2008年3月14日
#

其實就是關(guān)鍵一句話:
window.opener.document.getElementById("XXX").value=“123456”;
例程如下:
http://www.aygfsteel.com/Files/junglesong/ParentChildWnd20080520140659.rar
類之間關(guān)聯(lián)的Hibernate表現(xiàn)
在Java程序中,類之間存在多種包含關(guān)系,典型的三種關(guān)聯(lián)關(guān)系有:一個類擁有另一個類的成員,一個類擁有另一個類的集合的成員;兩個類相互擁有對象的集合的成員.在Hibernate中,我們可以使用映射文件中的many-to-one, one-to-many, many-to-many來實現(xiàn)它們.這樣的關(guān)系在Hibernate中簡稱為多對一,一對多和多對多.
多對一的類代碼
事件與地點是典型的多對一關(guān)系,多個事件可以在一個地點發(fā)生(時間不同),一個地點可發(fā)生多個事件.它們的對應(yīng)關(guān)系是(多)事件對(一)地點.
兩個類的代碼如右:
public class Event{
private String id;
private String name;
private Location location;
}
public class Location{
private String id;
private String name;
}
多對一的映射文件
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Event"
table="Event_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<many-to-one name="location" column="locationId" class="com.sitinspring.domain.Location"/>
</class>
</hibernate-mapping>
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Location"
table="Location_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
</class>
</hibernate-mapping>
多對一的表數(shù)據(jù)

一對多的類代碼
如果一個用戶有多個權(quán)限,那么User類和Privilege類就構(gòu)成了一對多的關(guān)系,User類將包含一個Privilege類的集合.
public class User{
private String id;
private String name;
private Set<Privilege> privileges=new LinkedHashSet<Privilege>();
}
public class Privilege{
private String id;
private String userId;
private int privilegeLevel;
}
一對多的映射文件
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="User_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<set name="privileges">
<key column="userId"/>
<one-to-many class="com.sitinspring.domain.Privilege"/>
</set>
</class>
</hibernate-mapping>
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Privilege"
table="Privilege_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="userId" column="userId" />
<property name="privilegeLevel" column="privilegeLevel" />
</class>
</hibernate-mapping>
一對多的表數(shù)據(jù)

多對多
多對多關(guān)系 是指兩個類相互擁有對方的集合,如文章和標(biāo)簽兩個類,一篇文章可能有多個標(biāo)簽,一個標(biāo)簽可能對應(yīng)多篇文章.要實現(xiàn)這種關(guān)系需要一個中間表的輔助.
類代碼如右:
public class Article{
private String id;
private String name;
private Set<Tag> tags = new HashSet<Tag>();
}
public class Tag{
private String id;
private String name;
private Set<Article> articles = new HashSet<Article>();
}
多對多的映射文件
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Article" table="ARTICLE_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="NAME" />
<set name="tags" table="ARTICLETAG_TB" cascade="all" lazy="false">
<key column="ARTICLEID" />
<many-to-many column="TAGID" class="com.sitinspring.domain.Tag" />
</set>
</class>
</hibernate-mapping>
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Tag" table="TAG_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="NAME" />
<set name="articles" table="ARTICLETAG_TB" cascade="all" lazy="false">
<key column="TAGID" />
<many-to-many column="ARTICLEID" class="com.sitinspring.domain.Article" />
</set>
</class>
</hibernate-mapping>
多對多的表數(shù)據(jù)

源碼下載:
http://www.aygfsteel.com/Files/junglesong/HibernateMapping20080430203526.rar
Criteria查詢
Hibernate中的Criteria API提供了另一種查詢持久化的方法。它讓你能夠使用簡單的API動態(tài)的構(gòu)建查詢,它靈活的特性通常用于搜索條件的數(shù)量可變的情況。
Criteria查詢之所以靈活是因為它可以借助Java語言,在Java的幫助下它擁有超越HQL的功能。Criteria查詢也是Hibernate竭力推薦的一種面向?qū)ο蟮牟樵兎绞健?br />
Criteria查詢的缺點在于只能檢索完整的對象,不支持統(tǒng)計函數(shù),它本身的API也抬高了一定的學(xué)習(xí)坡度。
Criteria查詢示例代碼
Session session=HibernateUtil.getSession();
Criteria criteria=session.createCriteria(User.class);
// 條件一:名稱以關(guān)開頭
criteria.add(Restrictions.like("name", "關(guān)%"));
// 條件二:email出現(xiàn)在數(shù)組中
String[] arr={"1@2.3","2@2.3","3@2.3"};
criteria.add(Restrictions.in("email", arr));
// 條件三:password等于一
criteria.add(Restrictions.eq("password", "1"));
// 排序條件:按登錄時間升序
criteria.addOrder(Order.asc("lastLoginTime"));
List<User> users=(List<User>)criteria.list();
System.out.println("返回的User實例數(shù)為"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
Criteria查詢實際產(chǎn)生的SQL語句
select
this_.ID as ID0_0_,
this_.name as name0_0_,
this_.pswd as pswd0_0_,
this_.email as email0_0_,
this_.lastLoginTime as lastLogi5_0_0_,
this_.lastLoginIp as lastLogi6_0_0_
from
USERTABLE_OKB this_
where
this_.name like '關(guān)%'
and this_.email in (
'1@2.3', '2@2.3', '3@2.3'
)
and this_.pswd='1'
order by
this_.lastLoginTime asc
注:參數(shù)是手工加上的。
HQL介紹
Hibernate中不使用SQL而是有自己的面向?qū)ο蟛樵冋Z言,該語言名為Hibernate查詢語言(Hibernate Query Language).HQL被有意設(shè)計成類似SQL,這樣開發(fā)人員可以利用已有的SQL知識,降低學(xué)習(xí)坡度.它支持常用的SQL特性,這些特性被封裝成面向?qū)ο蟮牟樵冋Z言,從某種意義上來說,由HQL是面向?qū)ο蟮?因此比SQL更容易編寫.
本文將逐漸介紹HQL的特性.
查詢數(shù)據(jù)庫中所有實例
要得到數(shù)據(jù)庫中所有實例,HQL寫為”from 對象名”即可,不需要select子句,當(dāng)然更不需要Where子句.代碼如右.
Query query=session.createQuery("from User");
List<User> users=(List<User>)query.list();
for(User user:users){
System.out.println(user);
}
限制返回的實例數(shù)
設(shè)置查詢的maxResults屬性可限制返回的實例(記錄)數(shù),代碼如右:
Query query=session.createQuery("from User order by name");
query.setMaxResults(5);
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數(shù)為"+users.size());
for(User user:users){
System.out.println(user);
}
分頁查詢
分頁是Web開發(fā)的常見課題,每種數(shù)據(jù)庫都有自己特定的分頁方案,從簡單到復(fù)雜都有.在Hibernate中分頁問題可以通過設(shè)置firstResult和maxResult輕松的解決.
代碼如右:
Query query=session.createQuery("from User order by name");
query.setFirstResult(3);
query.setMaxResults(5);
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數(shù)為"+users.size());
for(User user:users){
System.out.println(user);
}
條件查詢
條件查詢只要增加Where條件即可.
代碼如右:
Hibernate中條件查詢的實現(xiàn)方式有多種,這種方式的優(yōu)點在于能顯示完整的SQL語句(包括參數(shù))如下.
select
user0_.ID as ID0_,
user0_.name as name0_,
user0_.pswd as pswd0_,
user0_.email as email0_,
user0_.lastLoginTime as lastLogi5_0_,
user0_.lastLoginIp as lastLogi6_0_
from
USERTABLE_OKB user0_
where
user0_.name like '何%'
public static void fetchByName(String prefix){
Session session=HibernateUtil.getSession();
Query query=session.createQuery("from User where name like'"+prefix+"%'");
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數(shù)為"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
}
位置參數(shù)條件查詢
HQL中也可以象jdbc中PreparedStatement一樣為SQL設(shè)定參數(shù),但不同的是下標(biāo)從0開始.
代碼如右:
public static void fetchByPos(String prefix){
Session session=HibernateUtil.getSession();
Query query=session.createQuery("from User where name=?");
// 注意下標(biāo)是從0開始,和jdbc中PreparedStatement從1開始不同
query.setParameter(0, prefix);
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數(shù)為"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
}
命名參數(shù)條件查詢
使用位置參數(shù)條件查詢最大的不便在于下標(biāo)與?號位置的對應(yīng)上,如果參數(shù)較多容易導(dǎo)致錯誤.這時采用命名參數(shù)條件查詢更好.
使用命名參數(shù)時無需知道每個參數(shù)的索引位置,這樣就可以節(jié)省填充查詢參數(shù)的時間.
如果有一個命名參數(shù)出現(xiàn)多次,那在每個地方都會設(shè)置它.
public static void fetchByNamedParam(){
Session session=HibernateUtil.getSession();
Query query=session.createQuery("from User where name=:name");
query.setParameter("name", "李白");
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數(shù)為"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
}
命名查詢
命名查詢是嵌在XML映射文件中的查詢。通常,將給定對象的所有查詢都放在同一文件中,這種方式可使維護相對容易些。命名查詢語句寫在映射定義文件的最后面。
執(zhí)行代碼如下:
Session session=HibernateUtil.getSession();
Query query=session.getNamedQuery("user.sql");
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數(shù)為"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
映射文件節(jié)選:
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
</class>
<query name="user.sql">
<![CDATA[from User where email='2@2.3']]>
</query>
</hibernate-mapping>
主要的Hibernate組件

Configuration類
Configuration類啟動Hibernate的運行環(huán)境部分,用于加載映射文件以及為它們創(chuàng)建一個SessionFacotry。完成這兩項功能后,就可丟棄Configuration類。
// 從hibernate.cfg.xml創(chuàng)建SessionFactory 示例
sessionFactory = new Configuration().configure()
.buildSessionFactory();
SessionFactory類
Hibernate中Session表示到數(shù)據(jù)庫的連接(不止于此),而SessionFactory接口提供Session類的實例。
SessionFactory實例是線程安全的,通常在整個應(yīng)用程序中共享。
從Configuration創(chuàng)建SessionFacotry的代碼如右。
// 從hibernate.cfg.xml創(chuàng)建SessionFactory 示例
SessionFactory sessionFactory = new Configuration().configure()
.buildSessionFactory();
Session類
Session表示到數(shù)據(jù)庫的連接,session類的實例是到Hibernate框架的主要接口,使你能夠持久化對象,查詢持久化以及將持久化對象轉(zhuǎn)換為臨時對象。
Session實例不是線程安全的,只能將其用于應(yīng)用中的事務(wù)和工作單元。
創(chuàng)建Session實例的代碼如右:
SessionFactory sessionFactory = new Configuration().configure()
.buildSessionFactory();
Session session=sessionFactory.openSession();
保存一個對象
用Hibernate持久化一個臨時對象也就是將它保存在Session實例中:
對user實例調(diào)用save時,將給該實例分配一個生成的ID值,并持久化該實例,在此之前實例的id是null,之后具體的id由生成器策略決定,如果生成器類型是assignd,Hibernate將不會給其設(shè)置ID值。
Flush()方法將內(nèi)存中的持久化對象同步到數(shù)據(jù)庫。存儲對象時,Session不會立即將其寫入數(shù)據(jù)庫;相反,session將大量數(shù)據(jù)庫寫操作加入隊列,以最大限度的提高性能。
User user=new User(“Andy”,22);
Session session=sessionFatory.openSession();
session.save(user);
session.flush();
session.close();
保存或更新一個對象
Hibernate提供了一種便利的方法用于在你不清楚實例對應(yīng)的數(shù)據(jù)在數(shù)據(jù)庫中的狀態(tài)時保存或更新一個對象,也就是說,你不能確定具體是要保存save還是更新update,只能確定需要把對象同步到數(shù)據(jù)庫中。這個方法就是saveOrUpdate。
Hibernate在持久化時會查看實例的id屬性,如果其為null則判斷此對象是臨時的,在數(shù)據(jù)庫中找不到對應(yīng)的實例,其后選擇保存這個對象;而不為空時則意味著對象已經(jīng)持久化,應(yīng)該在數(shù)據(jù)庫中更新該對象,而不是將其插入。
User user=。。。;
Session session=sessionFatory.openSession();
session.saveOrUpdate(user);
Session.flush();
session.close();
刪除一個對象
從數(shù)據(jù)庫刪除一個對象使用session的delete方法,執(zhí)行刪除操作后,對象實例依然存在,但數(shù)據(jù)庫中對應(yīng)的記錄已經(jīng)被刪除。
User user=。。。;
Session session=sessionFatory.openSession();
session.delete(user);
session.flush();
session.close();
以ID從數(shù)據(jù)庫中取得一個對象
如果已經(jīng)知道一個對象的id,需要從數(shù)據(jù)庫中取得它,可以使用Session的load方法來返回它。代碼如右.
注意此放在id對應(yīng)的記錄不存在時會拋出一個HibernateException異常,它是一個非檢查性異常。對此的正確處理是捕獲這個異常并返回一個null。
使用此想法如果采用默認的懶惰加載會導(dǎo)致異常,對此最簡單的解決方案是把默認的懶惰加載屬性修改為false。如右:
User user=(User)session.load(User.class,"008");
session.close();
-----------------------------------------------
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
。。。。
</class>
</hibernate-mapping>
檢索一批對象
檢索一批對象需要使用HQL,session接口允許你創(chuàng)建Query對象以檢索持久化對象,HQL是面向?qū)ο蟮模阈枰槍︻惡蛯傩詠頃鴮懩愕腍QL而不是表和字段名。
從數(shù)據(jù)庫中查詢所有用戶對象如下:
Query query=session.createQuery(“from User”);// 注意這里User是類名,from前沒有select。
List<User> users=(List<User>)query.list();
從數(shù)據(jù)庫中查詢名為“Andy”的用戶如下:
String name=“Andy”;
Query query=session.createQuery(“from User where name=‘”+name+”’”);
List<User> users=(List<User>)query.list();
以上方法類似于Statement的寫法,你還可以如下書寫:
Query query=session.createQuery("from User user where user.name = :name");
query.setString("name", “Andy");
List<User> users=(List<User>)query.list();
Hibernate的映射文件
映射文件也稱映射文檔,用于向Hibernate提供關(guān)于將對象持久化到關(guān)系數(shù)據(jù)庫中的信息.
持久化對象的映射定義可全部存儲在同一個映射文件中,也可將每個對象的映射定義存儲在獨立的文件中.后一種方法較好,因為將大量持久化類的映射定義存儲在一個文件中比較麻煩,建議采用每個類一個文件的方法來組織映射文檔.使用多個映射文件還有一個優(yōu)點:如果將所有映射定義都存儲到一個文件中,將難以調(diào)試和隔離特定類的映射定義錯誤.
映射文件的命名規(guī)則是,使用持久化類的類名,并使用擴展名hbm.xml.
映射文件需要在hibernate.cfg.xml中注冊,最好與領(lǐng)域?qū)ο箢惙旁谕荒夸浿?這樣修改起來很方便.
領(lǐng)域?qū)ο蠛皖?/strong>
public class User{
// ID
private String id;
// 名稱
private String name;
// 密碼
private String password;
// 郵件
private String email;
// 上次登錄時間
private String lastLoginTime;
// 上次登錄ip
private String lastLoginIp;
public User(String name,String password,String email){
this.name=name;
this.password=password;
this.email=email;
}
}
<?xml version="1.0"?><!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd"><hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
</class></hibernate-mapping>
hibernate.cfg.xml中的映射文件設(shè)置
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI數(shù)據(jù)源設(shè)置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect適合所有Oracle數(shù)據(jù)庫 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
<!-- 顯示SQL語句 -->
<property name="show_sql">true</property>
<!-- SQL語句整形 -->
<property name="format_sql">true</property>
<!-- 啟動時創(chuàng)建表.這個選項在第一次啟動程序時放開,以后切記關(guān)閉 -->
<!-- <property name="hbm2ddl.auto">create</property> -->
<!-- 持久化類的映射文件 -->
<mapping resource="com/sitinspring/domain/User.hbm.xml" />
<mapping resource="com/sitinspring/domain/Privilege.hbm.xml" />
<mapping resource="com/sitinspring/domain/Article.hbm.xml" />
<mapping resource="com/sitinspring/domain/Record.hbm.xml" />
</session-factory>
</hibernate-configuration>
映射文件物理位置示例
映射文件的基本結(jié)構(gòu)
映射定義以hibernate-mapping元素開始, package屬性設(shè)置映射中非限定類名的默認包.設(shè)置這個屬性后,對于映射文件中列出的其它持久化類,只需給出類名即可.要引用指定包外的持久化類,必須在映射文件中提供全限定類名.
在hibernate-mapping標(biāo)簽之后是class標(biāo)簽.class標(biāo)簽開始指定持久化類的映射定義.table屬性指定用于存儲對象狀態(tài)的關(guān)系表.class元素有很多屬性,下面將逐個介紹.
ID
Id元素描述了持久化類的主碼以及他們的值如何生成.每個持久化類必須有一個ID元素,它聲明了關(guān)系表的主碼.如右:
Name屬性指定了持久化類中用于保存主碼值的屬性,該元素表明,User類中有一個名為id的屬性.如果主碼字段與對象屬性不同,則可以使用column屬性.
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
生成器
生成器創(chuàng)建持久化類的主碼值.Hibernate提供了多個生成器實現(xiàn),它們采用了不同的方法來創(chuàng)建主碼值.有的是自增長式的,有點創(chuàng)建十六進制字符串, 還可以讓外界生成并指定對象ID,另外還有一種Select生成器你那個從數(shù)據(jù)庫觸發(fā)器trigger檢索值來獲得主碼值.
右邊使用了用一個128-bit的UUID算法生成字符串類型的標(biāo)識符, 這在一個網(wǎng)絡(luò)中是唯一的(使用了IP地址)。UUID被編碼為一個32位16進制數(shù)字的字符串 .這對字段類型是字符串的id字段特別有效.UUID作為ID字段主鍵是非常合適的,比自動生成的long類型id方式要好。
UUID示例
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
自動增長的id
<id name="id" column="ID" type="long">
<generator class="native"/>
</id>
屬性
在映射定義中,property元素與持久化對象的一個屬性對應(yīng),name表示對象的屬性名,column表示對應(yīng)表中的列(字段),type屬性指定了屬性的對象類型,如果type被忽略的話,Hibernate將使用運行階段反射機制來判斷類型.
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
獲取Hibernate
在創(chuàng)建Hibernate項目之前,我們需要從網(wǎng)站獲得最新的Hibernate版本。Hibernate主頁是www.hibernate.org,找到其菜單中的download連接,選擇最新的Hibernate版本即可。下載后將其解開到一個目錄中。
右邊是解開后的主要目錄。其中最重要的是hibernate.jar,它包含全部框架代碼;lib目錄,包括Hibernate的所有依賴庫;doc目錄,包括JavDocs和參考文檔。
Hibernate的配置文件
Hibernate能夠與從應(yīng)用服務(wù)器(受控環(huán)境,如Tomcat,Weblogic,JBoss)到獨立的應(yīng)用程序(非受控環(huán)境,如獨立應(yīng)用程序)的各種環(huán)境和諧工作,這在一定程度上要歸功于其配置文件hibernate.cfg.xml,通過特定的設(shè)置Hibernate就能與各種環(huán)境配合。右邊是hibernate.cfg.xml的一個示例。
配置Hibernate的所有屬性是一項艱巨的任務(wù),下面將依此介紹Hibernate部署將用到的基本配置。
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI數(shù)據(jù)源設(shè)置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect適合所有Oracle數(shù)據(jù)庫 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
<!-- 顯示SQL語句 -->
<property name="show_sql">true</property>
<!-- SQL語句整形 -->
<property name="format_sql">true</property>
<!-- 啟動時創(chuàng)建表.這個選項在第一次啟動程序時放開,以后切記關(guān)閉 -->
<!-- <property name="hbm2ddl.auto">create</property> -->
<!-- 持久化類的配置文件 -->
<mapping resource="com/sitinspring/domain/User.hbm.xml" />
<mapping resource="com/sitinspring/domain/Privilege.hbm.xml" />
<mapping resource="com/sitinspring/domain/Article.hbm.xml" />
<mapping resource="com/sitinspring/domain/Record.hbm.xml" />
</session-factory>
</hibernate-configuration>
使用Hibernate管理的JDBC連接
右邊配置文件中的Database connection settings 部分制定了Hibernate管理的JDBC連接, 這在非受控環(huán)境如桌面應(yīng)用程序中很常見。
其中各項屬性為:
connection.driver_class:用于特定數(shù)據(jù)庫的JDBC連接類
connection.url:數(shù)據(jù)庫的完整JDBC URL
connection.username:用于連接到數(shù)據(jù)庫的用戶名
connection.password:用戶密碼
這種方案可用于非受控環(huán)境和基本測試,但不宜在生產(chǎn)環(huán)境中使用。
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- Database connection settings -->
<property name="connection.driver_class">org.hsqldb.jdbcDriver</property>
<property name="connection.url">jdbc:hsqldb:hsql://localhost</property>
<property name="connection.username">sa</property>
<property name="connection.password"></property>
<!-- JDBC connection pool (use the built-in) -->
<property name="connection.pool_size">1</property>
<!-- SQL dialect -->
<property name="dialect">org.hibernate.dialect.HSQLDialect</property>
<!-- Enable Hibernate's automatic session context management -->
<property name="current_session_context_class">thread</property>
。。。。。。。。
</session-factory>
</hibernate-configuration>
使用JNDI 數(shù)據(jù)源
在受控環(huán)境中,我們可以使用容器提供的數(shù)據(jù)源,這將使數(shù)據(jù)庫訪問更加快捷,右邊就是使用Tomcat提供的數(shù)據(jù)源的配置部分。
附:Server.Xml中的數(shù)據(jù)源設(shè)置
<Context path="/MyTodoes" reloadable="true" docBase="E:\Program\Programs\MyTodoes" workDir="E:\Program\Programs\MyTodoes\work" >
<Resource name="jdbc/myoracle" auth="Container"
type="javax.sql.DataSource" driverClassName="oracle.jdbc.OracleDriver"
url="jdbc:oracle:thin:@192.168.104.173:1521:orcl"
username="hy" password="123456" maxActive="20" maxIdle="10"
maxWait="-1"/>
</Context>
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI數(shù)據(jù)源設(shè)置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect適合所有Oracle數(shù)據(jù)庫 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
</hibernate-configuration>
數(shù)據(jù)庫方言
Dialect屬性能告知Hibernate執(zhí)行特定的操作如分頁時需要使用那種SQL方言,如MySql的分頁方案和Oracle的大相徑庭,如設(shè)置錯誤或沒有設(shè)置一定會導(dǎo)致問題。
附錄:常見的數(shù)據(jù)庫方言
DB2 :org.hibernate.dialect.DB2Dialect
MySQL :org.hibernate.dialect.MySQLDialect
Oracle (any version) :org.hibernate.dialect.OracleDialect
Oracle 9i/10g :org.hibernate.dialect.Oracle9Dialect
Microsoft SQL Server :org.hibernate.dialect.SQLServerDialect
Sybase Anywhere :org.hibernate.dialect.SybaseAnywhereDialect
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI數(shù)據(jù)源設(shè)置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect適合所有Oracle數(shù)據(jù)庫 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
<!-- 顯示SQL語句 -->
<property name="show_sql">true</property>
<!-- SQL語句整形 -->
<property name="format_sql">true</property>
</hibernate-configuration>
其它屬性
show_sql:它可以在程序運行過程中顯示出真正執(zhí)行的SQL語句來,建議將這個屬性始終打開,它將有益于錯誤診斷。
format_sql:將這個屬性設(shè)置為true能將輸出的SQL語句整理成規(guī)范的形狀,更方便用于查看SQL語句。
hbm2ddl.auto:將其設(shè)置為create能在程序啟動是根據(jù)類映射文件的定義創(chuàng)建實體對象對應(yīng)的表,而不需要手動去建表,這在程序初次安裝時很方便。
如果表已經(jīng)創(chuàng)建并有數(shù)據(jù),切記關(guān)閉這個屬性,否則在創(chuàng)建表時也會清除掉原有的數(shù)據(jù),這也許會導(dǎo)致很嚴(yán)重的后果。
從后果可能帶來的影響來考慮,在用戶處安裝完一次后就應(yīng)該刪除掉這個節(jié)點
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
。。。。。。
<!-- 顯示SQL語句 -->
<property name="show_sql">true</property>
<!-- SQL語句整形 -->
<property name="format_sql">true</property>
<!-- 啟動時創(chuàng)建表.這個選項在第一次啟動程序時放開,以后切記關(guān)閉 -->
<!-- <property name="hbm2ddl.auto">create</property> -->
。。。。。。
</hibernate-configuration>
映射定義
在hibernate.cfg.xml中,還有一個重要部分就是映射定義,這些文件用于向Hibernate提供關(guān)于將對象持久化到關(guān)系數(shù)據(jù)庫的信息。
一般來說,領(lǐng)域?qū)佑幸粋€領(lǐng)域?qū)ο缶陀幸粋€映射文件,建議將它們放在同一目錄(domain)下以便查閱和修改,映射文件的命名規(guī)則是:持久化類的類名+.hbm.xml
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI數(shù)據(jù)源設(shè)置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
。。。。。。
<!-- 持久化類的配置文件 -->
<mapping resource="com/sitinspring/domain/User.hbm.xml" />
<mapping resource="com/sitinspring/domain/Privilege.hbm.xml" />
<mapping resource="com/sitinspring/domain/Article.hbm.xml" />
<mapping resource="com/sitinspring/domain/Record.hbm.xml" />
</session-factory>
</hibernate-configuration>
本文假定讀者已經(jīng)熟知以下知識
能夠熟練使用JDBC創(chuàng)建Java應(yīng)用程序;
創(chuàng)建過以數(shù)據(jù)庫為中心的應(yīng)用
理解基本的關(guān)系理論和結(jié)構(gòu)化查詢語言SQL (Strutured Query Language)
Hibernate
Hibernate是一個用于開發(fā)Java應(yīng)用的對象/關(guān)系映射框架。它通過在數(shù)據(jù)庫中為開發(fā)人員存儲應(yīng)用對象,在數(shù)據(jù)庫和應(yīng)用之間提供了一座橋梁,開發(fā)人員不必編寫大量的代碼來存儲和檢索對象,省下來的精力更多的放在問題本身上。
持久化與關(guān)系數(shù)據(jù)庫
持久化的常見定義:使數(shù)據(jù)的存活時間超過創(chuàng)建該數(shù)據(jù)的進程的存活時間。數(shù)據(jù)持久化后可以重新獲得它;如果外界進程沒有修改它,它將與持久化之前相同。對于一般應(yīng)用來說,持久化指的是將數(shù)據(jù)存儲在關(guān)系數(shù)據(jù)庫中。
關(guān)系數(shù)據(jù)庫是為管理數(shù)據(jù)而設(shè)計的,它在存儲數(shù)據(jù)方面很流行,這主要歸功于易于使用SQL來創(chuàng)建和訪問。
關(guān)系數(shù)據(jù)庫使用的模型被稱為關(guān)系模型,它使用二維表來表示數(shù)據(jù)。這種數(shù)據(jù)邏輯視圖表示了用戶如何看待包含的數(shù)據(jù)。表可以通過主碼和外碼相互關(guān)聯(lián)。主碼唯一的標(biāo)識了表中的一行,而外碼是另一個表中的主碼。
對象/關(guān)系阻抗不匹配
關(guān)系數(shù)據(jù)庫是為管理數(shù)據(jù)設(shè)計的,它適合于管理數(shù)據(jù)。然而,在面向?qū)ο蟮膽?yīng)用中,將對象持久化為關(guān)系模型可能會遇到問題。這個問題的根源是因為關(guān)系數(shù)據(jù)庫管理數(shù)據(jù),而面向?qū)ο蟮膽?yīng)用是為業(yè)務(wù)問題建模而設(shè)計的。由于這兩種目的不同,要使這兩個模型協(xié)同工作可能具有挑戰(zhàn)性。這個問題被稱為 對象/關(guān)系阻抗不匹配(Object/relational impedance mismatch)或簡稱為阻抗不匹配
阻抗不匹配的幾個典型方面
在應(yīng)用中輕易實現(xiàn)的對象相同或相等,這樣的關(guān)系在關(guān)系數(shù)據(jù)庫中不存在。
在面向?qū)ο笳Z言的一項核心特性是繼承,繼承很重要,因為它允許創(chuàng)建問題的精確模型,同時可以在層次結(jié)構(gòu)中自上而下的共享屬性和行為。而關(guān)系數(shù)據(jù)庫不支持繼承的概念。
對象之間可以輕易的實現(xiàn)一對一,一對多和多對多的關(guān)聯(lián)關(guān)系,而數(shù)據(jù)庫并不理解這些,它只知道外碼指向主碼。
對象/關(guān)系映射
前頁列舉了一些阻抗不匹配的問題,當(dāng)然開發(fā)人員是可以解決這些問題,但這一過程并不容易。對象/關(guān)系映射(Object/Relational Mapping)就是為解決這些問題而開發(fā)的。
ORM在對象模型和關(guān)系模型之間架起了一座橋梁,讓應(yīng)用能夠直接持久化對象,而不要求在對象和關(guān)系之間進行轉(zhuǎn)換。Hibernate就是ORM工具中最成功的一種。它的主要優(yōu)點是簡單,靈活,功能完備和高效。
Hibernate的優(yōu)點之一:簡單
Hibernate不像有些持久化方案那樣需要很多的類和配置屬性,它只需要一個運行階段配置文件已經(jīng)為每個要持久化的應(yīng)用對象指定一個XML格式的映射文件。
映射文件可以很短,讓框架決定映射的其它內(nèi)容,也可以通過制定額外的屬性,如屬性的可選列名,向框架提供更多信息。如右就是一個映射文檔的示例。
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
</class>
</hibernate-mapping>
Hibernate的優(yōu)點之二:功能完備
Hibernate支持所有的面向?qū)ο筇匦裕ɡ^承,自定義對象類型和集合。它可以讓你創(chuàng)建模型時不必考慮持久層的局限性。
Hibernate提供了一個名為HQL的查詢語言,它與SQL非常相似,只是用對象屬性名代替了表的列。很多通過SQL實現(xiàn)的常用功能都能用HQL實現(xiàn)。
Hibernate的優(yōu)點之三:高效
Hibernate使用懶惰加載提高了性能,在Hibernate并不在加載父對象時就加載對象集合,而只在應(yīng)用需要訪問時才生成。這就避免了檢索不必要的對象而影響性能。
Hibernate允許檢索主對象時選擇性的禁止檢索關(guān)聯(lián)的對象,這也是一項改善性能的特性。
對象緩存在提高應(yīng)用性能方面也發(fā)揮了很大的作用。Hibernate支持各種開源和緩存產(chǎn)品,可為持久化類或持久化對象集合啟用緩存。
總結(jié)
在同一性,繼承和關(guān)聯(lián)三方面,對象模型和關(guān)系模型存在著阻抗不匹配,這是眾多ORM框架致力解決的問題,hibernate是這些方案中最成功的一個,它的主要優(yōu)點是簡單,靈活,功能完備和高效。
使用Hibernate不要求領(lǐng)域?qū)ο髮崿F(xiàn)特別的接口或使用應(yīng)用服務(wù)器,它支持集合,繼承,自定義數(shù)據(jù)類型,并攜帶一種強大的查詢語言HQL,能減少很多持久化方面的工作量,使程序員能把更多精力轉(zhuǎn)移到問題本身上來。
C/S 架構(gòu)
C/S 架構(gòu)是一種典型的兩層架構(gòu),其全程是Client/Server,即客戶端服務(wù)器端架構(gòu),其客戶端包含一個或多個在用戶的電腦上運行的程序,而服務(wù)器端有兩種,一種是數(shù)據(jù)庫服務(wù)器端,客戶端通過數(shù)據(jù)庫連接訪問服務(wù)器端的數(shù)據(jù);另一種是Socket服務(wù)器端,服務(wù)器端的程序通過Socket與客戶端的程序通信。
C/S 架構(gòu)也可以看做是胖客戶端架構(gòu)。因為客戶端需要實現(xiàn)絕大多數(shù)的業(yè)務(wù)邏輯和界面展示。這種架構(gòu)中,作為客戶端的部分需要承受很大的壓力,因為顯示邏輯和事務(wù)處理都包含在其中,通過與數(shù)據(jù)庫的交互(通常是SQL或存儲過程的實現(xiàn))來達到持久化數(shù)據(jù),以此滿足實際項目的需要。
C/S 架構(gòu)的優(yōu)缺點
優(yōu)點:
1.C/S架構(gòu)的界面和操作可以很豐富。
2.安全性能可以很容易保證,實現(xiàn)多層認證也不難。
3.由于只有一層交互,因此響應(yīng)速度較快。
缺點:
1.適用面窄,通常用于局域網(wǎng)中。
2.用戶群固定。由于程序需要安裝才可使用,因此不適合面向一些不可知的用戶。
3.維護成本高,發(fā)生一次升級,則所有客戶端的程序都需要改變。
B/S架構(gòu)
B/S架構(gòu)的全稱為Browser/Server,即瀏覽器/服務(wù)器結(jié)構(gòu)。Browser指的是Web瀏覽器,極少數(shù)事務(wù)邏輯在前端實現(xiàn),但主要事務(wù)邏輯在服務(wù)器端實現(xiàn),Browser客戶端,WebApp服務(wù)器端和DB端構(gòu)成所謂的三層架構(gòu)。B/S架構(gòu)的系統(tǒng)無須特別安裝,只有Web瀏覽器即可。
B/S架構(gòu)中,顯示邏輯交給了Web瀏覽器,事務(wù)處理邏輯在放在了WebApp上,這樣就避免了龐大的胖客戶端,減少了客戶端的壓力。因為客戶端包含的邏輯很少,因此也被成為瘦客戶端。
B/S架構(gòu)的優(yōu)缺點
優(yōu)點:
1)客戶端無需安裝,有Web瀏覽器即可。
2)BS架構(gòu)可以直接放在廣域網(wǎng)上,通過一定的權(quán)限控制實現(xiàn)多客戶訪問的目的,交互性較強。
3)BS架構(gòu)無需升級多個客戶端,升級服務(wù)器即可。
缺點:
1)在跨瀏覽器上,BS架構(gòu)不盡如人意。
2)表現(xiàn)要達到CS程序的程度需要花費不少精力。
3)在速度和安全性上需要花費巨大的設(shè)計成本,這是BS架構(gòu)的最大問題。
4)客戶端服務(wù)器端的交互是請求-響應(yīng)模式,通常需要刷新頁面,這并不是客戶樂意看到的。(在Ajax風(fēng)行后此問題得到了一定程度的緩解)
String的特殊之處
String是Java編程中很常見的一個類,這個類的實例是不可變的(immutable ).為了提高效率,JVM內(nèi)部對其操作進行了一些特殊處理,本文就旨在于幫助大家辨析這些特殊的地方.
在進入正文之前,你需要澄清這些概念:
1) 堆與棧
2) 相同與相等,==與equals
3) =的真實意義.
棧與堆
1. 棧(stack)與堆(heap)都是Java用來在內(nèi)存中存放數(shù)據(jù)的地方。與C++不同,Java自動管理棧和堆,程序員不能直接地設(shè)置棧或堆。每個函數(shù)都有自己的棧,而一個程序只有一個堆.
2. 棧的優(yōu)勢是,存取速度比堆要快,僅次于直接位于CPU中的寄存器。但缺點是,存在棧中的數(shù)據(jù)大小與生存期必須是確定的,缺乏靈活性。另外,棧數(shù)據(jù)可以共享,詳見第3點。堆的優(yōu)勢是可以動態(tài)地分配內(nèi)存大小,生存期也不必事先告訴編譯器,Java的垃圾收集器會自動收走這些不再使用的數(shù)據(jù)。但缺點是,由于要在運行時動態(tài)分配內(nèi)存,存取速度較慢。 3. Java中的數(shù)據(jù)類型有兩種。 一種是基本類型(primitive types), 共有8種,即int, short, long, byte, float, double, boolean, char(注意,并沒有string的基本類型)。這種類型的定義是通過諸如int a = 3; long b = 255L;的形式來定義的,稱為自動變量。值得注意的是,自動變量存的是字面值,不是類的實例,即不是類的引用,這里并沒有類的存在。如int a = 3; 這里的a是一個指向int類型的引用,指向3這個字面值。這些字面值的數(shù)據(jù),由于大小可知,生存期可知(這些字面值固定定義在某個程序塊里面,程序塊退出后,字段值就消失了),出于追求速度的原因,就存在于棧中。 另外,棧有一個很重要的特殊性,就是存在棧中的數(shù)據(jù)可以共享。假設(shè)我們同時定義 int a = 3; int b = 3; 編譯器先處理int a = 3;首先它會在棧中創(chuàng)建一個變量為a的引用,然后查找有沒有字面值為3的地址,沒找到,就開辟一個存放3這個字面值的地址,然后將a指向3的地址。接著處理int b = 3;在創(chuàng)建完b的引用變量后,由于在棧中已經(jīng)有3這個字面值,便將b直接指向3的地址。這樣,就出現(xiàn)了a與b同時均指向3的情況。 特別注意的是,這種字面值的引用與類對象的引用不同。假定兩個類對象的引用同時指向一個對象,如果一個對象引用變量修改了這個對象的內(nèi)部狀態(tài),那么另一個對象引用變量也即刻反映出這個變化。相反,通過字面值的引用來修改其值,不會導(dǎo)致另一個指向此字面值的引用的值也跟著改變的情況。如上例,我們定義完a與 b的值后,再令a=4;那么,b不會等于4,還是等于3。在編譯器內(nèi)部,遇到a=4;時,它就會重新搜索棧中是否有4的字面值,如果沒有,重新開辟地址存放4的值;如果已經(jīng)有了,則直接將a指向這個地址。因此a值的改變不會影響到b的值。 另一種是包裝類數(shù)據(jù),如Integer, String, Double等將相應(yīng)的基本數(shù)據(jù)類型包裝起來的類。這些類數(shù)據(jù)全部存在于堆中,Java用new()語句來顯示地告訴編譯器,在運行時才根據(jù)需要動態(tài)創(chuàng)建,因此比較靈活,但缺點是要占用更多的時間。
相同與相等,==與equals
在Java中,相同指的是兩個變量指向的地址相同,地址相同的變量自然值相同;而相等是指兩個變量值相等,地址可以不同.
相同的比較使用==,而相等的比較使用equals.
對于字符串變量的值比較來說,我們一定要使用equals而不是==.
=的真實意義
=即賦值操作,這里沒有問題,關(guān)鍵是這個值有時是真正的值,有的是地址,具體來說會根據(jù)等號右邊的部分而變化.
如果是基本類型(八種),則賦值傳遞的是確定的值,即把右邊變量的值傳遞給左邊的變量.
如果是類類型,則賦值傳遞的是變量的地址,即把等號左邊的變量地址指向等號右邊的變量地址.
指出下列代碼的輸出
String andy="andy";
String bill="andy";
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
String str=“andy”的機制分析
上頁代碼的輸出是andy和bill地址相同.
當(dāng)通過String str=“andy”;的方式定義一個字符串時,JVM先在棧中尋找是否有值為“andy”的字符串,如果有則將str指向棧中原有字符串的地址;如果沒有則創(chuàng)建一個,再將str的地址指向它. String andy=“andy”這句代碼走的是第二步,而String bill=“andy”走的是第一步,因此andy和bill指向了同一地址,故而andy==bill,andy和bill地址相等,所以輸出是andy和bill地址相同.
這樣做能節(jié)省空間—少創(chuàng)建一個字符串;也能節(jié)省時間—定向總比創(chuàng)建要省時.
指出下列代碼的輸出
String andy="andy";
String bill="andy";
bill="bill";
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
輸出及解釋
上頁代碼的輸出是:andy和bill地址不同
當(dāng)執(zhí)行bill=“bill”一句時,外界看來好像是給bill變換了一個新值bill,但JVM的內(nèi)部操作是把棧變量bill的地址重新指向了棧中一塊值為bill的新地址,這是因為字符串的值是不可變的,要換值(賦值操作)只有將變量地址重新轉(zhuǎn)向. 這樣andy和bill的地址在執(zhí)行bill=“bill”一句后就不一樣了,因此輸出是andy和bill地址不同.
指出下列代碼的輸出
String andy=new String("andy");
String bill=new String("andy");
// 地址比較
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比較
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
輸出及機制分析
andy和bill地址不同
andy和bill值相等
我們知道new操作新建出來的變量一定處于堆中,字符串也是一樣.
只要是用new()來新建對象的,都會在堆中創(chuàng)建,而且其字符串是單獨存值的,即每個字符串都有自己的值,自然地址就不會相同.因此輸出了andy和bill地址不同.
equals操作比較的是值而不是地址,地址不同的變量值可能相同,因此輸出了andy和bill值相等.
指出下列代碼的輸出
String andy=new String("andy");
String bill=new String(andy);
// 地址比較
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比較
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
輸出
andy和bill地址不同
andy和bill值相等
道理仍和第八頁相同.只要是用new()來新建對象的,都會在堆中創(chuàng)建,而且其字符串是單獨存值的,即每個字符串都有自己的值,自然地址就不會相同.
指出下列代碼的輸出
String andy="andy";
String bill=new String(“Bill");
bill=andy;
// 地址比較
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比較
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
輸出及解析
andy和bill地址相同
andy和bill值相等
String bill=new String(“Bill”)一句在棧中創(chuàng)建變量bill,指向堆中創(chuàng)建的”Bill”,這時andy和bill地址和值都不相同;而執(zhí)行bill=andy;一句后,棧中變量bill的地址就指向了andy,這時bill和andy的地址和值都相同了.而堆中的”Bill”則沒有指向它的指針,此后這塊內(nèi)存將等待被垃圾收集.
指出下列代碼的輸出
String andy="andy";
String bill=new String("bill");
andy=bill;
// 地址比較
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比較
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
輸出
andy和bill地址相同
andy和bill值相等
道理同第十二頁
結(jié)論
使用諸如String str = “abc”;的語句在棧中創(chuàng)建字符串時時,str指向的字符串不一定會被創(chuàng)建!唯一可以肯定的是,引用str本身被創(chuàng)建了。至于這個引用到底是否指向了一個新的對象,必須根據(jù)上下文來考慮,如果棧中已有這個字符串則str指向它,否則創(chuàng)建一個再指向新創(chuàng)建出來的字符串. 清醒地認識到這一點對排除程序中難以發(fā)現(xiàn)的bug是很有幫助的。
使用String str = “abc”;的方式,可以在一定程度上提高程序的運行速度,因為JVM會自動根據(jù)棧中數(shù)據(jù)的實際情況來決定是否有必要創(chuàng)建新對象。而對于String str = new String(“abc”);的代碼,則一概在堆中創(chuàng)建新對象,而不管其字符串值是否相等,是否有必要創(chuàng)建新對象,從而加重了程序的負擔(dān)。
如果使用new()來新建字符串的,都會在堆中創(chuàng)建字符串,而且其字符串是單獨存值的,即每個字符串都有自己的值,且其地址絕不會相同
當(dāng)比較包裝類里面的數(shù)值是否相等時,用equals()方法;當(dāng)測試兩個包裝類的引用是否指向同一個對象時,用==。
由于String類的immutable性質(zhì),當(dāng)String變量需要經(jīng)常變換其值如SQL語句拼接,HTML文本輸出時,應(yīng)該考慮使用StringBuffer類,以提高程序效率。
摘要: 序言:本指南旨在幫助你建立全面的個人品牌戰(zhàn)略。個人品牌的建立是你銷售自己從而在商業(yè)上取得成功的重要一環(huán)。個人品牌的建立是一個持續(xù)的過程正如你不斷認識自己的過程。你自己強大了,品牌也亦然。在全球化導(dǎo)致工作競爭加劇的今天,個人品牌的提升也顯得尤為重要。正如像金子那樣發(fā)光,你能在人群中嶄露自己,就能步入精英的行列。如今這場角力將比你的預(yù)想更為激烈和艱難。
或許是David Samuel這個家伙把我?guī)нM個人品牌研究這一行的,幾年前我看了他的報告。他在報告中說了我們?yōu)槭裁葱枰獋€人品牌。當(dāng)時他的聽眾來自一個電信大公司:
“如果我們根據(jù)人的智力把他們劃分三六九等,那么他們就是一群A,一群B,一群C和一群D。因為全球化趨勢,C群和D群的工作已經(jīng)被外包了。一切已經(jīng)過去了。至于留下的你們,現(xiàn)在就要為躋身A群和B群而開始競爭。或許在這個人才濟濟的群體中,你會想用大聲嚷嚷來取得關(guān)注了。如何才能讓自己受到關(guān)注?你該如何讓自己發(fā)光以證明自己可以獲得額外的工作機會?你該如何從身邊每個人都像你一樣能干甚至更甚于你的環(huán)境中勝出?如果你身邊的每個人都是很能干的A群B群,你又該如何與他
閱讀全文
 package com.sitinspring;
package com.sitinspring;

 /** *//**
/** *//**
 * 全排列算法示例
* 全排列算法示例
如果用P表示n個元素的排列,而Pi表示不包含元素i的排列,(i)Pi表示在排列Pi前加上前綴i的排列,那么,n個元素的排列可遞歸定義為:
如果n=1,則排列P只有一個元素i
如果n>1,則排列P由排列(i)Pi構(gòu)成(i=1、2、 .、n-1)。
.、n-1)。
根據(jù)定義,容易看出如果已經(jīng)生成了k-1個元素的排列,那么,k個元素的排列可以在每個k-1個元素的排列Pi前添加元素i而生成。
例如2個元素的排列是1 2和2 1,對3個元素而言,p1是2 3和3 2,在每個排列前加上1即生成1 2 3和1 3 2兩個新排列,
p2和p3則是1 3、3 1和1 2、2 1,
按同樣方法可生成新排列2 1 3、2 3 1和3 1 2、3 2 1。
* @author: sitinspring(junglesong@gmail.com)
* @date: 2008-3-25
 */
*/
public class Permutation<T>{

 public static void main(String[] args){
public static void main(String[] args){
String[] arr={"1","2","3"};
Permutation<String> a=new Permutation<String>();
a.permutation(arr,0,arr.length);
 }
}
public void permutation(T[] arr,int start,int end){
if(start<end+1){
permutation(arr,start+1,end);
for(int i=start+1;i<end;i++){
T temp;
temp=arr[start];
arr[start]=arr[i];
arr[i]=temp;
permutation(arr,start+1,end);
temp=arr[i];
arr[i]=arr[start];
arr[start]=temp;
}
}
else{
for(int i=0;i<end;i++){
System.out.print(arr[i]);
}
System.out.print("\n");
}
}
}
JNDI(Java Naming and Directory Interface)的中文意思是Java命名和目錄接口。
借助于JNDI ,開發(fā)者能夠通過名字定位用戶,機器,網(wǎng)絡(luò),對象,服務(wù)。 JNDI的常見功能有定位資源,如定位到內(nèi)網(wǎng)中一臺打印機,定位Java對象或RDBMS(關(guān)系型數(shù)據(jù)庫管理系統(tǒng))等
在EJB,RMI,JDBC等JavaEE(J2EE)API技術(shù)中JNDI得到了廣泛應(yīng)用。JNDI為J2EE平臺提供了標(biāo)準(zhǔn)的機制,并借助于名字來查找網(wǎng)絡(luò)中的一切對象。
理解“命名和目錄服務(wù)”
在掌握JNDI之前,開發(fā)者必須理解命名和目錄服務(wù)。
名字類似于引用,即能標(biāo)識某實體如對象,人等。在企業(yè)應(yīng)用中,經(jīng)常需要借助于名字實現(xiàn)對各種對象的引用,如借助于名字引用電話號碼,IP地址,遠程對象等。
命名服務(wù)類似于話務(wù)員,如果需要打電話給某人,但又不知道他的電話號碼,于是將電話打到查詢臺,以便能夠詢問到用戶的電話號碼,打電話者需要提供人名給他。隨后,話務(wù)員就能查到那人的電話號碼。
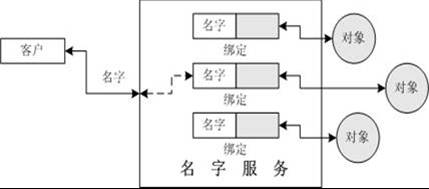
命名服務(wù)的功能
將名字與對象綁定在一起,這類似于電話公司提供的服務(wù),比如將人名綁定到被叫端的電話。
提供根據(jù)名字查找對象的機制。這稱為查找對象或者解析名字。這同電話公司提供的服務(wù)類似,比如根據(jù)人名查找到電話號碼。
在現(xiàn)實的計算機環(huán)境中,命名服務(wù)很常見,如需要定位網(wǎng)絡(luò)中的某臺機器,則借助于域名系統(tǒng)(Domain Name System,DNS)能夠?qū)C器名轉(zhuǎn)化成IP地址。
目錄對象和目錄服務(wù)
在命名服務(wù)中,借助名字能夠找到任何對象,其中有一類對象比較特殊,它能在對象中存儲屬性,它們被稱之為目錄對象或稱之為目錄入口項(Directory Entry)。將目錄對象連接在一起便構(gòu)成了目錄(Directory),它是一個樹狀結(jié)構(gòu)的構(gòu)成,用戶可以通過節(jié)點和分支查找到每個目錄對象。
目錄服務(wù)是對命名服務(wù)的擴展,它能夠依據(jù)目錄對象的屬性而提供目錄對象操作。
JNDI的概念和主要用途
為實現(xiàn)命名和目錄服務(wù),基于java的客戶端需要借助于JNDI系統(tǒng),它為命名和目錄服務(wù)架起了通信的橋梁。JNDI的主要用途有:
開發(fā)者使用JNDI,能夠?qū)崿F(xiàn)目錄和Java對象之間的交互。
使用JNDI,開發(fā)者能獲得對JAVA事務(wù)API中UserTransaction接口的引用。
借助于JNDI,開發(fā)者能連接到各種資源工廠,如JDBC數(shù)據(jù)源,Java消息服務(wù)等。
客戶和EJB組件能夠借助于JNDI查找到其他EJB組件。
名字,綁定和上下文的概念
JNDI中存在多種名字,一種是原子名,如src/com/sitinspring中的src,com和sitinspring;一種是復(fù)合名,它由0個或多個原子名構(gòu)成,如src/com/sitinspring。
綁定就是將名字和對象關(guān)聯(lián)起來的操作。如system.ini綁定到硬盤中的文件, src/com/sitinspring/.classpath分別綁定到三個目錄和一個文件。
上下文(Context)由0個或多個綁定構(gòu)成,每個綁定存在不同的原子名。如WEB-INF文件夾下分別含有.cvsignore和web.xml的文件名。在JNDI中, WEB-INF是上下文,它含有原子名.cvsignore和web.xml的綁定,它們分別綁定到硬盤中的文件。
上下文中也允許存在上下文,它們被成為子上下文(subcontext),子上下文和上下文類似,它也能含有多個名字到對象的綁定。這類似于文件夾下含有子文件夾。
命名系統(tǒng)和初始上下文
命名系統(tǒng)由一套連在一起的上下文構(gòu)成,而且這些上下文使用了相同的命名語法。可以用目錄樹來類比這個概念。
瀏覽命名空間的起點稱之為初始上下文(Initial Context),初始上下文類似于目錄樹中的根節(jié)點概念。
借助于初始上下文,能夠開始命名和目錄服務(wù)。
JNDI查找資源示例
try {
Context initCtx = new InitialContext();
// java:comp/env是命名空間,相當(dāng)于是本機JNDI資源引用根目錄
Context envCtx = (Context) initCtx.lookup("java:comp/env");
Member bean = (Member) envCtx.lookup("Member");
System.out.print("member name=" + bean.getMemberName() + " age="
+ bean.getAge());
} catch (NamingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
JNDI有關(guān)API
list():用于獲得當(dāng)前上下文的綁定列表
lookup():用于解析上下文中名字綁定,該操作將返回綁定到給定名字的對象。
rename():重新命名
createSubContext():從當(dāng)前上下文創(chuàng)建子上下文。
destroySubContext():從當(dāng)前上下文銷毀子上下文。
bind()。從當(dāng)前上下文中創(chuàng)建名字到對象的綁定。
rebind():再次綁定,如果已經(jīng)存在同名綁定則覆蓋之。
本文詳細代碼請見:
http://www.aygfsteel.com/sitinspring/archive/2008/03/14/186372.html
問題:將左邊的SQL語句解析成右邊的形式
Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2,g3 order by g2,g3
select
c1,
c2,
c3
from
t1,
t2,
t3
where
condi1=5 and
condi6=6 or
condi7=7
group by
g1,
g2,
g3
order by
g2,
g3
按關(guān)鍵字找出SQL語句中各部分
我們閱讀SQL語句會把整句分來成列,表,條件,分組字段,排序字段來理解,解析SQL的目的也是這樣.
分解SQL語句有規(guī)律可循,以列為例,它必定包含在select和from之間,我們只要能找到SQL語句中的關(guān)鍵字select和from,就能找到查詢的列.
怎么找到select和from之間的文字呢?其實一個正則表達式就能解決:(select)(.+)(from),其中第二組(.+)代表的文字就是select和from之間的文字.
程序見右邊.
/**
* 從文本text中找到regex首次匹配的字符串,不區(qū)分大小寫
* @param regex: 正則表達式
* @param text:欲查找的字符串
* @return regex首次匹配的字符串,如未匹配返回空
*/
private static String getMatchedString(String regex,String text){
Pattern pattern=Pattern.compile(regex,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(text);
while(matcher.find()){
return matcher.group(2);
}
return null;
}
解析函數(shù)分析
private static String getMatchedString(String regex,String text){
Pattern pattern=Pattern.compile(regex,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(text);
while(matcher.find()){
return matcher.group(2);
}
return null;
}
左邊的這個函數(shù),第一個參數(shù)是擬定的正則表達式,第二個是整個SQL語句.
當(dāng)正則表達式為(select)(.+)(from)時,程序?qū)⒃赟QL中查找第一次匹配的地方(有Pattern.CASE_INSENSITIVE的設(shè)置,查找不區(qū)分大小寫),如果找到了則返回模式中的第二組代表的文字.
如果sql是select a,b from tc,則返回的文字是a,b.
選擇的表對應(yīng)的查找正則表達式
選擇的表比較特殊,它不想選擇的列一樣固定處于select和from之間,當(dāng)沒有查找條件存在時,它處于from和結(jié)束之間;當(dāng)有查找條件存在時,它處于from和where之間.
因此查詢函數(shù)寫為右邊的形式:
/**
* 解析選擇的表
*
*/
private void parseTables(){
String regex="";
if(isContains(sql,"\\s+where\\s+")){
regex="(from)(.+)(where)";
}
else{
regex="(from)(.+)($)";
}
tables=getMatchedString(regex,sql);
}
isContains函數(shù)
isContains函數(shù)用于在lineText中查找word,其中不區(qū)分大小些,只要找到了即返回真.
/**
* 看word是否在lineText中存在,支持正則表達式
* @param lineText
* @param word
* @return
*/
private static boolean isContains(String lineText,String word){
Pattern pattern=Pattern.compile(word,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(lineText);
return matcher.find();
}
解析查找條件的函數(shù)
private void parseConditions(){
String regex="";
if(isContains(sql,"\\s+where\\s+")){
// 包括Where,有條件
if(isContains(sql,"group\\s+by")){
// 條件在where和group by之間
regex="(where)(.+)(group\\s+by)";
}
else if(isContains(sql,"order\\s+by")){
// 條件在where和order by之間
regex="(where)(.+)(order\\s+by)";
}
else{
// 條件在where到字符串末尾
regex="(where)(.+)($)";
}
}
else{
// 不包括where則條件無從談起,返回即可
return;
}
conditions=getMatchedString(regex,sql);
}
解析GroupBy的字段
private void parseGroupCols(){
String regex="";
if(isContains(sql,"group\\s+by")){
// 包括GroupBy,有分組字段
if(isContains(sql,"order\\s+by")){
// group by 后有order by
regex="(group\\s+by)(.+)(order\\s+by)";
}
else{
// group by 后無order by
regex="(group\\s+by)(.+)($)";
}
}
else{
// 不包括GroupBy則分組字段無從談起,返回即可
return;
}
groupCols=getMatchedString(regex,sql);
}
解析OrderBy的字段
private void parseOrderCols(){
String regex="";
if(isContains(sql,"order\\s+by")){
// 包括order by,有分組字段
regex="(order\\s+by)(.+)($)";
}
else{
// 不包括GroupBy則分組字段無從談起,返回即可
return;
}
orderCols=getMatchedString(regex,sql);
}
得到解析后的各部分
按以上解析方法獲得了列,表,條件,分組條件,排序條件各部分之后,它們會存儲到各個成員變量中.
注意這些成員變量的原值都是null,如果在SQL語句中能夠找到對應(yīng)的部分的話它們將借助getMatchedString獲得值,否則還是null.我們通過判斷這些成員變量是否為空就能知道它對應(yīng)的部分是否被解析出來.
/**
* 待解析的SQL語句
*/
private String sql;
/**
* SQL中選擇的列
*/
private String cols;
/**
* SQL中查找的表
*/
private String tables;
/**
* 查找條件
*/
private String conditions;
/**
* Group By的字段
*/
private String groupCols;
/**
* Order by的字段
*/
private String orderCols;
取得不需要單行顯示時的SQL語句
進展到這一步,SQL語句中列,表,條件,分組條件,排序條件各部分都被獲取了出來,這時把它們重新組合一下就能得到整理后的SQL語句.
如下面的SQL語句將變成右邊的部分(先使靜態(tài)成員isSingleLine=false):
Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2,g3 order by g2,g3
select
c1,c2,c3
from
t1,t2,t3
where
condi1=5 and condi6=6 or condi7=7
group by
g1,g2,g3
order by
g2,g3
進一步解析
有時我們需要把列,表,條件,分組條件,排序條件單行顯示以方便查看或加上注釋,這就要求我們對列,表,條件,分組條件,排序條件等進行進一步解析.
初看解析很方便,以固定的分隔符劈分即可,但需要注意的是查詢條件中分隔符有and和or兩種,如果貿(mào)然分隔會使重新組合時使SQL失真.
推薦一種做法,我們可以在分隔符后加上一個標(biāo)志如空行,然后再以這個標(biāo)志來劈分.這樣就不會使SQL失真了.
請見下頁的getSplitedParagraph函數(shù).
getSplitedParagraph函數(shù)
private static List<String> getSplitedParagraph(String paragraph,String splitStr){
List<String> ls=new ArrayList<String>();
// 先在分隔符后加空格
Pattern p = Pattern.compile(splitStr,Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(paragraph);
StringBuffer sb = new StringBuffer();
boolean result = m.find();
while (result) {
m.appendReplacement(sb, m.group(0) + Crlf);
result = m.find();
}
m.appendTail(sb);
// 再按空格斷行
String[] arr=sb.toString().split("[\n]+");
for(String temp:arr){
ls.add(FourSpace+temp+Crlf);
}
return ls;
}
處理結(jié)果
把靜態(tài)成員變量isSingleLine=true后我們來看看執(zhí)行結(jié)果:
select
c1,
c2,
c3
from
t1,
t2,
t3
where
condi1=5 and
condi6=6 or
condi7=7
group by
g1,
g2,
g3
order by
g2,
g3
小結(jié)
從這個例子中我們體會了分治的思想:分治是把一個大問題分解成小問題,然后分別解決小問題,再組合起來大問題的解決方法就差不多了.這種思想在工程領(lǐng)域解決問題時很普遍,我們要學(xué)會使用這種思想來看待,分析和解決問題,不要貪多求大,結(jié)果導(dǎo)致在大問題面前一籌莫展.
其次我們可以從這個例子中學(xué)習(xí)找規(guī)律,然后借助規(guī)律的過程,現(xiàn)實世界千變?nèi)f化,但都有規(guī)律可循,只要我們找到了規(guī)律,就等于找到了事物之門的鑰匙.
接下了我們復(fù)習(xí)了正則表達式用于查找的方法,以前的正則表達式學(xué)習(xí)多用于驗證匹配,其實這只是正則表達式的一部分功能.
最后從解析條件成單行的過程中,我們可以學(xué)習(xí)到一種解決問題的技巧,即當(dāng)現(xiàn)實中的規(guī)律存在變數(shù)時加入人為設(shè)置的規(guī)律,這有時能使我們更好更快的解決問題.
在XHTML中CSS的意義
傳統(tǒng)的HTML能夠并已經(jīng)創(chuàng)建了大量優(yōu)秀美觀使用的網(wǎng)頁,但隨著時代的發(fā)展和客戶要求的逐步提高,傳統(tǒng)HTML網(wǎng)頁將網(wǎng)頁的數(shù)據(jù),表現(xiàn)和行為混雜的方式妨礙了自身可維護性和精確性的提高。
在XHTML中,CSS能把網(wǎng)頁的數(shù)據(jù)和表現(xiàn)(主要是格式和樣式規(guī)則)分隔開來,使人對網(wǎng)頁能有更精確細致的控制,同時可維護性也變得更好,更方便。
在本文中,我們將學(xué)習(xí)CSS的相關(guān)知識。
框模型
在CSS處理網(wǎng)頁時,它認為網(wǎng)頁包含的每一個元素都包含在一個不可見的框中,這個框由內(nèi)容(Content),內(nèi)容外的內(nèi)邊距(padding),內(nèi)邊距的外邊框(border)和外邊框的不可見空間-外邊距(margin)組成。
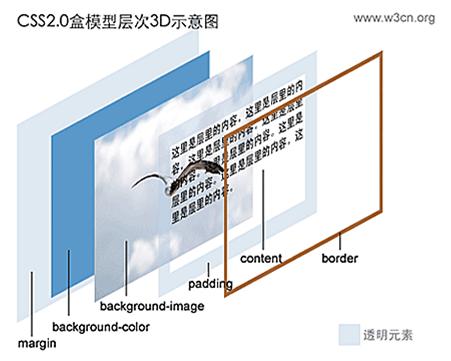
塊級元素和行內(nèi)元素
在XHTML中,元素可能是塊級(block)的,也可能是行級(inline)的。
塊級元素會產(chǎn)生一個新行(段落),而行級元素是行內(nèi)的,不會產(chǎn)生新行(段落)。
常見的塊級元素有div,p等,常見的行級元素有a,span等。
在默認情況下,元素按照在XHTML中從上到下的次序顯示,并且在每個塊級元素的框的開頭和結(jié)尾換行。
注意:塊級元素和行級元素不是絕對的,我們可以通過樣式設(shè)置來改變元素的這個屬性。
元素的基本屬性
內(nèi)邊距:padding
邊框:border
外邊距:margin
大小:width,height
對齊:text-align
顏色:color
背景:background
使元素浮動:float
下面將講述如何對這些元素屬性進行設(shè)置。
改變元素背景
Background有以下子屬性:
background-color:背景顏色,默認值transparent,輸入#rrggbb即可。
background-image:背景圖像,默認值none
background-repeat:背景圖像的重復(fù)顯示,默認值repeat(縱橫重復(fù)),repeat-x(水平重復(fù)),repeat-y(垂直重復(fù)),no-repeat(使圖像不并排顯示)
background-attachment:默認值scroll,表示隨頁面滾動,如果是fixed則不隨頁面滾動。
background-posistion:默認值top left。
這些屬性也可以統(tǒng)一設(shè)置,如:background:#ccc url(theadbg.gif) repeat-x left center;
例:
TABLE.Listing TH {
FONT-WEIGHT: bold;
background:#ccc url(theadbg.gif) repeat-x left center;
BORDER-BOTTOM: #6b86b3 1px solid
}
設(shè)定元素的大小
設(shè)置width和height即可,如:
width:180px;
height:50%;
注意這里可以設(shè)置絕對大小如180px也可以設(shè)置相對大小50%,其中百分?jǐn)?shù)是相對與父元素的比例,父元素即容納本元素的元素。
此外設(shè)置元素大小還可以使用min-width,max-width,max-height,min-height等,但在部分瀏覽器中不支持這些屬性。
例:
#content{
width:640px;
height:500px;
float:right;
background:#f8f8f8;
}
Px和em的區(qū)別
px像素(Pixel)。相對長度單位。像素px是相對于顯示器屏幕分辨率而言的。(引自CSS2.0手冊)
em是相對長度單位。相對于當(dāng)前對象內(nèi)文本的字體尺寸。如當(dāng)前對行內(nèi)文本的字體尺寸未被人為設(shè)置,則相對于瀏覽器的默認字體尺寸。(引自CSS2.0手冊) 任意瀏覽器的默認字體高都是16px。所有未經(jīng)調(diào)整的瀏覽器都符合: 1em=16px。那么12px=0.75em, 10px=0.625em。為了簡化font-size的換算,需要在css中的body選擇器中聲明Font-size=62.5%,這就使em值變?yōu)?16px*62.5%=10px, 這樣12px=1.2em, 10px=1em, 也就是說只需要將你的原來的px數(shù)值除以10,然后換上em作為單位就行了。
設(shè)置元素的外邊距
外邊距是一個元素與下一個元素之間的透明空間量,位于元素的邊框外邊。
設(shè)置外邊距設(shè)置margin的值即可,如margin:1;它將應(yīng)用與四個邊。
如果要為元素的上右下左四個邊設(shè)置不同的外邊距,可以設(shè)置margin-top,margin-right,margin-bottom,margin-left四個屬性。
例:
fieldset{
margin:1em 0;
padding:1em;
border:1px solid #ccc;
background:#f8f8f8;
}
添加元素的內(nèi)邊距
內(nèi)邊距是邊框到內(nèi)容的中間空間。使用它我們可以把內(nèi)容和邊界拉開一些距離。
設(shè)置內(nèi)邊距如右:padding:1px;
如果要為元素的上右下左四個邊設(shè)置不同的內(nèi)邊距,可以設(shè)置padding-top,padding-right,padding-bottom,padding-left四個屬性。
例:
li{
padding-left:10px;
}
控制元素浮動
float屬性可以使元素浮動在文本或其它元素中,這種技術(shù)的最大用途是創(chuàng)建多欄布局(layout)
float可以取兩個值:left,浮動到左邊,right:浮動到右邊
例:
#sidebar{
width:180px;
height:500px;
float:left;
background:#f8f8f8;
padding-top:20px;
padding-bottom:20px;
}
#content{
width:640px;
height:500px;
float:right;
background:#f8f8f8;
}
設(shè)置邊框
邊框位于外邊距和內(nèi)邊距中間,在應(yīng)用中常用來標(biāo)示特定的區(qū)域。它的子屬性有:
border-style:可以設(shè)定邊框的樣式,常見的有solid,dotted,dashed等。
border-width:邊框的寬度。
border-color:邊框顏色
border-top,border-right,border-bottom,border-left可以把邊框限制在一條或幾條邊上。
例:
ul a{
display:block;
padding:2px;
text-align:center;
text-decoration:none;
width:130px;
margin:2px;
color:#8d4f10;
}
ul a:link{
background:#efb57c;
border:2px outset #efb57c;
}
控制元素內(nèi)容的對齊
text-align屬性可以讓我們設(shè)置元素內(nèi)容的對齊,它可以取的值有l(wèi)eft,center,right等。
例:
body{
margin:0 auto;
text-align:center;
min-width:760px;
background:#e6e6e6;
}
#bodyDiv{
width:822px;
margin:0 auto;
text-align:left;
background:#f8f8f8;
border:1px solid #FFFFFf;
}
控制元素在父元素的垂直對齊
設(shè)置vertical-align可以控制元素在父元素的垂直對齊位置,它可以取的值有:
middle:垂直居中
text-top:在父元素中頂對齊
text-bottom:是元素的底線和父元素的底線對齊。
在網(wǎng)頁中引入樣式表
<title>"記賬系統(tǒng)"單項收支記錄瀏覽頁面</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<script src="web/js/ajax.js" type="text/javascript"></script>
<link rel="stylesheet" rev="stylesheet" href="web/css/style.css"
type="text/css" />
</head>
樣式表示例
body{
margin:0 auto;
text-align:center;
min-width:760px;
background:#e6e6e6;
}
#bodyDiv{
width:822px;
margin:0 auto;
text-align:left;
background:#f8f8f8;
border:1px solid #FFFFFf;
}
TABLE.Listing {
MARGIN: 0px 0px 8px;
WIDTH: 92%;
BORDER-BOTTOM: #6b86b3 3px solid
}
#content{
width:640px;
height:500px;
float:right;
background:#f8f8f8;
}
#content h1,#content h2,#content p{
padding-left:20px;
}
#footer{
clear:both;
}
fieldset{
margin:1em 0;
padding:1em;
border:1px solid #ccc;
background:#f8f8f8;
}
如何知道頁面元素對應(yīng)樣式表的那部分?
如果頁面元素設(shè)置了id,則它對應(yīng)的樣式表部分是#id,如#bodyDiv。
如果頁面元素設(shè)定了class,則它在樣式表中尋找”元素類型.class”對應(yīng)的部分,如TABLE.Listing。
如果沒有寫明,則元素會找和自己類型對應(yīng)的樣式設(shè)置,如fieldset。
注意CSS中沒有大小寫的區(qū)別。
例:
<div id="content">
<table id="TbSort" class="Listing" width=100% align=center>
<fieldset><legend>添加賬目</legend>
JavaScript的運行環(huán)境和代碼位置
編寫JavaScript腳本不需要任何特殊的軟件,一個文本編輯器和一個Web瀏覽器就足夠了,JavaScript代碼就是運行在Web瀏覽器中。
用JavaScript編寫的代碼必須嵌在一份html文檔才能得到執(zhí)行,這可以通過兩種方法得到,第一種是將JavaScript代碼直接寫在html文件中,這多用于僅適用于一個頁面的JS程序;另一種是把JavaScript代碼存入一個獨立的文件中(.js作為擴展名),在利用<Script>標(biāo)簽的src屬性指向該文件.
將JavaScript直接嵌入頁面文件中
<%@ page contentType="text/html; charset=UTF-8" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>歡迎進入"我的事務(wù)備忘錄"</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<script src="web/js/strUtil.js" type="text/javascript"></script>
</head>
<body>
<div>這個頁面應(yīng)該很快消失,如果它停止說明Web容器已經(jīng)停止運作了,或JavaScript功能未開啟
<form method=post action="ShowPage?page=login">
</form>
<div>
</body>
</html>
<script LANGUAGE="JavaScript">
<!--
document.body.onload=function(){
document.forms[0].submit();
}
//-->
</script>
將JavaScript存入單獨的文件中(頁面文件)
<%@ page contentType="text/html; charset=UTF-8" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>"我的事務(wù)備忘錄"用戶登錄頁面</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<script src="web/js/ajax.js" type="text/javascript"></script>
<link rel="stylesheet" rev="stylesheet" href="web/css/style.css"
type="text/css" />
</head>
<body>
<div id="branding">歡迎進入"個人事務(wù)備忘錄",請輸入您的用戶名和密碼,再按登錄鍵登錄
<form method=post action="ShowPage?page=loginCheck">
<table bgcolor="#ffffff" id="TbSort" class="Listing" width="200" align=center>
<tbody id="loginTable">
<tr><th align="center" colspan=3>用戶登錄.</th></tr>
<tr>
<td width=50>用戶名:</td>
<td width=150><input type="text" name="userName" value=""
style="width: 300px; height: 20px" /></td>
</tr>
<tr>
<td width=50>密碼:</td>
<td width=150><input type="text" name="userPswd" value=""
style="width: 300px; height: 20px" /></td>
</tr>
<tr>
<td width=50></td>
<td width=150><input type="submit" value="登錄"
style="width: 100px; height: 20px" /></td>
</tr>
</tbody>
</table>
</form>
<div>
</body>
</html>
將JavaScript存入單獨的文件中(ajax.js)
var prjName="/MyTodoes/";
var ajaxObj;
function createAjaxObject(){
try{return new ActiveXObject("Msxml2.XMLHTTP");}catch(e){};
try{return new ActiveXObject("Microsoft.XMLHTTP");}catch(e){};
try{return new XMLHttpRequest();}catch(e){};
alert("XmlHttpRequest not supported!");
return null;
}
function $(id){
return document.getElementById(id);
}
JavaScript中的語句和注釋
JavaScript中的語句和Java中一樣,也是一行書寫一條語句,末尾加上分號’;’,雖然js中也可以把多條語句寫在一行,但推薦不要這樣做.
JavaScript中注釋也和Java中一樣,以// 來注釋單行,/*….*/來注釋多行,雖然HTML風(fēng)格的注釋<!-- ***** --> 在JS中也有效,但建議不要這樣做.
JavaScript中的變量
在js中,變量允許字母,數(shù)字,美元符號和下劃線字符.變量定義使用var關(guān)鍵字,如
var age;
age=23;
var name=“andy”;
雖然js允許程序員可以直接對變量進行賦值而無需提前對它們做出聲明,但我們強烈建議不要這樣做.
Js中變量和其它語法元素都是區(qū)分字母大小寫的,如變量age,Age,AGE沒有任何關(guān)系,它們都不是同一個變量.
JavaScript是一種弱類型語言
和強制要求程序員對數(shù)據(jù)類型做出聲明的強類型(Strongly typed)程序設(shè)計語言如java,C#等不一樣,js不要求程序員進行類型說明,這就是所謂的弱類型”weakly typed”語言.這意味著程序員可以隨意改變某個變量的數(shù)據(jù)類型.
以下寫法在Java中是絕對不允許的,但在js中完全沒有問題:
var age=23;
age=“Twenty three”
Js并不關(guān)心age的值是字符串還是變量.
JavaScript中的數(shù)據(jù)類型-字符串
字符串必須放在單引號或雙引號中.如
var name=“Andy”;
var name=‘Bill’;
一般情況下宜使用雙引號,但如果字符串中有雙引號則應(yīng)該把字符串放在單引號中,反之則應(yīng)該把字符串放在雙引號中.
JavaScript中的數(shù)據(jù)類型-數(shù)值
Js中并沒有int,float,double,long的區(qū)別,它允許程序員使用任意位數(shù)的小數(shù)和整數(shù),實際上js中的數(shù)值應(yīng)該被稱為浮點數(shù).
如:
var salary=10000;
var price=10.1;
var temperature=-6;
JavaScript中的數(shù)據(jù)類型-布爾值
Js中的布爾值和Java中的一致,true表示真,false表示假,如:
var isMale=true;
var isFemale=false;
注意布爾值true和false不要寫成了字符串”true”和’false’.
JS中的函數(shù)
如果需要多次使用同一組語句,可以把這些語句打包成一個函數(shù)。所謂函數(shù)就是一組允許人們在代碼中隨時調(diào)用的語句。從效果上看,每個函數(shù)都相當(dāng)于一個短小的腳本。
和Java中每個函數(shù)都在類中不一樣,JS中函數(shù)不必屬于一個類,在使用上它類似于Java中的靜態(tài)公有函數(shù),只要引入這個函數(shù)所在的文件就可以使用它。
JS中函數(shù)的語法
JS中,一個函數(shù)的大致語法如下:
function fname(args){
statements;
}
Function是函數(shù)的固定標(biāo)志;fname是函數(shù)名;args是函數(shù)參數(shù),它可以有很多個,只要你把它們用逗號分割開來即可;statements是其中的語句,每句結(jié)尾都和java中一樣用“;”表示結(jié)束。
在定義了這個函數(shù)的腳本(頁面)中,你可以從任意位置去調(diào)用這個函數(shù);引入這個頁面后,你還可以從其它頁面訪問它。
一般來說,對于共通性強,適用面廣,會在多個頁面中調(diào)用的函數(shù),我們一般把它們放在一個JS頁面中,然后由需要使用這些函數(shù)的頁面引入它們;而對于只適用于一個頁面的函數(shù),還是把它放在單個頁面中較好。
JS函數(shù)的返回值
在JS中,函數(shù)不僅能夠以參數(shù)的形式接受數(shù)據(jù),運行代碼,它和其它編程語言中的函數(shù)一樣,可以返回數(shù)據(jù)。
讓JS函數(shù)返回數(shù)據(jù),你不需要也不能在函數(shù)簽名上動任何手腳,只需要用return語句返回你想返回的數(shù)字即可,舉例如下:
function substract(op1,op2){
return op1-op2; }
}
JS中變量的作用域
在JS中,我們提倡用var來定義一個變量,凡是變量就會有作用域的問題,根據(jù)定義方式和位置的不同,它既可能是全局的,也有可能是局部的。
用var定義在腳本文件中,不屬于任何一個函數(shù)的變量,它的作用域就是全局性的,它可以在腳本中的任何位置被引用,包括有關(guān)函數(shù)的內(nèi)部。全局變量的作用域是整個腳本。
用var定義在函數(shù)中的變量,它的作用域就是局部性的,它的作用域僅限于這個函數(shù),在函數(shù)的外部是無法使用它的。
不用var定義在函數(shù)中的變量,它的作用域是全局的,如果你的腳本里已經(jīng)存在一個與之同名的變量,這個函數(shù)將覆蓋那個現(xiàn)有變量的值。
定義函數(shù)時,我們必須明確的把它內(nèi)部的變量都明確的聲明為局部變量,如果從來沒有忘記在函數(shù)中使用var關(guān)鍵字,就可以避免任何形式的二義性隱患。
JS中的數(shù)組
在JS中,我們使用Array關(guān)鍵字聲明數(shù)組,在聲明時對數(shù)組長度進行限定,如:
var arr=Array(3);
有時運行起來才知道數(shù)組長度,JS中我們也可以這樣定義數(shù)組:
var arr=Array();
向數(shù)組中添加元素時你需要給出新元素的值,還需要在數(shù)組中為新元素制定存放位置,這個位置由下標(biāo)給出,如arr[1]=4。
在JS中定義數(shù)組的例子
定義方式一:
var arr=Array(3);
arr[0]=“劉備”; arr[1]=“關(guān)于”; arr[2]=“張飛”;
定義方式二:
var arr=Array();
arr[0]=3; arr[1]=4;arr[2]=5;
定義方式三:
Var arr=Array(“1”,2,true);
定義方式四:
var arr=[“征東”,”平西”,”鎮(zhèn)南”,”掃北”];