開始接觸工作流是兩年前,那時剛進公司,自己也算是個新手,到公司后被分配到做IT網管的項目組,做了些東西,后來成立了個新的項目組,我被分配到這個新組成的項目組,也就是從這以后開始接觸工作流的。當時對工作流是一點概念都沒有,慢慢從公司開發的基于db的工作流平臺開始接觸工作流,并基于此工作流平臺結合業務開發了幾個模塊。
公司的這個基于db的工作流平臺還是實現了許多功能:
1、基于web的流程設計器,主要是基于IE的vml語言開發的,可以設計出如下圖的流程模板。
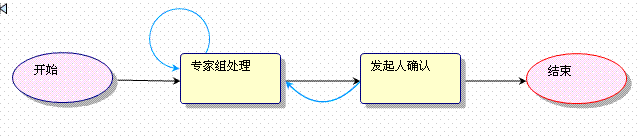
此流程模板包括開始環節,結束環節以及人工處理的兩個環節(專家組處理和發起人確認),實現環節的自循環以及回朔,分別在“專家組處理”環節和“發起人確認”環節上實現。基于此流程運行中的實例圖如下:

2
、環節的扭轉
A
、串行
像上圖中介紹的就是實現了串行的功能。
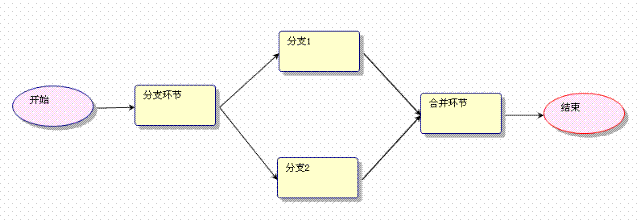
B
、并行如圖
C、多實例(即平常所說的會簽)
實現了包括所有會簽都完成后才往下個環節走和幾個會簽后就可往下個環節走的功能,流程的模板如圖:
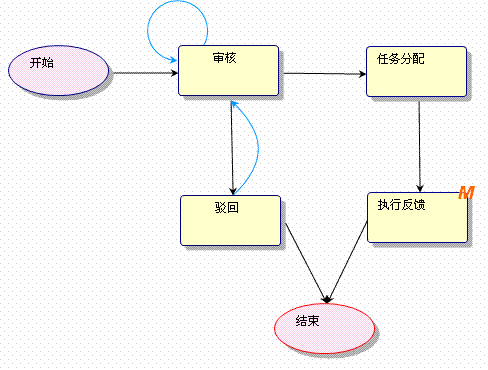
其中環節模板上帶“M”的環節就表示是多實例的環節。
運行中的實例如圖:

D、子流程子流程是在一個虛擬環節中實現的,即該環節不是人工環節。如圖:

基本上一個簡單的工作流平臺的功能都差不多實現了,不過在使用過程中還是發現了許多的弊端,畢竟系統的邏輯大部分是基于數據庫函數實現的,這使得大部分的邏輯都要依賴于數據庫,而外圍的一些基于java的邏輯實現就比較難實現了,舉個例子:在和外系統做接口時,當某個環節竣工后要向外系統發信息,而信息是通過url的方式傳遞的,這個用java實現是很容易的,而用數據庫函數就無法直接實現了(據目前自己掌握的技術判斷,不知是否有辦法實現,望知道者告知),現在變通的一個做法是在數據庫里保存信息,然后通過quartz定時的掃描該表,有數據則通過httpclient給外系統發送信息。還有模型本身只有開始環節,結束環節,虛擬環節和人工執行環節,使得客戶提的要按業務路由的功能就無法實現了,因為缺少個判斷環節模板,就是jbpm中的decision環節模板,所以在創建下個環節的時候大部分都是人為的主觀去判斷到底是走上圖中的“方案審核”還是“任務分配”環節。這使得運用流程整合業務邏輯時并沒有完全的實現流程的自動化。
其實還有很多的缺陷,只是我們都是通過變相的方式給予了實現,可是客戶有些需求在該平臺上還是無法實現的。鑒于此,就開始尋找開源的工作流引擎,在osworkflow、jbpm、shark等的開源工作流引擎中選擇了jbpm。為什么會選擇jbpm呢?原因還是蠻多的,具體列出幾條如下幾條:
1、 基于petri net理論實現的工作流。
2、 引擎核心以微內核的方式實現(主要邏輯都在graph包下)。
3、 基于hibernate實現持久化。
4、 很容易的和spring實現整合,通過spring-modules實現整合。
等。最后附上一個最復雜的流程圖(像蜘蛛網更貼切^_^)
posted on 2008-09-15 18:21
囧囧之豬 閱讀(727)
評論(0) 編輯 收藏 所屬分類:
workflow