作為一個純 JAVA 的GUI應用,JMeter 對于CPU和內存的消耗還是很驚人的,所以當需要模擬數以千計的并發用戶時,使用單臺機器模擬所有的并發用戶就有些力不從心,甚至還會引起JAVA內存溢出的錯誤。不過,JMeter 也可以像 LoadRunner 一樣通過使用多臺機器運行所謂的 Agent 來分擔 Load Generator 自身的壓力,并借此來獲取更大的并發用戶數。根據 JMeter官方文檔的署名,你需要自己完成這個配置,不過不用擔心,這將非常簡單 ^_^
1. 在所有期望運行 JMeter 作為 Load Generator 的機器上安裝 JMeter,并確定其中一臺機器作為 Controller,其他的機器作為 Agent。然后運行所有 Agent 機器上的JMeter-server.bat文件——假定我們使用兩臺機器 192.168.0.1 和 192.168.0.2 作為 Agent;
2. 在Controller 機器的 JMeter 安裝目錄下找到 bin 目錄,再找到 JMeter.properties 這個文件,使用記事本或者其他文字編輯工具打開它;
3. 在打開的文件中查找“remote_hosts=”這個字符串,你可以找到這樣一行“remote_hosts=127.0.0.1”。其中的 127.0..0.1 表示運行 JMeter Agent 的機器,這里需要修改為“remote_hosts=192.168.0.1:1664,192.168.0.2:1664”
默認的端口號為:1099
——其中的 1664 為 JMeter 的 Controller 和 Agent 之間進行通訊的默認 RMI 端口號;
4. 保存文件,并重新啟動 Controller 機器上的 JMeter.bat,并進入 Run -> Remote Start 菜單項。看到啥了?^_^
話說上回,我們用Badboy錄制了Jmeter的
腳本,用Jmeter打開后形成了原始的腳本。但是在實際應用中,為了增強腳本的多樣性,就要使腳本
參數化。這里我以登錄為例,參數化
用戶賬號與用戶密碼。

圖1 :原始腳本
這里我利用Jmeter的CSV Data Set Config來實現參數化功能。
步驟如下:
1.在本地磁盤下新建一個文本。比如:F:\test.txt 文件的內容如下:
user,passwd
user1,passwd1
user2,passwd2
2.右鍵點擊Jmeter中需要參數化的某個請求,選擇添加——配置原件——CSV Data Set Config,會添加一個CSV Data Set Config,需要設置相關的一些內容,具體如下:

圖2:CSV Data Set Config設置
解釋下圖2的參數:
Filename:文件名。指保存信息的文件目錄,可以相對或者絕對路徑(比如:F:\test.txt)
Variable Names:參數名稱(如:有幾個參數,在這里面就寫幾個參數名稱,每個名稱中間用分隔符分割,分隔符在下面的“Delimitet”中定義,為了和文件中的“,”對于,這里也用“,”分割每個參數名,(比如:user,passwd)
Delimitet:定義分隔符,這里定義某個分隔符,則在“Variable Names”用這里定義的分隔符分割參數。
Recycle on EOF:是否循環讀入,因為CSV Data Set Config一次讀入一行,分割后存入若干變量中交給一個線程,如果線程數超過文本的記錄行數,那么可以選擇從頭再次讀入。
3.在需要使用變量的地方,比如在登錄操作中,需要提交的表單字段包含用戶名密碼,我們就可以用${變量名} 的形式進行替換,例如${user}和${password}。如圖3

圖3:參數化設置
這樣,腳本的參數化基本上完成了。如果我們要確定Jmeter有沒有按照我們的預期進行工作,我們應當考慮使Jmeter提供的斷言,加到Sampler 里面可以對返回的結果進行判斷,例如判斷HTTP返回結果里面是否含有某個字符串。我們可以根據自己的需要選擇要測試的響應字段,文本,還是代碼,一般選 擇響應文本,然后,我們選擇匹配規則,一般選擇“包含”,如果要精確匹配,則可以選擇“匹配”,但是選擇“匹配”,因為響應的內容一般還包含其他的信息, 比如html語言標簽,所以很難準確匹配。然后在在要冊似乎的模式下面,添加你要響應的內容。如圖

圖4 :斷言設置
添加好斷言后,要添加一個監聽器,以監聽響應斷言,選擇添加——監聽器——斷言結果。

圖5 :添加斷言結果
添加完斷言結果后,我們運行腳本來測試下參數化和斷言的功能。首先先設置下線程組中的線程數,Ramp-up period,和循環次數,我這里設置為10,0,5.就是10個線程
并發,循環5次。然后點擊運行-啟動。我們查看斷言結果的圖。

圖6:運行成功的斷言結果
運行沒有出錯。全部成功。我們修改下登錄參數,讓登錄失敗,然后看下斷言結果。如圖

圖7:響應斷言失敗
代碼分析也無需事無巨細皆列而剖之,只要找到關鍵所在也就是了;又不然列一堆的聲明上來,縱然有人有耐心看下去,我也沒耐心寫下去啊。特別關注了三 個類,Stats、MonitorPerformancePanel、MonitorGraph。分別是獲取解析得到的數據、監控器面板顯示和監視器上的 圖像繪制。下面選取了一些關鍵代碼來進行分析:
首先是Stats.java,下面是計算內存使用率的方法
public static int calculateMemoryLoad(Status stat) {
double load = 0;
if (stat != null) {
double total = stat.getJvm().getMemory().getTotal();
double free = stat.getJvm().getMemory().getFree();
double used = total - free;
load = (used / total);
}
return (int) (load * 100);
}
很簡單吧?就是獲取total值和free值,然后計算內存使用率,那么它解析的是什么東西呢?我們取了一份tomcat上的status的xml,內容如下:
<?xml version="1.0" encoding="utf-8"?><status><jvm><memory free='937000' total='5177344' max='66650112'/></jvm><connector name='http-8080'><threadInfo maxThreads="40" currentThreadCount="2" currentThreadsBusy="1" /><requestInfo maxTime="1715" processingTime="2819" requestCount="20" errorCount="2" bytesReceived="0" bytesSent="108662" /><workers><worker stage="S" requestProcessingTime="0" requestBytesSent="0" requestBytesReceived="0" remoteAddr="127.0.0.1" virtualHost="localhost" method="GET" currentUri="/manager/status" currentQueryString="XML=true" protocol="HTTP/1.1" /><worker stage="R" requestProcessingTime="0" requestBytesSent="0" requestBytesRecieved="0" remoteAddr="?" virtualHost="?" method="?" currentUri="?" currentQueryString="?" protocol="?" /></workers></connector><connector name='jk-8009'><threadInfo maxThreads="200" currentThreadCount="4" currentThreadsBusy="1" /><requestInfo maxTime="0" processingTime="0" requestCount="0" errorCount="0" bytesReceived="0" bytesSent="0" /><workers></workers></connector></status>
這亂七八糟的,誰看得清啊,不要急,保存下來命名為.xml文件,扔到ie里再看一下

其實上面那段代碼所取的,就是這個xml里面的memory free和total。
這 個xml里這么多可以利用的內容,要是我們都解析出來,不就可以有很多資源數據了?有人也許會問,這些都是什么tread信息什么,又沒有cpu啊,io 之類的信息,解析出來也沒用;要知道,這個xml文件你自己可以生成的,里面存什么數據,你自己怎么定義都行啊,定義好了,寫一個動態更新這里面的數據的 腳本或程序,再利用web去展現這個xml,jmeter不就可以取來用了?
我們再看看MonitorPerformancePanel.java
public static final String LEGEND_MEM = JMeterUtils.getResString("monitor_legend_memory_per"); //$NON-NLS-1$
public static final ImageIcon LEGEND_MEM_ICON = JMeterUtils.getImage("monitor-orange-legend.gif"); //$NON-NLS-1$
這兩句就是設置監視器上顯示的圖例,是啥東西呢?就是這個:

標識了圖線的顏色和內容標簽
上面兩句設置好了,要顯示就要看下面這段的了:
JLabel mem = new JLabel(LEGEND_MEM);
mem.setFont(plaintext);
mem.setPreferredSize(lsize);
mem.setIcon(LEGEND_MEM_ICON);
legend.add(mem);
做過java的gui編程的朋友一定不會覺得陌生,呵呵
再下來看一下MonitorGraph.java
if (MEM) {
int mmy = (int) (height - (height * (model.getMemload() / 10000.0)));
int lastmmy = (int) (height - (height * (last.getMemload() / 10000.0)));
g.setColor(Color.orange);
g.drawLine(lastx, lastmmy, xaxis, mmy);
}
這段就是展現曲線的代碼,可以產生如下的效果:
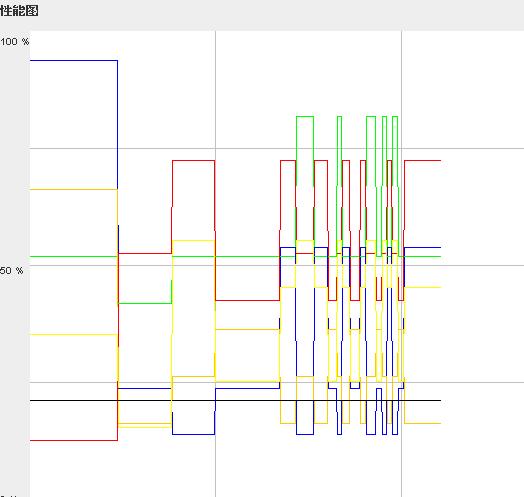
用jmeter做過tomcat監控的人一定會覺得很熟悉。不過也許會問,為啥這個圖像上曲線這么多呢,jmeter不是就四條么?
呵呵,不忙,且聽我慢慢道來。
我們團隊WP7上基于Academic Search 的會議助手手機客 戶端的alpha版本已經結束。在團隊中,限于團隊規模,每個人都會做點dev的事情,但是 我的最為主要的角色就是tester,以前從未做過tester,一個月的alpha版本開發下來,我在tester的崗位上也有許多的感想,我想,把它 們都記下了,希望它見證我們的成長,當然,希望能夠得到大家的指點,從眾人的認知領域獲得我們能汲取的經驗和知識。
理論上我們學到了什么?
我想,人們對于test最基本的認識,莫過于嘗試使用軟件,找出bug。事實上,真正做測試的時候要有很規范的流程。我簡要的挑幾個概念跟大家分享一下。
1)測試計劃:測試計劃描述測試活動的主要方面,why?what?who?when?。詳細的說包含一下方面:
測試的策略和方法、測試日程安排、質量目標、資源、測試變量矩陣。
2)什么是測試變量矩陣:
簡單的說,測試變量矩陣是通過考量用戶類型,系統的OS,語言,瀏覽器類型,網絡情況等各種因素,來確定測試變量數目以后列出的一個表格,測試變量矩陣是測試人員進行測試的藍本。
3)軟件測試的方法:
這里首先澄清一下,我們常說的黑箱測試和白箱測試其實并不是指的某種軟件測試的方法,它們是兩類軟件測試設計的方法。我們OMG團隊在alpha版本里主要采用的軟件測試方法集中在功能測試和非功能測試。
軟件測試方法,按功能測試分類,有單元測試(驗證測試每個單元程序的正確性)、模塊功能測試(測試每個模塊的功能)、集成測試(幾個相互依賴的模塊的功能的測試)、場景測試(驗證能否完成特定的用戶場景)、系統測試和alpha測試(alpha發布在實際的用戶環境中對軟件測試)。而非功能測試包括負載測試,效能測試,本地化/全球化測試,兼容性測試,配置測試,易用性測試和軟件安全測試等。
當然,軟件測試的方法還有很多,包括代碼覆蓋率測試(PS:對于新手的我來說,我真不知道如何設計代碼覆蓋測試方法。。。求高人指點)、驗收測試、回歸測試、“探索式”測試等等。
作為tester有何工作感想?
首先,我想說,主要角色是tester, 盡管我做的dev的工作相對較少,但是,我不覺得自己比別人貢獻的少。
很多人會有種執念,做軟件開發,不做dev似乎就沒有動力。其實,通過一個月的實踐,我覺得,社會本就是高度分工的。tester在一個軟件開發中起到的作用也是不可忽視的。很簡單,如果不做各種測試,軟件性能如何去評測?如何保證最后release的產品能夠很好的滿足用戶的需求?
其次,test工作并沒有想象中的那么容易。
一開始,接手tester的角色,心里想自己的工作壓力應該是比較小的。事實證明,真正用心去做好一個tester,還是需要付出很多的努力。在產品的 計劃階段,tester要討論測試計劃,調研和收集用戶對軟件的非功能性需求,比如軟件的效能,易用性等的信息,確定我們的非功能性測試標準;在開發階 段,tester需要及時的進行BVT(Build Verification Test),及時提交bug給dev,另外,作為tester,需要想很多“探索性測試”的例子,隨機的驗證軟件的穩定性和魯棒性;而當進入穩定階段后, 尤其是alpha版本發布后,tester需要收集用戶的alpha試用反饋,確定beta版本的測試標準。
最后也是最重要的一點,tester應該有怎么樣的素質。
做了把tester,才知道,tester不是那么好做的,當然,自己水平是那么那么的有限,所掌握的和接觸的知識也是比較少的。結合我的工作體驗,我發現了一下幾點:
1、足夠細心、耐心和信心。
首先你得相信自己有足夠的創造性和好奇心,要相信自己能挑出軟件的bug。然后你才有動力去嘗試各種可能的case,如果沒有了好奇心,打打醬油或許某 個bug就不經意間溜走了。而耐心和細心是做好任何工作的基礎。tester的工作,更是這樣,試想一下,某個功能或者某個用戶場景,你需要盡可能多的設 想各種test case去挑剔它,其實,有時候并不是那么的有意思的事情。
2、見多識廣,基礎要好。
我作為一個非CS專業的tester,更是對這一點體會有嘉。tester在設計黑箱測試方法的時候還更多地依賴創造性好奇心等。然而做白箱測試,代碼 的結構其實是對你透明的,能不能專業的分析代碼結構,能不能敏銳的察覺代碼中可能的風險或紕漏,這就是考驗一個tester專業技能的時候了。另外,見多 識廣很重要,tester要是能了解IT的各個方向,背景知識比較的多,對他來說,設計更好更有創造性的test case是相當有利的。
3、學習與鉆研精神。
取人之長,補己之短,他山之石,可以攻玉。老祖宗都說爛了。但是,我的經歷又一次檢驗了它。我從一開始連test plan都不知道如何下筆,到今天寫下這篇日志,我覺得,這就是從學習的過程中積累下來的,盡管我剛剛接觸它,我的這些文字看上去顯得稚嫩而有淺顯,但是,學習讓我成長,我也相信,學習能讓每一個都或者成功,或者成長。與君共勉。
賀炘-讓
測試敏捷起來在微博上問道:剛剛了解到,大多數測試人員不按測試用例來進行測試,原因是太麻煩了,那么測試用力基本形同虛設,對于這個問題,您怎么看?
大家對此展開了討論。
賀炘-讓測試敏捷起來: 首先測試過程是需要規劃的。規劃的方法可以是大綱或者具體的用例,也就是用顆粒度來平衡。
徐毅-Kaveri:回復@寶賢2011:測試用例要看你具體的內容,寫得太詳細,那么很有可能容易過時,某些命令、操作已無法執行;也有可能是用例寫得太虛,起不到指導的作用。這些都有可能是對方不按用例執行的原因,需要去弄明白。
寶賢2011:回復@徐毅-Kaveri:原來是這樣,不過據說用例寫得太詳細了,就沒有人愿意去執行,很麻煩。現在搞不清楚什么樣的用例才是好用例。用例形同虛設的多呢。
徐毅-Kaveri:回復@寶賢2011: 從你的描述中可以看出,你應該是站在測試用例編寫人的角度在思考問題,并未考慮用例閱讀者的需要,例如用例的可讀性、易理解程度?另外,我覺得用例的編寫 和執行根本就不應該分開,所以,我感覺在你們的組織結構設置里應該也是存在一些問題的。
寶賢2011:回復@徐毅-Kaveri:你是 說公司的組織結構嗎?如果是公司的組織結構設置應該在大多數公司都存在問題,所以這個,不應該在考慮的范圍內,即使存在問題,也應該想辦法克服,所以僅從 這個事情的角度來說的話,測試用例是很難寫出高覆蓋率又簡捷的。高覆蓋率和簡捷是大多數包括測試用例編寫者,以及執行者都希望看到的。
徐毅-Kaveri:回復@寶賢2011: 有的辦法治標有的辦法治本。那你就先從改進測試用例入手吧,和執行測試的人員一起來看測試用例,一起來執行測試用例,看看到底是哪些地方、哪些語句、哪些操作不好執行了,然后再修改,很簡單的事情啊。
寶賢2011:回復@徐毅-Kaveri:我有很多做測試的朋友,他們也一樣,用例和執行根本不在一起執行,我想知道這其中發生了什么事情。如果用例寫得不夠豐富,上面有關部門會覺得不夠豐富,何況什么事做到事無巨細,是很煩人的事情。
VIATelecom陳波:測試用例是需要分類的。功能、交互性、性能、壓力、兼容、自動化等等,在項目不同階段來執行發揮不同作用。用例對于覆蓋還是 非常有用的,執行時的粗細程度要測試人員根據項目情況來判斷。測試人員的情況是有差別的,組織者需要根據大家的情況安排不同的培訓,以求得更好協同工作,發揮大家最大的作用。
寶賢2011:回復@VIATelecom陳波:我認為測試應該從四個部分入手:1、界面——分頁、輸入格式、對不正確的數據有無驗證、與設計頁面是否 相符。2、數據測試——CRUD是否正確、報表、業務規則等等。3、業務測試——各基礎類模塊是否傳遞正確數據。4、流程測試。不知道您有什么看法?
VIATelecom陳波:回復@寶賢2011:光從測試本身來說,根據測試不同的產品,可以對測試做一些分類,沒有問題。很多時候需要結合項目的情況來決定每個版本做哪些測試,這很重要。
軟件測試方法種類繁多,記憶起來混亂,如果把軟件測試方法進行分類,就會清晰很多。我參考一些書籍和網上的資料,把常用的軟件測試方法列出來,讓大家對軟件測試行業有個總體的看法。
從測試設計方法分類
測試名稱 | 測試內容 |
Black box黑盒測試 | 把軟件系統當作一個“黑箱”,無法了解或使用系統的內部結構及知識。從軟件的行為,而不是內部結構出發來設計測試. |
White box白盒測試 | 設計者可以看到軟件系統的內部結構,并且使用軟件的內部知識來指導測試數據及方法的選擇。 |
Gray box. 灰盒測試 | 介于黑盒和白盒之間 |
總結:實際工作中,對系統的了解越多越好。目前大多數的測試人員都是做黑盒測試,很少有做白盒測試的。因為白盒測試對軟件測試人員的要求非常高,需要有很多編程經驗。做.NET程序的白盒測試你要能看得懂.NET代碼。做JAVA程序的測試,需要你能看懂JAVA的代碼。如果你都能看懂了,你還會做測試么
從測試是手動還是自動上分類
測試名稱 | 測試內容 |
Manual Test 手動測試 | 測試人員用鼠標去手動測試 (測試GUI) |
Automation 自動化測試 | 用程序測試程序 (測試API) |
對于項目來說,手動測試和自動化測試同等重要,都是保障軟件質量的方法。目前大部分的項目組都是手動測試和自動化測試相結合。因為很多測試無法做成自動化,很多復雜的業務邏輯也很難自動化,所以自動化測試無法取代手動測試。
對于軟件測試人員個人發展來說,做自動化測試是個挑戰,也是測試人員發展的一個方向,需要測試人員學習大量的開發知識(開發的知識真是學無止境啊)。從長遠角度來看,自動化測試肯定是越來越吃香的。
而手動測試比較適合剛工作不久的人,手動測試最大的缺點就是技術含量低,單調乏味,容易廢人。
總的來說,手工測試勝在測試業務邏輯,而自動化測試勝在測試底層架構。
如果被測試的程序可測試性比較好,很有必要做成自動化測試。能做自動化的盡量做成自動化,下面這些情形是可以做自動化的
1、測試存儲過程。例如用C#去測試存儲過程
2、測試Webservies.例如:用SoupUI工具,或者C#,Java去測試Webservies。
3、界面和業務邏輯分離的系統,比如,MVC,MVP架構,或者WPF程序。可以用測試腳本去測試這些程序的API。
從測試的目的分類
功能測試
測試的范圍從小到大,從內到外,從程序開發人員(單元測試)到測試人員,到一般用戶Alpha/Beta測試
測試名稱 | 測試內容 |
Unit Test 單元測試 | 在最低的功能/參數上驗證程序的準確性,比如測試一個函數的正確性(開發人員做的) |
Functional Test 功能測試 | 驗證模塊的功能 (測試人員做的) |
Integration Test 集成測試 | 驗證幾個互相有依賴關系的模塊的功能 (測試人員做的) |
Scenario Test 場景測試 | 驗證幾個模塊是否能完成一個用戶場景 (測試人員做的) |
System Test 系統測試 | 對于整個系統功能的測試 (測試人員做的) |
alpha 測試
| 軟件測試人員在真實用戶環境中對軟件進行全面的測試 (測試人員做的) |
Beta 測試 | 真實的用戶在真實的用戶環境中進行的測試, 也叫公測 (最終用戶做的) |
|
測試名稱 | 測試內容 | | Stress test 壓力測試 | 驗證軟件在超過負載設計的情況下仍能返回正確的結果,沒有崩潰 | | Load test負載測試 | 測試軟件在負載情況下能否正常工作 | | Performance test性能測試 | 測試軟件的效能,是否提供滿意的服務質量 | | Accessibility test | 軟件輔助功能測試-測試軟件是否向殘疾用戶提供足夠的輔助功能 | | Localization/Globalization | 本地化/全球化測試 | | Compatibility Test | 兼容性測試 | | Configuration Test | 配置測試-測試軟件在各種配置下能否正常工作 | | Usability Test | 可用性測試 –測試軟件是否好用 | | Security Test | 軟件安全性測試 |
性能測試 性能測試要求測試人員熟練性能測試工具,比如QTP,LoadRunner,Jmeter。VisualStudio也提供了很多性能測試的工具。要求測試人員對低層協議非常理解和編寫腳本 性能測試非常有技術含量,很有發展前途,是軟件測試人員的一個職業發展方向。 安全性測試 安全性測試的內容很廣,非常有難度啊。我只接觸過XSS(跨站腳本攻擊)和SQL注入攻擊。 安全性測試非常有技術含量,我認為也是軟件測試人員的一個職業發展方向 按測試的時機和作用分類 在開發軟件的過程中,不少測試起著“烽火臺”的作用,它們告訴我們軟件開發的流程是否暢通。 | 測試名稱 | 測試內容 | | Smoke Test | “冒煙”–如果測試不通過,則不能進行下一步工作 | | Build Verification Test(BVT) | 驗證構建是否通過基本測試。 | | Acceptance Test | 驗收測試,為了全面考核某功能/特性而做的測試 | BVT測試是一種Smoke Test,指Build生成好之后,自動運行的自動化測試腳本來檢查這個Build的基本功能。如果BVT測試失敗了,需要開發人員馬上修改,重新生成Buil 按測試測策略分類 | 測試名稱 | 測試內容 | | Regression Test 回歸測試 | 對一個新的版本,重新運行以往的測試用例,看看新版本和已知的版本相比是否有退化 (regression) | | Ad hoc Test 探索性測試 | 隨機進行的,探索性的測試。 | | Santiy Test | 粗略的測試, 只需要執行部分的測試用例 | Regression Test 回歸測試: 對軟件測試人員來說就是重復測試,所以回歸測試最好是自動化的,否則測試人員就要一遍又一遍地重復測試。 1、開發人員做些小改動,就需要測試人員做回歸測試。確保現有的功能沒有被破壞 2、Bug Fix 也需要回歸測試,確保新的代碼修復了Fix,也確保現有的功能沒有被破壞 3、項目后期,需要做一個完整回歸測試,確保所有的功能都是好的 Ad hoc Test 探索性測試: 平常我最喜歡做隨機測試了,拋開test case,自己按照自己的思路,隨便點點。如果測試GUI,Ad hoc能發現大量的bug。 |
非功能測試
一個軟件除了基本功能之外,還有很多功能之外的特性,這些叫“Quality of Service requirement”服務質量需求。沒有軟件的功能,這些特性都無從表現出來,因此,我們要在軟件開發的適當階段-基本功能完成后做這些測試。
測試的角色(Test)要獨立出來么 ?
獨立出來的測試角色怎么才能發揮作用?
有些成功人士和成功的公司號稱沒必要有獨立的測試角色(Test),你怎么看?
最近又看到一些關于開發人員要不要負責測試的討論。例如:
http://www.51testing.com/html/94/n-807994.html
大多數的開發團隊并不需要一個獨立的測試角色。即使有一個,他的所有的開發時間比上所有的測試時間應該>20:1。
我正好在寫相關的教案,也來湊個熱鬧。
[這篇文章的一些事例來自于我曾經和現在的團隊。希望這些例子不足以影響相關人物和團隊的偉大形象。任何軟件團隊都會犯錯誤,偉大的團隊有勇氣面對自己的錯誤并不斷改進。]
首先,明確兩個概念:
軟件測試(Test):運用定義好的流程,工具去驗證軟件能實現預先設計的功能和特性,工作的流程和結果通常是可量化的,例如,測試用例,bugs,代碼覆蓋率,MTTF,軟件效能的參數。[注:正因為流程和結果是可明確定義的,可量化的,很多測試工作可以自動化]
軟件質量保證工作(QualityAssurance):軟件團隊的成員為了讓軟件達到事先定義的質量而進行的所有活動,包括測試工作。
對于這兩個術語,不同人有不同的定義,有人認為它們是互通的,在《現代軟件工程》的上下文中我盡量使用上述的定義.
測試的角色(Test)要獨立出來么?
回答:首先,我相信有分工是好事,軟件團隊中應該有獨立的測試(Testing)角色。所有人都可以參與QA的工作(報告bug什么的),但是最后要有 一個角色對QA這件事負責。不但角色要獨立,而且在最后軟件發布的時候,必須得到此角色的簽字保證(signoff)。我在微軟參與的項目都是這樣做的。
在開始論證之前,先引用斯密特·亞當斯的《國富論》來暖場(我沒讀過這本書,直接從網上抄的)。
分工理論
亞當斯認為,分工的起源是由人的才能具有自然差異。…假定個人樂于專業化及提高生產力,經由剩余產品之交換行為,促使個人增加財富,此等過程將擴大社會 生產,促進社會繁榮,并達私利與公益之調和。他列舉制針業來說明。“如果他們各自獨立工作,不專習一種特殊業務,那么他們不論是誰,絕對不能一日制造二十 枚針,說不定一天連一枚也制造不出來。他們不但不能制出今日由適當分工合作而制成的數量的二百四十分之一,就連這數量的四千八百分之一,恐怕也制造不出 來。”
分工促進勞動生產力的原因有三:第一,勞動者的技巧因專業而日進;第二,由一種工作轉到另一種工作,通常需損失不少時間,有了分工,就可以免除這種損失;第三,許多簡化勞動和縮減勞動的機械發明,只有在分工的基礎上方才可能。
我們看團隊形式的職業體育比賽,各個位置的分工都很明確,拿足球來說,有專注進攻的,有專注防守的,但是在我的印象中,那些偉大的前鋒大多數只管一件事-進攻。亨利(ThierryHenry)參加防守么?
當然一些球賽也有沒有分工的時候,原因有好幾個:
事太小,幾個小孩踢個半場。
無知,小孩們剛開始玩球。
人手不夠,一對一打籃球,你要參與防守么?沙灘排球,兩人都是全攻全守。
如果你的軟件團隊做的事情和上面的情況類似,那當然不必分工。你們做的很可能不是商用軟件,你的軟件團隊大概也不用受什么軟件工程規律的束縛。
任何產業產業成熟到一定階段的時候,獨立的質量保證角色是不可避免的。團隊內部有QA角色,團隊外部也有獨立的QA角色。
拿藥品和食品來做例子,除了生產廠家自己的檢測之外,這些產品還要接受行業主管部門相關機構的檢測和認可(藥品檢驗,食品檢驗),才能上市。在出現爭議的情況下,還要第三方機構來進行測試或認證。
有人也許這樣建議:
這些藥品都是藥廠同一批工人一邊制造一邊測試出來的,特別有保證!不用測了,趕緊吃了吧!
也許還有人這樣建議:
這個十字坡夫妻店的農家飯都是他們自己親手做的,很可信,咱們今晚就去吃飯住一宿吧。
我們每天經常使用的電子產品,從大彩電到電影插座,也經歷了很多團隊內部的和外部的測試,請隨手拿過任何一個電器,你會在背面看到密密麻麻的小字,其中肯定有下列標記之一:

沒有這些標記的產品電子產品,市面上很少看到。
在軟件和互聯網產業,目前沒有這些認證,相反的,倒是有“人肉認證”:
你想申請某個著名專業網站的賬戶或者郵箱,但是又擔心這個網站對用戶信息的保護程度不夠。有人說,沒關系的,這個網 站的創始人也用賬戶,CTO,總監什么的還經常發軟件安全博客,賬戶一定是非常安全的!這里不存在獨立的質量認證,只能通過人肉(創始人/CTO/總監) 來認證產品的質量。
其實這種認證未必安全…(密碼門事件)(明文密碼事件)(郵箱密碼漏洞)
如果有第三方的認證“此網站對用戶信息的保護程度是X級,我們認證它不會明文存儲用戶密碼…”我就放心了。在第三方認證出現之前,我希望團隊內部至少有獨立的QA角色,來確保軟件的質量。否則我是不樂意使用這些軟件/服務的。
[補充一句,互聯網服務的各種認證也在發展,例如verisign公司提供的各種認證。]
獨立出來的質量保證角色怎么才能發揮作用?
有了獨立的質保角色之后,是不是萬事大吉了?未必,分工意味著一件事要分給別人去工作。讓別人做事,并且依賴別人做出的結果,這會出現一些問題。
問題:既然有專人負責,那我就不用負責了!
生活中一個常見的歪理是,既然有清潔工,那我亂扔點兒垃圾算什么,這才是他們工作啊!
盡管有專人負責QA中的測試工作,但是保證質量仍然是所有成員的職責。軟件團隊中的一些人往往在有意無意中忘記這一 點。最常見的現象是開發人員寫好一個功能之后,迫不及待地宣布成功,然后希望測試人員去發現所有問題。如果問題在發布后才被發現,開發人員會說–測試人員 怎么搞的,這種bug都沒找出來!?
某項目的某功能有重要的改進,這個改進經過研究員的研究,開發人員的設計,美工的美化,兩個開發人員的配合實現,項 目管理人員的督促,測試人員的測試,最后所有人都號稱做好了,上線了!為此,我約了某個目標用戶給他做實地展示,幾天后,大家都到齊了,開始演示。開始進 行的不錯,馬上最重要的killerfeature就會出來了…噯,預想的效果怎么還沒出現呢?再試試,還沒有?各相關人員面面相覷,大家小聲說:
“我不是把那個新模塊給你了么?”
“我就是照著那個接口實現的啊…”
“我不是已經交給那啥…”
“所有的bug不是已經都搞定了么…”,
會議在尷尬中勝利結束了。
來查問題的根源,這個復雜的功能由于兩個模塊的接口在最后沒有同步,某重要的參數被忽略了,這個功能中最出彩的部分壓根就不可能工作!那負責測試的角色怎么解釋“所有測試用例通過,同意發布”的呢?
這還是開發人員引以自豪的“殺手級功能”(killerfeature),那其它普通的功能是什么命運呢?
回過頭來,我們可以問:
·這件事真的要通過這么多環節么?
·測試人員真的知道最最關鍵的地方如何測試么?
·在系統上線之后,所有為這個功能感到自豪的人是否去實地測試過呢?
一個開發人員應該負責下面“開發功能”右邊的幾個圓圈呢?
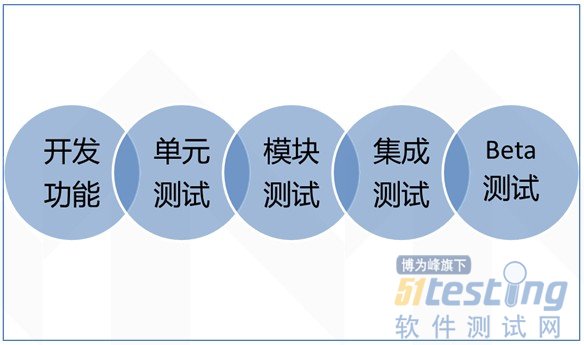
問題:盲目信任“專業人士”扮演的角色
每個角色的水平不一樣,軟件的質量往往受最差的角色的影響最大。我們團隊要為某軟件寫一段英語介紹文字,團隊成員都 是通過四六級英語考試的牛人,可他們都很謙虛,說要請一個專業的人士來寫不可。于是求了一個專業人士,求了好幾次(專業人士很忙的),在上市之前才得到專 業的文案,于是,copy/paste幾次之后,軟件就向全世界發布了.
這個文案第一句就是熱情洋溢的設問句:“haveyoueverthinkabout...”隨后還有幾處非常明顯的語法錯誤.這個軟件吸引了不少評論文章,有旁觀者說,從介紹文字的幾處典型中國式語法錯誤來看,這個軟件是由在中國的某分部搞出來的…
即使有專業人士扮演各種角色,還得有專人獨立地檢查驗證質量。
我們回頭來看,可以問兩個問題:
·這件事真的要專業人士來做么?
·專業人士做完之后,誰來負責測試?
問題:為了自己角色而做績效優化
分工之后,每個角色為了自己的績效而優化,會出現局部最優,而全局未必最優的情況。
我們團隊的另一個wp7的應用也要發布,這次專業人士又出手了,寫了175個英語單詞的介紹,極盡溢美之事,而且找 不到明顯的語法問題!這的確是一種局部最優了。但是完全沒考慮到用戶在小小的手機屏幕上有多少耐心讀完那么多形容詞和狀語從句。經過簡化,我們把它減少到 78個詞,勉強能放進手機的兩個屏幕。
我們回頭來看,可以問:
·這些事真的要交給和項目無關的專業人士來做?
·當我們給專業人士介紹需求的時候,是否花了足夠的時間讓對方理解我們要的是什么?
·專業人士做完之后,我們要做什么樣的QA?光保證沒有明顯的語法錯就夠了?
很多年前,當COBOL還是主流商用語言之一的時候,我曾在一個在軟件團隊里負責測試工作。職責之一,是寫各種測試用例,來保證系統的代碼覆蓋 率到達80%以上。做過實際項目的工程師都知道,程序里很多語句是用來處理種種異常情況的,這些情況大多數情況下不會發生。但是這些語句如果沒有被覆蓋的 話,這個模塊的覆蓋率就會下降,我就達不到80%的目標。所以我花了很多時間構造各種奇怪的測試數據,把程序中的那些犄角旮旯都盡可能覆蓋掉。至于這些犄 角旮旯在實際中是否會發生,對用戶的影響如何,程序是否應該這樣設計,我都不太關心。只要覆蓋率達到80%,老子的活就干完了!
問題:畫地為牢的分工
在一個長期而復雜的項目中,我要求所有新來的成員,包括外包公司的新成員,在加入團隊的時候,先找到系統當前100個數據方面的問題,并用內部 工具修復。我認為這能有效地讓新人了解系統的復雜性,弱點,和維護的流程。外包公司的員工很爽快地答應了,但是我們一些專家反而有不同意見。專家認為,外 包公司的人是來做測試用例的設計,所以不必做其它事情,我們期望他們一上手就能設計出高質量的測試用例,不應該給他們那些低級的手工操作任務…
理論上這都是非常有道理,但是如果這些人如果沒有親力親為地在這個項目中做一些具體事,他們怎么能“設計”出高質量,有實際意義的測試用例呢?
有時分工導致鏈條過長,信息丟失。一個開發者對自己寫的程序有什么潛在問題還是很有感覺的,有些問題可以用文字表述出來(如果開發人員有耐心把文字寫出來的話),有些問題是一些預感…現在都交給別人測試了,那好,讓他們測吧,我也懶得說了。
分工還可能會導致一個軟件的靈魂被切碎分給各個"角色",每個功能都做得很賣力,但是整體就是不太行,明顯看出來是費了老大的勁給強行“集成”起來的。
問題:無明確責任的分工
在我寫第一本書的時候,編輯部告訴我他們會對書稿進行初讀,二讀,三讀等流程,每個環節要花幾天時間。作為出版界的外行,我理解這些都是QA的 階段,等過了二讀的時間,我就發信去問,負責二讀的專業人士找到了什么問題了?得到了語焉不詳的回答…一個問題都沒找到?但是從編輯部的回答來看,二讀不 二讀,似乎沒什么影響。其實這本書的小問題還很多,在出版之后,都陸陸續續被讀者報告了。
有時候出于種種考慮,人們會把一些善良但是能力有限的同事安排在一些位置上,扮演一些角色,例如“二讀”什么的。或者有些角色就是由一些人占據著,但是大家對這個角色也沒有什么明確的要求。這是許多問題的根源。
我們對這個角色有什么可以量化,可以核查的責任要求?
我們對“一本書的質量是X”的信心是Y,剛開始組稿的時候,X的取值范圍非常大(爛書…一般…好書…年度大賣…永恒經典),信心也比較低。經過每個一個QA環節,我們都應該把X的范圍縮小,把信心值Y提高。
例如:二讀之后,找到了20個嚴重問題,100個小問題,因此我們有更大的信心認為這本書是一本爛書(如果不做改進的話)。
再入:二讀之后,找到了10個小問題,確信沒有更嚴重的問題了。因此我們有更大的信心認為這本書是一本好書。
。。。
把“書”換成“軟件”,“二讀”換成“測試”,同樣道理。
從上面舉的例子可以看到,分工之后,的確會產生很多問題。但是解決的方案是什么呢?是取消分工,讓開發人員順手做測試人員的事情,順便把項目管理,美工,市場推廣,客服都干了?顯然不是。
注意我們提到了“角色”,角色是有人來扮演的,如果一人扮演了“開發”的角色,又能夠來扮演“測試”的獨立角色,當然很好。但是條件是她要以“獨立”的心態測試,而不是想:“這代碼就是我寫的,哪會有什么錯…”而草草了事。
那么獨立的測試角色怎么才能發揮最大作用?從上面的壞現象中,我們不難總結出來。其實MSF原則都講到了。
·充分授權和信任(Empower team members)
·各司其職,對項目共同負責(Establish clear accountability and shared responsibility)
有些成功人士和成功的公司號稱沒必要有獨立的測試角色(Test),你怎么看?
我猜想和踢足球類似,還是那幾個原因:
人太牛:
不世出的天才,例如高德納寫書的時候發現排版軟件不好用,就自己寫了一個。也沒聽說他為這個軟件項目請了什么獨立測試人員。對了,他不讀email已經很多年,有秘書幫他處理這些事-這也是一種分工!
太小:
“我寫了個小類庫,全部自己測試”這當然不錯。
我以前的一個優秀實習生后來一個人嘗試寫一些UI的控件,寫得很高興的時候說了一句“我現在軟件工程的原則都不管了…”為了玩得爽,不妨打破束縛,諸法皆空,挺好。
但是順水推舟,推廣到所有情況,從而得出"程序員就應該自己測試,獨立測試不必了"這樣的普適結論,未免有點過。
人不夠:
那就自己動手多做一些事情,也挺好。就像前面提到的,一個人扮演多個角色,只要能入戲就行。
條件特殊:
近年來,軟件產業百舸爭流,魚龍混雜,在海里裸泳的弄潮兒也不少,出現了種種類型的分工合作和開發模式。不在有些情況下(例如一窩蜂模式,主治醫師模式),強力的dev是可以搞定很多事情。運用之妙,存乎一心。
引起網上討論的兩篇文章在這里:
http://www.51testing.com/html/94/n-807994.html
http://www.quora.com/Is-it-true-that-Facebook-has-no-testers
其中打分最高的回答來自前雇員(Evan Priestley),他總結了Facebook這個公司為什么貌似沒有全職測試人員:
a、全公司人員經常使用自己的軟件產品!(如果你開發的軟件是航天飛行某控制模塊,你怎么能經常使用呢?)
b、使用log來分析問題可能出在哪里。(我們的一些程序員寫程序都沒有log,那大家看什么呢?)
c、利用用戶的反饋和實時狀態分析(比較過去一小時和上周同一時間的數據來判斷是否有bug)
d、應用開發商給Facebook報bug。(開發商其實比較不爽,但是FB有時就是無預警地修改API,你除了趕緊報bug,還能怎么著?)
e、很多人自愿給Facebook報bug,這位貼主自稱每月給他的前雇主報13,000個問題.(沒錯,是每月一萬三千個!)
f、最后這位前雇員還加了一句:還有一個原因是,Facebook大體上也不需要搞出太高水平的軟件。
當你的公司也能有a)到e)這樣的文化,流程,開發商和給力的前員工,而且你的軟件“大體上也不要太高質量”你的確不需要什么全職測試人員!
微軟是怎么做的呢?
就像MSF原則講的那樣,有分工,有合作。
微軟開發測試主要有三種角色:
·SDE: Software Design Engineer,簡稱dev。
·SDE/T: Software Design Engineer in Test,也寫代碼,但是重點在測試。
·STE: Software Test Engineer.
對于如何更有效地開發互聯網應用,微軟很多團隊都做過不少探索。例如一些團隊嘗試把SDE和SDE/T合成一體。每個人都負責開發/測試/發布這一整套流程,根據我的觀察,有好處,也有額外的成本。
結束
一位網友說得好:分工是社會和行業進化的結果。開發和測試其實是軟件工程的兩分支。不同的軟件/服務需要不同方式和程度的測試。獨立專業的測試等同于第三方代表客戶對產品認證。
拉拉扯扯這么多話,團隊/個人/角色到底應該怎么辦呢?我認為,
·在初始階段(新項目,團隊進入一個新領域,人員剛進入一個項目),每個團隊成員都要盡量打通各個環節,多負責,把所有事情都搞懂,培養通才。
·當項目/產業發展到一定階段(進入陣地戰的時候), 要大力提倡分工合作, 培養專才。
·把自己項目的架構和流程做好, 讓所有人都能比較容易地進行 Quality Assurance 的工作。
·培養“大家都要做QA, 專人負責量化的Test, 有條件多做測試自動化”的文化。
·要明白自己項目的特點, 人員的特點, 產業的特點。避免照搬別人的做法。不要聽說某某偉大的系統的開發/測試比例是多少, 就哭著喊著也要同樣的比例…
思考題:
分工之后, 每人負責一小塊東西, 怎么能體現出個人的獨特而巨大的價值呢? 例如, 你剛到一個出版社, 領導讓你做 “二讀” 這份工作; 或者你剛到一個軟件公司, 領導讓你做 “測試” 這份工作, 你怎么能展現出你獨特的價值呢?
你在某團隊做測試,兢兢業業已經三年, 今天大家傳說公司認為開發人員應該做測試, 所以不需要專職的測試人員了。 你怎么想? 你能否做到:
明確列出過去三年你對團隊的貢獻? 除了“認真執行測試用例”之外, 你對團隊整體的“質量保證”還有什么獨特的貢獻?
有理有據地說明, 沒有專職測試人員, 項目會有什么風險?
這三年的經歷在你的簡歷怎么寫出來? 你比三年前更容易找到工作么?
這三點搞不清楚的, 還是改行吧。