@echo off
: basedata
set ip=10.39.28.234
set user=root
set password=root1234
set databaseName=crm_cloud
set /a backupDays=7
set mysqlBinPath=C:\Program Files (x86)\MySQL\MySQL Server 6.0\bin\
set mysqlBackupPath=C:\mysql_back\
set logs=%mysqlBackupPath%\logs.txt
set day=%date:~7,2%
set month=%date:~4,2%
set /a year=%date:~10,4%
if not exist %mysqlBackupPath% md %mysqlBackupPath%
echo %year%-%month%-%day% >> %logs%
set backupingFilePath=%mysqlBackupPath%\%databaseName%_%year%-%month%-%day%.sql
cd /d %mysqlBinPath%
echo backupdata >> %logs%
set errorlevel=0
echo errorlevel=%errorlevel%
mysqldump -h%ip% -u%user% -p%password% --default-character-set=gbk --opt --extended-insert=false --triggers -R --hex-blob -x %databaseName%>%backupingFilePath%
set /a myerrorlevel=%errorlevel%
echo myerrorlevel=%myerrorlevel%
if %myerrorlevel% leq 0 (
if exist %backupingFilePath% (
echo backupcomplete mysqlBackup_%year%-%month%-%day%.sql
echo backupcomplete mysqlBackup_%year%-%month%-%day%.sql >> %logs%
) else (
echo backupfaile
echo backupfaile >> %logs%
pause
exit
)
) else (
echo backupfail
echo backupfail >> %logs%
if exist %backupingFilePath% (
del %backupingFilePath%
)
pause
exit
)
rem delete backupDays's backup
set /a day=1%day%-100-backupDays
rem
if %day% lss 1 (
set /a daysTemp=day
call :daysOfLastMonth
) else set /a daysTemp=0
set /a day+=daysTemp
rem
if day lss 10 (set day=0%day%)
set /a month=%month%
if %month% lss 10 (set month=0%month%)
set deleteBackupFilePath=%databaseName%%year%%month%%day%.sql
echo mysqlBackup_%year%-%month%-%day%.sql
echo mysqlBackup_%year%-%month%-%day%.sql >> %logs%
if exist %mysqlBackupPath%\%deleteBackupFilePath% (
del %mysqlBackupPath%\%deleteBackupFilePath%
echo delcomplete >> %logs%
) else (
echo the document isn't exist >> %logs%
)
echo -----------------------------------------------------end >> %logs%
:daysOfLastMonth
set /a month=%month%-1
set /a mod1=%year%%%4
set /a mod2=%year%%%100
if %month% lss 1 (
set month=12
set year=%year%-1
set day=31
) else (
if %month% == 2 (
set day=28
if %mod1% == 0 (
set day=29
if mod2 == 0 (
set day=28
)
)
) else (
for %%a in (1 3 5 7 8 10 12) do (
if %month% == %%a (
set day=31
goto :eof
)
)
set day=30
)
)
goto :eof
以上為windows版本
----------------------------------------------------
以下為linux版本第一個
#!/bin/bash
#Write by oneleaf@gmail.com
#數據庫服務器地址
DBHOST=localhost
#數據庫登錄名
USERNAME=root
#數據庫密碼
PASSWORD=
#需要備份的數據庫 或 輸入類似 db1 db2 的列表清單
DBNAMES="all"
#備份MYSQL時生成CREATE數據庫語句
CREATE_DATABASE="yes"
#備份的目錄
BACKUPDIR="/tmp/mysqlbackup"
#發(fā)生到郵件的地址
MAILADDR="test@example.com"
#郵件最大附件尺寸2M
MAILMAXATTSIZE="2000000"
#當前備份日期和時間
DATE=`date +%Y-%m-%d_%H_%M`
OPT="--quote-names --opt"
#檢查備份路徑是否存在,不存在則建立
if [ ! -e "${BACKUPDIR}" ]; then
mkdir -p "${BACKUPDIR}"
fi
#刪除備份路徑下的所有文件
rm -fv ${BACKUPDIR}/*
#檢查是否需要生成CREATE數據庫語句
if [ "${CREATE_DATABASE}" = "yes" ]; then
OPT="${OPT} --databases"
else
OPT="${OPT} --no-create-db"
fi
#檢查是否是備份所有數據庫
if [ "${DBNAMES}" = "all" ]; then
DBNAMES="--all-databases"
fi
BACKUPFILE=${DATE}.sql.gz
cd ${BACKUPDIR}
#備份數據庫
`which mysqldump` --user=${USERNAME} --password=${PASSWORD} --host=${DBHOST} ${OPT} ${DBNAMES} |gzip > "${BACKUPFILE}"
#獲取備份文件的尺寸
BACKFILESIZE=`du -b ${BACKUPFILE}|sed -e "s/\t.*$//"`
#檢查是否需要分割
if [ ${BACKFILESIZE} -ge ${MAILMAXATTSIZE} ]; then
#分割數據庫,合并使用 cat ${BACKUPFILE}.* > ${BACKUPFILE}
`which split` -b ${MAILMAXATTSIZE} ${BACKUPFILE} ${BACKUPFILE}.
for BFILE in ${BACKUPFILE}.*
do
echo "Backup Databases: ${DBNAMES}; Use cat ${BACKUPFILE}.* > ${BACKUPFILE}" | mutt ${MAILADDR} -s "MySQL Backup SQL Files for ${HOST} - ${DATE}" -a "${BFILE}"
done
else
echo "Backup Databases: ${DBNAMES}" | mutt ${MAILADDR} -s "MySQL Backup SQL Files for ${HOST} - ${DATE}" -a "${BACKUPFILE}"
fi
--------------------------------------------------------------------------
以下為第二個版本
ubuntu定時備份mysql,首先要寫一段shell腳本,用來備份mysql數據庫,再通過crontab定時執(zhí)行備份mysql數據庫的shell腳本。
1.備份mysql的shell腳本如下:
?
1
2
3
4
5
6
#!/bin/bash
date_str=$(date +%Y%m%d-%T)
cd /home/steven/backup
mysqldump -h localhost -u root --password=xxxx -R -E -e \
--max_allowed_packet=1048576 --net_buffer_length=16384 databaseName\
| gzip > /home/steven/backup/juziku_$date_str.sql.gz
把上面這個腳本存放位置:/home/steven/mysql_backup.sh (當然,也可以放在其他位置)
再賦于執(zhí)行的權限,通過下面命令:
sudo chmod +x /home/steven/mysql_backup.sh
完成這步,我們就來執(zhí)行一下這段腳本,看能不能備份mysql數據庫。
在命令行輸入
./mysql_backup.sh
就可以看到備份好的數據庫文件了
2.完成上面這步,就可以備份mysql數據庫了,接下來,我們再通過crontab定時執(zhí)行這段腳本。
使用crontab -e命令,這個命令的使用比較簡單。
在命令行輸入中,直接輸入 crontab -e
就會打開一個編輯窗口,最后一行會有內容格式的提示:
# m h dom mon dow command
具體意義表示:分鐘 小時 日期 月份 星期 命令,在某月(mon)的某天(dom)或者星期幾(dow)的幾點(h,24小時制)幾分(m)執(zhí)行某個命令(command),*表示任意時間。例如:0 3 * * * /home/steven/mysql_backup.sh就是:每天早上3點,執(zhí)行mysql_backup.sh腳本。
我們只要在里面添加一行就行了,內容如下:
?
1
2
# 備份mysql數據庫 每天早上3點整執(zhí)行
0 3 * * * /home/steven/mysql_backup.sh
這樣,每天早上3點,就會自動備份mysql數據庫了。
-=----------------------------------------
第三個版本
我只需要
1、創(chuàng)建保存?zhèn)浞菸募哪夸洠?home/mysql_data
cd /home
mkdir mysql_data
2、創(chuàng)建備份腳本文件:/home/mysql_data/mysql_databak.sh
cd /home
cd mysql_data
touch mysql_databak.sh
vim mysql_databak.sh
輸入以下內容:
1
#!/bin/sh
2
/etc/init.d/mysqld stop #執(zhí)行備份前先停止MySql,防止有數據正在寫
入,備份出錯
3
date=` date +%Y%m%d ` #獲取當前日期
4
DAYS=7 #DAYS=7代表刪除7天前的備份,即只保留最近
7天的備份
5
BK_DR=/home/mysql_data #備份文件存放路徑
6
DB_DR=/var/lib/mysql/pw85 #數據庫路徑
7
LINUX_USER=root #系統(tǒng)用戶名
8
tar zcvf $BK_DR/mysql_data$date.tar.gz $DB_DR #備份數據
========================================第2頁========================================
9
/etc/init.d/mysqld start #備份完成后,啟動MySql
10
chown -R $LINUX_USER:$LINUX_USER $BK_DR #更改備份
數據庫文件的所有者
11
find $BK_DR -name "mysql_data*" -type f -mtime +$DAYS -exec rm {} \
;
#刪除7天前的備份文件(注意:{} \;中間有空格)
12
deldate=` date -d -7day +%Y_%m_%d ` #刪除ftp服務器空間7天前的備份
13
ftp -n<open 192.168.1.1 21 #打開ftp服務器。21為ftp端口
14
user admin 123456 #用戶名、密碼
15
binary #設置二進制傳輸
16
cd mysqlbak #進入ftp目錄(注意:這個目錄必須真實存在)
17
lcd /home/mysql_data #列出本地目錄
18
prompt
19
mput mysql_data$date.tar.gz mysql_data$date.tar.gz #上傳目錄中的
文件
20
mdelete mysql_data$deldate.tar.gz mysql_data$deldate.tar.gz #刪除
ftp空間7天前的備份
21
close #關閉
22
bye ! #退出
3、修改文件屬性,使其可執(zhí)行
chmod +x /home/mysql_data/mysql_databak.sh
4、修改/etc/crontab #添加計劃任務
vi /etc/crontab #在下面添加
5 23 * * * root /home/mysql_data/mysql_databak.sh #表示每天23點05分
執(zhí)行備份
5、重新啟動crond使設置生效
/etc/rc.d/init.d/crond restart
chkconfig crond on #設為開機啟動
service crond start #啟動
作為一個開發(fā)團隊的管理者,例如當你是一個團隊的項目經理的時候,任務的完成情況通常是你最關心的內容之一,比如說分配的任務是否能夠按時間完成,整個項目的進度是否尚在計劃之中,團隊內的人是不是都在高效地工作,大家有沒有什么困難,這些是你經常會關注的問題。在軟件開發(fā)團隊中,任務的分配、跟蹤和管理通常是這個團隊管理者的一個重要的工作內容。
1、從問題談起
我曾經碰到過一個項目經理,她管理著一個團隊開發(fā)一個web應用,團隊里開發(fā)人員大概10個左右,測試人 員3個,業(yè)務分析師1個人。對于任務的管理她是這么做的。通常,她會將需求分析人員分析得到的需求給每個人分一些。然后每個人在領到任務之后會給她承諾一 個大致的時間點。整個項目大致的交付計劃用一個excel表管理著,根據客戶要求的交付時間點,并且考慮到一些需求之間的集成測試關系,定出了每個需求的 大致交付時間點。只要每個開發(fā)人員承諾的時間點和期望的相差不大,她都可以接受,每個開發(fā)人員這樣就知道自己應該在什么時間點交付什么東西。
一切本該很完美,但是不和諧的問題不斷出現。最經常發(fā)生的事情就是大家在承諾的時間點快要到的時候不能按時交付,每次她詢問進度的時候,會被告知還差一 點就完成了。通常的說法是“底層部分已經做完了,或還差頁面部分就可以搞定了”,然而實際情況是又過了相當的時間才真正完成。當然也不是沒有按時交付的需 求,但是她發(fā)現也許是大家經常加班,已經開始疲倦了,有時候明明很簡單的可以提前完成的需求,大家還是到最后一刻才交付給測試。
也有的 開發(fā)人員拿到自己的那一批需求之后,會批量工作,把若干個類似的需求的底層邏輯全部實現,然后再實現上層內容。她默認了這種做法,就像這位開發(fā)人員說的 “這幾個需求都差不多,只要底層做好了,基本上就都差不多完成了”。雖然這部分工作早點和其他人一起集成測試會比較好,但是他這樣做也只能推后集成測試的 時間點了。還好承諾給測試團隊的交付時間點還在1個月之后,只要1個月之內能夠完成這些需求就可以了。
還有一些其他的問題,比如有的新 人經常碰到問題,然而出了問題并不會主動問其他人,而是在胡亂嘗試中浪費了時間。組里還有個開發(fā)人員非常激進,經常花時間去重構代碼,追求完美的架構設 計,進度很讓人擔憂。組內的開發(fā)人員有時候還經常被其他項目的事情打擾,因為有幾個人剛剛從上一個項目中調過來,上個項目的有些問題只有他們熟悉和有能力 解決。她就不止一次發(fā)現,有一個開發(fā)人員經常在修復其他項目的bug。
她會不定時地去詢問每個開發(fā)人員的開發(fā)進度,當需求的計劃交付時 間點逼近的時候,這種檢查會越來越頻繁,開發(fā)人員感受到壓力,有時候甚至需要加班來完成開發(fā)工作。然而盡管她花了很多精力去跟蹤和檢查每個需求的完成情 況,還是有很多出乎期望的事情在不斷發(fā)生。盡管她一直相信說,只要開發(fā)人員們能夠完成任務,采用什么方式她是不干預的,而具體的時間也是由他們自己分配 的。但是她漸漸感覺到,任務越來越不可控,計劃通常無法按時完成,每天對大家的檢查花了大部分時間,然而卻不能揭示出真正的問題。
運轉 良好的項目都差不多,而問題項目的問題各有各的不同。盡管每個團隊的問題可能不完全相同,但是當我們審視這些項目的運作和管理方式的時候,不難發(fā)現一些諸 如多任務并行等共性的問題,這些問題給軟件項目帶來了各種各樣的浪費。當一個團隊采用瀑布開發(fā)模式的時候,開發(fā)階段全部結束之后測試人員才會介入,開展測 試活動,在一個通常很漫長的開發(fā)階段內,各種開發(fā)活動中的浪費、估計的不準確,以及成員自己的拖沓、被打擾、問題阻塞等,都被掩蓋住了。只要在最終時間點 前能夠全部開發(fā)完成,不管是前松后緊,還是加班熬夜,都已經成了項目開發(fā)的常態(tài)。項目經理只能看到交付的最終時間點,問題不能及時的暴露,而等到問題被暴 露的時候,可以使用的調整手段也非常有限。
這樣的一種團隊生存狀態(tài)在外部環(huán)境要求短交付周期,需求允許經常變化的情況下顯示出了極度地 不適應。市場環(huán)境的變化驅動了軟件需求的變化,這種變化催生了縮短交付周期的訴求,較短的交付周期使得人們可以不必去預期過于長遠的需求,具備根據市場的 變化快速地制定和調整軟件需求的能力。而當交付模型由幾個月的瀑布模型轉變?yōu)閿抵苌踔粮痰牡P偷臅r候,我們在前面談到的團隊中的各種浪費、低效、半 成品堆積等問題,就會急劇地爆發(fā)出來。
熟悉敏捷方 法的讀者可能都知道,敏捷方法包含一系列實踐來幫助團隊實現短周期快速交付,更好地響應需求變化。比如說userstory方法,將需求從用戶價值的角度 進行組織,避免將需求從功能模塊角度劃分。小粒度的用戶故事可以在一兩周的迭代內完成開發(fā)和測試(并行開發(fā)),從而可以縮短交付周期。問題是,在敏捷團隊 內,我們是如何有效管理大量小粒度userstory,同時避免上述項目管理中的問題呢?下面我們結合敏捷開發(fā)中的看板工具來看看敏捷團隊是如何管理任務的。
2、可視化看板任務管理

看板源于精益生產實踐,敏捷將其背后的可視化管理理念借鑒過來,經過一番改造,形成了有自己獨特風格的可視化管理工具。曾有人總結過scrum和kanban的使用,而很多時候,我們也將它叫做迭代狀態(tài)墻。
先看看我們怎么樣能用這個狀態(tài)墻來管理迭代任務。說起來其實是一個很簡單的東西。
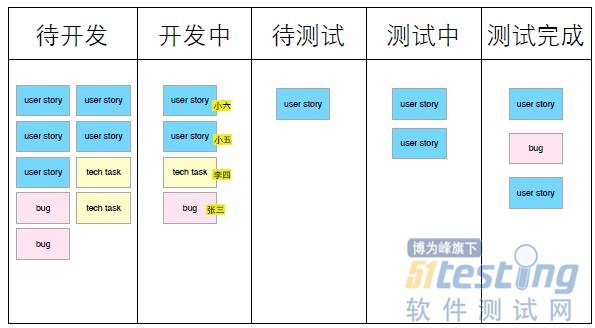
通常一個迭代的狀態(tài)墻上反映了某一個迭代的計劃和任務進展情況。狀態(tài)墻上按照一個迭代內團隊的典型開發(fā)活動分成幾欄,例如“待開發(fā)”、“開發(fā) 中”、“待測試”、“測試中”、“測試完成”等。在一個迭代之初,我們會將計劃在本迭代完成的故事卡放到“待開發(fā)”這一欄中。可視化狀態(tài)墻的一個好處就是 所有團隊成員都可以實時地了解到本迭代的計劃和進展情況。開發(fā)人員領取任務時,就將他領取的故事卡片從“待開發(fā)”移到“開發(fā)中”,同時貼上帶有自己名字的 小紙條。當他開發(fā)完成之后,就將故事卡片移到“待測試”一欄。我們的測試人員看到這一欄里有待測的故事卡時,就取下一張,移動到“測試中”,開始這個用戶 故事的測試,測試完成后,就將故事卡移動到“測試完成”一欄。如果測試人員發(fā)現了一個bug,那么他可以用紅顏色的卡片記下這個bug,然后放到待開發(fā)這 一欄中。在狀態(tài)墻上,除了用戶故事、bug之外,還會有一些諸如重構、搭建測試環(huán)境這樣的不直接產生業(yè)務價值的任務,這三類任務用不同顏色的卡片,放到狀 態(tài)墻上統(tǒng)一管理。
這樣一個簡單的工具,是如何幫助我們消除浪費、解決項目管理中的問題的?讓我們逐條分析一下看看。
2.1 如何減少返工帶來的浪費
返工是軟件開發(fā)過程中的一大嚴重浪費。比如說開發(fā)人員開發(fā)完成的任務交給測試人員測試的時候,關鍵流程不能走通,阻礙了測試進程;交付給客戶的 東西被客戶說“這不是我想要的東西”;分析人員將還沒分析透徹的任務交給開發(fā)人員,在最后驗收的時候發(fā)現開發(fā)人員加入了自己的一些“發(fā)揮”。這些都會造成 返工。返工意味著沒有一次性將事情做對,意味著流程中的上游沒有交付高質量的工作,也可能意味著團隊成員間的溝通出了問題。
在傳統(tǒng)的瀑布流程中,我們往往是期望通過前期細致入微的工作來確保一個階段的工作被高質量完成之后才移交到下一階段。后來我們慢慢從失敗的經驗 中學習到,這種方法在變化的需求環(huán)境下實在是太過脆弱,不僅不能如愿保證質量,而且會造成更大的浪費,交付周期也不能滿足要求。于是我們引入了迭代式開發(fā) 方法,一個需求的分析、開發(fā)、測試、驗收成了一個小粒度地更連續(xù)的過程,在這個小的交付循環(huán)中,看板幫助我們以更細節(jié)的粒度來管理一個任務每個階段的工作 質量。
通常我們是這么做的。當我們把一張故事卡從“待開發(fā)”移動到“開發(fā)中”時,這張卡片必須是已經分析完成的。也就是說,當開發(fā)人員準備真正開始開 發(fā)這張故事卡之前,我們的需求分析師們必須保證這張卡片所包含的所有內容和細節(jié)已經被分析完成,不再有模棱兩可的細節(jié),不再留給開發(fā)人員過多的自我發(fā)揮和 想象空間,而且這些細節(jié)必須和客戶確認過,而不只是團隊自己“設計”的結果。
這一道關看似很尋常,實際上很多項目會在這里出問題。很多時候開發(fā)人員開始開發(fā)的時候,需求還沒有分析完成,很多細節(jié)尚須澄清確認,實現上的技 術風險還沒有被完全排除。也有的分析師善于給開發(fā)人員留有大量自我發(fā)揮空間,需求過于言簡意賅。開發(fā)人員開始開發(fā)這樣的需求時,要么做不下去,要么按照自 己的理解做下去。做完了之后分析師一看發(fā)現不對,和我想的不一樣,于是開發(fā)人員返工。最糟糕的情形莫過于最后被客戶發(fā)現說,這不是我當初想要的東西。
由此可見,確保開發(fā)人員挪卡的時候,這張待開發(fā)的用戶故事已經被真正分析完成,是我們準確實現用戶需求的第一步。通過規(guī)定這一挪卡的前提,同時 輔以用戶故事的澄清(由分析師向開發(fā)人員澄清)或者反向澄清(由開發(fā)人員向分析師講述自己的理解),可以很大程度上將返工減少到最低。
還有一種浪費發(fā)生在測試過程中。測試人員經常會發(fā)現,處于“待測試”狀態(tài)中的一些故事卡,在測試的時候主要的流程都走不通,根本無法進一步展開測試,于是乎不得不將故事卡
打回到開發(fā)人員手中。而往往這個時候開發(fā)人員已經工作在另一個用戶故事上了。要么他停下手中的任務解決測試的問題,要么讓測試人員等到這些問題修復過后再測。無論哪種都是不好的選擇。
這種問題的一個主要原因是因為開發(fā)人員聲稱他已經“開發(fā)完成”,將故事卡從“開發(fā)中”挪到“待測試”時,實際上自己并沒有對這部分功能進行測 試。或者是因為疏忽,或者是因為懶惰,或者是因為過于自信。通過在這個狀態(tài)轉換階段引入用戶故事初驗,讓分析師在挪卡之前先到開發(fā)人員機器上看看是否該故 事卡包含的功能被實現了,可以很大程度上提升效率,減少浪費。若分析師在初驗過程中發(fā)現了問題,那么開發(fā)人員馬上能以最小的成本進行修復,而不用等到之后 測試人員發(fā)現時再來修復。而且,分析師初驗也提供了一個判斷實現是否良好的反饋點,這是我們能夠看到一個需求是否被實現并能夠真正工作的最早的時間點。
2.2 如何避免多任務并行
多任務之間的頻繁切換是一個常見的問題。表現在團隊里的成員,特別是開發(fā)人員,會在不同的任務間切換。就像前面的故事中提到的,可能這一刻還在 實現某一個需求,而下一刻馬上就會被叫走去修復某一個遺留版本的缺陷。又或者該人手頭被分配了多個任務,每個任務都在進行中,而沒有一個處于完成狀態(tài)。任 務切換是導致效率降低的一個重要原因,不同任務間的上下文的切換會導致頻繁地將任務當前狀態(tài)在頭腦中“壓棧”和“出棧”,這些操作會耗費時間。如果完成一 個任務需要一個人一天時間,那么兩天內這個人可以完成兩個任務,但是如果他在第一天同時開始并行工作在這兩個任務上,那么完成這兩個任務會需要大于兩天的 時間。
大家可能已經注意到了,在前面的看板圖中,處于“開發(fā)中”的所有任務卡片上都有一個小紙條,上面標記著正在這張卡片上工作的人的名字。如果說有 兩個人結對在一個卡片上工作,那么這張卡片上應該有兩個名字。這一小小的實踐可以幫助我們隨時發(fā)現團隊內某一時刻,是否每個人只工作在一個任務上。
如果這一簡單的規(guī)則能夠嚴格被遵循,那么當我們看到一個人的名字出現在多張卡片上的時候,我們就知道這個人此刻可能忙著在多個任務之間切換,而每 一個任務都將不會在估計的時間點內完成。如果我們看到有人的名字沒有出現在任何卡片上,那么他目前大概處于休息狀態(tài)。團隊內的每個人的名字都應該對應在一 個小紙條上,如果你此刻工作在某個任務上,那么就將自己的名字貼到相應卡片上,如果此刻沒有工作在該任務上,就將自己的名字移去。
我們在領取“待開發(fā)”狀態(tài)欄中的卡片時,保證每次每人只領一張卡片,不要多領,完成了這張卡片之后,再回來領下一張。當一張卡片被認領之后,我 們就會對這張卡片進行跟蹤,在站會上談論它的完成情況,談論實現過程中碰到的問題。當它的進度和估計的可能偏差較大時,我們能夠及時而不是在最后一刻察覺 到,提供需要的幫助,確保它能夠順利完成。這樣一種方式讓我們能夠將注意力集中到小粒度的需求(例如用戶故事)上,更多地關注這些用戶故事的流動速度。而 當每個小的用戶故事能夠順暢地流動起來時,整個項目的交付也得到了保障。
當然這一實踐并不能自動保證團隊內不再出現多任務并發(fā)、拖延、或者做和任務無關的其他事情等問題。可能有些人在做一個用戶故事的過程中,突然中斷去做了一些其他事情,但是
卻沒有及時在狀態(tài)墻上更新自己的狀態(tài)。重要的是團隊要有實現交付目標的共同愿景,能夠透明地暴露問題,并且善于利用狀態(tài)墻來發(fā)現和改進自身的問題。對于不成熟的團隊,這可能需要一個轉變的周期。
如果一個團隊的職責共享較好,代碼被所有人集體擁有,每個人都被鼓勵熟悉和工作在代碼的不同部分,那么在這樣的團隊內便不太會出現把一大塊任務 事先就明確給某一個人的情況。相反,所有人的工作事先不具體確定,大家會更容易形成某一時刻只領取一張卡片的情況,避免同時工作在多個任務上。實際上,狀 態(tài)墻的使用也可以幫助團隊走向職責共享之路,只需要在大家領取任務的時候有意地給人們分配一些之前沒做過的內容,同時安排好有經驗的人與其結對工作,一段 時間之后,團隊內的人便會逐漸體會到和之前只是專注在一個模塊內不同的工作方式。
2.3 如何減少半成品庫存,縮短交付周期
一個需求的交付周期(leadtime)是從它被識別到最終交付給用戶手中所耗費的時間。交付周期越短,意味著客戶從提出想法到能夠在軟件中實 際使用到這個點子的時間越短。從客戶的角度來看,更短的交付周期意味著自己的軟件能夠對市場變化的更快地響應,因而獲得更強的競爭力,同時也意味著能夠更 快地驗證自己的想法。
任務管理的粒度太大會直接導致交付周期變長。最極端的情況是將屬于某一模塊的任務在一開始就全部分給負責這個模塊的人,所有這個模塊相關的修改 都由他來實現。在一個按模塊劃分職責,每個人只負責自己具體模塊的團隊里,通常這個模塊的負責人會實現這個模塊的所有修改。不然,就是將一個可能需要做2 周到一個月的任務分給某個人。或者更好一點的情況是,單個任務本身不大,但是會將相關聯的任務成批地分配給某個人。如果你的團隊內也是采用大篇的“規(guī)格說 明書”等word文檔來組織需求的,那么就要小心,這種問題很可能在團隊內已經存在。整個團隊沒有小粒度頻繁交付的概念,習慣了大批量長時間地交付方式。 由于批量大,所以估計常常不準,而且時間跨度長,中間也會有更多地干擾因素出現,這些都導致任務不能在開始承諾的時間點交付。開發(fā)周期長同樣導致測試活動 的滯后,極端地滯后就演變?yōu)樗虚_發(fā)工作完成之后才能進行測試,這就是我們熟悉的瀑布模式。最終的影響就是需求的交付周期會很長。
傳統(tǒng)團隊的一個常見組織方式是按照功能模塊劃分團隊成員,明確分離職責,這也會變相增長交付周期。這樣的團隊通常傾向于按照功能模塊來組織半成 品任務,而不是按照可以交付價值的完成品來組織任務。習慣按照功能模塊來組織開發(fā)的團隊通常會階段性得“聯調”,不同模塊的人帶著自己的代碼合在一起調 試,由于缺乏頻繁地集成,這種聯調活動的時間經常不可控。團隊在大部分時間內通常只擁有一大堆半成品,后續(xù)的測試和驗收活動沒有辦法進行,而只能等到團隊 在某一刻組裝出一個完整的功能后才能測試,因此交付周期也會比較長。
因此,如果我們的需求都是按照軟件的功能模塊劃分,而不是按照面向用戶的價值來劃分的,那么我們在交付用戶價值這一目標上,一開始就走錯了路。采用用戶故事能夠把需求以用戶能夠理解的價值來組織,這一點是我們縮短交付周期的一個重要基礎。
我們的狀態(tài)墻能夠揭示需求的交付周期。讓我們來看看這樣幾個場景。
如果我們的需求是按照軟件的功能模塊劃分的,那么通常單個模塊的編碼完成往往不可測。例如有的團隊喜歡將web應用的上層頁面部分和下層數據庫 邏輯部分劃分到不同的模塊組,一個用戶的需求也會攔腰切成兩截,一部分交給上層團隊完成,一部分交給下層團隊。單個團隊的任務完成都不能開展這個需求的測 試,于是這些任務就會堆積在“待測試”這一欄。
如果我們的需求很大,以至于開發(fā)人員要花費很長的時間(超過1周)才能完成開發(fā),那么這個需求會在“開發(fā)中”這一欄停留很久。大家可以猜到,當一個人同時進行多個任務時,這些任務也會比它們單個依次被開發(fā)時在“開發(fā)中”這一欄停留更久的時間。
任何一欄中的任務其實都是半成品,只有完成測試,交付到用戶手中的需求才是完成品。狀態(tài)墻上的每一欄都好比一個存放著各種零件的倉庫,每一欄中 的卡片越多,停留的越久,就說明當前半成品的庫存越多,是該得到團隊的認真關注的時候了。狀態(tài)墻將每個階段的半成品數量可視化呈現出來,讓虛擬的數量通過 卡片這種物理介質的數量得以呈現。
通過狀態(tài)墻,我們可以計算出每一個需求的交付周期大概是多久。狀態(tài)墻上一個用戶故事從放到“待開發(fā)”這一欄,到它被移動到“完成”這一欄,這一 個時間段是需求的整個交付周期的其中一段,也是很重要的一段。通過優(yōu)化從“待開發(fā)”到“完成”的這一個過程,我們可以縮短需求的交付周期。通過比較需求的 交付周期和客戶對交付周期的要求,我們可以量化之間的差距,然后指導我們的改進。
在我們理解了狀態(tài)墻是如何呈現一個需求的交付周期后,我們就不難理解瀑布方法是如何讓交付周期變長的。在瀑布模型中,全部開發(fā)完成之后才會進行 測試工作,相當于所有的任務卡片都堆積到“待測試”狀態(tài)之后,才開始逐一測試。所有開發(fā)完成的半成品,都會留存在“待測試”這一倉庫中,一直等到所有開發(fā) 活動結束的那一刻。
當出現庫存堆積的時候,就是我們需要改進的時候。如果“待測試”這一欄有太多的任務卡片,那么就說明我們的測試活動沒有跟上。有可能是我們的測 試環(huán)境出了問題,或者是我們的測試人員人力不足。如果太多的卡片位于“測試完成”狀態(tài),說明我們的發(fā)布和最終交付過程出了某些問題。如果“待開發(fā)”這一欄 中任務過多,說明我們的計劃有可能超出了當前團隊的開發(fā)能力,或者說反映了開發(fā)人員的不足。也有一種情況,那就是“待開發(fā)”這一欄空了很久,這可能說明了 另外一個問題,那就是我們的分析師的分析速度匹配不上團隊的開發(fā)能力。一個良好的團隊,必然是各種角色協調配合,并行工作,同時他們之間的任務銜接也能夠 比較流暢。
2.4 迭代產能的度量,計劃及其他
團隊在每個迭代所能完成的工作量,通常被成為迭代的velocity(速度),是衡量團隊每迭代產能的一個指標。這個指標能夠幫助團隊進行制定 迭代計劃。根據團隊估計任務工作量的方法不同,迭代的velocity的單位也可能不同(例如故事點數)。通常,我們只需要在迭代結束的時候,數一數狀態(tài) 墻上完成的任務工作量就可以了。
當我們經歷了若干個迭代以后,通常團隊的迭代速度會趨于穩(wěn)定,我們在做下一個迭代的計劃的時候,會參考以往迭代的數據。如果上個迭代完成了15個點,那么下個迭代我們通常也
會計劃15個點左右的工作量,將這些卡片放到“待開發(fā)”這一欄中。也就是說,每個迭代結束時,我們都會對狀態(tài)墻進行更新,將即將到來的迭代的卡片放到墻上,并且將一些處于半成品狀態(tài)的卡片進行適當的調整。
前面提到,狀態(tài)墻上可能由三種卡片,除了需求,還可能有bug和技術任務。測試人員每次在迭代中測出一個bug,就會將bug寫成卡片,放到 “待開發(fā)”這一欄。當bug不多的時候,團隊可以在不太影響原有計劃的情況消化掉這些bug,確保軟件的質量持續(xù)地得到保證。如果bug太多,則需要做一 些計劃,將bug分散到幾個迭代里去消化。然而到這個時候,團隊可能更需要及時反省一下為什么會出現這么多bug的原因了。
另一類技術任務也需要和bug以及需求卡片一起被考慮到迭代計劃中去。通常技術任務包括諸如搭建持續(xù)集成環(huán)境、準備測試環(huán)境、重構這樣的任務。 它們雖然不直接給用戶帶來價值,但是卻是保證軟件質量、確保團隊效率的重要因素。比如重構類的任務,對于工作在遺留系統(tǒng)上的團隊來說可能是需要一直考慮的 事情,為了保障新的需求的順利實現,可能需要有計劃地重構之前的一些遺留代碼。
bug和技術任務耗費團隊成員的時間資源,但是不直接產生用戶價值。如果我們衡量團隊每個迭代的總體生產能力,需要在計算迭代速度時考慮這三類 任務。但是如果我們只考察團隊每迭代交付的用戶價值的量的大小,那么就不應該包含技術任務和bug。當一個團隊在迭代中花了過多的時間在技術任務上,或者 修復bug上,那么團隊就需要回顧反省一下其中的原因,是否是團隊的基礎設施太差,或者是團隊在開發(fā)時過于粗心導致太多的bug,抑或是其他的一些原因。
3、總結
在本文中我們從項目管理中常常出現的一些問題著手,分析了其中的一些原因,然后介紹了如何采用狀態(tài)墻(看板)來可視化任務管理。在敏捷項目中, 狀態(tài)墻作為一種有效的迭代任務管理工具,已經被廣泛地使用。團隊利用狀態(tài)墻這樣一種簡單的工具,將迭代開發(fā)中的日常工作透明實時地跟蹤管理起來,能夠幫助 團隊及時發(fā)現問題,消除浪費,快速地交付用戶價值。希望這些文字,能夠對渴望嘗試敏捷、改善任務管理和日常運作的團隊帶來一些幫助。
離職信(轉)
公司諸君:
自吾之來此,已一年有余。本當披肝,以報知遇,卻發(fā)現往昔之熱情所剩無幾。想來與人無涉。問題在己,蓋因自己實不具榮辱不驚之修為。既已無心向工,終不能 應景混事,長此以往,百無一利。唯今之計,只有主動剝職,才是正議,如此即可順遂心意,亦可免于日后復為旗下之祭。
其實去不足惜。輾轉數月,倍感煎熬,故去留之事可知已。奈何,晃晃終日不安,去留兩相難。且畫餅充饑,終不可為,此之內傷,故而吾之所事,上效和尚撞鐘, 敷衍了事,得過且過。況汝之于如來,吾之于金蟬子,必之為歧。故與子謀皮吾之損已。故而或棄或留,亦為不悖。
吾等人士,或曾芳心暗許,愿擇良主,從一而終。奈何落花有意,流水無情。去意生時,悲從中來,心路歷程,猶如爪撕。人生一世,草木一春,草木含情,人豈無義?古人云:“
月明星稀,烏鵲南飛,繞樹三匝,無枝可依。”此般情景,感同身受。
雖不舍同事,但天下無不散之宴席。一朝同事,終身為友,人雖已走,望茶勿涼。他日遇吾衣食無計,望賜茶一杯以示無望;倘得日后前程無憂,尚能噓寒問暖,吾愿足已
前些天在網站上看到一篇名為我們需要專職的QA嗎?讓我很讓震驚!
發(fā)這篇文章的目的,并不是對原作者的看法表示如何的批評,且說出自己的想法(自認為很中正的看法),希望各位網友能說出你的看法,也希望我能解釋很多開發(fā)人員的疑惑。
文章鏈接:我們需要專職的QA嗎?
紫色的文字為引用原文,因為引用文章很長,請見諒
在開始今天的討論之前,先看幾個名詞解釋(參考):
質量保證(QA):QA(QUALITY ASSURANCE,中文意思是“品質保證”,通過過程的持續(xù)改進來提高產品質量,是軟件成熟度模型(CMMI/ISO)中的一個角色
QA可以對開發(fā)的具體技術不了解,但要對CMMI、ISO900等的流程要清楚
軟件配置管理(SCM):配置管理(Configuration Management,CM)是通過技術或行政手段對軟件產品及其開發(fā)過程和生命周期進行控制、規(guī)范的一系列措施。配置管理的目標是記錄軟件產品的演化過程(其中涉及到基線的概念),確保軟件開發(fā)者在軟件生命周期中各個階段都能得到精確的產品配置;
配置管理包括六大任務:配置標識、版本管理、變更管理、配置審核、狀態(tài)報告、發(fā)布管理,配置管理的最重要的是版本管理和發(fā)布管理;
配置管理往往是配置在質量部統(tǒng)一進行管理,現時還要為測試提供一個測試環(huán)境,即我們講的搭測試環(huán)境。
軟件測試(Tester):使用人工或者自動手段來運行或測試某個系統(tǒng)的過程(他是一個驗證的過程),其目的在于檢驗它是否滿足規(guī)定的需求或弄清預期結果與實際結果之間的差別,通俗的說是去驗證兩個方面:是否做了正確的某事,是否正確的做了某事
QA通過對流程(過程)的持續(xù)改進來提升產品的最終質量;軟件測試通過技術來保證產品的最終質量;配置管理是對過程產品及軟件生命周期進行管理。
所以,到這里我們就可以看到,其實標題中把測試和QA的概念混為一談,是錯誤的!
“我們都同意,Dev 要懂測試,QA 要懂開發(fā),只不過分工不同,既然你中有我,我中有你,那就不要分彼此了,一起攜手開發(fā)測試吧 (另外,我個人覺得不懂開發(fā)的測試人員不可能測試得好”)
對于上面的觀點我是認同的。
至于園子中轉載的文章,我不知道作者是誰,既然是分享,那么我們來看一下作者的故事:
我們暫且沿用作者的QA稱謂
“我再說說我最糟糕的 QA 經歷吧,這個公司的 QA 部門只做測試,他們的 leader 覺得所有的 test design 和 test 的過程都不需要 Dev 參與,他們是獨立于 Dev 之外的部門,他們幾乎不關心 Dev 的設計和實現,他們只關心能跑通他們自己設計的 test case。但是去執(zhí)行 Test Case 的時候,又需要 Dev 的支持,尤其在環(huán)境設置,測試工具使用,確認是否是 bug 方面,全都在消耗著 Dev 的資源,最扯的是,他們對任何線上的問題不負責,反正出了問題由 Dev 加班搞定。”
上面的文字包含了很多分享者公司的情況,不知是不是可以猜測如下:
把測試能獨立于開發(fā)之外(把需求視若無物)進行,這首先是Tester或Leader認知層面上的一個錯誤(是否作者的理解有誤差暫且不論);
或者可能從中看出來,分享者的公司中沒有測試總監(jiān)、測試組長之類的Leader或者他們的資質明顯不足以勝任他們的工作,才會出現前面所說的將測試獨立于開發(fā)和其他部門而存在;
我們或者可以從Dev的抱怨中看到,公司的測試人員資質不夠(不懂得基本測試工具的使用,不擅長自我學習、自我突破),過分的依賴本身已有的知識及開發(fā)人員的協助;
公司對于需求的管理很粗或者根本沒有管理(或者還是測試人員的理解能力太差,無法理解需求的含義,無法分辨需求與實現之前的差異是否可以定義為Bug),如果有明確的需求管理,則不會出現經常無法確認是否Bug的情況;
我們可以從字里行間,感覺分享者的公司好像是為了測試而測試,要知道測試的目的是為了最終的質量,這一點在整個公司上下的目的都是一致的,任何的工作都不能偏離這個目標而存在
我認為:
公司要做好測試工作保證質量,公司從CEO到普通員工有質量意識很重要,只有從意識上認識到質量的重要性,才能真正的做好質量的管理,沒質量的意識,其他就都是空中樓閣;
同時優(yōu)秀的測試總監(jiān)和測試組長是保證測試工作質量的前提 ,相信強將手下少弱兵;
不要認為任何人都能做好測試,基層測試人員的素質很重要(懂開發(fā)的測試人員或Dev最好,還要有專業(yè)系統(tǒng)的測試理論,同時最好了解需求或業(yè)務),他們最終的測試執(zhí)行者,是質量保證的第一關和最后一關;
需求管理與需求培訓很重要,遇到需求問題,溝通很重要;
質量部不是擺設,測試人員也不是找茬的家伙,大家的目標要一致的---質量
“我有一次私自 review 他們的 test case 的時候,發(fā)現很多的 test case 這樣寫到 – “Expected Result:Make sure every thing is fine” ,WTF,什么叫“Every thing is fine”?!而在 test case design 的時候,沒有說明 test environment/configuration 是什么?沒有說明 test data 在哪里?Test Case、Test Data、Test Configuration 都沒有版本控制,還有很多 Test Case 設計得非常冗余(多個 Test Case 只測試了一個功能),不懂得分析 Function Point 就做 Test Design。另外,我不知道他們?yōu)槭裁茨敲礋嶂杂谠O計一堆各式各樣的 Negative Test Case,而有很多 Positive 的 Test Case 沒有覆蓋到。為什么呢,因為他們不知道開發(fā)和設計的細節(jié),所以沒有辦法設計出 Effective 的 Test Case,只能從需求和表面上做黑盒。”
我很能理解這會Dev的感受,測試人員把預期結果寫成“Every thing is fine”,誰他都受不了!
上面所說到的測試人員存在兩個問題:
①測試用例的基本構成不完成,構成元素過于模糊無法達到準確測試的目的,無法實現測試用例的延續(xù)(他人無法看懂你的測試用例)
②測試人員對需求或測試理論理解不夠,導致很多的漏洞或重復測試
但是我要告訴你的是“這和測試沒有什么關系,這所有的一切都只能說明,你們的測試人員很濫,他們的很濫直接影響到了你對整個測試的理解”;
同時,我要講的是是否了解需求與是否做黑盒測試沒有關系,下面是黑盒測試的概念可以參考一下:
黑盒測試:也稱功能測試,它是通過測試來檢測每個功能是否都能正常使用。在測試中,把程序看作一個不能打開的黑盒子,在完全不考慮程序內部結構和內部特性的情況下,在程序接口進行測試,它只檢查程序功能是否按照需求規(guī)格說明書的規(guī)定正常使用,程序是否能適當地接收輸入數據而產生正確的輸出信息。
所以,如果遇到上面的情況,不應該是說對軟件測試失去信心(因為我們需要更好的保證質量),而應該向你的上級反應,我們需要更稱職的測試人員!!!
建議去51Testing上看一看有關軟件測試方面的信息
“在做性能測試的時候,需要 Dev 手把手的教怎么做性能測試,如何找到系統(tǒng)性能極限,如何測試系統(tǒng)的 latency,如何觀察系統(tǒng)的負載(CPU,內存,網絡帶寬,磁盤和網卡I/O,內存換頁……)如何做 Soak Test,如何觀察各個線程的資源使用情況,如何通過配置網絡交換機來模擬各種網絡錯誤,等等,等等。”
這就是我上面說的,測試人員的本身素質太差,無法實現自我學習,自我提升與自我突破的情形
要知道在工作中要用到的東西并不是我們都會的,在這種情況下,我們就要積極主動的去學習,個人認為在有壓力的情況下學習,往往是事半功倍的!
“在項目快要上線前的一周,我又私自查看了一下他們的 Test Result,我看到 5 天的 Soak Test 的內存使用一直往上漲,很明顯的內存泄露,這個情況發(fā)生在 2 個月前,但是一直都沒有報告,我只好和我的程序員每天都加班到凌晨,趕在上線前解決了這個問題。但是,QA 部門的同學們就像沒發(fā)生什么事似的,依然正常上下班。哎……”
首先要肯定的是測試人員沒有測試好,開發(fā)人員沒有開發(fā)好,所以誰也不要說誰做得不好。人非圣賢,離孰能無過焉!
出現問題時,先解決問題,而不是先追究責任,在問題解決之后,我們需要討論問題產生的原因,如何避免下次再出現這樣的情況,同時如果可以追溯到相關的責任人,我們要進行一定的處理,但處理不是重點。
出現一些緊急的情況,加班難免,要能扛得住!
“為什么會這樣?我覺得有這么幾點原因(和鄒欣的觀點一樣)
1、給了 QA 全部測試的權力,但是沒有給相應的責任,
2、QA 沒有體會過軟件質量出問題后的痛苦(解決線上問題的壓力),導致 QA 不會主動思考和改進。
3、QA 對 Dev 的開發(fā)過程和技術完全不了解,增加了很多 QA 和 Dev 的溝通。
4、QA 對軟件項目的設計和實現要點不了解,導致了很多不有效的測試。”
1、質量部的責任是很重的,一量出現漏測或出現線上事故,質量部是要承擔一半或以上的責任的(但具體的也要看公司的情況,如果沒有系統(tǒng)的管理,這個很難說)
2、軟件出現問題,測試人員是不是要重新測試,甚至有時候要加班加點(至于分享者說的他們測試人員不管什么時候按時下班,這還是歸結到測試人員的素質問題,就無關乎能力了)是常有的事;計算機行業(yè)是一個快速發(fā)展的行業(yè),不思考不主動學習,你很快就會被淘汰,如果你的公司的測試人員還抱著過去的知識、抑制學習、被動思考,那么你可以讓他回家抱孩子,熱坑頭……
3、測試人員不了解軟件工程或開發(fā)語言的情況常有,但有時候我們也需要精通業(yè)務的人來進行測試,這個是很重要的!
4、這個涉及到我前面講過的對需求的管理與測試人員對需求的理解,以及對基礎測試理論的缺失
從以上的幾個觀點來看,可以看出來文章的作者對測試人員還是很存在一定的理解偏差的,他的問題主要是把他們公司的測試一些人員當成了整個軟件測試行業(yè)!
如果他可以跳出他們公司,去質量管理規(guī)范的公司看一看,或許能有極大的改觀,不知道他本身是否認可?
“我越來越覺得軟件開發(fā),真的不需要專職的 QA,更不需要只寫代碼不懂做測試的專職的 Dev”
關于作者的這句話,我不敢完全茍同,我覺得更應該這樣說:
“我越來越覺得需要軟件測試人員,但不需要不專業(yè)的測試人員,更不需要只寫代碼不懂做測試的專職的 Dev”
我為什么我不說“我們需要專業(yè)的測試人員”而不是說“我們需要懂開發(fā)的測試人員”?
專業(yè),包括懂需求、懂開發(fā)、懂測試理論的人員,也包括懂業(yè)務、懂需求、懂測試理論的測試人員,這兩者都是我們需要的優(yōu)秀的測試人員!
“1) 開發(fā)人員做測試更有效
開發(fā)人員本來就要測試自己寫的軟件,如果開發(fā)人員不懂測試,或是對測試不專業(yè),那么這就不是一個專業(yè)的開發(fā)人員。
開發(fā)人員了解整個軟件的設計和開發(fā)過程,開發(fā)人員是最清楚應該怎么測試的,這包括單元測試,功能測試,性能測試,回歸測試,以及 Soak Test 等。
開發(fā)人員知道怎么測試是最有效的。開發(fā)人員知道所有的 function point,知道 fix 一個 bug 后,哪些測試要做回歸和驗證,哪些不需要。開發(fā)人員的技術能力知道怎么才能更好的做測試。
很多開發(fā)人員只喜歡寫代碼,不喜歡做測試,或是他們說,開發(fā)人員應該關注于開發(fā),而不是測試。這個思路相當的錯誤。開發(fā)人員最應該關注的是軟件質量,需要證明自己的開發(fā)成果的質量。開發(fā)人員如果都不知道怎么做測試,這個開發(fā)人員就是一個不合格的開發(fā)人員。
另外,我始終不明白,為什么不做開發(fā)的 QA 會比 Dev 在測試上更專業(yè)? 這一點都說不通啊。”
聞道有先后,術業(yè)有專攻!
首先我對寫下這段文字的Dev表示我的景仰,你能說出這番話說明你還是對軟件測試、對軟件質量、對Dev本身的測試還是有一定的了解和意識的。
但是,要知道軟件測試也是一個系統(tǒng)的過程,和軟件開發(fā)一樣,他有一個長期的過程,開發(fā)人員通經系統(tǒng)、完善的培訓或者可以成為一個優(yōu)秀的測試人員,這個不虛假;但是術業(yè)有專攻,開發(fā)人員專攻的是開發(fā),測試人員專攻的是測試(最最好是彼此都有一些了解)。開發(fā)人員要進行的測試是對基礎功能的粗略測試,因為他有更重要的開發(fā)工作要去完成,做不到詳細的完全測試;而測試人員一方面要詳細的對基礎功能進行測試,還要對很多很多的細支末節(jié)進行測試,尤其是平常經常使用的或可能會出現,但一般人很少想到的,在測試中我們稱之為場景,測試人員要對各種可能出現的場景進行測試,往往這種測試是很煩瑣的。
同時,專業(yè)的測試人員和專業(yè)的開發(fā)人員一樣,都是要經常系統(tǒng)、完善的培訓才能正式以一名合格的測試人員的身份上崗的,所以說,不能單純的去懷疑Tester對測試的專業(yè)性……
“2)減少溝通,扯皮,和推諉
想想下面的這些情況你是否似曾相識?
QA 做的測試計劃,測試案例設計,測試結果,總是需要 Dev 來評審和檢查。(不是說測試需要依賴開發(fā),這是本身的一個溝通、交流,是保證質量的一個流程需要,在CMMI\ISO中是有明文的規(guī)定的)
QA 在做測試的過程中,總是需要 Dev 對其測試的環(huán)境,配置,過程做指導。(這個是為了保證測試的正確性,要是因為配置不正確而導致誤報,當如何?)
QA 總是會和 Dev 爭吵某個問題是不是 BUG,爭吵要不要解決。(是不是缺陷需要相互溝通,需要判斷優(yōu)先級,需要參考需求,需要領導定奪,而不是開發(fā)和測試的吵,凡事要有依據)
無論發(fā)現什么樣的問題,總是 Dev 去解決,QA 從不 fix 問題。(Tester fix Bug?部分的缺陷是可以,如果他有開發(fā)的經驗,但你會放心么?項目經理能放心么,術業(yè)有專攻)
我們總是能聽到,線上發(fā)生問題的時候,Dev 的抱怨 QA 這樣的問題居然沒測出來(出現漏測,是雙方的責任,不要想到推諉責任,這樣的人不僅人品存在問題,連職業(yè)道德也值得重新審視)
QA 也總會抱怨 Dev 代碼太差,一點也不懂測試,沒怎么測就給 hand over 給 QA 了。(所以說開發(fā)要懂測試,提高交付質量,避免低級錯誤,但有偶爾有也是可以理解的,人非圣賢嘛)
QA 總是會 push Dev,這個 bug 再不 fix,你就影響我的進度了。(相互理解、支持)
等等,等等。
如果沒有 QA,那么就沒有這么多事了,DEV 自己的干出來的問題,自己處理,沒什么好扯皮的。
而一方面,QA 說 Dev 不懂測試,另一方面 Dev 說 QA 不懂技術,而我們還要讓他們隔離開來,各干各的,這一點都不利于把 Dev 和 QA 的代溝給填平了。要讓 Dev 理解 QA,讓 QA 理解 Dev,減少公說公有理,婆說婆有理的只站在自己立場上的溝通,只有一個方法,那就是讓 Dev 來做測試,讓 QA 來做開發(fā)。這樣一樣,大家都是程序員了。”
(扯皮,多么俗的字眼,當然不是說這種情況沒有,但這種情況是不應該的,還是那句:相互的溝通、相互的理解、統(tǒng)一的目標很重要)
“3)吃自己的狗食
真的優(yōu)秀的開發(fā)團隊都是要吃自己狗食的。這句話的意思是——如果你不能切身體會到自己干的爛事,自己的痛苦,你就不會有想要去改進的動機。沒有痛苦,就不會真正地去思考,沒有真正的思考,就沒有真正的進步。
在我現在的公司,程序員要干幾乎有的事,從需求分析,設計,編碼,集成,測試,部署,運維,OnCall,從頭到尾,因為:
只有了解了測試的難度,你才明白怎么寫出可測試的軟件,怎么去做測試的自動化和測試系統(tǒng)。
只有自己真正去運維自己的系統(tǒng),你才知道怎么在程序里寫日志,做監(jiān)控,做統(tǒng)計……
只有自己去使用自己的系統(tǒng),你才明白用戶的反饋,用戶的想法,和用戶的需求。
所以,真正的工程師是能真正明白軟件開發(fā)不單單只是 coding,還更要明白整個軟件工程。只明白或是只喜歡 coding 的,那只是碼農,不能稱之為工程師。”
這段的理解,說明文章作者對開發(fā)者自測還是有比較深的理解,比較重視的!
一個優(yōu)秀的程序員,不,應該是工程師,要知道的、要做的還是很多的!
“關于 SDET。全稱是 Software Development Engineer on Test。像微軟,Google, Amazon 都有這樣的職位。但我不知道這樣的職位在微軟和 Google 的比例是多少,在 Amazon 是非常少的。那么像這樣的懂開發(fā)的專職測試可以有嗎?我的答案是可以有!但是,我在想,如果一個人懂開發(fā),為什么只讓其專職做測試呢?這樣的程序員分工合理嗎?把程序分成兩等公民有意義嗎?試問有多少懂開發(fā)的程序員愿意只做測試開發(fā)呢?所以,SDET 在實際的操作中,更多的還是對開發(fā)不熟的測試人員。還是哪句話,不懂開發(fā)的人是做不好測試的。”
雖然我對上面的“不懂開發(fā)是做不好測試的”這句話表示同意,但反過來我是不能同意的,是存在需求(業(yè)務)測試工程師,也就是說他們不懂開發(fā),但相當的精通業(yè)務、需求
只要是對工作、對最終的目標是合理的,那么怎樣的工作都是需要人去完成的,所以不要認為做哪樣工作就不怎么的,這個可以做為你奮斗的動力,但不能作為評價一個人的標準
“如果你說 Dev 對測試不專業(yè),不細心,不認真,那么我們同樣也無法保證 QA 的專業(yè),細心和認真。在 Dev 上可能出現的問題,在 QA 也也會一樣出現。而出了問題 QA 不會來加班解決,還是開發(fā)人員自己解決。所以,如果 QA 不用來解決問題,那么,QA 怎么可能真正的細心和認真呢?”
是的,都會出現問題,開發(fā)人員開發(fā)代碼時會出現問題,所以需要測試;測試人員測試會出現問題,所以需要開發(fā)人加班加點解決問題;而往往兩者都會出現問題
在這個問題上作者陷入了一個死循環(huán)中,記住“沒有成功個人,只有成功的團隊”
“如果你說不要 QA 的話,Dev 人手會不夠。你這樣想一下,如果把你團隊中現有的 QA 全部變成 Dev,然后,大家一起開發(fā),一起測試,親密無間,溝通方便,你會不會覺得這樣會更有效?你有沒有發(fā)現,在重大問題上,Dev 可以幫上 QA 的忙,但是 QA 幫不上 Dev 的忙。”
首先肯定作者話,如果能從開發(fā)中轉過來部分專業(yè)的測試人員,這樣對于項目肯定是有幫助的,但我們仍然需要質量管理體系來管理,通過流程來保證我們的產品/項目質量
從文章作者的言語中可以看到他作為開發(fā)人員的優(yōu)越性,而這種優(yōu)越性容易造成的結果是:“我不應該來做這個事,我可以做更高級、更有難度的事”
有人說態(tài)度決定一切,雖然我不太贊成這句話,但我也明白一個人的能力重要,一個人的心態(tài)也很重要
最后,讓一個優(yōu)秀的開發(fā)人員做測試確實有些浪費,公司損失不起
“第三方中立,你會說人總是測不好自己寫的東西,因為有思維定式。沒錯,我同意。但是如果是 Dev 交叉測試呢?你可能會說開發(fā)人員會有開發(fā)人員的思維定式。那這只能說明開發(fā)人員還不成熟,他們還不合格。沒關系,只要吃自己的狗食,痛苦了,就會負責的。”
思維定式、個人習慣、自我保護意識是三個魔鬼
當然測試人員也有這三個魔鬼,所以測試負責人在安排測試時,一般會交叉測試,具體的涉及到測試策略的問題,就不在這里說了
越多的測試越能保證產品的質量,所以一般都會要求開發(fā)人員對自己的程序進行測試,會有代碼評審,會有同行評審,其中的原因也就不言而喻
“磨刀不誤砍柴功。如果你開發(fā)的東西自己在用,那么自己就是自己天然的 QA,如果有別的團隊也在用你開發(fā)的模塊,那么,別的團隊也就很自然地在幫你做測試了,而且是最真實的測試。”
說的沒有錯,是測試,但是不完全的測試,對于質量我們追求的是質量的零缺陷,雖然那不可能實現,而實現的基礎是專業(yè)、系統(tǒng)、完整的測試
“關于自動化測試。所謂自動化的意思是,這是一個機械的重復勞動,我想讓測試人員思考一下,你是否在干這樣的事?如果你正在干這樣的事,那么,你要思考一下你的價值了。但凡是重復性比較高的機械性的勞動,總有一天都會被機器取代的。”
知道為什么人沒有被機器人替代么?
因為人有無窮無盡的思想
“關于線上測試。我們都知道,無論自己內測的怎么樣,到了用戶那邊,總是會有一些測試不到的東西。所以,有些公司會整出個 UAT,用戶驗收測試。做產品的公司會叫 Beta 測試。無論怎么樣,你總是要上生產線做測試的。對于互聯網企業(yè)來說,生產線上測試有的玩A/B測試,有的玩部分用戶測試,比如,新上線的功能只有 10% 的用戶可以訪問得到,這樣不會因為出問題讓全部用戶受到影響。做這種測試的人必然是開發(fā)人員。”
UAT是用戶會要求進行的,如果不做接收測試,客戶不滿意你的項目,后期的款項如何收回?
Beta測試一方面是通過線上的真實情況,檢查程序的功能、性能,同時也是對市場的試探、對用戶的試探,觀察市場、用戶對產品的響應,為公司的后期決策做以參考。
寫在結尾:
對于你的耐心,Tester Chen很感謝,成文時間倉促,如有不妥,希望留下你寶貴的意見、建議。
這篇
文章是以
MySQL 為背景,很多內容同時適用于其他關系型
數據庫,需要有一些索引知識為基礎。
優(yōu)化目標
1、減少 IO 次數
IO永遠是數據庫最容易瓶頸的地方,這是由數據庫的職責所決定的,大部分數據庫操作中超過90%的時間都是 IO 操作所占用的,減少 IO 次數是 SQL 優(yōu)化中需要第一優(yōu)先考慮,當然,也是收效最明顯的優(yōu)化手段。
2、降低 CPU 計算
除了 IO 瓶頸之外,SQL優(yōu)化中需要考慮的就是 CPU 運算量的優(yōu)化了。order by, group by,distinct … 都是消耗 CPU 的大戶(這些操作基本上都是 CPU 處理內存中的數據比較運算)。當我們的 IO 優(yōu)化做到一定階段之后,降低 CPU 計算也就成為了我們 SQL 優(yōu)化的重要目標
優(yōu)化方法
1、改變 SQL 執(zhí)行計劃
明確了優(yōu)化目標之后,我們需要確定達到我們目標的方法。對于 SQL 語句來說,達到上述2個目標的方法其實只有一個,那就是改變 SQL 的執(zhí)行計劃,讓他盡量“少走彎路”,盡量通過各種“捷徑”來找到我們需要的數據,以達到 “減少 IO 次數” 和 “降低 CPU 計算” 的目標
常見誤區(qū)
1、count(1)和count(primary_key) 優(yōu)于 count(*)
很多人為了統(tǒng)計記錄條數,就使用 count(1) 和 count(primary_key) 而不是 count(*) ,他們認為這樣性能更好,其實這是一個誤區(qū)。對于有些場景,這樣做可能性能會更差,應為數據庫對 count(*) 計數操作做了一些特別的優(yōu)化。
2、count(column) 和 count(*) 是一樣的
這個誤區(qū)甚至在很多的資深工程師或者是 DBA 中都普遍存在,很多人都會認為這是理所當然的。實際上,count(column) 和 count(*) 是一個完全不一樣的操作,所代表的意義也完全不一樣。
count(column) 是表示結果集中有多少個column字段不為空的記錄;
count(*) 是表示整個結果集有多少條記錄;
3、select a,b from … 比 select a,b,c from … 可以讓數據庫訪問更少的數據量
這個誤區(qū)主要存在于大量的開發(fā)人員中,主要原因是對數據庫的存儲原理不是太了解。
實際上,大多數關系型數據庫都是按照行(row)的方式存儲,而數據存取操作都是以一個固定大小的IO單元(被稱作 block 或者 page)為單位,一般為4KB,8KB… 大多數時候,每個IO單元中存儲了多行,每行都是存儲了該行的所有字段(lob等特殊類型字段除外)。
所以,我們是取一個字段還是多個字段,實際上數據庫在表中需要訪問的數據量其實是一樣的。
當然,也有例外情況,那就是我們的這個查詢在索引中就可以完成,也就是說當只取 a,b兩個字段的時候,不需要回表,而c這個字段不在使用的索引中,需要回表取得其數據。在這樣的情況下,二者的IO量會有較大差異。
4、order by 一定需要排序操作
我們知道索引數據實際上是有序的,如果我們的需要的數據和某個索引的順序一致,而且我們的查詢又通過這個索引來執(zhí)行,那么數據庫一般會省略排序操作,而直接將數據返回,因為數據庫知道數據已經滿足我們的排序需求了。
實際上,利用索引來優(yōu)化有排序需求的 SQL,是一個非常重要的優(yōu)化手段
5、執(zhí)行計劃中有 filesort 就會進行磁盤文件排序
有這個誤區(qū)其實并不能怪我們,而是因為 MySQL 開發(fā)者在用詞方面的問題。filesort 是我們在使用 explain 命令查看一條 SQL 的執(zhí)行計劃的時候可能會看到在 “Extra” 一列顯示的信息。
實際上,只要一條 SQL 語句需要進行排序操作,都會顯示“Using filesort”,這并不表示就會有文件排序操作。
其實,這篇短文,我早就應該寫了。因為,
Java存儲過程今后在各大
數據庫廠商中越來越流行,功能也越來越強大。這里以
Oracle為例,介紹一下java存儲過程的具體用法。
一、如何創(chuàng)建java存儲過程?
通常有三種方法來創(chuàng)建java存儲過程。
1、使用oracle的sql語句來創(chuàng)建:
e.g. 使用create or replace and compile java source named "<name>" as
后邊跟上java源程序。要求類的方法必須是public static的,才能用于存儲過程。
- SQL> create or replace and compile java source named "javademo1"
- 2 as
- 3 import java.sql.*;
- 4 public class JavaDemo1
- 5 {
- 6 public static void main(String[] argv)
- 7 {
- 8 System.out.println("hello, java demo1");
- 9 }
- 10 }
- 11 /
- Java 已創(chuàng)建。
- SQL> show errors java source "javademo1"
- 沒有錯誤。
- SQL> create or replace procedure javademo1
- 2 as
- 3 language java name 'JavaDemo1.main(java.lang.String[])';
- 4 /
- 過程已創(chuàng)建。
- SQL> set serveroutput on
- SQL> call javademo1();
- 調用完成。
- SQL> call dbms_java.set_output(5000);
- 調用完成。
- SQL> call javademo1();
- hello, java demo1
- 調用完成。
- SQL> call javademo1();
- hello, java demo1
- 調用完成。
|
2、使用外部class文件來裝載創(chuàng)建
e.g. 這里既然用到了外部文件,必然要將class文件放到oracle Server的某一目錄下邊。
- public class OracleJavaProc
- {
- public static void main(String[] argv)
- {
- System.out.println("It's a Java Oracle procedure.");
- }
- }
- SQL> grant create any directory to scott;
- 授權成功。
- SQL> conn scott/tiger@iihero.oracledb
- 已連接。
- SQL> create or replace directory test_dir as 'd:/oracle';
- 目錄已創(chuàng)建。
- SQL> create or replace java class using bfile(test_dir, 'OracleJavaProc.CLASS')
- 2 /
- Java 已創(chuàng)建。
- SQL> create or replace procedure testjavaproc as language java name 'OracleJavaProc.main(java.lang.String[])';
- 2 /
- 過程已創(chuàng)建。
- SQL> call testjavaproc();
- 調用完成。
- SQL> execute testjavaproc;
- PL/SQL 過程已成功完成。
- SQL> set serveroutput on size 5000
- SQL> call dbms_java.set_output(5000);
- 調用完成。
- SQL> execute testjavaproc;
- It's a Java Oracle procedure.
3、我推薦的一種方法,直接使用loadjava命令遠程裝載并創(chuàng)建。
先創(chuàng)建一個類, e.g.
- import java.sql.*;
- import oracle.jdbc.*;
-
- public class OracleJavaProc {
-
- //Add a salgrade to the database.
- public static void addSalGrade(int grade, int losal, int hisal) {
-
- System.out.println("Creating new salgrade for EMPLOYEE...");
-
- try {
- Connection conn =
- DriverManager.getConnection("jdbc:default:connection:");
-
- String sql =
- "INSERT INTO salgrade " +
- "(GRADE,LOSAL,HISAL) " +
- "VALUES(?,?,?)";
- PreparedStatement pstmt = conn.prepareStatement(sql);
- pstmt.setInt(1,grade);
- pstmt.setInt(2,losal);
- pstmt.setInt(3,hisal);
- pstmt.executeUpdate();
- pstmt.close();
- }
- catch(SQLException e) {
- System.err.println("ERROR! Adding Salgrade: "
- + e.getMessage());
- }
- }
- }
|
使用loadjava命令將其裝載到服務器端并編譯:
- D:eclipse3.1workspacedbtest>loadjava -u scott/tiger@iihero.oracledb -v -resolve Or
- acleJavaProc.java
- arguments: '-u' 'scott/tiger@iihero.oracledb '-v' '-resolve' 'OracleJavaProc.java'
- creating : source OracleJavaProc
- loading : source OracleJavaProc
- resolving: source OracleJavaProc
|
查詢一下狀態(tài):
- 連接到:
- Oracle9i Enterprise Edition Release 9.2.0.1.0 - Production
- With the Partitioning, OLAP and Oracle Data Mining options
- JServer Release 9.2.0.1.0 - Production
-
- SQL> SELECT object_name, object_type, status FROM user_objects WHERE object_type LIKE 'JAVA%';
-
- OBJECT_NAME
- --------------------------------------------------------------------------------
-
- OBJECT_TYPE STATUS
- ------------------------------------ --------------
- OracleJavaProc
- JAVA CLASS VALID
-
- OracleJavaProc
- JAVA SOURCE VALID
|
測試一下存儲過程:
- SQL> create or replace procedure add_salgrade(id number, losal number, hisal num
- ber) as language java name 'OracleJavaProc.addSalGrade(int, int, int)';
- 2 /
-
- 過程已創(chuàng)建。
-
- SQL> set serveroutput on size 2000
- SQL> call dbms_java.set_output(2000);
-
- 調用完成。
-
- SQL> execute add_salgrade(6, 10000, 15000);
- Creating new salgrade for EMPLOYEE...
-
- PL/SQL 過程已成功完成。
-
- SQL> select * from salgrade where grade=6;
-
- GRADE LOSAL HISAL
- ---------- ---------- ----------
- 6 10000 15000
二、如何更新你已經編寫的java存儲過程?
假如要往類OracleJavaProc里添加一個存儲過程方法,如何開發(fā)?
正確的步驟應該是先dropjava, 改程序,再loadjava。
e.g.修改OracleJavaProc類內容如下:
- import java.sql.*;
- import oracle.jdbc.*;
-
- public class OracleJavaProc {
-
- // Add a salgrade to the database.
- public static void addSalGrade(int grade, int losal, int hisal) {
-
- System.out.println("Creating new salgrade for EMPLOYEE...");
-
- try {
- Connection conn =
- DriverManager.getConnection("jdbc:default:connection:");
-
- String sql =
- "INSERT INTO salgrade " +
- "(GRADE,LOSAL,HISAL) " +
- "VALUES(?,?,?)";
- PreparedStatement pstmt = conn.prepareStatement(sql);
- pstmt.setInt(1,grade);
- pstmt.setInt(2,losal);
- pstmt.setInt(3,hisal);
- pstmt.executeUpdate();
- pstmt.close();
- }
- catch(SQLException e) {
- System.err.println("ERROR! Adding Salgrade: "
- + e.getMessage());
- }
- }
-
- public static int getHiSal(int grade)
- {
- try {
- Connection conn =
- DriverManager.getConnection("jdbc:default:connection:");
- String sql = "SELECT hisal FROM salgrade WHERE grade = ?";
- PreparedStatement pstmt = conn.prepareStatement(sql);pstmt.setInt(1, grade);
- ResultSet rset = pstmt.executeQuery();
- int res = 0;
- if (rset.next())
- {
- res = rset.getInt(1);
- }
- rset.close();
- return res;
- }
- catch (SQLException e)
- {
- System.err.println("ERROR! Querying Salgrade: "
- + e.getMessage());
- return -1;
- }
- }
-
- }
如何更新呢?
- D:eclipse3.1workspacedbtest>dropjava -u scott -v OracleJavaProc
-
- D:/tiger@iihero.oracledbeclipse3.1workspacedbtest>loadjava -u scott -v -resolve Or
- acleJavaProc/tiger@iihero.oracledb.java
- arguments: '-u' 'scott/tiger@iihero.oracledb' '-v' '-resolve' 'OracleJavaProc.java'
- creating : source OracleJavaProc
- loading : source OracleJavaProc
- resolving: source OracleJavaProc
|
后邊的應用示例:
- SQL> create or replace function query_hisal(grade number) return number as langu
- age java name 'OracleJavaProc.getHiSal(int) return int';
- 2 /
-
- 函數已創(chuàng)建。
-
- SQL> set serveroutput on size 2000
- SQL> call dbms_java.set_output(2000);
-
- 調用完成。
- SQL> select query_hisal(5) from dual;
-
- QUERY_HISAL(5)
- --------------
- 9999
|
全文完!
用法個人見解:不要手動drop java source,不要手動drop procedure。
內部類:定義在類的內部的類
為什么需要內部類?
● 典型的情況是,內部類繼承自某個類或實現某個接口,內部類的代碼操作創(chuàng)建其的外圍類的對象。所以你可以認為內部類提供了某種進入其外圍類的窗口。
● java中的內部類和接口加在一起,可以實現多繼承。
● 可以使某些編碼根簡潔。
● 隱藏你不想讓別人知道的操作。
使用內部類最吸引人的原因是:
每個內部類都能獨立地繼承自一個(接口的)實現,所以無論外圍類是否已經繼承了某個(接口的)實現,對于內部類都沒有影響。如果沒有內部類提供的可以繼 承多個具體的或抽象的類的能力,一些設計與編程問題就很難解決。從這個角度看,內部類使得多重繼承的解決方案變得完整。接口解決了部分問題,而內部類有效 地實現了“多重繼承”。
內部類分為: 成員內部類、靜態(tài)嵌套類、方法內部類、匿名內部類。
特點:
一、內部類仍然是一個獨立的類,在編譯之后內部類會被編譯成獨立的.class文件,但是前面冠以外部類的類命和$符號。
二、內部類可以直接或利用引用訪問外部類的屬性和方法,包括私有屬性和方法(但靜態(tài)內部類不能訪問外部類的非靜態(tài)成員變量和方法)。內部類所訪問的外部屬性的值由構造時的外部類對象決定。
三、而外部類要訪問內部類的成員,則只能通過引用的方式進行,可問內部類所有成員
四、訪問機制:
- System.out.println(this.x);或System.out.println(x);//內部類訪問內部類的成員變量或成員方法可用此方法。
- System.out.println(OuterClass.this.x);//內部類訪問外部類的同名變量時可用此方法,如果沒有同名可用System.out.println(x);
|
五、內部類可以使用任意的范圍限定:public/private/protected class InnerClass,且嚴格按照這幾種訪問權限來控制內部類能使用的范圍。普通類的范圍限定只可以是public或者不加。
六、內部類的命名不允許與外部類 重名,內部類可以繼承同級的內部類,也可繼承其它類(除內部類和外部類)。
七、內部類可以定義為接口,并且可以定義另外一個類來實現它
八、內部類可以定義為抽象類,可以定義另外一個內部類繼承它
九、內部類使用static修飾,自動升級為頂級類,外部類不可以用static修飾,用OuterClass.InnerClass inner=new OuterClass.InnerClass();創(chuàng)建實例。內部類還可定義為final.
十、內部類可以再定義內部類(基本不用)
十一、方法內的內部類:
方法內的內部類不能加范圍限定(protected public private)
方法內的內部類不能加static修飾符
方法內的內部類只能在方法內構建其實例
方法內的內部類如果訪問方法局部變量,則此局部變量必須使用final修飾
1)靜態(tài)內部類(靜態(tài)嵌套類)
從技術上講,靜態(tài)嵌套類不屬于內部類。因為內部類與外部類共享一種特殊關系,更確切地說是對實例的共享關系。而靜態(tài)嵌套類則沒有上述關系。它只是位置在另一個類的內部,因此也被稱為頂級嵌套類。
靜態(tài)的含義是該內部類可以像其他靜態(tài)成員一樣,沒有外部類對象時,也能夠訪問它。靜態(tài)嵌套類不能訪問外部類的成員和方法。
語法
- package com.tarena.day13;
-
- import com.tarena.day13.Foo.Koo;
- /**
- * 靜態(tài)類內部語法演示
- */
- public class StaticInner {
- public static void main(String[] args) {
- Koo koo = new Koo();
- System.out.println(koo.add());//4
- }
-
- }
- class Foo{
- int a = 1;
- static int b = 3;
- /** 靜態(tài)內部類,作用域類似于靜態(tài)變量,屬于類的 */
- static class Koo{
- public int add(){
- //a ,不能訪問a
- return b+1;
- }
- }
- }
|
2)成員內部類
* 1 成員內部類必須利用外部類實例創(chuàng)建
* 2 成員內部類可以共享外部類的實例變量
- import com.tarena.day13.inn.Goo.Moo;
-
- public class InnerClassDemo {
- public static void main(String[] args) {
- //Moo moo = new Moo(); //編譯錯誤,必須創(chuàng)建Goo的實例
- Goo goo = new Goo();
- Moo moo = goo.new Moo();//利用goo實例創(chuàng)建Moo實例
- Moo moo1 = goo.new Moo();
- //moo和moo1共享同一個goo實例的實例變量
- System.out.println(moo.add());//2
- System.out.println(moo1.add());//2
- Goo goo1 = new Goo();
- goo1.a = 8;
- Moo m1 = goo1.new Moo();
- Moo m2 = goo1.new Moo();
- System.out.println(m1.add());//9
- System.out.println(m2.add());//9
-
- }
- }
- class Goo{
- int a = 1;
- /**成員內部類*/
- class Moo{
- public int add(){
- return a+1;
- }
- }
- }
|
3)局部內部類(方法內部類)
(1)方法內部類只能在定義該內部類的方法內實例化,不可以在此方法外對其實例化。
(2)方法內部類對象不能使用該內部類所在方法的非final局部變量。
因為方法的局部變量位于棧上,只存在于該方法的生命期內。當一個方法結束,其棧結構被刪除,局部變量成為歷史。但是該方法結束之后,在方法內創(chuàng) 建的內部類對象可能仍然存在于堆中!例如,如果對它的引用被傳遞到其他某些代碼,并存儲在一個成員變量內。正因為不能保證局部變量的存活期和方法內部類對 象的一樣長,所以內部類對象不能使用它們。用法
- package com.tarena.day13.inn;
-
- import java.util.Comparator;
-
- /**
- * 局部內部類
- */
- public class LocalInnerClassDemo {
- public static void main(String[] args) {
- int a = 5;
- final int b = 5;
- //局部內部類,定義在方法內部,作用域類似于局部變量
- //僅僅在方法內部可見
- //在局部內部類中可以訪問方法中的局部final變量
- class Foo{
- public int add(){
- return b;//正確
- //return a;//編譯錯誤
- }
- }
-
- Foo foo = new Foo();
- //臨時的自定義比較規(guī)則
- class ByLength implements Comparator<String>{
- public int compare(String o1,String o2){
- return o1.length()-o2.length();
- }
- }
- }
-
- }
|
4)匿名內部類
顧名思義,沒有名字的內部類。表面上看起來它們似乎有名字,實際那不是它們的名字。
匿名內部類就是沒有名字的內部類。什么情況下需要使用匿名內部類?如果滿足下面的一些條件,使用匿名內部類是比較合適的:
只用到類的一個實例。
● 類在定義后馬上用到。
● 類非常小(SUN推薦是在4行代碼以下)
● 給類命名并不會導致你的代碼更容易被理解
在使用匿名內部類時,要記住以下幾個原則:
● 匿名內部類不能有構造方法。
● 匿名內部類不能定義任何靜態(tài)成員、方法和類。
● 匿名內部類不能是public,protected,private,static。
● 只能創(chuàng)建匿名內部類的一個實例。
● 一個匿名內部類一定是在new的后面,用其隱含實現一個接口或實現一個類。
● 因匿名內部類為局部內部類,所以局部內部類的所有限制都對其生效。
A、繼承式的匿名內部類和接口式的匿名內部類。
- import java.util.Arrays;
- import java.util.Comparator;
-
- /**匿名內部類 語法*/
- public class AnnInnerClass {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- Yoo yoo = new Yoo();//創(chuàng)建Yoo的實例
- Yoo y1 = new Yoo(){};
- //new Yoo(){}創(chuàng)建匿名類實例
- //匿名類new Yoo(){}是繼承Yoo類,并且同時創(chuàng)建了對象
- //new Yoo(){}是Yoo的子類型,其中{}是類體(class Body)
- //類體中可以定義任何類內的語法,如:屬性,方法,方法重載,方法覆蓋,等
- //子類型沒有名字,所以叫匿名類!
- Yoo y2 = new Yoo(){
- public String toString(){//方法重寫(覆蓋)
- return "y2"; //y2是子類的實例
- }
- };
- System.out.println(y2);//"y2",調用了匿名類對象toString()
- //匿名內部類可以繼承/實現 于 類,抽象類,接口等
- //按照繼承的語法,子類型必須實現所有的抽象方法
-
- //Xoo x = new Xoo(){};//編譯錯誤,沒有實現方法
- final int b = 5;
- Xoo xoo = new Xoo(){ //是實現接口,并且創(chuàng)建匿名類實例,不是創(chuàng)建接口對象
- public int add(int a){//實現接口中的抽象方法
- return a+b; //要訪問局部變量b,只能訪問final變量
- }
- };
- System.out.println(xoo.add(5));//10,調用對象的方法
- //Comparator接口也可以使用匿名類的方式
- Comparator<String> byLength = new Comparator<String>(){
- public int compare(String o1,String o2){
- return o1.length()-o2.length();
-
- }
- };
- String[] names = {"Andy","Tom","Jerry"};
- Arrays.sort(names,byLength);
- System.out.println(Arrays.toString(names));
- //也可以這樣寫,工作中常用
- Arrays.sort(names,new Comparator<String>(){
- public int compare(String o1,String o2){
- return o1.length()-o2.length();
- }
- });
- }
-
- }
接口式的匿名內部類是實現了一個接口的匿名類。而且只能實現一個接口。
B. 參數式的匿名內部類。
- class Bar{
- void doStuff(Foo f){
- }
- }
- interface Foo{
- void foo();
- }
- class Test{
- static void go(){
- Bar b = new Bar();
- b.doStuff(new Foo(){
- public void foo(){
- System.out.println("foofy");
- }
- });
- }
- }
|
構造內部類對象的方法有:
1、內部類在自己所處的外部類的靜態(tài)方法內構建對象或在另一個類里構造對象時應用如下形式:
(1)
- OuterClass out = new OuterClass();
- OuterClass.InnerClass in = out.new InnerClass();
|
(2)
| OuterClass.InnerClass in=new OuterClass().new InnerClass(); |
其中OuterClass是外部類,InnerClass是內部類。
2、內部類在它所在的外部類的非靜態(tài)方法里或定義為外部類的成員變量時,則可用以下方式來構造對象:
| InnerClass in = new InnerClass(); |
3、如果內部類為靜態(tài)類,則可用如下形式來構造函數:
| OuterClass.InnerClass in = new OuterClass.InnerClass(); |
無需再利用外部類的對象來來構造內部類對象,如果靜態(tài)內部類需要在靜態(tài)方法或其它類中構造對象就必須用上面的方式來初始化。
引子
按照原定計劃,今天開始研究 JMeter,一天的時間看完了大半的 User Manual,發(fā)現原來只要沉住氣,學習效率還是蠻高的,而且大堆的英文文檔也沒有那么可怕。
本來想順便把文檔翻譯一下,不過后來想了想,看懂是一回事,全部翻譯出來又是另外一回事了,工作量太大,而且這也不是我一開始要研究 JMeter 的本意。不如大家有興趣一起研究的遇到問題再一起討論吧。
開源工具通常都是為了某個特定的目的而開發(fā)出來的,所以如果想找到一個開源的性能測試工具去與LoadRunner 或者 QALoad 之類去比較,實在有些勉強。但是開源工具也有它自己的優(yōu)勢:小巧、輕便,在自己擅長的領域可以提供優(yōu)秀的解決方案。所以,我們可以考慮準備一個自己的“開 源測試工具箱”,平時利用空閑時間了解各種工具所適用的環(huán)境和目的,知識慢慢積累下來以后,就可以在遇到問題時順手拈來,輕松化解。
另外,如果8月份和9月份的空閑時間足夠多,我想我會寫一個系列文章來講述在實際的開發(fā)和測試過程中引入開源性能測試工具的情況。如果有朋友感興趣,希望大家可以一起研究和討論。
簡介
ab的全稱是ApacheBench,是 Apache 附帶的一個小工具,專門用于 HTTP Server 的benchmark testing,可以同時模擬多個并發(fā)請求。前段時間看到公司的開發(fā)人員也在用它作一些測試,看起來也不錯,很簡單,也很容易使用。
通過下面的一個簡單的例子和注釋,相信大家可以更容易理解這個工具的使用。
一個簡單的例子
在這個例子的一開始,我執(zhí)行了這樣一個命令 ab -n 10 -c 10 http://www.google.com/
這個命令的意思是啟動 ab ,模擬10個用戶(-n 10)同時訪問 www.google.com ,并迭代10次(-c 10)。跟著下面的是 ab 輸出的測試報告,紅色部分是我添加的注釋。
/*在這個例子的一開始,我執(zhí)行了這樣一個命令ab -n 10 -c 10http://www.google.com/。這個命令的意思是啟動 ab ,向www.google.com發(fā)送10個請求(-n 10) ,并每次發(fā)送10個請求(-c 10)——也就是說一次都發(fā)過去了。跟著下面的是 ab 輸出的測試報告,紅色部分是我添加的注釋。*/ C:\Program Files\Apache Software Foundation\Apache2.2\bin>ab -n 10 -c 10 http://www.google.com/ This is ApacheBench, Version 2.0.40-dev <$Revision: 1.146 $> apache-2.0 Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Copyright 1997-2005 The Apache Software Foundation, http://www.apache.org/ Benchmarking www.google.com (be patient).....done Server Software: GWS/2.1 Server Hostname: www.google.com Server Port: 80 Document Path: / Document Length: 230 bytes Concurrency Level: 10 /*整個測試持續(xù)的時間*/ Time taken for tests: 3.234651 seconds /*完成的請求數量*/ Complete requests: 10 /*失敗的請求數量*/ Failed requests: 0 Write errors: 0 Non-2xx responses: 10 Keep-Alive requests: 10 /*整個場景中的網絡傳輸量*/ Total transferred: 6020 bytes /*整個場景中的HTML內容傳輸量*/ HTML transferred: 2300 bytes /*大家最關心的指標之一,相當于 LR 中的每秒事務數,后面括號中的 mean 表示這是一個平均值*/ Requests per second: 3.09 [#/sec] (mean) /*大家最關心的指標之二,相當于 LR 中的平均事務響應時間,后面括號中的 mean 表示這是一個平均值*/ Time per request: 3234.651 [ms] (mean) /*這個還不知道是什么意思,有知道的朋友請留言,謝謝 ^_^ */ Time per request: 323.465 [ms] (mean, across all concurrent requests) /*平均每秒網絡上的流量,可以幫助排除是否存在網絡流量過大導致響應時間延長的問題*/ Transfer rate: 1.55 [Kbytes/sec] received /*網絡上消耗的時間的分解,各項數據的具體算法還不是很清楚*/ Connection Times (ms) min mean[+/-sd] median max Connect: 20 318 926.1 30 2954 Processing: 40 2160 1462.0 3034 3154 Waiting: 40 2160 1462.0 3034 3154 Total: 60 2479 1276.4 3064 3184 /*下面的內容為整個場景中所有請求的響應情況。在場景中每個請求都有一個響應時間,其中 50% 的用戶響應時間小于 3064 毫秒,60 % 的用戶響應時間小于 3094 毫秒,最大的響應時間小于 3184 毫秒*/ Percentage of the requests served within a certain time (ms) 50% 3064 66% 3094 75% 3124 80% 3154 90% 3184 95% 3184 98% 3184 99% 3184 100% 3184 (longest request) |
在這個例子的一開始,我執(zhí)行了這樣一個命令 ab -n 10 -c 10http://www.google.com/
這個命令的意思是啟動 ab ,模擬10個用戶(-n 10)同時訪問www.google.com,并迭代10次(-c 10)。跟著下面的是 ab 輸出的測試報告,紅色部分是我添加的注釋。
更多信息 ab 不像 LR 那么強大,但是它足夠輕便,如果只是在開發(fā)過程中想檢查一下某個模塊的響應情況,或者做一些場景比較簡單的測試,ab 還是一個不錯的選擇——至少不用花費很多時間去學習 LR 那些復雜的功能,就更別說那 License 的價格了。
下面是 ab 的詳細參數解釋。
ab [ -A auth-username:password ] [ -c concurrency ] [ -C cookie-name=value ] [ -d ] [ -e csv-file ] [ -g gnuplot-file ] [ -h ] [ -H custom-header ] [ -i ] [ -k ] [ -n requests ] [ -p POST-file ] [ -P proxy-auth-username:password ] [ -q ] [ -s ] [ -S ] [ -t timelimit ] [ -T content-type ] [ -v verbosity] [ -V ] [ -w ] [ -x <table>-attributes ] [ -X proxy[:port] ] [ -y <tr>-attributes ] [ -z <td>-attributes ] [http://]hostname[:port]/path
-A auth-username:password
Supply BASIC Authentication credentials to the server. The username and password are separated by a single : and sent on the wire base64 encoded. The string is sent regardless of whether the server needs it (i.e., has sent an 401 authentication needed).
-c concurrency
Number of multiple requests to perform at a time. Default is one request at a time.
-C cookie-name=value
Add a Cookie: line to the request. The argument is typically in the form of a name=value pair. This field is repeatable.
-d
Do not display the "percentage served within XX [ms] table". (legacy support).
-e csv-file
Write a Comma separated value (CSV) file which contains for each percentage (from 1% to 100%) the time (in milliseconds) it took to serve that percentage of the requests. This is usually more useful than the 'gnuplot' file; as the results are already 'binned'.
-g gnuplot-file
Write all measured values out as a 'gnuplot' or TSV (Tab separate values) file. This file can easily be imported into packages like Gnuplot, IDL, Mathematica, Igor or even Excel. The labels are on the first line of the file.
-h
Display usage information.
-H custom-header
Append extra headers to the request. The argument is typically in the form of a valid header line, containing a colon-separated field-value pair (i.e., "Accept-Encoding: zip/zop;8bit").
-i
Do HEAD requests instead of GET.
-k
Enable the HTTP KeepAlive feature, i.e., perform multiple requests within one HTTP session. Default is no KeepAlive.
-n requests
Number of requests to perform for the benchmarking session. The default is to just perform a single request which usually leads to non-representative benchmarking results.
-p POST-file
File containing data to POST.
-P proxy-auth-username:password
Supply BASIC Authentication credentials to a proxy en-route. The username and password are separated by a single : and sent on the wire base64 encoded. The string is sent regardless of whether the proxy needs it (i.e., has sent an 407 proxy authentication needed).
-q
When processing more than 150 requests, ab outputs a progress count on stderr every 10% or 100 requests or so. The -q flag will suppress these messages.
-s
When compiled in
1
搭建良好的測試環(huán)境是執(zhí)行測試用例的前提,也是完成測試任務順利完成的保證。測試環(huán)境大體可分為硬件環(huán)境和軟件環(huán)境,硬件環(huán)境包括測試必須的PC機,服務器,設備,網線,分配器等硬件設備;軟件環(huán)境包括數據庫,操作系統(tǒng),被測試軟件,共存軟件等;特殊條件下還要考慮網絡環(huán)境,比如網絡帶寬,IP地址設置等。
搭建測試環(huán)境前后要注意以下幾點:
1> 搭建測試環(huán)境前,確定測試目的
即是功能測試,穩(wěn)定性測試,還是性能測試, 測試目的不同,搭建測試環(huán)境時應注意的點也不同。比如要進行功能測試,那么我們就不需要大量的數據,需要覆蓋率高,測試數據要求盡量真實,這對硬件環(huán)境配 置的好壞要求不是太苛刻,為提高覆蓋率,就要配置不同的硬件環(huán)境。如要進行性能測試,就需要大量的數據,測試數據應盡可能的達到符合實際的數據分配,這時 可能需要大量的設備來給測試對象施加壓力,要提前準備大量設備。
2> 測試環(huán)境時盡可能的模擬真實環(huán)境
這個要求對測試人員要求很高,因為很多測試人員沒有去過用戶使用現場,要完全模擬用戶使用環(huán)境根本不可能。這時我們就應該通過技術支持人員,銷售人員了 解,盡可能的模擬用戶使用環(huán)境,選用合適的操作系統(tǒng)和軟件平臺,了解符合測試軟件運行的最低要求及用戶使用的硬件配置,了解用戶常用的軟件,避免所有配置 所有操作系統(tǒng)下都要進行測試,沒有側重點,浪費時間。這樣一方面,可以在測試執(zhí)行過程中發(fā)生軟件產品與其他協同工作產 品之間的兼容性,避免軟件發(fā)布給用戶之后才發(fā)現的問題;另一方面也可以用來檢驗產品是不是用戶真正需要的。多說情況下,測試環(huán)境都是真空環(huán)境,完全純凈的 平臺,測試時,沒有問題,一旦拿到現場,與其它軟件并存,硬件配置等原因,問題多多,這個就是搭建測試環(huán)境時沒有考慮用戶的使用環(huán)境。
3> 確保無毒環(huán)境
我測試過幾個項目都是因為搭建的測試環(huán)境感染病毒,導致測試軟件經常出現莫名的崩潰,運行不起來等現象,導致測試中斷。這是殺毒是必要的,但是殺毒的時 間也應掌握好,具體可按照下列步驟:選擇PC機-à安裝操作系統(tǒng)—>安裝殺毒軟件殺毒—>安裝驅動程序及用戶常用軟件及瀏覽器à殺毒à安裝測 試軟件—>殺毒,安裝測試軟件后殺毒,要注意如果我們不是使用正版殺毒軟件,很可能我們安裝的測試軟件的一些文件被當做可疑文件或者病毒被清除,導 致測試軟件直接不可用。要確保殺毒軟件正版,如果不是正版,建議在安裝測試軟件前,卸載掉殺毒軟件。測試過程中,要注意U盤的使用以及測試環(huán)境與外網的控 制。每次使用U盤前,要在其它機器上先殺毒;當測試環(huán)境與外網聯通時,不建議使用共享方式互訪測試機。當小范圍PC機與外界隔離起來做測試環(huán)境時,可以禁 掉可移動存儲設備的使用,只允許一臺PC使用,這臺PC機上安裝殺毒軟件,進行資料傳送時,先拷貝到這臺機器上殺毒,然后以共享的方式進行資料的傳送。經 過這些措施可以很好的防止病毒感染測試環(huán)境,確保無毒環(huán)境。
4> 營造獨立的測試環(huán)境
測試過程中要確保我們的測試環(huán)境獨立,避免測試環(huán)境被占用,影響測試進度及測試結果,比如設備連網后,是不是其他測試組也在共用,這樣就可能影響我們的 測試結果。有時開發(fā)人員為確定問題會使用我們的測試環(huán)境,這樣會打亂我們的測試活動,更嚴重的是影響測試進度。為避免這種情況,測試人員在提交缺陷單時, 提供詳細的復現步驟以及盡可能多的信息。讓開發(fā)人員根據缺陷單,在開發(fā)環(huán)境中復現和定位問題。
5> 構建可復用的測試環(huán)境
當我們剛搭建好測試環(huán)境,安裝測試軟件之前及測試過程中,對操作系統(tǒng)及測試環(huán)境進行備份是必要的,這樣一來可以為我們下輪測試時直接恢復測試環(huán)境,避免 重新搭建測試環(huán)境花費時間,二來在當測試環(huán)境遭到破壞時,可以恢復測試環(huán)境,避免測試數據丟失,重現問題。構建可“復用”的測試環(huán)境,往往要用到如 ghost、Drive Image等磁盤備份工具軟件;這些工具軟件,主要實現對磁盤文件的備份和還原功能;在應用這些工具軟件之前,我們首先要做好以下幾件十分必要的準備工 作:
A、確保所使用的磁盤備份工具軟件本身的質量可靠性,建議使用正版軟件;
B、利用有效的正版殺毒軟件檢測要備份的磁盤,保證測試環(huán)境中沒有病毒
C、對于在測試過程中備份時,為減少鏡像文件的體積,要刪除掉Temp文件夾下的所有文件,要刪除掉Win386.swp文件或_RESTORE文件夾,這樣C盤就不至于過分膨脹,選擇采用壓縮方式進行鏡像文件的創(chuàng)建,可使要備份的數據量大大減小;
D、最后,再進行一次徹底的磁盤碎片整理,將C盤調整到最優(yōu)狀態(tài)。
對于剛安裝的操作系統(tǒng),驅動程序等安裝完成之后,測試程序安裝之前,也要進行備份工作,這樣可以防止不同項目交叉進行時,當使用相同操作系統(tǒng)時,直接恢復即可。
完成了這些準備工作,我們就可以用備份工具逐個逐個的來創(chuàng)建各種組合類型的軟件測試環(huán) 境的磁盤鏡像文件了。對已經創(chuàng)建好的各種鏡像文件,要將它們設成系統(tǒng)、隱含、只讀屬性,這樣一方面可以防止意外刪除、感染病毒;另一方面可以避免在對磁盤 進行碎片整理時,頻繁移動鏡像文件的位置,從而可節(jié)約整理磁盤的時間;同時還要記錄好每個鏡像文件的適用范圍,所備份的文件的信息等內容。
測試環(huán)境的搭建和維護處在重要的位置,它的好壞直接影響測試結果的真實性和準確性。維護測試環(huán)境需要大量的精力,不是一個人能完成的,需要我們大家積極配合。
成功的軟件產品是建立在成功的需求基礎之上的,而高質量的需求來源于用戶與開發(fā)人員之間有效的溝通與合作。當用戶有一個問題可以用計算機系統(tǒng)來解決,而開發(fā)人員開始幫助用戶解決這個問題,溝通就開始了。
需求獲取可能是軟件開發(fā)中 最困難、最關鍵、最易出錯及最需要溝通交流的活動。對需求的獲取往往有錯誤的認識:用戶知道需求是什么,我們所要做的就是和他們交談從他們那里得到需求, 只要問用戶系統(tǒng)的目標特征,什么是要完成的,什么樣的系統(tǒng)能適合商業(yè)需要就可以了,但是實際上需求獲取并不是想象的這樣簡單,這條溝通之路布滿了荊棘。首 先需求獲取要定義問題范圍,系統(tǒng)的邊界往往是很難明確的,用戶不了解技術實現的細節(jié),這樣造成了系統(tǒng)目標的混淆。
其次是對問題的理解,用戶對計算機系統(tǒng)的能力和限制缺乏了解,任何一個系統(tǒng)都會有很多的用戶或者不同類型的用戶,每個用戶只知道自己需要的系統(tǒng),而不知道系統(tǒng)的整體情況,他們不知道系統(tǒng)作為一個整體怎么樣工作效 率更好,也不太清楚那些工作可以交給軟件完成,他們不清楚需求是什么,或者說如何以一種精確的方式來描述需求,他們需要開發(fā)人員的協助和指導,但是用戶與 開發(fā)人員之間的交流很容易出現障礙,忽略了那些被認為是“很明確的信息。最后是需求的確認,因為需求的不穩(wěn)定性往往隨著時間的推移產生變動,使之難以確 認。為了克服以上的問題,必須有組織的執(zhí)行需求的獲取活動。
需求獲取活動建議要完成的11個任務或者說步驟分別是確定需求過程、編寫項 目視圖和范圍文檔、用戶群分類、選擇用戶代表、選擇用戶代表、建立核心隊伍、確定使用實例、召開聯合會議、分析用戶工作流程、確定質量屬性、檢查問題報告 和需求重用。當然應該根據組織和項目的具體情況進行適當的裁減,比如根據項目和用戶情況把需求獲取會議改成問卷調查或者座談等等。
1、編寫項目視圖和范圍文檔
系統(tǒng)的需求包括四個不同的層次:業(yè)務需求、用戶需求和功能需求、非功能性需求。業(yè)務需求說明了提供給用戶新系統(tǒng)的最初利益,反映了組織機構或用戶對系 統(tǒng)、產品高層次的目標要求,它們在項目視圖與范圍文檔中予以說明。用戶需求文檔描述了用戶使用產品必須要完成的任務,這在使用實例文檔或方案腳本說明中予 以說明。功能需求定義了開發(fā)人員必須實現的軟件功能,使得用戶能完成他們的任務,從而滿足了業(yè)務需求。
非功能性需求是用戶對系統(tǒng)良好運 作提出的期望,包括了易用性、反應速度、容錯性、健壯性等等質量屬性。需求獲取就是根據系統(tǒng)業(yè)務需求去獲得系統(tǒng)用戶需求,然后通過需求分析得到系統(tǒng)的功能 需求和非功能需求。項目視圖和范圍文檔就是從高層次上描述系統(tǒng)的業(yè)務需求,應該包括高層的產品業(yè)務目標,評估問題解決方案的商業(yè)和技術可行性,所有的使用 實例和功能需求都必須遵從的標準。而范圍文檔定義了項目產品所包括的所有工作及產生產品所用的過程。項目相關人員對項目的目標和范圍能達成共識,整個項目 組都應該把注意力集中在項目目標和范圍上。
2、用戶群分類
系統(tǒng)用戶在很多方面存 在著差異,例如:使用系統(tǒng)的頻度和程度、應用領域和計算機系統(tǒng)知識、所使用的系統(tǒng)特性、所進行的業(yè)務過程、訪問權限、地理上的布局以及個人的素質和喜好等 等。根據這些差異,你可以把這些不同的用戶分成不同的用戶類。與UML中Usecase的Actor概念一樣,用戶類不一定都指人,也可以包括其他應用系 統(tǒng)、接口或者硬件,這樣做使得與系統(tǒng)邊界外的接口也成為系統(tǒng)需求。將用戶群分類并歸納各自特點,并詳細描述出它們的個性特點及任務狀況,將有助于需求的獲 取和系統(tǒng)設計。
3、選擇用戶代表
不可能對所有的用戶都進行需求獲取,這樣做時間 不允許效果也不一定好,所以要識別出能夠確定需求和了解業(yè)務流程的用戶作為每類用戶的代表。每類用戶至少選擇一位能真正代表他們需求的人作為代表并且能夠 作出決策,用戶代表往往是本類用戶中三類人:對項目有決定權的領導、熟悉業(yè)務流程的專家、系統(tǒng)最終用戶。
每一個用戶代表者代表了一個特定的用戶類,并在那個用戶類和開發(fā)者之間充當主要的接口,用戶代表從他們所代表的用戶類中收集需求信息,同時每個用戶代表又負責協調他們所代表的用戶在需求表達上的不一致性和不兼容性。
4、建立核心隊伍
通常用戶和開發(fā)人員不自覺的都有一種”我們和他們“的想法,產生一種對立關系,把彼此放在對立面,每一方都定義自己的”邊界“,只想自己的利益而忽略對 方的想法。他們通過文檔、記錄和對話來溝通,而不是作為一個合作的整體去識別和確定需求完成任務。實踐證明這樣的方法是不正確的,不會給雙方帶來一點益 處,良好的溝通關系沒有建立導致了誤解和忽略重要的信息。只有當雙方參與者都明白要成功自己需要什么,同時也知道要成功對方需要什么時,才能建立起一種合 作關系。
為了建立合作關系通常采取一種組隊的方式來獲取需求,建立一個由用戶代表和開發(fā)人員組成的聯合小組作為需求獲取的核心隊伍。聯 合小組將負責識別需求、分析解決方案和協商分歧,小組成員可以采用會議、電子郵件、綜合辦公系統(tǒng)等方式進行交流,但交流時應注意以下原則:小組會議應該由 中立方來組織和主持,用戶和開發(fā)人員都要參加;交流預先要確定準備和參與的規(guī)則;議題要明確并覆蓋所有關鍵點,但信息來源應該自由;交流目標要明確,并告 知所有的成員。
5、確定使用實例
從用戶代表處收集他們將使用系統(tǒng)完成所需任務的 描述,討論用戶與系統(tǒng)間的交互方式和對話要求,這就是使用實例,一個單一的使用實例可能包括完成某項任務的許多邏輯相關任務和交互順序。使用實例方法給需 求獲取帶來的好處來自于該方法是用以任務為中心和以用戶為中心的觀點,比起使用以功能為中心和以開發(fā)者為中心的方法,使用實例方法可以使用戶更清楚地理解 和認識到新系統(tǒng)允許他們做什么和怎么做。描寫使用實例的時候要注意使用簡潔直白的表述,盡量使用主動語態(tài),”系統(tǒng)“或者”用戶“作為主語,比如”用戶提交 用戶密碼,系統(tǒng)驗證用戶密碼是否正確“,還有一點在描述中不要設計界面細節(jié),比如”用戶從下拉框中選擇產品類型“。使用實例為以后寫用例場景描述中的基本 路徑和擴展路徑提供了素材。
6、召開聯合會議
最常見的需求獲取方法是召開會議或者面談,聯合會議是范圍廣的、簡便的討論會,也是核心隊伍成員之間一種很好的溝通方法,該會議通過緊密而集中 的討論得以將用戶代表與開發(fā)人員間的合作伙伴關系付諸于實踐并能由此擬出需求文檔的底稿。聯合會議的第一個議題就是系統(tǒng)的必要性和合理性,必須所有成員都 同意系統(tǒng)是必要的而且合理的。接下來就可以討論使用實例清單,清單可以打印成大紙掛在墻上、寫在黑板上或做成演示材料。對每個清單合并去掉重復項,加上補 充內容就可以得到一份總的清單,注意避免采用負面的”太差“”不可行“去否定用戶的想法,這些想法都應該保留下來作為被評議的清單項,這樣保護了小組成員 開放的思維。最后對清單進行討論,會議成員必須檢查每一個使用實例,在把它們納入需求之前決定其是否在項目所定義的范圍內,形成最終的需求報告。
在進行討論時,也應該避免受不成熟的細節(jié)的影響,在對系統(tǒng)需求取得共識之前,用戶能很容易地在一個報表或對話框中列出某些精確設計,如果這些細 節(jié)都作為需求記錄下來,他們會給隨后的設計過程帶來不必要的限制,應確保用戶參與者將注意力集中在與所討論的話題適合的抽象層上,重點就是討論做什么而不 是怎么做。這里有一點很重要就是要讓用戶理解對于某些功能的討論并不意味著即將在系統(tǒng)中實現它,更不要做暗示或者承諾什么時候完成需求。在討論之后,記下 所討論的條目,并請參與討論的用戶評論并更正,因為只有提供需求的人才能確定是否真正獲取需求。當最后拿到了一份詳細準確的需求報告書的時候,會議就算成 功完成了。但是要清楚需求過程本身就是一個迭代的過程,在以后的過程活動中不可避免的將要修改和完善這份報告。
7、分析用戶工作流程
分析用戶工作流程觀察用戶執(zhí)行業(yè)務任務的過程,通過分析使用實例得到系統(tǒng)的用例圖。編制用例圖文檔將有助于明確系統(tǒng)的使用實例和功能需求,統(tǒng)一 建模語言的使用有助于與用戶進一步交流。每個用例的描述應包括:編號,為每個用例分配一個唯一的編號,為需求的追溯提供了方便;參與者,與這個用例交互的 actor;前置條件,開始用例前所必須具備的系統(tǒng)狀態(tài);后置條件,用例完成后系統(tǒng)達到的狀態(tài);基本路徑,用例完成的關鍵路徑,也是用戶期望的路徑;擴展 點,基本路徑的分枝,表示意外情況;字段說明,路徑中名稱的進一步分解說明,對以后類屬性的定義和數據庫字段設計起作用;設計約束,實現用例的非功能約 束。寫基本路徑時應該使用主動語句;句子以actor或者系統(tǒng)作為主語;一句表示一個actor動作,一句表示系統(tǒng)動作,交叉表現交互;不要涉及界面細 節(jié),比如“用戶在文本框輸入名稱,下拉框選擇類型”。
| |
| 編號 | UC1 |
| 參與者 | 用戶 |
| 前置條件 | 用戶訪問系統(tǒng),系統(tǒng)運行正常 |
| 后置條件 | 系統(tǒng)記錄用戶注冊信息 |
| 基本路徑 | 1. 用戶請求注冊。
2. 系統(tǒng)顯示注冊界面。
3. 用戶提交注冊信息。
4. 系統(tǒng)驗證注冊信息是否正確。
5. 系統(tǒng)生成用戶名和密碼,保存注冊信息。
6. 系統(tǒng)顯示"注冊成功"信息,進入會員頁面。 |
| 擴展點 | 4a. 用戶提供的信息不正確: 4a1. 系統(tǒng)提示輸入正確信息 4a2. 返回3 |
| 補充說明 | 注冊信息包括=用戶實名+電話+傳真+Email+聯系地址聯系地址=省份+城市+街道+郵編 |
| 設計約束 | 注冊反應時間不能超過3秒 |
8、確定質量屬性
在功能需求之外再考慮一下非功能的質量特點,以及確定由于特殊的商業(yè)應用環(huán)境對系統(tǒng)提出的功能或性能上的約束,這會 使你的產品達到并超過客戶的期望。對系統(tǒng)如何能很好地執(zhí)行某些行為或讓用戶采取某一措施的陳述就是質量屬性,這是一種非功能需求。聽取那些描述合理特性的 意見:快捷、簡易、直覺性、用戶友好、健壯性、可靠性、安全性和高效性。你將要和用戶一起商討精確定義他們模糊的和主觀言辭的真正含義,并且要將質量屬性 分配到每個用例的設計約束中去。
9、檢查問題報告
通過檢查當前已經運行系統(tǒng)的問題報告來進一步完善需求客戶的問題報告及補充需求為新系統(tǒng)或新版本提供了大量豐富的改進及增加特性的想法,負責提供用戶支持及幫助的人能為收集需求過程提供極有價值的信息。
10、需求重用
如果客戶要求的功能與已有的系統(tǒng)很相似,則可查看需求是否有足夠的靈活性以允許重用一些已有的軟件組件。業(yè)務建模和領域建模式需求重用的最好方法,像分析模式和設計模式一樣,需求也有自己的模式。