|
|
2011年11月3日
1.和業務部門 、客戶溝通(溝通是整個需求設計到開發使用為止);
2.學習業務;
3.有意識聽速求(客戶最急需的),也就是優先級問題;
4.搜集需求,整合,提煉,完成分析;(考慮周全找關聯 找核心)
5.編寫需求產品文檔(文字和圖列、流程圖等相結合)
6.掌握相關工具;(比如visio/axure)
7.文檔系統講解(講解對象:開發和測試)
8.驗證開發完后的產品(驗證結束后再測試);
9.用戶培訓(需求工程師主持);
10.了解相關系統(了解整個業務面 而不是 內部的功能點);
注意:數據表設計中盡量存可分析的信息代碼;
- struts1和struts2的區別
- hibernate和ibatis的區別
- json和xml的區別
- ajax的原理
- ajax和iframe嵌套有什么區別
- gbk utf8 iso-8859-1都是多少字節
- extjs和jquery的區別
- js從前端如何解決跨域問題
- 單例模式的優點,工廠模式的原理
- spring的mvc模式
- jdk1.7新功能
- 為什么會出現亂碼
http://www.iteye.com/problems/74892List<Integer> ids = new ArrayList<Integer>(); ids.add(3); ids.add(4); ids.add(5); Query query=session.createQuery(from document where id in (:ids)); query.setParameterList("ids", ids); query.list();
public FDataReport addFDataReport(FDataReport datareport);//數據新錄入返回對象,對應的就會把ID也返回
Cookie cookies[]=request.getCookies();
Cookie stCookie=null;
String password=null;
String passwordvalue=null;
String usernamevalue=null;
String cookiename = null;
String nameandpassword[]=new String[3];
if (cookies != null) {
for (int i = 0; i < cookies.length; i++) {
stCookie = cookies[i];
cookiename = stCookie.getName();
if (cookiename!=null && cookiename.equalsIgnoreCase("db_password")) {
passwordvalue = stCookie.getValue();
password = passwordvalue;//.substring(8, passwordvalue.length()-3);
nameandpassword[1] = password.trim();
}
if (cookiename!=null && cookiename.equalsIgnoreCase("db_username")) {
usernamevalue = stCookie.getValue();
nameandpassword[0] = usernamevalue.trim();
}
}
}
<body>
<p>
<label for="LoginName">
用戶名 / 郵箱:
</label>
<input class="text" type="text" id="LoginName" name="LoginName"
value="<%=nameandpassword[0]==null?"":nameandpassword[0] %>" />
</p>
<p>
<label for="Password">
密碼:
</label>
<input class="text" type="password" value="<%=nameandpassword[1]==null?"":nameandpassword[1] %>" name="Password" id="Password" />
</p>
</body>
昨天做用戶注冊,添加用戶時候總是提交兩次
最后才找到原因 提交表單的按鈕就是設置成button的了 但是名稱是submitButton也不可以 所以修改下按鈕名稱就可以了!!!
⊙﹏⊙b汗
1.當用戶操作用戶中心的信息,編碼獲取用戶對象應該是通過該用戶登錄保存的session或者cookie獲得,
而不是通過用戶ID獲得(否則當有人知道通過ID傳值,容易輕易修改掉其他用戶的信息)
2.前臺下載也需要通過后臺處理 放置業內人士知道下載文件真實地址,獲得大量數據信息
《轉自 http://blog.sina.com.cn/s/blog_5f66526e0100kf6b.html》
主要步驟:
第一步:導入需要的js文件(根據實際情況修改相應路徑)
<script src="js/jquery.js" type=text/javascript></script>
<script src="fckeditor/fckeditor.js" type="text/javascript"></script>
第二步:初始化(根據實際情況修改相應路徑)
sBasePath = '/duotunkf/fckeditor/' ;#編輯器所在文件夾;
oFCKeditor = new FCKeditor('content') ;
oFCKeditor.BasePath = sBasePath ;
oFCKeditor.Value = 'test' ;
oFCKeditor.ToolbarSet = 'Basic' ;
oFCKeditor.Create() ;
其中content為頁面你所綁定的textArea的id或name
第三步:取值
var oEditor = FCKeditorAPI.GetInstance('content');
editorValue = oEditor.GetHTML();
第四步:賦值(更新的時候先把原有的值賦給textarea)
var oEditor = FCKeditorAPI.GetInstance('content');
oEditor.SetHTML("value");
下面是本人寫的一個賦值測試程序,供大家參考。源碼如下:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="js/jquery-1.3.2.min.js"></script>
<script src="fckeditor/fckeditor.js"></script>
<script>
$(document).ready(function(){
$("#test").click(function(){
var oEditor = FCKeditorAPI.GetInstance('content');
oEditor.SetHTML($("#test option:selected" ).text());
});
});
</script>
</head>
<body>
<form action="" method="post">
<script>
sBasePath = '/duotunkf/fckeditor/' ;#編輯器所在文件夾;
oFCKeditor = new FCKeditor('content') ;
oFCKeditor.BasePath = sBasePath ;
oFCKeditor.Value = 'test' ;
oFCKeditor.ToolbarSet = 'Basic' ;
oFCKeditor.Create() ;
</script>
<br>
<label for="test">
<select name="test" size="4" id="test">
<option value="1">i.點擊這里改變編輯器的值</option>
<option value="2">ii.點擊這里改變編輯器的值</option>
<option value="3">iii.點擊這里改變編輯器的值</option>
</select>
</label>
</form>
</body>
</html>
提交了,剛才修正了一些問題;一主鍵需要設置number類型同時告訴擴充到10
管華(管華) 10:44:15
你剛才是int類型,,int最大是到6萬多吧,,如果你設置這個,意味著到時你到6萬多的會員后,系統出問題,插入不進去了,到時你還得改;
管華(管華) 10:45:46
第二,你用的是字符VARCHAR2類型,這個;類型在oracle里不太好,會持久化占用一部分空間,比如你設置的VARCHAR2(1000),他不管你里面有沒有數據,都會占用這1000個字符的空間;因此需要改為NVARCHAR2 ,他是自適應,當你沒存儲值,他不占據空間
另外根據有些字段,比如人名 name NVARCHAR2(20)分配20個字符就可了,分配500個,會浪費多余的空間同時使得系統慢碎片多;因此根據實際情況,酌情分配
update tc_report t set xlsfile='ChinaLivestock'||chr(38)||'FeedWeeklyMarketReport20130703.doc' where t.xlsfile like 'China Livestock & Feed Weekly Market Report 20130703%'
將tomcat下的bin\startup.bat下的文件打開后,最下面有一句話 call "%EXECUTABLE%" jpda start %CMD_LINE_ARGS%,,復制我這個替換你那個,保存后,即可實現不重啟就編譯java
例子:
function getDate(day){
var zdate=new Date();
var sdate=zdate.getTime()-(1*24*60*60*1000);
var edate=new Date(sdate-(day*24*60*60*1000)).format("yyyy-MM-dd");
return edate;
}
function changevalue(obj){
alert(obj);
var a = getDate(+7);
var b = getDate(+31);
if(obj=="8"){
document.getElementById("enddate").value=b;
}else{
document.getElementById("enddate").value=a;
}
}
java.lang.UnsatisfiedLinkError: no jcom in java.library.path
將 jcom.dll 文件放在 C:\WINDOWS\system32 和jdk的bin 目錄下
設置問題  Debug model選中
1.下載模塊:年鑒、研究報告、企業榜單和行業數據(需要權限控制)
2.FTP使用:
1.針對不同類型跳轉不同的action方法 除了使用JS以外 還可以 使用參數獲得參數例如method=....不同值來跳轉像不同的方法
例子:分國別 (method="showCountryList") 分地區(method="showAreaList")
后臺 String method = request.getParameter("method");
request.setAttribute("method", method);
if (method != null && method.equals("showCountryList")) {
return showCountryList(map, form, request, response);//分國別
} else if (method != null && method.equals("showAreaList")) {
return showAreaList(map, form, request, response);//分地區
}
2.Jsp........記得使用IFram嵌套
<iframe width="100%" height="800" class="share_self" frameborder="0" scrolling="no" src="/tyreportAction.do?method=lookReportInfo&bid=${record.bid } "></iframe>
總結:思維要活躍些 往往一個問題有很多種解決方法的
存值 Clob organdetail =Hibernate.createClob(request.getParameter("organdetail").equals("")?"":request.getParameter("organdetail").trim());// 機構簡介 取值 顯示JSP <%=ToolsCommon.Clob2String(institutions.getOrgandetail())==null?"":ToolsCommon.Clob2String(institutions.getOrgandetail())%>
public static String Clob2String(java.sql.Clob clob) {
String s1 = "";
char ac[] = new char[200];
if (clob == null)
return null;
java.io.Reader reader = null;
int i;
try {
reader = clob.getCharacterStream();
while ((i = reader.read(ac, 0, 200)) != -1)
s1 = s1 + new String(ac, 0, i);
} catch (Exception exception1) {
// throw new java.sql.SQLException(exception1.getMessage());
System.out.println(exception1.toString());
}
finally {
try {
reader.close();
} catch (Exception _ex) {
}
}
return s1;
}
《此文拷貝自 http://kxjhlele.iteye.com/blog/323657》
1,驗證傳入路徑是否為正確的路徑名(Windows系統,其他系統未使用) // 驗證字符串是否為正確路徑名的正則表達式 private static String matches = "[A-Za-z]:\\\\[^:?\"><*]*"; // 通過 sPath.matches(matches) 方法的返回值判斷是否正確 // sPath 為路徑字符串
2,通用的文件夾或文件刪除方法,直接調用此方法,即可實現刪除文件夾或文件,包括文件夾下的所有文件 /** * 根據路徑刪除指定的目錄或文件,無論存在與否 *@param sPath 要刪除的目錄或文件 *@return 刪除成功返回 true,否則返回 false。 */ public boolean DeleteFolder(String sPath) { flag = false; file = new File(sPath); // 判斷目錄或文件是否存在 if (!file.exists()) { // 不存在返回 false return flag; } else { // 判斷是否為文件 if (file.isFile()) { // 為文件時調用刪除文件方法 return deleteFile(sPath); } else { // 為目錄時調用刪除目錄方法 return deleteDirectory(sPath); } } }
3,實現刪除文件的方法, /** * 刪除單個文件 * @param sPath 被刪除文件的文件名 * @return 單個文件刪除成功返回true,否則返回false */ public boolean deleteFile(String sPath) { flag = false; file = new File(sPath); // 路徑為文件且不為空則進行刪除 if (file.isFile() && file.exists()) { file.delete(); flag = true; } return flag; }
4,實現刪除文件夾的方法, /** * 刪除目錄(文件夾)以及目錄下的文件 * @param sPath 被刪除目錄的文件路徑 * @return 目錄刪除成功返回true,否則返回false */ public boolean deleteDirectory(String sPath) { //如果sPath不以文件分隔符結尾,自動添加文件分隔符 if (!sPath.endsWith(File.separator)) { sPath = sPath + File.separator; } File dirFile = new File(sPath); //如果dir對應的文件不存在,或者不是一個目錄,則退出 if (!dirFile.exists() || !dirFile.isDirectory()) { return false; } flag = true; //刪除文件夾下的所有文件(包括子目錄) File[] files = dirFile.listFiles(); for (int i = 0; i < files.length; i++) { //刪除子文件 if (files[i].isFile()) { flag = deleteFile(files[i].getAbsolutePath()); if (!flag) break; } //刪除子目錄 else { flag = deleteDirectory(files[i].getAbsolutePath()); if (!flag) break; } } if (!flag) return false; //刪除當前目錄 if (dirFile.delete()) { return true; } else { return false; } }
5,main() 方法
public static void main(String[] args) {
HandleFileClass hfc = new HandleFileClass();
String path = "D:\\Abc\\123\\Ab1";
boolean result = hfc.CreateFolder(path);
System.out.println(result);
path = "D:\\Abc\\124";
result = hfc.DeleteFolder(path);
System.out.println(result);
}
main() 方法只是做了一個簡單的測試,建立文件夾和文件都是本地建立,情況考慮的應該很全面了,包括文件夾包含文件夾、文件。文件的不同情況…………
實現沒有問題,可以正確刪除文件夾和文件。
對于其他類型文件的操作繼續學習…………
1.原字段類型是字符串 使用“||”連接 update table1 set num = substr(num,0,instr(num,'-'))||(substr(num,instr(num,'-')+1) +9) 2.原字段是數字 使用+連接 UPDATE table1SET num = num+10 3.截取 update tc_report t set xlsfile=substr(xlsfile,6) where xlsfile like '%uku\%'
1.放到HashMap中
String varsort=exp.getVarsort();
String vars[]=null;
HashSet setvar = new HashSet();
if(varsort!=null&&!varsort.trim().equals("")){
vars=varsort.substring(0,varsort.length()-1).split(",");
for(int i=0;i<vars.length;i++){
setvar.add(vars[i].trim());
}
}
2. contains比較是否包含
<% if(varsorts!=null&&varsorts.size()>0){
for(int j=0;j<varsorts.size();j++){
TDictionarys td=varsorts.get(j);
%>
<input type="checkbox" value="<%=td.getDataid() %>" <%if(setvar.contains(String.valueOf(td.getDataid()).trim())){out.print("checked");} %> onclick="getBreeds()" name="varsort" id="varsort" />
<label for="checkbox" class="font12">
<%=td.getName() %>
</label>
<%
}
}
%>
前提 列表走了數據庫查詢
1.引入架包 <%@ taglib uri="oscache" prefix="cache"%>
2.包含要緩存的部分
<cache:cache key="dbnewscache" time="3600">
<%List<Article> list=new CmsByMysql().getNews(); %>
<c:forEach var="cu" items="<%=list%>">
<li>
<a href="${cu.url}">${cu.titleContent} </a>
</li>
</c:forEach>
</cache:cache>
<iframe marginwidth="0" framespacing="0" marginheight="0" frameborder="0"
name="uploadframe" id="uploadframe" src="c.html" scrolling="no" width="100" height="100" ></iframe>
如想在c.html 中寫一些代碼去改變parent.html 中的一些內容,以下代碼可作為參考:
1、parent.window.frames 可返回parent.html 中所有的iframe;返回結果應該是一個數組,用parent.window.frames[iframeId]可得到iframeId;
2、用parent.document.getElementById('xxxx')可得到父里的xxxx,并改變相應的值,例如:parent.document.getElementById('xxxx').className = 'test';
3、如果我想在父中再創建一個元素,直接用parent.appendChild(yyyy)在firefox中是可以的,但在IE(最起碼IE6)是不行的; 所以,要把創建這個動作放在父中來完成,在子中調用;
parent.document.getElementById("pinming").innerHTML = retText2;
2011-07-13 10:07
jQuery 目錄樹插件介紹——ligerTree
一,簡介
ligerTree的功能列表:
1,支持本地數據和服務器數據(配置data或者url)
2,支持原生html生成Tree
3,支持動態獲取增加/修改/刪除節點
4,支持大部分常見的事件
5,支持獲取選中行等常見的接口方法
二,第一個例子
引入庫文件
遵循LigerUI系列插件的設計原則(插件盡量單獨),ligerTree是一個單獨的插件,也就是說只需要引入plugins/ligerTree.js和樣式css文件就可以使用(當然必須先引入jQuery),在這個例子中,我把tree用到的樣式和圖片分離了出來,有興趣的朋友可以下載來看看
<script src="lib/jquery/jquery-1.3.2.min.js" type="text/javascript"></script> <link href="lib/ligerUI/skins/Aqua/css/ligerui-tree.css" rel="stylesheet" type="text/css"/> <script src="lib/ligerUI/js/plugins/ligerTree.js" type="text/javascript"></script>
加入HTML
<ul id="tree1"> <li> <span>節點1</span> <ul> <li> <span>節點1.1</span> <ul> <li><span>節點1.1.1</span></li> <li><span>節點1.1.2</span></li> </ul> </li> <li><span>節點1.2</span></li> </ul> </li> </ul>
調用ligerTree <table style="margin-top: 0px !important; margin-right: 0px !important; margin-bottom: 0px !important; margin-left: 0px !important; padding-top: 0px !important; padding-right: 0px !important; padding-bottom: 0px !important; padding-left: 0px !important; border-top-width: 0px !important; border-right-width: 0px !important; border-bottom-width: 0px !important; border-left-width: 0px !important; border-style: initial !important; border-color: initial !important; outline-width: 0px !important; outline-style: initial !important; outline-color: initial !important; background-image: none !important; background-attachment: initial !important; background-origin: initial !important; background-clip: initial !important; background-color: initial !important; text-align: left !important; float: none !important; vertical-align: baseline !important; position: static !important; left: auto !important; top: auto !important; right: auto !important; bottom: auto !important; height: auto !important; width: auto !important; font-family: Consolas, 'Bitstream Vera Sans Mono', 'Courier New', Courier, monospace !important; font-weight: normal !important; font-style: normal !important; font-size: 1em !important; min-height: inherit !important; border-collapse: collapse !important; background-position: initial initial !important; background-repeat: initial initial !important; "><td style="font-size: 1em !important; margin-top: 0px !important; margin-right: 0px !important; margin-bottom: 0px !important; margin-left: 0px !important; padding-top: 0px !important; padding-right: 0px !important; padding-bottom: 0px !important; padding-left: 0.5em !important; border-top-width: 0px !important; border-right-width: 0px !important; border-bottom-width: 0px !important; border-left-width: initial !important; border-style: initial !important; border-color: initial !important; outline-width: 0px !important; outline-style: initial !important; outline-color: initial !important; background-image: none !important; background-attachment: initial !important; background-origin: initial !important; background-clip: initial !important; background-color: initial !important; text-align: left !important; float: none !important; vertical-align: top !important; position: static !important; left: auto !important; top: auto !important; right: auto !important; bottom: auto !important; height: auto !important; width: auto !important; font-family: Consolas, 'Bitstream Vera Sans Mono', 'Courier New', Courier, monospace !important; font-weight: normal !important; font-style: normal !important; min-height: inherit !important; border-left-style: none !important; border-left-color: initial !important; color: rgb(0, 0, 0) !important; background-position: initial initial !important; background-repeat: initial initial !important; ">$("#tree1").ligerTree();
效果圖

三,常用場景
場景一:不使用復選框: $("#tree2").ligerTree({ checkbox: false });
場景二:不使用復習框和圖標: $("#tree3").ligerTree({ checkbox: false, parentIcon: null, childIcon: null });
效果如圖:
?
append(parentNode, newdata)增加節點集合clear()清空collapseAll()全部節點都折疊demotion(treenode)降級為葉節點級別expandAll()全部節點都展開getChecked()獲取選擇的行(復選框)getData()獲取樹的數據源getParentTreeItem(treenode, level)獲取父節點getSelected()獲取選擇的行hasChildren(treenode)是否包含子節點 loadData(node, url, param)加載數據remove(node)刪除節點upgrade(treenode)升級為父節點級別
StringBuffer content = new StringBuffer();
// FileInputStream fis = null;
// byte[] b = new byte[2048];
// try {
// if(lang!=null&&lang.trim().equals("10")){
// fis = new FileInputStream(passwordTemplatePath);
// }else if(lang!=null&&lang.trim().equals("20")){
// fis = new FileInputStream(passwordTemplateEnPath);
// }else if(lang!=null&&lang.trim().equals("30")){
// fis = new FileInputStream(passwordTemplateChinaEnPath);
// }
// int m = 0;
// while ((m = fis.read(b)) != -1) {
// content.append(new String(b, 0, m));
// }
//passwordTemplatePath 文本 文件地址
BufferedReader br = null;
try {
if(lang!=null&&lang.trim().equals("10")){
br = new BufferedReader(new InputStreamReader(new FileInputStream(passwordTemplatePath), "utf-8"));
}else if(lang!=null&&lang.trim().equals("20")){
br = new BufferedReader(new InputStreamReader(new FileInputStream(passwordTemplateEnPath), "utf-8"));
}else if(lang!=null&&lang.trim().equals("30")){
br = new BufferedReader(new InputStreamReader(new FileInputStream(passwordTemplateChinaEnPath), "utf-8"));
}
String s = null;
while ((s = br.readLine()) != null) {
content.append(s);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
class MyThread implements Runnable {
@Override
public void run() {
System.out.println("1、進入run()方法休眠");
try {
System.out.println("2、線程休眠20秒");
Thread.sleep(20000);//這里休眠20秒
System.out.println("3、線程正常休眠完畢");
} catch (InterruptedException e) {
System.out.println("4、線程發生異常休眠被中斷");
return;//返回方法調用處
}
System.out.println("5、線程正常結束run()方法體");
}
}
public class InterruptDemo {
public static void main(String[] args) {
MyThread mt = new MyThread();
Thread t = new Thread(mt,"線程A");
t.start();//啟動線程
//========================================================
try {
Thread.sleep(2000); //保證線程至少執行2秒
} catch (InterruptedException e) {
e.printStackTrace();
}
//========================================================
t.interrupt();//中斷線程
}
}
public static void main(String[] args)
{
try {
java.util.Date date;
// 首先設置"Mon Dec 28 00:00:00 CST 2008"的格式,用來將其轉化為Date對象
DateFormat df = new SimpleDateFormat("EEE MMM dd HH:mm:ss zzz yyyy", Locale.US);
//將已有的時間字符串轉化為Date對象
date = df.parse("Tue Jun 19 00:00:00 CST 2012");// 那天是周一
// 創建所需的格式
df = new SimpleDateFormat("yyyy-MM-dd");
String str = df.format(date);// 獲得格式化后的日期字符串
System.err.println(str);// 打印最終結果
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
http://www.infoq.com/ - Info IT新聞 http://www.apache.org/ - Apache基金會 http://www.springsource.org/ - 廣大Java開發者喜愛的Spring http://www.hibernate.org/ - 開源ORM框架 http://sourceforge.net/ - 開源技術的集結地 http://www.javaalmanac.com – Java開發者年鑒一書的在線版本. 要想快速查到某種Java技巧的用法及示例代碼, 這是一個不錯的去處. http://www.onjava.com – O’Reilly的Java網站. 每周都有新文章. http://java.sun.com – 官方的Java開發者網站 – 每周都有新文章發表. http://www.developer.com/java – 由Gamelan.com 維護的Java技術文章網站. http://www.java.net – Sun公司維護的一個Java社區網站. http://www.builder.com – Cnet的Builder.com網站 – 所有的技術文章, 以Java為主. http://www.ibm.com/developerworks/java – IBM的Developerworks技術網站; 這是其中的Java技術主頁. http://www.javaworld.com – 最早的一個Java站點. 每周更新Java技術文章. http://www.devx.com/java – DevX維護的一個Java技術文章網站. http://www.fawcette.com/javapro – JavaPro在線雜志網站. http://www.sys-con.com/java – Java Developers Journal的在線雜志網站. http://www.javadesktop.org – 位于Java.net的一個Java桌面技術社區網站. http://www.theserverside.com – 這是一個討論所有Java服務器端技術的網站. http://www.jars.com – 提供Java評論服務. 包括各種framework和應用程序. http://www.jguru.com – 一個非常棒的采用Q&A形式的Java技術資源社區. http://www.javaranch.com – 一個論壇,得到Java問題答案的地方,初學者的好去處。 http://www.ibiblio.org/javafaq/javafaq.html – comp.lang.java的FAQ站點 – 收集了來自comp.lang.java新聞組的問題和答案的分類目錄. http://java.sun.com/docs/books/tutorial/ – 來自SUN公司的官方Java指南 – 對于了解幾乎所有的java技術特性非常有幫助. http://www.javablogs.com – 互聯網上最活躍的一個Java Blog網站. http://java.about.com/ – 來自About.com的Java新聞和技術文章網站.
JSP頁面頁頭添加 <%@ taglib uri="/WEB-INF/taglib/c.tld" prefix="c"%> <%@ taglib prefix="fn" uri=" 頁面內容如下: <c:if test="${fn:contains(record.name,'樣例')==false}"> <% if ((f != null && f.trim().equals("0"))&&name!=null&&!name.trim().equals("免費報告")) { %><a href="javascript:void(0);alert('很抱歉,您無權訪問!如需訪問請購買產品或聯系管理員...');"> ${record.name} </a> <% } else { %> <a href="/tcreportAction.do?method=lookReportInfo&bid=${record.bid } ">${record.name}</a> <% } %> </c:if> <c:if test="${fn:contains(record.name,'樣例')}"> <a href="/tcreportAction.do?method=lookReportInfo&bid=${record.bid } ">${record.name}</a> </c:if>
${wjcd.lrsj}原來得到的是如2006-11-12 11:22:22.0
${fn:substring(wjcd.lrsj, 0, 16)}
使用functions函數來獲取list的長度
${fn:length(list)}
- fn:contains(string, substring)
- 假如參數string中包含參數substring,返回true
-
- fn:containsIgnoreCase(string, substring)
- 假如參數string中包含參數substring(忽略大小寫),返回true
-
- fn:endsWith(string, suffix)
- 假如參數 string 以參數suffix結尾,返回true
-
- fn:escapeXml(string)
- 將有非凡意義的XML (和HTML)轉換為對應的XML character entity code,并返回
-
- fn:indexOf(string, substring)
- 返回參數substring在參數string中第一次出現的位置
-
- fn:join(array, separator)
- 將一個給定的數組array用給定的間隔符separator串在一起,組成一個新的字符串并返回。
-
- fn:length(item)
- 返回參數item中包含元素的數量。參數Item類型是數組、collection或者String。假如是String類型,返回值是String中的字符數。
-
- fn:replace(string, before, after)
- 返回一個String對象。用參數after字符串替換參數string中所有出現參數before字符串的地方,并返回替換后的結果
-
- fn:split(string, separator)
- 返回一個數組,以參數separator 為分割符分割參數string,分割后的每一部分就是數組的一個元素
-
- fn:startsWith(string, prefix)
- 假如參數string以參數prefix開頭,返回true
-
- fn:substring(string, begin, end)
- 返回參數string部分字符串, 從參數begin開始到參數end位置,包括end位置的字符
-
- fn:substringAfter(string, substring)
- 返回參數substring在參數string中后面的那一部分字符串
-
- fn:substringBefore(string, substring)
- 返回參數substring在參數string中前面的那一部分字符串
-
- fn:toLowerCase(string)
- 將參數string所有的字符變為小寫,并將其返回
-
- fn:toUpperCase(string)
- 將參數string所有的字符變為大寫,并將其返回
-
- fn:trim(string)
- 去除參數string 首尾的空格,并將其返回
截取字符串!使用!
<c:if test="${fn:length(onebeans.info)>100 }">${ fn:substring( onebeans.info ,0,100)} ...</c:if>
<c:if test="${fn:length(onebeans.info)<=100 }">${ onebeans.info }</c:if>
終止執行submit
<form name="myf" action="/.....">
<input name="pmcode" id="pmcode" value="<%=pmcode%>"
type="text" class="shuihao" onkeydown="if(event.keyCode==13){event.keyCode = 9 ;searchCodes();return false;}" size="20" maxlength="20" />
</form>
當回車的時候 將鍵盤碼變成別的 例如 If( event.keyCode == 13) event.keyCode = 9 之類。
msg+="<li id=\""+codes[i].value+"\" name=\""+codes[i].value+"\" ><INPUT class=\"ac\" onclick=\"javascript:nextSetcode('"+codes[i].value+"');oper('"+codes[i].value+"');\" type=\"button\" name=\"codes\" value=\""+codes[i].value+"\" /></li>";
動態參數據 JS方法加 單引號 方法如上
<%@ page language="java" import="java.util.*" pageEncoding="GBK"%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<SCRIPT type="text/javascript">
function numberCells()
{
var count=0;
for (i=0; i < document.all.Tab.rows.length; i++)
{
for (j=0; j < document.all.Tab.rows(i).cells.length; j++)
{
document.all.Tab.rows(i).cells(j).innerText = count;
count++;
}
}
}
function tb_addnew()
{
var ls_t=document.all("Tab")
maxcell=ls_t.rows(0).cells.length;
mynewrow = ls_t.insertRow();
for(i=0;i <maxcell;i++)
{
mynewcell=mynewrow.insertCell();
mynewcell.innerText="a"+i;
}
}
function tb_delete()
{
var ls_t=document.all("Tab");
ls_t.deleteRow() ;
}
</SCRIPT>
<html>
<head>
<script type="text/javascript">
function addRow(TabId){
//獲取要插入行的表格
var table = document.getElementByIdx_x(TabId);
//在最后一行插入一行
var newRow = table.insertRow(table.rows.length);
//在該行插入單元格
var newCel1 = newRow.insertCell(0);
var newCel2 = newRow.insertCell(1);
var newCel3 = newRow.insertCell(2);
newCel1.innerHTML = "第一列";
newCel2.innerHTML = "第二列";
newCel3.innerHTML = "第三列";
}
</script>
</head>
<body>
<center>
<table id="Tab" border="1" cellspacing="0" cellpadding="0">
<tr>
<td>
第一列
</td>
<td>
第二列
</td>
<td>
第三列
</td>
</table>
<br>
<input type="button" onclick="addRow('Tab');" value="插入行"/>
<input type="button" onclick="tb_delete();" value="刪除行"/>
<input type="button" onclick="tb_addnew();" value="添加行"/>
<input type="button" onclick="numberCells();" value="顯示單元個數"/>
</center>
</body>
</html>
設置單元格的顯示格式 : 單擊單元格右鍵——樣式——自定義 就OK了 輸出保存各種文件格式:導航欄,文件——輸出 http://www.finereport.com/knowledge/faq
parent.function() 就可以通過B.jsp去調用A。jsp的函數
在B.jsp中通過javascript代碼中可以通過parent對象來訪問A.jsp中的內容。在A.jsp中寫的代碼差不多,只要加上"parent."前綴就可以訪問了。
步驟: 1.windows--》preferences —— 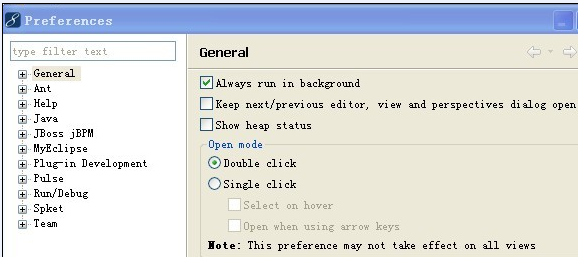 2.General——Editors ——— 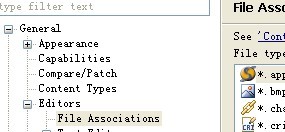 3.File Association 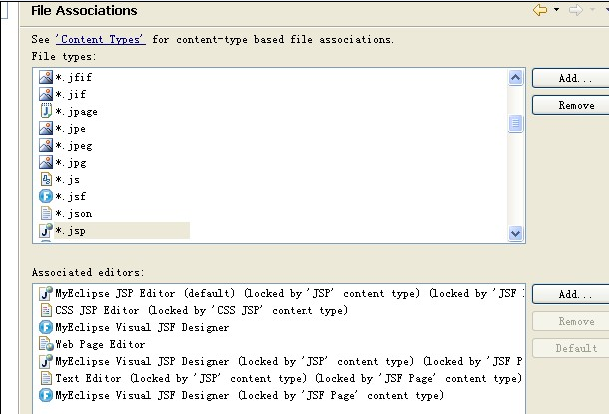 s  將改圖的值設為默認的
--分詞收索
創建
String name = rs.getString("name");
if (name != null && !name.equals(""))
document.add(new Field("name", name, Field.Store.YES,
Field.Index.UN_TOKENIZED));
檢索
query = new TermQuery(new Term("name", name));
booleanQuery.add(query, BooleanClause.Occur.MUST);
SimpleDateFormat bartDateFormat = new SimpleDateFormat("yyyy-MM-dd");
java.sql.Date btime=null;;
if(cdata.getBegintime()!=null){
java.util.Date date = bartDateFormat.parse(cdata.getBegintime().toString());
btime= new java.sql.Date(date.getTime());
}else{
java.util.Date date = bartDateFormat.parse("1970-01-01");
btime= new java.sql.Date(date.getTime());
}
insert into v9_dataen_data (content, `from`, gengxin, danwei, btime, etime)values( '碳酸飲料 價格', 'BOABC','3', 'Yuan',1262275200, 1320076800)
注意from的設置 `` 符號
2010-03-24 22:05 859人閱讀 評論(0) 收藏 舉報
1. 排序
1.1. Sort類
public Sort()
public Sort(String field)
public Sort(String field,Boolean reverse) //默認為false,降序排序
public Sort(String[] fields)
public Sort(SortField field)
public Sort(SortField[] fields)
Sort sort=new Sort(“bookname”);按照“bookname“這個Field值進行降序排序
Sort sort=new Sort(“bookname”,true) //升序排序
Sort sort=new Sort(new String[]{“bookNumber”,”bookname”,”publishdate”});按照三個Field進行排序,但無法指定升序排序,所以用SortField
1.2. SortField類
public SortField(String field)
public SortField(String field,Boolean reverse)
public SortField(String field,int type) //type表示當前Field值的類型
public SortField(String field,int type,boolean reverse) //默認為false,升序
Field值的類型:SortField.STRING、SortField.INT、SortField.FLOAT
SortField sf1=new SortField(“bookNumber”,SortField.INT,false);
SortField sf2=new SortField(“bookname”,SortField.STRING,false);
1.3. 指定排序的法則
1.3.1.按照文檔的得分降序排序
Hits hits=searcher.search(query,Sort.RELEVANCE);
1.3.2.按文檔的內部ID升序排序
Hits hits=searcher.search(query, Sort.INDEXORDER);
1.3.3.按照一個Field來排序
Sort sort=new Sort();
SortField sf=new SortField(“bookNumber”,SortField.INT,false);
sort.setSort(sf);
Hits hits=searcher.search(query,sort);
1.3.4.按照多個Field來排序
Sort sort=new Sort();
SortField sf1=new SortField(“bookNumber”,SortField.INT,false);//升序
SortField sf2=new SortField(“publishdate”,SortField.STRING,true);//降序
sort.setSort(new SortField[]{sf1,sf2});
Hits hits=searcher.search(query,sort);
1.3.5.改變SortField中的Locale信息
String str1=”我”; String str2=”你”;
Collator co1=Collator.getInstance(Locale.CHINA);
Collator co2=Collator.getInstance(Locale.JAPAN);
System.out.println(Locale.CHINA+”:”+co1.compare(str1,str2));
System.out.println(Locale.JAPAN+”:”+co2.compare(str1,str2));
輸出結果為:
zh_CN:1
ja_JP:-1
所以
public SortField(String field,Locale locale)
public SortField(String field,Locale locale,boolean reverse)
2. 過濾器
使用public Hits search(Query query,Filter filter)
(1)簡單過濾
Hits hits=searcher.search(query,new AdvancedSecurityFilter());//過濾掉securitylevel為0的結果
(2)范圍過濾—RangeFilter
只顯示中間的
RangeFilter filter=new RangeFilter(“publishdate”,”1970-01-01”,”1998-12-31”,true,true”);
Hits hits=searcher.search(query,filter);
無上邊界
public static RangeFilter More(String fieldname,String lowerTerm)
無下邊界
public static RangeFilter Less(String fieldname,String upperTerm)
(3)在結果中查詢QueryFilter
RangeQuery q=new RangeQuery(new Term(“publicshdate”,”1970-01-01”),
new Term(“publishdate”,”1999-01-01”),true);
QueryFilter filter=new QueryFilter(q);
Hits hits=searcher.search(query,filter);
3. 分析器Analysis
3.1. 自帶分析器和過濾器
Ø 標準過濾器:StandardAnalyzer
Ø 大小寫轉換器:LowerCaseFilter
Ø 忽略詞過濾器:StopFilter
public StopFilter(TokenStream input,String [] stopWords)
public StopFilter(TokenStream in,String [] stopWords,boolean ignoreCase)
public StopFilter(TokenStream input,Set stopWords,boolean ignoreCase)
public StopFilter(TokenStream in, Set stopWords)
其中,參數TokenStream代表當前正在進行處理的流;String類型的數組代表一個用數組表示的忽略詞集合;Set類型的參數與String一樣,是用來表示忽略詞集合的;boolean表示當與忽略詞集合中的詞進行匹配時,是否需要忽略大小寫。
Ø 長度過濾器:LengthFilter
Ø PerFieldAnalyzerWrapper
Ø WhitespaceAnalyzer
String str="str1 str2 str3";
StringReader reader=new StringReader(str);
Analyzer anlyzer=new WhitespaceAnalyzer();
TokenStream ts=anlyzer.tokenStream("", reader);
Token t=null;
while( (t=ts.next())!=null ){
System.out.println(t.termText());
}
3.2. 第三方過分析器
Ø 單字分詞
Ø 二分法:CJKAnalyzer、中科院ICTCLAS分詞、JE分詞
Ø 詞典分詞
3.2.1.JE分詞用法
3.2.1.1. 示例
import jeasy.analysis.MMAnalyzer;
IndexWriter writer = new IndexWriter(INDEX_STORE_PATH, new MMAnalyzer()
, true);
String str=" Lucene是一個全文檢索引擎的架構,"+
"提供了完整的查詢引擎和索引引擎。Lucene以其方便使用、快" +
"速實施以及靈活性受到廣泛的關注。它可以方便地嵌入到各種應用" +
"中實現針對應用的全文索引、檢索功能,本總結使用lucene--2.3.2。";
MMAnalyzer analyzer=new MMAnalyzer();
try{
System.out.println(analyzer.segment(str, "|"));
}
catch(Exception e)
{
e.printStackTrace();
}
輸出結果:lucene|一個|全文|檢索|引擎|架構|提供|完整|查詢|。。。。
3.2.1.2. 設定正向最大匹配的字數
MMAnalyzer analyzer=new MMAnalyzer(4);
3.2.1.3. 添加新詞
MMAnalyzer.addWord(String word);
MMAnalyzer.addDictionary(Reader reader);
MMAnalyzer analyzer=new MMAnalyzer();
MMAnalyzer.addWord("邁克爾雷第");
4. 索引的合并
RAMDirectory RAMDir=new RAMDirectory();
IndexWriter writer = new IndexWriter(RAMDir, new StandardAnalyzer(), true);//刪除原有索引
IndexWriter writer2=new IndexWriter(FSDirectory.getDirectory(path,true),
new StandardAnalyzer(), true);
writer.addDocument(doc1);
writer2.addDocument(doc2);
writer.close();
writer2.addIndexes(new Directory[]{RAMDir});
writer2.close();
public ActionForward exportExcel(ActionMapping mapping,
ActionForm form, HttpServletRequest request,
HttpServletResponse response) {
String sfile = this.getServlet().getServletContext().getRealPath("/upload/")+ File.separator +"data.xls";// 服務器端名字
String filename ="data.xls";// 客戶端名字
OutputStream os = null;
WritableWorkbook wwb = null;
try {
os = new FileOutputStream(savePath);
wwb = Workbook.createWorkbook(os);//第一步,創建一個webbook,對應一個Excel文件
WritableSheet ws = wwb.createSheet("statistics", 0); //第二步,在webbook中添加一個sheet,對應Excel文件中的sheet
for (int i = 0; i < titleList.size(); i++) {
String title = (String) titleList.get(i);
Label titleLabel = new Label(i+1, 0, title);//從第二列 第一行 開始
ws.addCell(titleLabel);
}
for (int i = 0; i < dataList.size(); i++) {
Map obj= (HashMap) dataList.get(i);
String areaName = (String) obj.get("時間");//價格
Label areaNameLabel = new Label(0, i+1, areaName);
ws.addCell(areaNameLabel);//第一行的值
for (int k = 0; k < str.length; k++) {
if(db != null&& db.trim().equals("0")&&i>2){
Label label = new Label(1+(k*3), i + 1, "xxx");
ws.addCell(label);
label = new Label(2+(k*3), i + 1, "xxx");
ws.addCell(label);
label = new Label(3+(k*3), i + 1, "xxx");
ws.addCell(label);
}else{
String number = (String) obj.get(str[k][0] + "n");//數量
String sum = (String) obj.get(str[k][0] + "s");//金額
String cif = (String) obj.get(str[k][0] + "c");//價格
Label label = new Label(1+(k*3), i + 1, number==null?"0":number);
ws.addCell(label);
label = new Label(2+(k*3), i + 1, sum==null?"0":sum);
ws.addCell(label);
label = new Label(3+(k*3), i + 1, cif==null?"0":cif);
ws.addCell(label);
}
}
}
wwb.write();
} catch (Exception ex) {
ex.printStackTrace();
} finally {
try {
wwb.close();
os.close();
} catch (Exception e) {
e.printStackTrace();
}
}
try {
response.setHeader("Content-Disposition", "attachment;filename="
+ filename);
response.setContentType("application/vnd.ms-excel");
BufferedOutputStream out = new BufferedOutputStream(
new DataOutputStream(response.getOutputStream()));
BufferedInputStream in = new BufferedInputStream(
new FileInputStream(sfile));
byte[] b = new byte[in.available()];
in.read(b);
out.write(b);
out.close();
in.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
jsp 下載txt文件和excel文件
最近做了個用jsp下載的頁面 將代碼貼出來 權作記錄吧
1 下載txt文件
這個花了我不少時間 原因是用ie下載txt文件時是在頁面中直接打開了文件.雖然查了一些資料,也看了別人的解決方案,可還是解決不了問題,最后發現是一個字母惹的禍:少寫一個字母 嘿嘿 夠馬虎!!!
代碼如下:
OutputStream o=response.getOutputStream();
byte b[]=new byte[500];
File fileLoad=new File("e:/test.txt");
response.setContentType("application/octet-stream");
response.setHeader("content-disposition","attachment; filename=text.txt");
long fileLength=fileLoad.length();
String length1=String.valueOf(fileLength);
response.setHeader("Content_Length",length1);
FileInputStream in=new FileInputStream(fileLoad);
int n;
while((n=in.read(b))!=-1){
o.write(b,0,n);
}
in.close();
out.clear();
out = pageContext.pushBody();
2 下載excel文件
跟下載txt文件時的唯一區別是ContentType值的設置不同:
OutputStream o=response.getOutputStream();
byte b[]=new byte[500];
File fileLoad=new File("e:/text.xls");
response.reset();
response.setContentType("application/vnd.ms-excel");
response.setHeader("content-disposition","attachment; filename=text.xls");
long fileLength=fileLoad.length();
String length1=String.valueOf(fileLength);
response.setHeader("Content_Length",length1);
FileInputStream in=new FileInputStream(fileLoad);
int n;
while((n=in.read(b))!=-1){
o.write(b,0,n);
}
in.close();
out.clear();
out = pageContext.pushBody();
這兩個本來是放在一起的,因為我的頁面中需要判斷是下載的txt文件還是xls文件 在這里給分開了 需要注意的是,最后兩句一定要加上,否則會出現getOutputStream()錯誤的!!!!
實例:
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<%
String path = request.getContextPath();
String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<base href="<%=basePath%>">
<title>My JSP 'index.jsp' starting page</title>
<script type="text/javascript">
function download(filename){
var url = encodeURI("down2.jsp?filename="+filename);
window.location.href= url;
}
</script>
</head>
<body>
普通測試:
<a href="javascript:void(0)" onclick="download('a.txt');">Down a.txt</a>
中文文件名測試:
<a href="javascript:void(0)" onclick="download('中文.txt');">Down 中文.txt</a>
普通轉向:
<a href="a.txt">down.txt</a>
</body>
</html>
down2.jsp:
<%@ page language="java" import="java.util.*,java.io.* " pageEncoding="UTF-8"%>
<%
request.setCharacterEncoding("utf-8");
String filename = request.getParameter("filename");
filename = new String(filename.getBytes("ISO-8859-1"),"UTF-8");
System.out.println(filename);
OutputStream o=response.getOutputStream();
byte b[]=new byte[500];
/** * 得到文件的當前路徑 * @param args */
String serverpath=request.getRealPath("\\");
File fileLoad=new File(serverpath+filename);
response.setContentType("application/octet-stream");
response.setHeader("content-disposition","attachment; filename="+filename);
long fileLength=fileLoad.length();
String length1=String.valueOf(fileLength);
response.setHeader("Content_Length",length1);
FileInputStream in=new FileInputStream(fileLoad);
int n;
while((n=in.read(b))!=-1){
o.write(b,0,n);
}
in.close();
out.clear();
out = pageContext.pushBody();
%>
JS導出EXCEL的兩種方法
function method1(tableid) {//整個表格拷貝到EXCEL中
var curTbl = document.getElementById(tableid);
var oXL = new ActiveXObject("Excel.Application");
//創建AX對象excel
var oWB = oXL.Workbooks.Add();
//獲取workbook對象
var oSheet = oWB.ActiveSheet;
//激活當前sheet
var sel = document.body.createTextRange();
sel.moveToElementText(curTbl);
//把表格中的內容移到TextRange中
sel.select();
//全選TextRange中內容
sel.execCommand("Copy");
//復制TextRange中內容
oSheet.Paste();
//粘貼到活動的EXCEL中
oXL.Visible = true;
//設置excel可見屬性
}
function method2(tableid) //讀取表格中每個單元到EXCEL中
{
var curTbl = document.getElementById(tableid);
var oXL = new ActiveXObject("Excel.Application");
//創建AX對象excel
var oWB = oXL.Workbooks.Add();
//獲取workbook對象
var oSheet = oWB.ActiveSheet;
//激活當前sheet
var Lenr = curTbl.rows.length;
//取得表格行數
for (i = 0; i < Lenr; i++)
{
var Lenc = curTbl.rows(i).cells.length;
//取得每行的列數
for (j = 0; j < Lenc; j++)
{
oSheet.Cells(i + 1, j + 1).value = curTbl.rows(i).cells(j).innerText;
//賦值
}
}
oXL.Visible = true;
//設置excel可見屬性
}
<input type="button" onclick="javascript:method1('TableExcel');" value="第一種方法導入到EXCEL">
<input type="button" onclick="javascript:method2('TableExcel');" value="第二種方法導入到EXCEL">
5. 排序
通過 SortField 的構造參數,我們可以設置排序字段,排序條件,以及倒排。
Sort sort = new Sort(new SortField(FieldName, SortField.DOC, false)); IndexSearcher searcher = new IndexSearcher(reader); Hits hits = searcher.Search(query, sort);
排序對搜索速度影響還是很大的,盡可能不要使用多個排序條件。
6. 過濾
使用 Filter 對搜索結果進行過濾,可以獲得更小范圍內更精確的結果。
舉個例子,我們搜索上架時間在 2005-10-1 到 2005-10-30 之間的商品。
對于日期時間,我們需要轉換一下才能添加到索引庫,同時還必須是索引字段。
// index document.Add(FieldDate, DateField.DateToString(date), Field.Store.YES, Field.Index.UN_TOKENIZED); //... // search Filter filter = new DateFilter(FieldDate, DateTime.Parse("2005-10-1"), DateTime.Parse("2005-10-30")); Hits hits = searcher.Search(query, filter);
除了日期時間,還可以使用整數。比如搜索價格在 100 ~ 200 之間的商品。
Lucene.Net NumberTools 對于數字進行了補位處理,如果需要使用浮點數可以自己參考源碼進行。
// index document.Add(new Field(FieldNumber, NumberTools.LongToString((long)price), Field.Store.YES, Field.Index.UN_TOKENIZED)); //... // search Filter filter = new RangeFilter(FieldNumber, NumberTools.LongToString(100L), NumberTools.LongToString(200L), true, true); Hits hits = searcher.Search(query, filter);
使用 Query 作為過濾條件。
QueryFilter filter = new QueryFilter(QueryParser.Parse("name2", FieldValue, analyzer));
我們還可以使用 FilteredQuery 進行多條件過濾。
Filter filter = new DateFilter(FieldDate, DateTime.Parse("2005-10-10"), DateTime.Parse("2005-10-15")); Filter filter2 = new RangeFilter(FieldNumber, NumberTools.LongToString(11L), NumberTools.LongToString(13L), true, true); Query query = QueryParser.Parse("name*", FieldName, analyzer); query = new FilteredQuery(query, filter); query = new FilteredQuery(query, filter2); IndexSearcher searcher = new IndexSearcher(reader); Hits hits = searcher.Search(query);
7. 分布搜索
我們可以使用 MultiReader 或 MultiSearcher 搜索多個索引庫。
MultiReader reader = new MultiReader(new IndexReader[] { IndexReader.Open(@"c:\index"), IndexReader.Open(@"\\server\index") }); IndexSearcher searcher = new IndexSearcher(reader); Hits hits = searcher.Search(query);
或
IndexSearcher searcher1 = new IndexSearcher(reader1); IndexSearcher searcher2 = new IndexSearcher(reader2); MultiSearcher searcher = new MultiSearcher(new Searchable[] { searcher1, searcher2 }); Hits hits = searcher.Search(query);
還可以使用 ParallelMultiSearcher 進行多線程并行搜索。
8. 合并索引庫
將 directory1 合并到 directory2 中。
Directory directory1 = FSDirectory.GetDirectory("index1", false); Directory directory2 = FSDirectory.GetDirectory("index2", false); IndexWriter writer = new IndexWriter(directory2, analyzer, false); writer.AddIndexes(new Directory[] { directory }); Console.WriteLine(writer.DocCount()); writer.Close();
9. 顯示搜索語法字符串
我們組合了很多種搜索條件,或許想看看與其對等的搜索語法串是什么樣的。
BooleanQuery query = new BooleanQuery(); query.Add(query1, true, false); query.Add(query2, true, false); //... Console.WriteLine("Syntax: {0}", query.ToString());
輸出:
Syntax: +(name:name* value:name*) +number:[0000000000000000b TO 0000000000000000d]
呵呵,就這么簡單。
10. 操作索引庫
刪除 (軟刪除,僅添加了刪除標記。調用 IndexWriter.Optimize() 后真正刪除。)
IndexReader reader = IndexReader.Open(directory); // 刪除指定序號(DocId)的 Document。 reader.Delete(123); // 刪除包含指定 Term 的 Document。 reader.Delete(new Term(FieldValue, "Hello")); // 恢復軟刪除。 reader.UndeleteAll(); reader.Close();
增量更新 (只需將 create 參數設為 false,即可往現有索引庫添加新數據。)
Directory directory = FSDirectory.GetDirectory("index", false); IndexWriter writer = new IndexWriter(directory, analyzer, false); writer.AddDocument(doc1); writer.AddDocument(doc2); writer.Optimize(); writer.Close();
11. 優化
批量向 FSDirectory 增加索引時,增大合并因子(mergeFactor )和最小文檔合并數(minMergeDocs)有助于提高性能,減少索引時間。
IndexWriter writer = new IndexWriter(directory, analyzer, true); writer.maxFieldLength = 1000; // 字段最大長度 writer.mergeFactor = 1000; writer.minMergeDocs = 1000; for (int i = 0; i < 10000; i++) { // Add Documentes... } writer.Optimize(); writer.Close();
文章來自學IT網:http://www.xueit.com/LuceneNet/show-10315-2.aspx
轉自《深入 Lucene 索引機制》
利用 Lucene,在創建索引的工程中你可以充分利用機器的硬件資源來提高索引的效率。當你需要索引大量的文件時,你會注意到索引過程的瓶頸是在往磁盤上寫索引文件的過程中。為了解決這個問題, Lucene 在內存中持有一塊緩沖區。但我們如何控制 Lucene 的緩沖區呢?幸運的是,Lucene 的類 IndexWriter 提供了三個參數用來調整緩沖區的大小以及往磁盤上寫索引文件的頻率。
1.合并因子 (mergeFactor)
這個參數決定了在 Lucene 的一個索引塊中可以存放多少文檔以及把磁盤上的索引塊合并成一個大的索引塊的頻率。比如,如果合并因子的值是 10,那么當內存中的文檔數達到 10 的時候所有的文檔都必須寫到磁盤上的一個新的索引塊中。并且,如果磁盤上的索引塊的隔數達到 10 的話,這 10 個索引塊會被合并成一個新的索引塊。這個參數的默認值是 10,如果需要索引的文檔數非常多的話這個值將是非常不合適的。對批處理的索引來講,為這個參數賦一個比較大的值會得到比較好的索引效果。
2.最小合并文檔數 (minMergeDocs)
這個參數也會影響索引的性能。它決定了內存中的文檔數至少達到多少才能將它們寫回磁盤。這個參數的默認值是10,如果你有足夠的內存,那么將這個值盡量設的比較大一些將會顯著的提高索引性能。
3.最大合并文檔數 (maxMergeDocs)
這個參數決定了一個索引塊中的最大的文檔數。它的默認值是 Integer.MAX_VALUE,將這個參數設置為比較大的值可以提高索引效率和檢索速度,由于該參數的默認值是整型的最大值,所以我們一般不需要改動這個參數。
文章來自學IT網:http://www.xueit.com/LuceneNet/show-10315-2.aspx
一、創建索引 :TDictionaryIndex.java 例子
二、實用Lucene收索
A. 普通查詢
if (pname != null && !("").equals(pname)) {
queryParser = new QueryParser("name", analyzer);
query = queryParser.parse(pname);
booleanQuery.add(query, BooleanClause.Occur.MUST);
}
B. In 范圍查詢
if(datavarsor.trim().equals("30,22,4,14,12,2,7,15,21,1,6,8,5,28")){
datavarsor="30 22 4 14 12 2 7 15 21 1 6 8 5 28";
queryParser = new QueryParser("datavarsort", analyzer);
queryParser.setDefaultOperator(QueryParser.Operator.OR);//
query = queryParser.parse(datavarsor);// 多選擇產品稅號
booleanQuery.add(query, BooleanClause.Occur.MUST);
}
C. 選擇查詢 關鍵字
if (wd != null && !wd.equals("")) {
queryParser = new MultiFieldQueryParser(new String[] {// 查詢條件是或的關系。。。
"department", "isorno", "filename" }, analyzer);
query = queryParser.parse(wd);
booleanQuery.add(query, BooleanClause.Occur.MUST);
HeighlighterQuery = query;
D.準確查詢
注意創建索引的時候:
if (typename != null && !typename.equals(""))
document.add(new Field("typename", typename, Field.Store.YES,
Field.Index.UN_TOKENIZED));
查詢的時候:
query = new TermQuery(new Term("typename", typename));
booleanQuery.add(query, BooleanClause.Occur.MUST);
E.時間排序
org.apache.lucene.search.Sort sort2 = new org.apache.lucene.search.Sort(new SortField("endtime", SortField.STRING,
true));// 完成按照時間來排序
hits = search.search(booleanQuery, null, toIndex,sort2).scoreDocs;
}
不用jquery實現$.val(), $.html(), $.css(), $.attr()
jquery寫久了,發現val, html,attr, 和css這些函數非常的實用,但是沒有jquery的環境呢?可以使用以下代碼來分別代替。
toolbarLocation="top" 設置導出、翻頁在表格開頭
---------------擴展行可以任意添加內容
<ec:extendbar before="top">
<tr style="background-color:#ffeedd" title="擴展行">
<td colspan="2"><a>導出</a></td>
<td>任意信息0</td>
<td>任意信息1</td>
<td>任意信息2</td>
</tr>
</ec:extendbar>
var OneMonth = start.substring(5,start.lastIndexOf ('-')); var OneDay = start.substring(start.length,start.lastIndexOf ('-')+1); var OneYear = start.substring(0,start.indexOf ('-')); var TwoMonth = end.substring(5,end.lastIndexOf ('-')); var TwoDay = end.substring(end.length,end.lastIndexOf ('-')+1); var TwoYear = end.substring(0,end.indexOf ('-')); var cha=((Date.parse(OneMonth+'/'+OneDay+'/'+OneYear)- Date.parse(TwoMonth+'/'+TwoDay+'/'+TwoYear))/86400000); alert(cha); var date1=new Date("2008/7/29"); var date2=new Date(); var nDiff=date2-date1; var nHour,nMini,nSecond; nHour=parseInt(nDiff/3600000); nMini=parseInt((nDiff%3600000)/60000); alert("今天距離昨天零點:\n" +nHour+":小時\n" +nMini+":分鐘"); http://blog.csdn.net/xuStanly/article/details/2186411
以下并非本人整理,但是看后感覺相當不錯,特此收藏共享。
1、應用程序中,保證在實現功能的基礎上,盡量減少對數據庫的訪問次數;通過
搜索參數,盡量減少對表的訪問行數,最小化結果集,從而減輕網絡負擔;能夠分
開的操作盡量分開處理,提高每次的響應速度;在數據窗口使用SQL時,盡量把使
用的索引放在選擇的首列;算法的結構盡量簡單;在查詢時,不要過多地使用通配
符如SELECT * FROM T1語句,要用到幾列就選擇幾列如:SELECT COL1,COL2 FROM
T1;在可能的情況下盡量限制盡量結果集行數如:SELECT TOP 300
COL1,COL2,COL3 FROM T1,因為某些情況下用戶是不需要那么多的數據的。不要在
應用中使用數據庫游標,游標是非常有用的工具,但比使用常規的、面向集的SQL
語句需要更大的開銷;按照特定順序提取數據的查找。
2、 避免使用不兼容的數據類型。例如float和int、char和varchar、binary和
varbinary是不兼容的。數據類型的不兼容可能使優化器無法執行一些本來可以進
行的優化操作。例如:
SELECT name FROM employee WHERE salary > 60000
在這條語句中,如salary字段是money型的,則優化器很難對其進行優化,因為60000
是個整型數。我們應當在編程時將整型轉化成為錢幣型,而不要等到運行時轉化。
3、 盡量避免在WHERE子句中對字段進行函數或表達式操作,這將導致引擎放棄
使用索引而進行全表掃描。如:
SELECT * FROM T1 WHERE F1/2=100
應改為:
SELECT * FROM T1 WHERE F1=100*2
SELECT * FROM RECORD WHERE SUBSTRING(CARD_NO,1,4)=’5378’
應改為:
SELECT * FROM RECORD WHERE CARD_NO LIKE ‘5378%’
SELECT member_number, first_name, last_name FROM members
WHERE DATEDIFF(yy,datofbirth,GETDATE()) > 21
應改為:
SELECT member_number, first_name, last_name FROM members
WHERE dateofbirth < DATEADD(yy,-21,GETDATE())
即:任何對列的操作都將導致表掃描,它包括數據庫函數、計算表達式等等,查詢
時要盡可能將操作移至等號右邊。
4、 避免使用!=或<>、IS NULL或IS NOT NULL、IN ,NOT IN等這樣的操作符,
因為這會使系統無法使用索引,而只能直接搜索表中的數據。例如:
SELECT id FROM employee WHERE id != 'B%'
優化器將無法通過索引來確定將要命中的行數,因此需要搜索該表的所有行。
5、 盡量使用數字型字段,一部分開發人員和數據庫管理人員喜歡把包含數值信
息的字段
設計為字符型,這會降低查詢和連接的性能,并會增加存儲開銷。這是因為引擎在
處理查詢和連接回逐個比較字符串中每一個字符,而對于數字型而言只需要比較一
次就夠了。
6、 合理使用EXISTS,NOT EXISTS子句。如下所示:
1.SELECT SUM(T1.C1)FROM T1 WHERE(
(SELECT COUNT(*)FROM T2 WHERE T2.C2=T1.C2>0)
2.SELECT SUM(T1.C1) FROM T1WHERE EXISTS(
SELECT * FROM T2 WHERE T2.C2=T1.C2)
兩者產生相同的結果,但是后者的效率顯然要高于前者。因為后者不會產生大量鎖
定的表掃描或是索引掃描。
如果你想校驗表里是否存在某條紀錄,不要用count(*)那樣效率很低,而且浪費服
務器資源。可以用EXISTS代替。如:
IF (SELECT COUNT(*) FROM table_name WHERE column_name = 'xxx')
可以寫成:
IF EXISTS (SELECT * FROM table_name WHERE column_name = 'xxx')
經常需要寫一個T_SQL語句比較一個父結果集和子結果集,從而找到是否存在在父
結果集中有而在子結果集中沒有的記錄,如:
1.SELECT a.hdr_key FROM hdr_tbl a---- tbl a 表示tbl用別名a代替
WHERE NOT EXISTS (SELECT * FROM dtl_tbl b WHERE a.hdr_key = b.hdr_key)
2.SELECT a.hdr_key FROM hdr_tbl a
LEFT JOIN dtl_tbl b ON a.hdr_key = b.hdr_key WHERE b.hdr_key IS NULL
3.SELECT hdr_key FROM hdr_tbl
WHERE hdr_key NOT IN (SELECT hdr_key FROM dtl_tbl)
三種寫法都可以得到同樣正確的結果,但是效率依次降低。
7、 盡量避免在索引過的字符數據中,使用非打頭字母搜索。這也使得引擎無法
利用索引。
見如下例子:
SELECT * FROM T1 WHERE NAME LIKE ‘%L%’
SELECT * FROM T1 WHERE SUBSTING(NAME,2,1)=’L’
SELECT * FROM T1 WHERE NAME LIKE ‘L%’
即使NAME字段建有索引,前兩個查詢依然無法利用索引完成加快操作,引擎不得不
對全表所有數據逐條操作來完成任務。而第三個查詢能夠使用索引來加快操作。
8、 分利用連接條件,在某種情況下,兩個表之間可能不只一個的連接條件,這
時在 WHERE 子句中將連接條件完整的寫上,有可能大大提高查詢速度。
例:
SELECT SUM(A.AMOUNT) FROM ACCOUNT A,CARD B WHERE A.CARD_NO = B.CARD_NO
SELECT SUM(A.AMOUNT) FROM ACCOUNT A,CARD B WHERE A.CARD_NO = B.CARD_NO
AND A.ACCOUNT_NO=B.ACCOUNT_NO
第二句將比第一句執行快得多。
9、 消除對大型表行數據的順序存取
盡管在所有的檢查列上都有索引,但某些形式的WHERE子句強迫優化器使用
順序存取。如:
SELECT * FROM orders WHERE (customer_num=104 AND order_num>1001) OR
order_num=1008
解決辦法可以使用并集來避免順序存取:
SELECT * FROM orders WHERE customer_num=104 AND order_num>1001
UNION
SELECT * FROM orders WHERE order_num=1008
這樣就能利用索引路徑處理查詢。
10、 避免困難的正規表達式
LIKE關鍵字支持通配符匹配,技術上叫正規表達式。但這種匹配特別耗費時
間。例如:SELECT * FROM customer WHERE zipcode LIKE “98_ _ _”
即使在zipcode字段上建立了索引,在這種情況下也還是采用順序掃描的方式。如
果把語句改為SELECT * FROM customer WHERE zipcode >“98000”,在執行查詢
時就會利用索引來查詢,顯然會大大提高速度。
11、 使用視圖加速查詢
把表的一個子集進行排序并創建視圖,有時能加速查詢。它有助于避免多重排序
操作,而且在其他方面還能簡化優化器的工作。例如:
SELECT cust.name,rcvbles.balance,……other columns
FROM cust,rcvbles
WHERE cust.customer_id = rcvlbes.customer_id
AND rcvblls.balance>0
AND cust.postcode>“98000”
ORDER BY cust.name
如果這個查詢要被執行多次而不止一次,可以把所有未付款的客戶找出來放在一個
視圖中,并按客戶的名字進行排序:
CREATE VIEW DBO.V_CUST_RCVLBES
AS
SELECT cust.name,rcvbles.balance,……other columns
FROM cust,rcvbles
WHERE cust.customer_id = rcvlbes.customer_id
AND rcvblls.balance>0
ORDER BY cust.name
然后以下面的方式在視圖中查詢:
SELECT * FROM V_CUST_RCVLBES
WHERE postcode>“98000”
視圖中的行要比主表中的行少,而且物理順序就是所要求的順序,減少了磁盤
I/O,所以查詢工作量可以得到大幅減少。
12、 能夠用BETWEEN的就不要用IN
SELECT * FROM T1 WHERE ID IN (10,11,12,13,14)
改成:
SELECT * FROM T1 WHERE ID BETWEEN 10 AND 14
因為IN會使系統無法使用索引,而只能直接搜索表中的數據。
13、 DISTINCT的就不用GROUP BY
SELECT OrderID FROM Details WHERE UnitPrice > 10 GROUP BY OrderID
可改為:
SELECT DISTINCT OrderID FROM Details WHERE UnitPrice > 10
14、 部分利用索引
1.SELECT employeeID, firstname, lastname
FROM names
WHERE dept = 'prod' or city = 'Orlando' or division = 'food'
2.SELECT employeeID, firstname, lastname FROM names WHERE dept =
'prod'
UNION ALL
SELECT employeeID, firstname, lastname FROM names WHERE city = 'Orlando'
UNION ALL
SELECT employeeID, firstname, lastname FROM names WHERE division =
'food'
如果dept 列建有索引則查詢2可以部分利用索引,查詢1則不能。
15、 能用UNION ALL就不要用UNION
UNION ALL不執行SELECT DISTINCT函數,這樣就會減少很多不必要的資源
16、 不要寫一些不做任何事的查詢
如:SELECT COL1 FROM T1 WHERE 1=0
SELECT COL1 FROM T1 WHERE COL1=1 AND COL1=2
這類死碼不會返回任何結果集,但是會消耗系統資源。
17、 盡量不要用SELECT INTO語句。
SELECT INTO 語句會導致表鎖定,阻止其他用戶訪問該表。
18、 必要時強制查詢優化器使用某個索引
SELECT * FROM T1 WHERE nextprocess = 1 AND processid IN (8,32,45)
改成:
SELECT * FROM T1 (INDEX = IX_ProcessID) WHERE nextprocess = 1 AND
processid IN (8,32,45)
則查詢優化器將會強行利用索引IX_ProcessID 執行查詢。
19、 雖然UPDATE、DELETE語句的寫法基本固定,但是還是對UPDATE語句給點建
議:
a) 盡量不要修改主鍵字段。
b) 當修改VARCHAR型字段時,盡量使用相同長度內容的值代替。
c) 盡量最小化對于含有UPDATE觸發器的表的UPDATE操作。
d) 避免UPDATE將要復制到其他數據庫的列。
e) 避免UPDATE建有很多索引的列。
f) 避免UPDATE在WHERE子句條件中的列。
上面我們提到的是一些基本的提高查詢速度的注意事項,但是在更多的情況下,往往
需要反復試驗比較不同的語句以得到最佳方案。最好的方法當然是測試,看實現相
同功能的SQL語句哪個執行時間最少,但是數據庫中如果數據量很少,是比較不出
來的,這時可以用查看執行計劃,即:把實現相同功能的多條SQL語句考到查詢分
析器,按CTRL+L看查所利用的索引,表掃描次數(這兩個對性能影響最大),總體
上看詢成本百分比即可。
簡單的存儲過程可以用向導自動生成:在企業管理器工具欄點擊運行向導圖標,點
擊”數據庫”、”創建存儲過程向導”。復雜存儲過程的調試:在查詢分析器左邊
的對象瀏覽器(沒有?按F8)選擇要調試的存儲過程,點右鍵,點調試,輸入參數
執行,出現一個浮動工具條,上面有單步執行,斷點設置等。
|