1.前言:
LoadRunner 最重要也是最難理解的地方--測試結果的分析.其余的錄制和加壓測試等設置對于我們來講通過幾次操作就可以輕松掌握了.針對 Results Analysis 我用圖片加文字做了一個例子,希望通過例子能給大家更多的幫助.這個例子主要講述的是多個用戶同時接管任務,測試系統的響應能力,確定系統瓶頸所在.客戶要求響應時間是1 個人接管的時間在5S 內.
2.系統資源:
2.1 硬件環境:
CPU:奔四2.8E
硬盤:100G
網絡環境:100Mbps
2.2 軟件環境:
操作系統:英文windowsXP
服務器:tomcat 服務
瀏覽器:IE6.0
系統結構:B/S 結構
3.添加監視資源
下面要講述的例子添加了我們平常測試中最常用到的一些資源參數.另外有些特殊的資源暫時在這里不做講解了.我會在以后相繼補充進來。
Mercury Loadrunner Analysis 中最常用的5 種資源.
1. Vuser
2. Transactions
3. Web Resources
4. Web Page Breakdown
5. System Resources
在Analysis 中選擇“Add graph”或“New graph”就可以看到這幾個資源了.還有其他沒有數據的資源,我們沒有讓它顯示.

如果想查看更多的資源,可以將左下角的display only graphs containing data 置為不選.然后選中相應的點“open graph”即可.
打開Analysis 首先可以看的是Summary Report.這里顯示了測試的分析摘要.應有盡有.但是我們并不需要每個都要仔細去看.下面介紹一下部分的含義:
Duration(持續時間):了解該測試過程持續時間.測試人員本身要對這個時期內系統一共做了多少的事有大致的熟悉了解.以確定下次增加更多的任務條件下測試的持續時間。
Statistics Summary(統計摘要):只是大概了解一下測試數據,對我們具體分析沒有太大的作用.
Transaction Summary(事務摘要):了解平均響應時間Average單位為秒.
其余的看不看都可以.都不是很重要.
【注】 51Testing授權IT168獨家轉載,未經明確的書面許可,任何人或單位不得對本文內容復制、轉載或進行鏡像,否則將追究法律責任。
內容導航
4.分析集合點
在錄制腳本中通常我們會使用到集合點,那么既然我們用到了集合點,我們就需要知道Vuser 是在什么時候集合在這個點上,又是怎樣的一個被釋放的過程.這個時候就需要觀察Vuser-Rendezvous 圖.
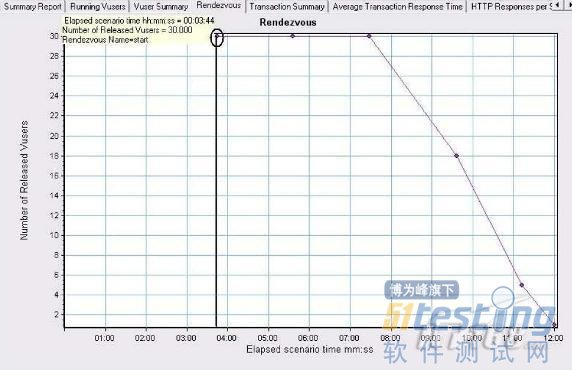
圖1
可以看到大概在3 分50 的地方30 個用戶才全部集中到start 集合點,持續了3 分多,在7 分30 的位置開始釋放用戶,9 分30 還有18 個用戶,11 分10 還有5 個用戶,整個過程持續了12 分.
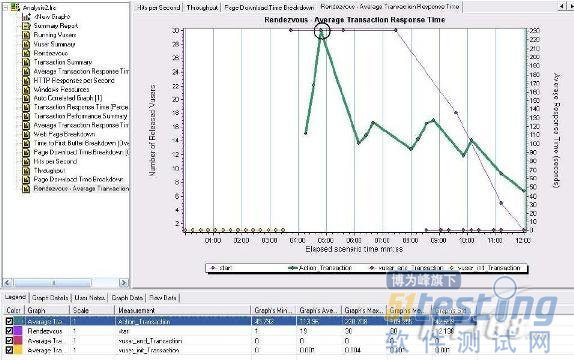
圖2
上面圖2 是集合點與平均事務響應時間的比較圖.
注:在打開analysis 之后系統LR 默認這兩個曲線是不在同一張圖中的.這就需要自行設置了.具體步驟如下:
點擊圖上.右鍵選擇merge graphs.然后在select graph to merge with 中選擇即將用來進行比較的graph.如圖3:
圖3
圖2 中較深顏色的是平均響應時間,淺色的為集合點,當Vuser 在集合點持續了1分后平均響應時間呈現最大值,可見用戶的并發對系統的性能是一個很大的考驗.接下來看一下與事務有關的參數分析.下看一張圖.
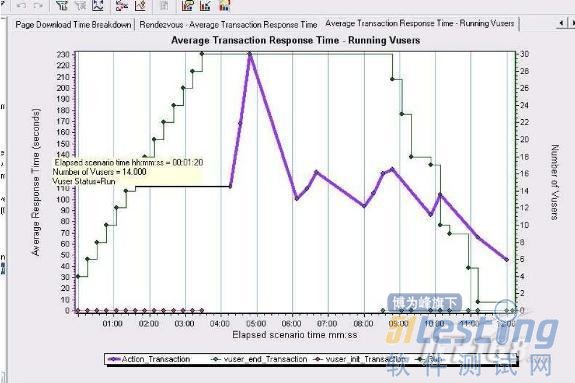
圖4
這張圖包括Average Transaction Response Time 和Running Vuser 兩個數據圖.從圖中可以看到Vuser_init_Transaction(系統登錄)對系統無任何的影響,Vuser 達到15 個的時候平均事務響應時間才有明顯的升高,也就是說系統達到最優性能的時候允許14 個用戶同時處理事務,Vuser 達到30 后1 分,系統響應時間最大,那么這個最大響應時間是要推遲1 分鐘才出現的,在系統穩定之后事務響應時間開始下降說明這個時候有些用戶已經執行完了操作.同時也可以看出要想將事務響應時間控制在10S 內.Vuser 數量最多不能超過2 個.看來是很難滿足用戶的需求了.
做一件事有時候上級會問你這件事辦得怎么樣了.你會說做完一半了.那么這個一半的事情你花了多少時間呢?所以我們要想知道在給定時間的范圍內完成事務的百分比就要靠下面這個圖(Transaction Response Time(Percentile)
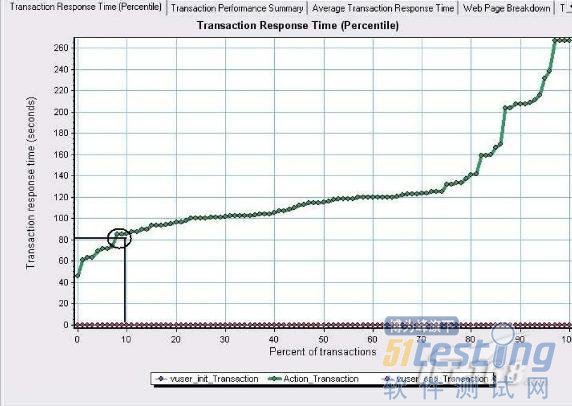
圖中畫圈的地方表示10%的事務的響應時間是在80S 左右.80S 對于用戶來說不是一個很小的數字,而且只有10%的事務,汗.你覺得這個系統性能會好么!
實際工作中遇到的事情不是每一件事都能夠在很短的時間內完成的,對于那些需要時間的事情我們就要分配適當的時間處理,時間分配的不均勻就會出現有些事情消耗的時間長一些,有些事情消耗的短一些,但我們自己清楚.LR 同樣也為我們提供了這樣的功能,使我們可以了解大部分的事務響應時間是多少?以確定這個系統我們還要付出多少的代價來提高它.
Transaction Response Time(Distribution)-事務響應時間(分布)
顯示在方案中執行事務所用時間的分布.如果定義了可以接受的最小和最大事務性能時間,可以通過此圖確定服務器性能是否在可接受范圍內.

很明顯大多數事務的響應時間在60-140S.在我測試過的項目中多數客戶所能接受的最大響應時間也要在20S 左右.140S 的時間!很少有人會去花這么多的時間去等待頁面的出現吧!
通過觀察以上的數據表.我們不難看到此系統在這種環境下并不理想.世間事有果就有因,那么是什么原因導致得系統性能這樣差呢?讓我們一步一步的分析.
系統性能不好的原因多方面,我們先從應用程序看.有的時候我不得不承認LR 的功能真的很強大,這也是我喜歡它的原因.先看一張頁面細分圖.

一個應用程序是由很多個組件組成的,整個系統性能不好那我們就把它徹底的剖析一下.圖片中顯示了整個測試過程中涉及到的所有web 頁.web page breakdown中顯示的是每個頁面的下載時間.點選左下角web page breakdown 展開,可以看到每個頁中包括的css 樣式表,js 腳本,jsp 頁面等所有的屬性
在select page to breakdown 中選擇頁面.
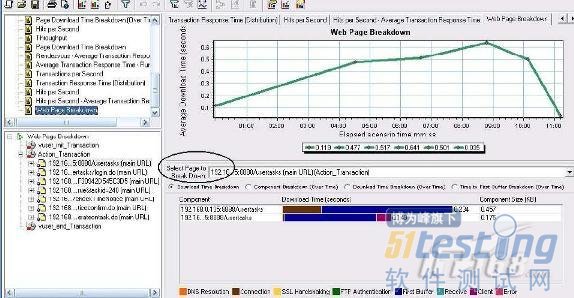
見圖.
在 Select Page To Breakdown 中選擇http://192.168.0.135:8888/usertasks 后,在下方看到屬于它的兩個組件,第一行中Connection 和First Buffer 占據了整個的時間,那么它的消耗時間點就在這里,我們解決問題就要從這里下手.


也有可能你的程序中client 的時間最長.或者其他的,這些就要根據你自己的測試結果來分析了.下面我們來看一下CPU,內存.硬盤的瓶頸分析方法:
首先我們要監視CPU,內存.硬盤的資源情況.得到以下的參數提供分析的依據.
%processor time(processor_total):器消耗的處理器時間數量.如果服務器專用于sql server 可接受的最大上限是80% -85 %.也就是常見的CPU 使用率.
%User time(processor_total)::表示耗費CPU的數據庫操作,如排序,執行aggregate functions等。如果該值很高,可考慮增加索引,盡量使用簡單的表聯接,水平分割大表格等方法來降低該值。
%DPC time(processor_total)::越低越好。在多處理器系統中,如果這個值大于50%并且Processor:% Processor Time非常高,加入一個網卡可能會提高性能,提供的網絡已經不飽和。
%Disk time(physicaldisk_total):指所選磁盤驅動器忙于為讀或寫入請求提供服務所用的時間的百分比。如果三個計數器都比較大,那么硬盤不是瓶頸。如果只有%Disk Time比較大,另外兩個都比較適中,硬盤可能會是瓶頸。在記錄該計數器之前,請在Windows 2000 的命令行窗口中運行diskperf -yD。若數值持續超過80%,則可能是內存泄漏。
Availiable bytes(memory):用物理內存數. 如果Available Mbytes的值很小(4 MB 或更小),則說明計算機上總的內存可能不足,或某程序沒有釋放內存。
Context switch/sec(system): (實例化inetinfo 和dllhost 進程) 如果你決定要增加線程字節池的大小,你應該監視這三個計數器(包括上面的一個)。增加線程數可能會增加上下文切換次數,這樣性能不會上升反而會下降。如果十個實例的上下文切換值非常高,就應該減小線程字節池的大小。
%Disk reads/sec(physicaldisk_total):每秒讀硬盤字節數.
%Disk write/sec(physicaldisk_total):每秒寫硬盤字節數.
Page faults/sec:進程產生的頁故障與系統產生的相比較,以判斷這個進程對系統頁故障產生的影響。
Pages per second:每秒鐘檢索的頁數。該數字應少于每秒一頁Working set:理線程最近使用的內存頁,反映了每一個進程使用的內存頁的數量。如果服務器有足夠的空閑內存,頁就會被留在工作集中,當自由內存少于一個特定的閾值時,頁就會被清除出工作集。
Avg.disk queue length:讀取和寫入請求(為所選磁盤在實例間隔中列隊的)的平均數。該值應不超過磁盤數的1.5~2 倍。要提高性能,可增加磁盤。注意:一個Raid Disk實際有多個磁盤。
Average disk read/write queue length: 指讀取(寫入)請求(列隊)的平均數Disk reads/(writes)/s:理磁盤上每秒鐘磁盤讀、寫的次數。兩者相加,應小于磁盤設備最大容量。
Average disk sec/read:以秒計算的在此盤上讀取數據的所需平均時間。Average disk sec/transfer:指以秒計算的在此盤上寫入數據的所需平均時間。
Bytes total/sec:為發送和接收字節的速率,包括幀字符在內。判斷網絡連接速度是否是瓶頸,可以用該計數器的值和目前網絡的帶寬比較Page read/sec:每秒發出的物理數據庫頁讀取數。這一統計信息顯示的是在所有數據庫間的物理頁讀取總數。由于物理 I/O 的開銷大,可以通過使用更大的數據高速緩存、智能索引、更高效的查詢或者改變數據庫設計等方法,使開銷減到最小。
Page write/sec:(寫的頁/秒)每秒執行的物理數據庫寫的頁數。
內容導航
1. 判斷應用程序的問題
如果系統由于應用程序代碼效率低下或者系統結構設計有缺陷而導致大量的上下文切換(context switches/sec顯示的上下文切換次數太高)那么就會占用大量的系統資源,如果系統的吞吐量降低并且CPU的使用率很高,并且此現象發生時切換水平在15000以上,那么意味著上下文切換次數過高.
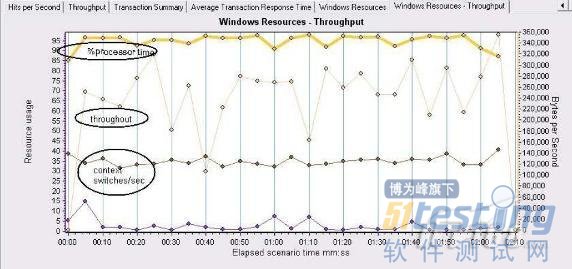
從圖的整體看.context switches/sec變化不大,throughout曲線的斜率較高,并且此時的contextswitches/sec已經超過了15000.程序還是需要進一步優化.
2. 判斷CPU瓶頸
如果processor queue length顯示的隊列長度保持不變(>=2)個并且處理器的利用率%Processortime超過90%,那么很可能存在處理器瓶頸.如果發現processor queue length顯示的隊列長度超過2,而處理器的利用率卻一直很低,或許更應該去解決處理器阻塞問題,這里處理器一般不是瓶頸.
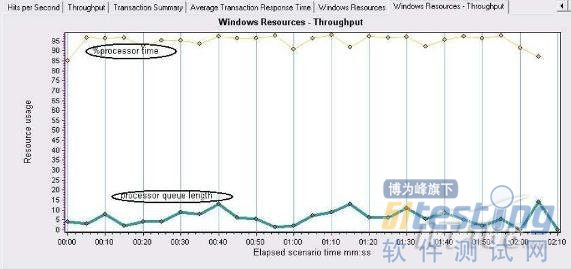
%processor time平均值大于95,processor queue length大于2.可以確定CPU瓶頸.此時的CPU已經不能滿足程序需要.急需擴展.
3. 判斷內存泄露問題
內存問題主要檢查應用程序是否存在內存泄漏,如果發生了內存泄漏,process\private bytes計數器和process\working set 計數器的值往往會升高,同時avaiable bytes的值會降低.內存泄漏應該通過一個長時間的,用來研究分析所有內存都耗盡時,應用程序反應情況的測試來檢驗.
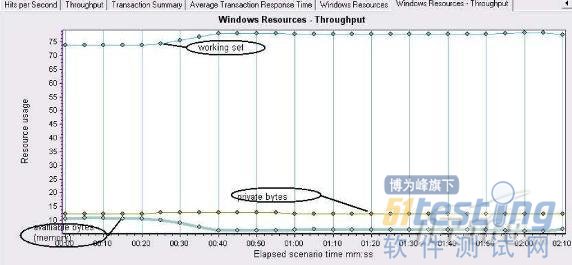
圖中可以看到該程序并不存在內存泄露的問題.內存泄露問題經常出現在服務長時間運轉的時候,由于部分程序對內存沒有釋放,而將內存慢慢耗盡.也是提醒大家對系統穩定性測試的關注.
附件:
CPU信息:
Processor\ % Processor Time 獲得處理器使用情況。
也可以選擇監視 Processor\ % User Time 和 % Privileged Time 以獲得詳細信息。
Server Work Queues\ Queue Length 計數器會顯示出處理器瓶頸。隊列長度持續大于 4 則表示可能出現處理器擁塞。
System\ Processor Queue Length 用于瓶頸檢測通過使用 Process\ % Processor Time 和 Process\ Working Set
Process\ % Processor Time過程的所有線程在每個處理器上的處理器時間總和。
硬盤信息:
Physical Disk\ % Disk Time
Physical Disk\ Avg.Disk Queue Length
例如,包括 Page Reads/sec 和 % Disk Time 及 Avg.Disk Queue Length。如果頁面讀取操作速率很低,同時 % Disk Time 和 Avg.Disk Queue Length的值很高,則可能有磁盤瓶徑。但是,如果隊列長度增加的同時頁面讀取速率并未降低,則內存不足。
Physical Disk\ % Disk Time
Physical Disk\ Avg.Disk Queue Length
例如,包括 Page Reads/sec 和 % Disk Time 及 Avg.Disk Queue Length。如果頁面讀取操作速率很低,同時 % Disk Time 和 Avg.Disk Queue Length的值很高,則可能有磁盤瓶徑。但是,如果隊列長度增加的同時頁面讀取速率并未降低,則內存不足。
請觀察 Processor\ Interrupts/sec 計數器的值,該計數器測量來自輸入/輸出 (I/O) 設備的服務請求的速度。如果此計數器的值明顯增加,而系統活動沒有相應增加,則表明存在硬件問題。
Physical Disk\ Disk Reads/sec and Disk Writes/sec
Physical Disk\ Current Disk Queue Length
Physical Disk\ % Disk Time
LogicalDisk\ % Free Space |
測試磁盤性能時,將性能數據記錄到另一個磁盤或計算機,以便這些數據不會干擾您正在測試的磁盤。
可能需要觀察的附加計數器包括 Physical Disk\ Avg.Disk sec/Transfer 、Avg.DiskBytes/Transfer,和Disk Bytes/sec。
Avg.Disk sec/Transfer 計數器反映磁盤完成請求所用的時間。較高的值表明磁盤控制器由于失敗而不斷重試該磁盤。這些故障會增加平均磁盤傳送時間。對于大多數磁盤,較高的磁盤平均傳送時間是大于 0.3 秒。
也可以查看 Avg.Disk Bytes/Transfer 的值。值大于 20 KB 表示該磁盤驅動器通常運行良好;如果應用程序正在訪問磁盤,則會產生較低的值。例如,隨機訪問磁盤的應用程序會增加平均 Disk sec/Transfer 時間,因為隨機傳送需要增加搜索時間。
Disk Bytes/sec 提供磁盤系統的吞吐率。
決定工作負載的平衡要平衡網絡服務器上的負載,需要了解服務器磁盤驅動器的繁忙程度。使用 Physical Disk\ %Disk Time 計數器,該計數器顯示驅動器活動時間的百分比。如果 % Disk Time 較高(超過90%),請檢查 Physical Disk\ Current Disk Queue Length 計數器以查看正在等待磁盤訪問的系統請求數量。等待 I/O 請求的數量應當保持在不大于組成物理磁盤的主軸數的 1.5 到2倍。
盡管廉價磁盤冗余陣列 (RAID) 設備通常有多個主軸,大多數磁盤有一個主軸。硬件 RAID設備在“系統監視器”中顯示為一個物理磁盤;通過軟件創建的 RAID 設備顯示為多個驅動器(實例)。可以監視每個物理驅動器(而不是 RAID)的 Physical Disk 計數器,也可以使用 _Total 實例來監視所有計算機驅動器的數據。
使用 Current Disk Queue Length 和 % Disk Time 計數器來檢測磁盤子系統的瓶頸。如果Current Disk Queue Length 和 % Disk Time 的值始終較高,可以考慮升級磁盤驅動器或將某些文件移動到其他磁盤或服務器。