前段時間有個朋友問我,分布式主鍵生成策略在我們這邊是怎么實現的,當時我給的答案是sequence,當然這在不高并發的情況下是沒有任何問題,實際上,我們的主鍵生成是可控的,但如果是在分布式高并發的情況下,那肯定是有問題的。
突然想起mongodb的objectid,記得以前看過文檔,objectid是一種輕量型的,不同的機器都能用全局唯一的同種方法輕量的生成它,而不是采用傳統的自增的主鍵策略,因為在多臺服務器上同步自動增加主鍵既費力又費時,不得不佩服,mongodb從開始設計就被定義為分布式數據庫。
下面深入一點來翻翻這個Objectid的底細,在mongodb集合中的每個document中都必須有一個"_id"建,這個鍵的值可以是任何類型的,在默認的情況下是個Objectid對象。
當我們讓一個collection中插入一條不帶_id的記錄,系統會自動地生成一個_id的key
> db.t_test.insert({"name":"cyz"})
> db.t_test.findOne({"name":"cyz"})
{ "_id" : ObjectId("4df2dcec2cdcd20936a8b817"), "name" : "cyz" }
可以發現這里多出一個Objectid類型的_id,當然了,這個_id是系統默認生成的,你也可以為其指定一個值,不過在同一collections中該值必須是唯一的
把 ObjectId("4df2dcec2cdcd20936a8b817")這串值拿出來并對照官網的解析來深入分析。
"4df2dcec2cdcd20936a8b817" 以這段字符串為例來進行解析,這是一個24位的字符串,看起來很長,很難理解,實際上它是由ObjectId(string)所創建的一組十六進制的字符,每個字節兩位的十六進制數字,總共使用了12字節的存儲空間,可能有些朋友會感到很奇怪,居然是用了12個字節,而mysql的INT類型也只有4個字節,不過按照現在的存儲設備,多出來的這點字節也應該不會成為什么瓶頸,實際上,mongodb在設計上無處不在的體現著用空間換時間的思想,接下看吧
下面是官網指定Bson中ObjectId的詳細規范
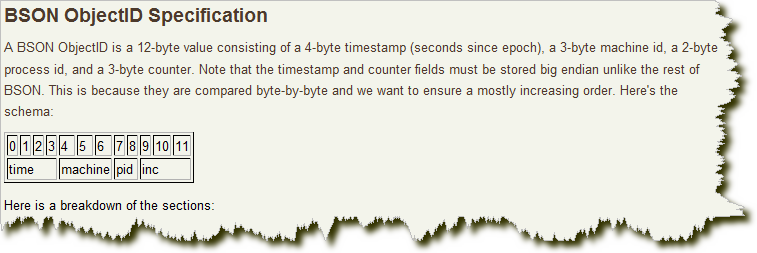
TimeStamp
前4位是一個unix的時間戳,是一個int類別,我們將上面的例子中的objectid的前4位進行提取“4df2dcec”,然后再將他們安裝十六進制專為十進制:“1307761900”,這個數字就是一個時間戳,為了讓效果更佳明顯,我們將這個時間戳轉換成我們習慣的時間格式
$ date -d '1970-01-01 UTC 1307761900 sec' -u
2011年 06月 11日 星期六 03:11:40 UTC
前4個字節其實隱藏了文檔創建的時間,并且時間戳處在于字符的最前面,這就意味著ObjectId大致會按照插入進行排序,這對于某些方面起到很大作用,如作為索引提高搜索效率等等。使用時間戳還有一個好處是,某些客戶端驅動可以通過ObjectId解析出該記錄是何時插入的,這也解答了我們平時快速連續創建多個Objectid時,會發現前幾位數字很少發現變化的現實,因為使用的是當前時間,很多用戶擔心要對服務器進行時間同步,其實這個時間戳的真實值并不重要,只要其總不停增加就好。
Machine
接下來的三個字節,就是 2cdcd2 ,這三個字節是所在主機的唯一標識符,一般是機器主機名的散列值,這樣就確保了不同主機生成不同的機器hash值,確保在分布式中不造成沖突,這也就是在同一臺機器生成的objectid中間的字符串都是一模一樣的原因。
pid
上面的Machine是為了確保在不同機器產生的objectid不沖突,而pid就是為了在同一臺機器不同的mongodb進程產生了objectid不沖突,接下來的0936兩位就是產生objectid的進程標識符。
increment
前面的九個字節是保證了一秒內不同機器不同進程生成objectid不沖突,這后面的三個字節a8b817,是一個自動增加的計數器,用來確保在同一秒內產生的objectid也不會發現沖突,允許256的3次方等于16777216條記錄的唯一性。
客戶端生成mongodb產生objectid還有一個更大的優勢,就是mongodb可以通過自身的服務來產生objectid,也可以通過客戶端的驅動程序來產生,如果你仔細看文檔你會感嘆,mongodb的設計無處不在的使
用空間換時間的思想,比較objectid是輕量級,但服務端產生也必須開銷時間,所以能從服務器轉移到客戶端驅動程序完成的就盡量的轉移,必須將事務扔給客戶端來完成,減低服務端的開銷,另還有一點原因就是擴展應用層比擴展數據庫層要變量得多。
好吧,既然我們了解到我們的程序產生objectid是在客戶端完成,那再繼續,進一步了解,打開
mongodb java driver源碼,無源碼可以到mongodb官網進行下載,下面摘錄部分代碼
public class ObjectId implements Comparable<ObjectId> , java.io.Serializable {

final int _time;
final int _machine;
final int _inc;
public ObjectId( byte[] b ){
if ( b.length != 12 )
throw new IllegalArgumentException( "need 12 bytes" );
ByteBuffer bb = ByteBuffer.wrap( b );
_time = bb.getInt();
_machine = bb.getInt();
_inc = bb.getInt();
_new = false;
}
public ObjectId( int time , int machine , int inc ){
_time = time;
_machine = machine;
_inc = inc;
_new = false;
}
public ObjectId(){
_time = (int) (System.currentTimeMillis() / 1000);
_machine = _genmachine;
_inc = _nextInc.getAndIncrement();
_new = true;
}
(完整代碼請查看源碼) 這里可以發現ObjectId的構建可以有多種方式,可以由自己制定字節,也可以指定時間,機器碼和自增值,這里重點看看驅動程序默認的構建,也就是public ObjectId()
可以看到objectid主要由_time _machine _inc 所組成,其中 _time直接由(System.currentTimeMillis() / 1000)計算出所謂的時間戳,這里很簡單,接下來是重點,主要看看機器碼和進程碼的構建
private static final int _genmachine;
static {
try {
final int machinePiece;//機器碼塊
{
StringBuilder sb = new StringBuilder();
Enumeration<NetworkInterface> e = NetworkInterface.getNetworkInterfaces();//NetworkInterface此類表示一個由名稱和分配給此接口的 IP 地址列表組成的網絡接口,它用于標識將多播組加入的本地接口,這里通過NetworkInterface此機器上所有的接口
while ( e.hasMoreElements() ){
NetworkInterface ni = e.nextElement();
sb.append( ni.toString() );
}
machinePiece = sb.toString().hashCode() << 16; //將得到所有接口的字符串進行取散列值
LOGGER.fine( "machine piece post: " + Integer.toHexString( machinePiece ) );
}
final int processPiece;//進程塊
{
int processId = new java.util.Random().nextInt();
try {
processId = java.lang.management.ManagementFactory.getRuntimeMXBean().getName().hashCode();//RuntimeMXBean是Java虛擬機的運行時系統的管理接口,這里是返回表示正在運行的 Java 虛擬機的名稱,并進行取散列值。
}
catch ( Throwable t ){
}
ClassLoader loader = ObjectId.class.getClassLoader();
int loaderId = loader != null ? System.identityHashCode(loader) : 0;
StringBuilder sb = new StringBuilder();
sb.append(Integer.toHexString(processId));
sb.append(Integer.toHexString(loaderId));
processPiece = sb.toString().hashCode() & 0xFFFF;
LOGGER.fine( "process piece: " + Integer.toHexString( processPiece ) );
}
_genmachine = machinePiece | processPiece; //最后將機器碼塊的散列值與進程塊的散列值進行位或運算,得到 _genmachine
LOGGER.fine( "machine : " + Integer.toHexString( _genmachine ) );
}
catch ( java.io.IOException ioe ){
throw new RuntimeException( ioe );
}
}
Enumeration<NetworkInterface> e = NetworkInterface.getNetworkInterfaces();
while ( e.hasMoreElements() ){
NetworkInterface ni = e.nextElement();
sb.append( ni.toString() );
}
machinePiece = sb.toString().hashCode() << 16;
這里的NetworkInterface.getNetworkInterfaces();取得的接口通常是按名稱(如 "le0")區分的,大約是下面的類型
name:lo (Software Loopback Interface 1) index: 1 addresses:
/0:0:0:0:0:0:0:1;
/127.0.0.1;
name:net0 (WAN Miniport (SSTP)) index: 2 addresses:
name:net1 (WAN Miniport (IKEv2)) index: 3 addresses:
name:net2 (WAN Miniport (L2TP)) index: 4 addresses:
name:net3 (WAN Miniport (PPTP)) index: 5 addresses:
name:ppp0 (WAN Miniport (PPPOE)) index: 6 addresses:
這里為什么要采取這樣方面進行取散列值,感覺有些不太理解,應該網絡接口本身相對而言是并不穩定的
int processId = new java.util.Random().nextInt();
try {
processId = java.lang.management.ManagementFactory.getRuntimeMXBean().getName().hashCode();
}
catch ( Throwable t ){
}RuntimeMXBean是Java虛擬機的運行時系統的管理接口,這里是返回表示正在運行的 Java 虛擬機的名稱,并進行取散列值,如果在這過程中出現異常,processId 將以隨機數的方式繼續計算
_genmachine = machinePiece | processPiece;最后將機器碼塊的散列值與進程塊的散列值進行位或運算,當然這里是十進制,你把這里的十進制專為十六進制,就會發現這塊的值就是生產objectid中間部分的值,這里的構建跟服務端的構建是有些不一樣的,不過最基本的構建元素還是一致的,就是TimeStamp,Machine ,pid,increment。
mongodb的ObejctId生產思想在很多方面挺值得我們借鑒的,特別是在大型分布式的開發,如何構建輕量級的生產,如何將生產的負載進行轉移,如何以空間換取時間提高生產的最大優化等等。
----------------------------------------
by 陳于喆
QQ:34174409
Mail: dongbule@163.com