)建一個(gè)簡(jiǎn)單的java.lang.Object實(shí)例耗用的時(shí)間大約是在Sun 1.3.1 JVM上使用new Object()的12倍,是在IBM 1.4.0 JVM的四倍,只是Sun 1.4.1 JVM上的兩部。使用Array.newInstance(type, size)創(chuàng)建一個(gè)數(shù)組耗用的時(shí)間是任何測(cè)試的JVM上使用new type[size]的兩倍,隨著數(shù)組大小的增加,差異逐步縮小。隨著jdk6.0的推出,反射機(jī)制的性能也有了很大的提升。期待中….
總結(jié):
Java語(yǔ)言反射提供一種動(dòng)態(tài)鏈接程序組件的多功能方法。它允許程序創(chuàng)建和控制任何類的對(duì)象(根據(jù)安全性限制),無(wú)需提前硬編碼目標(biāo)類。這些特性使得反射 特別適用于創(chuàng)建以非常普通的方式與對(duì)象協(xié)作的庫(kù)。例如,反射經(jīng)常在持續(xù)存儲(chǔ)對(duì)象為數(shù)據(jù)庫(kù)、XML或其它外部格式的框架中使用。Java reflection 非常有用,它使類和數(shù)據(jù)結(jié)構(gòu)能按名稱動(dòng)態(tài)檢索相關(guān)信息,并允許在運(yùn)行著的程序中操作這些信息。Java 的這一特性非常強(qiáng)大,并且是其它一些常用語(yǔ)言,如 C、C++、Fortran 或者 Pascal 等都不具備的。
但反射有兩個(gè)缺點(diǎn)。第一個(gè)是性能問(wèn)題。用于字段和方法接入時(shí)反射要遠(yuǎn)慢于直接代碼。性能問(wèn)題的程度取決于程序中是如何使用反射的。如果它作為程序運(yùn)行中相 對(duì)很少涉及的部分,緩慢的性能將不會(huì)是一個(gè)問(wèn)題。即使測(cè)試中最壞情況下的計(jì)時(shí)圖顯示的反射操作只耗用幾微秒。僅反射在性能關(guān)鍵的應(yīng)用的核心邏輯中使用時(shí)性 能問(wèn)題才變得至關(guān)重要。
許多應(yīng)用中更嚴(yán)重的一個(gè)缺點(diǎn)是使用反射會(huì)模糊程序內(nèi)部實(shí)際要發(fā)生的事情。程序人員希望在源代碼中看到程序的邏輯,反射等繞過(guò)了源代碼的技術(shù)會(huì)帶來(lái)維護(hù)問(wèn) 題。反射代碼比相應(yīng)的直接代碼更復(fù)雜,正如性能比較的代碼實(shí)例中看到的一樣。解決這些問(wèn)題的最佳方案是保守地使用反射——僅在它可以真正增加靈活性的地方 ——記錄其在目標(biāo)類中的使用。
一下是對(duì)應(yīng)各個(gè)部分的例子:
具體的應(yīng)用:
1、 模仿instanceof 運(yùn)算符號(hào)
class A {}
public class instance1 {
public static void main(String args[])
{
try {
Class cls = Class.forName("A");
boolean b1
= cls.isInstance(new Integer(37));
System.out.println(b1);
boolean b2 = cls.isInstance(new A());
System.out.println(b2);
}
catch (Throwable e) {
System.err.println(e);
}
}
}
2、 在類中尋找指定的方法,同時(shí)獲取該方法的參數(shù)列表,例外和返回值
import java.lang.reflect.*;
public class method1 {
private int f1(
Object p, int x) throws NullPointerException
{
if (p == null)
throw new NullPointerException();
return x;
}
public static void main(String args[])
{
try {
Class cls = Class.forName("method1");
Method methlist[]
= cls.getDeclaredMethods();
for (int i = 0; i < methlist.length;
i++)
Method m = methlist[i];
System.out.println("name
= " + m.getName());
System.out.println("decl class = " +
m.getDeclaringClass());
Class pvec[] = m.getParameterTypes();
for (int j = 0; j < pvec.length; j++)
System.out.println("
param #" + j + " " + pvec[j]);
Class evec[] = m.getExceptionTypes();
for (int j = 0; j < evec.length; j++)
System.out.println("exc #" + j
+ " " + evec[j]);
System.out.println("return type = " +
m.getReturnType());
System.out.println("-----");
}
}
catch (Throwable e) {
System.err.println(e);
}
}
}
3、 獲取類的構(gòu)造函數(shù)信息,基本上與獲取方法的方式相同
import java.lang.reflect.*;
public class constructor1 {
public constructor1()
{
}
protected constructor1(int i, double d)
{
}
public static void main(String args[])
{
try {
Class cls = Class.forName("constructor1");
Constructor ctorlist[]
= cls.getDeclaredConstructors();
for (int i = 0; i < ctorlist.length; i++) {
Constructor ct = ctorlist[i];
System.out.println("name
= " + ct.getName());
System.out.println("decl class = " +
ct.getDeclaringClass());
Class pvec[] = ct.getParameterTypes();
for (int j = 0; j < pvec.length; j++)
System.out.println("param #"
+ j + " " + pvec[j]);
Class evec[] = ct.getExceptionTypes();
for (int j = 0; j < evec.length; j++)
System.out.println(
"exc #" + j + " " + evec[j]);
System.out.println("-----");
}
}
catch (Throwable e) {
System.err.println(e);
}
}
}
4、 獲取類中的各個(gè)數(shù)據(jù)成員對(duì)象,包括名稱。類型和訪問(wèn)修飾符號(hào)
import java.lang.reflect.*;
public class field1 {
private double d;
public static final int i = 37;
String s = "testing";
public static void main(String args[])
{
try {
Class cls = Class.forName("field1");
Field fieldlist[]
= cls.getDeclaredFields();
for (int i
= 0; i < fieldlist.length; i++) {
Field fld = fieldlist[i];
System.out.println("name
= " + fld.getName());
System.out.println("decl class = " +
fld.getDeclaringClass());
System.out.println("type
= " + fld.getType());
int mod = fld.getModifiers();
System.out.println("modifiers = " +
Modifier.toString(mod));
System.out.println("-----");
}
}
catch (Throwable e) {
System.err.println(e);
}
}
}
5、 通過(guò)使用方法的名字調(diào)用方法
import java.lang.reflect.*;
public class method2 {
public int add(int a, int b)
{
return a + b;
}
public static void main(String args[])
{
try {
Class cls = Class.forName("method2");
Class partypes[] = new Class[2];
partypes[0] = Integer.TYPE;
partypes[1] = Integer.TYPE;
Method meth = cls.getMethod(
"add", partypes);
method2 methobj = new method2();
Object arglist[] = new Object[2];
arglist[0] = new Integer(37);
arglist[1] = new Integer(47);
Object retobj
= meth.invoke(methobj, arglist);
Integer retval = (Integer)retobj;
System.out.println(retval.intValue());
}
catch (Throwable e) {
System.err.println(e);
}
}
}
6、 創(chuàng)建新的對(duì)象
import java.lang.reflect.*;
public class constructor2 {
public constructor2()
{
}
public constructor2(int a, int b)
{
System.out.println(
"a = " + a + " b = " + b);
}
public static void main(String args[])
{
try {
Class cls = Class.forName("constructor2");
Class partypes[] = new Class[2];
partypes[0] = Integer.TYPE;
partypes[1] = Integer.TYPE;
Constructor ct
= cls.getConstructor(partypes);
Object arglist[] = new Object[2];
arglist[0] = new Integer(37);
arglist[1] = new Integer(47);
Object retobj = ct.newInstance(arglist);
}
catch (Throwable e) {
System.err.println(e);
}
}
}
7、 變更類實(shí)例中的數(shù)據(jù)的值
import java.lang.reflect.*;
public class field2 {
public double d;
public static void main(String args[])
{
try {
Class cls = Class.forName("field2");
Field fld = cls.getField("d");
field2 f2obj = new field2();
System.out.println("d = " + f2obj.d);
fld.setDouble(f2obj, 12.34);
System.out.println("d = " + f2obj.d);
}
catch (Throwable e) {
System.err.println(e);
}
}
}
使用反射創(chuàng)建可重用代碼:
1、 對(duì)象工廠
Object factory(String p) {
Class c;
Object o=null;
try {
c = Class.forName(p);// get class def
o = c.newInstance(); // make a new one
} catch (Exception e) {
System.err.println("Can't make a " + p);
}
return o;
}
public class ObjectFoundry {
public static Object factory(String p)
throws ClassNotFoundException,
InstantiationException,
IllegalAccessException {
Class c = Class.forName(p);
Object o = c.newInstance();
return o;
}
}
2、 動(dòng)態(tài)檢測(cè)對(duì)象的身份,替代instanceof
public static boolean
isKindOf(Object obj, String type)
throws ClassNotFoundException {
// get the class def for obj and type
Class c = obj.getClass();
Class tClass = Class.forName(type);
while ( c!=null ) {
if ( c==tClass ) return true;
c = c.getSuperclass();
}
return false;
}
打個(gè)比方:一個(gè)object就像一個(gè)大房子,大門(mén)永遠(yuǎn)打開(kāi)。房子里有很多房間(也就是方法)。這些房間有上鎖的(synchronized方法),和不上鎖之分(普通方法)。房門(mén)口放著一把鑰匙(key),這把鑰匙可以打開(kāi)所有上鎖的房間。另外我把所有想調(diào)用該對(duì)象方法的線程比喻成想進(jìn)入這房子某個(gè)房間的人。所有的東西就這么多了,下面我們看看這些東西之間如何作用的。
在此我們先來(lái)明確一下我們的前提條件。該對(duì)象至少有一個(gè)synchronized方法,否則這個(gè)key還有啥意義。當(dāng)然也就不會(huì)有我們的這個(gè)主題了。
一個(gè)人想進(jìn)入某間上了鎖的房間,他來(lái)到房子門(mén)口,看見(jiàn)鑰匙在那兒(說(shuō)明暫時(shí)還沒(méi)有其他人要使用上鎖的房間)。于是他走上去拿到了鑰匙,并且按照自己的計(jì)劃使用那些房間。注意一點(diǎn),他每次使用完一次上鎖的房間后會(huì)馬上把鑰匙還回去。即使他要連續(xù)使用兩間上鎖的房間,中間他也要把鑰匙還回去,再取回來(lái)。
因此,普通情況下鑰匙的使用原則是:“隨用隨借,用完即還。”
這時(shí)其他人可以不受限制的使用那些不上鎖的房間,一個(gè)人用一間可以,兩個(gè)人用一間也可以,沒(méi)限制。但是如果當(dāng)某個(gè)人想要進(jìn)入上鎖的房間,他就要跑到大門(mén)口去看看了。有鑰匙當(dāng)然拿了就走,沒(méi)有的話,就只能等了。
要是很多人在等這把鑰匙,等鑰匙還回來(lái)以后,誰(shuí)會(huì)優(yōu)先得到鑰匙?Not guaranteed。象前面例子里那個(gè)想連續(xù)使用兩個(gè)上鎖房間的家伙,他中間還鑰匙的時(shí)候如果還有其他人在等鑰匙,那么沒(méi)有任何保證這家伙能再次拿到。(JAVA規(guī)范在很多地方都明確說(shuō)明不保證,象Thread.sleep()休息后多久會(huì)返回運(yùn)行,相同優(yōu)先權(quán)的線程那個(gè)首先被執(zhí)行,當(dāng)要訪問(wèn)對(duì)象的鎖被釋放后處于等待池的多個(gè)線程哪個(gè)會(huì)優(yōu)先得到,等等。我想最終的決定權(quán)是在JVM,之所以不保證,就是因?yàn)镴VM在做出上述決定的時(shí)候,絕不是簡(jiǎn)簡(jiǎn)單單根據(jù)一個(gè)條件來(lái)做出判斷,而是根據(jù)很多條。而由于判斷條件太多,如果說(shuō)出來(lái)可能會(huì)影響JAVA的推廣,也可能是因?yàn)橹R(shí)產(chǎn)權(quán)保護(hù)的原因吧。SUN給了個(gè)不保證就混過(guò)去了。無(wú)可厚非。但我相信這些不確定,并非完全不確定。因?yàn)橛?jì)算機(jī)這東西本身就是按指令運(yùn)行的。即使看起來(lái)很隨機(jī)的現(xiàn)象,其實(shí)都是有規(guī)律可尋。學(xué)過(guò)計(jì)算機(jī)的都知道,計(jì)算機(jī)里隨機(jī)數(shù)的學(xué)名是偽隨機(jī)數(shù),是人運(yùn)用一定的方法寫(xiě)出來(lái)的,看上去隨機(jī)罷了。另外,或許是因?yàn)橐肱拇_定太費(fèi)事,也沒(méi)多大意義,所以不確定就不確定了吧。)
再來(lái)看看同步代碼塊。和同步方法有小小的不同。
1.從尺寸上講,同步代碼塊比同步方法小。你可以把同步代碼塊看成是沒(méi)上鎖房間里的一塊用帶鎖的屏風(fēng)隔開(kāi)的空間。
2.同步代碼塊還可以人為的指定獲得某個(gè)其它對(duì)象的key。就像是指定用哪一把鑰匙才能開(kāi)這個(gè)屏風(fēng)的鎖,你可以用本房的鑰匙;你也可以指定用另一個(gè)房子的鑰匙才能開(kāi),這樣的話,你要跑到另一棟房子那兒把那個(gè)鑰匙拿來(lái),并用那個(gè)房子的鑰匙來(lái)打開(kāi)這個(gè)房子的帶鎖的屏風(fēng)。
記住你獲得的那另一棟房子的鑰匙,并不影響其他人進(jìn)入那棟房子沒(méi)有鎖的房間。
為什么要使用同步代碼塊呢?我想應(yīng)該是這樣的:首先對(duì)程序來(lái)講同步的部分很影響運(yùn)行效率,而一個(gè)方法通常是先創(chuàng)建一些局部變量,再對(duì)這些變量做一些操作,如運(yùn)算,顯示等等;而同步所覆蓋的代碼越多,對(duì)效率的影響就越嚴(yán)重。因此我們通常盡量縮小其影響范圍。如何做?同步代碼塊。我們只把一個(gè)方法中該同步的地方同步,比如運(yùn)算。
另外,同步代碼塊可以指定鑰匙這一特點(diǎn)有個(gè)額外的好處,是可以在一定時(shí)期內(nèi)霸占某個(gè)對(duì)象的key。還記得前面說(shuō)過(guò)普通情況下鑰匙的使用原則嗎。現(xiàn)在不是普通情況了。你所取得的那把鑰匙不是永遠(yuǎn)不還,而是在退出同步代碼塊時(shí)才還。
還用前面那個(gè)想連續(xù)用兩個(gè)上鎖房間的家伙打比方。怎樣才能在用完一間以后,繼續(xù)使用另一間呢。用同步代碼塊吧。先創(chuàng)建另外一個(gè)線程,做一個(gè)同步代碼塊,把那個(gè)代碼塊的鎖指向這個(gè)房子的鑰匙。然后啟動(dòng)那個(gè)線程。只要你能在進(jìn)入那個(gè)代碼塊時(shí)抓到這房子的鑰匙,你就可以一直保留到退出那個(gè)代碼塊。也就是說(shuō)你甚至可以對(duì)本房?jī)?nèi)所有上鎖的房間遍歷,甚至再sleep(10*60*1000),而房門(mén)口卻還有1000個(gè)線程在等這把鑰匙呢。很過(guò)癮吧。
在此對(duì)sleep()方法和鑰匙的關(guān)聯(lián)性講一下。一個(gè)線程在拿到key后,且沒(méi)有完成同步的內(nèi)容時(shí),如果被強(qiáng)制sleep()了,那key還一直在它那兒。直到它再次運(yùn)行,做完所有同步內(nèi)容,才會(huì)歸還key。記住,那家伙只是干活干累了,去休息一下,他并沒(méi)干完他要干的事。為了避免別人進(jìn)入那個(gè)房間把里面搞的一團(tuán)糟,即使在睡覺(jué)的時(shí)候他也要把那唯一的鑰匙戴在身上。
最后,也許有人會(huì)問(wèn),為什么要一把鑰匙通開(kāi),而不是一個(gè)鑰匙一個(gè)門(mén)呢?我想這純粹是因?yàn)閺?fù)雜性問(wèn)題。一個(gè)鑰匙一個(gè)門(mén)當(dāng)然更安全,但是會(huì)牽扯好多問(wèn)題。鑰匙的產(chǎn)生,保管,獲得,歸還等等。其復(fù)雜性有可能隨同步方法的增加呈幾何級(jí)數(shù)增加,嚴(yán)重影響效率。
這也算是一個(gè)權(quán)衡的問(wèn)題吧。為了增加一點(diǎn)點(diǎn)安全性,導(dǎo)致效率大大降低,是多么不可取啊。
摘自:http://www.54bk.com/more.asp?name=czp&id=2097
一、當(dāng)兩個(gè)并發(fā)線程訪問(wèn)同一個(gè)對(duì)象object中的這個(gè)synchronized(this)同步代碼塊時(shí),一個(gè)時(shí)間內(nèi)只能有一個(gè)線程得到執(zhí)行。另一個(gè)線程必須等待當(dāng)前線程執(zhí)行完這個(gè)代碼塊以后才能執(zhí)行該代碼塊。
二、然而,當(dāng)一個(gè)線程訪問(wèn)object的一個(gè)synchronized(this)同步代碼塊時(shí),另一個(gè)線程仍然可以訪問(wèn)該object中的非synchronized(this)同步代碼塊。
三、尤其關(guān)鍵的是,當(dāng)一個(gè)線程訪問(wèn)object的一個(gè)synchronized(this)同步代碼塊時(shí),其他線程對(duì)object中所有其它synchronized(this)同步代碼塊的訪問(wèn)將被阻塞。
四、第三個(gè)例子同樣適用其它同步代碼塊。也就是說(shuō),當(dāng)一個(gè)線程訪問(wèn)object的一個(gè)synchronized(this)同步代碼塊時(shí),它就獲得了這個(gè)object的對(duì)象鎖。結(jié)果,其它線程對(duì)該object對(duì)象所有同步代碼部分的訪問(wèn)都被暫時(shí)阻塞。
五、以上規(guī)則對(duì)其它對(duì)象鎖同樣適用.
舉例說(shuō)明:
一、當(dāng)兩個(gè)并發(fā)線程訪問(wèn)同一個(gè)對(duì)象object中的這個(gè)synchronized(this)同步代碼塊時(shí),一個(gè)時(shí)間內(nèi)只能有一個(gè)線程得到執(zhí)行。另一個(gè)線程必須等待當(dāng)前線程執(zhí)行完這個(gè)代碼塊以后才能執(zhí)行該代碼塊。
package ths;
public class Thread1 implements Runnable {
public void run() {
synchronized(this) {
for (int i = 0; i < 5; i++) {
System.out.println(Thread.currentThread().getName() + " synchronized loop " + i);
}
}
}
public static void main(String[] args) {
Thread1 t1 = new Thread1();
Thread ta = new Thread(t1, "A");
Thread tb = new Thread(t1, "B");
ta.start();
tb.start();
}
}
結(jié)果:
A synchronized loop 0
A synchronized loop 1
A synchronized loop 2
A synchronized loop 3
A synchronized loop 4
B synchronized loop 0
B synchronized loop 1
B synchronized loop 2
B synchronized loop 3
B synchronized loop 4
二、然而,當(dāng)一個(gè)線程訪問(wèn)object的一個(gè)synchronized(this)同步代碼塊時(shí),另一個(gè)線程仍然可以訪問(wèn)該object中的非synchronized(this)同步代碼塊。
package ths;
public class Thread2 {
public void m4t1() {
synchronized(this) {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
}
public void m4t2() {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
public static void main(String[] args) {
final Thread2 myt2 = new Thread2();
Thread t1 = new Thread(
new Runnable() {
public void run() {
myt2.m4t1();
}
}, "t1"
);
Thread t2 = new Thread(
new Runnable() {
public void run() {
myt2.m4t2();
}
}, "t2"
);
t1.start();
t2.start();
}
}
結(jié)果:
t1 : 4
t2 : 4
t1 : 3
t2 : 3
t1 : 2
t2 : 2
t1 : 1
t2 : 1
t1 : 0
t2 : 0
三、尤其關(guān)鍵的是,當(dāng)一個(gè)線程訪問(wèn)object的一個(gè)synchronized(this)同步代碼塊時(shí),其他線程對(duì)object中所有其它synchronized(this)同步代碼塊的訪問(wèn)將被阻塞。
//修改Thread2.m4t2()方法:
public void m4t2() {
synchronized(this) {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
}
結(jié)果:
t1 : 4
t1 : 3
t1 : 2
t1 : 1
t1 : 0
t2 : 4
t2 : 3
t2 : 2
t2 : 1
t2 : 0
四、第三個(gè)例子同樣適用其它同步代碼塊。也就是說(shuō),當(dāng)一個(gè)線程訪問(wèn)object的一個(gè)synchronized(this)同步代碼塊時(shí),它就獲得了這個(gè)object的對(duì)象鎖。結(jié)果,其它線程對(duì)該object對(duì)象所有同步代碼部分的訪問(wèn)都被暫時(shí)阻塞。
//修改Thread2.m4t2()方法如下:
public synchronized void m4t2() {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
結(jié)果:
t1 : 4
t1 : 3
t1 : 2
t1 : 1
t1 : 0
t2 : 4
t2 : 3
t2 : 2
t2 : 1
t2 : 0
五、以上規(guī)則對(duì)其它對(duì)象鎖同樣適用:
package ths;
public class Thread3 {
class Inner {
private void m4t1() {
int i = 5;
while(i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : Inner.m4t1()=" + i);
try {
Thread.sleep(500);
} catch(InterruptedException ie) {
}
}
}
private void m4t2() {
int i = 5;
while(i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : Inner.m4t2()=" + i);
try {
Thread.sleep(500);
} catch(InterruptedException ie) {
}
}
}
}
private void m4t1(Inner inner) {
synchronized(inner) { //使用對(duì)象鎖
inner.m4t1();
}
}
private void m4t2(Inner inner) {
inner.m4t2();
}
public static void main(String[] args) {
final Thread3 myt3 = new Thread3();
final Inner inner = myt3.new Inner();
Thread t1 = new Thread(
new Runnable() {
public void run() {
myt3.m4t1(inner);
}
}, "t1"
);
Thread t2 = new Thread(
new Runnable() {
public void run() {
myt3.m4t2(inner);
}
}, "t2"
);
t1.start();
t2.start();
}
}
結(jié)果:
盡管線程t1獲得了對(duì)Inner的對(duì)象鎖,但由于線程t2訪問(wèn)的是同一個(gè)Inner中的非同步部分。所以兩個(gè)線程互不干擾。
t1 : Inner.m4t1()=4
t2 : Inner.m4t2()=4
t1 : Inner.m4t1()=3
t2 : Inner.m4t2()=3
t1 : Inner.m4t1()=2
t2 : Inner.m4t2()=2
t1 : Inner.m4t1()=1
t2 : Inner.m4t2()=1
t1 : Inner.m4t1()=0
t2 : Inner.m4t2()=0
現(xiàn)在在Inner.m4t2()前面加上synchronized:
private synchronized void m4t2() {
int i = 5;
while(i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : Inner.m4t2()=" + i);
try {
Thread.sleep(500);
} catch(InterruptedException ie) {
}
}
}
結(jié)果:
盡管線程t1與t2訪問(wèn)了同一個(gè)Inner對(duì)象中兩個(gè)毫不相關(guān)的部分,但因?yàn)閠1先獲得了對(duì)Inner的對(duì)象鎖,所以t2對(duì)Inner.m4t2()的訪問(wèn)也被阻塞,因?yàn)閙4t2()是Inner中的一個(gè)同步方法。
t1 : Inner.m4t1()=4
t1 : Inner.m4t1()=3
t1 : Inner.m4t1()=2
t1 : Inner.m4t1()=1
t1 : Inner.m4t1()=0
t2 : Inner.m4t2()=4
t2 : Inner.m4t2()=3
t2 : Inner.m4t2()=2
t2 : Inner.m4t2()=1
t2 : Inner.m4t2()=0
同步買(mǎi)票問(wèn)題
public class TicketsSystem {
public static void main(String[] args) {
SellThread st = new SellThread();
Thread th1 = new Thread(st);
th1.start();
Thread th2 = new Thread(st);
th2.start();
Thread th3 = new Thread(st);
th3.start();
}
}
class SellThread implements Runnable {
private int number=10;
String s = new String();
public void run() {
while (number > 0) {
synchronized (s) {
System.out.println("第" + number + "個(gè)人在"
+ Thread.currentThread().getName() + "買(mǎi)票");
}
number--;
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
Java線程:線程的同步-同步塊
對(duì)于同步,除了同步方法外,還可以使用同步代碼塊,有時(shí)候同步代碼塊會(huì)帶來(lái)比同步方法更好的效果。
追其同步的根本的目的,是控制競(jìng)爭(zhēng)資源的正確的訪問(wèn),因此只要在訪問(wèn)競(jìng)爭(zhēng)資源的時(shí)候保證同一時(shí)刻只能一個(gè)線程訪問(wèn)即可,因此Java引入了同步代碼快的策略,以提高性能。
在上個(gè)例子的基礎(chǔ)上,對(duì)oper方法做了改動(dòng),由同步方法改為同步代碼塊模式,程序的執(zhí)行邏輯并沒(méi)有問(wèn)題。
/**
* Java線程:線程的同步-同步代碼塊
*
* @author leizhimin 2009-11-4 11:23:32
*/
public class Test {
public static void main(String[] args) {
User u = new User("張三", 100);
MyThread t1 = new MyThread("線程A", u, 20);
MyThread t2 = new MyThread("線程B", u, -60);
MyThread t3 = new MyThread("線程C", u, -80);
MyThread t4 = new MyThread("線程D", u, -30);
MyThread t5 = new MyThread("線程E", u, 32);
MyThread t6 = new MyThread("線程F", u, 21);
t1.start();
t2.start();
t3.start();
t4.start();
t5.start();
t6.start();
}
}
class MyThread extends Thread {
private User u;
private int y = 0;
MyThread(String name, User u, int y) {
super(name);
this.u = u;
this.y = y;
}
public void run() {
u.oper(y);
}
}
class User {
private String code;
private int cash;
User(String code, int cash) {
this.code = code;
this.cash = cash;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
/**
* 業(yè)務(wù)方法
*
* @param x 添加x萬(wàn)元
*/
public void oper(int x) {
try {
Thread.sleep(10L);
synchronized (this) {
this.cash += x;
System.out.println(Thread.currentThread().getName() + "運(yùn)行結(jié)束,增加“" + x + "”,當(dāng)前用戶賬戶余額為:" + cash);
}
Thread.sleep(10L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return "User{" +
"code='" + code + '\'' +
", cash=" + cash +
'}';
}
}
線程E運(yùn)行結(jié)束,增加“32”,當(dāng)前用戶賬戶余額為:132
線程B運(yùn)行結(jié)束,增加“-60”,當(dāng)前用戶賬戶余額為:72
線程D運(yùn)行結(jié)束,增加“-30”,當(dāng)前用戶賬戶余額為:42
線程F運(yùn)行結(jié)束,增加“21”,當(dāng)前用戶賬戶余額為:63
線程C運(yùn)行結(jié)束,增加“-80”,當(dāng)前用戶賬戶余額為:-17
線程A運(yùn)行結(jié)束,增加“20”,當(dāng)前用戶賬戶余額為:3
Process finished with exit code 0
注意:
在使用synchronized關(guān)鍵字時(shí)候,應(yīng)該盡可能避免在synchronized方法或synchronized塊中使用sleep或者yield方法,因?yàn)閟ynchronized程序塊占有著對(duì)象鎖,你休息那么其他的線程只能一邊等著你醒來(lái)執(zhí)行完了才能執(zhí)行。不但嚴(yán)重影響效率,也不合邏輯。
同樣,在同步程序塊內(nèi)調(diào)用yeild方法讓出CPU資源也沒(méi)有意義,因?yàn)槟阏加弥i,其他互斥線程還是無(wú)法訪問(wèn)同步程序塊。當(dāng)然與同步程序塊無(wú)關(guān)的線程可以獲得更多的執(zhí)行時(shí)間。