Ruby的對象模型,包含在下面這張圖中:

首先要知道,Ruby中的類也是對象,類相比于其他對象特殊的地方在于能夠產生對象,既然類是對象,那么它顯然也有類,也就是所謂類的類,這個類的類在Ruby中就是類的metaclass,圖中的(OtherClass),(OtherClass)就是類OtherClass的klass(C層次),(OtherClass)存儲了類的方法(類方法)和類的實例變量,并且是唯一的且不可實例化。在Ruby層次上我們想操作(otherclass)應該類似:
class OtherClass
end
class<<OtherClass
attr_accessor:name #name是OtherClass的實例變量
def test
p 'hello'
end
end
OtherClass.name='1'
p OtherClass.name
OtherClass.test
圖中的instance是OtherClass的一個實例,那么顯然instance的class是OtherClass,可是圖中的(instance)又是什么呢?(instance)就是對象的singleton類,singleton類這個名稱怪怪的,不過每個對象只能有一個singleton類的角度上說也可以理解。看看下面的例子:
class OtherClass
end
instance=OtherClass.new
class<<instance
def test
p "a.test"
end
attr_accessor:name
end
instance.test
instance.name="dennis"
p instance.name
instance通過OtherClass.new創建,但是此時(instance)還不存在,這與(OtherClass)情況不同,每個類一經創建就有一個metaclass,而對象就不一樣,只有當你通過class<<instance 語法創建的時候,(instance)才被創建。注意test方法和name變量都將是instance對象特有的,類OtherClass并沒有改變。觀察下,發現(instance)繼承于OtherClass,引出類的metaclass與對象的singleton類的又一個區別:類的metaclass繼承自父類的metaclass,而對象的singleton類則是繼承于對象的class。
那么當我們調用instance.class的時候,怎么不返回(instance)?這是c ruby在底層做了處理,instance的class在c ruby層次是(instance),當查找的時候忽略了singleton類以及下面將要談到的include模塊的代理類,沿著繼承鏈上查找:
86 VALUE
87 rb_obj_class(obj)
88 VALUE obj;
89 {
90 return rb_class_real(CLASS_OF(obj));
91 }
76 VALUE
77 rb_class_real(cl)
78 VALUE cl;
79 {
80 while (FL_TEST(cl, FL_SINGLETON) || TYPE(cl) == T_ICLASS) {
81 cl = RCLASS(cl)->super;
82 }
83 return cl;
84 }
(object.c)
核心代碼就是:
while (FL_TEST(cl, FL_SINGLETON) || TYPE(cl) == T_ICLASS) {
cl = RCLASS(cl)->super;
}
其中FL_TEST(cl,FL_SINGLETON)用于測試是否是singleton類,而TYPE(cl)==TL_ICLASS是否是包含模塊的代理類,TL_ICLASS的I就是include的意思。
圖中類OtherClass繼承Object,這個是顯而易見的,不再多說。而Object、Class和Module這三個類是沒辦法通過API創建的,稱為元類,他們的之間的關系如圖所示,Object的class是Class,Module繼承Object,而Class又繼承Module,因此Class.kind_of? Object返回true,這個問題類似先有雞,還是先有蛋的問題,是先有Object?還是先有Class?而c ruby的解決辦法是不管誰先有,創建Object開始,接著創建Module和Class,然后分別創建它們的metaclass,從此整個Ruby的對象模型開始運轉。
1243 rb_cObject = boot_defclass("Object", 0);
1244 rb_cModule = boot_defclass("Module", rb_cObject);
1245 rb_cClass = boot_defclass("Class", rb_cModule);
1246
1247 metaclass = rb_make_metaclass(rb_cObject, rb_cClass);
1248 metaclass = rb_make_metaclass(rb_cModule, metaclass);
1249 metaclass = rb_make_metaclass(rb_cClass, metaclass);
(object.c)
那么當我們調用Class.class發生了什么?Class的klass其實指向的是(Class),可根據上面的代碼,我們知道會忽略這個(Class),繼續往上找就是(Module),同理找到(Object),而(Object)繼承自Class,顯然Class的類仍然是Class,Class的類的類也是Class,多么有趣。同理,Object.class和Module.class都將是Class類。
再來看看include模塊時發生的故事。include模塊的過程如下圖所示:
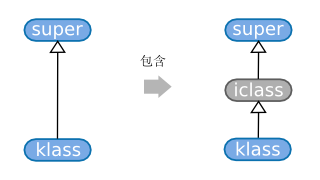
include模塊,本質上是在對象或者類的klass和super之間插入了一個代理類iclass,這個代理類的方法表(m_table)和變量表(iv_table)分別指向了被包含的模塊的方法表和變量表(通過指針,因此當包含的Module變化的時候,對象或者類也能相應變化),那么在查找類或者對象的class的時候,上面已經說明將忽略這些代理類。