
2012年2月24日
https://www.jianshu.com/p/ebf2e5b34aad
posted @
2018-11-18 16:56 Seraphi 閱讀(162) |
評(píng)論 (0) |
編輯 收藏
今天換了Macbook pro來(lái)寫(xiě)畢業(yè)論文,發(fā)現(xiàn)有一大堆中文相關(guān)的問(wèn)題導(dǎo)致編譯錯(cuò)誤。經(jīng)過(guò)一晚上的研究,終于解決。主要有以下要點(diǎn):
1. 由于MacTex對(duì)CTex的支持并不如TexLive那么好,在用pkuthss 1.7.3模板寫(xiě)論文的時(shí)候,首先需要對(duì)pkuthss.cls文件進(jìn)行修改:
需要將原來(lái)的\LoadClass[hyperref, cs4size, fntef, fancyhdr]{ctexbook}[2011/03/11]一行改為如下形式:
\LoadClass[fontset = windowsold,cs4size,UTF8,fancyhdr,hyperref,fntef,openany]{ctexbook}[2011/03/11]
2.在進(jìn)行上述改動(dòng)后,發(fā)現(xiàn)還是不行。提示simhei.ttf, simsong.ttc, simfang.ttf找不到。這個(gè)時(shí)候,需要將上述三種字體超鏈接到tex的目錄下。
具體方法如下:
(1)在tex對(duì)應(yīng)的下列目錄建立Chinese文件夾:/usr/local/texlive/2016/texmf-dist/fonts/truetype/
(2)將SimHei SimSong Fangsong三種字體超鏈接到上述目錄。這三種字體可以在/Library/Fonts/Microsoft中找到,注意的是放到tex下時(shí),文件名需要小寫(xiě),黑體和仿宋后綴名為.ttf,宋體為.ttc
(3)sudo texhash
3.再編譯的時(shí)候發(fā)現(xiàn)已經(jīng)可以了!Yeah~~~
posted @
2017-02-28 22:13 Seraphi 閱讀(532) |
評(píng)論 (0) |
編輯 收藏I have successfully run your code after doing the following two steps:
Download GLPK from
http://sourceforge.net/projects/winglpk/files/latest/download (as mentioned by oyvind)
- Unzip it into (for example) :
C:\glpk_is_here\ Add GLPK binaries to your system path before running python C:\>set PATH=%PATH%;C:\glpk_is_here\glpk-4.55\w64
Using the same cmd window from (3), use python/ipython to run your code:
C:\>ipython your_code.py
See the results Out[4]: 2.0
Good luck.
posted @
2016-05-27 14:25 Seraphi 閱讀(672) |
評(píng)論 (0) |
編輯 收藏原貼:http://www.cnblogs.com/ajunForNet/archive/2012/09/12/2682063.html
組長(zhǎng)說(shuō)在內(nèi)網(wǎng)部署一個(gè)論壇,這可難不倒我,裝個(gè)Discuz嘛。
部署環(huán)境就一臺(tái)普通的PC,四核i3,Windows7。這就開(kāi)搞了。
準(zhǔn)備工作
系統(tǒng)是Windows 7 專(zhuān)業(yè)版,自帶IIS7.5(家庭版不帶)。IIS7開(kāi)始帶了FastCgi,對(duì)PHP支持好了許多,所以也不必裝Apache啦。
下載 PHP 5.4、 MySQL 5.5 以及Discuz X2。
對(duì)于IIS7 FastCgi,我們應(yīng)當(dāng)選擇VC9編譯的線(xiàn)程安全的版本。
安裝PHP
解壓PHP,我給的路徑是C:\PHP,大伙兒隨意
把php.ini-production改名為php.ini(用于開(kāi)發(fā)環(huán)境的話(huà),就改那個(gè)development)
修改擴(kuò)展路徑
extension_dir = "./ext"
啟用MySQL擴(kuò)展(即去掉分號(hào))
extension=php_MySQL.dll
修改時(shí)區(qū)
date.timezone=Asia/Shanghai
完了可以嘗試在命令行中執(zhí)行以下PHP:
cd C:\PHP
php -v
可以看到php的版本信息,如果把dll文件不存在的擴(kuò)展打開(kāi)了的話(huà),會(huì)有提示。
配置IIS
IIS容易對(duì)付,不過(guò)先得把確保這幾項(xiàng)已經(jīng)裝上:

1、添加模塊映射
啟動(dòng)IIS管理器,對(duì)服務(wù)器設(shè)置“處理程序映射”,”添加模塊映射“:
(圖)
注意,設(shè)置可執(zhí)行文件路徑的時(shí)候,要選擇exe。

2、添加index.php為默認(rèn)文檔
對(duì)服務(wù)器設(shè)置“默認(rèn)文檔”,添加index.php
3、創(chuàng)建新站點(diǎn)
接著在創(chuàng)建一個(gè)新的站點(diǎn),并創(chuàng)建一個(gè)目錄存放你的網(wǎng)站,C:\Forum
主機(jī)名填你想要綁定的域名,對(duì)于一臺(tái)服務(wù)器上有多個(gè)網(wǎng)站的情況,域名幾乎是必須的。
當(dāng)然啦,內(nèi)網(wǎng)的話(huà),就改hosts隨便弄個(gè)上去吧。
4、設(shè)置程序池
去應(yīng)用程序池,設(shè)置剛才創(chuàng)建的站點(diǎn)對(duì)應(yīng)的程序池,把.Net framework版本設(shè)成無(wú)托管代碼。
重啟IIS,在網(wǎng)站目錄下放一個(gè)index.php,內(nèi)容很簡(jiǎn)單:
<?php phpinfo(); ?>
訪(fǎng)問(wèn)網(wǎng)站,設(shè)置無(wú)誤的話(huà)應(yīng)該能看到PHP的系統(tǒng)信息。
安裝MySQL
安裝MySQL挺容易的,按照Discuz給出的教程就可以了。
因?yàn)槲蚁碌氖荱TF8版本的Discuz,所以在選擇字符編碼那一步選的UTF8。
至于改數(shù)據(jù)庫(kù)目錄以及移動(dòng)那個(gè)dll,看上去完全沒(méi)那個(gè)必要,我也就沒(méi)弄。
安裝Discuz
最煩的都搞定了,最后把安裝包里upload里面的東西都復(fù)制到網(wǎng)站目錄下,
訪(fǎng)問(wèn)網(wǎng)站下的install目錄就能看到安裝界面
剩下的不用說(shuō)了吧···
得記得安裝完了以后,進(jìn)UCenter->全局->域名設(shè)置->應(yīng)用域名,把論壇的域名給設(shè)好了,
否則論壇首頁(yè)就是個(gè)500
Over.
posted @
2013-03-11 11:09 Seraphi 閱讀(590) |
評(píng)論 (0) |
編輯 收藏
nohup + 命令 + & 后臺(tái)運(yùn)行程序(連接服務(wù)器時(shí),運(yùn)行程序)
posted @
2013-03-06 10:38 Seraphi 閱讀(255) |
評(píng)論 (0) |
編輯 收藏
摘要: LaTeX( LATEX,音譯“拉泰赫”)是一種基于TeX的排版系統(tǒng),由 美國(guó) 計(jì)算機(jī)學(xué)家 萊斯利·蘭伯特(Leslie Lamport)在20世紀(jì)80年代初期開(kāi)發(fā),利用這種格式,即使使用者沒(méi)有排版和程序設(shè)計(jì)的知識(shí)也可以充分發(fā)揮由TeX所提供的強(qiáng)大功能,能在幾天,甚至幾小時(shí)內(nèi)生成很多具有書(shū)籍質(zhì)量的印刷品。 你可以在...
閱讀全文
posted @
2013-02-16 13:51 Seraphi 閱讀(271) |
評(píng)論 (0) |
編輯 收藏Python正則
初學(xué)Python,對(duì)Python的文字處理能力有很深的印象,除了str對(duì)象自帶的一些方法外,就是正則表達(dá)式這個(gè)強(qiáng)大的模塊了。但是對(duì)于初學(xué)者來(lái)說(shuō),要用好這個(gè)功能還是有點(diǎn)難度
,我花了好長(zhǎng)時(shí)間才摸出了點(diǎn)門(mén)道。由于我記性不好,很容易就忘事,所以還是寫(xiě)下來(lái)比較好一些,同時(shí)也可以加深印象,整理思路。
由于我是初學(xué),所以肯定會(huì)有些錯(cuò)誤,還望高手不吝賜教,指出我的錯(cuò)誤。
1 Python正則式的基本用法
Python的正則表達(dá)式的模塊是‘re’,它的基本語(yǔ)法規(guī)則就是指定一個(gè)字符序列,比如你要在一個(gè)字符串s=’123abc456’中查找字符串’abc’,只要這樣寫(xiě):
>>> import re
>>> s='123abc456eabc789'
>>> re.findall(r’abc’,s)
結(jié)果就是:
['abc', 'abc']
這里用到的函數(shù)”findall(rule , target [,flag] )” 是個(gè)比較直觀(guān)的函數(shù),就是在目標(biāo)字符串中查找符合規(guī)則的字符串。第一個(gè)參數(shù)是規(guī)則,第二個(gè)參數(shù)是目標(biāo)字符串,后面
還可以跟一個(gè)規(guī)則選項(xiàng)(選項(xiàng)功能將在compile函數(shù)的說(shuō)明中詳細(xì)說(shuō)明)。返回結(jié)果結(jié)果是一個(gè)列表,中間存放的是符合規(guī)則的字符串。如果沒(méi)有符合規(guī)則的字符串被找到,就返
回一個(gè)空列表。
為什么要用r’ ..‘字符串(raw字符串)?由于正則式的規(guī)則也是由一個(gè)字符串定義的,而在正則式中大量使用轉(zhuǎn)義字符’/’,如果不用raw字符串,則在需要寫(xiě)一個(gè)’/’的地
方,你必須得寫(xiě)成’//’,那么在要從目標(biāo)字符串中匹配一個(gè)’/’的時(shí)候,你就得寫(xiě)上4個(gè)’/’成為’////’!這當(dāng)然很麻煩,也不直觀(guān),所以一般都使用r’’來(lái)定義規(guī)則字符
串。當(dāng)然,某些情況下,可能不用raw字符串比較好。
以上是個(gè)最簡(jiǎn)單的例子。當(dāng)然實(shí)際中這么簡(jiǎn)單的用法幾乎沒(méi)有意義。為了實(shí)現(xiàn)復(fù)雜的規(guī)則查找,re規(guī)定了若干語(yǔ)法規(guī)則。它們分為這么幾類(lèi):
功能字符: ‘.’ ‘*’ ‘+’ ‘|’ ‘?’ ‘^’ ‘$’ ‘/’等,它們有特殊的功能含義。特別是’/’字符,它是轉(zhuǎn)義引導(dǎo)符號(hào),跟在它后面的字符一般有特殊的含義。
規(guī)則分界符: ‘[‘ ‘]’ ‘(’ ‘)’ ‘{‘ ‘}’等,也就是幾種括號(hào)了。
預(yù)定義轉(zhuǎn)義字符集:“/d” “/w” “/s” 等等,它們是以字符’/’開(kāi)頭,后面接一個(gè)特定字符的形式,用來(lái)指示一個(gè)預(yù)定義好的含義。
其它特殊功能字符:’#’ ‘!’ ‘:’ ‘-‘等,它們只在特定的情況下表示特殊的含義,比如(?# …)就表示一個(gè)注釋?zhuān)锩娴膬?nèi)容會(huì)被忽略。
下面來(lái)一個(gè)一個(gè)的說(shuō)明這些規(guī)則的含義,不過(guò)說(shuō)明的順序并不是按照上面的順序來(lái)的,而是我認(rèn)為由淺入深,由基本到復(fù)雜的順序來(lái)編排的。同時(shí)為了直觀(guān),在說(shuō)明的過(guò)程中盡量
多舉些例子以方便理解。
1.1基本規(guī)則
‘[‘ ‘]’字符集合設(shè)定符
首先說(shuō)明一下字符集合設(shè)定的方法。由一對(duì)方括號(hào)括起來(lái)的字符,表明一個(gè)字符集合,能夠匹配包含在其中的任意一個(gè)字符。比如[abc123],表明字符’a’ ‘b’ ‘c’ ‘1’
‘2’ ‘3’都符合它的要求。可以被匹配。
在’[‘ ‘]’中還可以通過(guò)’-‘ 減號(hào)來(lái)指定一個(gè)字符集合的范圍,比如可以用[a-zA-Z]來(lái)指定所以英文字母的大小寫(xiě),因?yàn)橛⑽淖帜甘前凑諒男〉酱蟮捻樞騺?lái)排的。你不可以
把大小的順序顛倒了,比如寫(xiě)成[z-a]就不對(duì)了。
如果在’[‘ ‘]’里面的開(kāi)頭寫(xiě)一個(gè)‘^’ 號(hào),則表示取非,即在括號(hào)里的字符都不匹配。如[^a-zA-Z]表明不匹配所有英文字母。但是如果‘^’不在開(kāi)頭,則它就不再是表示
取非,而表示其本身,如[a-z^A-Z]表明匹配所有的英文字母和字符’^’。
‘|’ 或規(guī)則
將兩個(gè)規(guī)則并列起來(lái),以‘|’連接,表示只要滿(mǎn)足其中之一就可以匹配。比如
[a-zA-Z]|[0-9]表示滿(mǎn)足數(shù)字或字母就可以匹配,這個(gè)規(guī)則等價(jià)于[a-zA-Z0-9]
注意:關(guān)于’|’要注意兩點(diǎn):
第一, 它在’[‘ ‘]’之中不再表示或,而表示他本身的字符。如果要在’[‘ ‘]’外面表示一個(gè)’|’字符,必須用反斜杠引導(dǎo),即’/|’ ;
第二, 它的有效范圍是它兩邊的整條規(guī)則,比如‘dog|cat’匹配的是‘dog’和’cat’,而不是’g’和’c’。如果想限定它的有效范圍,必需使用一個(gè)無(wú)捕獲組‘
(?: )’包起來(lái)。比如要匹配‘I have a dog’或’I have a cat’,需要寫(xiě)成r’I have a (?:dog|cat)’,而不能寫(xiě)成r’I have a dog|cat’
例
>>> s = ‘I have a dog , I have a cat’
>>> re.findall( r’I have a (?:dog|cat)’ , s )
['I have a dog', 'I have a cat'] #正如我們所要的
下面再看看不用無(wú)捕獲組會(huì)是什么后果:
>>> re.findall( r’I have a dog|cat’ , s )
['I have a dog', 'cat'] #它將’I have a dog’和’cat’當(dāng)成兩個(gè)規(guī)則了
至于無(wú)捕獲組的使用,后面將仔細(xì)說(shuō)明。這里先跳過(guò)。
‘.’ 匹配所有字符
匹配除換行符’/n’外的所有字符。如果使用了’S’選項(xiàng),匹配包括’/n’的所有字符。
例:
>>> s=’123 /n456 /n789’
>>> findall(r‘.+’,s)
['123', '456', '789']
>>> re.findall(r‘.+’ , s , re.S)
['123/n456/n789']
‘^’和’$’匹配字符串開(kāi)頭和結(jié)尾
注意’^’不能在‘[ ]’中,否則含意就發(fā)生變化,具體請(qǐng)看上面的’[‘ ‘]’說(shuō)明。在多行模式下,它們可以匹配每一行的行首和行尾。具體請(qǐng)看后面compile函數(shù)說(shuō)明的’M
’選項(xiàng)部分
‘/d’匹配數(shù)字
這是一個(gè)以’/’開(kāi)頭的轉(zhuǎn)義字符,’/d’表示匹配一個(gè)數(shù)字,即等價(jià)于[0-9]
‘/D’匹配非數(shù)字
這個(gè)是上面的反集,即匹配一個(gè)非數(shù)字的字符,等價(jià)于[^0-9]。注意它們的大小寫(xiě)。下面我們還將看到Python的正則規(guī)則中很多轉(zhuǎn)義字符的大小寫(xiě)形式,代表互補(bǔ)的關(guān)系。這樣很
好記。
‘/w’匹配字母和數(shù)字
匹配所有的英文字母和數(shù)字,即等價(jià)于[a-zA-Z0-9]。
‘/W’匹配非英文字母和數(shù)字
即’/w’的補(bǔ)集,等價(jià)于[^a-zA-Z0-9]。
‘/s’匹配間隔符
即匹配空格符、制表符、回車(chē)符等表示分隔意義的字符,它等價(jià)于[ /t/r/n/f/v]。(注意最前面有個(gè)空格)
‘/S’匹配非間隔符
即間隔符的補(bǔ)集,等價(jià)于[^ /t/r/n/f/v]
‘/A’匹配字符串開(kāi)頭
匹配字符串的開(kāi)頭。它和’^’的區(qū)別是,’/A’只匹配整個(gè)字符串的開(kāi)頭,即使在’M’模式下,它也不會(huì)匹配其它行的很首。
‘/Z’匹配字符串結(jié)尾
匹配字符串的結(jié)尾。它和’$’的區(qū)別是,’/Z’只匹配整個(gè)字符串的結(jié)尾,即使在’M’模式下,它也不會(huì)匹配其它各行的行尾。
例:
>>> s= '12 34/n56 78/n90'
>>> re.findall( r'^/d+' , s , re.M ) #匹配位于行首的數(shù)字
['12', '56', '90']
>>> re.findall( r’/A/d+’, s , re.M ) #匹配位于字符串開(kāi)頭的數(shù)字
['12']
>>> re.findall( r'/d+$' , s , re.M ) #匹配位于行尾的數(shù)字
['34', '78', '90']
>>> re.findall( r’/d+/Z’ , s , re.M ) #匹配位于字符串尾的數(shù)字
['90']
‘/b’匹配單詞邊界
它匹配一個(gè)單詞的邊界,比如空格等,不過(guò)它是一個(gè)‘0’長(zhǎng)度字符,它匹配完的字符串不會(huì)包括那個(gè)分界的字符。而如果用’/s’來(lái)匹配的話(huà),則匹配出的字符串中會(huì)包含那個(gè)
分界符。
例:
>>> s = 'abc abcde bc bcd'
>>> re.findall( r’/bbc/b’ , s ) #匹配一個(gè)單獨(dú)的單詞‘bc’ ,而當(dāng)它是其它單詞的一部分的時(shí)候不匹配
['bc'] #只找到了那個(gè)單獨(dú)的’bc’
>>> re.findall( r’/sbc/s’ , s ) #匹配一個(gè)單獨(dú)的單詞‘bc’
[' bc '] #只找到那個(gè)單獨(dú)的’bc’,不過(guò)注意前后有兩個(gè)空格,可能有點(diǎn)看不清楚
‘/B’匹配非邊界
和’/b’相反,它只匹配非邊界的字符。它同樣是個(gè)0長(zhǎng)度字符。
接上例:
>>> re.findall( r’/Bbc/w+’ , s ) #匹配包含’bc’但不以’bc’為開(kāi)頭的單詞
['bcde'] #成功匹配了’abcde’中的’bcde’,而沒(méi)有匹配’bcd’
‘(?:)’無(wú)捕獲組
當(dāng)你要將一部分規(guī)則作為一個(gè)整體對(duì)它進(jìn)行某些操作,比如指定其重復(fù)次數(shù)時(shí),你需要將這部分規(guī)則用’(?:’ ‘)’把它包圍起來(lái),而不能僅僅只用一對(duì)括號(hào),那樣將得到絕對(duì)
出人意料的結(jié)果。
例:匹配字符串中重復(fù)的’ab’
>>> s=’ababab abbabb aabaab’
>>> re.findall( r’/b(?:ab)+/b’ , s )
['ababab']
如果僅使用一對(duì)括號(hào),看看會(huì)是什么結(jié)果:
>>> re.findall( r’/b(ab)+/b’ , s )
['ab']
這是因?yàn)槿绻皇褂靡粚?duì)括號(hào),那么這就成為了一個(gè)組(group)。組的使用比較復(fù)雜,將在后面詳細(xì)講解。
‘(?# )’注釋
Python允許你在正則表達(dá)式中寫(xiě)入注釋?zhuān)?#8217;(?#’ ‘)’之間的內(nèi)容將被忽略。
(?iLmsux) 編譯選項(xiàng)指定
Python的正則式可以指定一些選項(xiàng),這個(gè)選項(xiàng)可以寫(xiě)在findall或compile的參數(shù)中,也可以寫(xiě)在正則式里,成為正則式的一部分。這在某些情況下會(huì)便利一些。具體的選項(xiàng)含義請(qǐng)
看后面的compile函數(shù)的說(shuō)明。
此處編譯選項(xiàng)’i’等價(jià)于IGNORECASE ,L 等價(jià)于 LOCAL ,m 等價(jià)于 MULTILINE,s等價(jià)于 DOTALL ,u等價(jià)于UNICODE , x 等價(jià)于 VERBOSE。
請(qǐng)注意它們的大小寫(xiě)。在使用時(shí)可以只指定一部分,比如只指定忽略大小寫(xiě),可寫(xiě)為‘(?i)’,要同時(shí)忽略大小寫(xiě)并使用多行模式,可以寫(xiě)為‘(?im)’。
另外要注意選項(xiàng)的有效范圍是整條規(guī)則,即寫(xiě)在規(guī)則的任何地方,選項(xiàng)都會(huì)對(duì)全部整條正則式有效。
1.2重復(fù)
正則式需要匹配不定長(zhǎng)的字符串,那就一定需要表示重復(fù)的指示符。Python的正則式表示重復(fù)的功能很豐富靈活。重復(fù)規(guī)則的一般的形式是在一條字符規(guī)則后面緊跟一個(gè)表示重復(fù)
次數(shù)的規(guī)則,已表明需要重復(fù)前面的規(guī)則一定的次數(shù)。重復(fù)規(guī)則有:
‘*’ 0或多次匹配
表示匹配前面的規(guī)則0次或多次。
‘+’ 1次或多次匹配
表示匹配前面的規(guī)則至少1次,可以多次匹配
例:匹配以下字符串中的前一部分是字母,后一部分是數(shù)字或沒(méi)有的變量名字
>>> s = ‘ aaa bbb111 cc22cc 33dd ‘
>>> re.findall( r’/b[a-z]+/d*/b’ , s ) #必須至少1個(gè)字母開(kāi)頭,以連續(xù)數(shù)字結(jié)尾或沒(méi)有數(shù)字
['aaa', 'bbb111']
注意上例中規(guī)則前后加了表示單詞邊界的’/b’指示符,如果不加的話(huà)結(jié)果就會(huì)變成:
>>> re.findall( r’[a-z]+/d*’ , s )
['aaa', 'bbb111', 'cc22', 'cc', 'dd'] #把單詞給拆開(kāi)了
大多數(shù)情況下這不是我們期望的結(jié)果。
‘?’ 0或1次匹配
只匹配前面的規(guī)則0次或1次。
例,匹配一個(gè)數(shù)字,這個(gè)數(shù)字可以是一個(gè)整數(shù),也可以是一個(gè)科學(xué)計(jì)數(shù)法記錄的數(shù)字,比如123和10e3都是正確的數(shù)字。
>>> s = ‘ 123 10e3 20e4e4 30ee5 ‘
>>> re.findall( r’ /b/d+[eE]?/d*/b’ , s )
['123', '10e3']
它正確匹配了123和10e3,正是我們期望的。注意前后的’/b’的使用,否則將得到不期望的結(jié)果。
1.2.1 精確匹配和最小匹配
Python正則式還可以精確指定匹配的次數(shù)。指定的方式是
‘{m}’ 精確匹配m次
‘{m,n}’ 匹配最少m次,最多n次。(n>m)
如果你只想指定一個(gè)最少次數(shù)或只指定一個(gè)最多次數(shù),你可以把另外一個(gè)參數(shù)空起來(lái)。比如你想指定最少3次,可以寫(xiě)成{3,}(注意那個(gè)逗號(hào)),同樣如果只想指定最大為5次,可
以寫(xiě)成{,5},也可以寫(xiě)成{0,5}。
例尋找下面字符串中
a:3位數(shù)
b: 2位數(shù)到4位數(shù)
c: 5位數(shù)以上的數(shù)
d: 4位數(shù)以下的數(shù)
>>> s= ‘ 1 22 333 4444 55555 666666 ‘
>>> re.findall( r’/b/d{3}/b’ , s ) # a:3位數(shù)
['333']
>>> re.findall( r’/b/d{2,4}/b’ , s ) # b: 2位數(shù)到4位數(shù)
['22', '333', '4444']
>>> re.findall( r’/b/d{5,}/b’, s ) # c: 5位數(shù)以上的數(shù)
['55555', '666666']
>>> re.findall( r’/b/d{1,4}/b’ , s ) # 4位數(shù)以下的數(shù)
['1', '22', '333', '4444']
‘*?’ ‘+?’ ‘??’最小匹配
‘*’ ‘+’ ‘?’通常都是盡可能多的匹配字符。有時(shí)候我們希望它盡可能少的匹配。比如一個(gè)c語(yǔ)言的注釋‘/* part 1 */ /* part 2 */’,如果使用最大規(guī)則:
>>> s =r ‘/* part 1 */ code /* part 2 */’
>>> re.findall( r’//*.*/*/’ , s )
[‘/* part 1 */ code /* part 2 */’]
結(jié)果把整個(gè)字符串都包括進(jìn)去了。如果把規(guī)則改寫(xiě)成
>>> re.findall( r’//*.*?/*/’ , s ) #在*后面加上?,表示盡可能少的匹配
['/* part 1 */', '/* part 2 */']
結(jié)果正確的匹配出了注釋里的內(nèi)容
1.3 前向界定與后向界定
有時(shí)候需要匹配一個(gè)跟在特定內(nèi)容后面的或者在特定內(nèi)容前面的字符串,Python提供一個(gè)簡(jiǎn)便的前向界定和后向界定功能,或者叫前導(dǎo)指定和跟從指定功能。它們是:
‘(?<=…)’前向界定
括號(hào)中’…’代表你希望匹配的字符串的前面應(yīng)該出現(xiàn)的字符串。
‘(?=…)’ 后向界定
括號(hào)中的’…’代表你希望匹配的字符串后面應(yīng)該出現(xiàn)的字符串。
例:你希望找出c語(yǔ)言的注釋中的內(nèi)容,它們是包含在’/*’和’*/’之間,不過(guò)你并不希望匹配的結(jié)果把’/*’和’*/’也包括進(jìn)來(lái),那么你可以這樣用:
>>> s=r’/* comment 1 */ code /* comment 2 */’
>>> re.findall( r’(?<=//*).+?(?=/*/)’ , s )
[' comment 1 ', ' comment 2 ']
注意這里我們?nèi)匀皇褂昧俗钚∑ヅ洌员苊獍颜麄€(gè)字符串給匹配進(jìn)去了。
要注意的是,前向界定括號(hào)中的表達(dá)式必須是常值,也即你不可以在前向界定的括號(hào)里寫(xiě)正則式。比如你如果在下面的字符串中想找到被字母夾在中間的數(shù)字,你不可以用前向界
定:
例:
>>> s = ‘aaa111aaa , bbb222 , 333ccc ‘
>>> re.findall( r’(?<=[a-z]+)/d+(?=[a-z]+)' , s ) #錯(cuò)誤的用法
它會(huì)給出一個(gè)錯(cuò)誤信息:
error: look-behind requires fixed-width pattern
不過(guò)如果你只要找出后面接著有字母的數(shù)字,你可以在后向界定寫(xiě)正則式:
>>> re.findall( r’/d+(?=[a-z]+)’, s )
['111', '333']
如果你一定要匹配包夾在字母中間的數(shù)字,你可以使用組(group)的方式
>>> re.findall (r'[a-z]+(/d+)[a-z]+' , s )
['111']
組的使用將在后面詳細(xì)講解。
除了前向界定前向界定和后向界定外,還有前向非界定和后向非界定,它的寫(xiě)法為:
‘(?<!...)’前向非界定
只有當(dāng)你希望的字符串前面不是’…’的內(nèi)容時(shí)才匹配
‘(?!...)’后向非界定
只有當(dāng)你希望的字符串后面不跟著’…’內(nèi)容時(shí)才匹配。
接上例,希望匹配后面不跟著字母的數(shù)字
>>> re.findall( r’/d+(?!/w+)’ , s )
['222']
注意這里我們使用了/w而不是像上面那樣用[a-z],因?yàn)槿绻@樣寫(xiě)的話(huà),結(jié)果會(huì)是:
>>> re.findall( r’/d+(?![a-z]+)’ , s )
['11', '222', '33']
這和我們期望的似乎有點(diǎn)不一樣。它的原因,是因?yàn)?#8217;111’和’222’中的前兩個(gè)數(shù)字也是滿(mǎn)足這個(gè)要求的。因此可看出,正則式的使用還是要相當(dāng)小心的,因?yàn)槲议_(kāi)始就是這樣
寫(xiě)的,看到結(jié)果后才明白過(guò)來(lái)。不過(guò)Python試驗(yàn)起來(lái)很方便,這也是腳本語(yǔ)言的一大優(yōu)點(diǎn),可以一步一步的試驗(yàn),快速得到結(jié)果,而不用經(jīng)過(guò)煩瑣的編譯、鏈接過(guò)程。也因此學(xué)習(xí)
Python就要多試,跌跌撞撞的走過(guò)來(lái),雖然曲折,卻也很有樂(lè)趣。
1.4組的基本知識(shí)
上面我們已經(jīng)看過(guò)了Python的正則式的很多基本用法。不過(guò)如果僅僅是上面那些規(guī)則的話(huà),還是有很多情況下會(huì)非常麻煩,比如上面在講前向界定和后向界定時(shí),取夾在字母中間
的數(shù)字的例子。用前面講過(guò)的規(guī)則都很難達(dá)到目的,但是用了組以后就很簡(jiǎn)單了。
‘(‘’)’ 無(wú)命名組
最基本的組是由一對(duì)圓括號(hào)括起來(lái)的正則式。比如上面匹配包夾在字母中間的數(shù)字的例子中使用的(/d+),我們?cè)倩仡櫼幌逻@個(gè)例子:
>>> s = ‘aaa111aaa , bbb222 , 333ccc ‘
>>> re.findall (r'[a-z]+(/d+)[a-z]+' , s )
['111']
可以看到findall函數(shù)只返回了包含在’()’中的內(nèi)容,而雖然前面和后面的內(nèi)容都匹配成功了,卻并不包含在結(jié)果中。
除了最基本的形式外,我們還可以給組起個(gè)名字,它的形式是
‘(?P<name>…)’命名組
‘(?P’代表這是一個(gè)Python的語(yǔ)法擴(kuò)展’<…>’里面是你給這個(gè)組起的名字,比如你可以給一個(gè)全部由數(shù)字組成的組叫做’num’,它的形式就是’(?P<num>/d+)’。起了名字之
后,我們就可以在后面的正則式中通過(guò)名字調(diào)用這個(gè)組,它的形式是
‘(?P=name)’調(diào)用已匹配的命名組
要注意,再次調(diào)用的這個(gè)組是已被匹配的組,也就是說(shuō)它里面的內(nèi)容是和前面命名組里的內(nèi)容是一樣的。
我們可以看更多的例子:請(qǐng)注意下面這個(gè)字符串各子串的特點(diǎn)。
>>> s='aaa111aaa,bbb222,333ccc,444ddd444,555eee666,fff777ggg'
我們看看下面的正則式會(huì)返回什么樣的結(jié)果:
>>> re.findall( r'([a-z]+)/d+([a-z]+)' , s ) #找出中間夾有數(shù)字的字母
[('aaa', 'aaa'), ('fff', 'ggg')]
>>> re.findall( r '(?P<g1>[a-z]+)/d+(?P=g1)' , s ) #找出被中間夾有數(shù)字的前后同樣的字母
['aaa']
>>> re.findall( r'[a-z]+(/d+)([a-z]+)' , s ) #找出前面有字母引導(dǎo),中間是數(shù)字,后面是字母的字符串中的中間的數(shù)字和后面的字母
[('111', 'aaa'), ('777', 'ggg')]
我們可以通過(guò)命名組的名字在后面調(diào)用已匹配的命名組,不過(guò)名字也不是必需的。
‘/number’ 通過(guò)序號(hào)調(diào)用已匹配的組
正則式中的每個(gè)組都有一個(gè)序號(hào),序號(hào)是按組從左到右,從1開(kāi)始的數(shù)字,你可以通過(guò)下面的形式來(lái)調(diào)用已匹配的組
比如上面找出被中間夾有數(shù)字的前后同樣的字母的例子,也可以寫(xiě)成:
>>> re.findall( r’([a-z]+)/d+/1’ , s )
['aaa']
結(jié)果是一樣的。
我們?cè)倏匆粋€(gè)例子
>>> s='111aaa222aaa111 , 333bbb444bb33'
>>> re.findall( r'(/d+)([a-z]+)(/d+)(/2)(/1)' , s ) #找出完全對(duì)稱(chēng)的數(shù)字-字母-數(shù)字-字母-數(shù)字中的數(shù)字和字母
[('111', 'aaa', '222', 'aaa', '111')]
Python2.4以后的re模塊,還加入了一個(gè)新的條件匹配功能
‘(?(id/name)yes-pattern|no-pattern)’ 判斷指定組是否已匹配,執(zhí)行相應(yīng)的規(guī)則
這個(gè)規(guī)則的含義是,如果id/name指定的組在前面匹配成功了,則執(zhí)行yes-pattern的正則式,否則執(zhí)行no-pattern的正則式。
舉個(gè)例子,比如要匹配一些形如usr@mail的郵箱地址,不過(guò)有的寫(xiě)成< usr@mail >即用一對(duì)<>括起來(lái),有點(diǎn)則沒(méi)有,要匹配這兩種情況,可以這樣寫(xiě)
>>> s='<usr1@mail1> usr2@maill2'
>>> re.findall( r'(<)?/s*(/w+@/w+)/s*(?(1)>)' , s )
[('<', 'usr1@mail1'), ('', 'usr2@maill2')]
不過(guò)如果目標(biāo)字符串如下
>>> s='<usr1@mail1> usr2@maill2 <usr3@mail3 usr4@mail4> < usr5@mail5 '
而你想得到要么由一對(duì)<>包圍起來(lái)的一個(gè)郵件地址,要么得到一個(gè)沒(méi)有被<>包圍起來(lái)的地址,但不想得到一對(duì)<>中間包圍的多個(gè)地址或不完整的<>中的地址,那么使用這個(gè)式子并
不能得到你想要的結(jié)果
>>> re.findall( r'(<)?/s*(/w+@/w+)/s*(?(1)>)' , s )
[('<', 'usr1@mail1'), ('', 'usr2@maill2'), ('', 'usr3@mail3'), ('', 'usr4@mail4'), ('', 'usr5@mail5')]
它仍然找到了所有的郵件地址。
想要實(shí)現(xiàn)這個(gè)功能,單純的使用findall有點(diǎn)吃力,需要使用其它的一些函數(shù),比如match或search函數(shù),再配合一些控制功能。這部分的內(nèi)容將在下面詳細(xì)講解。
小結(jié):以上基本上講述了Python正則式的語(yǔ)法規(guī)則。雖然大部分語(yǔ)法規(guī)則看上去都很簡(jiǎn)單,可是稍不注意,仍然會(huì)得到與期望大相徑庭的結(jié)果,所以要寫(xiě)好正則式,需要仔細(xì)的體
會(huì)正則式規(guī)則的含義后不同規(guī)則之間細(xì)微的差別。
詳細(xì)的了解了規(guī)則后,再配合后面就要介紹的功能函數(shù),就能最大的發(fā)揮正則式的威力了。
2 re模塊的基本函數(shù)
在上面的說(shuō)明中,我們已經(jīng)對(duì)re模塊的基本函數(shù)‘findall’很熟悉了。當(dāng)然如果光有findall的話(huà),很多功能是不能實(shí)現(xiàn)的。下面開(kāi)始介紹一下re模塊其它的常用基本函數(shù)。靈活
搭配使用這些函數(shù),才能充分發(fā)揮Python正則式的強(qiáng)大功能。
首先還是說(shuō)下老熟人findall函數(shù)吧
findall(rule , target [,flag] )
在目標(biāo)字符串中查找符合規(guī)則的字符串。
第一個(gè)參數(shù)是規(guī)則,第二個(gè)參數(shù)是目標(biāo)字符串,后面還可以跟一個(gè)規(guī)則選項(xiàng)(選項(xiàng)功能將在compile函數(shù)的說(shuō)明中詳細(xì)說(shuō)明)。
返回結(jié)果結(jié)果是一個(gè)列表,中間存放的是符合規(guī)則的字符串。如果沒(méi)有符合規(guī)則的字符串被找到,就返回一個(gè)空列表。
2.1使用compile加速
compile( rule [,flag] )
將正則規(guī)則編譯成一個(gè)Pattern對(duì)象,以供接下來(lái)使用。
第一個(gè)參數(shù)是規(guī)則式,第二個(gè)參數(shù)是規(guī)則選項(xiàng)。
返回一個(gè)Pattern對(duì)象
直接使用findall ( rule , target )的方式來(lái)匹配字符串,一次兩次沒(méi)什么,如果是多次使用的話(huà),由于正則引擎每次都要把規(guī)則解釋一遍,而規(guī)則的解釋又是相當(dāng)費(fèi)時(shí)間的,
所以這樣的效率就很低了。如果要多次使用同一規(guī)則來(lái)進(jìn)行匹配的話(huà),可以使用re.compile函數(shù)來(lái)將規(guī)則預(yù)編譯,使用編譯過(guò)返回的Regular Expression Object或叫做Pattern對(duì)
象來(lái)進(jìn)行查找。
例
>>> s='111,222,aaa,bbb,ccc333,444ddd'
>>> rule=r’/b/d+/b’
>>> compiled_rule=re.compile(rule)
>>> compiled_rule.findall(s)
['111', '222']
可見(jiàn)使用compile過(guò)的規(guī)則使用和未編譯的使用很相似。compile函數(shù)還可以指定一些規(guī)則標(biāo)志,來(lái)指定一些特殊選項(xiàng)。多個(gè)選項(xiàng)之間用’|’(位或)連接起來(lái)。
I IGNORECASE 忽略大小寫(xiě)區(qū)別。
L LOCAL 字符集本地化。這個(gè)功能是為了支持多語(yǔ)言版本的字符集使用環(huán)境的,比如在轉(zhuǎn)義符/w,在英文環(huán)境下,它代表[a-zA-Z0-9],即所以英文字符和數(shù)字。如果在一個(gè)法
語(yǔ)環(huán)境下使用,缺省設(shè)置下,不能匹配"é"或"ç"。加上這L選項(xiàng)和就可以匹配了。不過(guò)這個(gè)對(duì)于中文環(huán)境似乎沒(méi)有什么用,它仍然不能匹配中文字符。
M MULTILINE 多行匹配。在這個(gè)模式下’^’(代表字符串開(kāi)頭)和’$’(代表字符串結(jié)尾)將能夠匹配多行的情況,成為行首和行尾標(biāo)記。比如
>>> s=’123 456/n789 012/n345 678’
>>> rc=re.compile(r’^/d+’) #匹配一個(gè)位于開(kāi)頭的數(shù)字,沒(méi)有使用M選項(xiàng)
>>> rc.findall(s)
['123'] #結(jié)果只能找到位于第一個(gè)行首的’123’
>>> rcm=re.compile(r’^/d+’,re.M) #使用M選項(xiàng)
>>> rcm.findall(s)
['123', '789', '345'] #找到了三個(gè)行首的數(shù)字
同樣,對(duì)于’$’來(lái)說(shuō),沒(méi)有使用M選項(xiàng),它將匹配最后一個(gè)行尾的數(shù)字,即’678’,加上以后,就能匹配三個(gè)行尾的數(shù)字456 012和678了.
>>> rc=re.compile(r’/d+$’)
>>> rcm=re.compile(r’/d+$’,re.M)
>>> rc.findall(s)
['678']
>>> rcm.findall(s)
['456', '012', '678']
S DOTALL ‘.’號(hào)將匹配所有的字符。缺省情況下’.’匹配除換行符’/n’外的所有字符,使用這一選項(xiàng)以后,’.’就能匹配包括’/n’的任何字符了。
U UNICODE /w,/W,/b,/B,/d,/D,/s和/S都將使用Unicode。
X VERBOSE 這個(gè)選項(xiàng)忽略規(guī)則表達(dá)式中的空白,并允許使用’#’來(lái)引導(dǎo)一個(gè)注釋。這樣可以讓你把規(guī)則寫(xiě)得更美觀(guān)些。比如你可以把規(guī)則
>>> rc = re.compile(r"/d+|[a-zA-Z]+") #匹配一個(gè)數(shù)字或者單詞
使用X選項(xiàng)寫(xiě)成:
>>> rc = re.compile(r""" # start a rule/d+ # number| [a-zA-Z]+ # word""", re.VERBOSE)在這個(gè)模式下,如果你想匹配一個(gè)空格,你必須
用'/ '的形式('/'后面跟一個(gè)空格)
2.2 match與search
match( rule , targetString [,flag] )
search( rule , targetString [,flag] )
(注:re的match與search函數(shù)同compile過(guò)的Pattern對(duì)象的match與search函數(shù)的參數(shù)是不一樣的。Pattern對(duì)象的match與search函數(shù)更為強(qiáng)大,是真正最常用的函數(shù))
按照規(guī)則在目標(biāo)字符串中進(jìn)行匹配。
第一個(gè)參數(shù)是正則規(guī)則,第二個(gè)是目標(biāo)字符串,第三個(gè)是選項(xiàng)(同compile函數(shù)的選項(xiàng))
返回:若成功返回一個(gè)Match對(duì)象,失敗無(wú)返回
findall雖然很直觀(guān),但是在進(jìn)行更復(fù)雜的操作時(shí),就有些力不從心了。此時(shí)更多的使用的是match和search函數(shù)。他們的參數(shù)和findall是一樣的,都是:
match( rule , targetString [,flag] )
search( rule , targetString [,flag] )
不過(guò)它們的返回不是一個(gè)簡(jiǎn)單的字符串列表,而是一個(gè)MatchObject(如果匹配成功的話(huà)).。通過(guò)操作這個(gè)matchObject,我們可以得到更多的信息。
需要注意的是,如果匹配不成功,它們則返回一個(gè)NoneType。所以在對(duì)匹配完的結(jié)果進(jìn)行操作之前,你必需先判斷一下是否匹配成功了,比如:
>>> m=re.match( rule , target )
>>> if m: #必需先判斷是否成功
doSomethin
這兩個(gè)函數(shù)唯一的區(qū)別是:match從字符串的開(kāi)頭開(kāi)始匹配,如果開(kāi)頭位置沒(méi)有匹配成功,就算失敗了;而search會(huì)跳過(guò)開(kāi)頭,繼續(xù)向后尋找是否有匹配的字符串。針對(duì)不同的需
要,可以靈活使用這兩個(gè)函數(shù)。
關(guān)于match返回的MatchObject如果使用的問(wèn)題,是Python正則式的精髓所在,它與組的使用密切相關(guān)。我將在下一部分詳細(xì)講解,這里只舉個(gè)最簡(jiǎn)單的例子:
例:
>>> s= 'Tom:9527 , Sharry:0003'
>>> m=re.match( r'(?P<name>/w+):(?P<num>/d+)' , s )
>>> m.group()
'Tom:9527'
>>> m.groups()
('Tom', '9527')
>>> m.group(‘name’)
'Tom'
>>> m.group(‘num’)
'9527'
2.3 finditer
finditer( rule , target [,flag] )
參數(shù)同findall
返回一個(gè)迭代器
finditer函數(shù)和findall函數(shù)的區(qū)別是,findall返回所有匹配的字符串,并存為一個(gè)列表,而finditer則并不直接返回這些字符串,而是返回一個(gè)迭代器。關(guān)于迭代器,解釋起來(lái)
有點(diǎn)復(fù)雜,還是看看例子把:
>>> s=’111 222 333 444’
>>> for i in re.finditer(r’/d+’ , s ):
print i.group(),i.span() #打印每次得到的字符串和起始結(jié)束位置
結(jié)果是
111 (0, 3)
222 (4, 7)
333 (8, 11)
444 (12, 15)
簡(jiǎn)單的說(shuō)吧,就是finditer返回了一個(gè)可調(diào)用的對(duì)象,使用for i in finditer()的形式,可以一個(gè)一個(gè)的得到匹配返回的Match對(duì)象。這在對(duì)每次返回的對(duì)象進(jìn)行比較復(fù)雜的操作
時(shí)比較有用。
2.4字符串的替換和修改
re模塊還提供了對(duì)字符串的替換和修改函數(shù),他們比字符串對(duì)象提供的函數(shù)功能要強(qiáng)大一些。這幾個(gè)函數(shù)是
sub ( rule , replace , target [,count] )
subn(rule , replace , target [,count] )
在目標(biāo)字符串中規(guī)格規(guī)則查找匹配的字符串,再把它們替換成指定的字符串。你可以指定一個(gè)最多替換次數(shù),否則將替換所有的匹配到的字符串。
第一個(gè)參數(shù)是正則規(guī)則,第二個(gè)參數(shù)是指定的用來(lái)替換的字符串,第三個(gè)參數(shù)是目標(biāo)字符串,第四個(gè)參數(shù)是最多替換次數(shù)。
這兩個(gè)函數(shù)的唯一區(qū)別是返回值。
sub返回一個(gè)被替換的字符串
sub返回一個(gè)元組,第一個(gè)元素是被替換的字符串,第二個(gè)元素是一個(gè)數(shù)字,表明產(chǎn)生了多少次替換。
例,將下面字符串中的’dog’全部替換成’cat’
>>> s=’ I have a dog , you have a dog , he have a dog ‘
>>> re.sub( r’dog’ , ‘cat’ , s )
' I have a cat , you have a cat , he have a cat '
如果我們只想替換前面兩個(gè),則
>>> re.sub( r’dog’ , ‘cat’ , s , 2 )
' I have a cat , you have a cat , he have a dog '
或者我們想知道發(fā)生了多少次替換,則可以使用subn
>>> re.subn( r’dog’ , ‘cat’ , s )
(' I have a cat , you have a cat , he have a cat ', 3)
split( rule , target [,maxsplit] )
切片函數(shù)。使用指定的正則規(guī)則在目標(biāo)字符串中查找匹配的字符串,用它們作為分界,把字符串切片。
第一個(gè)參數(shù)是正則規(guī)則,第二個(gè)參數(shù)是目標(biāo)字符串,第三個(gè)參數(shù)是最多切片次數(shù)
返回一個(gè)被切完的子字符串的列表
這個(gè)函數(shù)和str對(duì)象提供的split函數(shù)很相似。舉個(gè)例子,我們想把上例中的字符串被’,’分割開(kāi),同時(shí)要去掉逗號(hào)前后的空格
>>> s=’ I have a dog , you have a dog , he have a dog ‘
>>> re.split( ‘/s*,/s*’ , s )
[' I have a dog', 'you have a dog', 'he have a dog ']
結(jié)果很好。如果使用str對(duì)象的split函數(shù),則由于我們不知道’,’兩邊會(huì)有多少個(gè)空格,而不得不對(duì)結(jié)果再進(jìn)行一次處理。
escape( string )
這是個(gè)功能比較古怪的函數(shù),它的作用是將字符串中的non-alphanumerics字符(我已不知道該怎么翻譯比較好了)用反義字符的形式顯示出來(lái)。有時(shí)候你可能希望在正則式中匹
配一個(gè)字符串,不過(guò)里面含有很多re使用的符號(hào),你要一個(gè)一個(gè)的修改寫(xiě)法實(shí)在有點(diǎn)麻煩,你可以使用這個(gè)函數(shù),
例在目標(biāo)字符串s中匹配’(*+?)’這個(gè)子字符串
>>> s= ‘111 222 (*+?) 333’
>>> rule= re.escape( r’(*+?)’ )
>>> print rule
/(/*/+/?/)
>>> re.findall( rule , s )
['(*+?)']
3 更深入的了解re的組與對(duì)象
前面對(duì)Python正則式的組進(jìn)行了一些簡(jiǎn)單的介紹,由于還沒(méi)有介紹到match對(duì)象,而組又是和match對(duì)象密切相關(guān)的,所以必須將它們結(jié)合起來(lái)介紹才能充分地說(shuō)明它們的用途。
不過(guò)再詳細(xì)介紹它們之前,我覺(jué)得有必要先介紹一下將規(guī)則編譯后的生成的patter對(duì)象
3.1編譯后的Pattern對(duì)象
將一個(gè)正則式,使用compile函數(shù)編譯,不僅是為了提高匹配的速度,同時(shí)還能使用一些附加的功能。編譯后的結(jié)果生成一個(gè)Pattern對(duì)象,這個(gè)對(duì)象里面有很多函數(shù),他們看起來(lái)
和re模塊的函數(shù)非常象,它同樣有findall , match , search ,finditer , sub , subn , split這些函數(shù),只不過(guò)它們的參數(shù)有些小小的不同。一般說(shuō)來(lái),re模塊函數(shù)的第一個(gè)
參數(shù),即正則規(guī)則不再需要了,應(yīng)為規(guī)則就包含在Pattern對(duì)象中了,編譯選項(xiàng)也不再需要了,因?yàn)橐呀?jīng)被編譯過(guò)了。因此re模塊中函數(shù)的這兩個(gè)參數(shù)的位置,就被后面的參數(shù)取
代了。
findall , match , search和finditer這幾個(gè)函數(shù)的參數(shù)是一樣的,除了少了規(guī)則和選項(xiàng)兩個(gè)參數(shù)外,它們又加入了另外兩個(gè)參數(shù),它們是:查找開(kāi)始位置和查找結(jié)束位置,也就
是說(shuō),現(xiàn)在你可以指定查找的區(qū)間,除去你不感興趣的區(qū)間。它們現(xiàn)在的參數(shù)形式是:
findall ( targetString [, startPos [,endPos] ] )
finditer ( targetString [, startPos [,endPos] ] )
match ( targetString [, startPos [,endPos] ] )
search ( targetString [, startPos [,endPos] ] )
這些函數(shù)的使用和re模塊的同名函數(shù)使用完全一樣。所以就不多介紹了。
除了和re模塊的函數(shù)同樣的函數(shù)外,Pattern對(duì)象還多了些東西,它們是:
flags 查詢(xún)編譯時(shí)的選項(xiàng)
pattern查詢(xún)編譯時(shí)的規(guī)則
groupindex規(guī)則里的組
這幾個(gè)不是函數(shù),而是一個(gè)值。它們提供你一些規(guī)則的信息。比如下面這個(gè)例子
>>> p=re.compile( r'(?P<word>/b[a-z]+/b)|(?P<num>/b/d+/b)|(?P<id>/b[a-z_]+/w*/b)' , re.I )
>>> p.flags
2
>>> p.pattern
'(?P<word>//b[a-z]+//b)|(?P<num>//b//d+//b)|(?P<id>//b[a-z_]+//w*//b)'
>>> p.groupindex
{'num': 2, 'word': 1, 'id': 3}
我們來(lái)分析一下這個(gè)例子:這個(gè)正則式是匹配單詞、或數(shù)字、或一個(gè)由字母或’_’開(kāi)頭,后面接字母或數(shù)字的一個(gè)ID。我們給這三種情況的規(guī)則都包入了一個(gè)命名組,分別命名
為’word’ , ‘num’和‘id’。我們規(guī)定大小寫(xiě)不敏感,所以使用了編譯選項(xiàng)‘I’。
編譯以后返回的對(duì)象為p,通過(guò)p.flag我們可以查看編譯時(shí)的選項(xiàng),不過(guò)它顯示的不是’I’,而是一個(gè)數(shù)值2。其實(shí)re.I是一個(gè)整數(shù),2就是它的值。我們可以查看一下:
>>> re.I
2
>>> re.L
4
>>> re.M
8
…
每個(gè)選項(xiàng)都是一個(gè)數(shù)值。
通過(guò)p.pattern可以查看被編譯的規(guī)則是什么。使用print的話(huà)會(huì)更好看一些
>>> print p.pattern
(?P<word>/b[a-z]+/b)|(?P<num>/b/d+/b)|(?P<id>/b[a-z_]+/w*/b)
看,和我們輸入的一樣。
接下來(lái)的p.groupindex則是一個(gè)字典,它包含了規(guī)則中的所有命名組。字典的key是名字,values是組的序號(hào)。由于字典是以名字作為key,所以一個(gè)無(wú)命名的組不會(huì)出現(xiàn)在這里。
3.2組與Match對(duì)象
組與Match對(duì)象是Python正則式的重點(diǎn)。只有掌握了組和Match對(duì)象的使用,才算是真正學(xué)會(huì)了Python正則式。
3.2.1 組的名字與序號(hào)
正則式中的每個(gè)組都有一個(gè)序號(hào),它是按定義時(shí)從左到右的順序從1開(kāi)始編號(hào)的。其實(shí),re的正則式還有一個(gè)0號(hào)組,它就是整個(gè)正則式本身。
我們來(lái)看個(gè)例子
>>> p=re.compile( r’(?P<name>[a-z]+)/s+(?P<age>/d+)/s+(?P<tel>/d+).*’ , re.I )
>>> p.groupindex
{'age': 2, 'tel': 3, 'name': 1}
>>> s=’Tom 24 88888888 <=’
>>> m=p.search(s)
>>> m.groups() #看看匹配的各組的情況
('Tom', '24', '8888888')
>>> m.group(‘name’) #使用組名獲取匹配的字符串
‘Tom’
>>> m.group( 1 ) #使用組序號(hào)獲取匹配的字符串,同使用組名的效果一樣
>>> m.group(0) # 0組里面是什么呢?
'Tom 24 88888888 <='
原來(lái)0組就是整個(gè)正則式,包括沒(méi)有被包圍到組里面的內(nèi)容。當(dāng)獲取0組的時(shí)候,你可以不寫(xiě)這個(gè)參數(shù)。m.group(0)和m.group()的效果是一樣的:
>>> m.group()
'Tom 24 88888888 <='
接下來(lái)看看更多的Match對(duì)象的方法,看看我們能做些什么。
3.2.2 Match對(duì)象的方法
group([index|id]) 獲取匹配的組,缺省返回組0,也就是全部值
groups() 返回全部的組
groupdict() 返回以組名為key,匹配的內(nèi)容為values的字典
接上例:
>>> m.groupindex()
{'age': '24', 'tel': '88888888', 'name': 'Tom'}
start( [group] ) 獲取匹配的組的開(kāi)始位置
end( [group] ) 獲取匹配的組的結(jié)束位置
span( [group] ) 獲取匹配的組的(開(kāi)始,結(jié)束)位置
expand( template )根據(jù)一個(gè)模版用找到的內(nèi)容替換模版里的相應(yīng)位置
這個(gè)功能比較有趣,它根據(jù)一個(gè)模版來(lái)用匹配到的內(nèi)容替換模版中的相應(yīng)位置,組成一個(gè)新的字符串返回。它使用/g<index|name>或/index來(lái)指示一個(gè)組。
接上例
>>> m.expand(r'name is /g<1> , age is /g<age> , tel is /3')
'name is Tom , age is 24 , tel is 88888888'
除了以上這些函數(shù)外,Match對(duì)象還有些屬性
pos 搜索開(kāi)始的位置參數(shù)
endpos 搜索結(jié)束的位置參數(shù)
這兩個(gè)是使用findall或match等函數(shù)時(shí),傳入的參數(shù)。在上面這個(gè)例子里,我們沒(méi)有指定開(kāi)始和結(jié)束位置,那么缺省的開(kāi)始位置就是0,結(jié)束位置就是最后。
>>> m.pos
0
>>> m.endpos
19
lastindex 最后匹配的組的序號(hào)
>>> m.lastindex
3
lastgroup 最后匹配的組名
>>> m.lastgroup
'tel'
re 產(chǎn)生這個(gè)匹配的Pattern對(duì)象,可以認(rèn)為是個(gè)逆引用
>>> m.re.pattern
'(?P<name>[a-z]+)//s+(?P<age>//d+)//s+(?P<tel>//d+).*'
得到了產(chǎn)生這個(gè)匹配的規(guī)則
string 匹配的目標(biāo)字符串
>>> m.string
'Tom 24 88888888 <='
轉(zhuǎn)自:
http://hi.baidu.com/yangdaming1983/item/e6a8146255a5442169105b91posted @
2013-02-11 16:28 Seraphi 閱讀(285) |
評(píng)論 (0) |
編輯 收藏
摘要: 1 概述1.1 什么是捕獲組捕獲組就是把正則表達(dá)式中子表達(dá)式匹配的內(nèi)容,保存到內(nèi)存中以數(shù)字編號(hào)或顯式命名的組里,方便后面引用。當(dāng)然,這種引用既可以是在正則表達(dá)式內(nèi)部,也可以是在正則表達(dá)式外部。捕獲組有兩種形式,一種是普通捕獲組,另一種是命名捕獲組,...
閱讀全文
posted @
2013-02-11 16:26 Seraphi 閱讀(1954) |
評(píng)論 (0) |
編輯 收藏Python讀寫(xiě)文件
1.open
使用open打開(kāi)文件后一定要記得調(diào)用文件對(duì)象的close()方法。比如可以用try/finally語(yǔ)句來(lái)確保最后能關(guān)閉文件。
file_object = open('thefile.txt')
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
注:不能把open語(yǔ)句放在try塊里,因?yàn)楫?dāng)打開(kāi)文件出現(xiàn)異常時(shí),文件對(duì)象file_object無(wú)法執(zhí)行close()方法。
2.讀文件
讀文本文件
input = open('data', 'r')
#第二個(gè)參數(shù)默認(rèn)為r
input = open('data')
讀二進(jìn)制文件
input = open('data', 'rb')
讀取所有內(nèi)容
file_object = open('thefile.txt')
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
讀固定字節(jié)
file_object = open('abinfile', 'rb')
try:
while True:
chunk = file_object.read(100)
if not chunk:
break
do_something_with(chunk)
finally:
file_object.close( )
讀每行
list_of_all_the_lines = file_object.readlines( )
如果文件是文本文件,還可以直接遍歷文件對(duì)象獲取每行:
for line in file_object:
process line
3.寫(xiě)文件
寫(xiě)文本文件
output = open('data', 'w')
寫(xiě)二進(jìn)制文件
output = open('data', 'wb')
追加寫(xiě)文件
output = open('data', 'w+')
寫(xiě)數(shù)據(jù)
file_object = open('thefile.txt', 'w')
file_object.write(all_the_text)
file_object.close( )
寫(xiě)入多行
file_object.writelines(list_of_text_strings)
注意,調(diào)用writelines寫(xiě)入多行在性能上會(huì)比使用write一次性寫(xiě)入要高。
在處理日志文件的時(shí)候,常常會(huì)遇到這樣的情況:日志文件巨大,不可能一次性把整個(gè)文件讀入到內(nèi)存中進(jìn)行處理,例如需要在一臺(tái)物理內(nèi)存為 2GB 的機(jī)器上處理一個(gè) 2GB 的日志文件,我們可能希望每次只處理其中 200MB 的內(nèi)容。
在 Python 中,內(nèi)置的 File 對(duì)象直接提供了一個(gè) readlines(sizehint) 函數(shù)來(lái)完成這樣的事情。以下面的代碼為例:
file = open('test.log', 'r')sizehint = 209715200 # 200Mposition = 0lines = file.readlines(sizehint)while not file.tell() - position < 0: position = file.tell() lines = file.readlines(sizehint)
每次調(diào)用 readlines(sizehint) 函數(shù),會(huì)返回大約 200MB 的數(shù)據(jù),而且所返回的必然都是完整的行數(shù)據(jù),大多數(shù)情況下,返回的數(shù)據(jù)的字節(jié)數(shù)會(huì)稍微比 sizehint 指定的值大一點(diǎn)(除最后一次調(diào)用 readlines(sizehint) 函數(shù)的時(shí)候)。通常情況下,Python 會(huì)自動(dòng)將用戶(hù)指定的 sizehint 的值調(diào)整成內(nèi)部緩存大小的整數(shù)倍。
file在python是一個(gè)特殊的類(lèi)型,它用于在python程序中對(duì)外部的文件進(jìn)行操作。在python中一切都是對(duì)象,file也不例外,file有file的方法和屬性。下面先來(lái)看如何創(chuàng)建一個(gè)file對(duì)象:
file(name[, mode[, buffering]])
file()函數(shù)用于創(chuàng)建一個(gè)file對(duì)象,它有一個(gè)別名叫open(),可能更形象一些,它們是內(nèi)置函數(shù)。來(lái)看看它的參數(shù)。它參數(shù)都是以字符串的形式傳遞的。name是文件的名字。
mode是打開(kāi)的模式,可選的值為r w a U,分別代表讀(默認(rèn)) 寫(xiě) 添加支持各種換行符的模式。用w或a模式打開(kāi)文件的話(huà),如果文件不存在,那么就自動(dòng)創(chuàng)建。此外,用w模式打開(kāi)一個(gè)已經(jīng)存在的文件時(shí),原有文件的內(nèi)容會(huì)被清空,因?yàn)橐婚_(kāi)始文件的操作的標(biāo)記是在文件的開(kāi)頭的,這時(shí)候進(jìn)行寫(xiě)操作,無(wú)疑會(huì)把原有的內(nèi)容給抹掉。由于歷史的原因,換行符在不同的系統(tǒng)中有不同模式,比如在 unix中是一個(gè)\n,而在windows中是‘\r\n’,用U模式打開(kāi)文件,就是支持所有的換行模式,也就說(shuō)‘\r’ '\n' '\r\n'都可表示換行,會(huì)有一個(gè)tuple用來(lái)存貯這個(gè)文件中用到過(guò)的換行符。不過(guò),雖說(shuō)換行有多種模式,讀到python中統(tǒng)一用\n代替。在模式字符的后面,還可以加上+ b t這兩種標(biāo)識(shí),分別表示可以對(duì)文件同時(shí)進(jìn)行讀寫(xiě)操作和用二進(jìn)制模式、文本模式(默認(rèn))打開(kāi)文件。
buffering如果為0表示不進(jìn)行緩沖;如果為1表示進(jìn)行“行緩沖“;如果是一個(gè)大于1的數(shù)表示緩沖區(qū)的大小,應(yīng)該是以字節(jié)為單位的。
file對(duì)象有自己的屬性和方法。先來(lái)看看file的屬性。
closed #標(biāo)記文件是否已經(jīng)關(guān)閉,由close()改寫(xiě)
encoding #文件編碼
mode #打開(kāi)模式
name #文件名
newlines #文件中用到的換行模式,是一個(gè)tuple
softspace #boolean型,一般為0,據(jù)說(shuō)用于print
file的讀寫(xiě)方法:
F.read([size]) #size為讀取的長(zhǎng)度,以byte為單位
F.readline([size])
#讀一行,如果定義了size,有可能返回的只是一行的一部分
F.readlines([size])
#把文件每一行作為一個(gè)list的一個(gè)成員,并返回這個(gè)list。其實(shí)它的內(nèi)部是通過(guò)循環(huán)調(diào)用readline()來(lái)實(shí)現(xiàn)的。如果提供size參數(shù),size是表示讀取內(nèi)容的總長(zhǎng),也就是說(shuō)可能只讀到文件的一部分。
F.write(str)
#把str寫(xiě)到文件中,write()并不會(huì)在str后加上一個(gè)換行符
F.writelines(seq)
#把seq的內(nèi)容全部寫(xiě)到文件中。這個(gè)函數(shù)也只是忠實(shí)地寫(xiě)入,不會(huì)在每行后面加上任何東西。
file的其他方法:
F.close()
#關(guān)閉文件。python會(huì)在一個(gè)文件不用后自動(dòng)關(guān)閉文件,不過(guò)這一功能沒(méi)有保證,最好還是養(yǎng)成自己關(guān)閉的習(xí)慣。如果一個(gè)文件在關(guān)閉后還對(duì)其進(jìn)行操作會(huì)產(chǎn)生ValueError
F.flush()
#把緩沖區(qū)的內(nèi)容寫(xiě)入硬盤(pán)
F.fileno()
#返回一個(gè)長(zhǎng)整型的”文件標(biāo)簽“
F.isatty()
#文件是否是一個(gè)終端設(shè)備文件(unix系統(tǒng)中的)
F.tell()
#返回文件操作標(biāo)記的當(dāng)前位置,以文件的開(kāi)頭為原點(diǎn)
F.next()
#返回下一行,并將文件操作標(biāo)記位移到下一行。把一個(gè)file用于for ... in file這樣的語(yǔ)句時(shí),就是調(diào)用next()函數(shù)來(lái)實(shí)現(xiàn)遍歷的。
F.seek(offset[,whence])
#將文件打操作標(biāo)記移到offset的位置。這個(gè)offset一般是相對(duì)于文件的開(kāi)頭來(lái)計(jì)算的,一般為正數(shù)。但如果提供了whence參數(shù)就不一定了,whence可以為0表示從頭開(kāi)始計(jì)算,1表示以當(dāng)前位置為原點(diǎn)計(jì)算。2表示以文件末尾為原點(diǎn)進(jìn)行計(jì)算。需要注意,如果文件以a或a+的模式打開(kāi),每次進(jìn)行寫(xiě)操作時(shí),文件操作標(biāo)記會(huì)自動(dòng)返回到文件末尾。
F.truncate([size])
#把文件裁成規(guī)定的大小,默認(rèn)的是裁到當(dāng)前文件操作標(biāo)記的位置。如果size比文件的大小還要大,依據(jù)系統(tǒng)的不同可能是不改變文件,也可能是用0把文件補(bǔ)到相應(yīng)的大小,也可能是以一些隨機(jī)的內(nèi)容加上去。
本文來(lái)自CSDN博客,轉(zhuǎn)載請(qǐng)標(biāo)明出處:http://blog.csdn.net/adupt/archive/2009/08/11/4435615.aspx
posted @
2013-02-10 23:31 Seraphi 閱讀(1315) |
評(píng)論 (0) |
編輯 收藏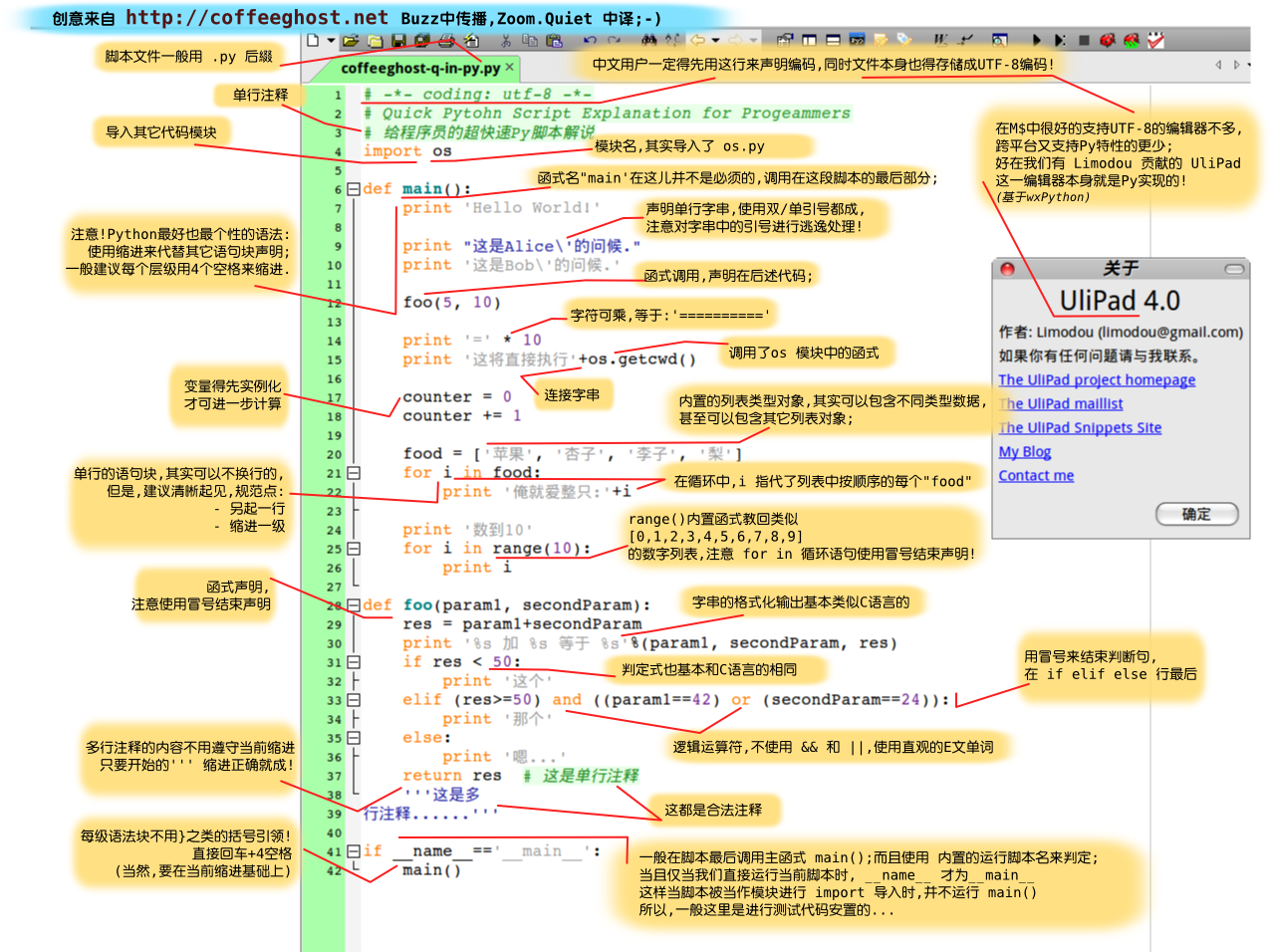
posted @
2013-02-02 16:01 Seraphi 閱讀(364) |
評(píng)論 (0) |
編輯 收藏linux 下的iconv命令可以把Windows默認(rèn)GBK編碼的文件轉(zhuǎn)成Linux下用的UTF-8編碼。
Example: $ iconv -f GBK -t UTF-8 file_name -o file_name
1. 安裝命令行版的texlive: sudo apt-get install texlive-full
2. 安裝一個(gè)比較有幫助性的編輯器: sudo apt-get install texmaker
3. 安裝中文環(huán)境: sudo apt-get install latex-cjk-all
A useful webiste http://chixi.an.blog.163.com/blog/static/29359272201262952120729/
To install/upgrade to TeX Live 2012:
- Open a terminal with Ctrl+Alt+T
Add the texlive-backports PPA by typing the below (enter your password when prompted):
sudo apt-add-repository ppa:texlive-backports/ppa
Then type:
sudo apt-get update
Installation:
If you are installing TeX Live for the first time, type:
sudo apt-get install texlive
If you already have TeX Live installed and are upgrading, type:
sudo apt-get upgrade
Warning: this will also upgrade all other packages on your Ubuntu system for which upgrades are available. If you do not wish to do this, please use the previous sudo apt-get install texliveinstead.
轉(zhuǎn)自:http://blog.csdn.net/lsg32/article/details/8058491
posted @
2013-02-02 15:27 Seraphi 閱讀(286) |
評(píng)論 (0) |
編輯 收藏
在新版本的UBUNTU里不支持WINDOWS的wubi安裝,要用如下方式:
Ubuntu 12.04 wubi的安裝
一、在12.04里,在Windows內(nèi)安裝那個(gè)選項(xiàng)被禁用了,只能通過(guò)以下指令開(kāi)啟,X為光驅(qū)盤(pán)符:
代碼:
X:\wubi.exe --force-wubi
posted @
2013-02-01 12:27 Seraphi 閱讀(259) |
評(píng)論 (0) |
編輯 收藏
1、學(xué)會(huì)latex
2、熟練python
3、NLP相關(guān)知識(shí),主要是gibbs sampling;以及這學(xué)期所學(xué)到的東西
4、Deep learning
5、改論文
6、加強(qiáng)算法方面的練習(xí)
posted @
2013-01-17 00:24 Seraphi 閱讀(191) |
評(píng)論 (0) |
編輯 收藏【招聘須知】 Facebook正在全球招聘,對(duì)中國(guó)頂尖大學(xué)的Engineering專(zhuān)業(yè)學(xué)生尤其歡迎。 具體職位信息可以在https://www.facebook.com/careers上找到,申請(qǐng)的時(shí)候一般都是選 擇Software Engineer (University Recruiting),F(xiàn)acebook的制度是并不預(yù)先定向你去 哪個(gè)組。在入職的第一個(gè)月統(tǒng)一進(jìn)行培訓(xùn),培訓(xùn)結(jié)束的兩周后進(jìn)行統(tǒng)一的Team Selectio n,每個(gè)組的大Manager過(guò)來(lái)將自己的組做的東西,你可以和感興趣的組聊,雙向選擇后最 終決定去哪里。所以是很自由的文化,決定你去哪里的最重要的是Potential,而不是你 已經(jīng)在這個(gè)area的experience,這也是FB的文化,希望培養(yǎng)每個(gè)Engineer成為多面手,對(duì) 任何問(wèn)題的Fast learner。 【基本要求】 專(zhuān)業(yè)不限要求有限,可以分成兩個(gè)類(lèi),看看你符合哪一類(lèi) 1. 第一類(lèi): - ACM/ICPC 區(qū)域銀牌以上,或者在大型比賽上得過(guò)不錯(cuò)的名次(前15%),這里大型比賽 指包括NOIP, NOI, APOI,省級(jí)選拔賽,Topcoder, Google Code Jam, 百度之星,有道難 題等等 - 在以下公司有過(guò)實(shí)習(xí)經(jīng)驗(yàn):Google, Microsoft Research Asia, Hulu, EMC/VMware, Microstrategy (這些公司只是在經(jīng)驗(yàn)范圍內(nèi)實(shí)習(xí)生非常靠譜,并沒(méi)有對(duì)其他公司不尊重 的意思,只是接觸的不多而已,見(jiàn)諒) - 本科成績(jī)年級(jí)前10%,核心課程算法,數(shù)據(jù)結(jié)構(gòu),C++,離散,組合數(shù)學(xué)等等絕大部分為 優(yōu)秀 - 頂級(jí)會(huì)議上發(fā)表一二作論文,頂級(jí)會(huì)議的定義是專(zhuān)業(yè)領(lǐng)域內(nèi)公認(rèn)的大會(huì),例如IR/ML領(lǐng) 域的SIGIR, ICML, WWW, ICDM等等 以上符合任意一條的話(huà),請(qǐng)聯(lián)系我 2. 第二類(lèi): - <Crack the Coding Interview> 從頭到尾詳細(xì)閱讀并且做完所有的例題和習(xí)題 - www.leetcode.com 全部做完所有的題 符合以上所有條件的,請(qǐng)聯(lián)系我,附上代碼 PS: CTCI書(shū)課后有答案,leetcode網(wǎng)上有不錯(cuò)的人做了發(fā)表,比如 https://github.com/zwxxx/LeetCode https://github.com/anson627/leetcode 做的時(shí)候請(qǐng)不要參考,做完以后可以和參考答案對(duì)比改進(jìn),直接抄答案是沒(méi)有意義的,答 案只是幫你提高的工具。對(duì)于代碼的要求是,寫(xiě)的塊,風(fēng)格簡(jiǎn)潔,易于理解 【聯(lián)系方式】 請(qǐng)發(fā)郵件到郵箱zhangchitc@gmail.com,附上簡(jiǎn)單的自我介紹,并著名是符合上述哪些要 求,如果第二類(lèi)請(qǐng)用zip壓縮包打包代碼附在附件中 BTW: 第一類(lèi)滿(mǎn)足的話(huà)最終還是要將第二類(lèi)里面的材料全部做了的。。。。 【面試過(guò)程】 職位都是美國(guó)總部,不排除可能外派海外Site,不過(guò)基本應(yīng)該都是前者。在推薦以后一 周之內(nèi)應(yīng)該總部會(huì)安排工程師使用skype進(jìn)行2到3輪電話(huà)面試,通過(guò)以后提供機(jī)票到美國(guó) 進(jìn)行onsite面試。3到5輪不等。基本都是算法面試,在白板上寫(xiě)程序。全程英文,不需要 英語(yǔ)標(biāo)準(zhǔn)考試成績(jī),但是對(duì)基本的聽(tīng)力和口語(yǔ)要求比較高,要能自由和工程師進(jìn)行交流, 語(yǔ)法有問(wèn)題的可以完全不用擔(dān)心 住宿和交通費(fèi)用全包。 【注意事項(xiàng)】 - 理論上是可以推實(shí)習(xí)的,不過(guò)對(duì)中國(guó)學(xué)生來(lái)講實(shí)習(xí)不是很現(xiàn)實(shí),本科生太忙,研究生完 全2、3個(gè)月在外面導(dǎo)師應(yīng)該說(shuō)不過(guò)去 - 基本沒(méi)有deadline,全年都可以聯(lián)系我,但是考慮到大陸學(xué)生過(guò)去的H1B簽證申請(qǐng),如 果拿到offer需要在每年4月前遞交申請(qǐng),所以最晚開(kāi)始面試應(yīng)該是2月,越快申請(qǐng)?jiān)胶?- 因?yàn)镕B在中國(guó)沒(méi)有公開(kāi)的招聘渠道,所以請(qǐng)不要傳播本帖(雖然知道基本是白說(shuō),但是 希望至少本校的同學(xué)不要傳播出去)招聘的細(xì)節(jié)我不能說(shuō)太多,接觸以后可以聊 - 滿(mǎn)足條件就請(qǐng)大膽申請(qǐng),在整個(gè)過(guò)程中我都可以為大家提供幫助和建議。根據(jù)HR的反饋 來(lái)看本人的推薦還是挺靠譜的,目前為止有7位同學(xué)通過(guò)我的推薦成功拿到了offer,目測(cè) 很快在一周之內(nèi)會(huì)達(dá)到10個(gè)
posted @
2013-01-11 00:24 Seraphi 閱讀(2283) |
評(píng)論 (2) |
編輯 收藏Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}]
@="Internet Explorer"
"InfoTip"="@C:\\WINDOWS\\system32\\zh-CN\\ieframe.dll.mui,-881"
"LocalizedString"="@C:\\WINDOWS\\system32\\zh-CN\\ieframe.dll.mui,-880"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\DefaultIcon]
@="C:\\Program Files\\Internet Explorer\\iexplore.exe,-32528"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\NoAddOns]
@="在沒(méi)有加載項(xiàng)的情況下啟動(dòng)"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\NoAddOns\Command]
@="C:\\Program Files\\Internet Explorer\\iexplore.exe about:NoAdd-ons"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\Open]
@="打開(kāi)(O)"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\Open\Command]
@="C:\\Program Files\\Internet Explorer\\iexplore.exe"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\屬性(R)]
@=""
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\屬性(R)\Command]
@="Rundll32.exe Shell32.dll,Control_RunDLL Inetcpl.cpl"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\ShellFolder]
@=""
"Attributes"=dword:00000010
"HideFolderVerbs"=""
"WantsParseDisplayName"=""
"HideOnDesktopPerUser"=""
@="C:\\WINDOWS\\system32\\ieframe.dll,-190"
"HideAsDeletePerUser"=""
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}]
@="Internet Explorer"
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Desktop\NameSpace\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}]
@="Windows Media"
posted @
2013-01-06 15:13 Seraphi 閱讀(181) |
評(píng)論 (0) |
編輯 收藏set tags=tags;
set backspace=indent,eol,start
set shiftwidth=4
set tabstop=4
set expandtab
set encoding=utf8
set fileencodings=utf8,gbk
set nocompatible "去掉討厭的有關(guān)vim一致性模式,避免以前版本的一些bug和局限.
set number "顯示行號(hào).
set background=dark "背景顏色暗色.(我覺(jué)得不錯(cuò),保護(hù)眼睛.)
syntax on "語(yǔ)法高亮顯示.(這個(gè)肯定是要的.)
set history=50 "設(shè)置命令歷史記錄為50條.
set autoindent "使用自動(dòng)對(duì)起,也就是把當(dāng)前行的對(duì)起格式應(yīng)用到下一行.
set smartindent "依據(jù)上面的對(duì)起格式,智能的選擇對(duì)起方式,對(duì)于類(lèi)似C語(yǔ)言編.
set tabstop=4 "設(shè)置tab鍵為4個(gè)空格.
set shiftwidth=4 "設(shè)置當(dāng)行之間交錯(cuò)時(shí)使用4個(gè)空格
set showmatch "設(shè)置匹配模式,類(lèi)似當(dāng)輸入一個(gè)左括號(hào)時(shí)會(huì)匹配相應(yīng)的那個(gè)右括號(hào)
set incsearch
"搜索選項(xiàng).(比如,鍵入"/bo",光標(biāo)自動(dòng)找到第一個(gè)"bo"所在的位置.)hi Comment ctermfg=darkmagenta
hi String ctermfg=darkred
hi Number ctermfg=darkblue
"是否生成一個(gè)備份文件.(備份的文件名為原文件名加“~“后綴
"(我不喜歡這個(gè)備份設(shè)置,一般注釋掉.)
"if has(“vms.
" set nobackup
"else
" set backup
"endif
關(guān)于注釋字體顏色的修改,可以參考:http://blog.csdn.net/a670449625/article/details/48051249
posted @
2012-11-09 19:44 Seraphi 閱讀(197) |
評(píng)論 (0) |
編輯 收藏http://www.coli.uni-saarland.de/~csporled/page.php?id=tools
這個(gè)站點(diǎn)列舉出了幾乎所有NLP和IR領(lǐng)域能夠直接使用的好用的工具包~
posted @
2012-10-29 10:25 Seraphi 閱讀(306) |
評(píng)論 (0) |
編輯 收藏轉(zhuǎn)載自:cool shell,作者:陳皓
From:http://coolshell.cn/articles/7992.html
先說(shuō)明一下,我不希望本文變成語(yǔ)言爭(zhēng)論貼。希望下面的文章能讓我們客觀(guān)理性地了解C++這個(gè)語(yǔ)言。(另,我覺(jué)得技術(shù)爭(zhēng)論不要停留在非黑即白的二元價(jià)值觀(guān)上,這樣爭(zhēng)論無(wú)非就是比誰(shuí)的嗓門(mén)大,比哪一方的觀(guān)點(diǎn)強(qiáng),毫無(wú)價(jià)值。我們應(yīng)該多看看技術(shù)是怎么演進(jìn)的,怎么取舍的。)
事由
 周五的時(shí)候,我在我的微博上發(fā)了一個(gè)貼說(shuō)了一下一個(gè)網(wǎng)友給我發(fā)來(lái)的C++程序的規(guī)范和內(nèi)存管理寫(xiě)的不是很好(后來(lái)我刪除了,因?yàn)楫?dāng)事人要求),我并非批判,只是想說(shuō)明其實(shí)程序員是需要一些“疫苗”的,并以此想開(kāi)一個(gè)“程序員疫苗的網(wǎng)站”,結(jié)果,@簡(jiǎn)悅云風(fēng)同學(xué)直接回復(fù)到:“不要用 C++ 直接用 C , 就沒(méi)那么多坑了。”就把這個(gè)事帶入了語(yǔ)言之爭(zhēng)。
周五的時(shí)候,我在我的微博上發(fā)了一個(gè)貼說(shuō)了一下一個(gè)網(wǎng)友給我發(fā)來(lái)的C++程序的規(guī)范和內(nèi)存管理寫(xiě)的不是很好(后來(lái)我刪除了,因?yàn)楫?dāng)事人要求),我并非批判,只是想說(shuō)明其實(shí)程序員是需要一些“疫苗”的,并以此想開(kāi)一個(gè)“程序員疫苗的網(wǎng)站”,結(jié)果,@簡(jiǎn)悅云風(fēng)同學(xué)直接回復(fù)到:“不要用 C++ 直接用 C , 就沒(méi)那么多坑了。”就把這個(gè)事帶入了語(yǔ)言之爭(zhēng)。
我又發(fā)了一條微博:
@左耳朵耗子 人認(rèn)證") : 說(shuō)C++比C的坑更多的人我可以理解,但理性地思考一下。C語(yǔ)言的坑也不少啊,如果說(shuō)C語(yǔ)言有90個(gè)坑,那么C++就是100個(gè)坑(另,我看很多人都把C語(yǔ)言上的坑也歸到了C++上來(lái)),但是C++你得到的東西更多,封裝,多態(tài),繼承擴(kuò)展,泛型編程,智能指針,……,你得到了500%東西,但卻只多了10%的坑,多值啊。
: 說(shuō)C++比C的坑更多的人我可以理解,但理性地思考一下。C語(yǔ)言的坑也不少啊,如果說(shuō)C語(yǔ)言有90個(gè)坑,那么C++就是100個(gè)坑(另,我看很多人都把C語(yǔ)言上的坑也歸到了C++上來(lái)),但是C++你得到的東西更多,封裝,多態(tài),繼承擴(kuò)展,泛型編程,智能指針,……,你得到了500%東西,但卻只多了10%的坑,多值啊。
結(jié)果引來(lái)了更多的回復(fù)(只節(jié)選了一些言論):
- @淘寶褚霸也在微博里說(shuō):“自從5年前果斷扔掉C++,改用了ansi c后,我的生活質(zhì)量大大提升,沒(méi)有各種坑坑我。”
- @Laruence在其微博里說(shuō): “我確實(shí)用不到, C語(yǔ)言靈活運(yùn)用struct, 可以很好的滿(mǎn)足這些需求.//@左耳朵耗子: 封裝,繼承,多態(tài),模板,智能指針,這也用不到?這也學(xué)院派?//@Laruence: 問(wèn)題是, 這些東西我都用不到… C語(yǔ)言是工程師搞的, C++是學(xué)院派搞的”
那么,C++的坑真的多么?我還請(qǐng)大家理性地思考一下。
C++真的比C差嗎?
我們先來(lái)看一個(gè)圖——《各種程序員的嘴臟的對(duì)比》,從這個(gè)圖上看,C程序員比C++的程序員在注釋中使用fuck的字眼多一倍。這說(shuō)明了什么?我個(gè)人覺(jué)得這說(shuō)明C程序員沒(méi)有C++程序員淡定。
言出現(xiàn) fuck 一詞的比率")
不要太糾結(jié)上圖,只是輕松一下,我沒(méi)那么無(wú)聊,讓我們來(lái)看點(diǎn)真正的論據(jù)。
相信用過(guò)C++的程序員知道,C++的很多特性主要就是解決C語(yǔ)言中的各種不完美和缺陷:(注:C89、C99中許多的改進(jìn)正是從C++中所引進(jìn)的)
- 用namespace解決了很C函數(shù)重名的問(wèn)題。
- 用const/inline/template代替了宏,解決了C語(yǔ)言中宏的各種坑。
- 用const的類(lèi)型解決了很多C語(yǔ)言中變量值莫名改變的問(wèn)題。
- 用引用代替指針,解決了C語(yǔ)言中指針的各種坑。這個(gè)在Java里得到徹底地體現(xiàn)。
- 用強(qiáng)類(lèi)型檢查和四種轉(zhuǎn)型,解決了C語(yǔ)言中亂轉(zhuǎn)型的各種坑。
- 用封裝(構(gòu)造,析構(gòu),拷貝構(gòu)造,賦值重載)解決了C語(yǔ)言中各種復(fù)制一個(gè)結(jié)構(gòu)體(struct)或是一個(gè)數(shù)據(jù)結(jié)構(gòu)(link, hashtable, list, array等)中淺拷貝的內(nèi)存問(wèn)題的各種坑。
- 用封裝讓你可以在成員變量加入getter/setter,而不會(huì)像C一樣只有文件級(jí)的封裝。
- 用函數(shù)重載、函數(shù)默認(rèn)參數(shù),解決了C中擴(kuò)展一個(gè)函數(shù)搞出來(lái)像func2()之類(lèi)的ugly的東西。
- 用繼承多態(tài)和RTTI解決了C中亂轉(zhuǎn)struct指針和使用函數(shù)指針的諸多讓代碼ugly的問(wèn)題。
- 用RAII,智能指針的方式,解決了C語(yǔ)言中因?yàn)槌霈F(xiàn)需要釋放資源的那些非常ugly的代碼的問(wèn)題。
- 用OO和GP解決各種C語(yǔ)言中用函數(shù)指針,對(duì)指針亂轉(zhuǎn)型,及一大砣if-else搞出來(lái)的ugly的泛型。
- 用STL解決了C語(yǔ)言中算法和數(shù)據(jù)結(jié)構(gòu)的N多種坑。
(注意:上面我沒(méi)有提重載運(yùn)算符和異常,前者寫(xiě)出來(lái)的代碼并不易讀和易維護(hù)(參看《
恐怖的C++語(yǔ)言》后面的那個(gè)示例),坑也多,后者并不成熟(相對(duì)于Java的異常),但是我們需要知道try-catch這種方式比傳統(tǒng)的不斷地判斷函數(shù)返回值和errno形成的大量的if-else在代碼可讀性上要好很多)
上述的這些東西填了不知有多少的C語(yǔ)言編程和維護(hù)的坑。少用指針,多用引用,試試autoptr,用用封裝,繼承,多態(tài)和函數(shù)重載…… 你面對(duì)的坑只會(huì)比C少,不會(huì)多。
C++的坑有多少?
C++的坑真的不多,如果你能花兩到三周的時(shí)候讀一下《Effecitve C++》里的那50多個(gè)條款,你就知道C++里的坑并不多,而且,有很多條款告訴我們C++是怎么解決C的坑的。然后,你可以讀讀《Exceptional C++》和《More Exceptional C++》,你可以了解一下C++各種問(wèn)題的解決方法和一些常見(jiàn)的經(jīng)典錯(cuò)誤。
當(dāng)然,C++在解決了很多C語(yǔ)的坑的同時(shí),也因?yàn)镺O和泛型又引入了一些坑。消一些,加一些,我個(gè)人感覺(jué)上總體上只比C多10%左右吧。但是你有了開(kāi)發(fā)速度更快,代碼更易讀,更易維護(hù)的500%的利益。
另外,不可否認(rèn)的是,C++中的代碼出了錯(cuò)誤,有時(shí)候很難搞,而且似乎用C++的人會(huì)覺(jué)得C++更容易出錯(cuò)?我覺(jué)得主要是下面幾個(gè)原因:
- C和C++都沒(méi)學(xué)好,大多數(shù)人用C++寫(xiě)C,所以,C的坑和C++的坑合并了。
- C++太靈活了,想怎么搞就怎么搞,所以,各種不經(jīng)意地濫用和亂搞。
另外,C++的編譯對(duì)標(biāo)準(zhǔn)C++的實(shí)現(xiàn)各異,支持地也千差萬(wàn)別,所以會(huì)有一些比較奇怪的問(wèn)題,但是如果你一般用用C++的封裝,繼承,多態(tài),以及namespace,const, refernece, inline, templete, overloap, autoptr,還有一些OO 模式,并不會(huì)出現(xiàn)奇怪的問(wèn)題。
而對(duì)于STL中的各種坑,我覺(jué)得是程序員們還對(duì)GP(泛型編程)理解得還不夠,STL是泛型編程的頂級(jí)實(shí)踐!屬于是大師級(jí)的作品,一般人很難理解。必需承認(rèn)STL寫(xiě)出來(lái)的代碼和編譯錯(cuò)誤的確相當(dāng)復(fù)雜晦澀,太難懂了。這也是C++的一個(gè)詬病。
這和Linus說(shuō)的一樣 —— “C++是一門(mén)很恐怖的語(yǔ)言,而比它更恐怖的是很多不合格的程序員在使用著它”。注意我飄紅了“很多不合格的程序員”!
我覺(jué)得C++并不適合初級(jí)程序員使用,C++只適合高級(jí)程序員使用(參看《21天學(xué)好C++》和《C++學(xué)習(xí)自信心曲線(xiàn)》),正如《Why C++》中說(shuō)的,C++適合那些對(duì)開(kāi)發(fā)維護(hù)效率和系統(tǒng)性能同時(shí)關(guān)注的高級(jí)程序員使用。
這就好像飛機(jī)一樣,開(kāi)飛機(jī)很難,開(kāi)飛機(jī)要注意的東西太多太多,對(duì)駕駛員的要求很高,但你不能說(shuō)飛機(jī)這個(gè)工具很爛,開(kāi)飛機(jī)的坑太多。(注:我這里并不是說(shuō)C++是飛機(jī),C是汽車(chē),C++和C的差距,比飛機(jī)到汽車(chē)的差距少太多太多,這里主要是類(lèi)比,我們對(duì)待C++語(yǔ)言的心態(tài)!)
C++的初衷
理解C++設(shè)計(jì)的最佳讀本是《C++演化和設(shè)計(jì)》,在這本書(shū)中Stroustrup說(shuō)了些事:
1)Stroustrup對(duì)C是非常欣賞,實(shí)際上早期C++許多的工作是對(duì)于C的強(qiáng)化和凈化,并把完全兼容C作為強(qiáng)制性要求。C89、C99中許多的改進(jìn)正是從C++中所引進(jìn)。可見(jiàn),Stroustrup對(duì)C語(yǔ)言的貢獻(xiàn)非常之大。今天不管你對(duì)C++怎么看,C++的確擴(kuò)展和進(jìn)化了C,對(duì)C造成了深遠(yuǎn)的影響。
2)Stroustrup對(duì)于C的抱怨主要來(lái)源于兩個(gè)方面——在C++兼容C的過(guò)程中遇到了不少設(shè)計(jì)實(shí)現(xiàn)上的麻煩;以及守舊的K&R C程序員對(duì)Stroustrup的批評(píng)。很多人說(shuō)C++的惡夢(mèng)就是要去兼容于C,這并不無(wú)道理(Java就干的比C++徹底得多),但這并不是Stroustrup考慮的,Stroustrup一邊在使盡渾身解數(shù)來(lái)兼容C,另一方面在拼命地優(yōu)化C。
3)Stroustrup在書(shū)中直接說(shuō),C++最大的競(jìng)爭(zhēng)對(duì)手正是C,他的目的就是——C能做到的,C++也必須做到,而且要做的更好。大家覺(jué)得是不是做到了?有多少做到了,有多少還沒(méi)有做到?
4)對(duì)于同時(shí)關(guān)注的運(yùn)行效率和開(kāi)發(fā)效率的程序員,Stroustrup多次強(qiáng)調(diào)C++的目標(biāo)是——“在保證效率與C語(yǔ)言相當(dāng)?shù)那闆r下,加強(qiáng)程序的組織性;能保證同樣功能的程序,C++更短小”,這正是淺封裝的核心思想。而不是過(guò)渡設(shè)計(jì)的OO。(參看:面向?qū)ο笫莻€(gè)騙局)
5)這本書(shū)中舉了很多例子來(lái)回應(yīng)那些批評(píng)C++有運(yùn)行性能問(wèn)題的人。C++在其第二個(gè)版本中,引入了虛函數(shù)機(jī)制,這是C++效率最大的瓶頸了,但我個(gè)人認(rèn)為虛函數(shù)就是多了一次加法運(yùn)算,但讓我們的代碼能有更好的組織,極大增加了程序的閱讀和降底了維護(hù)成本。(注:Lippman的《深入探索C++對(duì)象模型》也說(shuō)明了C++不比C的程序在運(yùn)行性能低。Bruce的《Think in C++》也說(shuō)C++和C的性能相差只有5%)
6)這本書(shū)中還講了一些C++的痛苦的取舍,印象最深的就是多重繼承,提出,拿掉,再被提出,反復(fù)很多次,大家在得與失中不斷地辯論和取舍。這個(gè)過(guò)程讓我最大的收獲是——a) 對(duì)于任何一種設(shè)計(jì)都有好有壞,都只能偏重一方,b) 完全否定式的批評(píng)是不好的心態(tài),好的心態(tài)應(yīng)該是建設(shè)性地批評(píng)。
我對(duì)C++的感情
我先說(shuō)說(shuō)我學(xué)C++的經(jīng)歷。
我畢業(yè)時(shí),是直接從C跳過(guò)C++學(xué)Java的,但是學(xué)Java的時(shí)候,不知道為什么Java要設(shè)計(jì)成這樣,只好回頭看C++,結(jié)果學(xué)C++的時(shí)候又有很多不懂,又只得回頭看C,最后發(fā)現(xiàn),C -> C++ -> Java的過(guò)程,就是C++填C的坑,Java填C++的坑的過(guò)程。
注,下面這些東西可以看到Java在填C/C++坑:
- Java徹底廢棄了指針(指針這個(gè)東西,絕對(duì)讓這個(gè)社會(huì)有幾百億的損失),使用引用。
- Java用GC解決了C++的各種內(nèi)存問(wèn)題的詬病,當(dāng)然也帶來(lái)了GC的問(wèn)題,不過(guò)功大于過(guò)。
- Java對(duì)異常的支持比C++更嚴(yán)格,讓編程更方便了。
- Java沒(méi)有像C++那樣的template/macro/函數(shù)對(duì)象/操作符重載,泛型太晦澀,用OO更容易一些。
- Java改進(jìn)了C++的構(gòu)造、析構(gòu)、拷貝構(gòu)造、賦值。
- Java對(duì)完全拋棄了C/C++這種面向過(guò)程的編程方式,并廢棄了多重繼承,更OO(如:用接口來(lái)代替多重繼承)
- Java比較徹底地解決了C/C++自稱(chēng)多年的跨平臺(tái)技術(shù)。
- Java的反射機(jī)制把這個(gè)語(yǔ)言提升了一個(gè)高度,在這個(gè)上面可以構(gòu)建各種高級(jí)用法。
- C/C++沒(méi)有一些比較好的類(lèi)庫(kù),比如UI,線(xiàn)程 ,I/O,字符串處理等。(C++0x補(bǔ)充了一些)
- 等等……
當(dāng)然時(shí)代還在前進(jìn),這個(gè)演變的過(guò)程還在C#和Go上體現(xiàn)著。不過(guò)我學(xué)習(xí)了C -> C++ -> Java這個(gè)填坑演進(jìn)的過(guò)程,讓我明白了很多東西:
- 我明白了OO是怎么一回事,重要的是明白了OO的封裝,繼承,和多態(tài)是怎么實(shí)現(xiàn)的。(參看我以前寫(xiě)過(guò)的《C++虛函數(shù)表解析》和《C++對(duì)象內(nèi)存布局》)
- 我明白了STL的泛型編程和Java的各種花哨的技術(shù)是怎么一回事,以及那些很花哨的編程方法和技術(shù)。
- 我明白了C,C++,Java的各中坑,這就好像玩火一樣,我知道怎么玩火不會(huì)燒身了。
我從這個(gè)學(xué)習(xí)過(guò)程中得到的最大的收獲不是語(yǔ)言本身,而是各式各樣的編程技術(shù)和方法,和技術(shù)的演進(jìn)的過(guò)程,這比語(yǔ)言本身更重要!(在這個(gè)角度上學(xué)習(xí),你看到的不是一個(gè)又一個(gè)的坑,你看到的是——各式各樣讓你可以爬得更高的梯子)
我對(duì)C++的感情有三個(gè)過(guò)程:先是喜歡地要死,然后是恨地要死,現(xiàn)在的又愛(ài)又恨,愛(ài)的是這個(gè)語(yǔ)言,恨的是很多不合格的人在濫用和凌辱它。
C++的未來(lái)
C++語(yǔ)言發(fā)展大概可以分為三個(gè)階段(摘自Wikipedia):
- 第一階段從80年代到1995年。這一階段C++語(yǔ)言基本上是傳統(tǒng)類(lèi)型上的面向?qū)ο笳Z(yǔ)言,并且憑借著接近C語(yǔ)言的效率,在工業(yè)界使用的開(kāi)發(fā)語(yǔ)言中占據(jù)了相當(dāng)大份額;
- 第二階段從1995年到2000年,這一階段由于標(biāo)準(zhǔn)模板庫(kù)(STL)和后來(lái)的Boost等程式庫(kù)的出現(xiàn),泛型程式設(shè)計(jì)在C++中占據(jù)了越來(lái)越多的比重性。當(dāng)然,同時(shí)由于Java、C#等語(yǔ)言的出現(xiàn)和硬件價(jià)格的大規(guī)模下降,C++受到了一定的沖擊;
- 第三階段從2000年至今,由于以L(fǎng)oki、MPL等程式庫(kù)為代表的產(chǎn)生式編程和模板元編程的出現(xiàn),C++出現(xiàn)了發(fā)展歷史上又一個(gè)新的高峰,這些新技術(shù)的出現(xiàn)以及和原有技術(shù)的融合,使C++已經(jīng)成為當(dāng)今主流程式設(shè)計(jì)語(yǔ)言中最復(fù)雜的一員。
在《Why C++? 王者歸來(lái)》中說(shuō)了 ,性能主要就是要省電,省電就是省錢(qián),在數(shù)據(jù)中心還不明顯,在手機(jī)上就更明顯了,這就是為什么Android 支持C++的原因。所以,在NB的電池或是能源出現(xiàn)之前,如果你需要注重程序的運(yùn)行性能和開(kāi)發(fā)效率,并更關(guān)注程序的運(yùn)性能,那么,應(yīng)該首選 C++。這就是iOS開(kāi)發(fā)也支持C++的原因。
今天的C++11中不但有更多更不錯(cuò)的東西,而且,還填了更多原來(lái)C++的坑。(參看:C++11 Wiki,C++ 11的主要特性)
總結(jié)
- C++并不完美,但學(xué)C++必然讓你受益無(wú)窮。
- 是那些不合格的、想對(duì)編程速成的程序員讓C++變得坑多。
最后,非常感謝能和“@簡(jiǎn)悅云風(fēng)”,“@淘寶諸霸”,“@Laruence”一起討論這個(gè)問(wèn)題!無(wú)論你們的觀(guān)點(diǎn)怎么樣,我都和你們“在一起”,嘿嘿嘿……
(全文完)
posted @
2012-08-06 12:58 Seraphi 閱讀(428) |
評(píng)論 (0) |
編輯 收藏轉(zhuǎn)載Cool Shell,作者:陳皓
From:http://coolshell.cn/articles/2250.html
下面是一個(gè)《Teach Yourself C++ in 21 Days》的流程圖,請(qǐng)各位程序員同仁認(rèn)真領(lǐng)會(huì)。如果有必要,你可以查看這個(gè)圖書(shū)以作參照:http://www.china-pub.com/27043

看完上面這個(gè)圖片,我在想,我學(xué)習(xí)C++有12年了,好像C++也沒(méi)有學(xué)得特別懂,看到STL和泛型,還是很頭大。不過(guò),我應(yīng)該去考慮研究量子物理和生物化學(xué),這樣,我才能重返98年殺掉還在大學(xué)的我,然后達(dá)到21天搞定C++的目標(biāo)。另外,得要特別提醒剛剛開(kāi)始學(xué)習(xí)C++的朋友,第21天的時(shí)候,小心被人殺害。呵呵。
當(dāng)然,上面只是一個(gè)惡搞此類(lèi)圖片,學(xué)習(xí)一門(mén)技術(shù),需要你很長(zhǎng)的時(shí)間,正如圖片中的第三圖和第四圖所示,你需要用十年的時(shí)間去不斷在嘗試,并在錯(cuò)誤中總結(jié)經(jīng)驗(yàn)教訓(xùn),以及在項(xiàng)目開(kāi)發(fā)中通過(guò)與別人相互溝通互相學(xué)習(xí)來(lái)歷練自己。你才能算得上是真正學(xué)會(huì)。
這里有篇文章叫《Teach Yourself Programming in Ten Years》,網(wǎng)上有人翻譯了一下,不過(guò)原文已被更新了,我把網(wǎng)上的譯文轉(zhuǎn)載并更新如下:
用十年來(lái)學(xué)編程
Peter Norvig
為什么每個(gè)人都急不可耐?
走進(jìn)任何一家書(shū)店,你會(huì)看見(jiàn)《Teach Yourself Java in 7 Days》(7天Java無(wú)師自通)的旁邊是一長(zhǎng)排看不到盡頭的類(lèi)似書(shū)籍,它們要教會(huì)你Visual Basic、Windows、Internet等等,而只需要幾天甚至幾小時(shí)。我在
Amazon.com上進(jìn)行了如下
搜索:
結(jié)論是,要么是人們非常急于學(xué)會(huì)計(jì)算機(jī),要么就是不知道為什么計(jì)算機(jī)驚人地簡(jiǎn)單,比任何東西都容易學(xué)會(huì)。沒(méi)有一本書(shū)是要在幾天里教會(huì)人們欣賞貝多芬或者量子物理學(xué),甚至怎樣給狗打扮。在《
How to Design Programs》這本書(shū)里說(shuō)“
Bad programming is easy. Idiots can learn it in 21 days, even if they are dummies.” (壞的程序是很容易的,就算他們是笨蛋白癡都可以在21天內(nèi)學(xué)會(huì)。)
- 學(xué)會(huì):在3天時(shí)間里,你不夠時(shí)間寫(xiě)一些有意義的程序,并從它們的失敗與成功中學(xué)習(xí)。你不夠時(shí)間跟一些有經(jīng)驗(yàn)的程序員一起工作,你不會(huì)知道在C++那樣的環(huán)境中是什么滋味。簡(jiǎn)而言之,沒(méi)有足夠的時(shí)間讓你學(xué)到很多東西。所以這些書(shū)談?wù)摰闹皇潜砻嫔系木ǎ巧钊氲睦斫狻H鏏lexander Pope(英國(guó)詩(shī)人、作家,1688-1744)所言,一知半解是危險(xiǎn)的(a little learning is a dangerous thing)
- C++:在3天時(shí)間里你可以學(xué)會(huì)C++的語(yǔ)法(如果你已經(jīng)會(huì)一門(mén)類(lèi)似的語(yǔ)言),但你無(wú)法學(xué)到多少如何運(yùn)用這些語(yǔ)法。簡(jiǎn)而言之,如果你是,比如說(shuō)一個(gè)Basic程序員,你可以學(xué)會(huì)用C++語(yǔ)法寫(xiě)出Basic風(fēng)格的程序,但你學(xué)不到C++真正的優(yōu)點(diǎn)(和缺點(diǎn))。那關(guān)鍵在哪里?Alan Perlis(ACM第一任主席,圖靈獎(jiǎng)得主,1922-1990)曾經(jīng)說(shuō)過(guò):“如果一門(mén)語(yǔ)言不能影響你對(duì)編程的想法,那它就不值得去學(xué)”。另一種觀(guān)點(diǎn)是,有時(shí)候你不得不學(xué)一點(diǎn)C++(更可能是javascript和Flash Flex之類(lèi))的皮毛,因?yàn)槟阈枰佑|現(xiàn)有的工具,用來(lái)完成特定的任務(wù)。但此時(shí)你不是在學(xué)習(xí)如何編程,你是在學(xué)習(xí)如何完成任務(wù)。
- 3天:不幸的是,這是不夠的,正如下一節(jié)所言。
10年學(xué)編程
一些研究者(
Bloom (1985),
Bryan & Harter (1899),
Hayes (1989),
Simmon & Chase (1973))的研究表明,在許多領(lǐng)域,都需要大約10 年時(shí)間才能培養(yǎng)出專(zhuān)業(yè)技能,包括國(guó)際象棋、作曲、繪畫(huà)、鋼琴、游泳、網(wǎng)球,以及神經(jīng)心理學(xué)和拓?fù)鋵W(xué)的研究。似乎并不存在真正的捷徑:即使是莫扎特,他4 歲就顯露出音樂(lè)天才,在他寫(xiě)出世界級(jí)的音樂(lè)之前仍然用了超過(guò)13年時(shí)間。再看另一種音樂(lè)類(lèi)型的披頭士,他們似乎是在1964年的Ed Sullivan節(jié)目中突然冒頭的。但其實(shí)他們從1957年就開(kāi)始表演了,即使他們很早就顯示出了巨大的吸引力,他們第一次真正的成功——Sgt. Peppers——也要到1967年才發(fā)行。
Malcolm Gladwell 研究報(bào)告稱(chēng),把在伯林音樂(lè)學(xué)院學(xué)生一個(gè)班的學(xué)生按水平分成高中低,然后問(wèn)他們對(duì)音樂(lè)練習(xí)花了多少工夫:
在這三個(gè)小組中的每一個(gè)人基本上都是從相同的時(shí)間開(kāi)始練習(xí)的(在五歲的時(shí)候)。在開(kāi)始的幾年里,每個(gè)人都是每周練習(xí)2-3個(gè)小時(shí)。但是在八歲的時(shí)候,練習(xí)的強(qiáng)度開(kāi)始顯現(xiàn)差異。在這個(gè)班中水平最牛的人開(kāi)始比別人練習(xí)得更多——在九歲的時(shí)候每周練習(xí)6個(gè)小時(shí),十二歲的時(shí)候,每周8個(gè)小時(shí),十四歲的時(shí)候每周16個(gè)小時(shí),并在成長(zhǎng)過(guò)程中練習(xí)得越來(lái)越多,到20歲的時(shí)候,其每周練習(xí)可超過(guò)30個(gè)小時(shí)。到了20歲,這些優(yōu)秀者在其生命中練習(xí)音樂(lè)總共超過(guò) 10,000 小時(shí)。與之對(duì)比,其它人只平均有8,000小時(shí),而未來(lái)只能留校當(dāng)老師的人僅僅是4,000 小時(shí)。
所以,這也許需要10,000 小時(shí),并不是十年,但這是一個(gè)magic number。Samuel Johnson(英國(guó)詩(shī)人)認(rèn)為10 年還是不夠的:“任何領(lǐng)域的卓越成就都只能通過(guò)一生的努力來(lái)獲得;稍低一點(diǎn)的代價(jià)也換不來(lái)。”(Excellence in any department can be attained only by the labor of a lifetime; it is not to be purchased at a lesser price.) 喬叟(Chaucer,英國(guó)詩(shī)人,1340-1400)也抱怨說(shuō):“生命如此短暫,掌握技藝卻要如此長(zhǎng)久。”(the lyf so short, the craft so long to lerne.)
下面是我在編程這個(gè)行當(dāng)里獲得成功的處方:
- 對(duì)編程感興趣,因?yàn)闃?lè)趣而去編程。確定始終都能保持足夠的樂(lè)趣,以致你能夠?qū)?0年時(shí)間投入其中。
- 跟其他程序員交談;閱讀其他程序。這比任何書(shū)籍或訓(xùn)練課程都更重要。
- 編程。最好的學(xué)習(xí)是從實(shí)踐中學(xué)習(xí)。用更加技術(shù)性的語(yǔ)言來(lái)講,“個(gè)體在特定領(lǐng)域最高水平的表現(xiàn)不是作為長(zhǎng)期的經(jīng)驗(yàn)的結(jié)果而自動(dòng)獲得的,但即使是非常富有經(jīng)驗(yàn)的個(gè)體也可以通過(guò)刻意的努力而提高其表現(xiàn)水平。”(p. 366),而且“最有效的學(xué)習(xí)要求為特定個(gè)體制定適當(dāng)難度的任務(wù),有意義的反饋,以及重復(fù)及改正錯(cuò)誤的機(jī)會(huì)。”(p. 20-21)《Cognition in Practice: Mind, Mathematics, and Culture in Everyday Life》(在實(shí)踐中認(rèn)知:心智、數(shù)學(xué)和日常生活的文化)是關(guān)于這個(gè)觀(guān)點(diǎn)的一本有趣的參考書(shū)。
- 如果你愿意,在大學(xué)里花上4年時(shí)間(或者再花幾年讀研究生)。這能讓你獲得一些工作的入門(mén)資格,還能讓你對(duì)此領(lǐng)域有更深入的理解,但如果你不喜歡進(jìn)學(xué)校,(作出一點(diǎn)犧牲)你在工作中也同樣能獲得類(lèi)似的經(jīng)驗(yàn)。在任何情況下,單從書(shū)本上學(xué)習(xí)都是不夠的。“計(jì)算機(jī)科學(xué)的教育不會(huì)讓任何人成為內(nèi)行的程序員,正如研究畫(huà)筆和顏料不會(huì)讓任何人成為內(nèi)行的畫(huà)家”, Eric Raymond,《The New Hacker’s Dictionary》(新黑客字典)的作者如是說(shuō)。我曾經(jīng)雇用過(guò)的最優(yōu)秀的程序員之一僅有高中學(xué)歷;但他創(chuàng)造出了許多偉大的軟件(XEmacs, Mozilla),甚至有討論他本人的新聞組,而且股票期權(quán)讓他達(dá)到我無(wú)法企及的富有程度(譯注:指Jamie Zawinski,Xemacs和Netscape的作者)。
- 跟別的程序員一起完成項(xiàng)目。在一些項(xiàng)目中成為最好的程序員;在其他一些項(xiàng)目中當(dāng)最差的一個(gè)。當(dāng)你是最好的程序員時(shí),你要測(cè)試自己領(lǐng)導(dǎo)項(xiàng)目的能力,并通過(guò)你的洞見(jiàn)鼓舞其他人。當(dāng)你是最差的時(shí)候,你學(xué)習(xí)高手們?cè)谧鲂┦裁矗约八麄儾幌矚g做什么(因?yàn)樗麄冏屇銕退麄冏瞿切┦拢?/li>
- 接手別的程序員完成項(xiàng)目。用心理解別人編寫(xiě)的程序。看看在沒(méi)有最初的程序員在場(chǎng)的時(shí)候理解和修改程序需要些什么。想一想怎樣設(shè)計(jì)你的程序才能讓別人接手維護(hù)你的程序時(shí)更容易一些。
- 學(xué)會(huì)至少半打編程語(yǔ)言。包括一門(mén)支持類(lèi)抽象(class abstraction)的語(yǔ)言(如Java或C++),一門(mén)支持函數(shù)抽象(functional abstraction)的語(yǔ)言(如Lisp或ML),一門(mén)支持句法抽象(syntactic abstraction)的語(yǔ)言(如Lisp),一門(mén)支持說(shuō)明性規(guī)約(declarative specification)的語(yǔ)言(如Prolog或C++模版),一門(mén)支持協(xié)程(coroutine)的語(yǔ)言(如Icon或Scheme),以及一門(mén)支持并行處理(parallelism)的語(yǔ)言(如Sisal)。
- 記住在“計(jì)算機(jī)科學(xué)”這個(gè)詞組里包含“計(jì)算機(jī)”這個(gè)詞。了解你的計(jì)算機(jī)執(zhí)行一條指令要多長(zhǎng)時(shí)間,從內(nèi)存中取一個(gè)word要多長(zhǎng)時(shí)間(包括緩存命中和未命中的情況),從磁盤(pán)上讀取連續(xù)的數(shù)據(jù)要多長(zhǎng)時(shí)間,定位到磁盤(pán)上的新位置又要多長(zhǎng)時(shí)間。(答案在這里)
- 嘗試參與到一項(xiàng)語(yǔ)言標(biāo)準(zhǔn)化工作中。可以是ANSI C++委員會(huì),也可以是決定自己團(tuán)隊(duì)的編碼風(fēng)格到底采用2個(gè)空格的縮進(jìn)還是4個(gè)。不論是哪一種,你都可以學(xué)到在這門(mén)語(yǔ)言中到底人們喜歡些什么,他們有多喜歡,甚至有可能稍微了解為什么他們會(huì)有這樣的感覺(jué)。
- 擁有盡快從語(yǔ)言標(biāo)準(zhǔn)化工作中抽身的良好判斷力。
抱著這些想法,我很懷疑從書(shū)上到底能學(xué)到多少東西。在我第一個(gè)孩子出生前,我讀完了所有“怎樣……”的書(shū),卻仍然感到自己是個(gè)茫無(wú)頭緒的新手。30個(gè)月后,我第二個(gè)孩子出生的時(shí)候,我重新拿起那些書(shū)來(lái)復(fù)習(xí)了嗎?不。相反,我依靠我自己的經(jīng)驗(yàn),結(jié)果比專(zhuān)家寫(xiě)的幾千頁(yè)東西更有用更靠得住。
Fred Brooks在他的短文《No Silver Bullets》(沒(méi)有銀彈)中確立了如何發(fā)現(xiàn)杰出的軟件設(shè)計(jì)者的三步規(guī)劃:
- 盡早系統(tǒng)地識(shí)別出最好的設(shè)計(jì)者群體。
- 指派一個(gè)事業(yè)上的導(dǎo)師負(fù)責(zé)有潛質(zhì)的對(duì)象的發(fā)展,小心地幫他保持職業(yè)生涯的履歷。
- 讓成長(zhǎng)中的設(shè)計(jì)師們有機(jī)會(huì)互相影響,互相激勵(lì)。
這實(shí)際上是假定了有些人本身就具有成為杰出設(shè)計(jì)師的必要潛質(zhì);要做的只是引導(dǎo)他們前進(jìn)。Alan Perlis說(shuō)得更簡(jiǎn)潔:“每個(gè)人都可以被教授如何雕塑;而對(duì)米開(kāi)朗基羅來(lái)說(shuō),能教給他的倒是怎樣能夠不去雕塑。杰出的程序員也一樣”。
所以盡管去買(mǎi)那些Java書(shū);你很可能會(huì)從中找到些用處。但你的生活,或者你作為程序員的真正的專(zhuān)業(yè)技術(shù),并不會(huì)因此在24小時(shí)、24天甚至24個(gè)月內(nèi)發(fā)生真正的變化。
(全文完)
posted @
2012-08-06 12:56 Seraphi 閱讀(352) |
評(píng)論 (0) |
編輯 收藏
注:如果看不到圖片,請(qǐng)右鍵圖片獲得圖片地址,然后在瀏覽中訪(fǎng)問(wèn)圖片地址即可~
1.去下載LINUX上使用的BIN文件,去www.java.sun.com,最終會(huì)到ORACLE網(wǎng)站上去,因?yàn)镾UN被收購(gòu)了嘛,下載JDK,名稱(chēng)為jdk-6u22-linux-i586.bin,然后去www.eclipse.org,下載eclipse,筆者下載的是JAVA EE版的,文件名稱(chēng)為eclipse-jee-helios-SR1-linux-gtk.tar.gz,因?yàn)檫@個(gè)工具多,比較適合WEB等開(kāi)發(fā)。路徑


2.本人的文件目錄放在/home/heroguo/下載,使用tar命令解壓(這個(gè)具體可以去查找資料或者tar -help)eclipse,會(huì)生成eclipse文件夾。mv到/home文件夾。
3、安裝JDK,使用終端,運(yùn)行下載下來(lái)的jdk-6u22-linux-i586.bin。
第一步,將目錄CD到/home/heroguo/下載。
第二步,使用命令./jdk-6u22-linux-i586.bin,等待中,直到完成。完成后,會(huì)在當(dāng)前目錄下生成一個(gè)JDK1.6.0_22的文件夾。
第三步,使用mv命令將JDK1.6.0_22到/home文件夾。
4.環(huán)境變量
用文本編輯器打開(kāi)/etc/profile
·在profile文件末尾加入:
export JAVA_HOME=/usr/share/jdk1.6.0_14
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
注意:千萬(wàn)不要范和筆者一樣的錯(cuò),狂暈,寫(xiě)PATH的時(shí)候,前面的$PATH 沒(méi)有寫(xiě),導(dǎo)致PATH路徑下所有位置被覆蓋,包括寫(xiě)命令都得打完整路徑,汗死!!路徑之間用:隔開(kāi)
這一步很重要:重啟ubuntu,在終端中輸入java –version,查看版本號(hào)

看到上面按要求1.6.0_22證明JDK被正確安裝了
5.用終端將當(dāng)前目錄CD為 /home/heroguo/eclipse,使用命令./eclipse,可以看到eclipse開(kāi)始運(yùn)行了。

彈出eclipse工作目錄設(shè)置,OK基本JAVA開(kāi)發(fā)環(huán)境也搞定了。

進(jìn)行WEB開(kāi)發(fā),再去下個(gè)TOMCAT,由于TOMCAT7 剛出來(lái),所以選擇了TOMCAT6,方法和WINDOWS上一樣的,就不再贅述了,哈哈,休息哈去!
轉(zhuǎn)貼:原文鏈接:
http://blog.csdn.net/guoleimail/article/details/5960244
posted @
2012-05-10 12:09 Seraphi 閱讀(994) |
評(píng)論 (1) |
編輯 收藏怎樣做研究(一)
幾年前,我寫(xiě)了一套膠片,題目是《怎樣做研究》,多次在實(shí)驗(yàn)室內(nèi)部給學(xué)生們做報(bào)告,也曾對(duì)外講過(guò)一次,聽(tīng)眾反應(yīng)良好。也有網(wǎng)友讀過(guò)這套膠片,給我來(lái)信稱(chēng)有所收獲。然而,膠片中的文字畢竟只是提綱攜領(lǐng),無(wú)法充分闡述我的想法,為此,借周末一點(diǎn)閑暇,把《怎樣做研究》寫(xiě)成一篇文章,與師友切磋。
什么是科學(xué)
科學(xué)是分科的學(xué)問(wèn),客觀(guān)地說(shuō),是起源于西方的。中國(guó)只有經(jīng)驗(yàn)科學(xué),典型的如中醫(yī)。我的母親是學(xué)中醫(yī)的,我從小就對(duì)中醫(yī)耳濡目染,生了病,媽媽就會(huì)請(qǐng)他的老師來(lái),一貼小藥下去,我的病就好了。因此,我對(duì)中醫(yī)一直是很信服的。然而,近些年來(lái),中醫(yī)多受批評(píng),發(fā)展也越來(lái)越緩慢,究其原因,中醫(yī)不是科學(xué),或者說(shuō)只是經(jīng)驗(yàn)科學(xué),而非實(shí)證科學(xué)。中藥的成分以及生化功效不曾用實(shí)驗(yàn)進(jìn)行深入的分析,望聞問(wèn)切的診斷方法完全憑經(jīng)驗(yàn)而無(wú)法量化,陰陽(yáng)五行的理論似是而非,祖?zhèn)髅胤降膫鞒蟹绞脚c知識(shí)共享的現(xiàn)代思維背道而馳。因此,盡管中醫(yī)有診治的整體觀(guān)和方劑的個(gè)性化兩大優(yōu)點(diǎn),但其停留于經(jīng)驗(yàn)層面,而遲遲不能進(jìn)入科學(xué)的殿堂,因此在現(xiàn)代社會(huì)中的發(fā)展必然步履維艱。
中醫(yī)不是科學(xué),那到底什么是科學(xué)呢?科學(xué)(自然科學(xué))是人們用來(lái)認(rèn)識(shí)和改造自然世界的思維武器,科學(xué)研究可以分為基礎(chǔ)研究(理論研究)和應(yīng)用研究(技術(shù)研發(fā))。
基礎(chǔ)研究
萬(wàn)事萬(wàn)物皆有其規(guī)律,掌握并且利用這些規(guī)律就能夠?yàn)槿祟?lèi)造福,這些規(guī)律是隱蔽在紛繁復(fù)雜的現(xiàn)象背后的,要識(shí)破大自然的奧秘,讀懂上帝的天書(shū),非要下一番深入觀(guān)察和探究的功夫不可。以揭示規(guī)律為目的的研究活動(dòng)屬于基礎(chǔ)研究,從事這些活動(dòng)的學(xué)者是科學(xué)家。規(guī)律不是被創(chuàng)造出來(lái)的,而是早已存在的,人們只有認(rèn)識(shí)規(guī)律的權(quán)利,而沒(méi)有創(chuàng)造規(guī)律的可能。
從根本上講,推動(dòng)基礎(chǔ)研究的也是人們?cè)谏a(chǎn)生活中的一些實(shí)際需要,但是隨著基礎(chǔ)研究的深入,理論已經(jīng)成為一個(gè)龐大的體系,理論研究早已開(kāi)始按照它自有的邏輯獨(dú)立發(fā)展,而不必時(shí)時(shí)刻刻聯(lián)系實(shí)際需要,比如著名的歌德巴赫猜想,可能在百年之后,發(fā)現(xiàn)其有重大的應(yīng)用價(jià)值,但是目前到底有什么用,誰(shuí)也說(shuō)不清楚。理論的價(jià)值在今天這個(gè)非常講求短期功利的社會(huì)中常常被忽視,現(xiàn)在有一種傾向認(rèn)為只有產(chǎn)生實(shí)際經(jīng)濟(jì)效益的科研工作才有價(jià)值,這種極端化的觀(guān)點(diǎn)顯然是錯(cuò)誤的,我們必須承認(rèn)并高度尊重理論研究者的成就。
理論研究的直接動(dòng)力是科學(xué)家的好奇心,以及他們對(duì)科學(xué)榮譽(yù)的渴望。越是單純的科學(xué)家越有希望發(fā)現(xiàn)真理,他們的科學(xué)探索有點(diǎn)像迷宮探寶或者海邊拾貝,偉大的科學(xué)家都是沒(méi)有喪失童趣的人,他們?cè)趯?shí)驗(yàn)室里是寧?kù)o而愉快的,他們是樂(lè)此不疲的,很多在常人看來(lái)難以忍受的寂寞在他們看來(lái)卻是一種幸福。越是找不到答案,越是激發(fā)探索的熱情,在一次次的失敗中積累著煩悶與緊張,在終于取得突破后興奮異常。與此同時(shí),也必須承認(rèn)科學(xué)榮譽(yù)也是激勵(lì)科學(xué)家們前進(jìn)的重要?jiǎng)恿Γ灰獎(jiǎng)e把榮譽(yù)看得高于真理,貨真價(jià)實(shí)的榮譽(yù)仍然是值得追求的。
理論上的突破對(duì)應(yīng)用研究產(chǎn)生持續(xù)不斷的推動(dòng)力,在模式識(shí)別領(lǐng)域,神經(jīng)網(wǎng)絡(luò)、支持向量機(jī)、條件隨機(jī)域等等機(jī)器學(xué)習(xí)技術(shù)不斷出現(xiàn),每當(dāng)一項(xiàng)理論出現(xiàn),應(yīng)用研究者們爭(zhēng)相將其應(yīng)用于自己的研究課題中,于是基于神經(jīng)網(wǎng)絡(luò)、基于支持向量機(jī)、基于條件隨機(jī)域的某某研究就成為一個(gè)標(biāo)準(zhǔn)的論文題目。首先把某項(xiàng)理論應(yīng)用于某個(gè)實(shí)際課題的研究工作應(yīng)該說(shuō)還是具有一定的創(chuàng)新性的,畢竟用一個(gè)新的思路、新的模型去觀(guān)察了一個(gè)舊的課題,HMM在語(yǔ)音識(shí)別上的成功應(yīng)用就是一例。有人比喻說(shuō),理論工具仿佛是錘子,實(shí)際課題好比是釘子,一個(gè)新的錘子被打造出來(lái),大家都借用過(guò)來(lái)砸一砸自己手頭的釘子,確屬常理。不過(guò),需要注意的事,如果拿一個(gè)碩大無(wú)比的汽錘去砸一個(gè)纖細(xì)的大頭針就荒誕可笑了,不注意思考問(wèn)題與理論的適配關(guān)系而盲目跟風(fēng)的事情在學(xué)術(shù)界也是司空見(jiàn)慣,比如我們就曾用HMM試圖解決詞義消歧的問(wèn)題,而每個(gè)多義詞的詞義跟它前后一兩個(gè)詞并沒(méi)有緊密的關(guān)系,因此詞義消歧貌似和詞性標(biāo)注一樣屬于線(xiàn)性序列標(biāo)注問(wèn)題,其實(shí)是有根本差別的。
應(yīng)用研究
我們是搞計(jì)算機(jī)的,計(jì)算機(jī)是一門(mén)應(yīng)用科學(xué),應(yīng)用科學(xué)是由應(yīng)用驅(qū)動(dòng)的。時(shí)至今日,數(shù)學(xué)定理和物理學(xué)定律似乎已經(jīng)被先哲們發(fā)現(xiàn)的差不多了,因此整個(gè)科學(xué)界中純粹搞理論研究的人越來(lái)越少,很多大學(xué)教授都和工業(yè)界有著密切的聯(lián)系,很多大企業(yè)也開(kāi)辦企業(yè)研究院,這些導(dǎo)致應(yīng)用科學(xué)的研究如火如荼。最近,國(guó)家863設(shè)立了一個(gè)"中文為核心的多語(yǔ)言信息處理"重點(diǎn)項(xiàng)目,總經(jīng)費(fèi)7000萬(wàn),這在多年前的大陸語(yǔ)言處理界完全是不可想象的。
應(yīng)用驅(qū)動(dòng),也可以說(shuō)是市場(chǎng)驅(qū)動(dòng)。市場(chǎng)是一個(gè)精靈古怪的家伙,搞應(yīng)用研究的人如果對(duì)市場(chǎng)的未來(lái)沒(méi)有一個(gè)基本準(zhǔn)確地判斷,往往會(huì)導(dǎo)致選題上的偏差。二十年前,國(guó)內(nèi)一些研究者開(kāi)始研究漢字手寫(xiě)輸入技術(shù),開(kāi)始人們覺(jué)得從鍵盤(pán)輸入漢字很困難,手寫(xiě)輸入一定有前途,但是很快,拼音輸入法大面積普及,而且拼音輸入的速度遠(yuǎn)比在手寫(xiě)板上輸入漢字快得多,于是漢字手寫(xiě)輸入套件根本賣(mài)不動(dòng),前景黯淡。有人開(kāi)始猶豫,有人開(kāi)始轉(zhuǎn)向搞印刷體漢字識(shí)別等,但忽然有一天,集成了手寫(xiě)功能的商務(wù)通大量熱銷(xiāo),人們忽然發(fā)現(xiàn)原來(lái)在手持設(shè)備上由于鍵盤(pán)太小,輸入不便,給手寫(xiě)功能留下了很大的應(yīng)用空間。一直專(zhuān)注于手寫(xiě)識(shí)別的漢王公司也借著商務(wù)通的熱銷(xiāo)而把多年的科研成果成功地產(chǎn)業(yè)化了。再舉一個(gè)例子:5年前,我認(rèn)為以圖像為輸入的圖像檢索沒(méi)有什么應(yīng)用價(jià)值,問(wèn)這些技術(shù)的倡導(dǎo)者,他們也只說(shuō)能夠在數(shù)碼相冊(cè)中可以找到一些應(yīng)用,但近來(lái)聽(tīng)了微軟一些學(xué)者們的演講,他們提到可以用手機(jī)拍下一個(gè)植物的圖片,傳回服務(wù)器,在大量植物圖片庫(kù)中檢索,找到最相似的植物,并給出植物的名稱(chēng),特點(diǎn)等。哈哈,這對(duì)于我這個(gè)五谷不分的人來(lái)說(shuō)實(shí)在是太有幫助了,可見(jiàn)對(duì)于一項(xiàng)技術(shù)是否有用實(shí)在要仔細(xì)思考,不要早下斷言。
技術(shù)和市場(chǎng)是一個(gè)互動(dòng)的關(guān)系,有人認(rèn)為技術(shù)嚴(yán)格地從用戶(hù)的現(xiàn)實(shí)需求出發(fā),這個(gè)觀(guān)點(diǎn)總的來(lái)說(shuō)沒(méi)有錯(cuò),但是忽視了技術(shù)創(chuàng)造需求的一面。大多數(shù)用戶(hù)往往并不了解技術(shù)發(fā)展到了什么程度,他們提不出需求來(lái),這時(shí)技術(shù)專(zhuān)家們需要把技術(shù)和產(chǎn)品做出來(lái)給人們看,刺激、引領(lǐng)用戶(hù)的需求,比如數(shù)碼相機(jī),5年前我想大多數(shù)用戶(hù)和我一樣并沒(méi)有淘汰膠卷相機(jī)的強(qiáng)烈要求,但當(dāng)數(shù)碼相機(jī)進(jìn)入市場(chǎng)后,人人都意識(shí)到:原來(lái)我需要這個(gè)東東。
在市場(chǎng)與技術(shù)的互動(dòng)中,總的來(lái)說(shuō),還是市場(chǎng)在引導(dǎo)和拉動(dòng)技術(shù)的發(fā)展。市場(chǎng)需要的是產(chǎn)品,產(chǎn)品往往集成了多項(xiàng)技術(shù),因此一項(xiàng)被市場(chǎng)接受的產(chǎn)品能夠推動(dòng)多項(xiàng)技術(shù)的進(jìn)步。比如搜索引擎,它拉動(dòng)了自然語(yǔ)言處理、并行計(jì)算、海量存儲(chǔ)設(shè)備、數(shù)據(jù)挖掘等等多項(xiàng)技術(shù)的發(fā)展。最近中國(guó)計(jì)算機(jī)學(xué)會(huì)設(shè)立了王選獎(jiǎng),在中國(guó)真正有市場(chǎng)眼光,能夠發(fā)明一項(xiàng)技術(shù),拉動(dòng)一個(gè)行業(yè)的計(jì)算機(jī)專(zhuān)家,王選是第一人。怎樣根據(jù)市場(chǎng)選擇研究方向,設(shè)計(jì)產(chǎn)品,調(diào)整技術(shù)形態(tài),我在后面還有詳細(xì)闡述。
科學(xué)技術(shù)的力量
科學(xué)技術(shù)的力量是巨大的,愛(ài)因斯坦給出的公式E=M*C2,C是光速啊,質(zhì)量乘以光速的平方,這是多么巨大的能量啊,愛(ài)因斯坦的理論直接導(dǎo)致了原子能的利用與開(kāi)發(fā)。基因圖譜的發(fā)現(xiàn)以及后基因組時(shí)代對(duì)基因圖譜的深入分析必將為人類(lèi)征服疾病提供一條嶄新的解決道路,通過(guò)對(duì)損壞的基因進(jìn)行修復(fù),將使無(wú)數(shù)患者得以康復(fù),無(wú)數(shù)家庭重拾幸福。互聯(lián)網(wǎng)的發(fā)明,把全世界連為一體,過(guò)不了多久,石頭里也會(huì)嵌入芯片,在這個(gè)世界上有生命的、無(wú)生命的各種物質(zhì)之間都可能進(jìn)行通訊,人們的生活面貌已經(jīng)徹底改變了。
當(dāng)然,科學(xué)也是雙刃劍:原子彈爆炸了,核戰(zhàn)爭(zhēng)始終威脅著人類(lèi);在對(duì)基因組這套上帝給出生命密碼沒(méi)有全面理解以前,任何盲動(dòng)都可能導(dǎo)致基因污染,以至于玩火自焚;互聯(lián)網(wǎng)上的虛擬生存讓人們感到更加孤獨(dú)。
怎樣做研究(二)
研究的層次
研究是分層次的,很多大科學(xué)家在晚年登上了最高層,比如錢(qián)學(xué)森在80年代倡導(dǎo)思維科學(xué),他對(duì)整個(gè)科學(xué)技術(shù)體系進(jìn)行了重新分類(lèi)。在中國(guó)的大學(xué)里,分為一級(jí)學(xué)科,二級(jí)學(xué)科等,我就處在計(jì)算機(jī)科學(xué)技術(shù)一級(jí)學(xué)科下面的計(jì)算機(jī)應(yīng)用技術(shù)二級(jí)學(xué)科下。二級(jí)學(xué)科的帶頭人稱(chēng)為學(xué)科帶頭人,二級(jí)學(xué)科下面一個(gè)研究方向的帶頭人稱(chēng)為學(xué)術(shù)帶頭人,我就被指定為學(xué)術(shù)帶頭人。
我的研究方向是信息檢索,信息檢索下面又有子方向,比如文本檢索、文本挖掘、跨語(yǔ)言檢索、跨媒體檢索等,子方向下面設(shè)立具體的科研課題,比如文本挖掘中的多文檔自動(dòng)文摘課題,針對(duì)一項(xiàng)課題又有不同的解決辦法,基于事件抽取與集成的多文檔文摘就是利用一種具體的解決問(wèn)題的方法。
總結(jié)來(lái)說(shuō),就是6個(gè)層級(jí):
A. 一級(jí)學(xué)科
B. 二級(jí)學(xué)科
C. 研究方向
D. 子方向
E. 課題
F. 基于某種方法對(duì)課題進(jìn)行的具體研究
君子思不出其位,我是學(xué)術(shù)帶頭人,因此主要在思考C類(lèi)的問(wèn)題,也就是和信息檢索相關(guān)的問(wèn)題。一個(gè)學(xué)院的院長(zhǎng)通常會(huì)思考A類(lèi)的課題,學(xué)科帶頭人或者說(shuō)是一個(gè)博士點(diǎn)的點(diǎn)長(zhǎng)是要考慮B類(lèi)問(wèn)題的。一個(gè)人對(duì)相關(guān)的方向或?qū)W科有所了解,對(duì)自己的研究工作是很有好處的,只有看清了整體的學(xué)科面貌,才能知道自己處在那個(gè)位置上,自己未來(lái)的方向在哪里。我在讀博士以及在微軟做副研究員的時(shí)候,只看到E類(lèi)問(wèn)題,想到最多的是F類(lèi)問(wèn)題,因此你讓我提一個(gè)新方向,讓我對(duì)一項(xiàng)技術(shù)進(jìn)行預(yù)測(cè),我茫然無(wú)知。后來(lái)?yè)?dān)任院長(zhǎng)助理,負(fù)責(zé)學(xué)院的成果轉(zhuǎn)化,需要了解學(xué)院里各個(gè)方向的發(fā)展?fàn)顟B(tài),使我的視野開(kāi)闊了一些。盡管我凡事不求甚解,但是喜歡總結(jié)歸納,因此對(duì)信息檢索與其它學(xué)科的關(guān)系有了更多地認(rèn)識(shí),這對(duì)后來(lái)的選題很有幫助,特別是在應(yīng)用研究方面,心里比較有底。
學(xué)科好比一棵大樹(shù)的樹(shù)根,研究方向如同樹(shù)干,具體的課題就是枝葉了。和學(xué)科中各個(gè)方向都相關(guān)的研究課題是最基礎(chǔ)的研究課題,比如在人工智能中,各類(lèi)機(jī)器學(xué)習(xí)算法是圖像識(shí)別、語(yǔ)音識(shí)別和語(yǔ)言理解等各個(gè)方向都離不開(kāi)的,機(jī)器學(xué)習(xí)技術(shù)提高一步,好比樹(shù)根抬高了一寸,各項(xiàng)應(yīng)用技術(shù)也都跟著進(jìn)步,因此越是基礎(chǔ)的研究,越會(huì)對(duì)業(yè)界產(chǎn)生較大較深遠(yuǎn)的影響力。不過(guò),基礎(chǔ)研究的突破比較難,而在某個(gè)應(yīng)用課題上不考慮一般情況,只考慮具體需要,成功的可能性大。枝葉上的課題做多了,經(jīng)過(guò)合并同類(lèi)項(xiàng),就會(huì)發(fā)現(xiàn)比較共性的基礎(chǔ)課題,比如我們?cè)谧鰡?wèn)答系統(tǒng)、多文檔文摘、例句檢索等課題時(shí)發(fā)現(xiàn)復(fù)述(paraphrasing)是一個(gè)共性的問(wèn)題,于是把復(fù)述單拿出來(lái)展開(kāi)專(zhuān)門(mén)的研究,如此,可以越做越深。
學(xué)者的層次
研究有層次,學(xué)者也有層次,大致可以分為:
A. 大家(劍客):提出問(wèn)題
B. 專(zhuān)家(俠客):解決問(wèn)題
C. 學(xué)徒:修修補(bǔ)補(bǔ)
D. 抄襲者:抄來(lái)抄去
E. 搞偽科學(xué)的人:弄虛作假
A類(lèi)是大家,站得高,看得遠(yuǎn),他們往往能夠前瞻性地提出某個(gè)學(xué)科領(lǐng)域中的若干重大問(wèn)題,最著名的是希爾伯特的23個(gè)問(wèn)題,對(duì)數(shù)學(xué)界影響深遠(yuǎn)。提出問(wèn)題其實(shí)也是解決問(wèn)題的一種方式,只不過(guò)他們是在很高的層面解決問(wèn)題,類(lèi)似一個(gè)軟件系統(tǒng)分析員,他把一個(gè)復(fù)雜的工程問(wèn)題分解為若干個(gè)有機(jī)聯(lián)系的子問(wèn)題,然后宣布只要這幾個(gè)子問(wèn)題解決了,整個(gè)大問(wèn)題也就解決了。至于這幾個(gè)子問(wèn)題到底怎樣解決,或者說(shuō)相應(yīng)的子系統(tǒng)到底怎樣開(kāi)發(fā),他就不管了。胡亂地提問(wèn)題并不難,小孩子也會(huì)向大人提出各種各樣有趣的問(wèn)題,有的大人也答不出來(lái),問(wèn)題的關(guān)鍵在于在適當(dāng)?shù)臅r(shí)候提出適合當(dāng)前學(xué)術(shù)發(fā)展階段的關(guān)鍵性課題,這絕對(duì)不是一般人能夠做到的,這是需要具有對(duì)整個(gè)領(lǐng)域全面深入的理解才行的。
B類(lèi)是專(zhuān)家,是在某個(gè)研究方向上有專(zhuān)長(zhǎng)的人,他們沿著大家指出的方向探索前進(jìn),提出全新的方法體系來(lái)解決問(wèn)題。比如在機(jī)器翻譯領(lǐng)域中,日本長(zhǎng)尾真教授提出了基于實(shí)例的機(jī)器翻譯方法,從一個(gè)全新的視角看待機(jī)器翻譯問(wèn)題。專(zhuān)家經(jīng)驗(yàn)豐富,能夠自由地駕馭課題,穩(wěn)步地推動(dòng)課題的進(jìn)展。
C類(lèi)是學(xué)徒,就是我們這些普通的研究人員了,這部分人的注意力在具體的課題上。學(xué)徒們還沒(méi)有宏大的視野,沒(méi)有捕捉全局戰(zhàn)略要點(diǎn)的本事,也還沒(méi)有在一個(gè)研究方向上提出原創(chuàng)性的解決之道,他們跟在拓荒者后面撿拾麥穗,他們負(fù)責(zé)對(duì)科學(xué)大廈修修補(bǔ)補(bǔ)。他們一會(huì)兒聽(tīng)說(shuō)了一個(gè)新的機(jī)器學(xué)習(xí)方法,趕緊在自己的課題上試一下;一會(huì)兒發(fā)現(xiàn)了一個(gè)以前忽略了的新的特征,立即想方設(shè)法把這個(gè)特征提取出來(lái);一會(huì)兒為了參加一個(gè)技術(shù)評(píng)測(cè),耐心地調(diào)一調(diào)系統(tǒng)參數(shù);一會(huì)兒為了發(fā)表一篇論文構(gòu)造出一個(gè)試驗(yàn)來(lái)。我們每天的研究活動(dòng)差不多都是在這樣進(jìn)行的,很多時(shí)候在原地打轉(zhuǎn)轉(zhuǎn)。
我這樣描述學(xué)徒們的工作情景絲毫沒(méi)有貶低的意味,在達(dá)到專(zhuān)家的水平,證悟研究真諦以前,跌跌撞撞、渾渾沌沌是在所難免的。只要遵守誠(chéng)信之道,不抄襲,不造假,點(diǎn)點(diǎn)滴滴的貢獻(xiàn)對(duì)科學(xué)界也是有幫助的。從更高的要求看,學(xué)徒的目標(biāo)應(yīng)該是成為專(zhuān)家,應(yīng)該時(shí)常靜下心來(lái)想一想,自己的工作是否有價(jià)值,是否有新意,揣摩一下大家們、專(zhuān)家們到底是怎樣思考問(wèn)題的,在不斷地反思與實(shí)踐中向上邁進(jìn)。
D類(lèi)學(xué)者根本算不上學(xué)者,他們?yōu)榱嗽u(píng)職稱(chēng)等目的,對(duì)別人的論文進(jìn)行抄襲拼湊,他們是思想的竊賊,對(duì)學(xué)術(shù)界毫無(wú)貢獻(xiàn)可言。
E類(lèi)學(xué)者不僅僅是做賊了,他編造偽科學(xué),毀壞科學(xué)界在公眾中的形象,他們是科學(xué)界的公敵。
以上的分類(lèi)也只是為了討論的方便,在各類(lèi)之間并沒(méi)有明確的界限,我只是依次談出我心中做學(xué)問(wèn)的境界而已。
在人類(lèi)已知的世界和未知的世界之間有一條動(dòng)態(tài)邊界,科學(xué)家就站在這條邊界上,他們是挑戰(zhàn)未知世界的勇士,他們每向前邁出一步,就意味著整個(gè)人類(lèi)的已知世界向前拓展了一步,由此足見(jiàn)科學(xué)工作的艱難和科學(xué)家的偉大。
研究又好比爬山,一座座山峰如同一個(gè)個(gè)研究領(lǐng)域,大家已登峰造極,一覽眾山小,把東南西北各條山路上的溝溝坎坎,把此山與他山之間的距離關(guān)系看得清清楚楚。隔行如隔山,隔行不隔道,在一個(gè)領(lǐng)域做到頂尖的學(xué)者已入化境,一通百通,你把另一個(gè)領(lǐng)域的問(wèn)題講給他聽(tīng),他往往也能夠很快地抓到要害。專(zhuān)家已到半山腰,看不到山的全貌,但是他找到了一條通往山頂?shù)牡缆罚⒁徊揭徊降叵蛏吓实侵W(xué)徒還沒(méi)有進(jìn)入山門(mén),他們一會(huì)兒仰望山頂,一會(huì)兒看看山腰,在山腳下繞來(lái)繞去找不到門(mén)徑,費(fèi)力不少,卻并沒(méi)有縮短與山頂?shù)木嚯x。
怎樣做研究(三)
怎樣選題
前文曾提到科學(xué)研究的層次,并分了6個(gè)層級(jí)。此處所說(shuō)的選題指的是從C到E三個(gè)層次上的選擇問(wèn)題,即:C. 研究方向、D. 子方向、E. 課題。選擇研究方向是實(shí)驗(yàn)室(Lab)主任們需要重點(diǎn)思考的事情,選擇子方向是研究小組(Group)的組長(zhǎng)們需要重點(diǎn)思考的事情,選擇課題是研究生們需要重點(diǎn)思考的事情。
選擇太多,很容易讓人困惑,要想理出一個(gè)頭緒來(lái),需要一些基本的原則。微軟的許峰雄來(lái)訪(fǎng)時(shí)談到了他選擇課題的三個(gè)標(biāo)準(zhǔn):有足夠的興趣,能成為世界第一,能賺錢(qián)。(!)興趣,這個(gè)原則是非常重要的,我贊同,獲得國(guó)家最高科技獎(jiǎng)的"黃土之父"劉東生院士是搞地球環(huán)境科學(xué)的,經(jīng)常在野外作業(yè),按常人推斷,這該是多么枯燥艱苦的工作啊,但他說(shuō):"枯燥?不!因?yàn)榻?jīng)常有新發(fā)現(xiàn),其中的樂(lè)趣難以形容"。我堅(jiān)信任何一個(gè)成功的科學(xué)家的直接工作動(dòng)源都是興趣,而不是意志。(2)成為世界第一,不容易,但是應(yīng)該作為一種判斷標(biāo)準(zhǔn),如果某個(gè)領(lǐng)域已經(jīng)非常成熟,很難有什么創(chuàng)新了,或者大牛云集,已經(jīng)打破頭了,則應(yīng)該有所回避。(3)賺錢(qián),許峰雄是在工業(yè)研究院中工作,比較注重實(shí)用,因此他強(qiáng)調(diào)了"賺錢(qián)",我是在工科大學(xué)里工作,也比較偏重應(yīng)用,因此是贊同"能賺錢(qián)"這個(gè)標(biāo)準(zhǔn)的。不過(guò),"能賺錢(qián)"不等于立即賺錢(qián),5年、10年,20年后能夠賺錢(qián)的研究課題都是值得關(guān)注的。
談?wù)勎疫x擇課題的一些體會(huì):
1、 要有實(shí)際需求
一個(gè)課題必須有實(shí)際需求,可能是現(xiàn)實(shí)的需求,也可能是潛在的需求;可能是直接的需求,也可能是間接的需求,總之是的的確確被人們所需要的。據(jù)個(gè)反例,比如自動(dòng)文摘,自動(dòng)文摘是我的博士論文課題,但是實(shí)際應(yīng)用需求始終不清楚,自動(dòng)文摘的結(jié)果用于編輯出版,質(zhì)量肯定無(wú)法保證,用于幫助人們快速瀏覽資料吧, Google提供的包含查詢(xún)?cè)~的簡(jiǎn)單的Snippet就起到了這個(gè)作用,因此,至今基于全文分析的單文檔自動(dòng)文摘到底用到哪里,仍然不清楚,這方面的研究已經(jīng)有50多年的歷史了,仍然是不死不活,總是找不到應(yīng)用就無(wú)法得到政府和企業(yè)界的持續(xù)性支持,以往的付出成為雞肋。我覺(jué)得單自動(dòng)文摘不是一個(gè)好課題,目前階段多文檔文摘,或者說(shuō)對(duì)某個(gè)題目的自動(dòng)綜述分析是非常好的題目。
2、 有較大的未知空間
以手寫(xiě)體漢字識(shí)別為例,市場(chǎng)上已經(jīng)大面積應(yīng)用了,在研究上就不宜再展開(kāi)。
3、 與自己以往的工作有關(guān)聯(lián)
如果你覺(jué)得自己的研究領(lǐng)域太窄,或者競(jìng)爭(zhēng)對(duì)手太多,或者自己缺乏興趣,則可以適當(dāng)擴(kuò)展研究方向,但最好是相關(guān)性地?cái)U(kuò)展,比如從自然語(yǔ)言處理(NLP)擴(kuò)展到信息檢索(IR),IR要用到NLP的技術(shù),這種擴(kuò)展是從底層技術(shù)到應(yīng)用系統(tǒng)的擴(kuò)展,很自然。再比如從圖片檢索擴(kuò)展到視頻檢索,只是處理對(duì)象有變化,很多原有的技術(shù)優(yōu)勢(shì)仍然能夠發(fā)揮。如果跳躍性太大,比如搞NLP,忽然發(fā)現(xiàn)做數(shù)據(jù)挖掘有前途,于是單純地轉(zhuǎn)向數(shù)據(jù)庫(kù)中數(shù)據(jù)挖掘,和文本處理完全脫節(jié),這種做法一方面無(wú)法發(fā)揮既有的技術(shù)積累,另一方面也讓同行感覺(jué)你不夠?qū)Wⅲ蝗菀椎玫秸J(rèn)可。最要命的是有的人根本就沒(méi)有自己的方向,什么課題都敢接,這樣的人可以一時(shí)間讓人覺(jué)得風(fēng)風(fēng)火火,經(jīng)費(fèi)也很充足,但過(guò)不了多久就會(huì)摔落下去,因?yàn)槿狈Ψe累,學(xué)術(shù)形象不清,公雞下蛋,干了自己不擅長(zhǎng)的事情,在學(xué)術(shù)圈還怎么混?
4、 有可能得到國(guó)家的支持
對(duì)于資深學(xué)者,他選定一個(gè)課題后,可以寫(xiě)出立項(xiàng)建議,去說(shuō)服政府或軍方支持他的工作,從而填補(bǔ)國(guó)家空白,成為國(guó)內(nèi)這個(gè)方向的先驅(qū)。哈工大的楊孝宗老師借鑒 CMU在wearable computing方面的研究成果,在國(guó)內(nèi)率先提出穿戴計(jì)算機(jī)的概念,堅(jiān)持多年,就獲得了軍方的認(rèn)可。對(duì)于剛出道的年輕人,無(wú)力直接影響政府,那只有自己預(yù)先判定一個(gè)幾年后可能成為熱點(diǎn)的方向,先走一步,做出一些成績(jī)來(lái),等到大氣候適宜的時(shí)候,由于他已經(jīng)取得了一定的成果,也有可能被認(rèn)可為這個(gè)領(lǐng)域的先行者,得到國(guó)家的支持。
課題的類(lèi)型
對(duì)一個(gè)課題的類(lèi)型要有一個(gè)判斷,是研究型的還是開(kāi)發(fā)型的,如果是研究型的,要組織博士生們來(lái)攻關(guān),鼓勵(lì)大家大膽嘗試,提出創(chuàng)見(jiàn);如果是開(kāi)發(fā)型的,要更多地召集碩士生們來(lái)做,強(qiáng)調(diào)利用一切現(xiàn)有的技術(shù)手段把技術(shù)或系統(tǒng)做到實(shí)用可靠。這兩者要分的比較清楚,既不能通過(guò)各種打補(bǔ)丁的方法,或者說(shuō)一大堆小技巧來(lái)對(duì)付研究型的課題,因?yàn)槟菢邮亲霾怀鐾黄菩赃M(jìn)展的,也不能在開(kāi)發(fā)類(lèi)課題上總是異想天開(kāi),嘗試還很不成熟的技術(shù)。
如果是研究型課題,還要區(qū)別是基礎(chǔ)研究還是應(yīng)用研究,基礎(chǔ)研究的結(jié)果不能直接被用戶(hù)使用,類(lèi)似重工業(yè),應(yīng)用研究的結(jié)果最終用戶(hù)直接就能夠用上,類(lèi)似輕工業(yè)。對(duì)于基礎(chǔ)研究,可以?huà)侀_(kāi)具體應(yīng)用的約束,專(zhuān)注于一些科學(xué)原理技術(shù)原理的突破。對(duì)于應(yīng)用研究,則需要考慮用戶(hù)的需求。
課題還有長(zhǎng)期(long term)和短期(short term)之分,長(zhǎng)期研究的課題往往難度大,研究結(jié)果難以預(yù)料,短期項(xiàng)目則比較好預(yù)測(cè),可以速戰(zhàn)速?zèng)Q。
怎樣做研究(四)
在一個(gè)具體的題目上作研究,應(yīng)該遵從怎樣的程序呢?我覺(jué)得可以概括為"螺旋式深入",也就是在"閱讀","思考","實(shí)驗(yàn)","寫(xiě)作",再閱讀。。。這四個(gè)階段的時(shí)間分配可以根據(jù)實(shí)際情況靈活調(diào)整,剛進(jìn)入課題的研究生閱讀調(diào)研花費(fèi)的時(shí)間要多一些,而在一個(gè)課題上已經(jīng)開(kāi)展了一兩年工作的人則可能增量式地閱讀資料,閱讀時(shí)間自然比起步時(shí)少一些。專(zhuān)門(mén)用于思考、設(shè)計(jì)、推演的時(shí)間可能并不多,但思考是滲透在其它三個(gè)階段中不斷進(jìn)行的,因此總的思考時(shí)間并不少。實(shí)驗(yàn)中編程的時(shí)間應(yīng)該盡可能短,用更多的時(shí)間進(jìn)行實(shí)驗(yàn)數(shù)據(jù)的分析。寫(xiě)作是常常被中國(guó)的研究生忽略的環(huán)節(jié),寫(xiě)作的時(shí)間要足夠長(zhǎng)。收集資料,了解別人的工作,找出問(wèn)題所在,針對(duì)性地提出自己的創(chuàng)意,用實(shí)驗(yàn)驗(yàn)證自己創(chuàng)意的正確性,總結(jié)歸納,撰寫(xiě)論文,發(fā)現(xiàn)新的問(wèn)題,再收集資料,如此反復(fù),這是研究活動(dòng)的大致流程。
怎樣閱讀資料
收集資料、閱讀資料是從事研究工作的第一步,但是如何收集、閱讀資料卻很有學(xué)問(wèn),初學(xué)者如果沒(méi)有得到足夠的指導(dǎo),常常走很多彎路。
1、 閱讀重要的論文
目前互聯(lián)網(wǎng)上的信息量太大了,對(duì)每一條信息的重要性、可靠性的判斷是一個(gè)人采集信息的關(guān)鍵環(huán)節(jié)。如果判斷一篇論文是否重要呢?GoogleScholar給出的引用數(shù)是一個(gè)有效指標(biāo),很多學(xué)者都引用的文章往往就是有價(jià)值的論文。有的同學(xué)覺(jué)得看中文論文容易,于是把自己能夠查到的中文論文一網(wǎng)打盡,反復(fù)閱讀,但是很多發(fā)表在三流刊物上為了評(píng)職晉級(jí)而炮制的論文完全沒(méi)有閱讀的價(jià)值,白白耽誤了時(shí)間。即使是英文論文,國(guó)外一樣有濫竽充數(shù)的文章,這樣的論文引用數(shù)肯定低,用引用數(shù)可能很容易地把這樣的論文淘汰掉。
計(jì)算機(jī)領(lǐng)域的頂級(jí)會(huì)議論文非常重要,在NLP領(lǐng)域有ACL,在IR領(lǐng)域有SIGIR,在機(jī)器翻譯領(lǐng)域有MT Summit,這些頂級(jí)會(huì)議的論文質(zhì)量很高,內(nèi)容很新,應(yīng)該高度關(guān)注。期刊上的論文是一個(gè)作者或機(jī)構(gòu)一個(gè)階段的研究成果的總結(jié),通常質(zhì)量較高,但由于審稿及編輯出版的周期很長(zhǎng),因此內(nèi)容不夠新,適當(dāng)關(guān)注即可。NLP領(lǐng)域的CL,機(jī)器翻譯中的MT,信息檢索領(lǐng)域的IP&M和JASIST等都是很好的期刊。進(jìn)入一個(gè)領(lǐng)域,必須立即了解該領(lǐng)域有哪些頂級(jí)的國(guó)際會(huì)議和國(guó)際期刊。
2、以作者為線(xiàn)索理清脈絡(luò)
閱讀論文一定要注意論文的作者是誰(shuí),研究機(jī)構(gòu)是哪里,以作者為線(xiàn)索理一理就會(huì)發(fā)現(xiàn)全世界搞你這個(gè)方向的也就那么幾個(gè)、十幾個(gè)研究機(jī)構(gòu)、研究者,以后就跟蹤這些人的研究工作即可,還能夠發(fā)現(xiàn)該作者的研究工作的演進(jìn)脈絡(luò)。如果拿到一篇文章就讀,讀完了也不知道作者是誰(shuí),時(shí)間長(zhǎng)了,就會(huì)感到暈頭暈?zāi)X,不知道從哪個(gè)期刊或會(huì)議上就會(huì)冒出一篇相關(guān)文章來(lái),讓你防不勝防。
3、 閱讀最新的論文
學(xué)術(shù)發(fā)展很快,要集中盡力閱讀近5年,特別是近3年的論文,對(duì)于5年前的論文,只看引用率最高的經(jīng)典文章即可。
4、 抓住論文的要害
讀完一篇論文必須了解哪些關(guān)鍵內(nèi)容呢?我覺(jué)得應(yīng)該包括以下方面:作者為什么要做這項(xiàng)工作?要解決的是一個(gè)什么問(wèn)題?作者在解決問(wèn)題時(shí)遇到了怎樣的困難?為了解決他的困難他提出了什么樣的解決辦法?試驗(yàn)結(jié)果是否可能真的證明他的方法好,數(shù)據(jù)是否充分,有沒(méi)有和別人的工作,別的方法進(jìn)行對(duì)比?你認(rèn)為他的方法是否新穎,你從中學(xué)到了什么?該方法有哪些不足,你是否立即有了新的改進(jìn)方案?如果有立即記錄下來(lái)。帶著上述問(wèn)題,抓住要點(diǎn),做好記錄,一篇長(zhǎng)文就會(huì)像庖丁解牛一樣轟然倒下。
5、 批判式閱讀
真理越辯越明,我們讀的是一篇學(xué)術(shù)論文,不是《圣經(jīng)》,不能帶著崇敬的心理去閱讀,要像一個(gè)審稿人那樣帶著批判挑剔的心理閱讀論文,在閱讀中不斷地找出論文中的問(wèn)題,選題上的,方法上的,實(shí)驗(yàn)上的,表述上的,并不斷地通過(guò)積極獨(dú)立的思考給出自己認(rèn)為見(jiàn)解。只有這樣,資料才能夠?yàn)槟闼茫粫?huì)成為你的包袱。有的同學(xué)讀資料,越讀越喪失信心,發(fā)現(xiàn)別人做得太好了,自己的想法都被別人做完了,資料全讀完了,自己也準(zhǔn)備換課題了,這是失敗的讀法。
中國(guó)的研究生要有信心,不要被國(guó)外所謂的名家嚇住。中國(guó)的科研水平在快速提高,科研人員的素質(zhì)也在快速提高。一位美籍華裔企業(yè)家在一篇文章中寫(xiě)道:"可不幸的是,除了很少頂尖學(xué)校的博士外,大部分博士所做的研究課題都是陳舊或者沒(méi)有意義的。"不知道頂尖高校的含義是什么,但是我覺(jué)得我們的研究生要對(duì)自己的國(guó)家有信心,對(duì)自己的學(xué)校有信心,對(duì)自己的倒是有信心,對(duì)自己有信心。只要我們掌握正確的研究方法,廣泛閱讀國(guó)外最新的研究成果,大膽嘗試自己人為正確的方法,充分釋放我們的聰明才智,我們就絲毫不用對(duì)國(guó)外的研究工作頂禮膜拜。在科學(xué)研究上,歐美人從內(nèi)心里是瞧不起我們亞洲人,我們中國(guó)人的,以至于歐美歸來(lái)的學(xué)者們也以歐美為樣板來(lái)評(píng)估我們教育科研體制,只要和美國(guó)不一樣就是大錯(cuò)特錯(cuò)了,中國(guó)高校的教師們都是在誤人子弟。我奉勸每一位研究生建立不崇拜權(quán)威,不崇拜歐美,只服從真理的獨(dú)立思維模式,大膽質(zhì)疑大膽批判,只有這樣才能不死于他人之言下,才能有活脫脫的自己。
posted @
2012-04-13 19:08 Seraphi 閱讀(337) |
評(píng)論 (0) |
編輯 收藏
用途:對(duì)我來(lái)說(shuō),學(xué)習(xí)HMM是為了對(duì)以后的詞性或概念標(biāo)注打下理論基礎(chǔ)
符號(hào)說(shuō)明:
S:表示狀態(tài)集合。
S=[S
1,S
2,S
3....]。其中S
i表示第i個(gè)狀態(tài)(第i種狀態(tài))
Q:表示系統(tǒng)實(shí)際的狀態(tài)序列,
Q=[q
1,q
2,....,q
T]。q1表示t=1時(shí),系統(tǒng)所處的狀態(tài),如:q
1=S
3表示t=1時(shí)刻,系統(tǒng)狀態(tài)為S
3。
1.離散馬爾可夫過(guò)程
(1)定義:一個(gè)系統(tǒng),在任一時(shí)刻t,可能處于N個(gè)不同狀態(tài)S
1,S
2...S
N中的某一個(gè)。系統(tǒng)變化服從某種統(tǒng)計(jì)規(guī)律。如果系統(tǒng)狀態(tài)序列滿(mǎn)足下列無(wú)后效的條件,則稱(chēng)(q
t,t
≥1)為離散的馬爾可夫過(guò)程。
P[q
t+1=S
j|q
t=S
i,q
t-1=S
k,...]=P[q
t+1=S
j|q
t=S
i]
可見(jiàn)系統(tǒng)將來(lái)的狀態(tài)僅與現(xiàn)在所處狀態(tài)有關(guān),與過(guò)去無(wú)關(guān),這種情況稱(chēng)之為“無(wú)后效”。
如果進(jìn)一步有P[q
t+1=S
j|q
t=S
i]與時(shí)刻t無(wú)關(guān),則稱(chēng)相應(yīng)的馬爾可夫過(guò)程是齊決的或是時(shí)齊的,引入記號(hào):
a
ij=P[q
t+1=S
j|q
t=S
i],1
≤i,j≤N
注:這里有人也稱(chēng)aij為Si→Sj的發(fā)射概率,也稱(chēng)轉(zhuǎn)移概率。
(2)初始概率分布: πi=P[q1=Si], 1≤i,j≤N
k步轉(zhuǎn)移概率:
aij(k)=P[qt+k=Sj|qt=Si]
當(dāng)k=1時(shí),aij(k)=aij(1)=aij
(3)切普曼—柯?tīng)柲缏宸蚬剑–hapman-Kolmogorol)

2.隱馬爾可夫模型
當(dāng)狀態(tài)本身是不可觀(guān)察,從而得到隱馬爾可夫模型(HMM)。值得一提的是,隱馬爾可夫模型(HMM)包含了雙重隨機(jī)過(guò)程:一是系統(tǒng)狀態(tài)變化的過(guò)程,即前面所述的馬爾可夫過(guò)程,另一個(gè)是由狀態(tài)決定觀(guān)察的隨機(jī)過(guò)程。
舉例:碗、球模型
假設(shè)N只碗,每個(gè)碗中放著數(shù)量與比例均不同的各種色彩的球,不同的彩色球?yàn)镸。先隨機(jī)選一個(gè)碗,再?gòu)耐胫须S機(jī)拿一個(gè)球,報(bào)告球的顏色得到一個(gè)觀(guān)察O1,然后將球放回到碗中,繼續(xù)這個(gè)過(guò)程,得到一系列觀(guān)察O=O1O2O3...OT
在這個(gè)模型中,碗(狀態(tài))是不可觀(guān)察的,只有球的顏色是可觀(guān)察的。這里引入M,指不同觀(guān)察值的數(shù)目 。所有不同觀(guān)察值記為V={V1,V2,....VM}。
對(duì)于第一種隨機(jī)過(guò)程(選碗),時(shí)齊馬爾可夫過(guò)程的轉(zhuǎn)移概率矩陣:A={aij},初始分布:π=(πi)
對(duì)于第二種隨機(jī)過(guò)程,有多項(xiàng)分布B={bj(k)},其中
bj(k)=P[時(shí)刻t時(shí)觀(guān)察值為Vk|qt=Sj]
給定一組N,M,A,B和π后,一個(gè)HMM即確定了,為緊縮起見(jiàn),今后將用λ=(A,B,π)表示一個(gè)HMM。
3.HMM中三個(gè)基本問(wèn)題
問(wèn)題1:
給定一個(gè)觀(guān)察序列O=O1O2...OT和一個(gè)模型λ=(A,B,π),如何有效計(jì)算P(O|λ),即給定模型λ的條件下,觀(guān)察序列O的概率。
問(wèn)題1是一個(gè)計(jì)算概率的問(wèn)題,也可以看成一個(gè)評(píng)估給定的模型能否很好地?cái)M合給定的觀(guān)察的問(wèn)題。
解法:
(1)前向算法:
定義αt(i)=P(O1O2....Ot,qt=Si|λ)
αt可用遞推算法完成計(jì)算:
①初始化:α1(i)= πibi(O1)
②遞推:
③終止:
(2)后向算法:
定義βt(i)=P(Ot+1,Ot+2,...,OT|qt=Si,λ)
βt可用遞推算法計(jì)算:
①初始化:βT(i)=1
②遞推:
③終止:
問(wèn)題2:
給定一個(gè)觀(guān)察序列O=O1O2...OT和一個(gè)模型λ=(A,B,π),如何選擇一個(gè)相應(yīng)狀態(tài)Q=q1q2...qT使得在某種意義下,它能最好地說(shuō)明觀(guān)察序列O。
兩個(gè)準(zhǔn)則:
準(zhǔn)則1:對(duì)每個(gè)時(shí)刻t,逐個(gè)選取狀態(tài)qt使
γt(i)=P(qt=Si|O,λ)=max
其中:

求出γ
t(i)后,問(wèn)題2便迎刃而解。
準(zhǔn)則2(應(yīng)用最為廣泛):綜合選取一個(gè)狀態(tài)序列
Q=q
1q
2....q
T使P(
Q|
O,
λ)=max
對(duì)于P(
Q|
O,
λ)=P(
Q,
O|
λ)/P(
O|
λ)
而分母P(
O|λ)與
Q無(wú)關(guān),因此等價(jià)于P(
Q,
O|
λ)=max。
對(duì)于全局最優(yōu)問(wèn)題,使用動(dòng)態(tài)規(guī)劃方法,這就是Viterbi算法。
定義

基于HMM特性,

因?yàn)槲覀兺瑯雨P(guān)心q
1q
2...q
T的序列,因此引入

整個(gè)遞推算法(Viterbi算法)描述如下:
①初始化
δ1(i)=πibi(O1)
φ1(i)=0
②遞推


③終止

④回溯最佳路徑
q
t*=
φt+1(qt+1*)
將其應(yīng)用到詞性自動(dòng)標(biāo)注中。在自動(dòng)標(biāo)注中,每個(gè)詞是可觀(guān)察的,一個(gè)詞串W=w1w2....wT即相當(dāng)這里的一個(gè)觀(guān)察序列O=O1O2...OT。不可觀(guān)察的狀態(tài)相當(dāng)于詞性或概念標(biāo)記,即狀態(tài)序列Q=q1q2....qT相當(dāng)于上一節(jié)中的一個(gè)標(biāo)記序列。
可以看出準(zhǔn)則1相當(dāng)于詞級(jí)評(píng)價(jià),準(zhǔn)則2相當(dāng)于句子級(jí)評(píng)價(jià)。
問(wèn)題3.
如何修正模型參數(shù)λ=(A,B,π)使P(O|
λ)=max。
問(wèn)題3是最困難的,至少也沒(méi)有很好的解法。可參考的方法有基于均值修正的迭代方法等。
參考文獻(xiàn):
[1] 吳立德: 大規(guī)模中文文本處理[M]. 復(fù)旦大學(xué)出版社,1993.
posted @
2012-03-07 13:56 Seraphi 閱讀(1324) |
評(píng)論 (0) |
編輯 收藏
1.馬爾可夫
2.GBDT,隨機(jī)森林
3.SVD,LDA等理論
4.上述理論的工具使用
5.網(wǎng)絡(luò)可視化工具的調(diào)研
暫時(shí)就想到這些,到時(shí)候再補(bǔ)充~
posted @
2012-02-29 10:16 Seraphi 閱讀(244) |
評(píng)論 (0) |
編輯 收藏Apriori算法乃是關(guān)聯(lián)規(guī)則挖掘的經(jīng)典算法,盡管是94年提出的算法,然而至今也有著旺盛的生命力。在互聯(lián)網(wǎng)科學(xué)領(lǐng)域,也有著廣泛的應(yīng)用,因此還是值得大家都對(duì)此學(xué)習(xí)一下。
一、術(shù)語(yǔ)
1.支持度:support,所有實(shí)例中覆蓋某一項(xiàng)集的實(shí)例數(shù)。
2.置信度:confidence。對(duì)于X→Y這個(gè)規(guī)則,如果數(shù)據(jù)庫(kù)的包含X的實(shí)例數(shù)的c%也包含Y,則X→Y的置信度為c%。
3.頻繁項(xiàng)集:也稱(chēng)large itemsets,指支持度大于minsup(最小支持度)的項(xiàng)集
二、思想
1.Apriori算法思想與其它關(guān)聯(lián)規(guī)則挖掘算法在某些方面是相同的。即首先找出所有的頻繁項(xiàng)集,然后從頻繁項(xiàng)集中抽取出規(guī)則,再?gòu)囊?guī)則中將置信度小于最小置信度的規(guī)則剃除掉。
2.若項(xiàng)集i為頻繁項(xiàng)集,則其所有子集必為頻繁項(xiàng)集。因此,Apriori算法思想在于從頻繁的k-1項(xiàng)集中合并出k項(xiàng)集,然后剃除掉子集有不是頻繁項(xiàng)集的k項(xiàng)集。
3.先從數(shù)據(jù)庫(kù)中讀出每條實(shí)例,對(duì)于設(shè)定閾值,選出頻繁1項(xiàng)集,然后從頻繁1項(xiàng)集中合并,并剃除掉包含非頻繁1項(xiàng)集子集的2項(xiàng)集……
4.符號(hào)說(shuō)明:
L
k:Set of large(frequent) k-itemsets
C
k:Set of candidate k-itemsets
apriori-gen()函數(shù)通過(guò)合并k-1的頻繁項(xiàng)集,生成C
k
三、算法描述
1) Apriori基本算法
1
 L1={large 1-itemsets};
L1={large 1-itemsets};
2 for(k=2;Lk-1!=Φ;k++)
for(k=2;Lk-1!=Φ;k++)
3{
4 Ck=apriori-gen(Lk-1);
Ck=apriori-gen(Lk-1);
5 for(all transaction t∈D)
6
 {
{
7 Ct=subset(Ck,t);
8 for(all candidates c∈Ct)
9 c.count++;
10 }
}
11 Lk={c∈Ck|c.count>=minsup}
12 }
}
13Answer=∪k Lk; 2)apriori-gen()函數(shù)
這個(gè)函數(shù)將L
k-1(即所有k-1頻繁項(xiàng)集的集合)作為參數(shù),返回一個(gè)L
k的超集(即C
k)
算法如下:
1insert into Ck
2select p.item1, p.item2,  ,p.itemk-1,q.itemk-1
,p.itemk-1,q.itemk-1
3from Lk-1 p, Lk-1 q
4where p.item1=q.item1, p.item2=q.item2, , p.itemk-1<q.itemk-1 然后通過(guò)剪枝,剃除掉C
k中某些子集不為頻繁k-1項(xiàng)集的項(xiàng)集,算法如下:
1for(all items c∈C
k)
3)從頻繁項(xiàng)集中生成規(guī)則
1 for(all l
for(all l∈Answer)
2 {
{
3 A=set of nonempty-subset(l);
A=set of nonempty-subset(l);
4 for(all a∈A)
5 {
{
6 output a→(l-a);
7 }
}
8 }
} 四、舉例(這里將minsup=1,mincof=0.5)
L3={{1 2 3}{1 2 4}{1 3 4}{1 3 5}{2 3 4}}
在合并步驟時(shí),選取L3中,前兩個(gè)項(xiàng)都相同,第三個(gè)項(xiàng)不同的項(xiàng)集合并,如{1 2 3}與{1 2 4}合并、{1 3 4}與{1 3 5}合并成{1 2 3 4}和{1 3 4 5}。因此,C4={{1 2 3 4}{1 3 4 5}},但是由于{1 3 4 5}中某子集{3 4 5}并未在L3中出現(xiàn),因此,將{1 3 4 5}剃除掉,所以L(fǎng)4={{1 2 3 4}}。
然后以L(fǎng)4為例,選取出關(guān)聯(lián)的規(guī)則:
L4中{1 2 3 4}項(xiàng)集中抽取出(這里只列出左邊為3項(xiàng)的情況):
{1 2 3}→4
{1 2 4}→3
{1 3 4}→2
{2 3 4}→1
顯然,因?yàn)橹挥幸粋€(gè)4項(xiàng)集,因此,這四條規(guī)則的置信度都為100%。因此,全數(shù)為關(guān)聯(lián)規(guī)則。
五、Apriori變體
有些Apriori變體為追求時(shí)間效率,不是從L
1→C
2→L
2→C
3→....的步驟產(chǎn)生,而是從L
1→C
2→C
3'..產(chǎn)生。
參考文獻(xiàn):
Agrawal, Rakesh, Srikant, Ramakrishnan. Fast algorithms for mining association rules in large databases. Very Large Data Bases, International Conference Proceedings, p 487, 1994 posted @
2012-02-27 13:08 Seraphi 閱讀(782) |
評(píng)論 (0) |
編輯 收藏本文要解決的主要問(wèn)題是社交網(wǎng)絡(luò)中的標(biāo)簽推薦(本文主要為音樂(lè)、視頻等多媒體對(duì)象推薦合適的標(biāo)簽)。較之以前的推薦策略——a.根據(jù)已有標(biāo)簽進(jìn)行詞語(yǔ)共現(xiàn)的推薦; b.根據(jù)文本特征(如標(biāo)題、描述)來(lái)推薦; c.利用標(biāo)簽相關(guān)性度量來(lái)推薦。大部分僅僅至多使用了上述的兩種策略,然而本文將3種特征全部結(jié)合,并提出一些啟發(fā)式的度量和兩種排序?qū)W習(xí)(L2R)的方法,使得標(biāo)簽推薦的效果(p@5)有了顯著的提高。
問(wèn)題陳述:作者將數(shù)據(jù)集分為三類(lèi):train, validation, test。對(duì)于訓(xùn)練集D,包含<L
d,F
d>。L
d指對(duì)象d的所有標(biāo)簽集;F
d指d的文本特征集(即L
d=L
1d∪L2d∪L
3d...L
nd,F
d=F
1d∪ F
2d∪ F
3d....F
nd)。對(duì)于驗(yàn)證集和測(cè)試集,由三部分組成<L
o,F
o,y
o>。L
o為已知標(biāo)簽,y
o為答案標(biāo)簽,實(shí)驗(yàn)中作者將一部分標(biāo)簽劃分L
o,一部分為y
o,這樣做可以方便系統(tǒng)自動(dòng)評(píng)價(jià)推薦性能。
Metrics說(shuō)明:(1)Tag Co-occurrence:基于共現(xiàn)方法的標(biāo)簽推薦主要是利用了關(guān)聯(lián)規(guī)則(association rules),如X→y,X為前導(dǎo)標(biāo)簽集,y為根據(jù)X(經(jīng)過(guò)統(tǒng)計(jì))得到的標(biāo)簽。還要提到兩個(gè)參數(shù):support(
σ),意為X,y在訓(xùn)練集中共現(xiàn)的次數(shù),confidence(
θ)=p(y與object o相關(guān)聯(lián)|X與object o相關(guān)聯(lián))。由于從訓(xùn)練集中得到的規(guī)則很多,因此要設(shè)定σ 、θ 的最小閾值,只選取最為頻繁發(fā)生、最可靠的共現(xiàn)信息。
Sum(c,o,l)=
ΣX⊆L0 θ(X→c), (X→c)
∈R, |X|≤l
(2)Discriminative Power: 指區(qū)分度,對(duì)于一個(gè)頻繁出現(xiàn)的標(biāo)簽特征,區(qū)分度會(huì)很低。作者提出一個(gè)IFF度量(類(lèi)似于IR中的IDF),定義如下:
IFF(c)=log[(|D|+1)/(fctag+1)]
其中f
ctag為訓(xùn)練集D中,以c作為標(biāo)簽者的對(duì)象數(shù)。
盡管這個(gè)度量可能偏重于一些并未在訓(xùn)練集中出現(xiàn)作為標(biāo)簽的詞語(yǔ),然而在排序函數(shù)中,它的權(quán)重會(huì)被合理安排。
另外,過(guò)于頻繁的標(biāo)簽和過(guò)于稀少的標(biāo)簽都不會(huì)是合理的推薦,而那些頻率中等的term則最受青睞。有一種Stability(Stab)度量?jī)A向于頻率適中的詞語(yǔ):
Stab(c,k
s)=k
s/[k
s+|k
s-log(f
ctag)|] , 其中k
s表示term的理想頻率,要根據(jù)數(shù)據(jù)集來(lái)調(diào)整。
(3)Descriptive Power
指對(duì)于一個(gè)侯選c的描述能力,主要有如下4種度量
:①TF: TF(c,o)=
ΣFoi∈Fo tf(c,Foi)②TS: TS(c,o)=
ΣFoi∈Fo j, where j=1 (if c
∈Foi )
, otherwise j=0③wTS:wTS(c,o)=
ΣFoi∈Fo j, where j=AFS(F
i) (if c∈
Foi )
, otherwise j=0 ④wTF:wTS(c,o)=
ΣFoi∈Fo tf(c,Foi), where j=AFS(F
i) (if c∈
Foi )
, otherwise j=0 這里要引入兩個(gè)概念:
FIS:Feature Instance spread. FIS(F
oi) 為F
oi中所有的term的平無(wú)數(shù)TS值。
AFS:Average Feature Spread:AFS(F
i)為訓(xùn)練集中所有對(duì)象的平均FIS(F
oi),即
AFS(F
i)=
Σoj∈D FIS(Foji)/|D|
(4)詞項(xiàng)預(yù)測(cè)度
Heymann et al.[11]通過(guò)詞項(xiàng)的熵來(lái)度量這個(gè)特征。
詞項(xiàng)c在標(biāo)簽特征的熵值H
tags(c)=-
Σ(c→i)∈R θ(c→i)logθ(c→i) ,其中R為訓(xùn)練集中的規(guī)則集。
標(biāo)簽推薦策略:(1)幾個(gè)先進(jìn)的baseline:
① Sum
+:擴(kuò)展了Sum度量,通過(guò)相應(yīng)關(guān)聯(lián)規(guī)則的前導(dǎo)和后繼中的詞項(xiàng)的Stablity為Confidence賦予權(quán)重。給定一個(gè)對(duì)象o的侯選標(biāo)簽c,Sum
+定義如下:
Sum
+(c,o,k
x,k
c,k
r)=
Σx∈L
0 θ(x→c)*Stab(x,kx)*Stab(c,kc)*Rank(c,o,kr)
其中:k
x,k
c,k
r為調(diào)節(jié)參數(shù),Rank(c,o,k
r)=k
r/[k
r+p(c,o), p(c,o)為c在這個(gè)關(guān)聯(lián)規(guī)則中confidence排名的位置,這個(gè)值可以使Confidence值更為平滑地衰減。Sum
+限制了前導(dǎo)中的標(biāo)簽數(shù)為1。
② LATRE(Lazy Associative Tag Recommendation):與Sum
+不同,LATRE可以在立即請(qǐng)求的方式快速生成更大的關(guān)聯(lián)規(guī)則,這與其它策略不同(因?yàn)樗鼈兌际鞘孪仍谟?xùn)練集中計(jì)算好所有的規(guī)則),但也可能包含一些在測(cè)試集中并不是很有用的規(guī)則。 LATRE排序每個(gè)侯選c,通過(guò)相加所有包含c的規(guī)則的confidence值。
③ CTTR(Co-occurrence and Text based Tag Recommender):利用了從文本域特征中抽取出的詞項(xiàng)和一個(gè)相關(guān)性度量,但所有考慮事先已經(jīng)賦給對(duì)象o的標(biāo)簽。作者對(duì)比CTTR與作者的方法,評(píng)價(jià)了作者自創(chuàng)幾個(gè)度量和應(yīng)用事先預(yù)有標(biāo)簽的有效性,篇幅有限,不再對(duì)此詳述。
(2) New Heuristics
8種,作者擴(kuò)展了Sum
+和LATRE baseline加入了描述性度量(TS,TF,wTS,wTF),共合成了8種方案。
Sum
+DP(c,o,k
x,k
c,k
r,
α)=αSum
+(c,o,k
x,k
c,k
r)+(1-α)DP(c,o)
LATRE
+DP(c,o,l,α)=αSum(c,o,l)+(1-α)DP(c,o)
(3)排序?qū)W習(xí)策略:
對(duì)一個(gè)Metric矩陣(對(duì)于侯選c)M
c∈Rm,m是考慮的metric數(shù),即矩陣的維數(shù)。然后驗(yàn)證集V的對(duì)象v賦一個(gè)Y
c,若c為v的合理推薦,Y
c=1,否則Y
c=0。因?yàn)橛?xùn)練集用來(lái)抽取關(guān)聯(lián)規(guī)則和計(jì)算metrics,驗(yàn)證集用來(lái)學(xué)習(xí)solutions,因此只對(duì)驗(yàn)證集賦Y
c。學(xué)習(xí)模型,即排序函數(shù)f(M
c)將被用于測(cè)試集:
① RankSVM:作者使用SVM-rank tool學(xué)習(xí)一個(gè)函數(shù)f(M
c)=f(W,M
c),其中W=<w
1,w
2,....,w
m>是一個(gè)對(duì)metrics賦權(quán)值的向量。其中,RankSVM有兩個(gè)參數(shù),kernel function和cost j。
② 遺傳算法:
這里將個(gè)體(即標(biāo)簽排序函數(shù))看成一個(gè)樹(shù)表示,葉子結(jié)點(diǎn)為變量或常數(shù)。樹(shù)內(nèi)結(jié)點(diǎn)為基本運(yùn)算符(+,-,*,/,ln)。若域超出運(yùn)算范圍,結(jié)果默認(rèn)為0。例如,一個(gè)樹(shù)表示函數(shù):Sum+0.7*TS,如下圖:
.JPG)
個(gè)體的健壯度(Fitness)表示相應(yīng)排序函數(shù)的推薦質(zhì)量,本文以P@k為衡量標(biāo)準(zhǔn)給定f(M
c),y
o是o的相關(guān)標(biāo)簽,R
of是通過(guò)f(M
c)排序后的o的推薦結(jié)果,R
k,of的R
of中前k個(gè)結(jié)果,推薦質(zhì)量定義如下:
P@k(R
of,y
o,f)=|R
k,of∩yo|/min(k,|y
o|)
實(shí)驗(yàn)評(píng)價(jià):(1)數(shù)據(jù)收集:LastFM, Youtube, YahooVideo。 然后去停用詞,詞干化處理(Poster Stemmer)
(2)評(píng)價(jià)方法:
a.將object預(yù)先的一些標(biāo)簽一部分作為已經(jīng),一部分作為答案,方便評(píng)價(jià),某些生成的答案,并不能在答案集中,但并不意味不相關(guān),因此可作為lower bound。
b.在實(shí)際實(shí)驗(yàn)中,作者將驗(yàn)證集和測(cè)試集的對(duì)象標(biāo)簽平均分為L(zhǎng)
o,y
o,使用title和description作為文本特征F
o。
c.在評(píng)價(jià)指標(biāo)上,主要使用P@5,并用了Recall和MAP值
d.以?xún)煞N方案來(lái)對(duì)各種推薦方法評(píng)價(jià):
① 把每個(gè)數(shù)據(jù)集分為3份,對(duì)應(yīng)小規(guī)模,中規(guī)模,大規(guī)模,以便針對(duì)每種情況,調(diào)整參數(shù),評(píng)價(jià)不同規(guī)模下各方法的效果
② 利用整個(gè)數(shù)據(jù)集,統(tǒng)一的評(píng)價(jià)
這兩種方案,①更加有針對(duì)性,②則代價(jià)較低
對(duì)于第一個(gè)方案,作者隨機(jī)從每個(gè)子集(大、中、小規(guī)模)中選取50000個(gè)樣本,對(duì)于第二種方案,作者使用第一個(gè)方案選取出的3個(gè)樣本集組合的樣本。這兩種方案都把每個(gè)樣本集分為5份來(lái)做5折交叉驗(yàn)證。3/5做訓(xùn)練,1/5做驗(yàn)證,1/5做測(cè)試。之所以在驗(yàn)證集上做L2R是為了避免過(guò)擬合。
(3)參數(shù)設(shè)定
① Sum
+DP中,k
r=k
x=k
c=5,
α=[0.7,1.0]
② LATRE
+DP和L2R中,l=3, k
s=5。在確定
σmin和θmin時(shí),將值設(shè)定為與σ
min和θ
min=0相比,結(jié)果下降小于3%的值
③ RankSVM中,選定線(xiàn)性核,cost j=100
④ 歸一化特征向量結(jié)果不明顯,因此本文并沒(méi)有采取特征向量歸一化。
(4)實(shí)驗(yàn)結(jié)果:
a. LastFM上提升較小,原因有二:① 有LastFM上標(biāo)簽、標(biāo)題、描述內(nèi)容重疊少,使TS,wTS集中在小值上,使得難以區(qū)別good,bad;② LastFM上對(duì)象標(biāo)簽較少,使TS,wTS難以發(fā)揮較好作用。
b. LATRE在大部分情況,好于Sum
+,而CTTR在一些情況好于LATRE。尤其是在Youtube。
c. 對(duì)比每個(gè)方案和數(shù)據(jù)集,作者的heuristics都有較大提升,因此引入描述性度量(descriptive power)會(huì)顯著提高推薦效果,尤其是標(biāo)簽數(shù)較少的情況(因?yàn)楣铂F(xiàn)效果差)
d. 比較Sum+, LATRE, CTTR。作者的8種啟發(fā)式護(hù)展都有不小的提升(LastFM最小),證實(shí)了利用預(yù)先已知標(biāo)簽和描述度量的作用。
e. 新啟發(fā)思想中,LATRE+wTS在大多數(shù)情況最好。在DP確定下,LATRE通常好于Sum+;DP變時(shí),wTS最好,其實(shí)是wTF,TS。
f. L2R中,兩種方法都有提升,但提升幅度有限,觀(guān)察發(fā)現(xiàn),GP和SVMRank主要利用的還是LATRE+wTS的metrics,GP中最常用的是Sum(c,o,3),然后是wTS,再是IFF,其它少于這些函數(shù)的25%。RankSVM中,最高權(quán)重主要還是集中于Sum,wTS。
g.盡管L2R效果提升不明顯,但框架靈活,易于擴(kuò)展(加入新度量和tag recommender問(wèn)題,如個(gè)性化)
h.對(duì)于SVMRank和GP的比較,效果好壞主要取決于數(shù)據(jù)集。
論文:Fabiano Belem, Eder Martins, Tatiana Pontes, Jussara Almeida, Marcos Goncalves. Associative Tag Recommendation Exploiting Multiple Textual Features.
Proceedings of the 34th international ACM SIGIR conference on Research and development in Information, Jul. 2011. 論文鏈接:SIGIR2011_Associative_Tag_Recommendation_Exploiting_Multiple_Textual_Features.pdf
posted @
2012-02-24 13:05 Seraphi 閱讀(694) |
評(píng)論 (0) |
編輯 收藏